如何使用Python WebDriver爬取ChatGPT内容(完整教程)
大背景
虽然我们能用网页版chatGPT来聊天、写文章,但是我们采集大量的内容,就得不断地手动输入提问来获取答案,并且将结果复制到数据库来保存。如果整个过程能使用程序来做自然要节省很多的人力,精力和时间。
Python webdirver 模拟浏览器的方式来实现,刚好能实现以上功能。
另外之所以不选择API 是因为以下原因:
-
普通开发者(国内)获取API KEY 是有困难的,需要海外手机号 + 信用卡等一系列条件,但是如果只是网页端,我们仅仅需要登录或者未登录的方式就可以直接聊天
-
网页端无需调整各项参数,可以直接交互获取内容,而且内容质量更高!
当然,如果你有条件用API 或者直接通过 wss交互获取内容的,到这儿可以直接结束了。
完整源码在文章末尾哦!
基本环境要求
准备自己的梯子
ChatGpt属于海外项目,国内的小伙伴,翻墙得找好自己的梯子(代理),这里自己有啥用啥即可。
安装Python 环境
Python要求:3.10 +
安装 Python Selenium
pip install selenium
其他扩展库说明:取决于自己电脑缺什么就安装什么。后面完整代码会提供完整的 requirements.txt
浏览器
这里以Chrome浏览器为准。也就是你本地必须要安装Chrome浏览器,并且获取其安装路径。
比如:C:Program FilesGoogleChromeApplicationchrome.exe
操作系统
这里以 windows 作为开发环境。
开发工具
自己什么顺手用什么。
这里讲个程序界的笑话:传说级别的开发者据说用的记事本来开发。
实现过程
这里只介绍主要的代码
浏览器控制
使用程序实现浏览器的控制,这包括浏览器的打开,关闭,以及代理配置。
创建 browser_manage.py
import subprocess, datetime
import os, signal, psutildef run_cmd(port=9200):cmd = [# chrome浏览器路径。 必须为首个参数'C:/Program Files/Google/Chrome/Application/chrome.exe',# 【必要】设置浏览器端口'--remote-debugging-port=%s' % port,# 【必要】设置浏览器数据存储路径'--user-data-dir=D:/data',# 隐藏一些弹窗之类的信息'--hide-crash-restore-bubble',# 设置浏览器分辨率。如果要跑多个浏览器可以将每个浏览器设置小一些'--force-device-scale-factor=1',# 假设代理地址为 http://127.0.0.1:10809'--proxy-server=http://127.0.0.1:10809',# 默认打开一个空白页面'about:blank']process = subprocess.Popen(cmd)# 返回pid 用于关闭浏览器杀死进程return process.piddef kill_process(parent_pid):try:# 获取父进程parent = psutil.Process(parent_pid)# 获取父进程的所有子进程(包括孙子进程等)children = parent.children(recursive=True)# 创建一个包含父进程PID的列表pids_to_kill = [parent_pid]# 将所有子进程的PID添加到列表中pids_to_kill.extend(child.pid for child in children)# 遍历列表,对每个PID发送SIGKILL信号for pid in pids_to_kill:try:os.kill(pid, signal.SIGILL)except PermissionError:# 忽略权限错误,可能我们没有权限杀死某个进程print("close browser PermissionError")passexcept ProcessLookupError:# 忽略进程查找错误,进程可能已经自然死亡print("close browser ProcessLookupError")passexcept (psutil.NoSuchProcess, PermissionError):# 忽略错误,如果进程不存在或者没有权限print("close browser PermissionError1")passreturn Truedef open_browser():"""打开浏览器"""# 打开指定端口的浏览器pid = run_cmd(9200)def close_borwser():"""关闭浏览器"""# pid 为打开浏览器获取到的进程idkill_process(pid)# 执行open_browser() 打开浏览器,执行 close_borwser() 关闭浏览器
初始化selenium
创建爬虫脚本 spider.py
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from fake_useragent import UserAgent
import subprocess, datetimechrome_options = Options()
ua = UserAgent()
# 浏览器端口信息,取决于启动浏览器设置的端口
browser_host = 9200
browser_host= "127.0.0.1"random_ua = ua.random
chrome_options.add_argument(f'user-agent={random_ua}')# 设置要连接的浏览器端口信息
chrome_options.add_experimental_option("debuggerAddress","%s:%s" % (browser_host, browser_port))
driver = webdriver.Chrome(options=chrome_options)
进入到目标页面
文件:spider.py
# 页面加载等待:最多10s
driver.implicitly_wait(10)
driver.get("https://chat.openai.com/")
页面等待除了以上的方案也可以用其他方法:
# 等待某个元素可见
try:element = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.XPATH, "//h1")))print(element.text)
finally:driver.quit()# 或者直接
time.sleep(10)
发起询问
发起新的提问
每次提问都应该是基于一个新窗口来提问。如果你的问题需要上下文的基础来回答,可以直接跳过这里。

