【python因果库实战5】使用银行营销数据集研究营销决策的效果5
目录
接触次数的效应
重新定义治疗变量和潜在混杂因素
更深入地审视干预情景
逆概率加权
标准化
总结及与非因果分析的比较
接触次数的效应
我们现在转而研究当前营销活动中接触次数的数量('campaign')对积极结果发生率的影响。具体来说,我们将估计如果所有客户都被接触多次与只被接触一次相比的成功率。这是一个相关的问题,因为接触客户需要资源(比如员工的时间)。结合其他输入,效果估计可以为员工提供是否在第一次尝试后继续联系客户,还是将时间更有利可图地用于其他任务的指导。
重新定义治疗变量和潜在混杂因素
相应地,我们将治疗变量a重新定义为:如果'campaign'大于1则为1,如果'campaign'等于1则为0。我们还需要重新定义y以恢复之前考虑接触方式时排除的非重叠群体。
y = pd.Series(le.fit_transform(data['y']))
a = (data['campaign'] > 1).astype(int)
print(y.mean())
print(a.mean())
0.11265417111780131
0.5716713605904632至于混杂因素,我们继续使用之前包括的客户特征、之前的营销活动特点以及经济指标。
confounders = ['age', 'job', 'marital', 'education', 'default', 'housing', 'loan', 'pdays','previous', 'poutcome', 'emp.var.rate', 'cons.price.idx', 'cons.conf.idx', 'euribor3m', 'nr.employed']以'campaign'作为治疗变量,我们设想在首次与客户接触后决定停止还是继续。在这种情况下,最后一次接触的特点('contact'、'day_of_week',当然还有'duration')可能还不知道,所以它们不应该被视为潜在的混杂因素。因此,我们只会添加'month'。
confounders += ['month']重新提取混杂因素:
X = data[confounders]
X = pd.get_dummies(X, prefix_sep='=', drop_first=True)更深入地审视干预情景
让我们停下来更仔细地思考一下决策情景:我们首先联系所有客户一次,然后决定是否继续联系还是停止。第一个观察是,通过继续联系,积极结果的发生率只能增加,因此治疗效果的正负符号是没有疑问的。相反,目标是估计在决定继续联系的情况下,积极结果的发生率有多大,以供成本效益分析参考。
第二,因果效应估计的主要挑战(也就是所谓的“因果推断的基本问题”)是我们通常不能观察到反事实结果:对于被给予a=0干预的个体,我们无法观察他们在a=1下的结果,反之亦然。然而,在当前的情景中,我们实际上可以推断出一些反事实结果。让我们定义Y0为客户仅被联系一次时可能出现的结果。对于实际上只被联系一次的客户(分配a=0),他们的观察结果y与潜在结果Y0相同。对于被联系多次的客户(分配a=1),如果我们选择在第一次联系后停止,则他们的潜在结果应该是Y0 = 0,否则银行员工不会持续联系他们。因此,对于所有客户,Y0可以根据以下方式推断:
y0 = y * (a == 0)
y0.mean()
0.05584150723511702这个5.6%的成功率实际上是仅联系一次这一干预措施下的成功率。我们稍后会回到这个数值上来。
此外,潜在结果Y0在银行员工第一次联系后作出决策时是已知的。实际上,它可以被视为一种特殊类型的混杂因素,因为它具有确定性影响:如果Y0=1(成功),那么a=0是确定性的,因为继续联系没有益处,并且y=1。由于Y0=1的客户只接受a=0的处理,它们构成了一个完全非重叠的治疗群体。因此,应该将它们从因果分析中排除,就像我们之前在分析'contact'时所做的那样。所以我们把它们移除:
y = y.loc[y0 == 0]
a = a.loc[y0 == 0]
X = X.loc[y0 == 0]
X.shape
(38888, 46)剩下的Y0=0的客户可以接受a=0或a=1的处理,因此它们不存在完全非重叠的情况。它们可能仍然存在部分非重叠的问题,但这可以通过使用逆概率加权(IPW)模型和Causal Inference 360的评估方法来进行检查,我们将在下一小节中这样做。
还需要记住的一点是,处理a=1,即'campaign' > 1,实际上是一个复合处理:它不是一个像“恰好联系两次”那样明确定义的干预措施,而是“根据数据中的'campaign'分布进行多次联系”(换句话说,遵循银行员工集体的做法)。实际上,人们可以想象在一定数量的联系之后,成功率可能会开始下降,因为客户可能会变得恼火甚至离开银行(这是我们在数据中没有观察到的结果)。在这个笔记本中,我们不会涉及这些额外的考虑因素,而是专注于二元化处理的简化案例。
逆概率加权
如同第2节中所述,我们将使用逻辑回归模型来实例化IPW,以预测治疗分配的概率。
lr = LogisticRegression(solver='lbfgs', max_iter=1000)
#lr = LogisticRegression(penalty='l1', solver='saga', max_iter=1000)
#lr = GradientBoostingClassifier()
ipw = IPW(lr)
ipw.fit(X, a)
IPW(clip_max=None, clip_min=None, use_stabilized=False, verbose=False,learner=LogisticRegression(max_iter=1000))让我们通过评估图表来检查IPW模型:
eval_results = evaluate(ipw, X, a, y)
eval_results.plot_all()
eval_results.plot_covariate_balance(kind="love")
两个治疗组从一开始就相当平衡:
ROC曲线:倾向性AUC(蓝色曲线)仅为0.55,经过IPW后进一步降低到0.51。
倾向性分布:倾向性估计的分布是平衡的。
协变量平衡Love图:即使在IPW之前,标准化的平均差异也都低于0.1。
现在我们获得积极结果率和治疗效果的估计:
outcomes = ipw.estimate_population_outcome(X, a, y)
print(outcomes)
ipw.estimate_effect(outcomes[1], outcomes[0], effect_types=['diff'])
0 0.000000
1 0.100092
dtype: float64
diff 0.100092
dtype: float64积极结果在a=0(停止)时为零,这符合该子人群的定义,即在一次接触后没有成功。在a=1下,估计的成功率为10%。接下来我们将使用标准化来分解这一比率。
