LEAST-TO-MOST PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS---正文
题目
最少到最多的提示使大型语言模型能够进行复杂的推理

论文地址:https://arxiv.org/abs/2205.10625
摘要
思路链提示在各种自然语言推理任务中表现出色。然而,它在需要解决比提示中显示的示例更难的问题的任务上表现不佳。为了克服这种由易到难的概括的挑战,我们提出了一种新颖的提示策略,即从最少到最多提示。该策略的关键思想是将复杂问题分解为一系列更简单的子问题,然后按顺序解决它们。先前解决的子问题的答案有助于解决每个子问题。我们在与符号操作、组合概括和数学推理相关的任务上的实验结果表明,从最少到最多提示能够推广到比提示中看到的更难的问题。一个值得注意的发现是,当使用 GPT-3 code-davinci-002 模型进行从最少到最多的提示时,它可以在任何分割(包括长度分割)中解决组合泛化基准 SCAN,准确率至少为 99%,而使用思路链提示的准确率仅为 16%。这一点尤其值得注意,因为文献中专门用于解决 SCAN 的神经符号模型是在包含超过 15,000 个示例的整个训练集上进行训练的。我们在附录中提供了所有任务的提示。
引言
尽管深度学习在过去十年中取得了巨大的成功,但人类智能与机器学习之间仍然存在巨大差异:
- 对于新任务,人类通常可以从几个演示示例中学会完成它,而机器学习需要大量标记数据进行模型训练;
- 人类可以清楚地解释他们预测或决策背后的原因,而机器学习本质上是一个黑匣子;
- 人类可以解决比他们以前见过的任何问题都更困难的问题,而对于机器学习来说,训练和测试中的例子通常处于相同的难度级别。
最近提出的思路链提示方法(Wei et al, 2022; Chowdhery et al, 2022)在缩小人类智能和机器智能之间的差距方面迈出了重要一步。它将自然语言原理的思想(Ling et al, 2017; Cobbe et al, 2021)与小样本提示(Brown et al, 2020)相结合。当进一步与自洽解码 (Wang et al, 2022b) 相结合,而不是使用典型的贪婪解码时,少数样本的思路链提示在许多具有挑战性的自然语言处理任务上的表现大大优于文献中的最新成果,这些任务是从专门设计的神经模型中获得的,这些模型使用数百倍的注释示例进行训练,同时具有完全可解释性。
然而,思路链提示有一个关键的局限性——它在需要泛化解决比演示示例更难的问题的任务上表现不佳,例如组合泛化 (Lake & Baroni, 2018; Keysers et al, 2020)。为了解决这种由易到难的泛化问题,我们提出了由少到多的提示。它包括两个阶段:首先将一个复杂的问题分解为一系列较容易的子问题,然后按顺序解决这些子问题,其中通过先前解决的问题的答案来促进给定子问题的解决子问题。两个阶段都是通过少样本提示实现的,因此两个阶段都没有训练或微调。图 1 显示了从最少到最多提示的示例用法。“从最少到最多提示”一词借用自教育心理学(Libby 等人,2008 年),用于表示使用渐进式提示序列帮助学生学习新技能的技术。在这里,我们将这种技术应用于教人类教授语言模型。符号操作、组合泛化和数学推理的实证结果表明,从最少到最多提示确实可以推广到比演示的更难的问题。

