《机器学习》3.7-4.3end if 启发式 uci数据集klda方法——非线性可分的分类器
目录
uci数据集
klda方法——非线性可分的分类器
计算
步骤 1: 选择核函数
步骤 2: 计算核矩阵
步骤 4: 解广义特征值问题
と支持向量机(svm)
目标:
方法:
核技巧的应用:
区别:
使用 OvR MvM 将多分类任务分解为二分类任务求解时,试述为何 无需专门针对类别不平衡性进行处理
end if
启发式
uci数据集
UCI数据集是指加州大学欧文分校(University of California, Irvine)提供的一系列用于机器学习和数据挖掘研究的数据集。这些数据集由UCI机器学习库(UCI Machine Learning Repository)维护,是研究人员和学者在开发和测试机器学习算法时广泛使用的一个资源。
以下是UCI数据集的一些特点:
-
多样性:UCI数据集涵盖了各种领域,包括医学、生物学、社会科学、工程学、物理学等,提供了多种类型的数据,如分类、回归、时间序列等。
-
广泛性:数据集的大小从几个实例到数百万实例不等,适用于不同的学习和研究需求。
-
标准化:UCI数据集通常以标准化的格式提供,便于研究人员使用。
-
免费可用:这些数据集通常可以免费下载和使用,为学术界和工业界的研究人员提供了便利。
-
引用:使用UCI数据集的研究人员在发表成果时通常会引用相应的数据集,这有助于追踪数据集的使用和影响。
一些著名的UCI数据集包括:
- Iris数据集:这是一个经典的分类问题数据集,包含了三种鸢尾花的萼片和花瓣的长度和宽度。
- Wine数据集:用于分类问题,包含了葡萄酒的化学成分数据,用于区分不同种类的葡萄酒。
- Adult数据集:这是一个用于收入预测的回归问题数据集,包含了人口普查数据。
- Pima Indians Diabetes数据集:用于预测糖尿病,包含了患者的医疗记录数据。
UCI机器学习库是一个宝贵的资源,对于机器学习领域的初学者和专家来说都是一个重要的工具。然而,随着在线数据集平台的增多,如Kaggle和OpenML,UCI数据集的使用可能会有所减少,但它仍然是一个重要的历史资源。
klda方法——非线性可分的分类器
k-LDA(kernel Linear Discriminant Analysis)是一种机器学习方法,它是传统的线性判别分析(LDA)的扩展,通过引入核技巧(kernel trick)来处理非线性可分的数据。LDA是一种监督降维技术,主要用于分类问题,它试图找到一个最佳的投影方向,使得不同类别的数据在该方向上投影后能够最大化类间差异,同时最小化类内差异。
以下是k-LDA方法的基本原理:
-
线性判别分析(LDA):
- LDA寻找一个线性变换,将高维数据投影到低维空间,使得同类别的数据点尽可能接近,不同类别的数据点尽可能远离。
- LDA假设数据在每个类别内部是高斯分布的,并且不同类别的协方差矩阵是相同的。
-
核技巧(Kernel Trick):
- 核技巧是一种数学方法,可以将数据隐式地映射到高维特征空间,在这个空间中数据可能是线性可分的。
- 常用的核函数包括线性核、多项式核、径向基函数(RBF)核和sigmoid核等。
-
k-LDA:
- k-LDA结合了LDA和核技巧,允许在原始特征空间中非线性可分的数据在高维特征空间中进行线性判别分析。
- 通过使用核函数,k-LDA不需要显式地计算数据在高维特征空间中的坐标,而是直接在原始空间中计算核矩阵,然后在该矩阵上进行LDA。
k-LDA的步骤通常包括:
- 选择一个合适的核函数来计算训练数据的核矩阵。
- 使用核矩阵来计算类内散布矩阵和类间散布矩阵。
- 解广义特征值问题来找到最佳的投影方向。
- 将数据投影到由这些方向定义的子空间中。
k-LDA方法的优势在于它能够处理非线性分类问题,而无需显式地定义映射函数到高维空间,这在很多实际应用中是非常有用的。然而,k-LDA也存在一些局限性,比如核函数的选择对结果有很大影响,而且计算复杂度通常比线性LDA要高。
k-LDA(kernel Linear Discriminant Analysis)是一种机器学习方法,它是传统的线性判别分析(LDA)的扩展,通过引入核技巧(kernel trick)来处理非线性可分的数据。LDA是一种监督降维技术,主要用于分类问题,它试图找到一个最佳的投影方向,使得不同类别的数据在该方向上投影后能够最大化类间差异,同时最小化类内差异。
以下是k-LDA方法的基本原理:
-
线性判别分析(LDA):
- LDA寻找一个线性变换,将高维数据投影到低维空间,使得同类别的数据点尽可能接近,不同类别的数据点尽可能远离。
- LDA假设数据在每个类别内部是高斯分布的,并且不同类别的协方差矩阵是相同的。
-
核技巧(Kernel Trick):
- 核技巧是一种数学方法,可以将数据隐式地映射到高维特征空间,在这个空间中数据可能是线性可分的。
- 常用的核函数包括线性核、多项式核、径向基函数(RBF)核和sigmoid核等。
-
k-LDA:
- k-LDA结合了LDA和核技巧,允许在原始特征空间中非线性可分的数据在高维特征空间中进行线性判别分析。
- 通过使用核函数,k-LDA不需要显式地计算数据在高维特征空间中的坐标,而是直接在原始空间中计算核矩阵,然后在该矩阵上进行LDA。
k-LDA的步骤通常包括:
- 选择一个合适的核函数来计算训练数据的核矩阵。
- 使用核矩阵来计算类内散布矩阵和类间散布矩阵。
- 解广义特征值问题来找到最佳的投影方向。
- 将数据投影到由这些方向定义的子空间中。
k-LDA方法的优势在于它能够处理非线性分类问题,而无需显式地定义映射函数到高维空间,这在很多实际应用中是非常有用的。然而,k-LDA也存在一些局限性,比如核函数的选择对结果有很大影响,而且计算复杂度通常比线性LDA要高。
计算
让我们通过一个简单的例子来展示如何计算k-LDA。假设我们有一组二维数据,这些数据在原始空间中不是线性可分的,但我们可以假设它们在某个高维特征空间中是线性可分的。我们将使用RBF核来计算k-LDA。
首先,我们需要以下步骤:
- 选择核函数(在这个例子中,我们使用RBF核)。
- 计算核矩阵。
- 计算类内散布矩阵和类间散布矩阵。
- 解广义特征值问题。
以下是具体的计算步骤:
步骤 1: 选择核函数
步骤 2: 计算核矩阵



