数据可视化的Python实现
一、GDELT介绍
GDELT ( www.gdeltproject.org ) 每时每刻监控着每个国家的几乎每个角落的 100 多种语言的新闻媒体 -- 印刷的、广播的和web 形式的,识别人员、位置、组织、数量、主题、数据源、情绪、报价、图片和每秒都在推动全球社会的事件,GDELT 为全球提供了一个自由开放的计算平台。
GDELT 主要包含两大数据集: Event Database (事件数据库) 、 Global Knowledge Graph (GKG, 全球知识图谱),记录了从1969 年至今的新闻,并于每十五分钟更新一次数据。
二、研究内容
本次研究数据来自 gdelt 数据库,爬取 2022.01.01-2022.07.20 所有 export 和 mentions 表,从中提取俄乌 冲突相关数据,由此进行分析。主要分析内容如下:
- 基于BERT实现GDELT新闻事件数据中事件正文文本的情感分析
- 基于MySQL的本地数据库导入、查询和存储
- 基于JavaScript和echarts的数据可视化图表库对新闻事件数据进行多方面可视化
- 将可视化界面部署到服务器上以供其他用户通过网址查看
- 其他算法进行情感分析
三、项目实施方法设计
1、使用语言
前段静态页面: html 、 css 、 JavaScript 、 echarts
连接数据库页面:增加 php 连接 MySQL
数据处理: Pycharm+Python , Jupyter+Python
2、项目流程

四、具体实现与测试
1、数据集下载
def get_data(url):# 获取urlfile_name = url.split("gdeltv2/")[1].split(".zip")[0]r = requests.get(url)temp_file=open("./temp.zip", "wb")temp_file.write(r.content)temp_file.close()try:my_zip=zipfile.ZipFile('./temp.zip','r')my_zip.extract(file_name,path="./data")my_zip.close()except Exception:print("%s not exist" % file_name)return None
def get_data_df(): #日期读取f=open("date.txt")date=[]time=[]for i in f.readlines():date.append(i.strip("\n"))f.close()f=open("time.txt")for i in f.readlines():time.append(i.strip("\n"))f.close()#地址整合url1 = "http://data.gdeltproject.org/gdeltv2/%s.export.CSV.zip"url2 = "http://data.gdeltproject.org/gdeltv2/%s.mentions.CSV.zip"for i in date:for j in time:str_real_time=i+jget_data(url1%str_real_time)get_data(url2%str_real_time)print("%s-complete"%i)下载 2022.01.01-2022.07.20 的数据, 数据量大约 20GB ,下载完成后, export 表和 mentions 表混合放置,因此需要将表按月分类放置,代码如下:
import os
import shutil
for i in range(1,8):src_folder="./totaldata/20220"+str(i)tar_folder="./totaldata/20220"+str(i)files=os.listdir(src_folder)for file in files:src_path=src_folder+'/'+filefor file in files:# 将每个文件的完整路径拼接出来src_path = src_folder + '/' + fileif os.path.isfile(src_path):tar_path = tar_folder + '/' + file.split('.')[-2]print(tar_path)# 如果文件夹不存在则创建if not os.path.exists(tar_path):os.mkdir(tar_path)# 移动文件shutil.move(src_path, tar_path)为了更方便处理,我们将 export 表的数据合并, mentions 表的数据合并,代码如下:
os.chdir(Folder_Path)
file_list=os.listdir()
for i in range(1,len(file_list)):df=pd.read_csv(file_list[i],sep='\t')df.to_csv(SaveFile_Path+"/"+SaveFile_Name,encoding="utf_8_sig",index=False,header=None,mode='a+')sys.stdout.write("\r已合并:%.2f%%"%float((i/len(file_list))*100))sys.stdout.flush()2、数据集处理
(1)查看空字段数量并排序
is_null=df_01.isnull().sum().sort_values(ascending=False)
is_null[is_null>row*0.85]#筛选出空值数量大于85%的数据(2)删除缺失率大于85%字段
drop_columns=['Actor2Type3Code','Actor1Type3Code','Actor2Religion2Code',
'Actor1Religion2Code','Actor2EthnicCode','Actor1EthnicCode',
'Actor2Religion1Code','Actor2KnownGroupCode','Actor1Religion1Code',
'Actor1KnownGroupCode','Actor2Type2Code','Actor1Type2Code']
df_01.drop(drop_columns,axis=1,inplace=True)得到结果如下:

3、数据导入MySQL与分析
(1)创建数据库
这里值得注意的是,很多字段在后续分析中没有用到,但还是导入进去了,为了和元数据保持一致性。
CREATE TABLE `export` (
`GLOBALEVENTID` int NOT NULL,
`SQLDATE` bigint,
`MonthYear` bigint,
`Year` bigint,
`FractionDate` bigint,
`Actor1Code` varchar(255),
`Actor1Name` varchar(255),
`Actor1CountryCode` varchar(255),
`Actor1Type1Code` varchar(255),
`Actor2Code` varchar(255),
`Actor2Name` varchar(255),
`Actor2CountryCode` varchar(255),
`Actor2Type1Code` varchar(255),
`IsRootEvent` varchar(255),
`EventCode` varchar(255),
`EventBaseCode` varchar(255),
`EventRootCode` varchar(255),
`QuadClass` int,
`GoldsteinScale` double,
`NumMentions` int,
`NumSources` int,
`NumArticles` int,
`AvgTone` double,
`Actor1Geo_Type` varchar(255),
`Actor1Geo_FullName` varchar(255),
`Actor1Geo_CountryCode` varchar(255),
`Actor1Geo_ADM1Code` varchar(255),
`Actor1Geo_ADM2Code` varchar(255),
`Actor1Geo_Lat` double,
`Actor1Geo_Long` double,
`Actor1Geo_FeatureID` varchar(255),
`Actor2Geo_Type` varchar(255),
`Actor2Geo_FullName` varchar(255),
`Actor2Geo_CountryCode` varchar(255),
`Actor2Geo_ADM1Code` varchar(255),
`Actor2Geo_ADM2Code` varchar(255),
`Actor2Geo_Lat` double,
`Actor2Geo_Long` double,
`Actor2Geo_FeatureID` varchar(255),
`ActionGeo_Type` varchar(255),
`ActionGeo_FullName` varchar(255),
`ActionGeo_CountryCode` varchar(255),
`ActionGeo_ADM1Code` varchar(255),
`ActionGeo_ADM2Code` varchar(255),
`ActionGeo_Lat` double,
`ActionGeo_Long` double,
`ActionGeo_FeatureID` varchar(255),
`DATEADDED` bigint,
`SOURCEURL` text,
PRIMARY KEY (`GLOBALEVENTID`)
);(2)导入数据
LOAD DATA INFILE 'E:/term/code/mergedata/export/export_202201.csv' INTO TABLE
`export`
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\r\n'
IGNORE 1 ROWS;(3)年份处理和简单查询
DELETE
FROM rus_and_ukr
WHERE `MonthYear`<202201
SELECT COUNT(GLOBALEVENTID) FROM export -- 21504131相关文章:
数据可视化的Python实现
一、GDELT介绍 GDELT ( www.gdeltproject.org ) 每时每刻监控着每个国家的几乎每个角落的 100 多种语言的新闻媒体 -- 印刷的、广播的和web 形式的,识别人员、位置、组织、数量、主题、数据源、情绪、报价、图片和每秒都在推动全球社会的事件,GDELT 为全…...

【Linux系列】Linux 系统配置文件详解:`/etc/profile`、`~/.bashrc` 和 `~/.bash_profile`
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

uni-app实现小程序、H5图片轮播预览、双指缩放、双击放大、单击还原、滑动切换功能
前言 这次的标题有点长,主要是想要表述的功能点有点多; 简单做一下需求描述 产品要求在商品详情页的头部轮播图部分,可以单击预览大图,同时在预览界面可以双指放大缩小图片并且可以移动查看图片,双击放大࿰…...