标准化
回想一下,在标准化中,我们使用回归器从混杂因素X和治疗a来预测结果y。由于排除了在a=0下的积极结果Y0=1,因此现在在a=0的条件下y恒为零。因此,我们只需要为a=1拟合一个模型。为此,我们使用梯度提升分类树的StratifiedStandardization来为a=1建模,而对于a=0则使用线性回归。后者是一个“虚拟”的模型,只会返回一个全零的模型。
from sklearn.linear_model import LinearRegression
std = StratifiedStandardization({0: LinearRegression(), 1: GradientBoostingClassifier()}, predict_proba=True)
std.fit(X, a, y)我们继续估计两种干预措施下的积极结果发生率。(最后两列的结果是预测的y=0和y=1的概率,是在a=1干预下的概率,因此加起来等于1。)
outcomes = std.estimate_population_outcome(X, a)
print(outcomes)
std.estimate_effect(outcomes[(1,1)], outcomes[0], effect_types=['diff'])
campaign
0 y 0.000000
1 0 0.9021711 0.097829
dtype: float64
diff 0.097829
dtype: float64a=0干预(停止)下的估计结果为零,正如预期。a=1下的估计结果9.8%略低于IPW的结果。
使用标准化,我们还可以看到在继续联系所有客户的干预措施下,分配到的治疗组a=0和a=1的估计成功率是否有差异。这可以通过使用estimate_individual_outcome方法(与上面的estimate_population_outcome方法相反),提取a=1干预下的(1,1)列的成功概率,然后对两个治疗组的概率求平均来完成。
yPot = std.estimate_individual_outcome(X, a)#.xs(1, axis=1, level='y')
#print(yPot.head())
y1 = yPot[(1,1)]
print('Estimated success rates under continuing contact')
print('for the "untreated" group a=0: {}'.format(y1.loc[a == 0].mean()))
print('for the "treated" group a=1: {}'.format(y1.loc[a == 1].mean()))
Estimated success rates under continuing contact
for the "untreated" group a=0: 0.09543383555412627
for the "treated" group a=1: 0.09938921214795549a=0组(未治疗组)的y1平均值略低于a=1组(治疗组),这解释了为什么总体的成功率9.8%略低。这意味着如果我们决定继续联系所有客户,我们可能在那些银行员工在数据中停止联系的客户(a=0)上的成功率略低于那些继续联系的客户(a=1)。这可能是由于银行员工在决定继续联系哪些客户时,有一定的能力预测哪些客户更有可能进行投资,尽管考虑到差异很小,我们不能肯定地说这一点。
我们也可以验证a=1组的估计成功率与观察到的成功率非常接近(因为这一组实际上接受了继续联系)。后者是在a=1条件下的发生率。再次说明,这可能是没有采用因果方法时所计算的结果。
print(y[a==1].mean())
0.09937993714431326总结及与非因果分析的比较
回想一下,在因果分析中我们排除了第一次接触后就有积极结果的客户(Y0=1)。对于这些客户,我们可以假设(或者说定义)他们的反事实结果为Y1=1,如果我们继续联系他们的话。然后我们可以构建在a=1干预下的完整潜在结果集y1All:
y1All = y0.copy()
y1All[y1All == 0] = y1
print('Estimated success rate under one contact for all clients: {}'.format(y0.mean()))
print('Estimated success rate under more than one contact for all clients: {}'.format(y1All.mean()))
Estimated success rate under one contact for all clients: 0.05584150723511702
Estimated success rate under more than one contact for all clients: 0.1482073490897146总结来说,从数据中我们观察到一次接触后的成功率为5.6%,而从因果分析中,我们预测如果所有客户都接受继续联系,成功率为14.8%。观察到的成功率11.3%介于两者之间,因为银行员工选择了一些客户继续联系,而停止了对其他客户的联系。
我们同样以与非因果分析的比较来结束,简单地查看基于治疗分配a=0、a=1的成功率。我们首先重新定义y和a,以带回被排除的Y0=1的人群。
y = pd.Series(le.fit_transform(data['y']))
a = (data['campaign'] > 1).astype(int)
y[a==0].mean(), y[a==1].mean()
(0.13037070626913047, 0.09937993714431326)我们现在看到这些条件成功率是非常误导人的。它们似乎表明,如果客户被联系多次,成功率会更低,我们知道这并不是真的(即使是常识)。我们来分别看一下这两种情况:
- 对于a=0,13.0%的成功率仅来自于那些银行员工只联系了一次的客户。但如果他们对剩余的客户也只联系一次就停止,他们不会有额外的成功。因此,正好一次接触干预下的成功率要低得多,如上所述为5.6%。
- 对于a=1,9.9%的成功率接近于我们使用标准化估计的9.8%,针对那些第一次接触后不是成功的客户(Y0=0)。但是,我们必须记得加上那些第一次接触后就已经同意定期存款的客户(Y0=1),这样我们得到了在超过一次接触的干预下14.8%的成功率。
相关文章:
【python因果库实战5】使用银行营销数据集研究营销决策的效果5
目录 接触次数的效应 重新定义治疗变量和潜在混杂因素 更深入地审视干预情景 逆概率加权 标准化 总结及与非因果分析的比较 接触次数的效应 我们现在转而研究当前营销活动中接触次数的数量(campaign)对积极结果发生率的影响。具体来说,…...

