GLM-4-Plus初体验

引言:为什么高效的内容创作如此重要?
在当前竞争激烈的市场环境中,内容创作已成为品牌成功的重要支柱。无论是撰写营销文案、博客文章、社交媒体帖子,还是制作广告,优质的内容不仅能够帮助品牌吸引目标受众的注意力,还能有效促进产品和服务的转化。然而,创作高质量内容却常常需要投入大量时间和精力,这使得很多内容创作者感到力不从心。
高效创作正成为现代内容创作者的迫切需求。如果你也为高效创作而苦恼,那么今天我们将为你介绍一款强大的内容创作工具——智谱AI GLM-4-Plus。通过这款 AI 写作助手,你将能够在短时间内生成高质量的内容,大大提升工作效率。
1. 什么是 GLM-4-Plus?
GLM-4-Plus是一种基于深度学习的自然语言处理(NLP)模型,属于生成式预训练变换器(GPT)系列的升级版本。它由大规模数据集训练而成,旨在理解和生成自然语言文本。GLM-4-Plus 在多个自然语言处理任务上表现优异,包括文本生成、文本理解、自动摘要、问答系统等。
GLM-4-Plus 的核心功能:
-
文本生成:GLM-4-Plus 能够根据给定的输入(例如提示语、关键词等)生成流畅、自然的文本,广泛应用于文案写作、广告创意、内容生成等场景。
-
问答能力:通过对问题的理解,GLM-4-Plus 可以生成精确的回答,适用于自动化客户服务、信息查询等场景。
-
文本理解:能够准确理解复杂的句子结构和上下文,进行有效的信息提取和分析。
-
多语言支持:除了中文,GLM-4-Plus 还支持多种语言的文本生成和理解,包括英语、法语、德语、日语等。
-
上下文保持:它能够保持长篇文本中的上下文一致性,在生成内容时不会失去原有语境,使得输出内容更加自然和连贯。
应用场景:
- 内容创作:可用于生成博客文章、产品描述、新闻稿、广告文案等。
- 客户支持:通过自动生成客服回答,减少人工客服的负担。
- 营销和广告:帮助品牌和电商平台快速生成创意广告、产品描述及推广文案。
- 教育与学习:用于自动化生成学习资料、解答学生提问等。
2. 如何调用 GLM-4-Plus API?
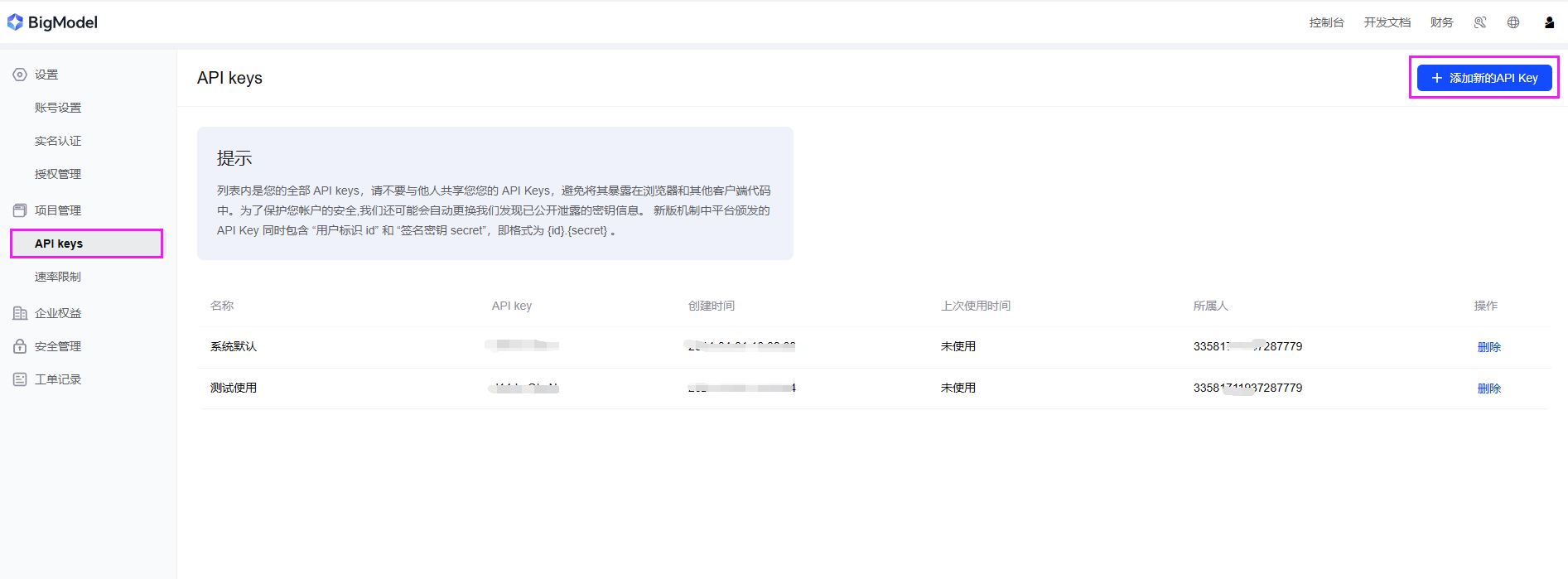
步骤 1:注册并获取 API 密钥
- 访问 GLM-4-Plus 的官方网站或开发者平台。
- 注册账号并登录,在个人中心-项目管理-APIkeys菜单 创建一个新的API Key。
- API 密钥通常是一个长字符串,用于身份验证和安全请求。
如下图
步骤 2:安装必要的依赖
为了调用 API,你需要在你的开发环境中安装相应的依赖,推荐使用 Python。你可以通过以下命令安装ZhipuAI库:
pip install ZhipuAI
步骤 3:编写代码调用 API
以下是一个 Python 代码示例,展示如何调用 GLM-4-Plus API 生成内容:
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 请填写您自己的APIKey
response = client.chat.completions.create(model="glm-4-plus", # 请填写您要调用的模型名称messages=[{"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的口号"},{"role": "assistant", "content": "当然,要创作一个吸引人的口号,请告诉我一些关于您产品的信息"},{"role": "user", "content": "智谱AI开放平台"},{"role": "assistant", "content": "点燃未来,智谱AI绘制无限,让创新触手可及!"},{"role": "user", "content": "创作一个更精准且吸引人的口号"}],