图 1:从最少到最多提示分两个阶段解决数学应用题:(1)查询语言模型将问题分解为子问题;(2)查询语言模型按顺序解决子问题。第二个子问题的答案建立在第一个子问题的答案之上。本例中省略了每个阶段提示的演示示例。
从最少到最多提示
从最少到最多提示通过将复杂问题分解为一系列更简单的子问题,教语言模型如何解决复杂问题。它包含两个连续的阶段:
- 分解。此阶段的提示包含演示分解的常量示例,然后是需要分解的具体问题。
- 子问题解决。此阶段的提示包含三部分:
- 演示如何解决子问题的常量示例;
- 之前回答过的子问题和生成的解决方案的可能为空的列表,以及
- 接下来要回答的问题。
在图 1 所示的示例中,首先要求语言模型将原始问题分解为子问题。传递给模型的提示包括说明如何分解复杂问题的示例(图中未显示),然后是要分解的具体问题(如图所示)。语言模型发现,原始问题可以通过解决中间问题“每次旅行需要多长时间?”来解决。在下一阶段,我们要求语言模型按顺序解决问题分解阶段的子问题。原始问题被附加为最终子问题。解决从向语言模型传递一个由说明如何解决问题的示例组成的提示开始(图中未显示),然后是第一个子问题“每次旅行需要多长时间?”。然后,我们获取语言模型生成的答案(“…每次旅行需要 5 分钟。”),并通过将生成的答案附加到上一个提示来构建下一个提示,然后是下一个子问题,这恰好是本例中的原始问题。然后将新提示传回语言模型,语言模型返回最终答案。
从最少到最多的提示可以与其他提示技术相结合,如思路链(Wei 等人,2022 年)和自洽(Wang 等人,2022b 年),但不是必须的。此外,对于某些任务,从最少到最多提示的两个阶段可以合并形成单次提示。
结果
我们展示了符号操作、组合概括和数学推理任务的从最少到最多提示结果,并将其与思路链提示进行了比较。
符号操作
我们采用最后一个字母连接任务(Wei et al,2022)。在此任务中,每个输入都是一个单词列表,相应的输出是列表中单词最后一个字母的连接。 例如,“thinking, machine”输出“ge”,因为“thinking”的最后一个字母是“g”,“machine”的最后一个字母是“e”。当测试列表的长度与提示范例中的列表长度相同时,思路链提示可以完美完成工作。然而,当测试列表比提示范例中的列表长得多时,它的表现会很差。我们表明,从最少到最多的提示克服了这一限制,并且在长度概括方面明显优于思路链提示。
问:“思考,机器,学习”
答:“思考”,“思考,机器”,“思考,机器,学习”
表 1:最后一个字母连接任务的从最少到最多的提示上下文(分解)。它可以将任意长的列表分解为连续的存在,准确率为 100%。
问:“think, machine”
答:“think”的最后一个字母是“k”。“machine”的最后一个字母是“e”。将“k”和“e”连接起来得到“ke”。因此,“think, machine”输出“ke”。
问:“think, machine, learning”
答:“think, machine”输出“ke”。“learning”的最后一个字母是“g”。将“ke”和“g”连接起来得到“keg”。因此,“think, machine, learning”输出“keg”。
表 2:最后一个字母连接任务的从最少到最多的提示上下文(解决方案)。此提示中的两个示例实际上演示了一个基本情况和一个递归步骤。
从最少到最多的提示。最后一个字母连接任务的从最少到最多的提示上下文如表 1 和表 2 所示。表 1 中的示例演示了如何将列表分解为一系列子列表。表 2 中的示例演示了如何将输入映射到所需的输出。给定一个新列表,我们首先将其附加到表 1 中的示例中以构建分解提示,该提示被发送到语言模型以获得列表的分解。然后,我们为每个子列表 S 构建一个解决方案提示,它由表 2 中的示例组成,后面是前一个子列表/响应对(如果有),然后是 S。我们按顺序将这些提示发送给语言模型,并使用最后的响应作为最终解决方案。
值得仔细研究一下表 2 中的示例。本质上,它们教语言模型如何使用以前解决的问题的答案来构建新问题的答案:
- 第二个范例(“思考,机器,学习”)是第一个范例(“思考,机器”)中列表的扩展,而不是完全独立的列表;
- 对“思考,机器,学习”的响应建立在“思考,机器”的输出之上,以“思考,机器”输出“ke”的句子开头。这两个范例一起说明了一个基本情况和一个递归步骤。
思路链提示。最后一个字母连接任务的思路链提示上下文列于表 3 中。它使用与表 2 中从最小到最大的提示相同的列表。唯一的区别是,在思路链提示中,对第二个列表(“思考,机器,学习”)的响应是从头开始构建的,而不是使用第一个列表(“思考,机器”)的输出。
Q:“think, machine”
A:“think”的最后一个字母是“k”。“machine”的最后一个字母是“e”。将“k”和“e”连接起来得到“ke”。因此,“think, machine”输出“ke”。
Q:“think, machine, learning”
A:“think”的最后一个字母是“k”。“machine”的最后一个字母是“e”。“learning”的最后一个字母是“g”。将“k”、“e”、“g”连接起来得到“keg”。因此,“think, machine, learning”输出“keg”。
表 3:最后一个字母连接任务的思路链提示上下文。与表 2 中的从最小到最大提示不同,思路链提示中的示例彼此独立。
我们将从最小到最大提示(表 1 和 2)与思路链提示(表 3)和标准少量提示进行比较。标准少量提示的提示是通过删除思路链提示中的中间解释而构建的。也就是说,它仅由这两个示例组成:
- “思考,机器”输出“ke”;
- “思考,机器,学习”输出“keg”。我们不考虑训练或微调基线,因为基于两个示例的机器学习模型的泛化能力很差。
结果。我们在 Wiktionary1 中随机抽样单词以构建长度从 4 到 12 不等的测试列表。对于每个给定长度,构建 500 个列表。表 4 显示了 GPT-3 中 code-davinci-002 的不同方法的准确率。标准提示完全无法通过所有测试用例,准确率为 0。思路链提示显著提高了标准提示的性能,但仍远远落后于从最少到最多提示,尤其是在列表很长的情况下。此外,随着长度的增加,思路链提示的性能下降速度比从最少到最多提示快得多。

表 4:不同提示方法在最后一个字母连接任务中的准确率。测试列表的长度从 4 个增加到 12 个。
在附录 7.2 和 7.3 中,我们展示了使用不同思路链提示和不同语言模型进行的额外实验。请注意,与从最少到最多提示相比,思路链提示中的样本可以彼此独立。对于最后一个字母连接任务,这意味着我们不需要呈现作为其他样本子列表的样本。事实上,具有独立列表的思路链提示往往优于具有依赖列表的思路链提示,因为前者传达了更多信息。此外,我们可以通过合并其他样本来增强思路链提示。这似乎是公平的,因为从最少到最多提示由于其额外的分解而包含更多单词。如表 13(附录 7.3)所示,对于长度为 12 的列表,思路链提示在有 4 个独立样本的情况下准确率为 37.4%(附录 7.2.2),在有 8 个独立样本的情况下准确率为 38.4%(附录 7.2.3)。与表 3 中原始提示的 31.8% 准确率相比,思路链提示的准确率有了显着提高,但仍然落后于从最少到最多提示,后者的准确率为 74.0%。
错误分析。虽然从最少到最多提示的表现明显优于思路链提示,但对于长列表,它还远未达到 100% 的准确率。在附录 7.4 中,我们提供了详细的错误分析。我们发现其中只有极少数是由于最后一个字母不正确造成的,而大多数是连接错误(删除或添加字母)。例如,给定列表“gratified, contract, fortitude, blew”,模型会删除“dte”和“w”连接中的最后一个字母,因此预测结果是“dte”而不是“dtew”。在另一个示例“hollow, supplies, function, gorgeous”中,模型以某种方式复制了“wsn”和“s”连接中的最后一个字母“s”,因此预测变为“wsnss”而不是“wsns”。
组合泛化
扫描 (Lake & Baroni, 2018) 可能是评估组合泛化最流行的基准。它需要将自然语言命令映射到动作序列(表 5)。序列到序列模型在长度分割下表现不佳,其中训练集中的动作序列(约占全集的 80%,超过 20,000 个示例)比测试集中的动作序列短。已经提出了许多专门的神经符号模型来解决 SCAN(Chen 等人,2020 年;Liu 等人,2020 年;Nye 等人,2020 年;Shaw 等人,2021 年;Kim,2021 年)。我们表明,具有从最少到最多提示的大型语言模型仅使用几个演示示例就可以解决 SCAN。无需训练或微调。