【Qt】QWidget中的常见属性及其功能(二)
目录 六、windowOpacity 例子: 七、cursor 例子: 八、font 九、toolTip 例子: 十、focusPolicy 例子: 十一、styleSheet 计算机中的颜色表示 例子: 六、windowOpacity opacity是不透明度的意思。 用于设…...

9 OOM和JVM退出。OOM后JVM一定会退出吗?
首先我们把两个概念讲清楚 OOM是线程在申请堆内存,发现堆内存空间不足时候抛出的异常。 JVM退出的条件如下: java虚拟机在没有守护线程的时候会退出。守护线程是启动JVM的线程,服务于用户线程。 我们简单说下守护线程的功能: 1.日志的记录…...

学习笔记070——Java中【泛型】和【枚举】
文章目录 1、泛型1.1、为什么要使用泛型?1.2、泛型的应用1.3、泛型通配符1.4、泛型上限和下限1.5、泛型接口 2、枚举 1、泛型 Generics 是指在定义类的时候不指定类中某个信息(属性/方法返回值)的具体数据类型,而是用一个标识符来…...
【工具变量】碳排放市场交易数据(2013-2023年)
一、时间范围:2013年8月5日到2023年1月13日 二、具体指标: 交易日期 城市名称 交易品种 开盘价 最高价 最低价 成交均价 收盘价 前收盘价 涨跌幅 总成交量 总成交额 …...

【视频生成模型】——Hunyuan-video 论文及代码讲解和实操
🔮混元文生视频官网 | 🌟Github代码仓库 | 🎬 Demo 体验 | 📝技术报告 | 😍Hugging Face 文章目录 论文详解基础介绍数据预处理 (Data Pre-processing)数据过滤 (Data Filtering)数据标注 (Data…...

