NIPS2014 | GAN: 生成对抗网络
Generative Adversarial Nets
- 摘要-Abstract
- 引言-Introduction
- 相关工作-Related Work
- 对抗网络-Adversarial Nets
- 理论结果-Theoretical Results
- 实验-Experiments
- 优势和不足-Advantages and disadvantages
- 缺点
- 优点
- 结论及未来工作-Conclusions and future work
- 研究总结
- 未来研究方向
论文链接
本文 “Generative Adversarial Nets” 提出了生成对抗网络(GAN)这一通过对抗过程估计生成模型的新框架,为生成模型的研究开辟了新方向。
摘要-Abstract
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G G G that captures the data distribution, and a discriminative model D D D that estimates the probability that a sample came from the training data rather than G G G. The training procedure for G G G is to maximize the probability of D D D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G G G and D D D, a unique solution exists, with G G G recovering the training data distribution and D D D equal to 1 2 \frac{1}{2} 21 everywhere. In the case where G G G and D D D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
我们提出了一种通过对抗过程估计生成模型的新框架,在这个框架中我们同时训练两个模型:一个生成模型 G G G,它捕获数据分布;以及一个判别模型 D D D,它估计一个样本来自训练数据而非 G G G 的概率。 G G G 的训练过程是最大化 D D D 犯错的概率。这个框架对应于一个极小极大的双人博弈。在任意函数 G G G 和 D D D 的空间中,存在一个唯一解,此时 G G G 恢复训练数据分布,并且 D D D 处处等于 1 2 \frac{1}{2} 21。在 G G G 和 D D D 由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间,不需要任何马尔可夫链或展开的近似推理网络。实验通过对生成样本的定性和定量评估展示了该框架的潜力。
引言-Introduction
深度学习旨在发现丰富的分层模型以表示数据概率分布,但目前在生成模型方面影响较小。生成对抗网络(GAN)框架通过对抗过程估计生成模型,其生成模型与判别模型相互竞争,推动双方改进方法,直至生成样本与真实样本难以区分。在该框架中,生成模型通过多层感知器将随机噪声映射到数据空间,判别模型也为多层感知器,用于判断样本来源。此框架可避免传统生成模型在近似概率计算和利用分段线性单元方面的困难,且训练时仅需反向传播和随机失活算法,无需马尔可夫链或近似推断网络,为生成模型研究带来新的思路与方法。
相关工作-Related Work
该部分主要回顾了与生成对抗网络(GAN)相关的先前研究工作,包括深度生成模型、生成机器、基于判别准则训练生成模型、神经网络竞争概念以及对抗样本等方面的研究进展,通过与这些工作对比,凸显了GAN的独特性与创新性。具体内容如下:
- 深度生成模型:多数工作聚焦于通过最大化对数似然训练提供概率分布函数参数化规范的模型,如深度玻尔兹曼机,但此类模型似然函数难处理,需众多近似计算。
- 生成机器:为解决上述问题,“生成机器”应运而生,如生成随机网络,可通过精确反向传播训练,但仍需马尔可夫链。本文工作在此基础上消除了马尔可夫链的使用。
- 基于判别准则训练生成模型:已有方法使用判别准则训练生成模型,但对于深度生成模型,这些准则难以处理,因其涉及概率比率,无法用变分近似法逼近。噪声对比估计(NCE)通过让生成模型区分数据与固定噪声分布来训练,类似GAN中的竞争机制,但NCE的“判别器”定义需评估和反向传播两种密度,限制了其应用。
- 神经网络竞争概念:先前工作如预测性最小化,让神经网络隐藏单元与预测其值的另一网络输出竞争,但与GAN有显著差异。GAN中网络竞争是唯一训练准则,竞争性质为生成丰富高维向量作为输入,且基于极小极大游戏而非优化问题。
- 对抗样本:GAN常与“对抗样本”概念混淆,对抗样本是通过梯度优化找到的使分类网络误分类的样本,主要用于分析神经网络行为,而非训练生成模型,而GAN是一种生成模型训练机制。
对抗网络-Adversarial Nets
这部分主要介绍了生成对抗网络(GAN)的模型结构、训练过程以及在实际训练中遇到的问题和解决方法,为理解GAN的工作原理和实现方式提供了详细阐述。具体内容如下:
- 模型结构
- 生成模型 G G G:将输入噪声变量 z z z(先验为 p z ( z ) p_z(z) pz(z))通过多层感知器映射到数据空间,记为 G ( z ; θ g ) G(z; \theta_g) G(z;θg),其中 θ g \theta_g θg 为参数。
- 判别模型 D D D:同样为多层感知器,输出一个标量,表示样本 x x x 来自数据而非生成模型 G G G 生成样本的概率。
- 训练过程
- 训练目标:判别模型 D D D 训练目标是最大化将训练样本和生成模型 G G G 生成样本正确分类的概率,生成模型 G G G 训练目标是最小化 log ( 1 − D ( G ( z ) ) ) \log (1 - D(G(z))) log(1−D(G(z))),二者构成极小极大博弈,价值函数为 V ( G , D ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] V(G, D)=\mathbb{E}_{x \sim p_{data}(x)}[\log D(x)]+\mathbb{E}_{z \sim p_{z}(z)}[\log (1 - D(G(z)))] V(G,D)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]。
- 实际训练方法:由于直接优化判别模型 D D D 至最优计算成本高且易过拟合,实际采用交替优化方法,即先进行 k k k 步优化 D D D(通过小批量随机梯度上升),再进行1步优化 G G G(通过小批量随机梯度下降),实验中 k = 1 k = 1 k=1 效果较好。
- 训练问题及解决方法:训练初期,生成模型 G G G 生成样本较差,判别模型 D D D 能高置信度拒绝,导致 log ( 1 − D ( G ( z ) ) ) \log (1 - D(G(z))) log(1−D(G(z))) 饱和,梯度消失。解决方法是训练 G G G 最大化 log D ( G ( z ) ) \log D(G(z)) logD(G(z)),该目标函数在学习早期能提供更强梯度,且与最小化 log ( 1 − D ( G ( z ) ) ) \log (1 - D(G(z))) log(1−D(G(z))) 有相同的动态平衡点。

