【机器学习算法】——决策树之集成学习:Bagging、Adaboost、Xgboost、RandomForest、XGBoost
集成学习
**集成学习(Ensemble learning)**是机器学习中近年来的一大热门领域。其中的集成方法是用多种学习方法的组合来获取比原方法更优的结果。
使用于组合的算法是弱学习算法,即分类正确率仅比随机猜测略高的学习算法,但是组合之后的效果仍可能高于强学习算法,即集成之后的算法准确率和效率都很高。
三个臭皮匠,赛过诸葛亮!!!以弱搏强,就是集成学习!

主要方法包括:
- Bagging
- Boosting
- Stacking
Stacking方法(知识蒸馏)
==Stacking方法(知识蒸馏)==是指训练一个模型用于组合其他各个模型。
- 先训练多个不同的模型,然后把训练得到的各个模型的输出作为输入来训练一个模型,以得到一个最终的输出。
- 原理:将多个不同模型的预测结果作为新的特征,输入到一个或多个元模型(meta-learner)中进行训练。

装袋法(Bagging)
装袋法(Bagging)又称为Bootstrap Aggregating, 是通过组合多个训练集的分类结果来提升分类效果
原理:对原始数据集进行多次有放回的抽样(bootstrap sampling),生成多个不同的训练数据集。
装袋法由于多次采样,每个样本被选中的概率相同,因此噪声数据的影响下降,所以装袋法太容易受到过拟合的影响。
【[数据挖掘Python] 26 集成学习 1 bagging算法 BaggingClassifier 个人银行贷款数据】
Bagging算法就是用多个弱分类器(CART)对划分的不同数据集进行分类,对于弱分类器的结果进行投票或者加权得到最终的结果。
Bagging对鸢尾花数据集进行分类
鸢尾花数据集是4个类别。
- 导入数据集
- 对数据集进行划分:·
KFold函数进行K折交叉验证 - 创建CART决策树:
cart = DecisionTreeClassifier(criterion='gini', max_depth=3)
cart_result = cart.fit(X, Y)# 训练决策树模型
- 利用CART模型作为基决策器生产Bagging模型:
可以设置基决策器的数量n_estimators,但不是越多越好哦!
model = BaggingClassifier(estimator=cart, n_estimators=100, random_state=seed)
result = cross_val_score(model, X, Y, cv=kfold)
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets# 1.获取数据
iris = datasets.load_iris()
X = iris.data
Y = iris.target
seed = 42# 创建K折交叉验证,设置分割数为10,打乱数据,设置随机种子
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)# 2.构建模型
# 创建决cart模型基础模型,设置使用基尼系数作为分裂标准,树的最大深度为3
cart = DecisionTreeClassifier(criterion='gini', max_depth=3)
cart_result = cart.fit(X, Y)# 训练决策树模型result = cross_val_score(cart_result, X, Y, cv=kfold)# 使用交叉验证计算决策树模型的分数
print("CART树结果:", result.mean())
#————————————————————————————————————————————————————————————————————————————————
# 创建bagging分类器,设置基础模型为cart,设置cart分类器数量为100,设置随机种子
model = BaggingClassifier(estimator=cart, n_estimators=100, random_state=seed)
result = cross_val_score(model, X, Y, cv=kfold)
print("装袋法提升后结果:", result.mean())
结果:
CART树结果: 0.9466666666666667
装袋法提升后结果: 0.9600000000000002
提升法:Boosting
原理
提升法(Boosting)与装袋法(Bagging)相比:每次的训练样本均为同一组,并且引入了权重的概念,给每个单独的训练样本都会分配个相同的初始权重。

