python操作Elasticsearch执行增删改查
文章目录
- 基本操作
- 更多查询方法
- 1. 查询全部数据
- 2. 针对某个确定的值/字符串的查询:term、match
- 3. 在多个选项中有一个匹配,就查出来:terms
- 4. 数值范围查询:range
- 5. 多个条件同时触发 bool
- 6. 指定返回值个数 size
- 7. 返回指定列 _source
- 完整示例程序
基本操作
- 首先连接Elasticsearch数据库,然后创建一个自定义的索引
from elasticsearch import Elasticsearch
import random
from elasticsearch import helpers# 连接到本地的 Elasticsearch 服务
es = Elasticsearch(hosts=["http://localhost:9200"])
index_name = "my_index"# 创建一个索引名为 "my_index" 的索引
if es.indices.exists(index=index_name): # 如果索引存在,删除es.indices.delete(index=index_name)
es.indices.create(index=index_name) # 新建索引
- 新增随机数据
这里我们创建随机数据项,包含value_num与value_choice项,
# 新增随机数据项
add_value_list: list = []
for _ in range(1000):num = random.randint(1, 100)add_value_list.append({"_index": index_name, # 注意!个参数决定要插入到哪个索引中"value_num": random.randint(1, 100),"value_choice": ["c1", 'c2', 'c3'][random.randint(0, 2)],})
# 批量插入数据
helpers.bulk(es, add_value_list)
- 查询操作
# 查询操作
_body_query = {"query": {"range": {"value_num": {"gte": 40, # >= 40"lte": 60 # <= 60}}},"size": 20, # 查询20条
}
response = es.search(index=index_name, body=_body_query)
# 打印查询的结果
for _hit in response["hits"]["hits"]:_value = _hit['_source']print("value_num:", _value["value_num"], " value_choice:", _value['value_choice'])
- 更新数据项
这里,我们将查询出的数据中,通过文档ID与修改的数据重新为数据赋值
# 更新操作
for _hit in response["hits"]["hits"]:update_body = {"doc": {"value_choice": "c4", # 更新value_choice字段为c4}}res = es.update(index=index_name, id=_hit['_id'], body=update_body)
- 删除数据项
# 删除操作
for _hit in response["hits"]["hits"]:res = es.delete(index=index_name, id=_hit['_id'])
更多查询方法
1. 查询全部数据
_body_query = {"query":{"match_all":{}}
}
2. 针对某个确定的值/字符串的查询:term、match
match会执行多个term操作,term操作精度更高
_body_query = {"query": {"match": {"value_choice": "c1"}}
}
_body_query = {"query": {"term": {"value_choice": "c1"}}
}
3. 在多个选项中有一个匹配,就查出来:terms
_body_query = {"query": {"terms": {"value_choice": ["c1", "c2"],}}
}
4. 数值范围查询:range
查询>=40且<=60的数据
_body_query = {"query": {"range": {"value_num": {"gte": 40, # >= 40"lte": 60 # <= 60}}}
}
5. 多个条件同时触发 bool
布尔查询可以同时查询多个条件,也称为组合查询,构造查询的字典数据时,query后紧跟bool,之后再跟bool的判断条件,判断条件有下面几个:
- filter:过滤器
- must:类似and,需要所有条件都满足
- should:类似or,只要能满足一个即可
- must_not:需要都不满足
写完判断条件后,在判断条件的list里再紧跟查询操作的具体细节
_body_query = {"query": {"bool": {"should": [{"match": {"value_choice": "c1"} # value_choice = "c1"},{"range": {"value_num": {"lte": 50}} # value_num <= 50}]}},
}
6. 指定返回值个数 size
在构造的字典中添加size关键字即可
_body_query = {"query": {"range": {"value_num": {"gte": 40, # >= 40"lte": 60 # <= 60}}},"size": 20,
}
7. 返回指定列 _source
_body_query = {"query": {"range": {"value_num": {"gte": 40, # >= 40"lte": 60 # <= 60}}},"_source": ["value_num"] # 这里指定返回的fields
}
完整示例程序
from elasticsearch import Elasticsearch
import random
from elasticsearch import helpers# 连接到本地的 Elasticsearch 服务
es = Elasticsearch(hosts=["http://localhost:9200"])
index_name = "my_index"# 创建一个索引名为 "my_index" 的索引
if es.indices.exists(index=index_name): # 如果索引存在,删除es.indices.delete(index=index_name)
es.indices.create(index=index_name) # 新建索引# 生成随机数据
add_value_list: list = []
for _ in range(1000):num = random.randint(1, 100)add_value_list.append({"_index": index_name, # 注意!个参数决定要插入到哪个索引中"value_num": random.randint(1, 100),"value_choice": ["c1", 'c2', 'c3'][random.randint(0, 2)],})
# 批量插入数据
helpers.bulk(es, add_value_list)# ================== 开始增删改查 ==================
_body_query = {"query": {"range": {"value_num": {"gte": 40, # >= 40"lte": 60 # <= 60}}},"size": 20,
}response = es.search(index=index_name, body=_body_query) # 查询10条
# 打印查询的结果
for _hit in response["hits"]["hits"]:_value = _hit['_source']print("value_num:", _value["value_num"], " value_choice:", _value['value_choice'])# 更新操作
for _hit in response["hits"]["hits"]:update_body = {"doc": {"value_choice": "c4", # 更新value_choice字段为c4}}res = es.update(index=index_name, id=_hit['_id'], body=update_body)# 删除操作
for _hit in response["hits"]["hits"]:res = es.delete(index=index_name, id=_hit['_id'])
相关文章:

python操作Elasticsearch执行增删改查
文章目录 基本操作更多查询方法1. 查询全部数据2. 针对某个确定的值/字符串的查询:term、match3. 在多个选项中有一个匹配,就查出来:terms4. 数值范围查询:range5. 多个条件同时触发 bool6. 指定返回值个数 size7. 返回指定列 _so…...

学习C++:关键字
关键字: 作用:关键字是C预先保留的单词(标识符) 在定义变量或者常量时候,不要用关键字 不要用关键字给变量或者常量起名称...

FFmpeg在python里推流被处理过的视频流
链式算法处理视频流 视频源是本地摄像头 # codinggbk # 本地摄像头直接推流到 RTMP 服务器 import cv2 import mediapipe as mp import subprocess as sp# 初始化 Mediapipe mp_drawing mp.solutions.drawing_utils mp_drawing_styles mp.solutions.drawing_styles mp_holis…...

为什么推荐使用构造函数注入而非@Autowired注解进行字段注入
在 Spring 框架中,推荐使用构造函数注入而非Autowired注解进行字段注入,主要有以下几个原因: 1. 依赖不可变和空指针安全 构造函数注入:使用构造函数注入时,依赖在对象创建时就必须提供,一旦对象创建完成&…...

如何卸载和升级 Angular-CLI ?
Angular-CLI 是开发人员使用 Angular 的必备工具。然而,随着频繁的更新和新版本的出现,了解如何有效地卸载和升级 Angular-CLI 对开发人员来说至关重要。本指南提供了一个全面的、循序渐进的方法来帮助您顺利过渡到最新版本。 必备条件 确保您的系统上…...
)
在线excel编辑(luckysheet)
项目地址:Luckysheet: 🚀Luckysheet ,一款纯前端类似excel的在线表格,功能强大、配置简单、完全开源。 可以下载项目使用npm安装运行,也可以用cdn 加载excel文件(使用luckyexcel): …...
)
【ES6复习笔记】Symbol 类型及其应用(9)
一、Symbol 简介 Symbol 是 JavaScript 中的一种基本数据类型,它表示唯一的标识符。Symbol 的主要目的是防止属性名冲突,尤其是在多个代码库或模块中共享对象时。Symbol 值可以用作对象的属性名,这样可以确保属性名是唯一的,不会…...