表 5:SCAN 中的示例命令及其对应的动作序列。代理通过执行其对应的动作序列成功执行自然语言命令。
从少到多提示。与第 3.1 节中的最后一个字母连接任务一样,SCAN 的从少到多提示基于两种提示:
- 命令分解提示包含 8 个示例,用于演示如何将长命令分解为短命令列表(请参阅表 6 了解其中一些示例);
- 命令映射提示包含 14 个示例,用于演示如何将自然语言命令映射到动作序列(请参阅表 7 了解其中一些示例)。分解和映射的完整提示上下文列于附录 8 中。命令映射提示中使用的示例旨在完全涵盖 SCAN 命令的语义。
问:“走路后向右看三次”
答:“向右看三次”可以这样解决:“向右看三次”,“向右看三次”。 “走路”可以用“走路”来解决。所以,“走路后向右看三次”可以这样解决:“向右看三次”,“向右看三次”,“走路”。
问:“向右看三次然后走路”
答:“向右看三次”可以这样解决:“向右看”,“向右看”,“向右看三次”。 “走路”可以用“走路”来解决。所以,“向右看三次然后走路”可以这样解决:“向右看”,“向右看”,“向右看三次”,“走路”。
表 6:从最少到最多提示中获取的两个示例,用于将长命令分解为一系列短命令。
我们使用 Python 符号使从最少到最多提示和基线(代表少量提示和思路链提示)中的提示简洁并满足语言模型的输入大小限制(通常最多 2048 个标记)。例如,在我们的提示设计中,我们将“看两次”映射到改为“LOOK” * 2,而不是“LOOK LOOK”。我们可能不得不指出,这些 Python 表达式只是中间表示。在获得语言模型的响应后,我们运行后处理脚本来扩展 Python 表达式以生成最终结果。然而,我们还可以进一步教语言模型正确处理表达式,这并不奇怪。在附录 8.4 中,我们展示了通过几个演示示例,语言模型能够以近乎完美的 99.7% 的准确率扩展 Python 表达式。
Q:“jump left”
A:“jump left”的输出连接了:“turn left”的输出,“jump”的输出。“turn left”输出“TURN LEFT”。“jump”输出“JUMP”。因此,将“turn left”的输出和“jump”的输出连接起来就是“TURN LEFT”+“JUMP”。因此,“jump left”的输出就是“TURN LEFT”+“JUMP”。
Q:“run and look twice”
A:“run and look twice”的输出连接了:“run”的输出,“look twice”的输出。“run”输出“RUN”。“look twice”输出“LOOK”*2。因此,将“run”的输出和“look twice”的输出连接起来就是“RUN”+“LOOK”*2。因此,“run and look twice”的输出就是“RUN”+“LOOK”*2
表 7:从最少到最多/思路链提示中获取的两个示例,用于将命令映射到动作序列。Python 表达式用作中间表示。
思路链提示。SCAN 的思路链提示使用与最少到最多提示相同的命令映射上下文(参见表 7),但它不使用命令分解,命令分解专门用于最少到最多提示。
结果。我们将最少到最多提示与思路链提示和标准少样本提示进行了比较。标准少样本提示的示例是从思路链提示中删除中间解释而得出的。表 8 显示了具有不同语言模型的不同提示方法的准确率。示例输出可在附录 8.3 中找到。使用 code-davinci-002,最少到最多提示在长度分割下实现了 99:7% 的准确率。我们还对所有其他分割甚至整个 SCAN 数据集进行了从最少到最多的提示测试。我们发现它的解决率保持不变。此外,值得注意的是,无论使用哪种提示方法,code-davinci-002 的表现始终优于 text-davinci-002。