-
从训练集用初始权重训练出一个弱学习器1,
-
根据弱学习的学习误差率表现来更新训练样本的权重:
使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的羽学习器2中得到更多的重视。 -
然后基于调整权重后的训练集来训练弱学习器2.,
-
如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
Adaboost(Adaptive Boosting)是一种自适应增强算法,它集成多个弱决策器进行决策。Adaboost解决二分类问题,且二分类的标签为{-1,1}。
注:一定是{-1,1},不能是{0,1}
它的训练过程是通过不断添加新的弱决策器,使损失函数继续下降,直到添加决策器已无效,最终将所有决策器集成一个整体进行决策。
理论上Adaboost适用于多种决策器,但实际中基本都是以决策树作为决策器
个体学习器之间存在强依赖关系、必须串行生成的序列化方法。
- 【提高】那些在前一轮被弱分类器【分错】的样本的权值
- 【减小】那些在前一轮被弱分类器【分对】的样本的权值
- 【加法模型】将弱分类器进行【线性组合】
Adaboost
是Boosting算法中最典型的一个算法!!!
【【五分钟机器学习】Adaboost:前人栽树后人乘凉】
直接上代码:
Adaboost对乳腺癌数据集进行分类(良性、恶心)
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasetsdataset_all = datasets.load_iris()#获取乳腺癌数据集
X = dataset_all.data
Y = dataset_all.targetseed = 42
kfold = KFold(n_splits=10, shuffle=True,random_state=seed)#10折交叉验证
cart = DecisionTreeClassifier(criterion='gini',max_depth=3)#构建决策树分类器,使用基尼系数(Gini)作为分裂的准则,并且设置树的最大深度为3
dtree = cart.fit(X, Y)#训练
result = cross_val_score(dtree, X, Y, cv=kfold)#交叉验证分数
print("决策树结果:",result.mean())model = AdaBoostClassifier(estimator=cart, n_estimators=100,random_state=seed)#创建AdaBoost分类器,使用决策树作为基学习器,弱学习器数量为100
result = cross_val_score(model, X, Y, cv=kfold)#交叉验证分数
print("提升法改进结果:",result.mean())
决策树结果: 0.92969924812
提升法改进结果: 0.970112781955
随机森林(RandomForest)
原理
随机森林与装袋法采取相同的样本抽取方式。
- 装袋法中的决策树每次从所有属性中选取一个最优的属性(gini)作为其分支属性,
- 而随机森林算法每次从所有属性中随机抽取𝑡个属性,然后从这𝑡个属性中选取一个最优的属性作为其分支属性,
- 这样就使得整个模型的随机性更强,从而使模型的泛化能力更强。
- 随机森林算法使用的弱分类决策树通常为CART算法。
- 【【五分钟机器学习】随机森林(RandomForest):看我以弱搏强】
代码实现
随机森林对鸢尾花数据进行分类,输出每个特征数据的重要性。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)#测试级比例是0.3,训练集比例是0.7.
# #训练集的特征X_train和训练集的标签y_train进行训练;测试集的特征X_test和测试集的标签y_test进行预测与评估# 创建随机森林分类器实例
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)#默认基分类器(弱分类器)是CART模型,CART模型数量是100个。
# 训练模型
rf_classifier.fit(X_train, y_train)#用划分的训练集数据(包括X_train, y_train)进行训练
# 预测测试集结果
y_pred = rf_classifier.predict(X_test)#用划分的测试集数据进行测试,但是预测predict只需要X_test(测试集的特征数据),预测结果为测试集的y_pred
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)#计算测试集的预测值y_pred和测试集的标签y_test的准确率accuracy
print(f"模型准确率: {accuracy:.2f}")# 输出特征重要性
feature_importances = rf_classifier.feature_importances_
print("特征重要性:")
for name, importance in zip(iris.feature_names, feature_importances):print(f"{name}: {importance:.4f}")
模型准确率: 100.00%
特征重要性:
sepal length (cm): 0.1081
sepal width (cm): 0.0304
petal length (cm): 0.4400
petal width (cm): 0.4215
Xgboost
GBDT
- 梯度提升决策树算法是利用梯度下降的思想,使用损失函数的负梯度在当前模型的值,作为提升树中残差的近似值,以此来拟合回归决策树。
- GBDT中的树都是回归树,不是分类树。
- GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。
GBDT
XGBoost
XGBoost
XGBoost可以用于:
- 分类
- 回归
- 异常检测
XGBoost安装:
pip install xgboost -i https://pypi.tuna.tsinghua.edu.cn/simple
XGBRegressor
import xgboost as xgb
import numpy as np
from sklearn.linear_model import LinearRegression
# 数据准备
X = [[1],[2],[3]]
y = [2, 4, 6]
# 构建XGBRegressor模型
model = xgb.XGBRegressor(n_estimators=1)# 训练模型
model.fit(X, y)
# 预测
X_predict = [[4]] # 修正预测数据的格式y_predict = model.predict(X_predict)
print(f"{X_predict}XGBoost预测y值为: {y_predict}")
#____________________________________________
model1 = LinearRegression()
#继续写线性回归预测X_predict
model1.fit(X,y)
y_predict = model1.predict(X_predict)
print(f"{X_predict}LinearRegression预测y值为: {y_predict}")
[[4]]XGBoost预测y值为: [4.3]
[[4]]LinearRegression预测y值为: [8.]
XGBoost预测误差很大!!!
因为XGBoost 是一个强大的非线性模型,更适合处理复杂的非线性关系。
而这个数据明显是简单的线性模型,更适合用LinearRegression!
XGBClassifier
用XGBoost对UCI蘑菇数据集进行分类:
UCI蘑菇数据集Kaggle下载
- 类别信息:可食用=e,有毒=p
- 帽形:钟形=b,圆锥形=c,凸面=x,平面=f,结节=k,凹陷=s
- 帽表面:纤维=f,凹槽=g,鳞片=y,光滑=s
- 帽子颜色:棕色=n,浅黄色=b,肉桂色=c,灰色=g,绿色=r,粉红色=p,紫色=u,红色=e,白色=w,黄色=y
瘀伤:瘀伤=t,否=f
气味:杏仁=a,八角=l,杂酚油=c,鱼腥味=y,恶臭=f,霉味=m,无=n,辛辣=p,辛辣=s
…
在写代码的时候需要将数据集进行编码转化为数字
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
import xgboost as xgb
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import AdaBoostClassifier
# 加载数据集
data = pd.read_csv('mushrooms.csv')#相对路径:mushrooms.csv# 对分类数据进行编码:值由字母变成数字
label_encoder = LabelEncoder()
for column in data.columns:data[column] = label_encoder.fit_transform(data[column])print(data.head())# 分割数据集
X = data.drop('class', axis=1)
y = data['class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化Xgboost模型
model = xgb.XGBClassifier()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
print(y_pred)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'模型准确率:{accuracy*100}%')#_________________________________________________
# LogisticRegression、AdaBoostClassifier也可以实现二分类哦
# model1 = LogisticRegression()
# model2 = AdaBoostClassifier()
class cap-shape cap-surface … spore-print-color population habitat
0 1 5 2 … 2 3 5
1 0 5 2 … 3 2 1
2 0 0 2 … 3 2 3
3 1 5 3 … 2 3 5
4 0 5 2 … 3 0 1
[5 rows x 23 columns]
[0 1 1 … 1 1 1]
模型准确率:100.0%
Process finished with exit code 0
相关文章:
【机器学习算法】——决策树之集成学习:Bagging、Adaboost、Xgboost、RandomForest、XGBoost
集成学习 **集成学习(Ensemble learning)**是机器学习中近年来的一大热门领域。其中的集成方法是用多种学习方法的组合来获取比原方法更优的结果。 使用于组合的算法是弱学习算法,即分类正确率仅比随机猜测略高的学习算法,但是组合之后的效果仍可能高于…...