新询问输入框可以根据 button data-testid=“create-new-chat-button” 来定位。
# 定位到新聊天元素
new_chat_dom = driver.find_element(By.CSS_SELECTOR, '[data-testid="create-new-chat-button"]')
# 发起点击,进入新界面
new_chat_dom.click()
定位到输入框
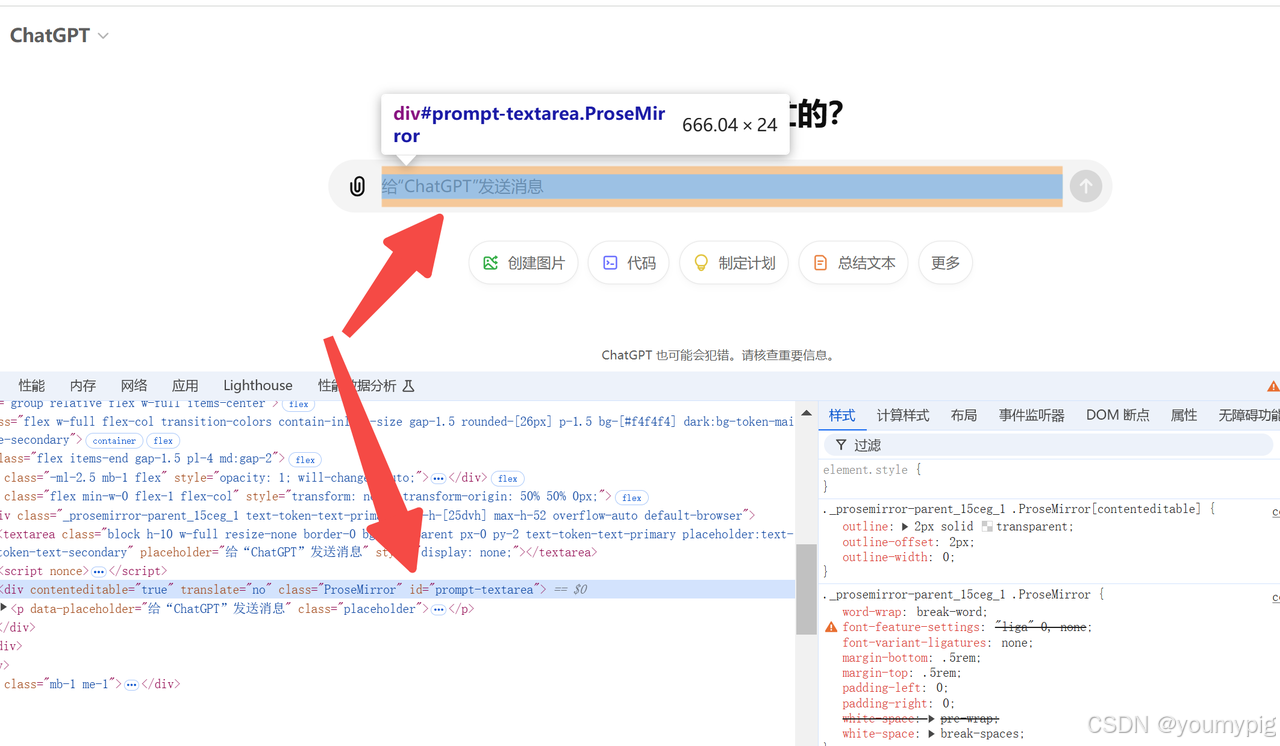
输入框使用的是div contentediable作为文本域。其id为 prompt-textarea
# 因为元素提供了id,则直接通过id获取最方便
textarea_dom = driver.find_element(By.ID, "prompt-textarea")
创建询问队列
因为我们的目标是自动化对问题列表发起询问,而不是一次性询问。所以需要创建一个问题队列。问题队列可以来源于数据库或者队列文件。这里为了演示,直接创建一个list
ask_list = ["请用Python写一个平均等分list的方案","请写一个关于小猪佩奇的笑话,要求:小猪佩奇可能不是猪,而是河马, 100字","称赞一个女生长得漂亮,如何不直接称赞也能看出来在形容她漂亮"
]
输入问题
这里我们按行来输入:一次输入一行。
for msg in ask_list:# 将字符串按换行分割开ask_msg_arr = msg.split('
')for msg_line in ask_msg_arr:textarea_dom.send_keys(ask_msg_item)# 发送textarea_dom.send_keys(Keys.ENTER)# TODO 这里是后续获取数据,存储到数据库环节
等待数据响应
可以根据回答结束后,出现的交互按钮来确认是否回答完毕
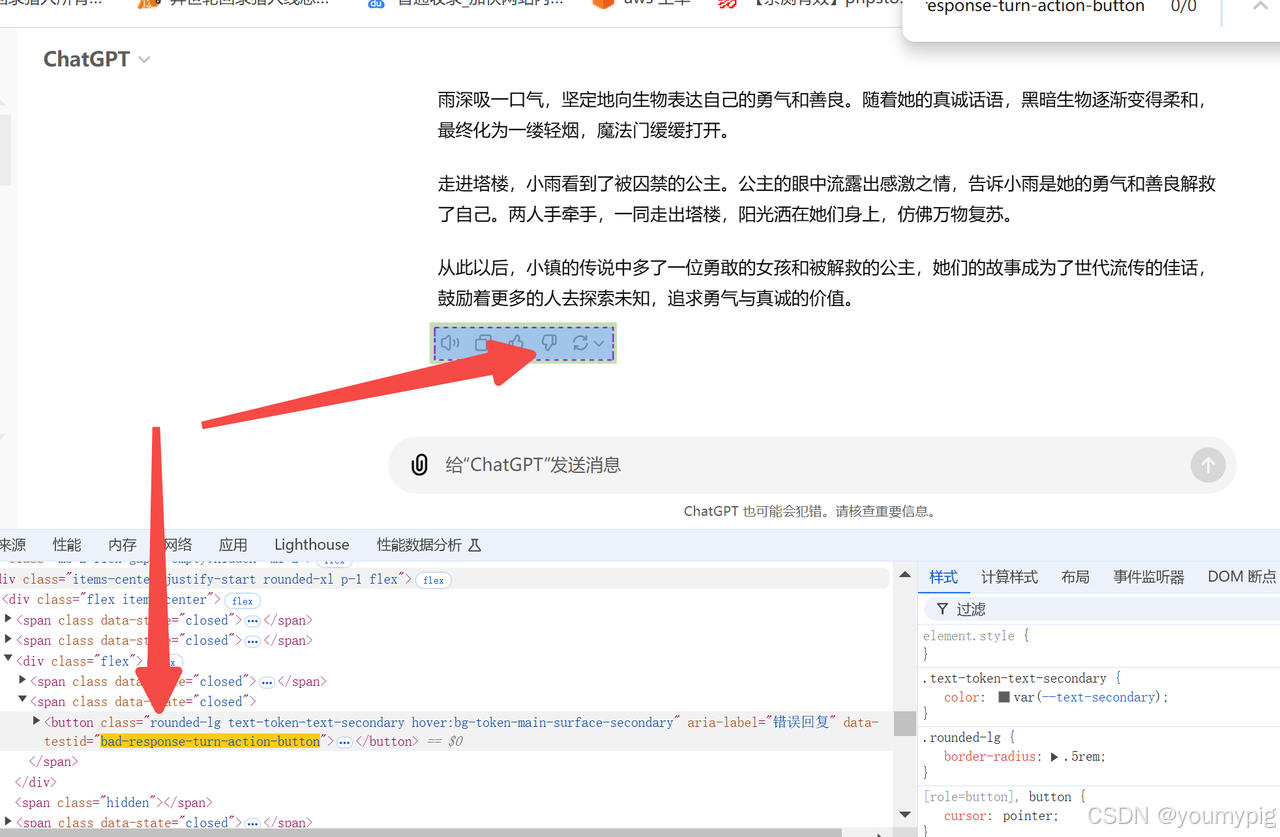
idx = 0
while True:idx = idx + 1# 请求超时if idx > 180:breaktime.sleep(1)try:driver.find_element(By.CSS_SELECTOR, '[data-testid="bad-response-turn-action-button"]') breakexcept:continue
也可以使用以下方法来校验:
# 设置最大等待时间
wait = WebDriverWait(driver, 180)
# 等待直到元素出现
element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[data-testid="bad-response-turn-action-button"]')))
获取响应数据
通过 class=“markdown” 来获取数据。
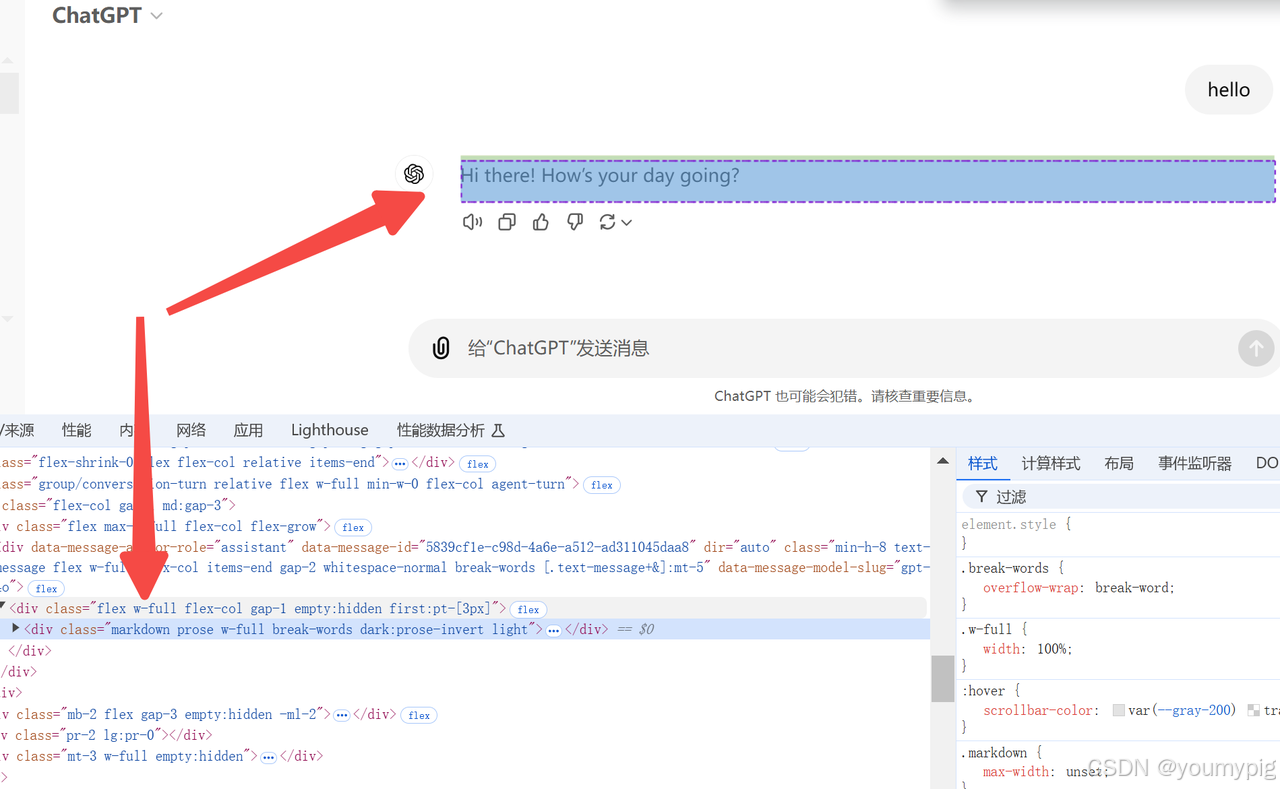
idx = 0