[原创](Modern C++)现代C++的第三方库的导入方式: 例如Visual Studio 2022导入GSL 4.1.0
[简介] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共23年] 职业生涯: 21年 开发语言: C/C、80x86ASM、PHP、Perl、Objective-C、Object Pascal、C#、Python 开发工具: Visual Studio、Delphi、XCode、Eclipse…...
)
【ES6复习笔记】Class类(15)
介绍 ES6 提供了更接近传统语言的写法,引入了 Class(类)这个概念,作为对象的模板。通过 class 关键字,可以定义类。基本上,ES6 的 class 可以看作只是一个语法糖,它的绝大部分功能,…...
)
【Golang 面试题】每日 3 题(六)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/UWz06 📚专栏简介:在这个专栏中,我将会分享 Golang 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏…...

openEuler安装OpenGauss5.0
OpenGauss5.0 Linux服务器 极简版 服务器安装 单节点安装 极简版安装 安装准备 获取安装包 下载地址:https://opengauss.org/zh/download/archive/版本选择:5.0.0 (LTS)系统架构:uname -m操作系统:cat /etc/os-release完整性校…...
线性回归(scikitlearn))
20241230 机器学习ML -(1)线性回归(scikitlearn)
机器学习ML入门。 线性回归 ScikitLearnLRRidgeLassoElasticNetL2:解决共线性问题 (Colinearity Problem) L1:特征选择(AI的解释) W=XtX XtY (Xw=Y >> XtXw= XtY) 当 COND(Xtx) ~ infinit, 导致inv(XtX)无解 举例: 12 23 46 XtX=[14,28] [28,56] eigVal=det…...

MacOS下TestHubo安装配置指南
TestHubo是一款开源免费的测试管理工具, 下面介绍MacOS私有部署的安装与配置。TestHubo 私有部署版本更适合有严格数据安全要求的企业,支持在本地或专属服务器上运行,以实现对数据和系统的完全控制。 1、Mac 服务端安装 Mac安装包下载地址&a…...

mysql性能问题排查
生产环境 Mysql执行性能分析 问题排查思路通过 performance_schema 分析performance_schema 说明查询 performance_schema 所有表信息performance_schema 相关表 主要相关介绍events_statements_history 分析慢查询 和查询当时状态字段说明 问题排查思路 查询慢SQL日志查询SQL…...

centos单机部署seata
文章目录 场景分析下载seata包启动 场景 centos7.9 jdk17 安装部署seata 分析 jdk和seata的版本对应关系如图 JDK版本 推荐 Seata 版本 理由 JDK 8 任何 Seata 版本 JDK 8 是 Seata 长期支持的版本,兼容性最好。 JDK 11 Seata 1.2.0 适合需要长期支持且性能较高的应…...

YOLOv9-0.1部分代码阅读笔记-lion.py
lion.py utils\lion.py 目录 lion.py 1.所需的库和模块 2.class Lion(Optimizer): 1.所需的库和模块 # Lion优化器是一种新型的神经网络优化算法,由Google Brain团队通过遗传算法发现,全称为EvoLved SIgn MOmeNtum,意为“进化的符号动…...

运行Zr.Admin项目(前端)
1.确认环境信息 我这里装的是node16.17版本的 官网16版本的最新为v16.20.2,下载链接https://nodejs.org/dist/v16.20.2/node-v16.20.2-x64.msi 2.去掉ssl 进入到Zr.Admin项目根目录,进入到ZR.vue 打开package.json 文件,删除启动命令配置中…...

HarmonyOS NEXT 实战之元服务:静态多案例效果(一)
背景: 前几篇学习了元服务,后面几期就让我们开发简单的元服务吧,里面丰富的内容大家自己加,本期案例 仅供参考 先上本期效果图 ,里面图片自行替换 效果图1代码案例如下: import { authentication } from…...

go下载依赖提示连接失败
1、现象 Go下载模块提示连接失败 dial tcp 142.251.42.241:443: connectex: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond.…...
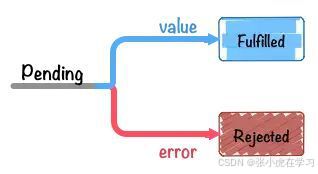
JS 异步 ( 二、Promise 的用法、手写模拟 Promise )
文章目录 一、Promise 基础Promise 作用Promise 语法Promise 内部状态值 和 链式调用Promise 是否为异步执行Promise 常用函数或属性 二、模拟 Promise,加深理解 一、Promise 基础 Promise 作用 1. 回调地狱 想知道 Promise 的作用, 需要先了解一个概念叫…...