JVM运行时数据区内部结构
VM内部结构 对于jvm来说他的内部结构主要分成三个部分,分别是类加载阶段,运行时数据区,以及垃圾回收区域,类加载我们放到之后来总结,今天先复习一下类运行区域 首先这个区域主要是分成如下几个部分 下面举个例子来解释…...

Navicat for MySQL 查主键、表字段类型、索引
针对Navicat 版本11 ,不同版本查询方式可能不同 1、主键查询 (重点找DDL!!!) 方法(1) :右键 - 对象信息 - 选择要查的表 - DDL - PRIMARY KEY 方法(2&…...
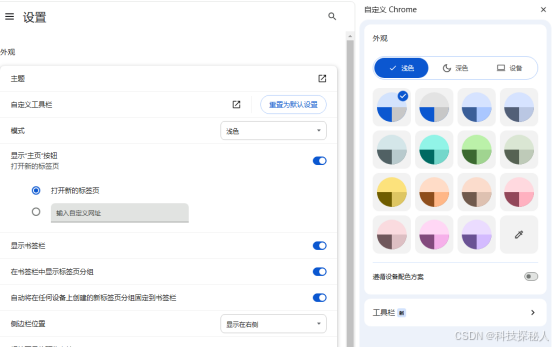
如何在谷歌浏览器中实现自定义主题
在数字化时代,个性化设置已成为提升用户体验的重要一环。对于广泛使用的谷歌浏览器而言,改变默认的浏览器主题不仅能够美化界面,还能在一定程度上提升使用效率和愉悦感。本文将详细介绍如何在谷歌浏览器中实现自定义主题,包括从官…...

visual studio 2022 c++使用教程
介绍 c开发windows一般都是visual studio,linux一般是vscode,但vscode调试c不方便,所以很多情况都是2套代码,在windows上用vs开发方便,在转到linux。 安装 1、官网下载vs2022企业版–选择桌面开发–安装位置–安装–…...