表 8:不同提示方法在长度分割下 SCAN 测试集上的准确率(%)。text-davinci-002 的结果基于 100 条命令的随机子集。
错误分析。在长度分割的测试集中,从最小到最大的提示总共有 13 次失败:其中 6 次错误地将“around”后面的“twice”和“thrice”解释为错误,其余的将“after”错误地解释为“and”。让我们为每个类别展示一个失败的示例。在“绕右跑三次后,向右相反方向走两次”这个例子中,code-davinci-002 正确地将表达式“绕右跑”翻译为(“TURN RIGHT” + “RUN”)* 4。然后,在将“thrice”应用于该表达式时出错,生成了(“TURN RIGHT” + “RUN”)* 9,而不是(“TURN RIGHT” + “RUN”)* 4 * 3 或(“TURN RIGHT” + “RUN”)* 12。在“绕左跑两次后,向左相反方向跑三次”这个例子中,code-davinci-002 对由“after”连接的两个子表达式生成了正确的翻译,但它将它们组合在一起,就好像它们由“and”连接一样。这意味着模型产生的是(“TURN LEFT” * 2 + “RUN”)* 3 +(“TURN LEFT” + “RUN”)* 4 * 2,而不是(“TURN LEFT” + “RUN”)* 4 * 2 +(“TURN LEFT” * 2 + “RUN”)* 3。详细的错误分析可参见附录 8.2。
数学推理
在本节中,我们应用从最少到最多的提示来解决 GSM8K(Cobbe 等人,2021 年)和 DROP(Dua 等人,2019 年)中的数学应用题。我们特别感兴趣的是看看大型语言模型与从最少到最多的提示相结合是否可以解决比提示中看到的更困难的问题。在这里,我们只是通过解决步骤的数量来衡量难度。
问:艾莎有 5 个苹果。安娜比艾莎多 2 个苹果。她们加起来有多少个苹果?
答:让我们分解一下这个问题:1. 安娜有多少个苹果?2. 她们加起来有多少个苹果?
1. 安娜比艾莎多 2 个苹果。所以安娜有 2 + 5 = 7 个苹果。
2. 艾莎和安娜加起来有 5 + 7 = 12 个苹果。
答案是:12。
表 9:解决 GSM8K 的从少到多提示。演示问题仅用两个步骤解决,但提示可以处理需要多个步骤解决的问题。
问:Elsa 有 5 个苹果。Anna 比 Elsa 多 2 个苹果。她们加起来有多少个苹果?答:Anna 比 Elsa 多 2 个苹果。所以 Anna 有 2 + 5 = 7 个苹果。所以 Elsa 和 Anna 加起来有 5 + 7 = 12 个苹果。
答案是:12。
表 10:解决 GSM8K 的思路链提示。它是从表 9 中的从少到多提示中删除分解部分而得出的。
我们设计的用于解决 GSM8K 的提示如表 9 所示。演示样本由两部分组成。第一部分(从“让我们分解这个问题……”开始)展示如何将原始问题分解为更简单的子问题,第二部分展示如何按顺序解决子问题。请注意,此提示将分解和子问题解决合并为一次。也可以设计两个不同的提示分别用于分解和子问题解决,就像前面几节中的从最少到最多提示一样,以进一步提高性能。在这里,我们重点研究这个简单的从最少到最多提示如何从简单的 2 步问题推广到更复杂的多步骤问题。我们还构建了一个思路链提示(表 10)作为基线。它是通过删除从最少到最多提示(表 9)的分解部分而得出的。结果如表 11 所示。
总体而言,从最少到最多提示仅略微改善了思路链提示:从 60:97% 到 62:39%:但是,从最少到最多提示在解决至少需要 5 个步骤才能解决的问题时,从最少到最多提示实质上改善了思路链提示:从 39:07% 到 45:23%(表 12)。我们发现,GSM8K 中几乎所有从最少到最多提示无法解决的问题最终都可以通过使用手动分解来解决。这并不奇怪。对于我们人类来说,只要我们知道如何将复杂问题分解为更简单的子问题,我们实际上就已经解决了它。对于 DROP 基准,从最少到最多提示的表现远远优于思路链提示(表 11)。这可能是因为 DROP 中的大多数问题都可以轻松分解。

