第二部分:进阶主题 14 . 性能优化 --[MySQL轻松入门教程]
MySQL性能优化是一个广泛的话题,它涉及到数据库设计、查询语句的编写、索引的使用、服务器配置等多个方面。下面是一些常见的MySQL性能优化策略:
1. 数据库和表结构优化
下面是三个关于MySQL数据库和表结构优化的具体示例:
示例 1: 合理选择数据类型
场景: 假设你有一个用户表users,其中包含用户的ID、姓名、电子邮件地址、性别等信息。性别通常只有两个值(或者加上未知/其他),这时使用TINYINT或枚举ENUM('male', 'female', 'other')比使用VARCHAR更合适。
CREATE TABLE users (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,email VARCHAR(255) NOT NULL UNIQUE,gender ENUM('male', 'female', 'other') DEFAULT 'other',-- other columns...
);
优化点: 使用合适的最小化数据类型可以减少存储空间,提高I/O效率。
示例 2: 使用适当的索引
场景: 如果你的应用程序经常根据用户的电子邮件地址来查找用户记录,那么在email字段上创建一个唯一索引是合理的。
CREATE UNIQUE INDEX idx_email ON users (email);
优化点: 索引能够加速查询速度,特别是对于频繁搜索的列。这里使用了唯一索引,不仅加速了查找还确保了邮箱地址的唯一性。
示例 3: 分区表
场景: 对于一个日志记录表logs,假设它包含了大量按时间戳排序的日志条目,并且大部分查询都是针对最近的数据。你可以根据日期对表进行分区,这样可以快速定位到特定时间段内的日志,而不需要扫描整个表。
-- 创建日志记录表 `logs`
CREATE TABLE logs (-- 日志ID,自动递增主键,用于唯一标识每一条日志记录log_id INT AUTO_INCREMENT PRIMARY KEY,-- 日志消息内容,不允许为空message TEXT NOT NULL,-- 日志创建时间戳,记录日志的时间,不允许为空created_at DATETIME NOT NULL
)
-- 根据 `created_at` 字段的时间戳对表进行范围分区
PARTITION BY RANGE (UNIX_TIMESTAMP(created_at)) (-- 分区 p_2023 包含所有创建时间在 2024 年 1 月 1 日之前的日志记录PARTITION p_2023 VALUES LESS THAN (UNIX_TIMESTAMP('2024-01-01')),-- 分区 p_2024 包含所有创建时间在 2024 年 1 月 1 日至 2025 年 1 月 1 日之间的日志记录PARTITION p_2024 VALUES LESS THAN (UNIX_TIMESTAMP('2025-01-01')),-- 分区 p_future 包含所有创建时间在 2025 年 1 月 1 日之后的日志记录PARTITION p_future VALUES LESS THAN MAXVALUE
);
优化点: 分区可以帮助管理大型数据集,使得查询更加高效,尤其是在处理时间序列数据时。此外,删除旧的日志数据也变得更加简单,只需删除对应的分区即可。
这些示例展示了如何通过合理选择数据类型、添加索引以及分区策略来优化MySQL中的表结构。每个示例都针对性地解决了不同的性能问题,从而提高了系统的整体效率。
2. 索引优化
索引优化是提高MySQL查询性能的关键步骤之一。以下是三个具体的索引优化示例,涵盖了不同场景下的最佳实践:
示例 1: 使用复合索引来覆盖查询
场景: 假设有一个电子商务平台的订单表orders,其中包含用户ID(user_id)、订单状态(status)、订单日期(order_date)等字段。如果经常需要根据用户ID和订单状态来查询订单信息,那么可以创建一个复合索引来加速这类查询。
CREATE INDEX idx_user_status ON orders (user_id, status);
优化点: 复合索引可以同时利用多个列进行快速查找。当查询条件完全匹配索引的前缀时,MySQL可以直接从索引中获取数据,而不需要回表查询,这就是所谓的“覆盖索引”。
示例 2: 避免在频繁更新的列上创建索引
场景: 在同一个订单表orders中,假设订单状态(status)会随着订单处理过程不断变化。在这种情况下,不建议在这个列上创建索引,因为每次状态更新都会导致索引的重新组织,增加了写入成本。
优化点: 对于那些频繁更新或插入的列,应该谨慎创建索引,尤其是单列索引。这可以帮助减少不必要的索引维护开销,提升写操作的性能。
示例 3: 使用索引选择性来优化索引
场景: 考虑到用户登录系统时需要验证用户名和密码。如果用户名(username)具有较高的唯一性(即高选择性),则可以在该列上创建索引来加速登录验证过程。
CREATE UNIQUE INDEX idx_username ON users (username);
优化点: 索引的选择性是指索引列中不同值的数量与总行数的比例。选择性越高,索引的效果越好。因此,优先为那些具有高选择性的列创建索引,可以显著提高查询效率。对于低选择性的列(如性别、是否激活等),创建索引可能不会带来明显的性能提升,反而会增加存储和维护成本。
这三个示例展示了如何通过合理设计和使用索引来优化MySQL数据库的性能。每个例子都针对不同的问题提出了有效的解决方案,从而提高了系统的响应速度和资源利用率。
3. 查询优化
优化MySQL查询可以显著提升数据库的性能,以下是三个具体的查询优化示例,涵盖不同场景下的最佳实践:
示例 1: 使用EXPLAIN分析查询计划
场景: 假设你有一个产品表products,并且你想查找特定类别的所有产品。你可以使用EXPLAIN来查看查询执行计划,以确保你的查询是高效的。
-- 分析查询计划
EXPLAIN SELECT * FROM products WHERE category_id = 5;-- 优化后的查询(假设我们只关心某些列)