Phi-4-mini-reasoning保姆级教学:Web服务健康检查失败的5类根因与对策
Phi-4-mini-reasoning保姆级教学:Web服务健康检查失败的5类根因与对策 1. 问题背景与模型介绍 Phi-4-mini-reasoning 是一款专注于推理任务的文本生成模型,特别擅长处理数学题、逻辑题、多步分析和简洁结论输出。与通用聊天模型不同,它采用…...

保姆级教学:FLUX.1文生图+SDXL Prompt风格,从环境准备到图片生成的完整流程
保姆级教学:FLUX.1文生图SDXL Prompt风格,从环境准备到图片生成的完整流程 你是否曾经遇到过这样的困扰:明明输入了详细的描述词,但生成的图片却与预期相差甚远?或者尝试混合多种风格时,结果变得不伦不类&…...
结合Q学习算法(Q-learning)进行无人机三维路径规划(含模型描述及部分示例代码) 还请多多点一下关注 加油)
项目介绍 MATLAB实现基于PSO-Q-learning 粒子群优化算法(PSO)结合Q学习算法(Q-learning)进行无人机三维路径规划(含模型描述及部分示例代码) 还请多多点一下关注 加油
MATLAB实现基于PSO-Q-learning 粒子群优化算法(PSO)结合Q学习算法(Q-learning)进行无人机三维路径规划的详细项目实例 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序&…...

房屋建筑学-门窗
一、门窗概述门窗的作用——采光、通风、通行(按照国家相应的规范要求,一般居住建筑的起居室、卧室的窗户面积不应小于地板面积的1/7;公建建筑方面,学校为1/5,医院手术室为1/2~1/3,辅助房间为1/12ÿ…...

OpenClaw备份方案:Qwen2.5-VL-7B技能与配置的定期同步
OpenClaw备份方案:Qwen2.5-VL-7B技能与配置的定期同步 1. 为什么需要备份OpenClaw系统 上周我的开发机突然蓝屏,硬盘分区表损坏。当我重装系统后,发现过去三个月精心调教的OpenClaw配置全部丢失——包括调试好的技能参数、对接的飞书机器人…...

OpenClaw+Phi-3-vision-128k-instruct安全方案:敏感数据本地化处理指南
OpenClawPhi-3-vision-128k-instruct安全方案:敏感数据本地化处理指南 1. 为什么需要本地化处理敏感数据? 上周我帮一位做财务咨询的朋友处理季度报表时,他提到一个痛点:每次用云端AI工具分析客户财务数据都提心吊胆。这让我意识…...

如何快速集成gh_mirrors/ca/card到React/Vue/Angular:打造专业信用卡表单的完整指南
如何快速集成gh_mirrors/ca/card到React/Vue/Angular:打造专业信用卡表单的完整指南 【免费下载链接】card :credit_card: make your credit card form better in one line of code 项目地址: https://gitcode.com/gh_mirrors/ca/card gh_mirrors/ca/card是一…...

思维重构:三月七小助手如何重新定义星穹铁道游戏体验
思维重构:三月七小助手如何重新定义星穹铁道游戏体验 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 在《崩坏:星穹铁道》的世界里࿰…...
技术研究)
光伏并网发电系统最大功率点跟踪(MPPT)技术研究
光伏并网发电系统最大功率点跟踪(MPPT)技术研究 第一章 绪论 1.1 研究背景与意义 随着全球能源危机和环境污染问题的日益严峻,太阳能作为一种取之不尽、用之不竭的清洁能源,受到了广泛关注。光伏并网发电系统已成为太阳能利用的主要形式。然而,光伏电池的光电转换效率较…...

N16 LCD
一、LCD简介LCD 液晶显示屏。i.MX6ULL 里驱动它的模块叫:eLCDIF Enhanced LCD Interface(增强型 LCD 接口,芯片内置的硬件控制器)分辨率:1920 * 1080 1280*720色域:帧率/刷新率:LCD 扫…...