Hadoop生态圈框架部署(九-2)- Hive HA(高可用)部署
文章目录
- 前言
- 一、Hive部署(手动部署)
- 下载Hive
- 1. 上传安装包
- 2. 解压Hive安装包
- 2.1 解压
- 2.2 重命名
- 2.3 解决冲突
- 2.3.1 解决guava冲突
- 2.3.2 解决SLF4J冲突
- 3. 配置Hive
- 3.1 配置Hive环境变量
- 3.2 修改 hive-site.xml 配置文件
- 3.3 配置MySQL驱动包
- 3.3.1 下在MySQL驱动包
- 3.3.2 上传MySQL驱动包
- 3.3.3 配置MySQL驱动包
- 4. 初始化MySQL上的存储hive元数据的数据库
- 5. 进入Hive客户端
- 6. 设置远程连接
- 6.1 启动MetaStore服务
- 6.2 启动HiveServer2服务
- 6.3 进入Hive客户端
- 二、Hive HA(高可用)实现
- 1. 在hadoop2部署hive
- 1.1 安装配置hive
- 1.2 设置环境变量
- 1.3 设置远程连接
- 2. 在hadoop3部署hive
- 2.1 安装配置hive
- 2.2 设置环境变量
- 2.3 设置远程连接
- 3. 测试远程连接
- 注意
前言
在大数据处理领域,Hive 是一个强大的数据仓库工具,能够提供数据的查询、分析和管理功能。它基于 Hadoop 构建,允许用户使用类似 SQL 的查询语言(HiveQL)来操作存储在 Hadoop 分布式文件系统(HDFS)中的数据。本文将详细介绍如何手动部署 Hive 3.1.3,包括从下载、安装到配置的每一个步骤。此外,我们还将探讨如何在多台虚拟机上实现 Hive 的高可用性(HA),确保在集群环境中能够稳定高效地运行 Hive 服务。
通过本教程,您将能够掌握 Hive 的基本部署和配置流程,并了解如何在多个节点上设置 Hive,以实现负载均衡和故障转移。
一、Hive部署(手动部署)
下载Hive
点击在华为镜像站下载Hvie3.1.3安装包:https://repo.huaweicloud.com/apache/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
1. 上传安装包
通过拖移的方式将下载的Hive安装包apache-hive-3.1.3-bin.tar.gz上传至虚拟机hadoop1的/export/software目录。

2. 解压Hive安装包
2.1 解压
在虚拟机hadoop1上传完成后将Hive安装包通过解压方式安装至/export/servers目录。
tar -zxvf /export/software/apache-hive-3.1.3-bin.tar.gz -C /export/servers/
解压完成如下图所示。

2.2 重命名
在虚拟机hadoop1执行如下命令将apache-hive-3.1.3-bin重命名为hive-3.1.3。
mv /export/servers/apache-hive-3.1.3-bin /export/servers/hive-3.1.3

2.3 解决冲突
2.3.1 解决guava冲突
如下图所示,hadoop中的guava与hive中的guava版本不一致,会产生冲突,需要把hive的guava更换为hadoop的guava高版本。

在虚拟机hadoop1执行如下命令解决guava冲突问题。
rm -f /export/servers/hive-3.1.3/lib/guava-19.0.jar
cp /export/servers/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar /export/servers/hive-3.1.3/lib

2.3.2 解决SLF4J冲突
在虚拟机hadoop1执行如下命令解决slf4j冲突问题。
rm -f /export/servers/hive-3.1.3/lib/log4j-slf4j-impl-2.17.1.jar

3. 配置Hive
3.1 配置Hive环境变量
在虚拟机hadoop1执行如下命令设置Hive环境变量,加载系统环境变量配置文件,并查看环境变量是否配置成功。
echo >> /etc/profile
echo 'export HIVE_HOME=/export/servers/hive-3.1.3' >> /etc/profile
echo 'export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile
source /etc/profile
echo $HIVE_HOME