)
print(response.choices[0].message)
响应示例
{"created": 1703487403,"id": "8239375684858666781","model": "glm-4-plus","request_id": "8239375684858666781","choices": [{"finish_reason": "stop","index": 0,"message": {"content": "以AI绘蓝图 — 智谱AI,让创新的每一刻成为可能。","role": "assistant"}}],"usage": {"completion_tokens": 217,"prompt_tokens": 31,"total_tokens": 248}
}
步骤 4:常用参数说明
model: 要调用的模型编码。model: 调用语言模型时,当前对话消息列表作为模型的提示输入,以JSON数组形式提供。max_tokens: 模型输出的最大token数,最大输出为4095,默认值为1024。temperature: 生成内容的创造性。值越高,生成的内容越多样化。top_p: 控制生成内容的合理性,值越低,生成内容的质量越高。tools: 模型可以调用的工具。stop: 模型遇到stop指定的字符时会停止生成。目前仅支持单个stop词,格式为[“stop_word1”]。
除了Python和java SDK,模型服务也支持标准的 HTTP 调用,我会在后面的案例中讲到。
更多使用参考 官方文档
3. 搭建你的内容生成神器
下面我写一个简单的前后端服务demo,来演示下如何搭建一个自己的内容创造神器。
前端我就用vue+axios写一个h5页面,根据输入的问题,发起请求展示响应结果。
显示效果如下:
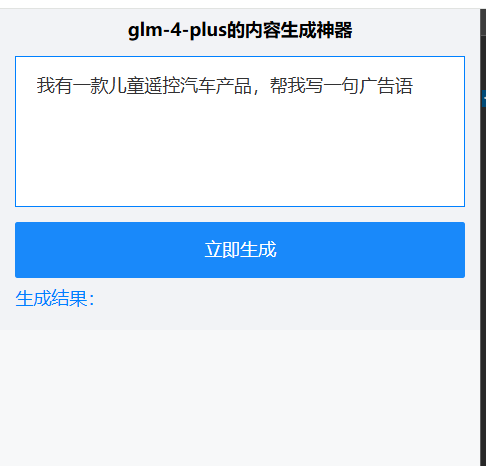
对应的代码:
<template><div class="page"><div class="title-info">glm-4-plus的内容生成神器</div><div class="input-box"><van-fieldv-model="inputValue"rows="4"autosizetype="textarea"placeholder="请输入描述内容"show-word-limit/></div><!-- <div class="type-select-box"><van-radio-group v-model="tyoe"><van-radio name="1">生成广告文案</van-radio><van-radio name="2">公众号炫酷标题</van-radio><van-radio name="3">电商产品撰写文案</van-radio></van-radio-group></div> --><div class="btn-box"><van-button block type="info" @click="searchResult"> 立即生成</van-button></div><div class="result-box"><p class="s-title">生成结果:</p><div v-if="loading">正在生成,请等待..</div><div class="markdown" v-html="renderedMarkdown" v-else></div><!-- <div v-html="result"></div> --></div></div>