步骤 4: 解广义特征值问题
解下面的广义特征值问题来找到最佳的投影方向 α:![]()
这个问题的解将给出特征值和对应的特征向量,这些特征向量定义了最佳投影方向。
由于这个计算过程涉及到矩阵运算和特征值分解,通常需要使用数值计算软件(如MATLAB、NumPy等)来执行。
请注意,这个例子非常简化,实际应用中的数据集会更大,计算过程会更复杂。此外,核函数的选择和参数调整对结果有重要影响,通常需要通过交叉验证等方法来确定。
と支持向量机(svm)
k-LDA(核线性判别分析)和SVM(支持向量机)都是机器学习中的分类算法,它们在处理非线性问题时都使用了核技巧,但它们在目标、方法和应用上存在一些差异。
目标:
- k-LDA:目标是找到一个最佳的投影方向(特征空间中的一组基向量),使得不同类别的数据在该方向上的投影尽可能分开,同时同类别的数据在该方向上的投影尽可能紧凑。它是一种监督降维技术,主要用于分类。
- SVM:目标是找到一个最优的超平面,将不同类别的数据点分开,并且使 margin(边界)尽可能大。SVM 不仅仅用于分类,还可以用于回归(称为支持向量回归,SVR)。
方法:
-
k-LDA:
- 使用类内散布矩阵和类间散布矩阵来寻找最佳投影方向。
- 通过解广义特征值问题来找到这些方向。
- 可以使用核技巧来处理非线性问题,将数据隐式映射到高维空间,然后在该空间中进行线性判别分析。
-
SVM:
- 通过最大化 margin 来找到最优超平面。
- 使用拉格朗日乘子法和核技巧来解决非线性问题。
- 对于分类问题,SVM 寻找的是那些最接近决策边界的数据点(支持向量),这些点对构建超平面至关重要。
核技巧的应用:
- k-LDA:使用核技巧来计算在高维特征空间中的类内和类间散布矩阵。
- SVM:使用核技巧来计算支持向量之间的内积,从而在高维空间中构建最优超平面。
区别:
- 优化目标:k-LDA 优化的是类内紧致性和类间可分性,而 SVM 优化的是 margin 的最大化和分类错误的最小化。
- 模型复杂度:SVM 通常被认为在处理高维数据和不同类型的核函数时更为灵活和强大。
- 泛化能力:SVM 通常具有较好的泛化能力,特别是在处理小样本问题时。
- 计算效率:SVM 在处理大规模数据集时可能更高效,因为它只关注支持向量,而 k-LDA 需要处理整个数据集。
- 多分类问题:SVM 原本是设计用于二分类问题,但可以通过一对多(one-vs-rest)或一对一(one-vs-one)等方法扩展到多分类问题。k-LDA 直接支持多分类问题。
总的来说,虽然 k-LDA 和 SVM 都可以使用核技巧来处理非线性问题,但它们在算法设计、优化目标和应用场景上有所不同。选择哪种算法取决于具体问题的需求、数据的特点以及预期的性能。
使用 OvR MvM 将多分类任务分解为二分类任务求解时,试述为何 无需专门针对类别不平衡性进行处理
在使用一对所有(OvR,One-vs-Rest)或者多对多(MvM,Many-vs-Many)策略将多分类任务分解为二分类任务时,通常不需要专门针对类别不平衡性进行处理的原因有以下几点:
-
分类器的目标:在OvR和MvM策略中,每个二分类任务的目标是区分一个类别与其他所有类别。因此,即使某些类别在整体数据集中样本数量较少,但在每个特定的二分类任务中,它们仍然与其他所有非目标类别的样本数量相当。这意味着每个分类器都是在平衡的数据集上训练的。
-
决策函数的性质:在OvR策略中,每个分类器都会为每个样本输出一个属于该类别的概率或决策得分。在预测阶段,会选择得分最高的类别作为最终预测。即使某些类别的样本数量较少,只要分类器能够正确地识别出这些样本,它们仍然可以被正确分类。
-
概率归一化:在使用OvR进行预测时,通常会通过softmax函数或其他归一化方法将所有二分类器的输出转换为概率分布,使得所有概率之和为1。这种方法可以在一定程度上减轻类别不平衡的影响。
-
损失函数的设计:在训练过程中,损失函数(如交叉熵损失)通常会考虑到每个类别的预测概率和真实标签之间的差异。即使类别不平衡,损失函数也会平等地对待每个类别,因为它的目标是减少所有类别的预测误差。