3.2 修改 hive-site.xml 配置文件
在虚拟机hadoop1使用cat命令把配置内容重定向并写入到 /export/servers/hive-3.1.3/conf/hive-site.xml 文件。
cat >/export/servers/hive-3.1.3/conf/hive-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 配置JDO(Java Data Objects)选项,指定Hive元数据存储的数据库连接URL。这里使用的是MySQL数据库,并且如果数据库不存在则自动创建。 --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop1:3306/hive?createDatabaseIfNotExist=true</value></property><!-- 指定用于连接数据库的JDBC驱动类名 --><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><!-- 数据库连接用户名 --><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- 数据库连接密码 --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><!-- 指定Hive元数据仓库在HDFS上目录的位置 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive_local/warehouse</value></property>
</configuration>
EOF

3.3 配置MySQL驱动包
3.3.1 下在MySQL驱动包
点击下载MySQL驱动jar包:https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar
3.3.2 上传MySQL驱动包
通过拖移的方式将下载的MySQL驱动包上传至虚拟机hadoop1的/export/software目录。

3.3.3 配置MySQL驱动包
在虚拟机hadoop1执行如下命令复制MySQL驱动包到/export/servers/hive-3.1.3/lib目录下。
cp /export/software/mysql-connector-java-8.0.30.jar /export/servers/hive-3.1.3/lib/

4. 初始化MySQL上的存储hive元数据的数据库
在虚拟机hadoop1执行如下命令初始化MySQL上的存储hive元数据的数据库。
schematool -initSchema -dbType mysql

初始化完成如下图所示。

5. 进入Hive客户端
在访问Hive客户端之前,由于Hive完全依赖于Hadoop集群,因此需要先启动Hadoop集群。
start-all.sh
在虚拟机hadoop1执行如下命令在本地进入Hive客户端。
hive

退出Hive客户端。可以使用exit;命令或者按快捷键Ctrl+c退出。
exit;

6. 设置远程连接
Hive 提供了两种服务以支持用户的远程连接:
-
MetaStore 服务:MetaStore 服务负责管理 Hive 的元数据,并通过与关系型数据库的连接来存储和检索这些元数据。
-
HiveServer2 服务:HiveServer2 服务基于 Thrift 协议实现,提供了通过 JDBC 和 ODBC 连接到 Hive 的功能。它依赖于 MetaStore 服务来获取元数据信息。用户在通过 HiveServer2 服务远程连接到 Hive 之前,需要确保 MetaStore 服务已经启动并运行。
6.1 启动MetaStore服务
在虚拟机hadoop1执行如下命令后台启动MetaStore服务,并指定日志输出位置。
mkdir -p /export/servers/hive-3.1.3/logs
nohup hive --service metastore > /export/servers/hive-3.1.3/logs/metastore.log 2>&1 &

可以使用如下命令查看启动后的MetaStore服务进程,此时如果要停止MetaStore服务,需要使用kill命令杀死对应进程。
ps -ef | grep hive

6.2 启动HiveServer2服务
在虚拟机hadoop1执行如下命令后台启动HiveServer2服务,并指定日志输出位置。
nohup hive --service hiveserver2 > /export/servers/hive-3.1.3/logs/hiveserver2.log 2>&1 &

可以使用如下命令查看启动后的HiveServer2服务进程,此时如果要停止HiveServer2服务,需要使用kill命令杀死对应进程。
ps -ef | grep hive

6.3 进入Hive客户端
在虚拟机hadoop1执行如下命令远程进入Hive客户端。
beeline -u jdbc:hive2://hadoop1:10000 -n root
-
参数
-u:指定HiveServer2服务的JDBC URL。jdbc:hive2://hadoop3:10000中:hadoop3是运行HiveServer2服务的服务器主机名。10000是HiveServer2服务默认使用的端口号。
-
参数
-n:指定连接HiveServer2服务时使用的用户名。root是用户名,该用户必须具有操作HDFS的适当权限。

可以使用按快捷键Ctrl+c退出客户端。
二、Hive HA(高可用)实现
1. 在hadoop2部署hive
1.1 安装配置hive
在虚拟机hadoop1上执行以下命令,将配置好的 Hive 复制到虚拟机hadoop2。由于共享同一个元数据数据库和 HDFS 目录,因此在 hadoop2 上无需初始化 Hive,即可直接操作。
scp -r root@hadoop1:/export/servers/hive-3.1.3 root@hadoop2:/export/servers/