while True:idx = idx + 1# 请求超时if idx > 180:breaktime.sleep(1)try:html_dom = driver.find_element(By.CSS_SELECTOR, '.markdown') breakexcept:continuecontent = html_dom .get_attribute('innerHTML')
数据清洗
具体的清洗规则,看具体的业务需求。大多数清洗,需要将一些总结类的语句删除,不合法的返回内容删除。这里不提供相应的清洗的方案。
至此,一个完整的数据链就已经完结。
完整源码
browser.py
import subprocess, datetime
import os, signal, psutildef run_cmd(port=9200):cmd = [# chrome浏览器路径。'C:/Program Files/Google/Chrome/Application/chrome.exe',# 【必要】设置浏览器端口'--remote-debugging-port=%s' % port,# 【必要】设置浏览器数据存储路径'--user-data-dir=E:/browser_data',# 隐藏一些弹窗之类的信息'--hide-crash-restore-bubble',# 设置浏览器分辨率。如果要跑多个浏览器可以将每个浏览器设置小一些'--force-device-scale-factor=1',# 假设代理地址为 http://127.0.0.1:10809'--proxy-server=http://127.0.0.1:10809',# 默认打开一个空白页面'about:blank']process = subprocess.Popen(cmd)# 返回pid 用于关闭浏览器杀死进程return process.piddef kill_process(parent_pid):try:# 获取父进程parent = psutil.Process(parent_pid)# 获取父进程的所有子进程(包括孙子进程等)children = parent.children(recursive=True)# 创建一个包含父进程PID的列表pids_to_kill = [parent_pid]# 将所有子进程的PID添加到列表中pids_to_kill.extend(child.pid for child in children)# 遍历列表,对每个PID发送SIGKILL信号for pid in pids_to_kill:try:os.kill(pid, signal.SIGILL)except PermissionError:# 忽略权限错误,可能我们没有权限杀死某个进程print("close browser PermissionError")passexcept ProcessLookupError:# 忽略进程查找错误,进程可能已经自然死亡print("close browser ProcessLookupError")passexcept (psutil.NoSuchProcess, PermissionError):# 忽略错误,如果进程不存在或者没有权限print("close browser PermissionError1")passreturn Truedef open_browser():"""打开浏览器"""# 打开指定端口的浏览器pid = run_cmd(9200)return piddef close_browser(pid):"""关闭浏览器"""# pid 为打开浏览器获取到的进程idkill_process(pid)pid = open_browser()