</template><script>
import markdownIt from 'markdown-it';
import { aiSearch } from '@api';
let md = null;
function markdownItCustomLink(md, options) {md.renderer.rules.link_open = function (tokens, idx, options, env, self) {const hrefIndex = tokens[idx].attrIndex('href');const href = tokens[idx].attrs[hrefIndex][1];// const text = tokens[idx + 1].content;// 返回一个自定义组件的标签,其中包含 href 和文本内容return `<span class="md-link-to-span" data-num="${href}">${href}</span>`;};md.renderer.rules.link_close = function () {return '';};
}
export default {name: 'HomeView',components: {},data() {return {inputValue: '',// type: '1',result: '',loading: false,renderedMarkdown: ''};},mounted() {md = markdownIt().use(markdownItCustomLink);this.renderedMarkdown = md.render(this.result);// this.mdText();},methods: {searchResult() {this.loading = true;aiSearch({ content: this.inputValue }).then(res => {this.loading = false;const { code, data } = res;if (code === '0000') {this.renderedMarkdown = md.render(data.content);} else {}}).catch(() => {this.loading = false;});},// 搜索search() {},mdText() {// this.renderedMarkdown = md.render(this.result);}}
};
</script>
<style lang="less" scoped>
.page {font-size: 28px;padding: 12px 24px;background-color: #f2f3f6;.title-info {font-weight: bold;text-align: center;}.input-box {margin: 24px 0;/deep/.van-cell {border: 2px solid #0080ff;}}.btn-box {margin-top: 20px;}.result-box {margin: 12px 0;.s-title {color: #0080ff;margin-bottom: 20px;}}