1.2 设置环境变量
在虚拟机hadoop2执行如下命令设置Hive环境变量,加载系统环境变量配置文件,并查看环境变量是否配置成功。
echo >> /etc/profile
echo 'export HIVE_HOME=/export/servers/hive-3.1.3' >> /etc/profile
echo 'export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile
source /etc/profile
echo $HIVE_HOME

1.3 设置远程连接
在虚拟机hadoop2执行如下命令后台启动MetaStore服务和HiveServer2服务,开启远程连接并指定日志输出位置。
mkdir -p /export/servers/hive-3.1.3/logs
nohup hive --service metastore > /export/servers/hive-3.1.3/logs/metastore.log 2>&1 &
nohup hive --service hiveserver2 > /export/servers/hive-3.1.3/logs/hiveserver2.log 2>&1 &

2. 在hadoop3部署hive
2.1 安装配置hive
在虚拟机hadoop1上执行以下命令,将配置好的 Hive 复制到虚拟机hadoop3。由于共享同一个元数据数据库和 HDFS 目录,因此在 hadoop3 上无需初始化 Hive,即可直接操作。
scp -r root@hadoop1:/export/servers/hive-3.1.3 root@hadoop3:/export/servers/

2.2 设置环境变量
在虚拟机hadoop3执行如下命令设置Hive环境变量,加载系统环境变量配置文件,并查看环境变量是否配置成功。
echo >> /etc/profile
echo 'export HIVE_HOME=/export/servers/hive-3.1.3' >> /etc/profile
echo 'export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile
source /etc/profile
echo $HIVE_HOME

2.3 设置远程连接
在虚拟机hadoop3执行如下命令后台启动MetaStore服务和HiveServer2服务,开启远程连接并指定日志输出位置。
mkdir -p /export/servers/hive-3.1.3/logs
nohup hive --service metastore > /export/servers/hive-3.1.3/logs/metastore.log 2>&1 &
nohup hive --service hiveserver2 > /export/servers/hive-3.1.3/logs/hiveserver2.log 2>&1 &

3. 测试远程连接
在虚拟机hadoop1执行如下命令远程进入hadoop2的Hive客户端。
beeline -u jdbc:hive2://hadoop2:10000 -n root

在虚拟机hadoop1执行如下命令远程进入hadoop3的Hive客户端。
beeline -u jdbc:hive2://hadoop3:10000 -n root

注意
在Hive HA安装并配置完成后,每当系统重启后,为了确保Hive能够正常工作,首先需要在虚拟机hadoop1执行如下命令启动Hadoop集群。
start-all.sh
如果还需要支持远程连接功能,则必须在虚拟机hadoop1、hadoop2和hadoop3执行如下命令启动Hive的MetaStore服务和HiveServer2服务。
mkdir -p /export/servers/hive-3.1.3/logs
nohup hive --service metastore > /export/servers/hive-3.1.3/logs/metastore.log 2>&1 &
nohup hive --service hiveserver2 > /export/servers/hive-3.1.3/logs/hiveserver2.log 2>&1 &
相关文章:
Hadoop生态圈框架部署(九-2)- Hive HA(高可用)部署
文章目录 前言一、Hive部署(手动部署)下载Hive1. 上传安装包2. 解压Hive安装包2.1 解压2.2 重命名2.3 解决冲突2.3.1 解决guava冲突2.3.2 解决SLF4J冲突 3. 配置Hive3.1 配置Hive环境变量3.2 修改 hive-site.xml 配置文件3.3 配置MySQL驱动包3.3.1 下在M…...

docker 相关操作
1. 以下是一些常见的 Docker 命令: docker --version显示安装的 Docker 版本。 docker pull <image_name>从 Docker Hub 或其他镜像仓库下载镜像。 docker build -t <image_name> <path>从指定路径的 Dockerfile 构建 Docker 镜像。 docker i…...

