机器学习基础 衡量模型性能指标
目录
1 前言
编辑1.1 错误率(Error rate)&精度(Accuracy)&误差(Error):
1.2 过拟合(overfitting): 训练误差小,测试误差大
1.3 欠拟合(underfitting):训练误差大,测试误差大
1.4 MSE:
1.5 RMSE:
1.6 MAE:
1.7 R-Squared:
2 准确度的缺陷 :
3 混淆矩阵:
4 精准率:
5 召回率:
6 准确率:
7 F1 Score:
8 宏平均和微平均:
9 偏差与方差:
思考:如何解决偏差、方差问题?
1 前言
大家知道已经,机器学习通常都是将训练集上的数据对模型进行训练,然后再将测试集上的数据给训练好的模型进行预测,最后根据模型性能的好坏选择模型,对于分类问题,大家很容易想到,可以使用正确率来评估模型的性能,那么回归问题可以使用哪些指标用来评估呢?
 1.1 错误率(Error rate)&精度(Accuracy)&误差(Error):
1.1 错误率(Error rate)&精度(Accuracy)&误差(Error):
- 错误率: 分类错误的样本数占样本总数的比例:E=a/m
- 精度: Accuracy=1-a/m
- 误差:学习器的实际预测输出与样本的真实输出之间的差异
- 训练(经验)误差(training/empirical error):训练集上的误差
- 测试误差(testing error):测试集上的误差
- 泛化误差(generalization error):除训练集外所有新样本上的误差
由于事先并不知道新样本的特征,我们只能努力使经验误差最小化;
很多时候虽然能在训练集上做到分类错误率为零,分类精度为100%,但多数情况下这样的学习器并不好。
1.2 过拟合(overfitting): 训练误差小,测试误差大
学习器把训练样本学习的“太好”,将训练样本本身的特点 当做所有样本的一般性质,导致泛化性能下降
- 优化目标加正则项
- 增加样本数量
- early stop
1.3 欠拟合(underfitting):训练误差大,测试误差大
对训练样本的一般性质尚未学好
- 决策树:拓展分支
- 神经网络:增加训练轮数
1.4 MSE:
MSE (Mean Squared Error)叫做均方误差,公式如下:
其中表示第 i个样本的真实标签,
表示模型对第 i 个样本的预测标签。线性回归的目的就是让损失函数最小。那么模型训练出来了,我们在测试集上用损失函数来评估模型就行了。
1.5 RMSE:
RMSE(Root Mean Squard Error)均方根误差,公式如下:
RMSE 其实就是 MSE 开个根号。有什么意义呢?其实实质是一样的。只不过用于数据更好的描述。
例如:要做房价预测,每平方是万元,我们预测结果也是万元。那么差值的平方单位应该是千万级别的。那我们不太好描述自己做的模型效果。怎么说呢?我们的模型误差是多少千万?于是干脆就开个根号就好了。我们误差的结果就跟我们数据是一个级别的了,在描述模型的时候就说,我们模型的误差是多少万元。
1.6 MAE:
MAE (平均绝对误差),公式如下:
MAE 虽然不作为损失函数,确是一个非常直观的评估指标,它表示每个样本的预测标签值与真实标签值的 L1 距离。
1.7 R-Squared:
上面的几种衡量标准针对不同的模型会有不同的值。比如说预测房价 那么误差单位就是万元。数子可能是 3,4 ,5 之类的。那么预测身高就可能是 0.1,0.6 之类的。没有什么可读性,到底多少才算好呢?不知道,那要根据模型的应用场景来。 看看分类算法的衡量标准就是正确率,而正确率又在 0~1 之间,最高百分之百。最低 0 。如果是负数,则考虑非线性相关。很直观,而且不同模型一样的。那么线性回归有没有这样的衡量标准呢?
R-Squared 就是这么一个指标,公式如下:
其中y mean表示所有测试样本标签值的均值。为什么这个指标会有刚刚我们提到的性能呢?我们分析下公式:

其实分子表示的是模型预测时产生的误差,分母表示的是对任意样本都预测为所有标签均值时产生的误差,由此可知:
,当我们的模型不犯任何错误时,取最大值 1。
- 当我们的模型性能跟基模型性能相同时,取 0。
- 如果为负数,则说明我们训练出来的模型还不如基准模型,此时,很有可能我们的数据不存在任何线性关系。
2 准确度的缺陷 :
准确度这个概念相信对于大家来说肯定并不陌生,就是正确率。例如模型的预测结果与数据真实结果如下表所示:
| 编号 | 预测结果 | 真实结果 |
| 1 | 1 | 2 |
| 2 | 4 | 2 |
| 3 | 3 | 3 |
| 4 | 2 | 2 |
| 5 | 2 | 4 |
很明显,算出来该模型的准确度为 2/5。
那么准确对越高就能说明模型的分类性能越好吗?非也!举个例子,现在我开发了一套信号传播信道系统,只要输入你的一些基本信号传播信道信息,就能预测出你现在是否有NLOS,并且分类的准确度为 0.999。您认为这样的系统的预测性能好不好呢?
您可能会觉得,哇,这么高的准确度!这个系统肯定很牛逼!但是我们知道,一般信号传播信道的概率非常低,假设分类的概率为 0.001,那么其实我这个信号传播信道系统只要一直输出NLOS,准确度也可能能够达到 0.999。
看到这里您应该已经体会到了,一个分类模型如果光看准确度是不够的,尤其是对这种样本极度不平衡的情况( 10000 条正常信息数据中,只有 1 条的类别是NLOS,其他的类别都是LOS)。
3 混淆矩阵:
混淆矩阵是机器学习模型评估的原始依据之一,通常可以用于评估一个分类器的分类性能[71]。该方法主要针对二元分类问题,可以将数据集分为肯定类和否定类,分类器做出阳性和阴性的判断。混淆矩阵的分类情形分析表显示四组不同的判断结果为真阳性(TP)、假阳性(FT)、真阴性(TN)、假阴性(FN),为分类器的评估指标提供了推导基础。
以信号传播信道预测为例,真阳性与假阴性分别是传播信道为LOS和传播信道为NLOS的结果阳性,真阴性和假阳性分别是传播信道为NLOS和传播信道为LOS的结果阴性。可以看出,真阳性和真阴性是信道传播正确的分类。如表1-1所示。
表1-1 混淆矩阵
| 混淆矩阵 | 预测值 | ||
| 传播信道为LOS | 传播信道为NLOS | ||
| 真实值 | 传播信道为LOS | Ture Positive,TP | False Negative,FN |
| 传播信道为NLOS | False Positive,FP | True Negative,TN | |
4 精准率:
准确率是所有类别整体性能的平均,如果希望对每个类都进行性能估计,就需要计算精确率(Precision)和召回率(Recall).精确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,在机器学习的评价中也被大量使用.
精准率(Precision)也称为FPR,指的是模型预测为 Positive 时的预测准确度,其计算公式如下:
5 召回率:
召回率(Recall)也称为TPR,指的是我们关注的事件发生了,并且模型预测正确了的比值,其计算公式如下:
也就是说 TPR 就是召回率。所以 TPR 描述的是模型预测 Positive 并且预测正确的数量占真实类别为 Positive 样本的比例。而 FPR 描述的模型预测 Positive 并且预测错了的数量占真实类别为 Negtive 样本的比例。
模型的精准率变高,召回率会变低,精准率变低,召回率会变高。
6 准确率:
由于混淆矩阵统计的是分类正确和错误的个数,只针对数量的分析对于模型优劣的衡量很难完成,故可以通过使用准确率(Accuracy,A)进行分类器的性能评估,计算公式如式所示。
7 F1 Score:
精准率变高,召回率会变低,精准率变低,召回率会变高。那如果想要同时兼顾精准率和召回率,这个时候就可以使用 F1 Score 来作为性能度量指标了。
F1 Score 是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。 F1 Score 可以看作是模型准确率和召回率的一种加权平均,它的最大值是 1,最小值是 0。其公式如下:
- 假设模型 A 的精准率为 0.2,召回率为 0.7,那么模型 A 的 F1 Score 为 0.31111。
- 假设模型 B 的精准率为 0.7,召回率为 0.2,那么模型 B 的 F1 Score 为 0.31111。
- 假设模型 C 的精准率为 0.8,召回率为 0.7,那么模型 C 的 F1 Score 为 0.74667。
- 假设模型 D 的精准率为 0.2,召回率为 0.3,那么模型 D 的 F1 Score 为 0.24。
从上述 4 个模型的各种性能可以看出,模型C的精准率和召回率都比较高,因此它的 F1 Score 也比较高。而其他模型的精准率和召回率要么都比较低,要么一个低一个高,所以它们的 F1 Score 比较低。
这也说明了只有当模型的精准率和召回率都比较高时 F1 Score 才会比较高。这也是 F1 Score 能够同时兼顾精准率和召回率的原因。
8 宏平均和微平均:
为了计算分类算法在所有类别上的总体精确率、召回率和F1值,经常使用两种平均方法,分别称为宏平均(Macro Average)和微平均(MicroAverage)。
宏平均是每一类的性能指标的算术平均值。微平均是每一个样本的性能指标的算术平均值.对于单个样本而言,它的精确率和召回率是相同的(要么都是1,要么都是0)。因此精确率的微平均和召回率的微平均是相同的。同理,F1 值的微平均指标是相同的。当不同类别的样本数量不均衡时,使用宏平均会比微平均更合理些.宏平均会更关注小类别上的评价指标。
9 偏差与方差:
通过实验可以估计学习算法的泛化性能,而“偏差-方差分解”可以用来帮助解释泛化性能。偏差-方差分解试图对学习算法期望的泛化错误率进行拆解。
- 偏差度量了学习算法期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;
- 方差度量了同样大小训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;
- 噪声表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。给定学习任务为了取得好的泛化性能,需要使偏差小(充分拟合数据)而且方差较小(减少数据扰动产生的影响)。
一般来说,偏差与方差是有冲突的,称为偏差-方差窘境。
如下图所示,假如我们能控制算法的训练程度:

- 在训练不足时,学习器拟合能力不强,训练数据的扰动不足以使学习器的拟合能力产生显著变化,此时偏差主导泛化错误率;
- 随着训练程度加深,学习器拟合能力逐渐增强,方差逐渐主导泛化错误率;
- 训练充足后,学习器的拟合能力非常强,训练数据的轻微扰动都会导致学习器的显著变化,若训练数据自身非全局特性被学到则会发生过拟合。
思考:如何解决偏差、方差问题?
整体思路:首先,要知道偏差和方差是无法完全避免的,只能尽量减少其影响。
(1)在避免偏差时,需尽量选择正确的模型,一个非线性问题而我们一直用线性模型去解决,那无论如何,高偏差是无法避免的。
(2)有了正确的模型,我们还要慎重选择数据集的大小,通常数据集越大越好,但大到数据集已经对整体所有数据有了一定的代表性后,再多的数据已经不能提升模型了,反而会带来计算量的增加。而训练数据太小一定是不好的,这会带来过拟合,模型复杂度太高,方差很大,不同数据集训练出来的模型变化非常大。
(3)最后,要选择合适的模型复杂度,复杂度高的模型通常对训练数据有很好的拟合能力。
相关文章:
机器学习基础 衡量模型性能指标
目录 1 前言 编辑1.1 错误率(Error rate)&精度(Accuracy)&误差(Error): 1.2 过拟合(overfitting): 训练误差小,测试误差大 1.3 欠拟合(underfitting):训练误差大,测试误差大 1.4 MSE: 1.5 RMSE: 1.6 MAE: 1.7 R-S…...
及形态学处理)
《OpenCV计算机视觉》-对图片的各种操作(均值、方框、高斯、中值滤波处理)及形态学处理
文章目录 《OpenCV计算机视觉》-对图片的各种操作(均值、方框、高斯、中值滤波处理)边界填充阈值处理图像平滑处理生成椒盐图片均值滤波处理方框滤波处理高斯滤波处理中值滤波处理 图像形态学腐蚀膨胀开运算闭运算顶帽和黑帽 《OpenCV计算机视觉》-对图片…...

如何让Tplink路由器自身的IP网段 与交换机和电脑的IP网段 保持一致?
问题分析: 正常情况下,我的需求是:电脑又能上网,又需要与路由器处于同一局域网下(串流Pico4 VR眼镜),所以,我是这么连接 交换机、路由器、电脑 的: 此时,登录…...