-
MvM的对称性:在MvM策略中,每个二分类任务都是成对进行的,即每个类别都会与其他每个类别进行一次比较。这种对称性确保了每个类别在所有二分类任务中都有机会作为正类和负类,从而平衡了类别的代表性。
尽管OvR和MvM策略不需要专门处理类别不平衡性,但在以下情况下,考虑类别不平衡仍然是有意义的:
- 极端不平衡:如果某些类别的样本数量非常少,以至于在这些类别上的训练数据不足以训练出一个有效的分类器,那么可能需要采用过采样、欠采样或其他技术来处理不平衡。
- 误分类成本:在某些应用中,不同类别的误分类成本是不同的。在这种情况下,可能需要调整损失函数或使用权重来反映这种成本差异。
总之,OvR和MvM策略通过设计本身就减少了对类别平衡性的依赖,但这并不意味着在所有情况下都可以忽略类别不平衡问题。在实际应用中,仍然需要根据具体问题和数据特性来决定是否需要采取额外的措施来处理类别不平衡。
end if
在编程和算法描述中,end if 是一个关键字或标记,用于指示一个 if 语句块的结束。这种结构通常出现在结构化编程语言中,如BASIC、Pascal、以及某些脚本语言。以下是一个使用 if 和 end if 的简单例子:
pascal
if condition then{ 代码块,当条件为真时执行 }
end if;
在这个例子中,if 关键字后面跟着一个条件表达式,如果该表达式为真(即条件成立),那么花括号 {} 内的代码块将被执行。end if 关键字则标志着 if 语句块的结束。
在更现代的编程语言中,如C、C++、Java、Python等,通常不使用 end if。相反,这些语言依赖于代码的缩进来表示代码块的开始和结束。以下是一个Python中的 if 语句的例子,它不使用 end if:
if condition:# 当条件为真时执行的代码块
在这个Python例子中,当 condition 为真时,缩进的部分代码将被执行。代码块的结束由缩进的减少来指示,而不是使用特定的结束关键字。
启发式
启发式(Heuristic)是一种问题解决的策略,它利用经验和直觉来找到问题的解决方案,而不是系统地列举所有可能的解决方案。启发式方法通常用于那些无法在合理时间内找到最优解或精确解的问题,特别是在复杂性和计算成本很高的情况下。
启发式算法(Heuristic algorithms)是一类算法,它们在解决问题时采用启发式方法。这些算法的目标是在合理的时间内找到一个足够好的解决方案,而不是一定找到最优解。启发式算法通常具有以下特点:
-
快速性:启发式算法通常能够快速地找到解决方案,尤其是当问题的规模很大时。
-
近似性:启发式算法通常不保证找到最优解,但它们可以提供一个足够好的近似解。
-
简单性:启发式算法的设计往往比较简单,易于理解和实现。
-
适应性:启发式算法通常能够适应不同的问题实例,即使是在问题特征发生变化时也能保持较好的性能。
以下是一些常见的启发式算法的例子:
- 贪心算法(Greedy algorithms):在每一步选择当前看起来最好的选项,希望这样能够导致全局最优解。
- 模拟退火(Simulated Annealing):灵感来源于固体材料的退火过程,允许在一定条件下接受比当前解更差的解,以跳出局部最优。
- 遗传算法(Genetic Algorithms):模仿自然选择和遗传学的原理,通过迭代选择、交叉和变异来优化解决方案。
- 蚁群算法(Ant Colony Optimization):模仿蚂蚁觅食行为,通过信息素交流来找到问题的解决方案。
- 禁忌搜索(Tabu Search):通过记忆之前的搜索历史来避免重复搜索,从而探索解空间的不同区域。
启发式算法在许多领域都有应用,包括运筹学、人工智能、网络路由、调度问题、组合优化等。由于它们通常能够在大规模和复杂问题中提供实用的解决方案,因此在实际应用中非常受欢迎。
8tqdm:yujianzhi4.3.1
相关文章:

《机器学习》3.7-4.3end if 启发式 uci数据集klda方法——非线性可分的分类器
目录 uci数据集 klda方法——非线性可分的分类器 计算 步骤 1: 选择核函数 步骤 2: 计算核矩阵 步骤 4: 解广义特征值问题 と支持向量机(svm) 目标: 方法: 核技巧的应用: 区别: 使用 OvR MvM 将…...

【Linux】VMware 安装 Ubuntu18.04.2
ISO镜像安装步骤 选择语言 English 选择键盘布局 English 选择系统 Ubuntu 虚拟机网卡地址,默认即可 代理地址,默认空即可 镜像地址,修改成阿里云地址 选择第二项,LVM 磁盘扩容技术 第一块硬盘名sda,默认…...

人员离岗监测摄像机智能人员睡岗、逃岗监测 Python 语言结合 OpenCV
在安全生产领域,人员的在岗状态直接关系到生产流程的顺利进行和工作环境的安全稳定。人员离岗监测摄像机的出现,为智能人员睡岗、逃岗监测提供了高效精准的解决方案,而其中的核心技术如AI识别睡岗脱岗以及相关的算法盒子和常见的安全生产AI算…...

【Spark】Spark数据倾斜解决方案、大表join小表及大表join大表优化思路
如果觉得这篇文章对您有帮助,别忘了点赞、分享或关注哦!您的一点小小支持,不仅能帮助更多人找到有价值的内容,还能鼓励我持续分享更多精彩的技术文章。感谢您的支持,让我们一起在技术的世界中不断进步! Sp…...

探索 Cesium 的未来:3D Tiles Next 标准解析
探索 Cesium 的未来:3D Tiles Next 标准解析 随着地理信息系统(GIS)和 3D 空间数据的快速发展,Cesium 作为领先的开源 3D 地球可视化平台,已成为展示大规模三维数据和进行实时渲染的强大工具。近年来,随着…...

每日一站技術架構解析之-cc手機桌布網
# 網站技術架構解析: ## 一、整體架構概述https://tw.ccwallpaper.com是一個提供手機壁紙、桌布免費下載的網站,其技術架構設計旨在實現高效的圖片資源管理與用戶訪問體驗優化。 ### (一)前端展示 1. **HTML/CSS/JavaScript基礎構…...

prometheus监控之黑盒(blackbox)监控
1.简单介绍 blackbox-exporter项目地址:https://github.com/prometheus/blackbox_exporter blackbox-exporter是Prometheus官方提供的一个黑盒监控解决方案,blackbox-exporter无须安装在被监控的目标环境中,用户只需要将其安装在与Promethe…...