}
</style>我使用了markdown-it 来处理接口返回的md格式内容
后端服务我使用了前端同学熟悉的express搭建,通过调用智谱 AI 提供的 http接口来实现的(当然使用py sdk是最好的)。
代码如下:
index.js 入口文件
const express = require('express');
const path = require('path');
const bodyParser = require('body-parser');
const cookieParser = require('cookie-parser');
const logger = require('morgan');
const partials = require('express-partials');const config = require('./config');
const routes = require('./routes/index');const app = express();const port = process.env.PORT || config.port;
app.set('port', port);
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'ejs');// 静态文件托管
app.use(express.static(path.join(__dirname, 'public')));app.use(logger('dev'));app.use(bodyParser.json());
//extended:false 方法内部使用querystring模块处理请求参数的格式
//extended:true 方法内部使用第三方模块qs处理请求参数的格式
app.use(bodyParser.urlencoded({ extended: false }));
app.use(partials());
app.use(cookieParser());//配置diskStorage来控制文件存储的位置以及文件名字等app.use('/', routes);app.listen(app.get('port'), () => {console.log('Program starts running ...');console.log('server run success on port ' + app.get('port'));
});module.exports = app;然后就是处理请求的主要代码:
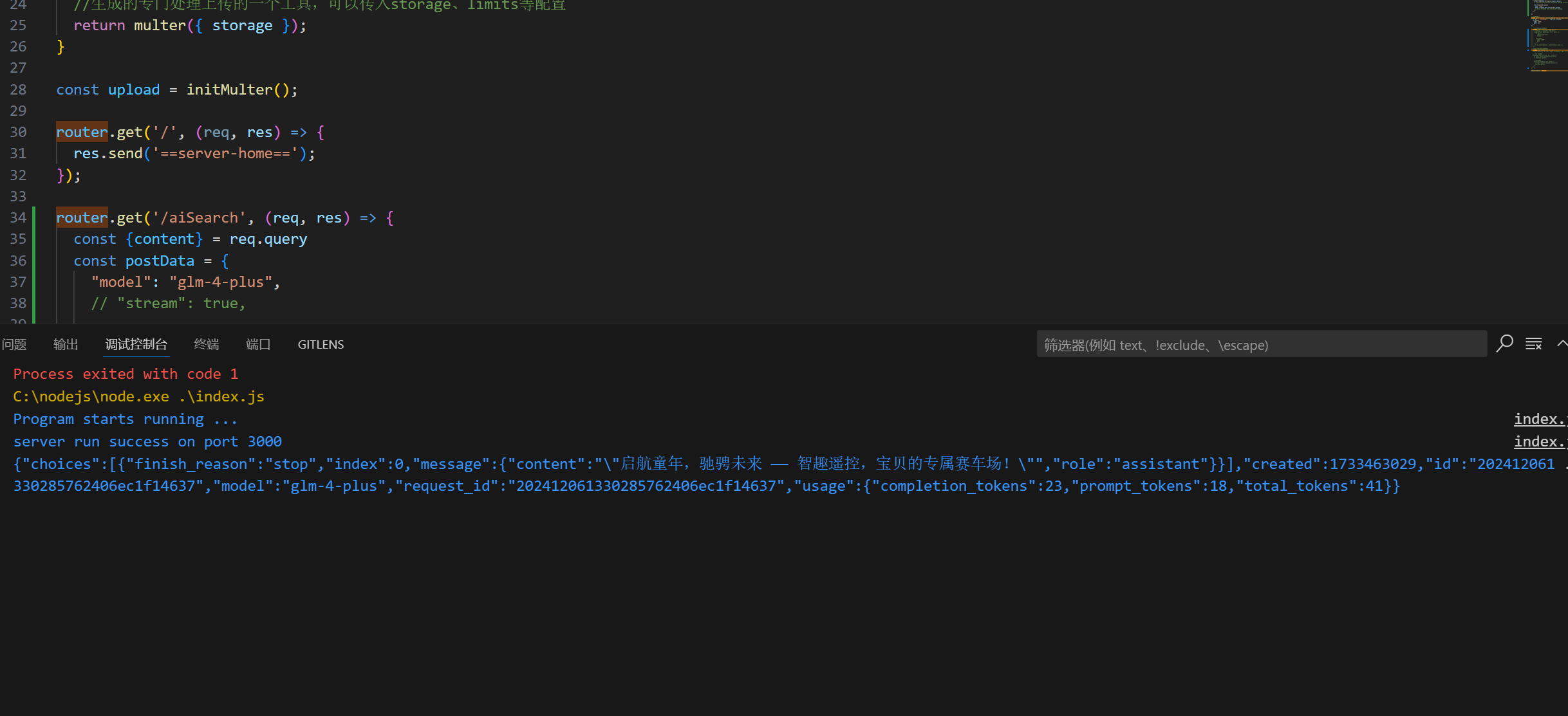
router.get('/aiSearch', (req, res) => {const {content} = req.queryconst postData = {"model": "glm-4-plus",// "stream": true,"messages": [{"role": "user","content": content}]}axios.post('https://open.bigmodel.cn/api/paas/v4/chat/completions', postData, {headers: {'Content-Type': 'application/json','Authorization': `Bearer ${apiKey}`}}).then(response => {console.log(JSON.stringify(response.data));// res.send(response.data.choices[0].message.content);res.status(200).json({code: '0000',data: response.data.choices[0]?.message// data: response.data.choices[0]?.message});});});
打印生成的结果:
最终前端页面呈现的结果:
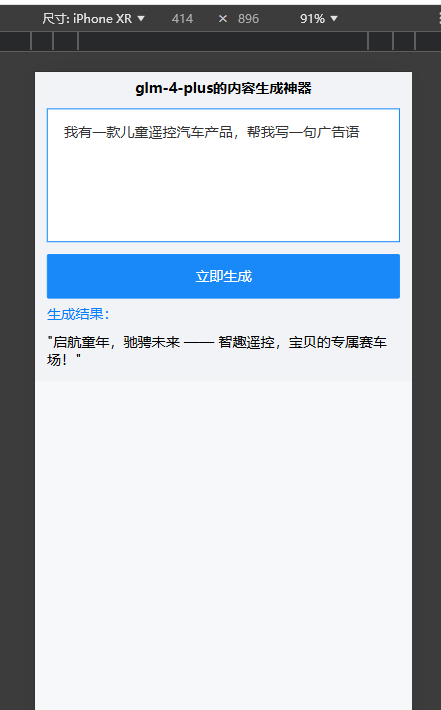
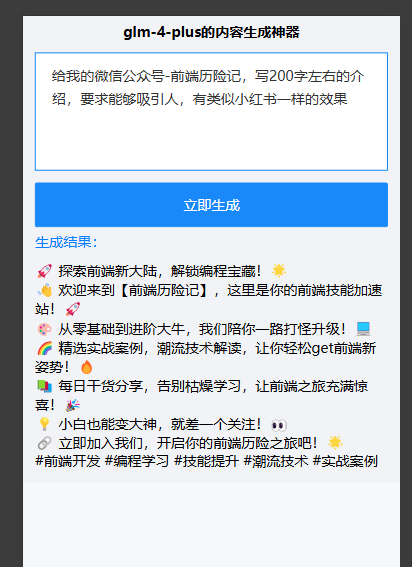
我们再给公众号生成类似小红书格式的介绍:
服务端源码地址 ,apikey 需要替换为自己的。
4. GLM-4-Plus 的使用技巧
通过 Function Call 访问外部 API
我们可以允许模型访问外部信息和执行操作,信息查询:如实时天气预 报、股票市场动态,提供即时且准确的数据,执行操作:比如播放音乐、 控制智能家居设备等。
通过 Retrieval 访问智谱AI 开放平台的知识库
通过Retrieval方法访问智谱开放平台的知识库,用户可上传相关的知识到知识库,模型将基于用户的查询,提取相关的语义切片,提供更加精准详细的信息。
引导它进行自我探索和推理
在明确引导模型进行推理判断之前,让它先生成结果作为基准。例如,如果我们需要模型评估代码的质量,可以先让模型自行生成答案,随后再对其正确性进行评判。这样做不仅促使模型更加深入地理解任务,还可以提高最终结果的准确性和可靠性。
5. GLM-4-Plus 的优势深入分析
-
高效的内容生成
GLM-4-Plus 能快速生成高质量的文本,极大提高写作效率。无论是文章、广告文案,还是社交媒体内容,几秒钟内就能完成生成。 -
灵活的文本风格与语气控制
支持多种文本风格(如正式、幽默、创意等)和语气(如劝导、激励等),让生成的内容精准符合目标需求。 -
高质量输出
生成的文本流畅自然、结构清晰,符合语法规范,接近人工创作水平,适合多种专业领域。 -
多场景适用
无论是电商文案、SEO文章,还是社交媒体帖子、技术文档,GLM-4-Plus 都能提供精准的内容生成支持。 -
多语言支持
除了中文,GLM-4-Plus 支持多种语言(如英语、日语等),适合全球化创作,能为不同语言的市场生成定制内容。 -
高度可定制
用户可以设置生成文本的长度、创意度等参数,满足不同创作需求,提供更高的控制灵活性。 -
自动化与API集成
支持API接口,可与现有工作流集成,实现内容生成自动化,提高团队效率。
总结
随着 AI 技术的快速发展,像GLM-4-Plus这样的智能写作工具正逐渐改变我们内容创作的方式。它不仅可以大大提升写作效率,还能帮助我们生成多样化、符合需求的高质量内容。未来,随着技术的不断进步,GLM-4-Plus 可能会引入更多智能化功能,进一步简化创作流程。
相关文章:
GLM-4-Plus初体验
引言:为什么高效的内容创作如此重要? 在当前竞争激烈的市场环境中,内容创作已成为品牌成功的重要支柱。无论是撰写营销文案、博客文章、社交媒体帖子,还是制作广告,优质的内容不仅能够帮助品牌吸引目标受众的注意力&a…...