【JetPack】Navigation知识点总结
Navigation的主要元素: 1、Navigation Graph: 一种新的XML资源文件,包含应用程序所有的页面,以及页面间的关系。 <?xml version"1.0" encoding"utf-8"?> <navigation xmlns:android"http://schemas.a…...

InnoDB引擎的内存结构
InnoDB擅长处理事务,具有自动崩溃恢复的特性 架构图: 由4部分组成: 1.Buffer Pool:缓冲池,缓存表数据和索引数据,减少磁盘I/O操作,提升效率 2.change Buffer:写缓冲区,…...

Y3地图制作1:水果缤纷乐、密室逃脱
文章目录 一、水果缤纷乐1.1 游戏设计1.1.1 项目解析1.1.2 项目优化1.1.3 功能拆分 1.2 场景制作1.2.1 场景需求1.2.2 创建主镜头、绘制草稿,构思文案和情景1.2.3 构建场景地图1.2.4 光源与氛围设置 1.3 游戏初始化1.3.1 物编、UI预设置1.3.2 游戏初始化1.3.2 玩家初…...

ESP32_H2(IDF)学习系列-ADC模数转换(连续转换)
一、简介(节选手册) 1 概述 ESP32-H2 搭载了以下模拟外设: • 一个 12 位逐次逼近型模拟数字转换器 (SAR ADC),用于测量最多来自 5 个管脚上的模拟信号。 • 一个温度传感器,用于测量及监测芯片内部温度。 2 SAR ADC 2…...

如何通过TikTok成功引流到独立站
随着短视频平台的迅猛发展,TikTok已成为全球最受欢迎的社交媒体之一,尤其是在年轻用户群体中更是势不可挡。如果你是一个独立站(如电商网站、博客、个人品牌站等)的运营者,那么如何通过TikTok引流到独立站已经成为一个…...

生成签名文件 .keystore
打开java sdk 到bin目录(D:\JDK\Java\jdk1.8.0_202\bin),打开dos窗口执行以下命令: 命令行输入: 1、生成签名文件:(-alias 别名 validity 有效期 9125 天) keytool -genkeypair -v…...

Mono里运行C#脚本3—mono_jit_init
前面已经介绍了配置参数的读取,这样就可以把一些特殊的配置读取进来,完成了用户配置阶段的参数,接着下来就需要进行大工程的建造了。 为什么这样说呢,因为需要解释并执行C#编译的受托管的代码,相当于就是建立一个C#代码运行的虚拟机,而这个虚拟机还是很复杂的,不但要支…...
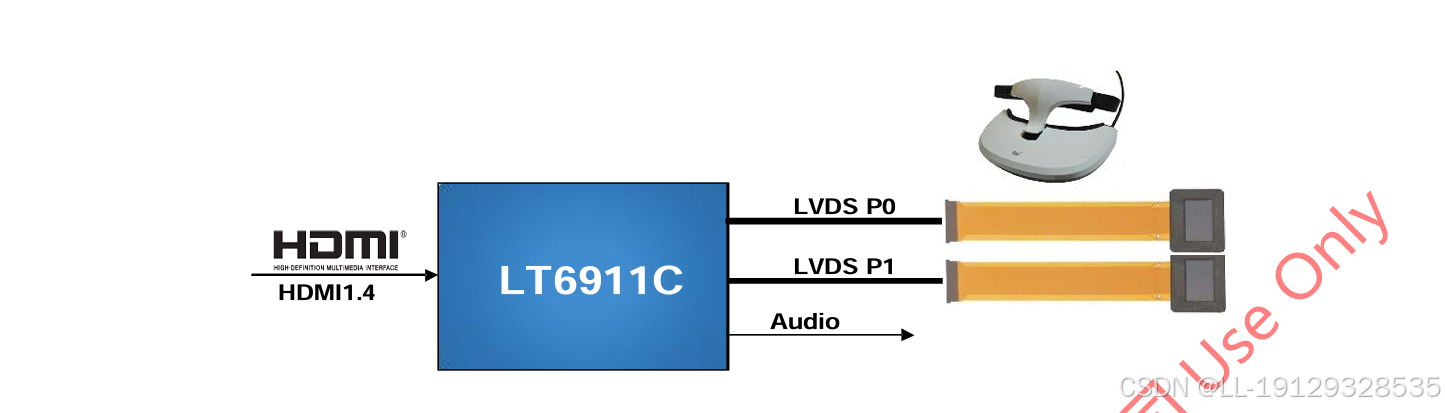
龙迅#LT6911C适用于HDMI转MIPI/LVDS产品应用,分辨率高达4K30HZ,内置程序,支持KEY(HDCP)!
1. 描述 LT6911C 是一款高性能 HDMI1.4/DP 转 MIPIDSI/CSI/LVDS 芯片,适用于 VR/智能手机/显示应用。 对于 MIPIDSI/CSI 输出,LT6911C具有可配置的单端口或双端口 MIPIDSI/CSI,具有 1 个高速时钟通道和 1~4 个高速数据通道,运行…...