print(pid)# close_browser(25996)
spider.py
import time
import tracebackfrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from fake_useragent import UserAgent
import subprocess, datetime
import oschrome_options = Options()
ua = UserAgent()
# 浏览器端口信息,取决于启动浏览器设置的端口
browser_port = 9200
browser_host = "127.0.0.1"random_ua = ua.random
chrome_options.add_argument(f'user-agent={random_ua}')# 设置要连接的浏览器端口信息
chrome_options.add_experimental_option("debuggerAddress", "%s:%s" % (browser_host, browser_port))
driver = webdriver.Chrome(options=chrome_options)def open_gpt_page():driver.implicitly_wait(10)driver.get("https://chat.openai.com/")def new_chat():"""该方案当前只适用于已经登录到chatgpt的页面。不适用非的登录页面"""# 定位到新聊天元素new_chat_dom = driver.find_element(By.CSS_SELECTOR, '[data-testid="create-new-chat-button"]')# 发起点击,进入新界面new_chat_dom.click()def get_input_box():return driver.find_element(By.ID, "prompt-textarea")def get_ask_list():return ["请用Python写一个平均等分list的方案","请写一个关于小猪佩奇的笑话,要求:小猪佩奇可能不是猪,而是河马, 100字","称赞一个女生长得漂亮,如何不直接称赞也能看出来在形容她漂亮"]def get_response():# 等待响应完成idx = 0while True:idx = idx + 1# 请求超时if idx > 180:breaktime.sleep(1)try:driver.find_element(By.CSS_SELECTOR, '[data-testid="bad-response-turn-action-button"]')breakexcept:continue# 获取请求结果idx = 0content = Nonewhile