表 11:GSM8K 和 DROP 上不同提示方法的准确率(%)(仅包含数值问题的子集)。基础语言模型是 code-davinci-002。

表 12:从最少到最多提示和思路链提示的准确率(%),按预期解决方案所需的推理步骤数细分。
相关工作
组合泛化。SCAN(Lake & Baroni,2018)是一种广泛使用的评估组合泛化的基准。在其所有分割中,最具挑战性的是长度分割,这要求模型能够泛化到比训练序列更长的测试序列。在 SCAN 上表现良好的先前工作大多提出了神经符号架构(Chen et al,2020;Liu et al,2020)和语法归纳技术(Nye et al,2020;Shaw et al,2021;Kim,2021)。
Chen 等人 (2020) 提出了神经符号堆栈机,它包含一个神经网络作为控制器,为给定输入生成执行轨迹,以及一个符号堆栈机来执行轨迹并产生输出。执行轨迹由用于序列操作的领域特定原语组成,这使机器能够将输入的句子分解为不同的部分,分别翻译它们,然后将它们组合在一起。Liu 等人 (2020) 提出了一个框架,该框架协同学习两个神经模块,即编写器和求解器,以共同学习输入结构和符号语法规则。Nye 等人 (2020) 和 Shaw 等人 (2021) 都推断出了 SCAN 的符号语法规则,而 Kim (2021) 提出学习潜在的神经语法。虽然使用符号成分的方法能够在 SCAN 上实现 100% 的准确率(Chen et al, 2020; Liu et al, 2020; Nye et al, 2020; Shaw et al, 2021),但它们需要复杂的模型训练和语法推理算法才能在大型语法空间中进行搜索。SCAN 的另一项工作设计了数据增强方案(Andreas, 2020; Akyurek et al ¨, 2021; Lake, 2019)。Andreas (2020) 和 Akyurek et al ¨ (2021) 都通过重组出现在不同训练样本中的片段来构建合成训练样本,Akyurek et al ¨ (2021) 进一步设计了一种采样方案,鼓励重组模型产生稀有样本。另一方面,Lake(2019)提出了一种元训练算法,该算法需要元语法空间来构建训练数据,并且采样语法的格式类似于 SCAN 语法。
虽然这些数据增强技术提高了几个组合泛化基准上的性能,但它们未能解决 SCAN 的长度分割问题。其他先前的研究提出了神经网络架构来改善组合泛化,它们鼓励模型学习单词和跨度映射(Russin et al, 2019; Li et al, 2019)、输入和输出作为跨度树的对齐(Herzig & Berant, 2021)以及输入和输出词的排列等方差(Gordon et al, 2020)。尽管如此,这些没有符号组件的端到端神经网络不能推广到更长的测试输入。与现有工作不同,我们证明,即使没有专门设计用于提高组合泛化的模型架构和符号组件,从最少到最多的提示仅使用少量演示示例就可以在任何分割(包括长度分割)上实现 99:7% 的准确率,并且不需要任何训练或微调。
从易到难的泛化。除了组合泛化之外,还有许多其他任务,其中测试用例需要比训练示例更多的推理步骤来解决,例如,最后一个字母连接任务中的测试列表比演示示例更长。Dong 等人(2019 年)提出了用于归纳学习和逻辑推理的神经逻辑机 (NLM)。在小规模任务(例如小尺寸块世界)上训练的 NLM 可以完美地推广到大规模任务(例如更大尺寸的块世界)。Schwarzschild 等人 (2021 年)表明,经过训练以使用少量递归步骤解决简单问题的递归网络(例如小尺寸迷宫或国际象棋谜题)可以通过在推理过程中执行额外的递归来解决更复杂的问题(例如更大尺寸的迷宫或国际象棋谜题)。在我们的方法中,我们通过将复杂问题分解为一系列更简单的问题来实现从易到难的泛化。