游戏引擎学习第45天
仓库: https://gitee.com/mrxiao_com/2d_game 回顾 我们刚刚开始研究运动方程,展示了如何处理当人物遇到障碍物时的情况。有一种版本是角色会从障碍物上反弹,而另一版本是角色会完全停下来。这种方式感觉不太自然,因为在游戏中,…...

electron常用方法
一,,electron设置去除顶部导航栏和menu 1,electron项目 在创建BrowserWindow实例的main.js页面添加frame:false属性 2,electron-vue项目 在src/main/index.js文件下找到创建窗口的方法(createWindow)&…...

【Spark】Spark Join类型及Join实现方式
如果觉得这篇文章对您有帮助,别忘了点赞、分享或关注哦!您的一点小小支持,不仅能帮助更多人找到有价值的内容,还能鼓励我持续分享更多精彩的技术文章。感谢您的支持,让我们一起在技术的世界中不断进步! Sp…...

meta llama 大模型一个基础语言模型的集合
LLaMA 是一个基础语言模型的集合,参数范围从 7B 到 65B。我们在数万亿个 Token 上训练我们的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而无需诉诸专有的和无法访问的数据集。特别是,LLaMA-13B 在大多数基准测试…...

JAVA爬虫获取1688关键词接口
以下是使用Java爬虫获取1688关键词接口的详细步骤和示例代码: 一、获取API接口访问权限 要使用1688关键词接口,首先需要获取API的使用权限,并了解接口规范。以下是获取API接口的详细步骤: 注册账号:在1688平台注册一…...

操作系统——内存管理
1、什么是虚拟内存?它是如何实现的?虚拟内存与物理内存之间有什么关系? 虚拟内存是操作系统提供的一种内存管理机制,它使程序认为自己拥有连续的内存空间,但实际上内存可能被分散存储在物理内存和磁盘交换空间中。 虚…...

android studio 模拟器不能联网?
模拟器路径: C:\Users\Administrator\AppData\Local\Android\Sdk\emulator\emulator.exe.关闭所有AVD设备实例 导航至: C:\Users\userName\AppData\Local\Android\Sdk\emulator查看模拟器名称 AdministratorDESKTOP-6JB1OGC MINGW64 ~/AppData/Local/…...

CTF-WEB: 目录穿越与模板注入 [第一届国城杯 Ez_Gallery ] 赛后学习笔记
step1 验证码处存在逻辑漏洞,只要不申请刷新验证码就一直有效 字典爆破得到 admin:123456 step2 /info?file../../../proc/self/cmdline获得 python/app/app.py经尝试,读取存在的目录时会返回 A server error occurred. Please contact the administrator./info?file.…...

数据结构6.4——归并排序
基本思想: 归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个…...

