es中段是怎么合并的
文章目录
- 1. 段合并的背景
- 2. 合并的方式
- 2.1TieredMergePolicy 的层次结构
- 2.2 层次的基本规则
- 2.3 如何理解层次(tier)
- 2.4. 合并过程中的层次示例
- 2.5. TieredMergePolicy 的优势
- 2.6. 小结
- 3. 合并过程中的优化
- 4. 合并的性能考虑
- 5. 使用 API 手动合并
- 6. 合并的影响
在 ES(Elasticsearch)中,合并(merge)操作通常是指索引中段(segments)的合并。Elasticsearch 使用段(segment)来存储数据,随着时间的推移,数据不断被写入索引,这些数据会被组织成多个段。当数据量增大时,段的数量也会增多,过多的小段可能会影响查询性能。因此,Elasticsearch 会在后台定期执行合并操作,将多个小段合并成较大的段,以提升查询效率并减少磁盘空间的使用。
1. 段合并的背景
- Elasticsearch 是基于 Apache Lucene 构建的,Lucene 采用段化存储(Segmented Storage)来管理索引。
- 每当新的文档被添加到索引时,它会被写入到一个新的段中,直到达到某个阈值(如磁盘空间或写入速率),才会将这些段合并成较大的段。
- 每次合并后,新的段包含了原有段的所有数据,但会丢弃已删除的文档(通过标记为“删除”而非实际删除)。
2. 合并的方式
合并操作主要是通过 Lucene 中的 Merge Policy 和 Merge Scheduler 来控制。Elasticsearch 会在后台使用以下机制来决定何时执行合并操作:
-
自动合并:Elasticsearch 会根据配置的阈值(如段的数量、大小等)来自动进行合并。合并操作是异步进行的,不会影响前台的查询操作。
-
合并触发的条件
:通常,当段的数量过多或者单个段的大小过小时,Elasticsearch 会触发合并操作。合并的过程是通过
MergePolicy来调整的。常见的合并策略包括:
- LogByteSizeMergePolicy:基于段的字节大小来进行合并。
- TieredMergePolicy:基于段的层次结构来进行合并,通常适用于包含大量文档的情况。
-
手动触发合并:可以通过 API(如
force_merge)来手动触发合并操作。例如,在删除大量文档或更新索引时,可能需要通过手动触发合并操作来优化索引。
理解 TieredMergePolicy 中的 层次(tier) 概念,对于更好地优化 Elasticsearch 的段合并策略至关重要。TieredMergePolicy 采用分层的策略来管理段的合并,它的主要目标是控制每个层次中的段的数量、大小以及合并的频率,从而提高索引的查询效率,并避免过早或过频繁的合并。
2.1TieredMergePolicy 的层次结构
在 TieredMergePolicy 中,层次(tier)是指按照段的大小划分的不同“层级”。这些层次帮助管理段的合并,避免过度合并小段,同时确保合并后的段大小合理,能够有效地提升查询性能。
具体来说,Elasticsearch 会将索引中的段分成若干层,每个层次内的段符合某些大小范围。每个层次内的段被合并成一个新的段,直到最终的段符合某个阈值。合并通常发生在以下几种情况:
- 每个层次中的段数量超过设定的阈值,即该层次的段数量过多,可能会导致查询性能下降。
- 每个层次中的段大小过大,即某些段已经过大,合并可以减少查询时需要加载的段数。
2.2 层次的基本规则
TieredMergePolicy 的层次规则可以通过以下几个核心参数来理解:
segments_per_tier(每个层次的最大段数):- 该参数决定了每个层次最多可以包含多少个段。如果某个层次的段数超过了这个值,就会触发合并操作。
- 默认值:
10,意味着每个层次最多有 10 个段。如果某个层次中的段数超过 10 个,就会触发合并,将这些段合并为一个更大的段。
floor_segment(最小段大小):- 该参数定义了段的最小大小。任何小于这个大小的段不会被合并。
- 默认值:
2MB,即小于 2MB 的段不会被合并,因为它们太小,合并也无法带来显著的性能提升。
max_merged_segment(最大合并段大小):- 该参数定义了合并后段的最大大小。合并后的段不应该超过此大小,否则会导致过大的段,影响查询性能。
- 默认值:
5GB,即合并后的段最大不超过 5GB。
2.3 如何理解层次(tier)
层次是 TieredMergePolicy 的核心概念,它描述了段在合并过程中的分组方式。可以通过以下几个层次的特征来理解它的工作机制:
- 第一层:包含最小的段,通常是刚刚写入索引的段,这些段很小(可能只有几MB),不适合马上合并,因此它们会被保留在第一层。
- 第二层及以上:随着段的合并,它们逐渐被移动到更高层次。合并后的段会被分配到第二层、第三层等,直到它们合并成一个大的段。
- 如果一个层次中的段数超过了
segments_per_tier的最大值,或者其中某些段的大小过大(超过了max_merged_segment),就会触发合并操作,将这些段合并成一个更大的段,并移动到下一层。
- 如果一个层次中的段数超过了
2.4. 合并过程中的层次示例
假设我们有以下设置:
segments_per_tier = 10:每个层次最多包含 10 个段。floor_segment = 2MB:最小段大小为 2MB。max_merged_segment = 5GB:每个合并后的段最多为 5GB。
假设索引中当前有以下段(按大小排序):
- 第一层:5 个段,分别为 1MB, 1.5MB, 2MB, 3MB, 4MB(都小于
max_merged_segment,适合保持在第一层)。 - 第二层:12 个段,大小分别为 10MB, 20MB, 30MB 等。
- 第三层:15 个段,大小分别为 100MB, 200MB 等。
在合并的过程中,TieredMergePolicy 会按以下规则工作:
-
第一层的段会尽量保留原样(因为它们很小,合并后可能会浪费资源)。
-
第二层的段,如果超过 10 个段,将被合并成更大的段,直到每个层次中段的数量少于
segments_per_tier(此处为 10)。 -
合并后的段会继续向 更高的层次移动,直到满足合并后的大小上限(例如 5GB)。
2.5. TieredMergePolicy 的优势
- 减少频繁的合并:与
LogByteSizeMergePolicy(基于字节大小的合并策略)不同,TieredMergePolicy会根据段的数量和层次来调整合并的时机,从而减少了过早合并小段的频率。它避免了过度合并的情况,提升了系统的性能和稳定性。 - 合并过程优化:它通过分层控制,使得每个层次中的段数量和大小都在合理范围内,从而避免了过大的段带来的性能问题,也避免了段数量过多导致的查找效率降低。
2.6. 小结
TieredMergePolicy 通过将段分成多个层次来管理合并策略,每个层次的段数和大小有一定的限制。每当一个层次中的段数超出限制时,Elasticsearch 就会触发合并操作,将小段合并为更大的段,并向更高层次迁移。这样可以有效地控制合并过程,减少系统负载,提高查询效率。
- 每个层次的段数超过
segments_per_tier时会触发合并。 - 合并的最大段大小由
max_merged_segment控制。 - 最小段大小由
floor_segment控制,不会合并小于该大小的段。
通过调整这些参数,可以根据实际业务需求优化 Elasticsearch 索引的合并行为,从而平衡性能和资源消耗。
3. 合并过程中的优化
- 去除已删除文档:合并过程中,Lucene 会通过清理标记为删除的文档来减少索引的大小。虽然删除操作是逻辑删除,但合并会物理删除这些文档,从而释放空间。
- 合并段的大小:合并后,新的段会比原来的段大,这样可以减少段的数量。大段通常会更有效地利用缓存和 I/O,从而提高查询性能。
4. 合并的性能考虑
- 后台运行,不影响查询:合并通常是后台任务,不会影响前端的查询性能。然而,在合并过程中,可能会有较高的磁盘和 CPU 使用率,所以在负载较高的生产环境中,要注意合并的频率和时机。
- 优化合并策略:可以根据实际的硬件环境和使用场景来调整合并的策略。例如,在资源紧张的情况下,可以延迟合并,减少系统负担;而在高查询量的环境中,可以加快合并,以提高查询性能。
5. 使用 API 手动合并
-
可以通过
POST /index_name/_forcemergeAPI 来手动触发合并:
POST /my_index/_forcemerge?max_num_segments=1这个命令会将
my_index索引的段合并为最多一个段。注意,
max_num_segments是可选的参数,用于指定要保留的最大段数。
6. 合并的影响
- 查询性能的提高:合并后,查询通常会变得更高效,因为段数减少了,搜索时需要遍历的段也更少。
- 磁盘空间的释放:合并会去除已删除文档,因此可以减少索引的磁盘占用。
- 暂时的性能波动:在合并操作进行时,可能会对系统的 I/O 和 CPU 造成一定压力,导致短期的性能波动。因此,最好在系统负载较低时执行合并操作,或者在需要时配置合并的优先级。
总结来说,Elasticsearch 的合并操作主要目的是通过减少段的数量来优化查询性能和磁盘占用。它是一个自动化的过程,但也可以根据实际情况进行手动触发和配置调整。
相关文章:

es中段是怎么合并的
文章目录 1. 段合并的背景2. 合并的方式2.1TieredMergePolicy 的层次结构2.2 层次的基本规则2.3 如何理解层次(tier)2.4. 合并过程中的层次示例2.5. TieredMergePolicy 的优势2.6. 小结 3. 合并过程中的优化4. 合并的性能考虑5. 使用 API 手动合并6. 合并…...

5、可暂停的线程控制模型
一、需求 在做播放器的时候,很多的模块会创建一个线程,然后在这个线程上跑单独的功能,同时,需要对这个线程进行控制,比如暂停,继续等,如播放器的解码,解封装等,都需要对…...

sql优化--mysql隐式转换
sql隐式转换 在SQL中,隐式转换是数据库自动进行的类型转换,隐式转换可以帮助我们处理不同类型的数据。 比如,数据表的字段是字符串类型的,传入一个整型的数据,也能够运行sql。 sql隐式转换的弊端 sql隐式转换&…...

Scratch021(画笔)
画笔模块 可以这么理解,画笔模块是Scratch的拓展模块,用它可以完成很多的功能,非常有趣! 案例要求 点击绿旗运行程序,页面显示需要绘制的背景。 可以使用鼠标移动画笔角色,按照顺序点击连线,…...

Leetcode 3387. Maximize Amount After Two Days of Conversions
Leetcode 3387. Maximize Amount After Two Days of Conversions 1. 解题思路2. 代码实现 题目链接:3387. Maximize Amount After Two Days of Conversions 1. 解题思路 这一题思路上其实就是要分别求出day 1以及day 2中原始货币与其他各个货币之间的成交价&…...

机器视觉与OpenCV--01篇
计算机眼中的图像 像素 像素是图像的基本单位,每个像素存储着图像的颜色、亮度或者其他特征,一张图片就是由若干个像素组成的。 RGB 在计算机中,RGB三种颜色被称为RGB三通道,且每个通道的取值都是0到255之间。 计算机中图像的…...

简单的Java小项目
学生选课系统 在控制台输入输出信息: 在eclipse上面的超级简单文件结构: Main.java package experiment_4;import java.util.*; import java.io.*;public class Main {public static List<Course> courseList new ArrayList<>();publi…...

使用layui的table提示Could not parse as expression(踩坑记录)
踩坑记录 报错图如下 原因: 原来代码是下图这样 上下俩中括号都是连在一起的,可能导致解析问题 改成如下图这样 重新启动项目,运行正常!...