图1:生成对抗网络通过同时更新判别分布( D D D,蓝色虚线)来进行训练,使其能够区分来自数据生成分布(黑色点线) p x p_{x} px 的样本和来自生成分布 p g p_{g} pg( G G G)(绿色实线)的样本。下方的水平线是 z z z 采样的域,在此情况下是均匀采样。上方的水平线是 x x x 域的一部分。向上的箭头展示了映射 x = G ( z ) x = G(z) x=G(z) 如何将非均匀分布 p g p_{g} pg 施加到变换后的样本上。 G G G 在 p g p_{g} pg 的高密度区域收缩,在低密度区域扩展。
(a)考虑一对接近收敛的对抗网络: p g p_{g} pg 与 p d a t a p_{data} pdata 相似,并且 D D D 是一个部分准确的分类器。
(b)在算法的内循环中, D D D 被训练以区分来自数据的样本,收敛到 D ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) D^*(x)=\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)} D∗(x)=pdata(x)+pg(x)pdata(x)。
(c)在对 G G G 进行更新后, D D D 的梯度引导 G ( z ) G(z) G(z) 流向更有可能被分类为数据的区域。
(d)经过若干步训练后,如果 G G G 和 D D D 有足够的能力,它们将达到一个两者都无法改进的点,因为 p g = p d a t a p_{g}=p_{data} pg=pdata。此时判别器无法区分这两个分布,即 D ( x ) = 1 2 D(x)=\frac{1}{2} D(x)=21。
理论结果-Theoretical Results
本部分从理论上对生成对抗网络(GAN)进行了深入分析,包括证明极小极大博弈的全局最优解以及算法1的收敛性,为GAN的有效性提供了理论支持,具体内容如下:
- 全局最优性
- 最优判别器 D D D 的形式:对于给定的生成器 G G G,最优判别器 D G ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) D_G^*(x)=\frac{p_{data}(x)}{p_{data}(x)+p_g(x)} DG∗(x)=pdata(x)+pg(x)pdata(x)。证明通过对判别器训练准则 V ( G , D ) V(G, D) V(G,D) 求最大值得到,其本质是最大化估计条件概率 P ( Y = y ∣ x ) P(Y = y|x) P(Y=y∣x) 的对数似然( Y Y Y 表示样本 x x x 来源, y = 1 y = 1 y=1 表示来自 p d a t a p_{data} pdata, y = 0 y = 0 y=0 表示来自 p g p_g pg)。
- 全局最小值条件:当且仅当 p g = p d a t a p_g = p_{data} pg=pdata 时,虚拟训练准则 C ( G ) C(G) C(G) 达到全局最小值 − log 4 -\log 4 −log4。证明通过将 p g = p d a t a p_g = p_{data} pg=pdata 代入 C ( G ) C(G) C(G) 表达式得到 C ( G ) = log 1 2 + log 1 2 = − log 4 C(G)=\log \frac{1}{2}+\log \frac{1}{2}=-\log 4 C(G)=log21+log21=−log4,再通过与 C ( G ) = − log ( 4 ) + K L ( p d a t a ∣ ∣ p d a t a + p g 2 ) + K L ( p g ∣ ∣ p d a t a + p g 2 ) C(G)=- \log (4)+KL(p_{data}||\frac{p_{data}+p_g}{2})+KL(p_g||\frac{p_{data}+p_g}{2}) C(G)=−log(4)+KL(pdata∣∣2pdata+pg)+KL(pg∣∣2pdata+pg) 对比,利用詹森 - 香农散度(JSD)非负性,得出 C ∗ ( G ) = − log 4 C^*(G)=-\log 4 C∗(G)=−log4 为全局最小值且唯一解为 p g = p d a t a p_g = p_{data} pg=pdata。
- 算法1的收敛性:若 G G G 和 D D D 有足够容量,在 算法1 的每一步中,判别器能达到给定 G G G 下的最优,且 p g p_g pg 按 E x ∼ p d a t a [ log D G ∗ ( x ) ] + E x ∼ p g [ log ( 1 − D G ∗ ( x ) ) ] \mathbb{E}_{x \sim p_{data}}[\log D_G^*(x)]+\mathbb{E}_{x \sim p_g}[\log (1 - D_G^*(x))] Ex∼pdata[logDG∗(x)]+Ex∼pg[log(1−DG∗(x))] 准则更新,则 p g p_g pg 收敛到 p d a t a p_{data} pdata。证明基于 V ( G , D ) = U ( p g , D ) V(G, D)=U(p_g, D) V(G,D)=U(pg,D) 是 p g p_g pg 的凸函数,其上确界的次导数包含函数在最大值点的导数,通过计算 p g p_g pg 的梯度下降更新,结合定理1中 sup D U ( p g , D ) \sup_D U(p_g, D) supDU(pg,D) 在 p g p_g pg 上的凸性和唯一全局最优性,得出 p g p_g pg 收敛到 p d a t a p_{data} pdata 的结论。
算法1:生成对抗网络的小批量随机梯度下降训练。应用于判别器的步数 k k k 是一个超参数。在我们的实验中,我们使用了 k = 1 k = 1 k=1,这是成本最低的选项。