基线检查:Windows安全基线.【手动 || 自动】
基线定义 基线通常指配置和管理系统的详细描述,或者说是最低的安全要求,它包括服务和应用程序设置、操作系统组件的配置、权限和权利分配、管理规则等。 基线检查内容 主要包括账号配置安全、口令配置安全、授权配置、日志配置、IP通信配置等方面内容&…...

uniapp跨端适配—条件编译
在uniapp中,跨端适配是通过条件编译实现的。条件编译允许开发者根据不同的平台(如iOS、Android、微信小程序、百度小程序等)编写不同的代码。这样可以确保每个平台上的应用都能得到最优的性能和用户体验。 以下是uniapp中条件编译的基本语法…...
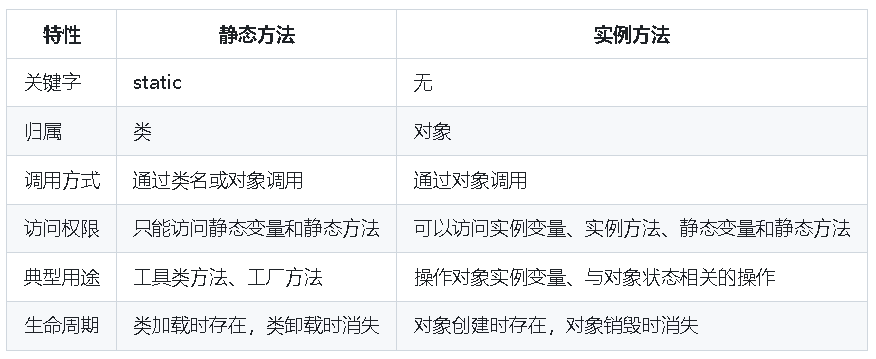
【Java基础面试题013】Java中静态方法和实例方法的区别是是么?
回答重点 静态方法 使用static关键字修修饰的方法属于类随着类的加载而加载,随着类的卸载而消失可以通过类名直接调用,也可以通过对象调用,但是这种方式不推荐,会混淆意义,也不利于后期维护与扩展 class Example {st…...

C语言入门(一):A + B _ 基础输入输出
前言 本专栏记录C语言入门100例,这是第(一)例。 目录 一、【例题1】 1、题目描述 2、代码详解 二、【例题2】 1、题目描述 2、代码详解 三、【例题3】 1、题目描述 2、代码详解 四、【例题4】 1、题目描述 2、代码详解 一、【例…...

Vue日历组件FullCalendar使用方法
FullCalendar (全日历)Vue组件的使用 FullCalendar官方文档地址 FullCalendar日历组件支持Vue React Angular Javascript Vue2的框架示例: npm install --save fullcalendar/core fullcalendar/vue<template><div class"cal…...

TinyML在OBD-II边缘设备上燃油类型分类的实现与优化
论文标题:TinyML Implementation and Optimization for Fuel Type Classification on OBD-II Edge Device(TinyML在OBD-II边缘设备上燃油类型分类的实现与优化) 作者信息:Miguel Amaral, Morsinaldo Medeiros, Matheus Andrade, …...

vue3 中 defineProps 声明示例
1、直接声明 // 1、直接使用 defineProps(["tableData", "acceptType"]); 2、运行时声明方式不使用TypeScript类型注解,而是使用JavaScript对象,使用 type 来定义props // 2、运行时声明方式不使用TypeScript类型注解,…...

SpringBoot整合MybatisPlus报错Bean不存在:NoSuchBeanDefinitionException
报错信息: Exception in thread “main” org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type ‘com.feng.mybatisplusdemo.dao.UserMapper’ available 解决办法: 将原来引入的MybatisPlus依赖:…...

异步电机的控制是否还有研究的必要,是不是已经非常成熟了?
随着工业现代化和自动化进程的加快,异步电机作为最为常见的电动机之一,广泛应用于各类机械设备和工业自动化系统中。异步电机因其结构简单、成本低廉、维护方便等优点而备受青睐。 异步电机的基本原理与应用 异步电机,又称感应电机…...
【Android】解决 ADB 中 SELinux 设置与 `Failed transaction (2147483646)` 错误
解决 ADB 中 SELinux 设置与 Failed transaction (2147483646) 错误 在使用 ADB 进行开发和调试时,经常会遇到由于 Android 系统安全策略(SELinux)引起的权限问题,尤其是在执行某些操作时,可能会遇到类似 cmd: Failur…...

