潜在狄利克雷分配LDA 算法深度解析
引言
潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)是一种广泛应用于文本挖掘和信息检索领域的主题模型。它能够从文档集合中自动发现隐藏的主题结构,为理解大规模文本数据提供了强有力的工具。本文将着重讲解 LDA 的核心理论,并详细介绍其数学基础与推导过程,帮助读者更好地掌握这一技术。
一、LDA 算法核心理论

1.1 概率图模型架构
LDA 是一种基于概率图模型的框架,用于建模文档中的主题分布。其结构包括三层:
- 词层:表示词汇表中的所有单词。
- 主题层:代表文档中可能涉及的不同主题。
- 文档层:对应实际的文档集合。
LDA 的关键假设是:
- 文档到主题的转换服从狄利克雷分布(Dirichlet Distribution),即每个文档都有一个特定的主题分布。
- 主题到词的转换则服从多项式分布(Multinomial Distribution),意味着每个主题关联着一个关于词汇的概率分布。
例如,对于一个包含多篇文档的集合,每篇文档都有一组主题占比(如体育、娱乐、科技等),而每个主题下有不同的词汇出现概率(如体育主题下的“比赛”、“运动员”)。这种三层结构和分布假设使得 LDA 能够对文本数据进行有效的主题建模。
图形化表示
LDA 的生成过程可以用图形化的方式表示:
文档 → 主题 → 单词
其中,箭头表示抽取关系,从文档节点指向主题节点按照主题分布抽取主题,再从主题节点指向单词节点按照单词分布抽取单词。
1.2 文档生成过程
LDA 中的文档生成是一个基于概率的逐步抽取过程:
- 抽取主题:根据文档的主题分布(从狄利克雷分布中抽取),随机选择一个主题。
- 抽取单词:根据选定主题的词汇分布(从多项式分布中抽取),随机选择一个单词。
- 重复步骤:上述过程重复进行,直到生成完整的文档。
这个生成过程可以图形化地表示为从文档节点指向主题节点再指向单词节点的链路,形成完整的文档生成路径。
示例代码
import numpy as npdef generate_document(alpha, beta, vocab_size, num_topics, doc_length):# 抽取文档的主题分布theta = np.random.dirichlet(alpha, size=1)[0]# 初始化文档document = []for _ in range(doc_length):# 抽取主题topic = np.random.choice(num_topics, p=theta)# 抽取单词word_dist = np.random.multinomial(1, beta[topic])word = np.argmax(word_dist)document.append(word)return document# 参数设置
alpha = [0.1] * 5 # 假设5个主题
beta = np.random.dirichlet([0.1] * 100, size=5) # 假设100个词汇
vocab_size = 100
num_topics = 5
doc_length = 100# 生成文档
document = generate_document(alpha, beta, vocab_size, num_topics, doc_length)
print(document)
二、LDA 数学基础与推导
2.1 狄利克雷分布与多项式分布
LDA 的数学基础在于狄利克雷分布和多项式分布之间的共轭关系。这两个分布的特性使得贝叶斯推断过程中后验分布依然是狄利克雷分布,从而简化了计算。
2.1.1 狄利克雷分布
狄利克雷分布(Dirichlet Distribution)是多项式分布的共轭先验,用于描述多个类别(或主题)的概率分布情况。它的概率密度函数为:
p ( θ ∣ α ) = 1 B ( α ) ∏ i = 1 K θ i α i − 1 p(\theta | \alpha) = \frac{1}{B(\alpha)} \prod_{i=1}^K \theta_i^{\alpha_i - 1} p(θ∣α)=B(α)1i=1∏Kθiαi−1
其中, θ \theta θ 是一个 ( K (K (K) 维向量,表示各个类别的概率; ( α (\alpha (α) 是超参数向量,控制这些类别的初始权重; ( B ( α ) (B(\alpha) (B(α)) 是归一化常数,确保总和为 1。