EXPLAIN SELECT id, name, price FROM products WHERE category_id = 5;
优化点: EXPLAIN命令可以帮助你理解MySQL如何执行查询,包括它选择了哪些索引、是否进行了全表扫描等。通过检查EXPLAIN输出,你可以发现潜在的问题,并进行相应的调整,比如选择更合适的索引或减少返回的列数。
示例 2: 避免不必要的SELECT *
场景: 在一个包含用户信息的表users中,如果你只需要获取用户的ID和姓名,而不是整个记录,那么应该明确列出所需的字段,而不是使用SELECT *。
-- 不推荐:检索所有字段,可能导致不必要的I/O操作
SELECT * FROM users WHERE status = 'active';-- 推荐:只检索需要的字段
SELECT id, name FROM users WHERE status = 'active';
优化点: 只请求你需要的数据可以减少服务器的处理负担和网络传输量,尤其是在表结构复杂或者数据量大的情况下。这不仅提高了查询速度,还减少了内存和CPU资源的消耗。
示例 3: 使用适当的连接类型(JOIN)
场景: 假设你有两个表——订单表orders和客户表customers,并且你想获取每个订单对应的客户信息。使用内连接(INNER JOIN)通常是正确的选择,因为它只返回两个表中都存在的匹配行。
-- 不推荐:使用笛卡尔积(CROSS JOIN),可能导致大量无用的数据组合
SELECT o.id, c.name
FROM orders o, customers c
WHERE o.customer_id = c.id;-- 推荐:使用内连接(INNER JOIN),确保只获取有效的匹配项
SELECT o.id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.id;
优化点: 选择正确的连接类型对于查询性能至关重要。不适当的连接可能会导致大量的额外计算和不必要的数据检索。内连接通常是最有效的方式,除非有特殊需求,否则应避免使用笛卡尔积或其他类型的外连接(如LEFT JOIN、RIGHT JOIN),除非确实需要那些未匹配的行。
这三个示例展示了如何通过分析查询计划、限制查询范围以及选择正确的连接方式来优化MySQL查询。每个例子都针对常见的性能瓶颈提供了实用的解决方案,帮助提高查询效率和系统响应速度。
4. 配置参数调整
调整MySQL的配置参数是优化数据库性能的重要步骤之一。以下是三个具体的配置参数调整示例,它们分别针对不同的优化目标:
示例 1: 调整InnoDB缓冲池大小 (innodb_buffer_pool_size)
场景: InnoDB缓冲池是MySQL用于缓存表数据和索引的最大内存区域。如果你的应用程序主要是读取密集型,并且服务器有足够的RAM,增加缓冲池的大小可以显著提高查询性能。
# my.cnf 或 my.ini 配置文件中
[mysqld]
innodb_buffer_pool_size = 8G # 根据服务器可用内存调整,建议设置为物理内存的50%-75%
优化点: 较大的缓冲池意味着更多的数据可以直接从内存中读取,减少了磁盘I/O操作,从而提高了查询速度。不过,要确保不要将缓冲池设置得过大以至于耗尽系统内存,导致操作系统使用交换空间,反而会降低性能。
示例 2: 设置最大连接数 (max_connections)
场景: 如果你的应用程序有大量的并发请求,你可能需要增加MySQL允许的最大连接数。但是,过高的连接数可能会导致资源争用问题,因此需要找到一个平衡点。
# my.cnf 或 my.ini 配置文件中
[mysqld]
max_connections = 500 # 根据服务器硬件能力和应用需求调整
优化点: 合理设置最大连接数可以帮助防止过多的并发连接导致服务器资源耗尽。同时,结合使用连接池等技术,可以在不影响性能的情况下支持更多用户。
示例 3: 启用慢查询日志 (slow_query_log 和 long_query_time)
场景: 慢查询日志记录了执行时间超过指定阈值的所有查询,这对于识别低效的查询非常有用。通过分析这些日志,你可以找出并优化那些影响性能的查询。
# my.cnf 或 my.ini 配置文件中
[mysqld]
slow_query_log = 1 # 启用慢查询日志
slow_query_log_file = /var/log/mysql/mysql-slow.log # 日志文件路径
long_query_time = 2 # 设置慢查询的时间阈值(秒),可以根据需要调整
log_queries_not_using_indexes = 1 # 记录未使用索引的查询,有助于发现潜在的优化机会
优化点: 慢查询日志是诊断性能瓶颈的有效工具。定期检查和分析这些日志可以帮助你及时发现和解决性能问题。特别是对于大型或复杂的查询,即使它们偶尔出现,也可能对整体性能产生重大影响。
这三个示例展示了如何通过调整关键配置参数来优化MySQL的性能。每个例子都旨在解决特定的性能挑战,帮助提高系统的稳定性和响应速度。在调整任何配置之前,请务必先备份现有的配置文件,并在非生产环境中进行测试以确保更改不会引起意外的问题。
5. 硬件和操作系统优化
硬件和操作系统的优化对于MySQL数据库的性能有着至关重要的影响。以下是三个具体的优化示例,涵盖硬件选择和操作系统配置两个方面:
示例 1: 使用高性能存储设备(SSD)
场景: 对于需要频繁读写的数据库应用,传统的HDD硬盘可能成为性能瓶颈。通过升级到固态硬盘(SSD),可以显著减少I/O延迟,提高数据读写速度。
优化点: SSD拥有更快的数据访问速度和更低的寻道时间,这使得它特别适合用于存放MySQL的数据文件、日志文件以及临时表空间。如果预算允许,考虑使用NVMe SSD,其性能比普通SATA SSD还要好得多。
# 确保MySQL的数据目录位于SSD上
sudo mkdir -p /mnt/ssd/mysql
sudo chown mysql:mysql /mnt/ssd/mysql
# 在my.cnf或my.ini中更新datadir设置
[mysqld]
datadir=/mnt/ssd/mysql
示例 2: 调整Linux内核参数以优化网络性能
