文本数据处理
文本数据处理
一、数据转换与错误处理
(一)运维中的数据转换问题
在计算机审计及各类数据处理场景中,数据转换是关键步骤,涉及将被审计单位或其他来源的数据有效装载到目标数据库,并明确标示各表及字段含义与关系。然而,此过程易出现转换数据错误,因为数据在系统间转移时,格式、编码或结构可能改变,导致数据含义及关系出错。例如,某公司 ERP 系统与审计软件间日期格式转换不当,就会造成数据错误解读,影响审计准确性。
(二)常见数据转换错误类型
- 命名错误:原端数据源标识符与目的数据源保留字冲突,如 CRM 系统的“order date”字段在 ERP 系统中为保留字,需重新命名避免冲突。
- 格式错误:同一种数据类型在不同系统可能有不同表示方法和语义差异,如 Excel 日期格式与 SQL 数据库期望格式不一致,需编写转换脚本统一格式。
- 结构错误:不同数据库的数据定义模型不同,如关系模型和层次模型转换时,需重新定义实体、属性和联系,防止信息丢失。
- 类型错误:不同数据库同一种数据类型存在精度差异,在转换时要综合考虑数据类型及其精度,确定合适映射关系。
(三)数据错误处理方法
- 数据输入错误:人工数据收集、记录或输入过程中产生失误,导致数据集中出现异常值,影响后续分析,如调查问卷年龄数据录入错误。
- 测量误差:使用不准确测量工具或方法,使数据偏离实际值,如物理实验中校准不准确的温度计记录的温度数据。
- 数据处理错误:数据分析过程中因操作不当产生异常值,如数据清洗时错误删除重要数据点或使用错误公式进行统计计算。
在数据转换环节增加数据检验步骤至关重要。以员工工资数据集为例,若发现负数工资记录(明显不合理),处理方法如下:
- 若错误数据量少,可直接删除,如少数几条负数工资记录可能是输入错误,删除不影响整体分析。
- 可替换错误数据,用均值、中位数或众数代替,如计算员工所在部门平均工资替换错误工资值。
- 若错误数据量多,将错误数据和正常数据分开处理,为异常值单独建立模型,与正常值模型结果合并,避免异常值对整体分析结果产生过大影响。
二、数据质量评估
数据质量是保证数据应用效果的基础,涉及多个维度评估指标:
- 完整性:数据集应包含所有预期信息项,无遗漏。评估时查看数据统计中的记录数和唯一值情况,如销售数据集中订单号字段存在大量重复或缺失,说明完整性有问题。
- 一致性:数据集中相同信息项在不同记录或数据源间应保持相同表示和含义,多数数据有标准编码、规则或格式要求,检验时看其是否符合既定标准,如客户信息系统中性别字段应遵循统一编码规则。
- 准确性:数据记录信息应准确无误,不存在异常或错误,常见错误包括乱码、格式错误、逻辑错误等,准确的数据是数据质量的核心要求之一。
- 及时性:数据应在最短时间内采集、处理和更新,以满足应用需求,如电商平台商品库存信息需实时更新,否则可能导致消费者下单后发现商品已售罄的情况。
在进行数据质量评估时,应根据具体应用场景和需求,对各项评估指标进行选择和权重分配,以全面、准确地衡量数据质量,为后续的数据应用提供可靠保障。
三、审计数据处理
审计数据处理包括数据查询、审计抽样、统计分析和数据分析等方法:
- 数据查询:审计人员依据经验和审计分析模型,使用审计软件中的查询命令分析采集的电子数据,或通过运行各种查询命令以特定格式检测被审计单位数据,是常用方法之一。
- 审计抽样:从审计对象总体中选取一定数量样本进行测试,根据样本测试结果推断总体特征,在面向数据的计算机审计中发挥重要作用。
- 统计分析:目的是探索被审计数据内在的数量规律性,以发现异常现象,快速寻找审计突破口,常用方法包括一般统计、分层分析和分类分析,通常与其他审计数据处理方法配合使用。
- 数据分析:根据字段数据值分布情况、出现频率等对字段进行分析,先不考虑具体业务,对分析出的可疑数据结合业务进行审计,有助于发现隐藏信息。
审计数据直接影响审计结果的准确性和效率性,国内外都重视审计数据处理,不断研究与开发电子数据审计软件,为审计数据的采集、处理与分析提供保障。在 Kettle 中,可通过日志和审计功能存储日志及转换步骤级别的日志信息,对日志进行事件细节审计,提供完整质量指标和信息统计,助力审计工作的开展和审计质量的提升。
四、中文分词算法
(一)中文分词的挑战与MMSEG算法
中文分词与英文等拉丁语系语言不同,中文没有明显单词分界线,因此中文分词算法需先确定基本单位(即单词)。MMSEG 分词算法是解决中文分词问题的一种有效方法,由 Hosein 提出,其基本思路是依据词典在待分析句子中寻找对应词,从句子两头同时开始找词,以更快找到最合适的分法,并根据上下文判断词的用法。该算法使用的词典主要有汉字字典、中文单位词语词典和自定义词典:
- 汉字字典:包含众多汉字,每个字有读音、意思及用法示例,字按一定顺序排列,如部首、笔画数或拼音字母顺序。
- 中文单位词语:通过分词和词性标注将中文文本切分成最小有意义单位(词语),并标注词性。
- 自定义词典:类似于个人词汇本,用于存放新词或专业术语,方便电脑识别其拼写和用法,提高分词准确性,尤其在处理特定领域文本时作用显著。
(二)匹配算法
MMSEG 算法采用简单最大匹配和复杂最大匹配两种算法:
- 简单最大匹配算法:从待分词文本左边开始,列出所有可能分词结果,但存在从左到右依次匹配可能忽略更合适分词方式的问题。例如对“国际化大都市”的分词,可能会出现多种不太准确的划分情况。
- 复杂最大匹配算法:从给定文本中选择起始点,每次向后扩展三个字符形成词组,不断重复此过程至文本末尾,然后根据词库中词的频率、长度等标准确定最优分词结果。如对“研究大数据”的分词,会尝试多种组合以找到最优方式。
(三)歧义消除规则
MMSEG 算法根据汉语组词习惯制定了四种解决词义混淆的规则:
- 规则一:备选词组合的最大匹配规则:从句子开头尽量找最长词,在词典中查找,找到则画出该词,对剩余部分重复操作,若找不到则缩短词长再试,若最终仍无法找到,则将单字作为词。此方法处理长词速度快,但可能在处理模棱两可的词时出现分错情况。
- 规则二:备选词组合的平均词长最大规则:基于较长词往往能提供更多信息的原理,通过词语长度寻找线索,帮助确定更合适的分词组合。
- 规则三:备选词组合的词长变化最小规则:类似于人们说话时尽量使每个词长度变化不突兀,让电脑处理后的语言更接近日常说话习惯,减少出错机会,提高分词的合理性和可读性。
- 规则四:单字词频率最高规则:在备选词组合中,统计一个字的词出现的频率,可通过计算每个单字词出现次数的自然对数并求和,选择总和最大的词作为频率最高的词,以此确定更优的分词结果。
(四)常用中文分词工具
- Jiba 分词:是常用的中文分词工具,用 Python 编写,具有精确模式、全模式和搜索引擎模式三种模式,适用于不同的应用场景,能满足多样化的分词需求。
- NLTK(自然语言工具包):由斯坦福大学自然语言处理小组开发的开源文本分析工具,包含分词器、命名实体识别、词性标注和句法分析器等,有助于更好地分析中文文本,特别适合自然语言处理研究和教学工作,为相关领域的学术研究和实践应用提供了有力支持。
- Solex:清华大学自然语言处理实验室开发的中文词法分析工具包,能实现分词和词性标注,具有能力强、准确率高、速度快的优点,在中文文本处理中表现出色,可有效提升分词和词性标注的质量与效率。
- NOPIER 分词系统:前身为 ICTCLES 词法分析系统,由北京理工大学张华平博士提供,经过十多年发展,功能丰富,性能强大,能够应对复杂的中文文本分词任务,为专业的文本处理工作提供了可靠的技术手段。
- snownlp:用 Python 编写的中文文本分词库,不仅能进行分词和词性标注,还具备情感分析、文本分类、转成拼音、繁简转换、提取关键词和摘要、计算文本相似度、统计词频和逆向文档频率等多种功能,功能全面,适用于多种自然语言处理任务,为中文文本的深入分析和挖掘提供了便利。
中文分词算法在自然语言处理和数据挖掘中具有重要地位,不同的分词算法和工具各有特点和优势,在实际应用中,需根据具体需求选择合适的方法和工具,以实现准确、高效的中文文本分词,为后续的文本分析、信息检索、情感分析等任务奠定基础。
五、文本分词基础概念
文本分词是将文本数据拆分成有意义的小单位(通常是单词)的过程。在中文中,由于单词间无空格,需借助特定技巧实现分词,而英文则通过空格分隔单词,使电脑更易识别。例如,英文句子“i am a teacher”能直接通过空格识别单词,而中文句子“我是一名教师”需确定“教师”为一个词,这就是分词算法的任务。
分词算法以一段文字为输入,通过切分和过滤,输出拆分后的单词。其基本原理多采用统计方法,利用标准语料库中的例子进行学习和分析。以“大数据将带来什么”为例,期望电脑能正确分词,而不是错误划分,这就需要通过数学模型学习和预测单词间关系,找到最优分词方式,使电脑更好地理解文本。这种技术在搜索引擎、语音识别等领域广泛应用,如在搜索引擎中,准确的分词有助于提高搜索结果的准确性和相关性,让用户更快找到所需信息;在语音识别中,能使电脑更准确地将语音转换为文字,提升交互体验。
(一)语言模型与算法