2.1.2 多项式分布
多项式分布(Multinomial Distribution)描述了给定主题下单词的出现频率。它的概率质量函数为:
p ( w ∣ θ ) = n ! ∏ i = 1 V n i ! ∏ i = 1 V θ i n i p(w | \theta) = \frac{n!}{\prod_{i=1}^V n_i!} \prod_{i=1}^V \theta_i^{n_i} p(w∣θ)=∏i=1Vni!n!i=1∏Vθini
其中, ( w (w (w) 表示单词序列; ( θ (\theta (θ) 表示各个类别的概率; ( n i (n_i (ni) 表示单词 ( i (i (i) 出现的次数; ( n (n (n) 是总的单词数量。
2.1.3 共轭性
狄利克雷分布和多项式分布的共轭性意味着,如果先验分布是狄利克雷分布,那么在观测到多项式分布的数据后,后验分布仍然是狄利克雷分布。具体来说:
p ( θ ∣ w , α ) = Dir ( θ ∣ α + n ) p(\theta | w, \alpha) = \text{Dir}(\theta | \alpha + n) p(θ∣w,α)=Dir(θ∣α+n)
其中, ( n (n (n) 是观测到的单词频次向量。
2.2 模型参数估计方法
2.2.1 变分推断(Variational Inference)
变分推断通过构建一个简单且易于计算的变分分布来逼近复杂的后验分布,优化变分分布的参数以最小化两个分布间的差异。具体来说,我们希望找到一个近似分布 ( q ( θ , z ) (q(\theta, z) (q(θ,z)),使得它尽可能接近真实的后验分布 p ( θ , z ∣ w , α , β ) p(\theta, z | w, \alpha, \beta) p(θ,z∣w,α,β))。
变分推断的目标是最小化 Kullback-Leibler 散度:
[ min q D K L ( q ( θ , z ) ∥ p ( θ , z ∣ w , α , β ) ) [ \min_q D_{KL}(q(\theta, z) \| p(\theta, z | w, \alpha, \beta)) [minqDKL(q(θ,z)∥p(θ,z∣w,α,β))]
通过引入拉格朗日乘子并求解优化问题,我们可以得到变分分布的更新规则。
2.2.2 Gibbs 采样(Gibbs Sampling)
Gibbs 采样是一种马尔科夫链蒙特卡洛(MCMC)方法,通过逐个更新每个单词的主题分配,经过多轮迭代后得到稳定的参数估计。具体来说,对于每个单词 w i w_i wi),我们根据当前估计的模型参数,计算其属于不同主题的概率,并重新抽样新的主题分配。
Gibbs 采样的更新公式为:
p ( z i = k ∣ z − i , w , α , β ) ∝ n − i ( k ) + α k n − i ( ⋅ ) + ∑ k α k × n w i , − i ( k ) + β w n ⋅ , − i ( k ) + ∑ w β w p(z_i = k | z_{-i}, w, \alpha, \beta) \propto \frac{n^{(k)}_{-i} + \alpha_k}{n^{(\cdot)}_{-i} + \sum_k \alpha_k} \times \frac{n^{(k)}_{w_i, -i} + \beta_w}{n^{(k)}_{\cdot, -i} + \sum_w \beta_w} p(zi=k∣z−i,w,α,β)∝n−i(⋅)+∑kαkn−i(k)+αk×n⋅,−i(k)+∑wβwnwi,−i(k)+βw
其中, ( z − i (z_{-i} (z−i) 表示除 (w_i) 外其他单词的主题分配; ( n − i ( k ) (n^{(k)}_{-i} (n−i(k)) 表示主题 ( k (k (k) 在文档中出现的次数(不包括 ( w i (w_i (wi)); ( n w i , − i ( k ) (n^{(k)}_{w_i, -i} (nwi,−i(k)) 表示单词 ( w i (w_i (wi) 在主题 ( k (k (k) 下出现的次数(不包括 ( w i (w_i (wi))。
2.2.3 实例推导
为了更清晰地理解参数估计过程,我们可以通过一个简单的例子来说明变分推断和 Gibbs 采样的应用。