区块链共识机制详解
一.共识机制简介 在区块链的交流和学习中,「共识算法」是一个很频繁被提起的词汇,正是因为共识算法的存在,区块链的可信性才能被保证。 1.1 为什么需要共识机制? 所谓共识,就是多个人达成一致的意思。我们生活中充满…...
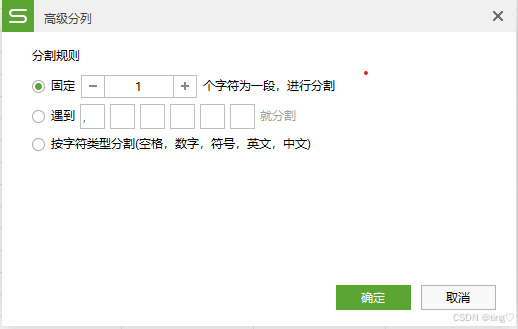
【Excel】单元格分列
目录 分列(新手友好) 1. 选中需要分列的单元格后,选择 【数据】选项卡下的【分列】功能。 2. 按照分列向导提示选择适合的分列方式。 3. 分好就是这个样子 智能分列(进阶) 高级分列 Tips: 新手推荐基…...

【含开题报告+文档+PPT+源码】基于微信小程序的旅游论坛系统的设计与实现
开题报告 近年来,随着互联网技术的迅猛发展,人们的生活方式、消费习惯以及信息交流方式都发生了深刻的变化。旅游业作为国民经济的重要组成部分,其信息化、网络化的发展趋势也日益明显。旅游论坛作为旅游信息交流和分享的重要平台࿰…...

微软 Phi-4:小型模型的推理能力大突破
在人工智能领域,语言模型的发展日新月异。微软作为行业的重要参与者,一直致力于推动语言模型技术的进步。近日,微软推出了最新的小型语言模型 Phi-4,这款模型以其卓越的复杂推理能力和在数学领域的出色表现,引起了广泛…...

操作系统课后习题2.2节
操作系统课后习题2.2节 第1题 CPU的效率指的是CPU的执行速度,这个是由CPU的设计和它的硬件来决定的,具体的调度算法是不能提高CPU的效率的; 第3题 互斥性: 指的是进程之间的同步互斥关系,进程是一个动态的过程&#…...
[小白系列]安装sentence-transformers
python环境为3.13.1执行 pip install sentence-transformers 总是报以下问题 ERROR: Cannot install sentence-transformers0.1.0, sentence-transformers0.2.0, sentence-transformers0.2.1, sentence-transformers0.2.2, sentence-transformers0.2.3, sentence-transformers…...

Python字符串format方法全面解析
在Python中,format方法是一种用于格式化字符串的强大工具。它允许你构建一个字符串,其中包含一些“占位符”,这些占位符将被format方法的参数替换。以下是对format方法用法的详细解释: 基本用法 format方法的基本语法如下&#…...

【Reading Notes】Favorite Articles from 2024
文章目录 1、January2、February3、March4、April5、May6、June7、July8、August9、September10、October11、November12、December 1、January 2、February 3、March Sora外部测试翻车了!3个视频都有Bug( 2024年03月01日) 不仔细看还真看不…...

Python爬虫之Scrapy框架基础入门
Scrapy 是一个用于Python的开源网络爬虫框架,它为编写网络爬虫来抓取网站数据并提取结构化信息提供了一种高效的方法。Scrapy可以用于各种目的的数据抓取,如数据挖掘、监控和自动化测试等。 【1】安装 pip install scrapy安装成功如下所示:…...

spring cloud contract mq测试
对于spring cloud contract的环境配置和部署,请看我之前的文章。 一 生产者测试 测试生产者是否发送出消息,并测试消息内容是否正确。 编写测试合同 测试基类(ContractTestBase)上面要添加下面注解 SpringBootTest AutoConfig…...

Axure原型设计技巧与经验分享
AxureRP作为一款强大的原型设计工具,凭借其丰富的交互设计能力和高保真度的模拟效果,赢得了众多UI/UX设计师、产品经理及开发人员的青睐。本文将分享一些Axure原型设计的实用技巧与设计经验,帮助读者提升工作效率,打造更加流畅、用…...