- N - gram 模型:根据前面几个词预测下一个词出现概率,如通过“今天”预测后续可能出现的词,用于分析单词组合规律,在文本处理中可辅助确定更合理的分词结果,提高文本理解的准确性和连贯性。
- 维特比算法:考虑分词仅与前一个分词相关,采用动态规划算法解决最优分词问题。就像依据一串神秘脚印(单词序列),通过一步步排除,找到最有可能留下脚印的嫌疑人(最合理的单词序列),该算法高效且能避免检查所有可能情况,快速确定最优解,提升分词效率和准确性。
(二)语料库
语料库是装满各种文本的巨大语言材料仓库,包含书本文字、日常对话等,以电子形式保存,便于研究和分析语言。构建语料库需遵循代表性、结构性、平衡性、规模性和原数据等原则:
- 代表性:语料应从特定范围随机挑选,能代表该范围内大多数情况,确保语料库能反映真实语言使用的多样性和普遍性,如不能仅收集某一特定主题的文本,而应涵盖多种领域和主题的内容。
- 结构性:搜集的语言材料需是电脑可读的电子形式,且有组织、有条理,每个材料有代码及相关信息,如类型、大小、取值范围等,并保证完整,以便于系统地分析和利用语料库中的数据,提高语言研究的效率和准确性。
- 平衡性:考虑学科领域、时间年代、文章风格、地方特色、发表文章的报纸杂志以及使用资料的人的年龄、性别、文化水平、经历等因素,选取一个或几个重要因素进行平衡,通常学科、时间、风格和地方等因素用得较多,使语料库能更全面、客观地反映语言的实际使用情况,避免因某些因素的过度偏重而导致语料库的偏差。
- 规模性:大量文字材料对语言研究有益,但随着材料增多,垃圾材料也会增加,且达到一定数量后,其作用并非线性增长,因此需根据实际情况确定合适的材料量,以在保证研究效果的前提下,提高资源利用效率,避免资源浪费和数据冗余。
- 原数据:对研究语料库至关重要,能帮助明确语料的时间、来源、作者、文本特征等信息,还可用于区分和比较不同小语料库,记录版权、加工过程和管理信息等,为语料库的有效管理和合理利用提供重要依据,确保语料库的质量和可靠性。
在实际应用中,虽然可通过数据预处理技术自行整理文本信息构建语料库,但考虑到上述原则以及搭建语料库的复杂性和人力消耗,通常会选择开源数据集,不过在特定商业目的下,若找不到合适的开源数据,也可能需要自行制作语料库,以满足特定的研究和应用需求。
六、中文分词方法分类
(一)基于字符串匹配的分词方法
基于字符串匹配的分词方法,又称机械分词方法,是将句子与词典比对,找到匹配的词串进行切分。根据扫描方式分为正向匹配和逆向匹配,正向匹配从文本开头向后扫描,逆向匹配从文本末尾向前扫描;根据长度优先匹配原则分为最大匹配和最小匹配,最大匹配优先找最长词,最小匹配优先找最短词;根据与词性标注结合方式分为单纯分词方法和分词与词性标注相结合的一体化方法,单纯分词只关注词汇分割,一体化方法同时进行词性标注以更好理解语义。
实际使用的分词系统多以机械分词为初步手段,并结合其他语言信息提高切分准确率。常用的机械分词法有正向最大匹配法、逆向最大匹配法和最少切分法:
- 正向最大匹配法:从文本最左边开始,取连续字符在词汇库中查找匹配词,若能匹配则画出该词,否则缩短字符串继续尝试,直到找到匹配词或字符串缩短为一个字。
- 逆向最大匹配法:从句子右边开始向左扫描,每次尽量匹配最长词,遇到不能匹配时,从稍左位置继续找下一个词,直至将句子全部分成单个词。逆向匹配法在处理复杂句子时切分精度相对较高,奇异现象较少,例如对“我喜欢吃苹果”的分词,逆向最大匹配法可能比分正向最大匹配法更准确,因此在实际应用中更受青睐。
- 双向最大匹配法:将正向和逆向最大匹配法结果进行比较,确定正确分词方法,综合两者优势,提高分词准确性和可靠性。
由于汉语单字可单独成词,正向最小匹配和逆向最小匹配法使用较少。
(二)基于理解的分词方法
基于理解的分词方法借助人工智能,让电脑在分词时分析句子结构和意思,利用这些信息解决词语模糊问题,提高分词准确性,更好地理解自然语言,在信息搜索和文本分析等领域有广泛应用。该方法通常包括分词子系统、句法语义子系统和总控部分,各部分协同工作,使电脑像人一样理解句子,从而实现更精准的分词。
(三)基于统计的分词方法
基于统计的分词方法先收集大量已分词文本,运用统计学和机器学习方法研究词语切分规律,训练模型,再用模型处理新文本进行分词。其优势在于能适应不同类型文本,随着训练数据增加,模型性能提升,分词准确率和速度也会提高。目前主要统计模型包括多种,实际应用中,采用统计方法的分词系统通常结合词典匹配词语和统计方法找新词,兼顾匹配分词的速度效率与统计方法识别新词、解决歧义的能力,提高分词的综合效果,为文本数据的深入分析和应用提供有力支持。
相关文章:

文本数据处理
文本数据处理 一、数据转换与错误处理 (一)运维中的数据转换问题 在计算机审计及各类数据处理场景中,数据转换是关键步骤,涉及将被审计单位或其他来源的数据有效装载到目标数据库,并明确标示各表及字段含义与关系。…...
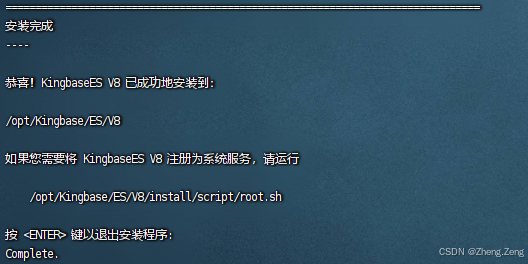
Liunx环境下安装人大金仓数据库V8R6版本
Liunx环境下安装人大金仓数据库V8R6版本 一:硬件环境要求二:软件环境要求三:安装包准备四:检测和配置环境4.1:检查操作系统信息4.2 检查系统内存与存储空间 五:配置内核参数六:预安装工作6.1 创…...
Android使用PorterDuffXfermode模式PorterDuff.Mode.SRC_OUT橡皮擦实现马赛克效果,Kotlin(3)
Android使用PorterDuffXfermode模式PorterDuff.Mode.SRC_OUT橡皮擦实现马赛克效果,Kotlin(3) import android.content.Context import android.graphics.Bitmap import android.graphics.BitmapFactory import android.graphics.Canvas impor…...