假设我们有一个包含 3 篇文档的语料库,每篇文档有 5 个单词,总共 100 个不同的词汇,设定 5 个主题。首先,我们需要初始化参数 (\alpha) 和 (\beta),然后使用变分推断或 Gibbs 采样逐步更新这些参数,直到收敛。
# Gibbs采样实现
import numpy as np# 假设数据
docs = [[0, 1, 2, 3, 4],[2, 3, 4, 5, 6],[4, 5, 6, 7, 8]
]
V = 100 # 词汇量
K = 5 # 主题数量
D = len(docs) # 文档数量# 初始化参数
alpha = np.array([0.1] * K)
beta = np.random.dirichlet(np.ones(V), K)# 初始化主题分配
z = [[np.random.randint(0, K) for w in doc] for doc in docs]# 迭代更新
for iteration in range(1000):for d, doc in enumerate(docs):for n, word in enumerate(doc):# 移除当前单词的主题分配topic = z[d][n]beta[topic, word] -= 1alpha[topic] -= 1# 计算当前单词属于每个主题的概率p_z = (beta[:, word] + alpha) * np.sum([z[d] == k for k in range(K)], axis=0)p_z /= np.sum(p_z)# 重新采样主题new_topic = np.random.choice(range(K), p=p_z)z[d][n] = new_topic# 更新参数beta[new_topic, word] += 1alpha[new_topic] += 1# 输出文档-主题分布和主题-词分布
theta = np.array([np.bincount(z[d], minlength=K) + alpha for d in range(D)]) / np.sum([np.bincount(z[d], minlength=K) + alpha for d in range(D)], axis=1)[:, np.newaxis]
phi = beta + np.ones((K, V))
phi /= np.sum(phi, axis=1)[:, np.newaxis]print("Document-Topic Distribution (theta):")
print(theta)
print("Topic-Word Distribution (phi):")
print(phi)2.3 实际应用中的问题
尽管 LDA 在理论上具有强大的建模能力,但在实际应用中也面临一些问题:
- 主题数量的选择:LDA 需要预先设定主题数量,这在实际应用中可能难以确定。
- 计算复杂度:对于大规模数据集,LDA 的计算复杂度较高,需要多次迭代计算参数。
- 异常值敏感性:LDA 对异常值较为敏感,可能导致模型生成的主题不准确或分类边界偏移。
为了应对这些问题,研究人员提出了多种优化策略,如在线学习、分布式计算、稀疏技术、硬件加速等,以提升 LDA 的计算效率和适应大数据场景的能力。
结论
本文对 LDA 算法进行了剖析,其重点在其核心理论和数学基础。LDA 作为一种强大的主题模型,在文本挖掘和信息检索中展现了重要的应用价值。通过适当的优化方法,可以使LDA在实际问题解决中发挥重要作用。
参考文献
- Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3, 993-1022.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Hofmann, T. (1999). Probabilistic Latent Semantic Analysis. Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence.
相关文章:
潜在狄利克雷分配LDA 算法深度解析
引言 潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)是一种广泛应用于文本挖掘和信息检索领域的主题模型。它能够从文档集合中自动发现隐藏的主题结构,为理解大规模文本数据提供了强有力的工具。本文将着重讲解 LDA 的核心理论&#x…...