阿里云虚拟主机ecs镜像如何转移到本地virtualbox上
导出阿里云 ECS 镜像 创建快照:登录阿里云 ECS 控制台,找到对应的 ECS 实例,创建一个快照,等待快照创建完成。创建自定义镜像:基于创建好的快照,创建一个自定义镜像,填写镜像名称和描述等信息。导出镜像:镜像创建完成后,点击 “导出镜像”,并授权访问,将镜像导出到阿…...

虚拟机桥接模式
主机Win10,虚拟机xp 1.虚拟机设置中选择桥接模式 2.在虚拟机菜单:编辑>虚拟机网络编辑,点击“更改设置”,可以看到三个网卡,这三个网卡分别对应不同的网络共享模式。桥接模式须使用VMnet0,如果没看到这个网卡&…...

酷睿i7和i5哪个好?i5和i7的区别介绍
在英特尔酷睿处理器家族中,i7与i5作为面向不同用户群体的主流产品,各自承载着不同的性能定位与使用价值。在面对“酷睿i7和i5哪个好”的问题时,答案并非一概而论,而是取决于具体的应用需求、预算考量以及对性能与效率的期待。本文…...

STM32 高级 谈一下IPV4/默认网关/子网掩码/DNS服务器/MAC
首先可以通过 winr->输入cmd->输入ipconfig 命令可以查看计算机的各种地址 IPV4:是互联网协议第 4 版(Internet Protocol version 4)所使用的地址。它是一个 32 位的二进制数字,通常被分为 4 个 8 位的部分ÿ…...

Pytorch | 利用FGSM针对CIFAR10上的ResNet分类器进行对抗攻击
Pytorch | 利用FGSM针对CIFAR10上的ResNet分类器进行对抗攻击 CIFAR数据集FGSM介绍FGSM代码实现FGSM算法实现攻击效果 代码汇总fgsm.pytrain.pyadvtest.py 之前已经针对CIFAR10训练了多种分类器: Pytorch | 从零构建AlexNet对CIFAR10进行分类 Pytorch | 从零构建Vgg…...

消息队列(二)消息队列的高可用原理
高可用的定义 上一篇文章提过,引入了消息队列的优势在于解耦、并发和缓冲,代价就是让程序的复杂性上升,引入了消息队列后,就需要考虑消息队列对于系统整体的影响,此时消息队列的稳定和健壮就是重中之重。也就是消息队…...

大模型-使用Ollama+Dify在本地搭建一个专属于自己的聊天助手与知识库
大模型-使用OllamaDify在本地搭建一个专属于自己的知识库 1、本地安装Dify2、本地安装Ollama并解决跨越问题3、使用Dify搭建聊天助手4、使用Dify搭建本地知识库 1、本地安装Dify 参考往期博客:https://guoqingru.blog.csdn.net/article/details/144683767 2、本地…...

深入理解索引的最左匹配原则:底层逻辑解析
1. 什么是最左匹配原则? 最左匹配原则是指在使用复合索引时,查询条件从左到右依次匹配索引列的顺序,一旦中间有列未匹配,索引将停止工作或部分失效。 1.1 举例说明 假设我们有一张用户表(users)…...