计算机网络之传输层协议TCP
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 计算机网络之传输层协议TCP 收录于专栏【计算机网络】 本专栏旨在分享学习计算机网络的一点学习笔记,欢迎大家在评论区交流讨论💌 目…...

子查询与嵌套查询
title: 子查询与嵌套查询 date: 2024/12/13 updated: 2024/12/13 author: cmdragon excerpt: 子查询和嵌套查询是关系型数据库中强大的查询工具,允许用户在一个查询的结果中再进行查询。通过使用子查询,用户能够简化复杂的SQL语句,增强查询的灵活性和可读性。本节将探讨子…...

GPT-SoVITS语音合成模型部署及使用
1、概述 GPT-SoVITS是一款开源的语音合成模型,结合了深度学习和声学技术,能够实现高质量的语音生成。其独特之处在于支持使用参考音频进行零样本语音合成,即使没有直接的训练数据,模型仍能生成相似风格的语音。用户可以通过微调模…...

springboot423玩具租赁系统boot(论文+源码)_kaic
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装玩具租赁系统软件来发挥其高效地信息处理的作用,…...

【收藏】Cesium 限制相机倾斜角(pitch)滑动范围
1.效果 2.思路 在项目开发的时候,有一个需求是限制相机倾斜角,也就是鼠标中键调整视图俯角时,不能过大,一般 pitch 角度范围在 0 至 -90之间,-90刚好为正俯视。 在网上查阅了很多资料,发现并没有一个合适的…...

Jenkins流水线初体验(六)
DevOps之安装和配置 Jenkins (一) DevOps 之 CI/CD入门操作 (二) Sonar Qube介绍和安装(三) Harbor镜像仓库介绍&安装 (四) Jenkins容器使用宿主机Docker(五) Jenkins流水线初体验(六) 一、Jenkins流水线任务介绍 之前采用Jenkins的自由风格构建的项目,每个步骤…...

Azure OpenAI 生成式人工智能白皮书
简介 生成式 AI 成为人工智能领域新的关键词。吸纳从机器智能到机器学习、深度学习的关键技术生成式 AI更进一步,能够根据提示或现有数据创建新的书面、视觉和听觉内容。在此基础上大模型和大模型应用一时涌现,并迅速确立AI落地新范式。据 data.ai inte…...

Ubuntu22.04安装docker desktop遇到的bug
1. 确认已启用 KVM 虚拟化 如果加载了模块,输出应该如下图。说明 Intel CPU 的 KVM 模块已开启。 否则在VMware开启宿主机虚拟化功能: 2. 下一步操作: Ubuntu | Docker Docs 3. 启动Docker桌面后发现账户登陆不上去: Sign in | …...

LLMC:大语言模型压缩工具的开发实践
关注:青稞AI,学习最新AI技术 青稞Talk主页:qingkelab.github.io/talks 大模型的进步,正推动我们向通用人工智能迈进,然而庞大的计算和显存需求限制了其广泛应用。模型量化作为一种压缩技术,虽然可以用来加速…...

基于阿里云Ubuntu22.04 64位服务器Java及MySql环境配置命令记录
基于阿里云Ubuntu22.04 64位服务器Java及MySql环境配置命令记录 Java 23 离线环境配置MySql 环境配置MySQL常用命令 Java 23 离线环境配置 下载 Ubuntu环境下 Java 23 离线包 链接: java Downloads. 在Linux环境下创建一个安装目录 mkdir -p /usr/local/java将下载好的jdk压缩…...
)
第一课【输入输出】(题解)
1.向世界问好 题目描述 编程输出以下内容: Hello World! Im a C program. 输入格式 本题无输入。 输出格式 请按照样例输出,注意大小写、空格、感叹号,句号,单引号都必须使用英文输入法里的符号。 样例输入/输出 输入数据 1 本题无…...
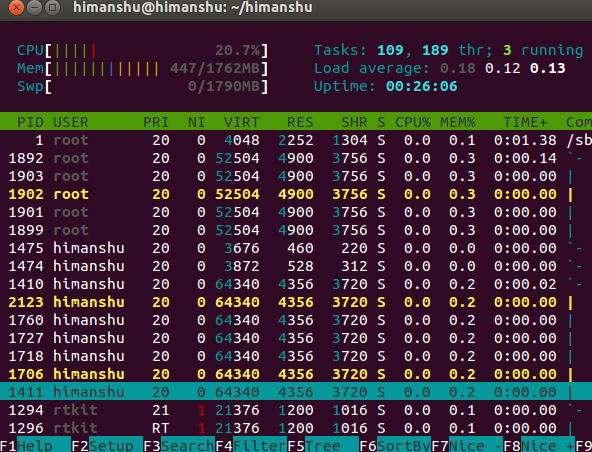
查看 Linux 进程运行所在 CPU 内核
判断进程运行在哪个 CPU 内核上 作者:Dan Nanni 译者:LCTT | 2015-09-28 10:43 问题:Linux 进程运行在多核处理器系统上。怎样才能找出哪个 CPU 内核正在运行该进程? 当你在 多核 NUMA 处理器上 运行需要较高性能的 HPC&…...