企业车辆管理系统(源码+数据库+报告)
一、项目介绍 352.基于SpringBoot的企业车辆管理系统,系统包含两种角色:管理员、用户,系统分为前台和后台两大模块 二、项目技术 编程语言:Java 数据库:MySQL 项目管理工具:Maven 前端技术:Vue 后端技术&a…...

SAP RESTful架构和OData协议
一、RESTful架构 RESTful 架构(Representational State Transfer)是一种软件架构风格,专门用于构建基于网络的分布式系统,尤其是在 Web 服务中。它通过利用 HTTP 协议和一组简单的操作(如 GET、POST、PUT、DELETE&…...

centOS定时任务-cron服务
最近在训练模型的过程中,经常会因为内存爆炸而停止模型训练过程,而且因为内存占满停止的训练进程甚至都没有任何的报错提示。 1、需要减少num_worker的数量,降低需要占用内存的数据数量 2、可以通过free -h监控内存的占用情况 3、可以通过lin…...

Python毕业设计选题:基于django+vue的宠物服务管理系统
开发语言:Python框架:djangoPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 管理员登录 管理员功能界面 用户管理 宠物商品管理 医疗服务管理 美容服务管理 系统…...

探索GetQzonehistory:永久保存QQ空间记忆的数字时光机
探索GetQzonehistory:永久保存QQ空间记忆的数字时光机 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,我们的记忆分散在各个社交平台,而Q…...

设备管理系统是什么?如何建立设备管理体系?
在现代企业的运转中,生产设备无疑是核心资产。无论是制造业的数控机床,还是建筑工地的重型机械,甚至是医疗机构的精密仪器,设备的稳定运行直接决定了企业的生产效率、产品质量和成本控制。然而,许多企业在设备管理上仍…...

BI 项目交付 SOP
...

GIL移除≠自动线程安全!揭秘Python 3.13+中asyncio+shared_memory+numpy.ndarray三者交汇处的5个未公开竞态漏洞
第一章:Python无锁GIL环境下的并发安全本质重构当Python脱离CPython解释器的全局解释器锁(GIL)约束——例如在PyPy的STM模式、Jython、Cython多线程扩展,或新兴的Rust-Python绑定(如PyO3 async-std)中运行…...

Qwen2.5-Coder-1.5B应用案例:自动生成Bash脚本处理日志文件
Qwen2.5-Coder-1.5B应用案例:自动生成Bash脚本处理日志文件 1. 日志处理场景与痛点分析 1.1 运维工程师的日常挑战 在服务器运维工作中,日志分析是最常见也最耗时的任务之一。想象一下这样的场景: 你需要检查10台服务器上50个不同的服务日…...

亚洲美女-造相Z-Turbo算力适配实践:24G显存下支持batch_size=2高清图并行生成
亚洲美女-造相Z-Turbo算力适配实践:24G显存下支持batch_size2高清图并行生成 1. 快速了解亚洲美女-造相Z-Turbo 亚洲美女-造相Z-Turbo是一个专门针对亚洲女性形象生成优化的文生图模型,基于Z-Image-Turbo的LoRA版本进行深度定制。这个模型最大的特点是…...

AI艺术创作大赛:Shadow Sound Hunter生成作品展示
AI艺术创作大赛:Shadow & Sound Hunter生成作品展示 1. 引言 最近参加了一场AI艺术创作大赛,用Shadow & Sound Hunter模型生成了不少有意思的作品。这个模型在数字绘画、诗歌创作和音乐编曲方面都表现出色,让我看到了AI在艺术创作领…...

细致配置Doctrine,专注于指定前缀表的迁移
在使用Symfony和Doctrine进行项目开发时,如何优雅地处理数据库迁移是一个常见的问题。本文将详细探讨如何配置Doctrine,使其在生成迁移文件时仅关注特定前缀的表(如pp_前缀的表),从而避免迁移文件中包含不必要的表。 背景介绍 假设你有一个Symfony项目,该项目中数据库已…...

暗黑破坏神2单机增强神器:PlugY插件全方位使用指南
暗黑破坏神2单机增强神器:PlugY插件全方位使用指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 对于暗黑破坏神2单机玩家而言,有限的储物空…...

UDOP-large高性能部署:Tesseract OCR预处理与UDOP-large联合加速方案
UDOP-large高性能部署:Tesseract OCR预处理与UDOP-large联合加速方案 1. 引言:当文档理解遇上效率瓶颈 想象一下,你手头有几百份英文PDF报告需要处理。你需要从中提取标题、摘要,甚至表格里的关键数据。传统的方法是:…...