python 怎么引入类
一、导入单个类 from fun import Dog dogDog(husike) dog.bark() 二、导入多个类 多个类之间用逗号分隔 from fun import Dog,Cat dogDog(husike) dog.bark() catCat(maomi) cat.catch_mouse() 三、导入整个模块 import fun dogfun.Dog(husike) dog.bark() catfun.Cat(maomi) …...

Day35汉明距离
两个整数之间的 汉明距离 指的是这两个数字对应二进制位不同的位置的数目。 给你两个整数 x 和 y,计算并返回它们之间的汉明距离。 class Solution {public int hammingDistance(int x, int y) {int cnt 0;while (Math.max(x, y) ! 0) {if ((x & 1) ! (y &…...

中文学习系统:客户服务与学习支持
3.1 系统可行性分析 开发一款程序软件不仅需要时间,也需要人力,物力资源。而进行可行性分析这个环节就是解决用户这方面的疑问,看看程序在当前的条件下是否可以进行开发。 3.1.1 技术可行性分析 此程序选用的开发语言是Java,这种编…...

华为麦芒5(安卓6)termux记录 使用ddns-go,alist
下载0.119bate1版,不能换源,其他源似乎都用不了,如果root可以直接用面具模块 https://github.com/termux/termux-app/releases/download/v0.119.0-beta.1/termux-app_v0.119.0-beta.1apt-android-5-github-debug_arm64-v8a.apk 安装ssh(非必要) pkg install openssh开启ssh …...

餐厅下单助手系统(Java+MySQL)
项目概览 餐厅下单助手系统是一个采用 Java 实现的小型食品订单管理系统,并且以 SwingUI 打造视觉界面,数据库提供。本系统分为商家和顾客两类体验,有效地给予简洁性能。可用做课程设计,参考学习。 技术栈 Java: 核心开发语言S…...

Go操作MySQL
连接 Go语言中的database/sql包提供了保证SQL或类SQL数据库的泛用接口,并不提供具体的数据库驱动。使用database/sql包时必须注入(至少)一个数据库驱动。 我们常用的数据库基本上都有完整的第三方实现。例如:MySQL驱动 下载依赖…...
配置开机自启动服务)
Linux(Ubuntu/CentOS)配置开机自启动服务
systemd和systemctl的区别和联系 systemd:是现代Linux系统中的初始化系统和服务管理器。它主要负责系统引导和进程管理,支持并行化启动服务,并提供高级的服务管理和依赖控制。 systemctl:是systemd的命令行工具,用于与…...

springboot3版本结合knife4j生成接口文档
1.概述 knife4j官网为:介绍 | Knife4j (xiaominfo.com)https://doc.xiaominfo.com/docs/introduction 初步了解的码友可以初步了解一下官网的如下几个模块: 其中在快速开始模块中,不同的springboot版本都有一个使用的案例demo如下图位置&am…...

谈谈 Wi-Fi 的 RTS/CTS 设计
我不是专业的 Wi-Fi 技术工作者。但我可以谈谈作为统计复用网络的 Wi-Fi,通用的网络分布式协调功能在底层是相通的。 从一个图展开: 基于这底层逻辑,共享以太网可以用 CSMA/CD,而 Wi-Fi 只能用 CSMA/CA,区别在 CD(冲…...

JVM 详解
一. JVM 内存区域的划分 1. 程序计数器 程序计数器是JVM中一块比较小的空间, 它保存下一条要执行的指令的地址. [注]: 与CPU的程序计数器不同, 这里的下一条指令不是二进制的机器语言, 而是Java字节码. 2. 栈 保存方法中的局部变量, 方法的形参, 方法之间的调用关系. 栈又…...

【debug】
error info: Error response Error response Error code 401. Message: Unauthorized. requests.exceptions.ConnectionError: HTTPConnectionPool(host‘127.0.0.1’, port9000): Max retries exceeded with url: /test/ (Caused by NewConnectionError(‘&l…...

PCB注意事项
1.记录一下我绘制PCB中遇到的一些坑 4G模块和SIM卡的信号线最好距离短,SIM卡下 不要过线 晶振是高速信号,两根线要尽可能差分,保持长度一直,而且线尽可能加粗,晶振下最好不要有线经过 继电器中间需要间隔 继电器中间挖空,起到隔离作用,绝缘,因为继电器有可能接市电220v 高压…...

Nmap使用指南
目录 nmap命令大全 1. 安装Nmap 2. 基本扫描 2.1 扫描单个IP地址 2.2 扫描指定端口范围 2.3 扫描整个子网 3. 高级扫描 3.1 服务版本检测 3.2 操作系统检测 3.3 脚本扫描 3.4 扫描速度 4. 输出结果 4.1 保存到文件 4.2 格式化输出 5. 注意事项 6. 进一步学习 n…...

社区版Dify 轻松实现文生图,Dify+LLM+ComfyUI
社区版Dify 轻松实文生图,DifyLLMComfyUI Dify 安装可参考这里ComfyUI 其实 比 WebUI更简单更实用DifyComfyUIDifyLLM1. Qwen 通义千问大模型系列2. OpenAI大模型系列3. 本地Ollama搭建 DifyLLMComfyUI Dify 安装可参考这里 这是一个在Dify上实现 文生图的教程&…...
)
Python - 获取当前函数中的所有参数信息(名称和值)
代码 import inspect import randomclass P:def start(self, p1, p2, p3None, p4None):arg_info inspect.getargvalues(inspect.currentframe())kwargs arg_info.locals # 获取到所有参数print(kwargs)del kwargs["self"]try:self._start(**kwargs)except Except…...