ESP32外设学习部分--SPI篇
SPI学习 前言 我个人以为开始学习一个新的单片机最好的方法就是先把他各个外设给跑一遍,整体了解一下他的功能,由此记录一下我学习ESP32外设的过程,防止以后忘记。 SPI 配置步骤 SPI总线初始化 spi_bus_config_t buscfg {.miso_io_num …...

深度揭秘:如何在Mac上无痛备份微信聊天记录
深度揭秘:如何在Mac上无痛备份微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因微信聊天记录丢失而懊恼?那些珍贵的对话、重…...

5分钟永久激活Windows和Office的终极解决方案:KMS智能激活工具完整指南
5分钟永久激活Windows和Office的终极解决方案:KMS智能激活工具完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Offi…...

unplugin-dts完整指南:从vite-plugin-dts迁移到通用插件
unplugin-dts完整指南:从vite-plugin-dts迁移到通用插件 【免费下载链接】unplugin-dts An unplugin for generating declaration (dts) files. 项目地址: https://gitcode.com/gh_mirrors/vi/unplugin-dts unplugin-dts是一款功能强大的通用插件,…...

7个实用技巧让你快速掌握Sabaki围棋软件:从零基础到高手复盘
7个实用技巧让你快速掌握Sabaki围棋软件:从零基础到高手复盘 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki Sabaki是一款优雅的围棋棋盘和SGF编辑器ÿ…...

终极指南:如何用amdgpu_top实时监控AMD显卡性能
终极指南:如何用amdgpu_top实时监控AMD显卡性能 【免费下载链接】amdgpu_top Tool to display AMDGPU usage 项目地址: https://gitcode.com/gh_mirrors/am/amdgpu_top 还在为AMD显卡性能监控而烦恼吗?想要像NVIDIA用户使用nvidia-smi那样轻松掌握…...

VideoDownloadHelper:打破视频下载壁垒的智能浏览器插件
VideoDownloadHelper:打破视频下载壁垒的智能浏览器插件 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 在信息爆炸的时代&#x…...

【限时解密】全球仅12家旅游公司跑通的AI Agent冷启动模型:含私有知识库构建SOP
更多请点击: https://codechina.net 第一章:【限时解密】全球仅12家旅游公司跑通的AI Agent冷启动模型:含私有知识库构建SOP 在旅游行业AI落地实践中,“冷启动难”长期制约Agent规模化部署——93%的试点项目因知识断层、意图歧义…...

5个步骤掌握ScriptHookV:GTA V脚本开发终极指南
5个步骤掌握ScriptHookV:GTA V脚本开发终极指南 【免费下载链接】ScriptHookV An open source hook into GTAV for loading offline mods 项目地址: https://gitcode.com/gh_mirrors/sc/ScriptHookV 你是否曾梦想过为GTA V创造属于自己的游戏模组?…...

Claude投资回报率究竟怎么算?揭秘企业级ROI模型的7个隐藏变量与实时测算模板
更多请点击: https://kaifayun.com 第一章:Claude投资回报率的核心定义与行业基准 Claude投资回报率(ROI)并非传统软件许可模型下的简单成本收益比,而是衡量企业将Claude系列大模型深度集成至核心业务流程后ÿ…...

在Node.js服务中集成Taotoken实现智能问答与内容生成功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现智能问答与内容生成功能 对于Node.js后端开发者而言,为应用添加智能问答或内容生成能…...