任务分解。 Perez 等人 (2020) 将多跳问题分解为多个独立的单跳子问题,这些子问题由现成的问答 (QA) 模型回答。然后,这些答案被聚合以形成最终答案。问题分解和答案聚合均由经过训练的模型实现。Wang 等人 (2022a) 通过将提示建模为连续的虚拟标记并逐步引出相关知识来进行多跳问答通过迭代提示从语言模型中获取边缘。与这些方法不同,我们的方法不涉及任何训练或微调。此外,从最少到最多提示生成的子问题通常是依赖的,必须按特定顺序依次解决,以便某些子问题的答案可以用作解决其他子问题的构建块。Yang 等人 (2022) 通过将问题分解为一系列通过基于规则的系统对应于 SQL 子句的填充槽的自然语言提示,将自然语言问题转换为 SQL 查询。Wu 等人 (2022) 提出将大型语言模型步骤链接起来,使得一个步骤的输出成为下一个步骤的输入,并开发一个交互式系统供用户构建和修改链。从最少到最多提示将问题分解和子问题解决的过程链接起来。
局限性
分解提示通常不能很好地推广到不同的领域。例如,演示分解数学应用题的提示(如表 9 所示)对于教大型语言模型分解常识推理问题(例如“亚里士多德使用笔记本电脑了吗?”)并不有效(Geva 等人,2021 年)。必须设计一个新的提示来演示这些类型问题的分解,以实现最佳性能。
在同一领域内推广分解也很困难。我们观察到,如果大型语言模型能够正确分解这些具有挑战性的问题,那么 GSM8K 中的几乎所有问题都可以准确解决。这一发现并不令人惊讶,与我们解决数学问题的经验相符。每当我们成功地将数学问题分解为我们可以解决的更简单的子问题时,我们基本上就解决了原始问题。在最后一个字母连接任务和 SCAN 基准上取得了卓越的成果,因为这些任务中的分解相对简单。
结论与讨论
我们引入了从最少到最多的提示,以使语言模型能够解决比提示更难的问题。这种方法需要一个双重过程:自上而下的问题分解和自下而上的解决方案生成。我们的实证研究结果涵盖了符号操作、组合概括和数学推理,表明从最少到最多的提示明显优于标准提示和思路链提示。
一般来说,提示可能不是向大型语言模型教授推理技能的最佳方法。提示可以看作是一种单向的交流形式,我们在其中指导语言模型而不考虑其反馈。一个自然的进展是将提示发展为完全双向的对话,从而能够立即向语言模型反馈,从而促进更高效、更有效的学习。从最少到最多的提示技术代表了通过这种双向交互指导语言模型的一大步。
相关文章:
LEAST-TO-MOST PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS---正文
题目 最少到最多的提示使大型语言模型能够进行复杂的推理 论文地址:https://arxiv.org/abs/2205.10625 摘要 思路链提示在各种自然语言推理任务中表现出色。然而,它在需要解决比提示中显示的示例更难的问题的任务上表现不佳。为了克服这种由易到难的概括…...
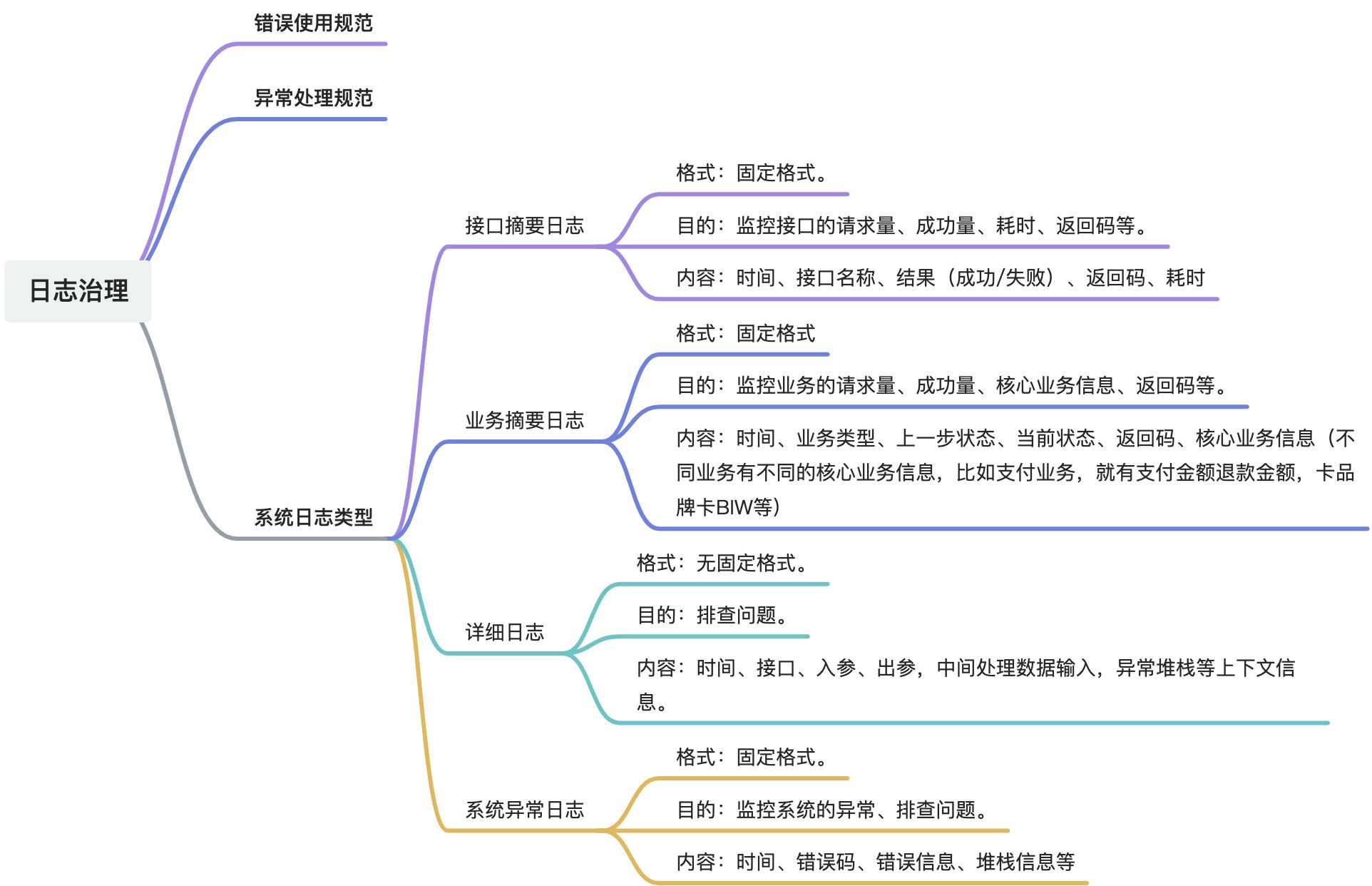
Java开发经验——日志治理经验
摘要 本文主要介绍了Java开发中的日志治理经验,包括系统异常日志、接口摘要日志、详细日志和业务摘要日志的定义和目的,以及错误码规范和异常处理规范。强调了日志治理的重要性和如何通过规范化错误码和日志格式来提高系统可观测性和问题排查效率。 1. …...
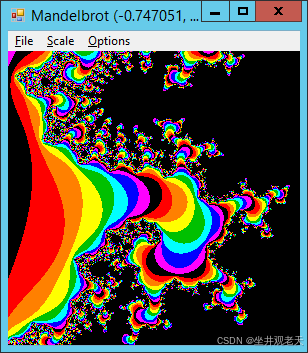
使用复数类在C#中轻松绘制曼德布洛集分形
示例在 C# 中绘制曼德布洛特集分形解释了如何通过迭代以下方程来绘制曼德布洛特集: 其中 Z(n) 和 C 是复数。程序迭代此方程,直到 Z(n) 的大小至少为 2 或程序执行最大迭代次数。 该示例在单独的变量中跟踪数字的实部和虚部。此示例使用Complex类来更轻松…...
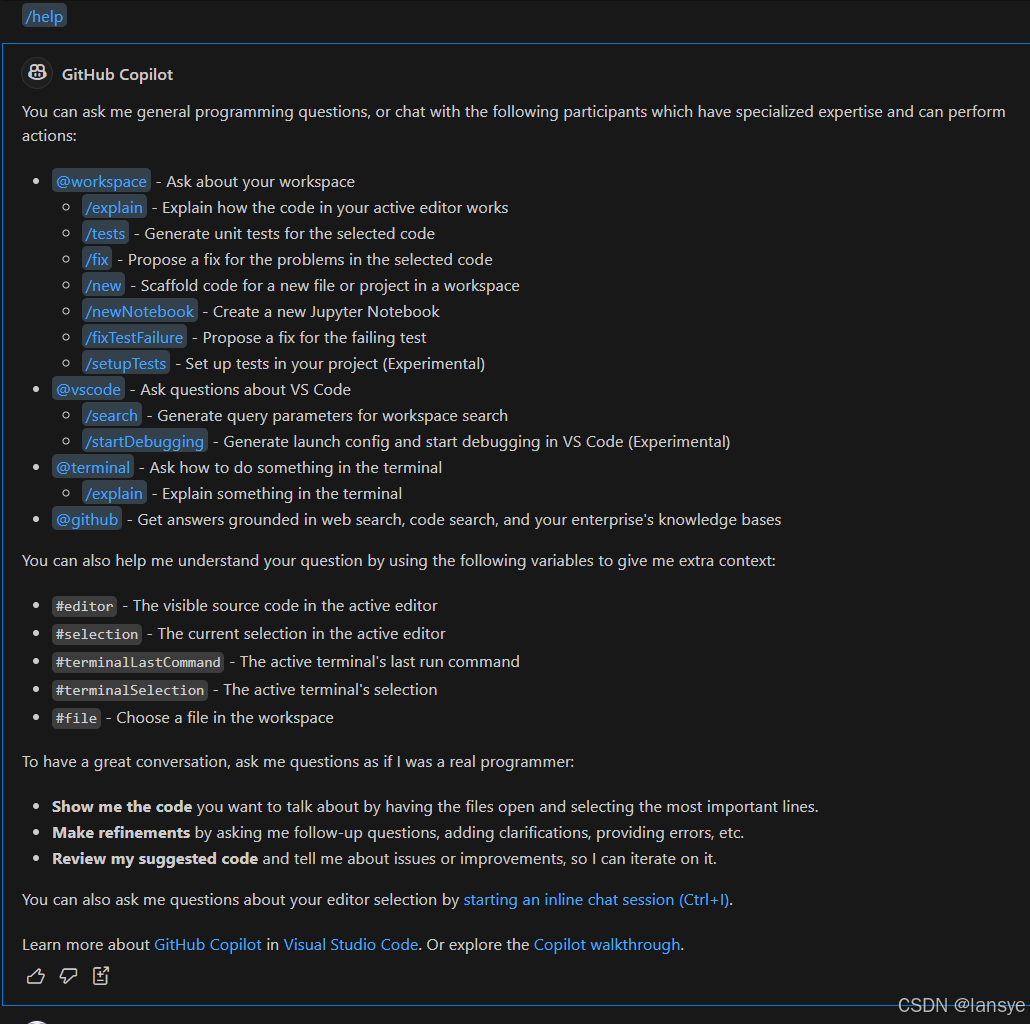
VSCode 启用免费 Copilot
升级VSCode到 1.96版本,就可以使用每个月2000次免费额度了,按照工作日每天近80次免费额度,满足基本需求。前两天一直比较繁忙,今天周六有时间正好体验一下。 引导插件安装GitHub Copilot - Visual Studio Marketplace Extension f…...