曝光三要素
一光圈 光圈越大,数值越小,画面越亮,背景越模糊 光圈越小,数值越大,画面越暗,背景越清晰 二 快门 快门最主要的作用是控制曝光时间的长短 快门速度的单位是秒,一般用 1秒,1/8秒&am…...

01-2 :PyCharm安装配置教程(图文结合-超详细)
一、PyCharm安装 PyCharm集成开发工具(IDE),是当下全球Python开发者,使用最频繁的工具软件。 绝大多数的Python程序,都是在PyCharm工具内完成的开发。 本篇文章基于PyCharm软件工具进行描述,教你如何安装…...

类OCSP靶场-Kioptrix系列-Kioptrix Level 1
一、前情提要 二、实战打靶 1. 信息收集 1.1. 主机发现 1.2. 端口扫描 1.3 目录爆破 1.4. 敏感信息 2.根据服务搜索漏洞 2.1. 搜索exp 2.2. 编译exp 2.3. 查看exp使用方法,并利用 3. 提权 二、第二种方法 一、前情提要 Kioptrix Level是免费靶场&#x…...

Maven插件打包发布远程Docker镜像
dockerfile-maven-plugin插件的介绍 dockerfile-maven-plugin目前这款插件非常成熟,它集成了Maven和Docker,该插件的官方文档地址如下: 地址:https://github.com/spotify/dockerfile-maven 其他说明: dockerfile是用…...

VisualStudio vsix插件自动加载
本文介绍如何在Visual Studio扩展中实现PackageRegistration,包括设置UseManagedResourcesOnly为true,允许背景加载,并针对C#、VB、F#项目提供自动装载,附官方文档链接。增加以下特性即可…… [PackageRegistration(UseManagedRe…...

Codesoft许可管理
在数字化时代,软件许可管理对于确保企业资产安全、优化成本和提高工作效率至关重要。Codesoft作为一款功能强大的标签设计软件,其许可管理功能同样出色。本文将为您介绍如何进行Codesoft的许可管理,确保您的软件投资得到最大回报。 一、了解…...

Unity3D 3D模型/动画数据压缩详解
前言 在Unity3D项目中,3D模型和动画数据通常占用大量内存和存储空间,有效的数据压缩技术对于提升游戏性能和加载速度至关重要。本文将详细介绍Unity3D中3D模型和动画数据的压缩技术,并提供相关的代码实现。 对惹,这里有一个游戏…...

ffmpeg和ffplay命令行实战手册
文章目录 视频拼接用concat视频分段拼接(ffplay 不可调用seek函数进行seek)给视频添加黑边,让视频填充并居中显示不同分辨率视频分段拼接,并且,设置单个视频的缩放比例和摆放位置视频画中画复杂嵌套用overlay(ffplay 可调用seek函数进行seek)…...

基于MobileNet v2模型的口罩实时检测系统实现
基于kaggle数据集训练的模型其实现结果如下: 代码结构如下: 实时口罩检测器: 从导航栏中的链接“实时的口罩检测器”功能,该系统包含一个实时检测用户是否佩戴口罩的功能。基于图片的口罩检测器: 从另一个导航链接“基…...

NEEP-EN2-2023-Section5PartB
题目 个人答案 The chart depicts the outcomes of a survey conducted in a specific university regarding the acquisition of practical activity in class. The chart illustrates that learning knowledges accounts for 91.3 percent, which is the highest percentage…...

PostgreSQL17.x数据库备份命令及语法说明
PostgreSQL17.x数据库备份命令及语法说明 文章目录 PostgreSQL17.x数据库备份命令及语法说明1. 备份命令1. pg_dump命令参数2. pg_dumpall命令参数 2. pg_dump 备份单库语法3. pg_dumpall 备份所有数据库语法4. 备份案例1. pg_dump单库备份2.pg_dumpall单库备份 4. 备份案例1. …...

Java实现一个带头节点的单链表
什么是单链表? 单链表是一种基础的数据结构,其中每个节点都包含两部分: 数据域:存储节点数据。指针域:存储指向下一个节点的引用。 为什么使用头节点? 头节点的存在简化了操作逻辑: 统一操作…...