在实际中,虽然GAN通过函数 G ( z ; θ g ) G(z; \theta_g) G(z;θg) 表示有限的 p g p_g pg 分布族,优化 θ g \theta_g θg 而非 p g p_g pg 本身,使得上述理论证明不完全适用,但多层感知器在实践中的良好性能表明其仍是合理模型。
实验-Experiments
该部分详细阐述了在多个数据集上对生成对抗网络(GAN)进行训练的实验过程,包括数据集选择、模型配置、评估指标以及实验结果展示,通过实验验证了GAN的有效性和潜力,具体内容如下:
- 实验设置
- 数据集:使用了MNIST、多伦多人脸数据库(TFD)和CIFAR - 10等数据集进行训练。
- 模型结构与激活函数:生成器网络使用整流线性激活函数和sigmoid激活函数的混合,判别器网络使用maxout激活函数,并在训练判别器网络时应用了随机失活(dropout)。实验中仅在生成器网络的最底层输入中添加噪声。
- 评估方法
- 通过将高斯Parzen窗拟合到生成器 G G G 生成的样本上,来估计测试集数据在 p g p_g pg 下的概率,并报告其对数似然。高斯分布的 σ \sigma σ 参数通过在验证集上进行交叉验证获得。此方法虽在高维空间表现不佳且方差较大,但为当时估计生成模型似然的最佳可用方法,也凸显了研究新评估方法的必要性。
- 实验结果
- 表1 展示了在MNIST和TFD数据集上基于Parzen窗的对数似然估计结果,与其他模型对比,体现了GAN的性能表现。
- 图2 展示了训练后从生成器网络中抽取的样本,表明这些样本与训练集中的最近邻样本不同,是模型实际生成的,且采样过程不依赖马尔可夫链混合,样本间不相关,凸显了GAN生成样本的能力。
- 图3 展示了通过在 z z z 空间坐标之间进行线性插值得到的数字,进一步展示了模型的特性。
通过这些实验,虽未声称GAN生成的样本优于现有方法,但表明其至少与文献中较好的生成模型具有竞争力,证明了对抗框架在生成模型研究中的潜力。