【html 常用MIME类型列表】
本表仅列出了常用的MIME类型,完整列表参考文档。 浏览器通常使用 MIME 类型(而不是文件扩展名)来确定如何处理 URL,因此 Web 服务器在响应头中添加正确的 MIME 类型非常重要。 如果配置不正确,浏览器可能会曲解文件内容…...
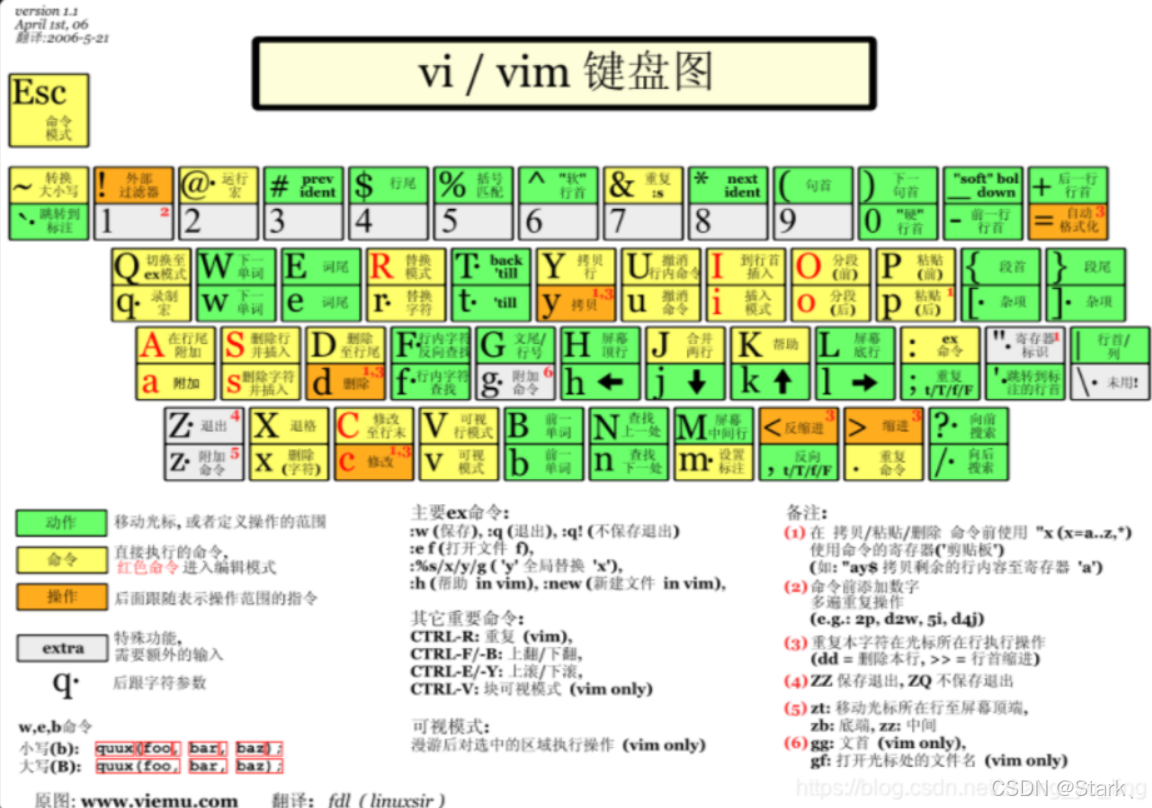
Linux之vim编辑器
vi编辑器是所有Unix及linux系统下标准的编辑器,类似于Windows系统下的记事本。很多软件默认使用vi作为他们编辑的接口。vim是进阶版的vi,vim可以视为一种程序编辑器。 前言: 1.文件准备 复制 /etc/passwd文件到自己的目录下(不…...

【工具介绍】可以批量查看LableMe标注的图像文件信息~
在图像处理和计算机视觉领域,LabelMe是一个广泛使用的图像标注工具,它帮助我们对图像中的物体进行精确的标注。但是,当标注完成后,我们常常需要一个工具来批量查看这些标注信息。 今天,我要介绍的这款exe程序…...
“信息安全管理与评估”赛项规程)
2024年山西省第十八届职业院校技能大赛 (高职组)“信息安全管理与评估”赛项规程
2024年山西省第十八届职业院校技能大赛 (高职组)“信息安全管理与评估”赛项规程 一、赛项名称 赛项名称:信息安全管理与评估 英文名称:Information Security Management and Evaluation 赛项组别:高职教师组 赛项归属…...

STM32完全学习——STemWin的移植小插曲
一、移植编译的一些问题 新版的STemWin的库没有区别编译器,只有一些这样的文件,默认你将这些文件导入到KEIL中,然后编译就会有下面的错误。 ..\MEWIN\STemWin\Lib\STemWin_CM4_wc16.a(1): error: A1167E: Invalid line start ..\MEWIN\STe…...