True:idx = idx + 1# 请求超时if idx > 180:breaktime.sleep(1)try:html_dom = driver.find_element(By.CSS_SELECTOR, '.markdown')content = html_dom.get_attribute('innerHTML')breakexcept:continuereturn contentdef simulator(ask_msg):# 进入输入框并且点击print("进入输入框并且点击")textarea_dom = get_input_box()textarea_dom.click()# 发送ask_msg_arr = ask_msg.split('
')for msg_line in ask_msg_arr:textarea_dom.send_keys(msg_line)textarea_dom.send_keys(Keys.ENTER)# 获取响应content = get_response()# 保存数据到文件root_path = "./data"os.makedirs(root_path, exist_ok=True)full_path = f"{root_path}/%s.text" % int(time.time())with open(full_path, 'w', encoding='utf-8') as file:file.write(content)print("save success")def start():open_gpt_page()print("页面加载完毕")time.sleep(3)ask_list = get_ask_list()for ask_msg in ask_list:time.sleep(3)print("进入新的聊天")new_chat()print("current msg %s" % ask_msg)for retry in range(0,3):try:simulator(ask_msg)breakexcept:print(traceback.format_exc())time.sleep(10)passstart()
requirements.txt
fake_useragent==1.2.1
psutil==5.9.5
selenium==4.26.1
获取扩展源码
扩展源码是基于 chatgpt聊天页面,通过多个浏览器并行数据爬取,包含以下功能:
-
基于数据库创建问题队列
-
创建多个浏览器窗口多线程并行运行,提高产量和效率
-
解决人工校验-自动化进行人工校验
-
为多个浏览器配置不同的代理方案
-
代理配置,为浏览器自动化分配代理,
-
通过web端进行浏览器管理,代理管理,代理分配等
需要以上扩展源码,QQ:1186969412
相关文章:
如何使用Python WebDriver爬取ChatGPT内容(完整教程)
大背景 虽然我们能用网页版chatGPT来聊天、写文章,但是我们采集大量的内容,就得不断地手动输入提问来获取答案,并且将结果复制到数据库来保存。如果整个过程能使用程序来做自然要节省很多的人力,精力和时间。 Python webdirver …...