场景: 如果你的应用程序依赖于高吞吐量的网络连接,比如分布式数据库集群或者远程客户端访问,那么调整Linux内核参数可以帮助提升网络性能。
优化点: 通过调整TCP缓冲区大小、启用TCP快速打开等功能,可以改善网络传输效率,降低延迟。下面是一些常见的网络相关参数调整:
# 编辑/etc/sysctl.conf文件,添加或修改以下内容
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.tcp_fastopen = 3
net.ipv4.tcp_tw_reuse = 1# 应用更改
sudo sysctl -p
示例 3: 配置操作系统调度器和进程优先级
场景: 在多任务环境中,MySQL服务器可能会与其他服务竞争CPU资源。为了确保MySQL能够获得足够的处理能力,可以调整操作系统调度器策略,并设置MySQL进程的优先级。
优化点: 使用实时调度器(如SCHED_FIFO)或提高MySQL进程的nice值可以让它在系统负载较高的时候仍然保持良好的响应性。此外,还可以为MySQL分配专门的CPU核心,避免其他进程干扰。
# 设置mysqld进程的调度策略和优先级
echo "mysql soft rtprio 99" | sudo tee /etc/security/limits.d/mysql.conf
echo "mysql hard rtprio 99" | sudo tee -a /etc/security/limits.d/mysql.conf# 或者直接使用chrt命令调整当前运行的mysqld进程
sudo chrt -r -p 99 $(pgrep mysqld)# 为MySQL指定专用CPU核心(例如,使用cgroups)
sudo cgcreate -g cpu:/mysql
sudo cgset -r cpu.shares=1024 mysql
sudo cgclassify -g cpu:mysql $(pgrep mysqld)
这三个示例展示了如何通过选择合适的硬件以及调整操作系统配置来优化MySQL数据库的性能。每个例子都针对特定的性能挑战提供了有效的解决方案,帮助提高了系统的稳定性和响应速度。在实施任何更改之前,请确保了解它们的影响,并在非生产环境中充分测试。
6. 应用程序级别的优化
在应用程序级别进行MySQL优化可以显著提高数据库的性能和响应速度。以下是三个具体的应用程序级别的优化示例,涵盖不同的优化策略:
示例 1: 批量处理数据
场景: 当你需要插入或更新大量数据时,逐行处理会导致大量的网络往返和事务开销。
优化点: 使用批量插入或更新操作可以减少与数据库服务器之间的交互次数,从而大大提高效率。
-- 单次插入多条记录
INSERT INTO users (name, email) VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com'),
('Charlie', 'charlie@example.com');-- 或者使用LOAD DATA INFILE快速导入大量数据
LOAD DATA INFILE '/path/to/file.csv'
INTO TABLE users
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
额外提示: 如果可能的话,考虑在非高峰时段执行大批量的数据加载,以减少对在线服务的影响。
示例 2: 合理管理事务
场景: 在一个电子商务系统中,购买商品的操作通常需要涉及多个表(如订单表、库存表等)的更新。
优化点: 应该将这些相关的更新封装在一个事务中,确保所有操作要么全部成功,要么全部失败,同时尽可能缩短持有锁的时间。
START TRANSACTION;-- 更新库存
UPDATE products SET stock = stock - 1 WHERE product_id = 123;
-- 创建订单
INSERT INTO orders (user_id, product_id, quantity) VALUES (456, 123, 1);COMMIT;
额外提示: 对于只读查询,使用BEGIN...READ ONLY来声明事务为只读模式,这可以帮助优化器做出更好的选择,并且对于某些存储引擎(如InnoDB),它还可以提供额外的性能优势。
示例 3: 实现读写分离
场景: 对于那些读操作远多于写操作的应用程序(如新闻网站、博客平台等),可以通过主从复制实现读写分离,减轻主库的压力。
优化点: 配置一主多从架构,所有的写操作都发生在主库上,而大部分的读取请求则分发到从库中执行。这样不仅可以分散负载,还能提高系统的可用性和容错能力。
// 假设使用PHP作为编程语言
function getConnection($read_only = false) {if ($read_only) {// 返回从库连接return new PDO("mysql:host=slave_host;dbname=example", "user", "password");} else {// 返回主库连接return new PDO("mysql:host=master_host;dbname=example", "user", "password");}
}// 使用例子
$pdo = getConnection(true); // 获取从库连接用于读操作
$stmt = $pdo->query("SELECT * FROM articles LIMIT 10");// 写操作仍然使用主库
$pdo = getConnection(); // 默认获取主库连接
$pdo->exec("INSERT INTO comments (article_id, content) VALUES (1, 'Great article!')");
这三个示例展示了如何通过改进应用程序逻辑来优化MySQL数据库的性能。每个例子都针对特定的应用场景提出了有效的解决方案,帮助提高了系统的响应速度和资源利用率。在实际应用中,应该根据具体情况灵活运用这些策略,并结合其他层面的优化措施,以达到最佳效果。
以上只是MySQL性能优化的一部分内容,实际优化还需要结合具体的应用场景和需求来进行。如果你有特定的问题或者想深入了解某个方面的优化,请告诉我!
相关文章:

第二部分:进阶主题 14 . 性能优化 --[MySQL轻松入门教程]
MySQL性能优化是一个广泛的话题,它涉及到数据库设计、查询语句的编写、索引的使用、服务器配置等多个方面。下面是一些常见的MySQL性能优化策略: 1. 数据库和表结构优化 下面是三个关于MySQL数据库和表结构优化的具体示例: 示例 1: 合理选…...
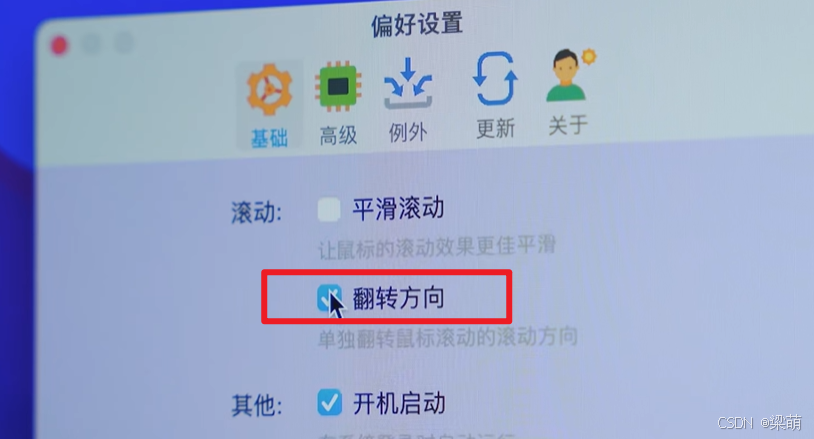
Mac电脑设置鼠标的滚轮方向
Mac电脑使用鼠标时,上下滚动,方向与Windows相反,如果要保持与Windows一致,则下载MOS这个软件,然后在MOS中进行配置,就可以让鼠标操作方式与Windows一致。 软件下载地址: https://mos.caldis.me…...