AI作图效率高,亲测ToDesk、顺网云、青椒云多款云电脑AIGC实践创作
一、引言 随着人工智能生成内容(AIGC)的兴起,越来越多的创作者开始探索高效的文字处理和AI绘图方式,而云电脑也正成为AIGC创作中的重要工具。相比于传统的本地硬件,云电脑在AIGC场景中展现出了显著的优势,…...
;53. 寻宝(kruskal算法))
【代码随想录day57】【C++复健】 53. 寻宝(prim算法);53. 寻宝(kruskal算法)
53. 寻宝(prim算法) 好像在研究生的算法课上学过prim算法和kruskal算法,不过当时只是了解了一下大致的概念和流程,并没有涉及到如何去写代码的部分,今天也算是学习了一下这两个算法的代码应该如何去实现,还…...

C++中多态
1) 什么是多态性?C中如何实现多态? 多态性是指通过基类指针或引用调用派生类的函数,实现不同的行为 多态性可以提高代码的灵活性和可扩展性,使程序能够根据不同的对象类型执行不同的操作。 2)C中如何实现多态&#…...
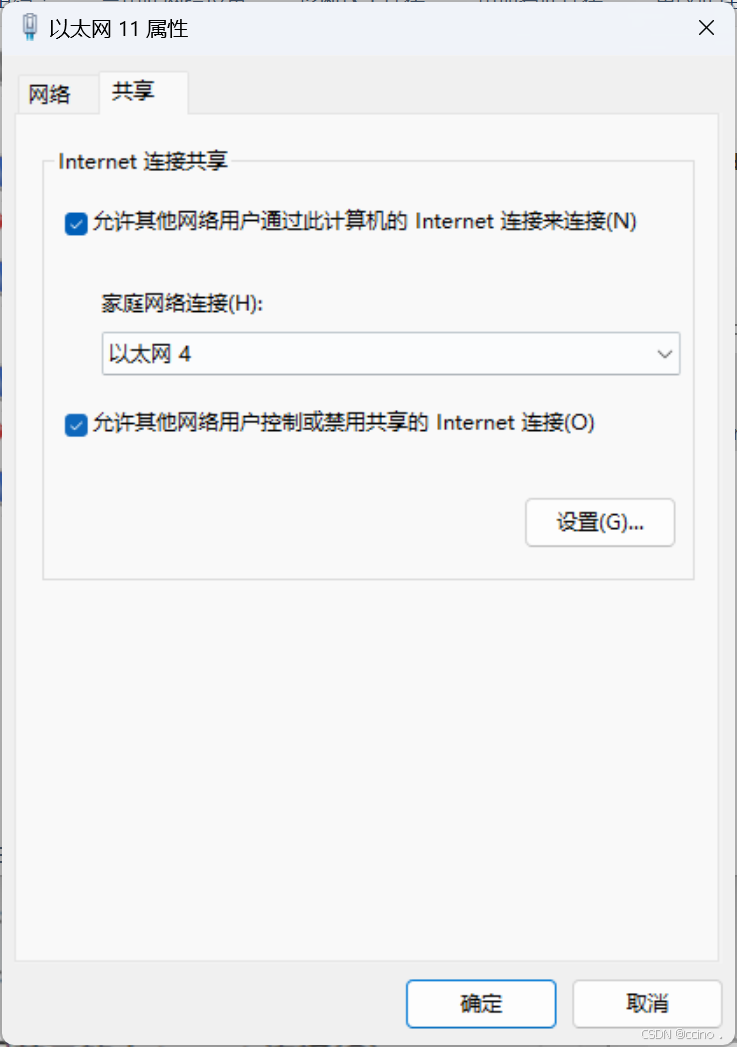
【实现多网卡电脑的网络连接共享】
电脑A配备有两张网卡,分别命名为eth0和eth1(对于拥有超过两张网卡的情况,解决方案相似)。其中,eth0网卡能够连接到Internet,而eth1网卡则通过网线直接与另一台电脑B相连(在实际应用中࿰…...