基于springboot+vue的高校校园交友交流平台设计和实现
文章目录 系统功能部分实现截图 前台模块实现管理员模块实现 项目相关文件架构设计 MVC的设计模式基于B/S的架构技术栈 具体功能模块设计系统需求分析 可行性分析 系统测试为什么我? 关于我项目开发案例我自己的网站 源码获取: 系统功能 校园交友平台…...

Nacos 3.0 Alpha 发布,在安全、泛用、云原生更进一步
自 2021 年发布以来,Nacos 2.0 在社区的支持下已走过近三年,期间取得了诸多成就。在高性能与易扩展性方面,Nacos 2.0 取得了显著进展,同时在易用性和安全性上也不断提升。想了解更多详细信息,欢迎阅读我们之前发布的回…...

【前端开发】HTML+CSS网页,可以拿来当作业(免费开源)
HTML代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content_lizhongyu"widthdevice-width, initial-scale1.0"><title>小兔鲜儿-新鲜、惠民、快捷<…...
的中阶应用:从图像分类到目标检测)
【人工智能-中级】卷积神经网络(CNN)的中阶应用:从图像分类到目标检测
文章目录 卷积神经网络(CNN)的中阶应用:从图像分类到目标检测1. 图像分类:CNN的基础应用CNN结构概述经典网络架构2. 目标检测:从分类到定位基于区域的目标检测方法单阶段目标检测方法边界框回归与NMS(Non-Maximum Suppression)3. 深度学习中的目标检测挑战与解决方案4. …...

[笔记] 编译LetMeowIn(C++汇编联编程序)过程
文章目录 前言过程下载源码vs2017 创建空项目 引入编译文件改项目依赖属性改汇编编译属性该项目还需注意编译运行 总结 前言 编译LetMeowin 项目发现是个混编项目,c调用汇编的程序,需要配置一下,特此记录一下 过程 下载源码 首先下载源码…...
)
牛客小白月赛107(A~E)
文章目录 A Cidoai的吃饭思路code B Cidoai的听歌思路code C Cidoai的植物思路code D Cidoai的猫猫思路code E Cidoai的可乐思路code 牛客小白月赛107 A Cidoai的吃饭 思路 签到题,按题意模拟即可 code void solve(){int n,a,b,c;cin >> n >> a &g…...

批量DWG文件转换低版本(CAD图转低版本)——c#插件实现
此插件可实现指定路径下所有dwg文件(包含子文件夹内dwg)一键全部转为低版本(包含2004、2007、2018版本,也可定制指定版本)。效果如下: (使用方法:命令行输入 “netload” 加载插件&…...

安装Python库
安装Python库 一、pip安装参数--no-deps 更换下载源,一劳永逸 二、conda下载 一、pip安装 换源安装并且信任该下载源 pip install pipenv -i http://pypi.douban.com/simple --trusted-host pypi.douban.com参数 –no-deps 有些 packages 会依赖一些其它的 p…...

智慧政务数据中台建设及运营解决方案
数据中台:政府数字化转型的引擎 数据中台作为政府数字化转型的核心驱动力,起源于美军的作战体系,强调高效、灵活与强大。它不仅促进了政府决策的科学性,还推动了政府服务的精细化与智能化。 数据中台的应用场景:数字…...

陪玩系统小程序源码/游戏陪玩APP系统用户端有哪些功能?游戏陪玩小程序APP源码开发
多客陪玩系统-游戏陪玩线下预约上门服务等陪玩圈子陪玩社区系统源码 陪玩系统源码,高质量的陪玩系统源码,游戏陪玩APP源码开发,语音陪玩源码搭建: 线上陪玩活动组局与线下家政服务系统的部署需要综合考虑技术选型、开发流程、部署流程、功能实…...

米哈游大数据面试题及参考答案
怎么判断两个链表是否相交?怎么优化? 判断两个链表是否相交可以采用多种方法。 一种方法是使用双指针。首先分别遍历两个链表,得到两个链表的长度。然后让长链表的指针先走两个链表长度差的步数。之后,同时移动两个链表的指针,每次比较两个指针是否指向相同的节点。如果指…...

使用Hydra库简化配置管理
使用Hydra库简化配置管理 简介 在现代软件开发中,配置管理是至关重要的。应用程序的灵活性和可维护性很大程度上取决于其如何处理配置。Hydra是一个由Facebook AI Research (FAIR) 开发的Python库,它旨在简化复杂应用的配置过程。Hydra使得开发者可以轻…...

二维数组和函数
文章目录 1、课程代码 #include <bits/stdc.h> using namespace std;//定义函数 /*函数名的命名规则和变量是一致的 函数的返回值数据类型 函数名(形式参数){函数体 } */ //自己写乘方pow这个函数 pow(2,3) int p(int a,int b); int p(int a,int b){int s1;for(i…...

如何在 Ubuntu 终端中打开当前文件夹的图形界面
文章目录 1. 简介2. 方法一:使用 Nautilus 文件管理器3. 方法二:使用通用命令 xdg-open4. 方法三:使用其他文件管理器5. 推荐方案6. 参考资料 1. 简介 在日常使用 Linux 系统时,我们常常会在终端中执行各种操作。有时,…...