WSL切换默认发行版
查看适用于wsl的子系统有哪些: wslconfig /list 设置wsl的默认发行版 wslconfig /setdefault Ubuntu-20.04...

全志H618 Android12修改doucmentsui功能菜单项
背景: 由于当前的文件管理器在我们的产品定义当中,某些界面有改动的需求,所以需要在Android12 rom中进行定制以符合当前产品定义。 需求: 在进入File文件管理器后,查看...功能菜单时,有不需要的功能菜单,需要隐藏,如:新建窗口、不显示的文件夹、故代码分析以及客制…...

移动网络(2,3,4,5G)设备TCP通讯调试方法
背景: 当设备是移动网络设备连接云平台的时候,如果服务器没有收到网络数据,移动物联设备发送不知道有没有有丢失数据的时候,需要一个抓取设备出来的数据和服务器下发的数据的方法。 1.服务器系统是很成熟的,一般是linu…...

网络安全概论——入侵检测系统IDS
一、入侵检测的概念 1、入侵检测的概念 检测对计算机系统的非授权访问对系统的运行状态进行监视,发现各种攻击企图、攻击行为或攻击结果,以保证系统资源的保密性、完整性和可用性识别针对计算机系统和网络系统或广义上的信息系统的非法攻击,…...

Linux通信System V:消息队列 信号量
Linux通信System V:消息队列 & 信号量 一、信号量概念二、信号量意义三、操作系统如何管理ipc资源(2.36版本)四、如何对信号量资源进行管理 一、信号量概念 信号量本质上就是计数器,用来保护共享资源。多个进程在进行通信时&a…...

计算机网络基础图解
注:本文为来自 猿小许 的 “计算机网络” 相关系列文章合辑。 一、计算机网络概述 猿小许于 2021-06-03 18:39:47 发布 一、计算机网络的概念 1.1 计算机网络 概念 计算机网络: 是一个将分散的、具有独立功能的计算机系统,通过通信设备与…...