PHP之伪协议
文章目录 PHP伪协议php://协议data://协议file://协议phar://协议zip:// & bzip2:// & zlib://协议 过滤器 题目练习[BJDCTF 2020]ZJCTF,不过如此BaseCTF[week1]Aura酱的礼物 PHP伪协议 file:// — 访问本地文件系统 http:// — 访问 HTTP(s) 网址 ftp:// …...

关于Vue的子组件改变父组件传来的值
一、组件直接传值 大家都知道父子组件传值的方案,有以下几个,不再详细敖述 Props:父组件向子组件传递数据 $emit:子组件通过自定义事件向父组件传递数据 .sync修饰符:一个方便且强大的工具,可以简化父子组…...

终极字体合并方案:如何一键解决游戏字体兼容性难题
终极字体合并方案:如何一键解决游戏字体兼容性难题 【免费下载链接】Warcraft-Font-Merger Warcraft Font Merger,魔兽世界字体合并/补全工具。 项目地址: https://gitcode.com/gh_mirrors/wa/Warcraft-Font-Merger 还在为游戏中文字显示不全而烦…...
)
GigE Vision 多相机同步终极检查清单(可直接用于项目部署)
GigE Vision 多相机同步终极检查清单(可直接用于项目部署)📋 GigE Vision 多相机同步终极检查清单一、网络基础设施二、PTP 配置三、硬件触发四、相机参数一致性五、软件数据处理六、验证手段📋 GigE Vision 多相机同步终极检查清…...

百度网盘限速难题如何破解?BaiduPCS-Web带来的下载体验革新
百度网盘限速难题如何破解?BaiduPCS-Web带来的下载体验革新 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 三个直击痛点的灵魂拷问 你是否经历过这样的场景:加班回家想下载一份工作资料,…...

从零构建编译器:编译原理实战与考试重点解析
1. 编译器是什么?为什么需要学习编译原理? 当你用Python写下print("Hello World")时,计算机其实看不懂这行代码。编译器就像一位翻译官,把人类能理解的高级语言转换成机器能执行的二进制指令。我在第一次实现编译器时&a…...

飞书机器人集成OpenClaw与百川2-13B-4bits量化版:对话触发任务实战
飞书机器人集成OpenClaw与百川2-13B-4bits量化版:对话触发任务实战 1. 为什么选择这个技术组合 去年冬天,我接手了一个小团队的内部效率优化项目。团队每天需要从海量行业报告中提取关键数据,整理成简报表。最初尝试用传统RPA工具ÿ…...

使用OpenGL纹理数组实现高精度实时Lut滤镜
之前写过的文章(使用OpenGL实现滤镜转换的一种思路_轮子初级玩家-CSDN博客),我把一整个Lut滤镜图作为单个纹理贴图,把图像原颜色采样后当作坐标,然后从lut纹理中查找出替换颜色实现滤镜功能,这是最简易的一种滤镜实现方式…...

YOLOv8n-face人脸检测架构:6MB模型实现92%精度与25ms延迟的企业级方案
YOLOv8n-face人脸检测架构:6MB模型实现92%精度与25ms延迟的企业级方案 【免费下载链接】yolov8-face yolov8 face detection with landmark 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8-face YOLOv8n-face是基于YOLOv8架构优化的轻量级人脸检测模型…...

SEO网站推广的长期效果如何_SEO网站推广对网站优化有什么要求
SEO网站推广的长期效果如何 在当今互联网时代,SEO网站推广已经成为提升网站流量和品牌知名度的关键手段。SEO,即搜索引擎优化,通过优化网站结构、内容和外部链接,提高网站在搜索引擎结果页面(SERP)中的排名…...

快商通:引领智能客服新范式,驱动企业服务数字化转型
在数字化转型加速的今天,智能客服系统已不再是企业的“可选项”,而是提升服务效率、优化客户体验、驱动业务增长的核心基础设施。无论是初创公司还是行业巨头,都面临着如何选择合适智能客服系统、如何将其真正落地并发挥最大价值的挑战。尤其…...

网安新手必刷的五个渗透测试靶场!黑客技术实战靶场零基础入门到精通教程!DVWA、Pikachu、SQLi-Labs、Upload-Labs、XSS-Labs靶场教程
前言 因为最近有任务需要搭建一些适合新手使用的靶场,所以收集了一下互联网常见的一些友好的新手渗透测试靶场。 分别是DVWA、Pikachu、SQLi-Labs、Upload-Labs、XSS-Labs。 DVWA靶场 DVWA靶场是一个专门用于漏洞测试和练习的Web应用程序,旨在为安全专业…...