表1:基于Parzen窗的对数似然估计。MNIST数据集上报告的数字是测试集样本的平均对数似然,均值的标准误差是通过样本计算得出的。在TFD数据集上,我们计算了数据集各折的标准误差,每折使用其验证集选择不同的 σ \sigma σ。在TFD数据集上, σ \sigma σ在每一折上进行交叉验证,并计算每折的平均对数似然。对于MNIST,我们与该数据集的实值(而非二进制)版本的其他模型进行比较。

图2:模型样本的可视化。最右侧列显示相邻样本的最近训练示例,以证明模型没有记忆训练集。样本是公平的随机抽取,并非精心挑选。与大多数其他深度生成模型的可视化不同,这些图像展示的是来自模型分布的实际样本,而非给定隐藏单元样本的条件均值。此外,由于采样过程不依赖马尔可夫链混合,这些样本是不相关的。a) MNIST数据集 b) TFD数据集 c) CIFAR - 10(全连接模型)d) CIFAR - 10(卷积判别器和“反卷积”生成器)

图3:通过在完整模型的(z)空间坐标之间进行线性插值得到的数字。
优势和不足-Advantages and disadvantages
该部分主要分析了生成对抗网络(GAN)相对于先前建模框架的优缺点,明确了GAN的特性和改进方向,具体内容如下:
缺点
- 缺乏显式表示:生成模型 p g ( x ) p_g(x) pg(x) 没有显式表示,这在某些应用场景下可能限制对模型分布的直接理解和分析。
- 训练同步要求高:训练时判别器 D D D 必须与生成器 G G G 良好同步。若 G G G 训练过多而未及时更新 D D D,可能出现“Helvetica场景”,即 G G G 将过多 z z z 值映射到相同 x x x 值,导致缺乏足够多样性来建模 p d a t a p_{data} pdata,类似于玻尔兹曼机中负链需在学习步骤间保持更新的要求。
优点
- 计算效率高
- 无需马尔可夫链,仅通过反向传播即可获得梯度,简化了训练过程。
- 学习过程中无需进行复杂推断,减少了计算资源和时间消耗。
- 能够灵活融入各种函数,增加了模型的表达能力。
- 统计特性良好
- 生成器网络仅通过判别器的梯度更新,避免了输入组件直接复制到参数中,有助于学习到更具代表性的特征。
- 可以表示非常尖锐甚至退化的分布,而基于马尔可夫链的方法为保证链在模式间混合,要求分布相对模糊,GAN在这方面具有优势。
总体而言,GAN在计算方面具有显著优势,在统计特性上也有独特之处,但仍存在一些需要解决的问题,特别是在训练同步和分布表示方面。这些优缺点为进一步研究和改进GAN提供了重要参考。
结论及未来工作-Conclusions and future work
本部分总结了生成对抗网络(GAN)框架的研究成果,并对未来研究方向提出了展望,为GAN的进一步发展提供了思路,具体内容如下:
研究总结
本文提出的GAN框架通过对抗过程估计生成模型,理论分析表明在一定条件下能使生成模型收敛到数据分布,实验在多个数据集上验证了其有效性,生成样本具有竞争力,证明了对抗框架的可行性。
未来研究方向
- 构建条件生成模型:通过将条件变量 c c c 作为输入添加到生成器 G G G 和判别器 D D D 中,可得到条件生成模型 p ( x ∣ c ) p(x|c) p(x∣c),从而扩展GAN的应用范围,如生成特定类别的图像等。
- 执行学习近似推断:训练一个辅助网络来预测给定 x x x 的 z z z,类似于唤醒 - 睡眠算法中的推断网,但具有在生成器网络训练完成后针对固定生成器进行训练的优势,有助于深入理解生成过程中的潜在因素。
- 建模条件分布:训练一系列共享参数的条件模型来近似建模 p ( x S ∣ x S ′ ) p(x_S|x_{S'}) p(xS∣xS′)( S S S 是 x x x 索引的子集),可实现对数据条件关系的更深入建模,例如对图像不同部分之间的关系进行建模。
- 用于半监督学习:利用判别器或推断网的特征,在有限标记数据情况下提高分类器性能,为半监督学习提供新的方法和思路,有望在数据标记困难或成本高昂的场景中发挥作用。
- 改进训练效率:通过设计更好的方法协调 G G G 和 D D D 的训练,或确定更合适的 z z z 采样分布,有望大幅加速训练过程,提高GAN的实用性和效率,使其能更好地应用于大规模数据和复杂任务。
这些研究方向有望进一步挖掘GAN框架的潜力,推动生成模型领域的发展,为解决实际问题提供更强大的工具。
相关文章:
NIPS2014 | GAN: 生成对抗网络
Generative Adversarial Nets 摘要-Abstract引言-Introduction相关工作-Related Work对抗网络-Adversarial Nets理论结果-Theoretical Results实验-Experiments优势和不足-Advantages and disadvantages缺点优点 结论及未来工作-Conclusions and future work研究总结未来研究方…...