常见问题整理
DevOps 和 CICD DevOps 全称Development & Operation 一种实现开发和运维一体化的协同模式,提供快速交付应用和服务的能力 用于协作:开发,部署,质量测试 整体生命周期工作内容,最终实现持续继承,持续部…...

使用Vue创建前后端分离项目的过程(前端部分)
前端使用Vue.js作为前端开发框架,使用Vue CLI3脚手架搭建项目,使用axios作为HTTP库与后端API交互,使用Vue-router实现前端路由的定义、跳转以及参数的传递等,使用vuex进行数据状态管理,后端使用Node.jsexpress…...

【Springboot知识】Redis基础-springboot集成redis相关配置
文章目录 1. 添加依赖2. 配置Redis连接3. 配置RedisTemplate(可选)4. 使用RedisTemplate或StringRedisTemplate5. 测试和验证 集群配置在application.properties中配置在application.yml中配置 主从配置1. 配置Redis服务器使用配置文件使用命令行 2. 配置…...

网络安全概论——身份认证
一、身份证明 身份证明可分为以下两大类 身份验证——“你是否是你所声称的你?”身份识别——“我是否知道你是谁?” 身份证明系统设计的三要素: 安全设备的系统强度用户的可接受性系统的成本 实现身份证明的基本途径 所知:个…...

OpenHarmony-4.HDI 框架
HDI 框架 1.HDI介绍 HDI(Hardware Device Interface,硬件设备接口)是HDF驱动框架为开发者提供的硬件规范化描述性接口,位于基础系统服务层和设备驱动层之间,是连通驱动程序和系统服务进行数据流通的桥梁,是…...

leecode494.目标和
这道题目第一眼感觉就不像是动态规划,可以看出来是回溯问题,但是暴力回溯超时,想要用动态规划得进行一点数学转换 class Solution { public:int findTargetSumWays(vector<int>& nums, int target) {int nnums.size(),bagWeight0,s…...
)
在Spring中application 的配置属性(详细)
application 的配置属性。 这些属性是否生效取决于对应的组件是否声明为 Spring 应用程序上下文里的 Bean (基本是自动配置 的),为一个不生效的组件设置属性是没有用的。 multipart multipart.enabled 开启上传支持(默认&a…...

jvm符号引用和直接引用
在解析阶段中,符号引用和直接引用是Java类加载和内存管理中的重要概念,它们之间存在显著的区别。以下是对这两个概念的详细解析: 一、定义与特性 符号引用(Symbolic Reference) 定义:符号引用是编译器生成的用于表示类、方法、字段等的引用方式。特性: 独立性:符号引用…...

一文流:JVM精讲(多图提醒⚠️)
一文流系列是作者苦于技术知识学了-忘了,背了-忘了的苦恼,决心把技术知识的要点一笔笔✍️出来,一图图画出来,一句句讲出来,以求刻在🧠里。 该系列文章会把核心要点提炼出来,以求掌握精髓,至于其他细节,写在文章里,留待后续回忆。 目前进度请查看: :::info https:/…...
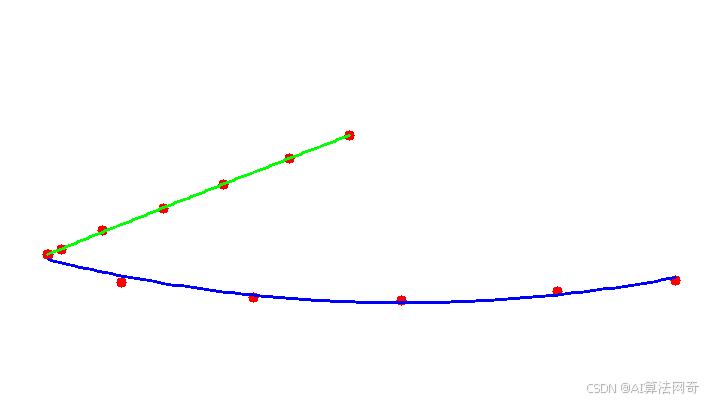
python 分段拟合笔记
效果图: 源代码: import numpy as np import cv2 import matplotlib.pyplot as plt from numpy.polynomial.polynomial import Polynomialdef nihe(x_points,y_points,p_id):# 按照 p_id 将 points 分成两组group_0_x = []group_0_y = []group_1_x = []group_1_y = []for i, …...