算力介绍与解析
算力(Computing Power)是指计算机系统在单位时间内处理数据和执行计算任务的能力。算力是衡量计算机性能的重要指标,直接影响计算任务的速度和效率。 算力的分类和单位 a. 基础算力:以CPU的计算能力为主。适用于各个领域的计算。…...
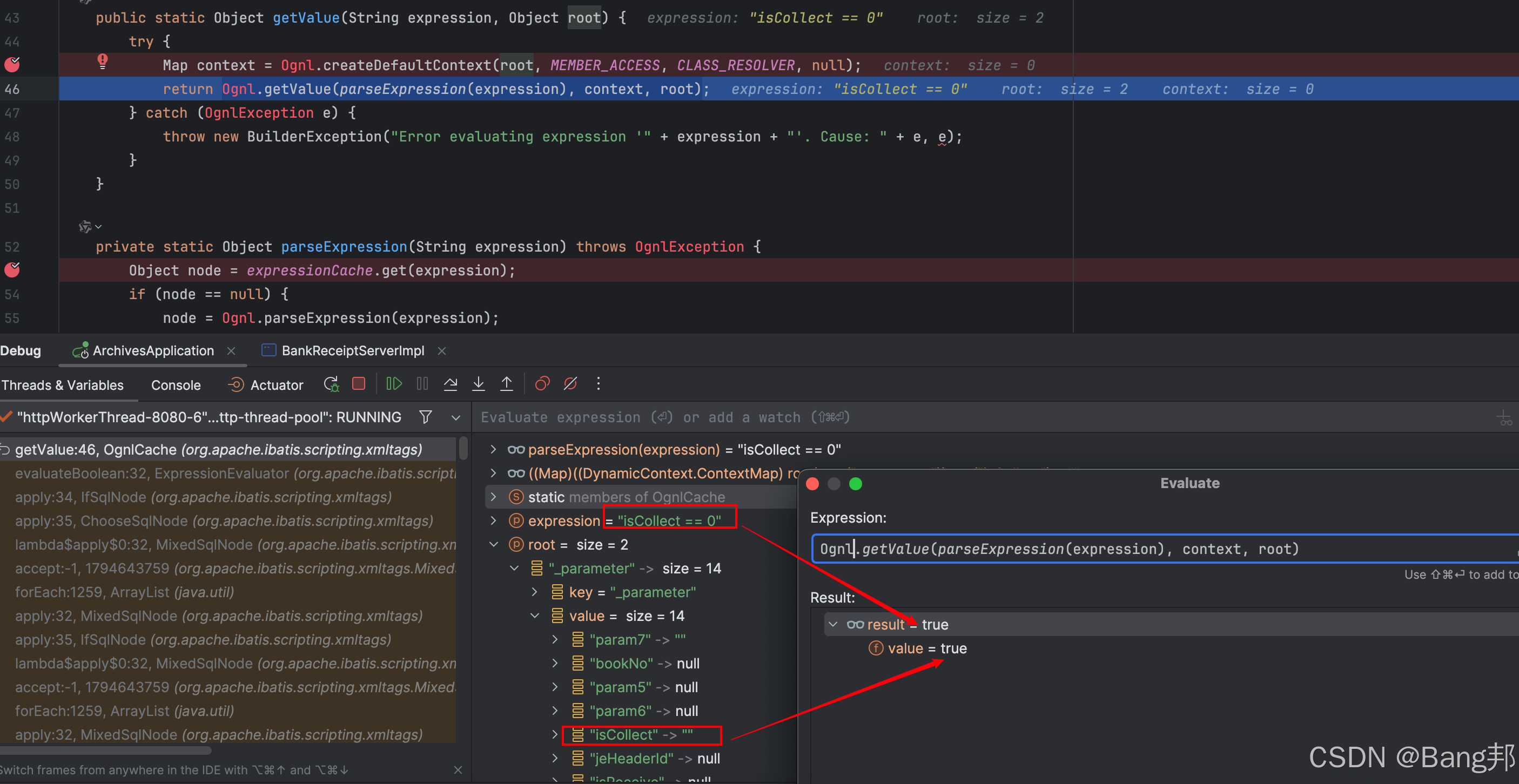
解决 MyBatis 中空字符串与数字比较引发的条件判断错误
问题复现 假设你在 MyBatis 的 XML 配置中使用了如下代码: <if test"isCollect ! null"><choose><when test"isCollect 1">AND exists(select 1 from file_table imgfile2 where task.IMAGE_SEQimgfile2.IMAGE_SEQ and im…...
 解释下)
python 词向量的代码解读 self.word_embeds = nn.Embedding(vocab_size, embedding_dim) 解释下
在PyTorch中,nn.Embedding 是一个用于将稀疏的离散数据表示为密集的嵌入向量的模块。这在自然语言处理(NLP)任务中非常常见,例如在处理单词或字符时,我们通常需要将这些离散的标识符转换为可以被神经网络处理的连续值向…...
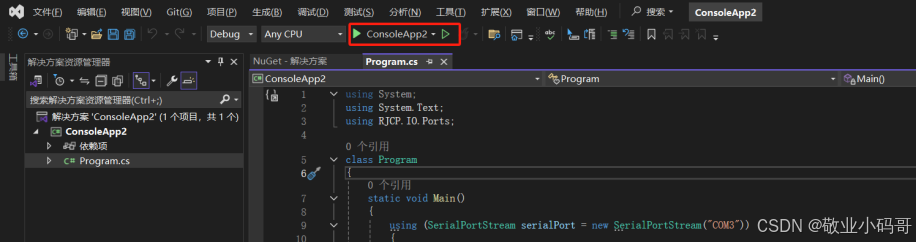
记一次:使用C#创建一个串口工具
前言:公司的上位机打不开串口,发送的时候设备总是关机,因为和这个同事关系比较好,编写这款软件是用C#编写的,于是乎帮着解决了一下(是真解决了),然后整理了一下自己的笔记 一、开发…...