[x86 ubuntu22.04]双触摸屏的触摸事件都响应在同一个触摸屏上
1 问题描述 CPU:G6900E OS:ubuntu22.04 Kernel:6.8.0-49-generic 系统下有两个一样的 edp 触摸屏,两个触摸屏的触摸事件都响应在同一个 edp 屏幕上。 2 解决过程 使用“xinput”命令查看输入设备,可以看到只有一个 to…...

重温设计模式--代理模式
文章目录 定义UML图代理模式主要有以下几种常见类型:代理模式涉及的主要角色有:C 代码示例 定义 代理模式(Proxy Pattern)属于结构型设计模式,它为其他对象提供一种代理以控制对这个对象的访问。 通过引入代理对象&am…...

一些elasticsearch重要概念与配置参数
ES 是在 lucene 的基础上进行研发的,隐藏了 lucene 的复杂性,提供简单易用的 RESTful Api接口。ES 的分片相当于 lucene 的索引。 Node 节点的几种部署实例 实例一: 只用于数据存储和数据查询,降低其资源消耗率 node.master: false node.da…...

leetcode 面试经典 150 题:螺旋矩阵
链接螺旋矩阵题序号54题型二维数组(矩阵)解题方法模拟路径法难度中等熟练度✅✅✅ 题目 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3…...

JAVA AOP简单实践(基于SpringBoot)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...
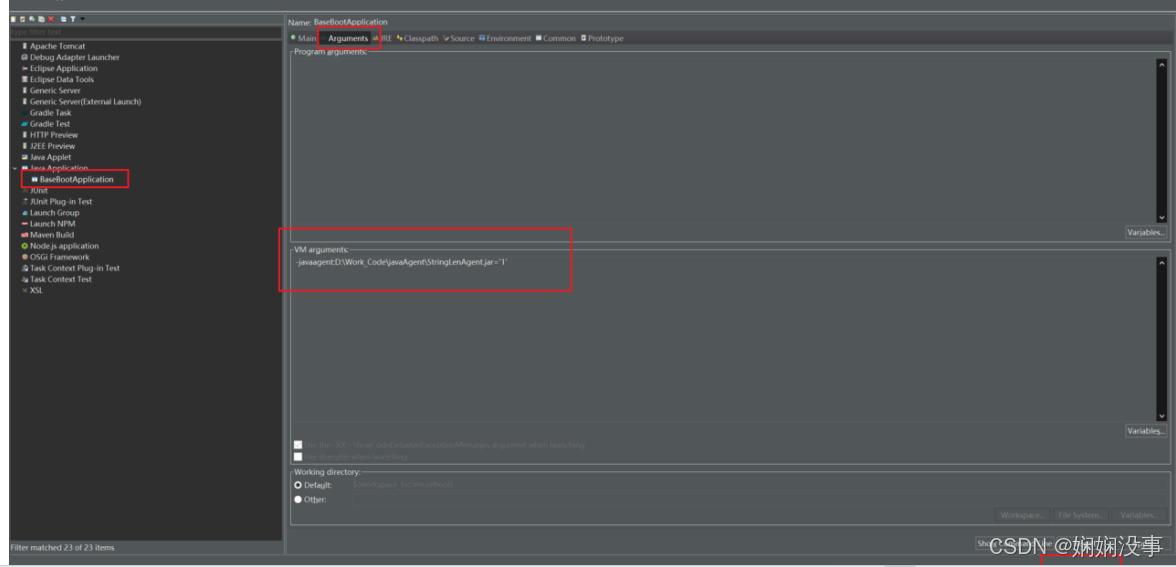
java agent的使用【通俗易懂版】
一、静态代理Agent 1.生成Agent的jar包 (1)创建Agent项目,引入javassist.jar包 (2)编写premain方法 import java.lang.instrument.Instrumentation;public class Agent1 {public static void premain(Stri…...

大模型学习指南
随着人工智能的迅猛发展,大模型成为了技术前沿的璀璨明星。踏入大模型学习领域,需要在多个关键方面下功夫。 扎实的数学功底是基石。线性代数为理解多维数据、矩阵运算提供支撑,像大模型中权重矩阵的处理就离不开它;概率论与数理…...
(附带源码))
单片机:实现定时器中断(数码管读秒+LED闪烁)(附带源码)
单片机实现定时器中断:数码管读秒与LED闪烁 在单片机项目中,定时器中断是一个常见的应用,用于实现定时任务,例如定时更新显示或控制周期性事件。本文将介绍如何使用定时器中断实现数码管读秒和LED闪烁功能。通过使用定时器中断&a…...