TDesign:NavBar 导航栏
NavBar 导航栏 左图,右标 appBar: TDNavBar(padding: EdgeInsets.only(left: 0,right: 30.w), // 重写左右内边距centerTitle:false, // 不显示标题height: 45, // 高度titleWidget: TDImage( // 左图assetUrl: assets/img/logo.png,width: 147.w,height: 41.w,),ba…...

hive注释comment中文乱码解决
问题描述 当使用以下命令查看表的元数据信息时出现中文乱码(使用的是idea连接hive) desc formatted test.t_archer; 解决 连接保存hive元数据的MySQL数据库,执行以下命令: use hive3; show tables;alter table hive3.COLUMNS_…...

电脑提示ntdll.d缺失是什么原因?不处理的话会怎么样?ntdll.dll文件缺失快速解决方案来啦!
电脑提示ntdll.dll缺失:原因、影响与解决方案 在日常的电脑使用中,我们偶尔会遇到一些令人困惑的系统错误,其中“ntdll.dll缺失”便是较为常见的一种。作为软件开发从业者,我深知这一错误给用户带来的不便,因此&#…...

MFC/C++学习系列之简单记录——序列化机制
MFC/C学习系列之简单记录——序列化机制 前言简述六大机制序列化机制使用反序列化总结 前言 MFC有六大机制,分别是程序启动机制、窗口创建机制、动态创建机制、运行时类信息机制、消息映射机制、序列化机制。 简述六大机制 程序启动机制:全局的应用程序…...
二十、服务发布Ingress
Ingress Kubernetes使用了一个Ingress策略定义和一个具体提供转发服务的Ingress Controller,两者结合,实现了基于灵活Ingress策略定义的服务路由功能。如果是对Kubernetes集群外部的客户端提供服务,那么IngressController实现的是类似于边缘路由器(Edge Router)的功能。需…...

计算机网络 八股青春版
什么是HTTP?HTTP和HTTPS的区别 HTTP HTTP是超文本运输协议,是一种无状态(每次请求都是独立的)的应用层协议。用于在客户端和服务器之间传输超文本数据(如HTML文件)。默认端口是80数据以明文形式传输&#…...

java全栈day18--Web后端实战(java操作数据库2)
前言:在上节入门程序当中我们见到了JDBC所提供的API,本节来详细说明一下。 一、JDBC--API详解 1.1DriverManager(驱动管理器) 回顾:作用获取连接,调用它里面的getConnection。即如下 作用 1.注册驱动解…...

electron-vite【实战】自定义标题栏【组件封装】(含异形标题栏,指定区域拖拽,窗口置顶,窗口最小化,窗口最大化,取消最大化,隐藏窗口到托盘等)
效果预览 技术要点 透明背景 src/main/index.ts 的 new BrowserWindow 中添加 transparent: true, // 设置窗口背景透明frame: false, // 隐藏窗口边框仅图标和标题部分可拖拽 仅图标和标题部分添加样式 drag .drag {-webkit-app-region: drag; }图标与标题栏的融合 标题栏的…...

vue2 项目webpack 4升5
项目背景 公司项目需要将进行微前端改造.主应用和子应用会需要共享依赖,考虑使用模块联邦进行依赖共享. 由于模块联邦要升级到webpack 5才能用,所以老项目要从webpack 4升级到webpack 5 实现思路 原来的项目用的是vue-cli 3,查了一下可以vue-cli 5用的就是webpack 5,所以可以…...

前端开发性能监控中的数据采集与性能调优方法
🌟 前端开发性能监控中的数据采集与性能调优方法 📖 前言 在现代 Web 应用中,性能是用户体验的关键因素之一。性能问题不仅会影响用户满意度,还可能导致业务损失。如何高效地监控前端性能并进行性能调优,成为每个开发…...

S32K324 Stack异常分析及解决方案
文章目录 前言正向排查尝试反向排查问题原因分析问题解决处理总结前言 在项目开发过程中,在一次软件变更时,调整了task优先级之后导致应用层软件中的float数据经常性的变为NAN,导致应用层功能失效。本文记录下这个bug的分析及解决过程。 正向排查尝试 由于问题复现的概率…...