计算机网络之王道考研读书笔记-1
第 1 章 计算机网络体系结构 1.1 计算机网络概述 1.1.1 计算机网络概念 internet(互连网):泛指由多个计算机网络互连而成的计算机网络。这些网络之间可使用任意通信协议。 Internet(互联网或因特网):指当前全球最大的、开放的、由众多网络和路由器互连…...

类型转换:隐式、显式与类型提升
在Java开发中,数据类型转换是最基础也最容易被忽略的核心操作——从简单的变量赋值、数字运算,到复杂的方法传参、泛型适配、多态转型、序列化,几乎每一行代码都隐含着类型转换的逻辑。很多同学只停留在“会用”的层面:知道int转l…...

TI AM64x 5路原生千兆网口:工业物联网确定性网络与多核异构计算实战
1. 项目概述:为什么我们需要5路原生千兆网口?在工业现场摸爬滚打十几年,我见过太多因为网络接口“捉襟见肘”而导致的尴尬局面。想象一下,一个产线控制柜里,PLC、视觉系统、多台伺服驱动器、HMI触摸屏,还有…...

MATLAB图像处理实战:用strel函数玩转膨胀腐蚀,5分钟搞定车牌去噪
MATLAB车牌去噪实战:形态学操作中的结构元素艺术 车牌识别系统在智能交通、停车场管理等场景中应用广泛,但实际采集的车牌图像常因环境干扰出现噪声、污渍或字符粘连问题。形态学处理作为图像预处理的关键步骤,其效果高度依赖结构元素的选择与…...

测试工程师的沟通技巧:如何向开发工程师反馈bug
在软件研发的协作链条中,测试工程师与开发工程师的互动至关重要,而反馈bug则是两者沟通的核心场景之一。高效、专业的bug反馈,不仅能加速问题解决,提升产品质量,更能维护良好的团队协作氛围。对于软件测试从业者而言&a…...

免费开源视频编辑神器Avidemux:5分钟快速上手专业剪辑
免费开源视频编辑神器Avidemux:5分钟快速上手专业剪辑 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 如果你正在寻找一款简单易用、功能强大的免费开源视频编辑软件,那么A…...

bili2text终极指南:一键将B站视频转换为高质量文字稿的免费工具
bili2text终极指南:一键将B站视频转换为高质量文字稿的免费工具 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾经为了整理B站视频中的精…...

别再只用JSON了!聊聊Qt里QDataStream的二进制序列化优势与避坑指南
二进制序列化新选择:Qt中QDataStream的高效实践与深度解析 在Qt开发者的工具箱里,JSON和XML常被视为数据交换的默认选择,但当面对高性能、紧凑存储或跨版本兼容性需求时,二进制序列化方案往往能带来意想不到的优势。QDataStream作…...
)
别再只用BackgroundImage了!C# WinForm窗体背景图5种方法全解析(含PictureBox与资源文件实战)
别再只用BackgroundImage了!C# WinForm窗体背景图5种方法全解析 当我们需要为WinForm窗体添加背景图时,很多开发者会条件反射地使用BackgroundImage属性。这种习惯性选择虽然简单,但在实际项目中可能会遇到性能瓶颈、内存泄漏或适配问题。本文…...

2026年玉米膨化机市场:谁是真正的行业领航者?
面对快速发展的休闲食品市场,如何在竞争激烈的玉米膨化机市场里抢占先机?随着消费者对健康食品需求的高涨,五谷杂粮膨化食品逐渐成为市场上的一股热潮。本篇将深度解析2026年玉米膨化机行业的趋势、选购要点,并对比测评几个行业知…...

STM32图像识别实战:从传统CV到TinyML的边缘AI部署
1. 项目概述:当STM32遇上图像识别在嵌入式开发领域,STM32系列微控制器因其出色的性能、丰富的外设和极高的性价比,早已成为工程师和爱好者的“瑞士军刀”。从简单的LED闪烁到复杂的电机控制、通信协议栈,STM32几乎无所不能。但提到…...