STM32单片机芯片与内部33 ADC 单通道连续DMA
目录 一、ADC DMA配置——标准库 1、ADC配置 2、DMA配置 二、ADC DMA配置——HAL库 1、ADC配置 2、DMA配置 三、用户侧 1、DMA开关 (1)、标准库 (2)、HAL库 2、DMA乒乓 (1)、标准库 ÿ…...

【0376】Postgres内核 分配 last safe MultiXactId
上一篇: 【0375】Postgres内核 XLOG 之 设置下一个待分配 MultiXactId 和 offset 文章目录 1. 最后一个安全的 MultiXactId1.1 计算 multi wrap limit1.2 计算 multi stop limit1.3 计算 multi warn limit1.4 计算 multi vacuum limit2. 初始化 MultiXactState 成员3. 完成 mu…...

php时间strtotime函数引发的问题 时间判断出错
在 PHP 中,strtotime 函数能处理的最大时间范围取决于您的系统和 PHP 版本。 一般来说,它可以处理的时间范围从 1901 年 12 月 13 日到 2038 年 1 月 19 日。超过这个范围可能会导致不可预测的结果或错误。 如果您需要处理更大范围的时间,可能…...

Kibana:LINUX_X86_64 和 DEB_X86_64两种可选下载方式的区别
最近需要在vm(操作系统是 Ubuntu 22.04.4 LTS,代号 Jammy。这是一个基于 x86_64 架构的 Linux 发行版)上安装一个7.17.8版本的Kibana,并且不采用docker方式。 在下载的时候发现有以下两个选项,分别是 LINUX_X86_64 和 …...

【LeetCode每日一题】 LeetCode 151.反转字符串中的单词
LeetCode 151.反转字符串中的单词 题目描述 给你一个字符串 s ,请你反转字符串中单词的顺序。 单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。 返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。 注意:…...

gitlab克隆仓库报错fatal: unable to access ‘仓库地址xxxxxxxx‘
首次克隆仓库,失效了,上网查方法,都说是网络代理的问题,各种清理网络代理后都无效,去问同事: 先前都是直接复制的网页url当做远端url,或者点击按钮‘使用http克隆’ 这次对于我来说有效的远端u…...

在已有vue cli项目中添加单元测试配置
使用的是vue cli ^4.0.0的脚手架,项目采用的vue2进行编写,项目本身是没有使用单元测试的。应该挺多项目还是使用的vue2的项目进行开发的,自己在开发中过程中,还是发生了挺多需要记录原来功能的情况,这个时候去翻文档明…...

企业级NoSql数据库REDIS集群
1.1数据库主要分为两大类:关系型数据库与 NoSQL数据库 关系型数据库,是建立在关系模型基础上的数把库,其借助于集合代数等数学概念和方法来处理数据库中的数掘主流的 MySQLOracle、Ms sOLSerer和 DB2 都属于这类传统数据库 NoSQL数据库,全称…...

HTML与数据抓取:GET与POST方法详解
讲GET和POST就不能只讲GET和POST 你要讲HTTP请求的基本概念: HTTP(HyperText Transfer Protocol,超文本传输协议)是互联网上应用最为广泛的一种网络协议,主要用于Web浏览器与Web服务器之间的数据通信。HTTP是一个基于…...
)
【es6复习笔记】模板字符串(3)
介绍 模板字符串是 ES6 引入的一种新的字符串声明方式,它使用反引号()来定义字符串,而不是单引号()或双引号(")。模板字符串可以包含变量、表达式和换行符,这使得它…...

cursor保存更改操作技巧
1. 当我们在agent模式时,要求cursor更改代码时,cursor回答后,就已经更改了代码了,这时候就可以对程序进行编译和测试, 不一定先要点” accept“, 先测试如果没有问题再点“accept”,这样composer就会多一条…...