【LDAP】LDAP概念和原理介绍
目录 一、前言 二、什么是LDAP? 2.1 什么是目录服务? 2.2 LDAP的介绍 2.3 为什么要使用LDAP 三、LDAP的主要产品线 四、LDAP的基本模型 4.1 目录树概念 4.2 LDAP常用关键字列表 4.3 objectClass介绍 五、JXplorer工具使用 一、前言 对于许多的…...

Android系统(android app和系统架构)
文章目录 AndroidAndroid Apps四大组件 Android系统Platform API之下:一个微笑内核adb(Android Debug Bridge) Android包管理机制Android的Intent机制参考 Android LinuxFrameworkJVM 在Linux/Java上做了个二次开发?并不完全是:Android定义…...

Android HandlerThread、Looper、MessageQueue 源码分析
Android HandlerThread、Looper、MessageQueue 源码分析 简介 在 Android 开发中,大家应该对 HandlerThread 有一定了解。顾名思义,HandlerThread 是 Thread 的一个子类。与普通的 Thread 不同,Thread 通常一次只能执行一个后台任务&#x…...

HTML知识点详解教程
文章目录 HTML知识点详解教程1. HTML基本语法2. HTML标签详解2.1 分区标签 <div>2.2 标题标签 <h1> ~ <h6>2.3 段落标签 <p>2.4 图片标签 <img>2.5 列表标签 <ul> 和 <ol>无序列表 <ul>有序列表 <ol> 2.6 超链接标签 &l…...