[创业之路-202]:任正非管理华为的思想与毛泽东管理党、军队、国家的思想的相似性与差异性
目录 一、相似性 1、指导思想 2、管理策略 3、危机意识与自我否定 4、理想主义与奋斗精神 二、差异性 1、哲学基础与思想倾向 2、管理方法与策略 3、组织文化与价值观 一、相似性 任正非管理华为的思想与毛泽东管理党、军队、国家的思想在多个方面存在相似性。 以下…...

SAP PP ECN CSAP_MAT_BOM_MAINTAIN
刚开始的时候ECN总是加不上, 参考kimi给出的案例 点击链接查看和 Kimi 智能助手的对话 https://kimi.moonshot.cn/share/cth1ipmqvl7f04qkggdg 效果 加上了 FUNCTION ZPBOM_PLM2SAP. *"------------------------------------------------------------------…...

【行业趋势】软件测试的第三次革命:从手工、自动化到AI Agent驱动
写在前面 如果你是一名测试工程师,大概率经历过这样的时刻:凌晨两点,被自动化回归失败的告警吵醒,爬起来一看,又是页面改了个按钮ID,三百条用例全红了。修了一小时定位器,天亮了。 如果你是一名…...

这几家有机膨润土厂家口碑稳定,你选对了吗?
在工业与新材料领域,有机膨润土作为一种关键的功能性添加剂,正从“幕后”走向“台前”。无论是涂料、油墨的流变控制,还是钻井液、润滑脂的耐温需求,又或是农药、兽药的载体优化,它的身影无处不在。然而,面…...

告别VirtualBox的‘不是Host-Only适配器’错误:一个网络配置的深度修复指南
VirtualBox Host-Only网络故障全解析:从原理到实战修复 当你正准备启动VirtualBox中的开发环境虚拟机时,突然弹出的红色错误提示框让所有工作戛然而止——"Interface is not a Host-Only Adapter"。这个看似简单的网络适配器错误背后…...

Node.js框架深度解析:从Express到Nest.js,如何选择最适合你的Web开发框架?
1. 项目概述:为什么Node.js框架值得你花时间研究?如果你是一名Web开发者,或者正在向这个方向转型,那么“Node.js框架”这个词组对你来说一定不陌生。但面对市面上林林总总的框架,从Express、Koa到Nest.js、Fastify&…...

Vidupe:3步快速清理重复视频的终极免费解决方案
Vidupe:3步快速清理重复视频的终极免费解决方案 【免费下载链接】vidupe Vidupe is a program that can find duplicate and similar video files. V1.211 released on 2019-09-18, Windows exe here: 项目地址: https://gitcode.com/gh_mirrors/vi/vidupe 您…...

CrapFixer深度解析:为什么这个7年老工具依然是Windows优化的首选
CrapFixer深度解析:为什么这个7年老工具依然是Windows优化的首选 【免费下载链接】Crapfixer Cr*ap Fixer 项目地址: https://gitcode.com/gh_mirrors/cr/Crapfixer 在Windows 11和Windows 10系统中,你是否厌倦了无处不在的广告、烦人的数据收集和…...

cstore_fdw迁移指南:从传统表到列式存储的无缝切换
cstore_fdw迁移指南:从传统表到列式存储的无缝切换 【免费下载链接】cstore_fdw Columnar storage extension for Postgres built as a foreign data wrapper. Check out https://github.com/citusdata/citus for a modernized columnar storage implementation bui…...
)
ArcGIS Pro 3.x 批量处理遥感栅格:用Python脚本实现自动化转点、计算与导出(附完整代码)
ArcGIS Pro 3.x 遥感栅格自动化处理实战:从数据清洗到生产级流水线构建 遥感数据分析师常常需要处理TB级的时序栅格数据,比如月度NDVI指数、地表温度或降水分布。传统手动操作不仅效率低下,还容易因人为失误导致数据不一致。本文将分享如何基…...

hot100 11盛最多水的容器
题目描述 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你不能倾斜容…...

Unity URP专业UI模糊效果实战指南:4步实现高性能毛玻璃界面
Unity URP专业UI模糊效果实战指南:4步实现高性能毛玻璃界面 【免费下载链接】Unified-Universal-Blur UI blur (translucent) effect for Unity. 项目地址: https://gitcode.com/gh_mirrors/un/Unified-Universal-Blur 在Unity游戏开发中,UI界面的…...