微服务——数据管理与一致性
1、在微服务架构中,每个微服务都有自己的数据库,这种设计有什么优点和挑战? 优点挑战服务自治:每个微服务可独立选择适合自己的数据库类型。数据一致性:跨微服务的事务难以保证强一致性。故障隔离:一个微服…...
,5分钟搞定语义分割的域迁移)
告别复杂对抗训练:用Python+PyTorch实现傅里叶域自适应(FDA),5分钟搞定语义分割的域迁移
5行代码实现傅里叶域自适应:用PythonPyTorch零成本完成语义分割域迁移 当你在GTA5游戏画面训练的模型遇到真实街景时,准确率突然暴跌30%——这是计算机视觉工程师最熟悉的噩梦。传统域自适应方法往往需要复杂的对抗训练和精细调参,而2020年CV…...
)
避坑指南:Raspberry Pi5安装LineageOS21常见问题全解(SSD启动/存储扩容/Play商店报错)
Raspberry Pi5安装LineageOS 21避坑指南:从SSD启动到Play商店认证全流程解析 当Raspberry Pi5遇上LineageOS 21,这个组合让单板计算机瞬间变身高性能Android设备。但实际安装过程中,从存储介质选择到Google服务集成,每个环节都可能…...

2026地学最新调剂信息:北京师范大学、合肥工业大学、兰州大学、广州大学、宁波大学等
北京师范大学文理学院(珠海):原网址:https://fas.bnu.edu.cn/zsjy/yjszs/72ce767035ea4a4cbd8ba5607569af1f.htm合肥工业大学资源与环境工程学院调剂信息:原网址:https://geoscience.hfut.edu.cn/info/1042…...

3步构建微信数据安全防线:WeChatExporter备份工具全解析
3步构建微信数据安全防线:WeChatExporter备份工具全解析 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 微信聊天记录承载着重要的工作信息与个人回忆&#x…...

AI Agent Skills 完全指南:从概念到实践,打造你的专属智能体能力库
文章目录一、什么是 Skills?AI Agent 的能力组件1.1 概念起源1.2 Skills 与传统 Prompt 的区别1.3 Skills 的典型应用场景二、主流 AI 编程工具的 Skills 生态2.1 Claude Code:Skills 的开创者2.2 Cursor:Composer 与 Agent 模式的 Skills2.3…...

Phi-3 Forest Laboratory在操作系统教学中的应用:模拟进程调度与内存管理
Phi-3 Forest Laboratory在操作系统教学中的应用:模拟进程调度与内存管理 不知道你有没有过这样的经历:坐在操作系统原理的课堂上,听着老师讲进程调度、内存分页,那些抽象的概念和算法在PPT上跳来跳去,公式和流程图看…...

LangGraph应用:设计MusicGen的自动化工作流
LangGraph应用:设计MusicGen的自动化工作流 1. 引言 想象一下这样的场景:你有一个绝佳的音乐创意,想要创作一首完整的歌曲,但面对复杂的音乐制作流程却无从下手。传统的音乐制作需要经历作词、编曲、混音、母带处理等多个环节&a…...
)
【C语言】-指针(1)
🦆 个人主页:深邃- ❄️专栏传送门:《C语言》《数据结构》 🌟Gitee仓库:《C语言》《数据结构》 目录内存和地址指针变量和地址指针变量和解引用操作符(*)指针变量的大小内存存放指针变量类型的…...

YOLOv10优化升级:利用TensorRT加速,推理性能再提升
YOLOv10优化升级:利用TensorRT加速,推理性能再提升 1. YOLOv10与TensorRT的完美结合 在计算机视觉领域,目标检测模型的推理速度直接影响着实际应用效果。YOLOv10作为最新一代的目标检测模型,通过消除NMS后处理实现了真正的端到端…...

利用modbus_tcp实现多设备数据聚合:构建高效modbusSlave网关的实践指南
1. 为什么需要Modbus TCP数据聚合网关 在工业自动化现场,我们经常会遇到这样的场景:车间里分散着十几台PLC设备,每台设备都通过Modbus TCP协议暴露数据接口。这时候如果上位机系统要同时监控所有设备,传统做法是逐个建立连接轮询数…...