如何突破AI编程工具的设备限制:go-cursor-help开源工具深度解析
如何突破AI编程工具的设备限制:go-cursor-help开源工具深度解析 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Your request has been blocked as our system has detected suspicious activity / Youve reached your trial reques…...

3种方法实现Axure全界面汉化:axure-cn语言包深度应用指南
3种方法实现Axure全界面汉化:axure-cn语言包深度应用指南 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn Axure-cn是…...
Windows 本地部署教程|一键安装 + 避坑指南)
OpenClaw(小龙虾)Windows 本地部署教程|一键安装 + 避坑指南
前言 OpenClaw 作为开源 AI 智能体工具,支持本地运行、可视化操作,可通过自然语言指令完成文件整理、浏览器自动化、数据提取等电脑操作,适配 Windows 多版本系统,部署流程简洁,适合办公场景与技术爱好者使用。本文整…...

李慕婉-仙逆-造相Z-Turbo应用实战:轻松生成仙逆角色同人图
李慕婉-仙逆-造相Z-Turbo应用实战:轻松生成仙逆角色同人图 1. 快速了解造相Z-Turbo模型 1.1 模型简介 李慕婉-仙逆-造相Z-Turbo是一款基于Z-Image-Turbo模型的LoRA版本,专门用于生成《仙逆》动漫中李慕婉角色的高质量同人图。这个预训练模型已经针对李…...

暗黑破坏神2终极单机增强插件:PlugY完全指南,三步搞定无限仓库与技能重置
暗黑破坏神2终极单机增强插件:PlugY完全指南,三步搞定无限仓库与技能重置 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 你是否曾经在暗黑破…...

第二十五节:Skill的打包、版本控制与社区发布
引言 上一章,我们为Skill精心打造了专业的README文档,这好比为产品准备好了精美的说明书。但要让用户能真正“安装”并使用你的成果,我们还需要完成从本地项目到可分发“产品”的关键转化。本章,我们将聚焦于Skill的打包、版本控制…...

EspDn32Mqtt:ESP32/ESP8266轻量级MQTT客户端封装库
1. EspDn32Mqtt 库深度解析:面向 ESP8266/ESP32 的轻量级 MQTT 客户端封装实践1.1 库定位与工程价值EspDn32Mqtt 是一个专为 ESP8266 和 ESP32 平台设计的轻量级 MQTT 客户端封装库。其核心目标并非替代PubSubClient或 ESP-IDF 原生mqtt_client,而是在保…...

如何通过Jar包快速集成国产工作流引擎的设计器
1. 为什么选择国产工作流引擎的设计器 在开发OA系统、ERP、CRM等企业级应用时,工作流引擎几乎是必不可少的核心组件。传统的开源工作流引擎如Activiti、Flowable虽然功能强大,但集成设计器往往需要复杂的配置和二次开发,这对中小型团队来说成…...

AI 时代新人击穿资深壁垒:专家思维 + 实战案例
一位技术观察者对「一维→二维→三维」成长框架的重新论断 引言:我为什么坚信"经验正在贬值,抽象永远升值" 作为 用维度概念来定义初级、中级、高级程序员 后续文章,我觉得这正是时候,之前所说的初中级概念正在模糊&am…...

告别串口调试!用ESP32-C3内置USB-JTAG在VSCode中实现高效开发
告别串口调试!用ESP32-C3内置USB-JTAG在VSCode中实现高效开发 嵌入式开发中,调试环节往往占据大量时间成本。传统串口调试需要反复插拔线缆、配置波特率,而逻辑分析仪又存在价格门槛。ESP32-C3芯片内置的USB-JTAG功能,正在改变这…...