[数据结构#1] 并查集 | FindRoot | Union | 优化 | 应用
目录 1. 并查集原理 问题背景 名称与编号映射 数据结构设计 2. 并查集基本操作 (1) 初始化 (2) 查询根节点 (FindRoot) (3) 合并集合 (Union) (4) 集合操作总结 并查集优化 (1) 路径压缩 (2) 按秩合并 3. 并查集的应用 (1) 统计省份数量 (2) 判断等式方程是否成…...

科研绘图系列:R语言绘制网络图和密度分布图(network density plot)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载图1图2图3图4图5图6图7图8系统信息参考介绍 R语言绘制网络图和密度分布图(network & density plot) 加载R包 library(magrittr) library(dplyr) library(…...

Linux中输入和输出基本过程
1.文件内核级缓冲区 前面在如何理解Linux一切皆文件的特点中提到为了保证在Linux中所有进程访问文件时的方式趋近相 同,在f ile 结构体中存在一个 files_operations 结构体指针,对应的结构体保存所有文件操作的函 数指针(这个结构体也被称为…...

使用 acme.sh 签发和自动续期 ssl https 证书
acme.sh 是一个热度非常高的签发和自动续期 https 证书的工具,虽然官网上提供了充分的操作说明,但是不够简洁,本文以在 nginx 中签发和配置http 为例,列出必要的几个简单步骤。 安装 因为网络原因,github 大部分人是…...

spring重点面试题总结
bean的生命周期 在 Spring 中,BeanDefinition、Bean 实例化、依赖注入、Aware 接口的处理、以及 BeanPostProcessor 的前置和后置处理等,都是 Spring 容器管理 Bean 生命周期的关键部分。下面我将详细解释这些过程。 1. 通过 BeanDefinition 获取 Bean…...

新的一章:codegeex
三层结构的优点:可扩展性,可复用性...

游戏引擎学习第50天
仓库: https://gitee.com/mrxiao_com/2d_game Minkowski 这个算法有点懵逼 回顾 基本上,现在我们所处的阶段是,回顾最初的代码,我们正在讨论我们希望在引擎中实现的所有功能。我们正在做的版本是初步的、粗略的版本,涵盖我们认…...

快速理解类的加载过程
当程序主动使用某个类时,如果该类还未加载到内存中,则系统会通过如下三个步骤来对该类进行初始化: 1.加载:将class文件字节码内容加载到内存中,并将这些静态数据转换成方法区的运行时数据结构,然后生成一个…...

医院跌倒检测识别 使用YOLO,COCO ,VOC格式对4806张原始图片进行标注,可识别病人跌倒,病人的危险行为,病床等场景,预测准确率可达96.7%
医院跌倒检测识别 使用YOLO,COCO ,VOC格式对4806张原始图片进行标注,可识别病人跌倒,病人的危险行为,病床等场景,预测准确率可达96.7% 数据集分割 4806总图像数 训练组70% 3364图片 有效集20&#…...

[Unity Shader] 【游戏开发】【图形渲染】Unity Shader的种类2-顶点/片元着色器与固定函数着色器的选择与应用
Unity 提供了不同种类的 Shader,每种 Shader 有其独特的优势和适用场景。在所有类型的 Shader 中,顶点/片元着色器(Vertex/Fragment Shader)与固定函数着色器(Fixed Function Shader)是两种重要的着色器类型。尽管它们具有不同的编写方式和用途,理解其差异与应用场景,对…...

浏览器端的 js 包括哪几个部分
一、核心语言部分 1. 变量与数据类型 变量用于存储数据,在 JavaScript 中有多种数据类型,如基本数据类型(字符串、数字、布尔值、undefined、null)和引用数据类型(对象、数组、函数)。 let name "…...

GoogLeNet网络:深度学习领域的创新之作
目录 编辑 引言 GoogLeNet的核心创新:Inception模块 Inception模块的工作原理 1x1卷积:降维与减少计算量 1x1卷积的优势 深度分离卷积:计算效率的提升 深度分离卷积的实现 全局平均池化:简化网络结构 全局平均池化的作…...