Mysql索引类型总结
按照数据结构维度划分: BTree 索引:MySQL 里默认和最常用的索引类型。只有叶子节点存储 value,非叶子节点只有指针和 key。存储引擎 MyISAM 和 InnoDB 实现 BTree 索引都是使用 BTree,但二者实现方式不一样(前面已经介…...

数据结构——队列的模拟实现
大家好,上一篇博客我带领大家进行了数据结构当中的栈的模拟实现 今天我将带领大家实现一个新的数据结构————队列 一:队列简介 首先来认识一下队列: 队列就像我们上学时的排队一样,有一个队头也有一个队尾。 有人入队的话就…...

在window环境下安装openssl生成钥私、证书和签名,nodejs利用express实现ssl的https访问和测试
在生成我们自己的 SSL 证书之前,让我们创建一个简单的 Express应用程序。 要创建一个新的 Express 项目,让我们创建一个名为node-ssl -server 的目录,用终端cmd中进入node-ssl-server目录。 cd node-ssl-server 然后初始化一个新的 npm 项目…...

Redis 最佳实践
这是以前写下来的文章,发出来备份一下 Redis 在企业中的最佳实践可以帮助提高性能、可用性和数据管理效率。以下是一些推荐的做法: 选择合适的数据结构: 根据需求选择适当的 Redis 数据结构(如 Strings、Lists、Sets、Hashes、So…...

网站灰度发布?Tomcat的8005、8009、8080三个端口的作用什么是CDNLVS、Nginx和Haproxy的优缺点服务器无法开机时
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默, 忍不住分享一下给大家。点击跳转到网站 学习总结 1、掌握 JAVA入门到进阶知识(持续写作中……) 2、学会Oracle数据库入门到入土用法(创作中……) 3、手把…...

从客户跟进到库存管理:看板工具赋能新能源汽车销售
在新能源汽车市场日益扩张的今天,门店销售管理变得更加复杂和重要。从跟踪客户线索到优化订单流程,再到团队协作,效率低下常常成为许多门店的“隐形成本”。如果你曾为销售流程不畅、客户管理混乱而苦恼,那么一种简单直观的工具—…...

从代码到知识图谱:构建交互式源码可视化分析工具
1. 项目概述:从“代码仓库”到“知识图谱”的跃迁在软件开发领域,我们每天都要面对海量的代码库。无论是为了复用轮子、学习最佳实践,还是为了理解一个庞大项目的架构,我们通常的做法是:克隆仓库、打开IDE、在文件和目…...
保姆级图解指南)
别再被hierarchy搞晕了!OpenCV cv2.findContours四种模式(RETR_*)保姆级图解指南
OpenCV轮廓检测全解析:四种层级模式与实战图解 轮廓检测是计算机视觉中最基础也最强大的工具之一,但很多开发者在面对cv2.findContours的层级参数时常常感到困惑。本文将用直观的可视化方式,带你彻底理解RETR_EXTERNAL、RETR_LIST、RETR_CCOM…...
)
英文论文怎么降AI?实测从88%降至20%的5大方法(附工具实测)
最近turnitin系统大升级,判定规则变得更加严格。很多不知道怎么给英文降ai的小伙伴对此都感到非常焦虑,检测报告里大面积的标蓝会导致稿件不合格被退回,手动降ai又要一直盯着屏幕改来改去,费时费力。 作为已经在这个领域摸爬滚打两…...

2026 AI企业推荐排行 技术创新榜 场景落地/全球布局 专业评测
一、摘要据赛迪顾问发布的《2026年全球AI技术创新与落地报告》显示,全球AI技术创新迭代速度持续加快,75%的企业将技术创新能力作为选型核心指标,62%的用户关注场景落地深度与全球化服务能力,46%的政企用户反映AI企业缺乏全流程技术…...

国央企备考求职精灵和粉笔APP哪个靠谱
每年国央企和事业单位招聘季,数百万求职者竞争激烈。面对庞大的招录名额、繁琐的笔试流程,选择合适的备考工具至关重要。市场上,粉笔是公考领域的老牌选手,而求职精灵 Genielink 作为 AI 原生工具也在改变着求职赛道格局。下面就对…...

MATLAB Robotics Toolbox避坑实战:用Kinova Gen3机械臂手把手教你搞定碰撞检测
MATLAB Robotics Toolbox避坑实战:用Kinova Gen3机械臂手把手教你搞定碰撞检测 在机器人仿真领域,碰撞检测是确保机械臂安全运行的核心技术。许多初学者在使用MATLAB Robotics System Toolbox时,往往会在环境建模、参数设置和结果解析等环节…...

飞凌嵌入式与中移物联战略合作:全国产化端云一体方案解析与实战
1. 项目概述:一次嵌入式领域的“国产化”深度握手最近在嵌入式圈子里,一个消息引起了不小的讨论:飞凌嵌入式与中移物联达成了战略合作。乍一看,这像是两家公司一次常规的商业合作新闻,但如果你对国内嵌入式硬件和物联网…...

如何高效使用星穹铁道抽卡数据分析工具:智能跃迁记录完整指南
如何高效使用星穹铁道抽卡数据分析工具:智能跃迁记录完整指南 【免费下载链接】star-rail-warp-export Honkai: Star Rail Warp History Exporter 项目地址: https://gitcode.com/gh_mirrors/st/star-rail-warp-export 你是否想知道自己在《崩坏:…...

如何突破网盘下载速度限制:LinkSwift直链解析工具全攻略
如何突破网盘下载速度限制:LinkSwift直链解析工具全攻略 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

EldenRingFPSUnlockAndMore:彻底解锁艾尔登法环性能限制的终极方案
EldenRingFPSUnlockAndMore:彻底解锁艾尔登法环性能限制的终极方案 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mi…...