【图像配准】方法总结
图像配准(Image registration)就是将不同时间、不同传感器(成像设备)或不同条件下(天候、照度、摄像位置和角度等)获取的两幅或多幅图像进行匹配、叠加的过程,就是找到1幅图像像素到另1幅图像像素间的空间映射关系它已…...

LabVIEW汽车综合参数测量
系统基于LabVIEW虚拟仪器技术,专为汽车带轮生产中的质量控制而设计,自动化测量和检测带轮的关键参数。系统采用PCIe-6320数据采集卡与精密传感器结合,能够对带轮的直径、厚度等多个参数进行高精度测量,并通过比较测量法判定产品合…...

三相异步电动机没有气压怎么办?
三相异步电动机作为工业和商业应用中最常见的电动机类型之一,广泛应用于各类机械设备及自动化系统中。其运行依赖于电能的转换,然而在某些情况下,可能会出现电动机驱动设备无法获得气压的情况。 一、三相异步电动机工作原理 三相异步电动机…...

NV170D语音芯片在智能锁离线语音交互中的工程实践
1. 项目概述:当智能锁“开口说话”智能锁这东西,现在家里、公寓、办公室基本都普及了。从最早的密码、指纹,到现在的刷脸、手机NFC,解锁方式越来越花哨。但不知道你有没有过这样的体验:大晚上回家,楼道灯暗…...

大模型应用开发指南:从入门到实践,收藏这份从Demo到生产落地的完整攻略
本文分享了AI应用开发中从Demo到生产落地的完整实践,涵盖技术选型、架构设计、核心算法优化及部署经验。通过LangGraph、RAGFlow和Langfuse等工具,解决上下文超限、Prompt管理混乱等问题,最终实现准确率提升25%的工业级AI系统。适合程序员和小…...

深度解析:实战掌握神经网络架构可视化完整方案
深度解析:实战掌握神经网络架构可视化完整方案 【免费下载链接】Neural-Network-Architecture-Diagrams Diagrams for visualizing neural network architecture 项目地址: https://gitcode.com/gh_mirrors/ne/Neural-Network-Architecture-Diagrams 在深度学…...
图形化管理Kafka集群,5分钟上手)
告别命令行!用Offset Explorer(原Kafka Tool)图形化管理Kafka集群,5分钟上手
告别命令行恐惧:用Offset Explorer实现Kafka集群的可视化高效管理 对于许多开发者和运维人员来说,Kafka的命令行操作就像一道难以逾越的门槛。那些复杂的参数、冗长的命令和难以直观理解的输出,常常让人望而却步。而Offset Explorerÿ…...

为OpenClaw工作流配置Taotoken作为统一模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw工作流配置Taotoken作为统一模型供应商 如果你正在使用OpenClaw构建复杂的Agent工作流,管理多个Agent的模型…...

正交试验结果怎么看?一张图教你读懂SPSSAU的极差分析表和均值图
正交试验结果解读指南:从极差分析到最优组合决策 正交试验作为多因素优化研究的利器,其价值往往在数据解读阶段才能真正释放。当SPSSAU输出的极差分析表和均值图呈现在眼前时,许多研究者会陷入"数字迷宫"——那些K1/K2/K3值究竟在诉…...

研究生必看:论文机制图、流程图快速画法
在学术研究中,高质量的科研配图往往是论文能否被接收的关键因素之一。然而,对于没有专业绘画背景的科研人员来说,传统绘图软件的学习成本高、操作复杂,往往让人望而却步。MedPeer科研绘图工具正是为解决这一痛点而设计——让科研人…...
)
FL Studio自带的Edison插件,才是隐藏的降噪神器!手把手教你清除录音底噪(含参数设置避坑指南)
FL Studio隐藏神器Edison:专业级降噪全流程实战指南 在家庭录音棚里,空调的嗡嗡声、电脑风扇的呼啸、电路底噪的嘶嘶声——这些不受欢迎的"伴奏"总是如影随形。当你在FL Studio中回放刚录制的人声或乐器时,这些背景噪音往往会毁掉整…...

终极免费ThinkPad双风扇智能控制方案:TPFanControl2完全指南
终极免费ThinkPad双风扇智能控制方案:TPFanControl2完全指南 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 在ThinkPad笔记本的日常使用中,散热…...

开发AI应用时如何利用Taotoken实现模型的快速选型与A/B测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI应用时如何利用Taotoken实现模型的快速选型与A/B测试 在开发AI应用的过程中,选择合适的模型是影响最终效果与成本…...