Android Studio新版本的一个资源id无法找到的bug解决
Android Studio新版本的一个资源id无法找到的bug解决 文章目录 Android Studio新版本的一个资源id无法找到的bug解决一、前言二、Android Studio的无法获取到资源id的bug1、一段简单的Java代码1、错误现象2、错误解决方法 三、其他1、小结2、gradle.properties文件 其他相关属性…...
Datawhale AI冬令营(第一期)--零基础定制你的专属大模型
本文主要简述如何快速完成和一些小细节 第一步下载嬛嬛数据集 数据来源:self-llm/dataset/huanhuan.json at master datawhalechina/self-llm GitHub 注意:1.一定是数据集下载完成一定是.json结尾的 2.这个是github的网址,可能会遇到打不开的情况 …...
LLMs之APE:基于Claude的Prompt Improver的简介、使用方法、案例应用之详细攻略
LLMs之APE:基于Claude的Prompt Improver的简介、使用方法、案例应用之详细攻略 目录 Prompt Improver的简介 0、背景痛点 1、优势 2、实现思路 Prompt优化 示例管理 提示词评估 Prompt Improver的使用方法 1、使用方法 Prompt Improver的案例应用 1、Kap…...

【Unity人形布娃娃插件】Ragdoll Animator
Ragdoll Animator 是一款为 Unity 引擎开发的插件,专注于让角色在运行时动态地切换到布娃娃物理系统(Ragdoll Physics)。该插件帮助开发者轻松创建逼真的角色动画过渡效果,尤其适用于需要角色碰撞、摔倒、受击或其他物理反应的场景…...

跨团队协作中目标一致性至关重要
在团队协作的复杂拼图里,目标一致性是那根贯穿始终的主线,缺之则拼图难成,团队亦难达预期之效。 且看这样一个实例:部门承接了业务方一项紧急的数据处理需求,此任务犹如一座亟待攀登的险峰,落在了 A 团队…...

Excel的文件导入遇到大文件时
Excel的文件导入向导如何把已导入数据排除 入起始行,选择从哪一行开始导入。 比如,前两行已经导入了,第二次导入的时候排除前两行,从第三行开始,就将导入起始行设置为3即可,且不勾选含标题行。 但遇到大文…...

使用字典进行动态编程
在你的程序中,你想要执行各种计算,例如计算卫星的总数。 此外,当你进行更高级的编程时,你可能会发现你需要从文件或数据库中加载此类信息,而不是直接编码到 Python 中。 为了帮助支持这些场景,Python 使你…...

机器学习02-发展历史补充
机器学习02-发展历史补充 文章目录 机器学习02-发展历史补充1-机器学习个人理解1-初始阶段:统计学习和模式识别(20世纪50年代至80年代)2-第二阶段【集成时代】【核方法】(20世纪90年代至2000年代初期)3-第三阶段【特征…...