深入C语言文件操作:从库函数到系统调用
引言 文件操作是编程中不可或缺的一部分,尤其在C语言中,文件操作不仅是处理数据的基本手段,也是连接程序与外部世界的重要桥梁。C语言提供了丰富的库函数来处理文件,如 fopen、fclose、fread、fwrite 等。然而,这些库…...

Java序列化
Java序列化 简单来说: 序列化是将对象的状态信息转换为可以存储或传输的形式(如字节序列)的过程。在 Java 中,通过序列化可以把一个对象保存到文件、通过网络传输到其他地方或者存储到数据库等。最直接的原因就是某些场景下需要…...

iPaaS厂商:五家主流集成平台的技术与市场观察
在数字化转型的深水区,企业级集成平台即服务(iPaaS)正在成为IT架构的“神经系统”。国内外众多厂商纷纷布局,形成了从全域智能集成到轻量SaaS连接的多极化格局。本文基于公开资料,对五家具有代表性的iPaaS厂商及其核心…...
)
告别轮询!用STM32CubeMX和DMA实现ADC多通道‘无感’采集与串口打印(附完整工程)
告别轮询!STM32CubeMX与DMA实现ADC多通道无感采集实战指南 在嵌入式开发中,数据采集系统的效率往往决定了整个应用的性能上限。传统轮询方式不仅消耗大量CPU资源,还会引入不可预测的延迟。想象一下,当你需要同时监测多个环境传感器…...

免费本地语音识别的终极解决方案:3步实现完全离线实时语音转文字
免费本地语音识别的终极解决方案:3步实现完全离线实时语音转文字 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 在数字化办公和在线学习日益普及的今天,你是否还在为云端语音识别服务的隐私…...

Vivado编译加速:Jobs与Threads参数配置实战指南
1. 项目概述:从一次编译卡顿说起那天下午,我正在赶一个FPGA项目的最后集成,Vivado里点下“Run Implementation”,进度条就像被冻住了一样,半天不动。电脑风扇倒是转得挺欢,可CPU占用率看着也就50%上下。我第…...

手把手教你用MATLAB图形放大法找方程根:从画图到定位,解决迭代法初值难题
手把手教你用MATLAB图形放大法找方程根:从画图到定位,解决迭代法初值难题 在数值计算的世界里,寻找方程的根就像在黑暗森林中探险——没有地图的指引,盲目选择起点可能导致算法陷入无限循环或收敛到错误解。而MATLAB的图形放大法&…...

RTOS如何通过确定性调度与内存管理增强嵌入式系统安全可靠性
1. 项目概述:为什么我们需要关注实时操作系统的安全与可靠?在嵌入式、工业控制、汽车电子乃至航空航天这些领域里,系统一旦“死机”或“反应迟钝”,后果往往不是重启一下那么简单。轻则产线停摆、设备损坏,重则可能危及…...

LabVIEW TCP通讯实战:从零搭建一个工业数据采集服务器
1. LabVIEW TCP通讯在工业数据采集中的应用价值 工业现场的数据采集系统对通讯稳定性有着近乎苛刻的要求。记得我第一次参与某汽车生产线改造项目时,产线上的PLC和传感器每分钟要上传近万条数据,传统的串口通讯根本吃不消。当时团队尝试了多种方案&#…...

AI率总超标?2026年AI论文平台排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重总不通过?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!Ἴ…...

Logstalgia高级配置技巧:自定义颜色、分组和过滤规则
Logstalgia高级配置技巧:自定义颜色、分组和过滤规则 【免费下载链接】Logstalgia replay or stream website access logs as a retro arcade game 项目地址: https://gitcode.com/gh_mirrors/lo/Logstalgia Logstalgia是一款将网站访问日志以复古街机游戏形…...

深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱
深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱 【免费下载链接】IDR Interactive Delphi Reconstructor 项目地址: https://gitcode.com/gh_mirrors/id/IDR 你是否曾经面对一个Delphi编译的程序,却无法理解它的内部逻辑?或者需要…...