Java——IO流(下)
一 (字符流扩展) 1 字符输出流 (更方便的输出字符——>取代了缓冲字符输出流——>因为他自己的节点流) (PrintWriter——>节点流——>具有自动行刷新缓冲字符输出流——>可以按行写出字符串,并且可通过println();方法实现自动换行) 在Java的IO流中…...

avue-crud 同时使用 column 与 group 的问题
场景一:在使用option 中的column 和 group 进行表单数据新增操作时,进行里面的控件操作时,点击后卡死问题,文本没问题 其它比如下拉,单选框操作,当删除 column 中的字段后, group 中的可以操作 …...

深入解析 Pytest 中的 conftest.py:测试配置与复用的利器
在 Pytest 测试框架中,conftest.py 是一个特殊的文件,用于定义测试会话的共享配置和通用功能。它是 Pytest 的核心功能之一,可以用于以下目的: 【主要功能】 1、定义共享的 Fixture (1)conftest.py 文件可…...

2026届学术党必备的十大降重复率神器推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 已正式被推出名为AIGC检测服务系统的是中国知网,其目的在于识别学术文献里由人工…...

如何永久保存微信聊天记录:5分钟掌握完整数据备份方案
如何永久保存微信聊天记录:5分钟掌握完整数据备份方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

构建一体化自动化媒体中心:从Docker容器化部署到全流程整合实践
1. 项目概述与核心价值最近在整理一些个人数据归档和媒体资源管理的工作时,我重新审视了“Leech-AIO-APP-EX”这个项目。这个名字听起来可能有点技术化,但它的核心目标非常明确:构建一个高度集成、自动化且易于管理的“一站式”数据抓取与媒体…...

基于明朝内阁制的AI多智能体协作系统:从原理到部署实战
1. 项目概述:当皇上,一个基于明朝内阁制的AI多智能体协作系统 如果你曾经幻想过像皇帝一样,只需动动嘴皮子,就有一群“大臣”为你分忧解难,处理从写代码到查账单的各种琐事,那么“当皇上”这个项目&#x…...

Hide Mock Location:三步解决Android模拟位置检测问题
Hide Mock Location:三步解决Android模拟位置检测问题 【免费下载链接】HideMockLocation Xposed module to hide the mock location setting. 项目地址: https://gitcode.com/gh_mirrors/hi/HideMockLocation Hide Mock Location是一款专为Android设备设计的…...

LLM提示词工程实战:开源模板库与浏览器扩展提升AI对话效率
1. 项目概述:一个为大型语言模型准备的“提示词武器库”如果你和我一样,日常工作中需要频繁地与ChatGPT、Claude、文心一言这类大型语言模型打交道,那你一定有过这样的体验:同一个问题,换种问法,得到的答案…...

构建防误删体系:从 rm -rf 灾难到生产环境数据安全实践
1. 项目概述:一个关于“删除生产环境”的警示性开源项目在软件开发和运维的圈子里,流传着一些“都市传说”级别的灾难性命令,而rm -rf /无疑是其中最令人闻风丧胆的一个。这个命令一旦在错误的路径下执行,意味着对根目录进行递归强…...

ChatGPT情感分析能力评测:零样本表现、小样本学习与实战应用
1. 项目概述:ChatGPT作为情感分析器的能力边界探索最近,但凡关注自然语言处理(NLP)领域的朋友,恐怕都绕不开ChatGPT这个名字。它展现出的通用对话和任务解决能力让人惊叹,但作为一个在一线搞了多年情感分析…...

保时捷裁撤重整数字化研发资源;特斯拉电动重卡的电池参数曝光;小米汽车调整人事筹备海外业务
保时捷裁撤Car-IT部门整合数字化研发资源牛喀网获悉,保时捷正式裁撤了三年前成立的Car-IT专属部门,将其负责的车联网、车机系统等数字化业务,重新整合回集团的核心研发部门,该部门的负责人SajjadKhan也将退出董事会。技术层面&…...

AI 术语通俗词典:学习率
学习率是机器学习、深度学习、神经网络和人工智能中非常常见的一个术语。它用来描述:模型每次根据梯度更新参数时,步子迈得有多大。 换句话说,学习率是在回答:模型知道应该往哪个方向改参数之后,到底一次应该改多少。如…...