基于SpringBoot的嗨玩旅游网站:一站式旅游信息服务平台的设计与实现
摘要 在旅游需求日益增长的今天,一个全面、便捷的旅游信息服务平台显得尤为重要。嗨玩旅游网站正是为了满足这一需求而设计的在线平台,它提供了包括景点信息、旅游线路、商品信息、社区信息和活动推广等在内的丰富旅游目的地信息,旨在帮助用…...

Opencv之图像梯度处理和绘制图像轮廓
一、梯度处理的sobel算子函数 处理示意 Sobel 算子是一种常用的图像边缘检测方法,结合了一阶导数和高斯平滑,用于检测图像的梯度信息。 1、功能 Sobel 算子用于计算图像在 x 和 y 方向的梯度,主要功能包括: 强调图像中灰度值的…...

vue3的watch一次性监听多个值用法
vue3的watch一次性监听多个值 1、监听单个值 watch(() > route.params.keyword, (newValue, oldValue) > {console.log(监听值变化, newVal, oldVal)state.a newValue});2、监听多个值 watch(() > [route.params.id, route.params.keyword], (newValue, oldValue) &g…...

Electron和C/C++开发桌面应用对比
Electron和C/C开发桌面应用对比 1. Electron 的特点 优点 跨平台支持: Electron 基于 Chromium 和 Node.js,可以轻松构建跨平台应用(Windows、macOS、Linux)。开发者只需编写一套代码,即可在多个平台上运行。 使用 …...

Q学习(Q-Learning)详解
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

Frida hook so层解析protobuf二进制数据实战指南
1. 这不是“hook个so那么简单”:为什么 protobuf 数据成了 Frida 调试里最隐蔽的拦路虎你有没有遇到过这种情况:用 Frida 成功 hook 到某个 so 库里的关键函数,log 打得满屏飞,参数地址、返回值、调用栈一应俱全——可当你兴冲冲地…...
)
MIMIC-CXR数据集加载实战:用Python从零处理医学影像与报告文本(附完整代码)
MIMIC-CXR数据集加载实战:用Python从零处理医学影像与报告文本(附完整代码)当你第一次打开MIMIC-CXR数据集时,那种面对海量嵌套目录和元数据的茫然感我深有体会。作为医学AI领域最具挑战性的公开数据集之一,MIMIC-CXR包…...

对比体验使用Taotoken聚合接口与直连原厂API的延迟与稳定性差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比体验使用Taotoken聚合接口与直连原厂API的延迟与稳定性差异 1. 引言 在集成大模型能力到实际业务时,开发者除了关…...

Topit:macOS窗口置顶的终极方案,提升多任务效率300%的必备工具
Topit:macOS窗口置顶的终极方案,提升多任务效率300%的必备工具 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 在macOS上工作时…...

对比Token Plan与按量计费,如何为你的项目选择更经济的消费模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比Token Plan与按量计费,如何为你的项目选择更经济的消费模式 对于使用大模型API的开发者而言,成本控制是…...

如何快速清理Windows右键菜单:终极管理工具完整指南
如何快速清理Windows右键菜单:终极管理工具完整指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是也遇到过这样的烦恼?安装的软…...

python flash加一个字段
USE product_db; ALTER TABLE products ADD COLUMN remark TEXT COMMENT 商品备注信息,支持长文本 AFTER cost_price;2. 修改数据访问层(product_dao.py)需要在以下函数中添加 remark 字段的处理:修改 get_all_products 函数&…...

深度解析ESLyric-LyricsSource:Foobar2000逐字歌词插件的终极技术方案
深度解析ESLyric-LyricsSource:Foobar2000逐字歌词插件的终极技术方案 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource ESLyric-LyricsSource是…...

如何用knitAYABInterface创建复杂图案:从JSON文件到针织成品的完整流程
如何用knitAYABInterface创建复杂图案:从JSON文件到针织成品的完整流程 【免费下载链接】knitAYABInterface A Python library with the interface to the AYAB shield. 项目地址: https://gitcode.com/gh_mirrors/ay/knitAYABInterface 想要将数字图案转化为…...

基于Rust和Axum的高性能静态文件服务器架构设计与实现
基于Rust和Axum的高性能静态文件服务器架构设计与实现 【免费下载链接】simple-http-server Simple http server in Rust (Windows/Mac/Linux) 项目地址: https://gitcode.com/gh_mirrors/si/simple-http-server 在现代化开发工作流中,高效的文件共享与静态资…...