全国青少年信息学奥林匹克竞赛(信奥赛)备考实战之计数器与累加器(一)
学习背景: 在现实生活中一些需要计数的场景下我们会用到计数器,如空姐手里记录乘客的计数器,跳绳手柄上的计数器等。累加器是累加器求和,以得到最后的结果。计数器和累加器它们虽然是基础知识,但是应用广泛࿰…...

Android的SurfaceView和TextureView介绍
文章目录 前言一、什么是SurfaceView ?1.1 SurfaceView 使用示例1.2 SurfaceView 源码概述1.3 SurfaceView 的构造与初始化1.4 SurfaceHolder.Callback 回调接口1.5 SurfaceView 渲染机制 二、什么是TextureView?2.1 TextureView 使用示例2.2 TextureVie…...
的互转)
从电话语音到网络传输:手把手教你用C语言实现PCM与G.711(a-law/u-law)的互转
从电话语音到网络传输:手把手教你用C语言实现PCM与G.711(a-law/u-law)的互转 在嵌入式音视频开发中,音频编解码技术是构建高效通信系统的核心。当我们需要在资源受限的硬件平台上实现语音通话、对讲机或安防监控设备时࿰…...

【Linux】权限相关指令
1.将命令翻译后交给核心执行2.将核心执行的结果翻译并返回给我们形象理解shell:假如小y过年回家打算相亲了,打算小y并不擅长与异性交流,这时候就拜托了媒人王姨作为中间人,帮忙小y和异性之前传话。这时候王姨就是“外壳程序”shel…...

《如果你还愿意等》的搜索理由:等待场景怎样被记住
从内容传播角度看,《如果你还愿意等》的优势在于语气。它不是命令,也不是苦情控诉,而是把等待放成一个“如果”:有余地,也有边界。这个标题能自然带出使用场景:未读消息、夜车灯光、异地关系、还没完全离开…...

AI智能体技能管理:MCP服务器安装配置与实战指南
1. 项目概述:一个为AI智能体管理“技能”的MCP服务器 最近在折腾AI智能体(Agent)开发的朋友,应该都遇到过同一个痛点:想让你的Claude、GPT或者Gemini去执行一些特定的、复杂的任务,比如调用某个API、处理特…...

MCP TypeScript SDK 服务说明文档
1. 服务概述 一句话简介:完整的MCP规范TypeScript实现,轻松构建MCP客户端和服务器,为LLM应用提供标准化的上下文管理能力。 服务名称:MCP TypeScript SDK版本号:Latest开发者/提供方:federated-alpha协议…...

第十一节:私有知识大脑——为本地 Agent 构建企业级 RAG 检索增强链路
引言 承接上一章我们对 embedding 和向量检索的实战部署,本章将聚焦打造私有知识大脑,通过构建完整的 RAG(Retrieval-Augmented Generation)检索增强链路,极大拓展本地 Agent 在企业场景的应用边界。 核心理论 RAG 是实现大模型实时访问和利用外部知识的关键技术,其数…...
)
大模型监控告警失效的9大隐形陷阱(SITS技术委员会2024压力测试实录)
更多请点击: https://intelliparadigm.com 第一章:大模型监控告警失效的9大隐形陷阱(SITS技术委员会2024压力测试实录) 在2024年SITS技术委员会开展的跨平台大模型服务压力测试中,超63%的生产级LLM推理集群遭遇了“告…...

纯电商用车再生制动能量回收模糊控制策略【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于自适应扩展卡尔曼滤波的SOC精确估计与能量管理…...

Ruby 变量
Ruby 变量 引言 在编程语言中,变量是存储数据的基本单元。Ruby 作为一种动态、面向对象的语言,同样依赖变量来存储和处理数据。本文将详细介绍 Ruby 中的变量类型、作用域、生命周期以及相关操作,帮助读者全面了解 Ruby 变量的使用。 变量类型 Ruby 中的变量类型主要分为…...

安全扫描自动化:构建持续安全检测体系
安全扫描自动化:构建持续安全检测体系 一、安全扫描自动化概述 1.1 安全扫描自动化的定义 安全扫描自动化是指通过工具和脚本自动执行安全检测任务,包括漏洞扫描、代码安全检测、配置安全检查等。它是DevSecOps实践的重要组成部分。 1.2 安全扫描自动化的…...