Postman接口测试01|接口测试基础概念、http协议、RESTful风格、接口文档
目录 一、接口测试基础概念 1、什么是接口 2、接口的类型 3、什么是接口测试 4、为什么要做接口测试 5、接口测试的实现方式 6、什么是自动化接口测试? 二、接口返回的数据格式 1、三种格式 2、Json 三、接口协议 1、webservice协议 2、dubbo协议 3、…...

Linux系统编程——详解页表
目录 一、前言 二、深入理解页表 三、页表的实际组成 四、总结: 一、前言 页表是我们之前在讲到程序地址空间的时候说到的,它是物理内存到进程程序地址空间的一个桥梁,通过它物理内存的数据和代码才能映射到进程的程序地址空间中ÿ…...

SpringBoot + HttpSession 自定义生成sessionId
SpringBoot HttpSession 自定义生成sessionId 业务场景实现方案 业务场景 最近在做用户登录过程中,由于默认ID是通过UUID创建的,缺乏足够的安全性,决定要自定义生成 sessionId。 实现方案 正常的获取session方法如下: HttpSe…...
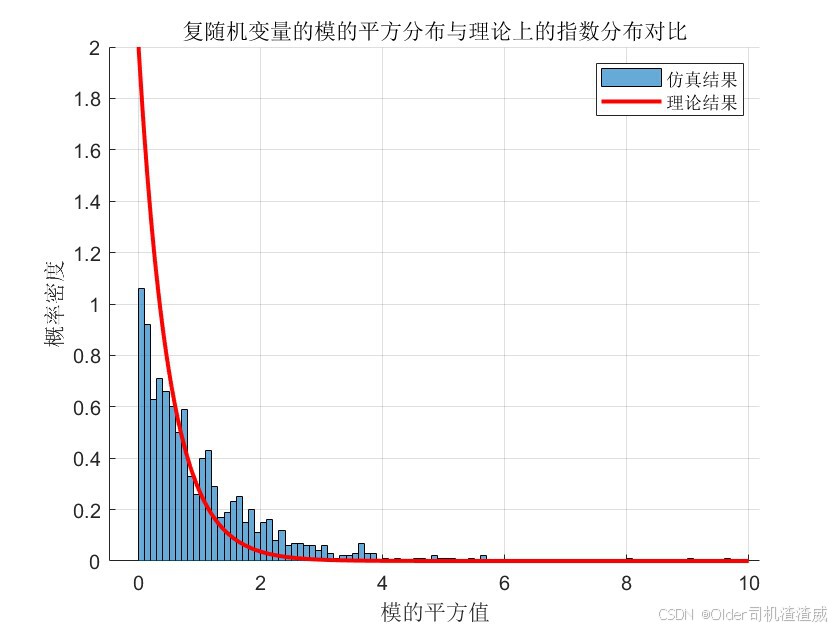
循环对称复高斯分布(Circularly Symmetric Complex Gaussian Distribution)
一、引言 循环对称复高斯分布(Circularly Symmetric Complex Gaussian Distribution,简称CSCG)在无线通信、信号处理等领域具有广泛的应用。作为一种特殊的复高斯分布,CSCG具有独特的性质,如循环对称性、高斯性等&…...
xinput1_3.dll放在哪里?当xinput1_3.dll丢失时的应对策略:详细解决方法汇总
在计算机系统的运行过程中,我们偶尔会遇到一些令人困扰的问题,其中xinput1_3.dll文件丢失就是较为常见的一种情况。这个看似不起眼的动态链接库文件,实则在许多软件和游戏的正常运行中发挥着至关重要的作用。一旦它丢失,可能会导致…...

基于STM32的智能家居环境监控系统设计
目录 引言系统设计 硬件设计软件设计系统功能模块 环境监控模块控制模块显示模块系统实现 硬件实现软件实现系统调试与优化结论与展望 1. 引言 随着智能家居技术的发展,环境监控系统已经成为家居管理的重要组成部分。智能家居环境监控系统通过实时监测室内温度、湿…...

Vscode + gdbserver远程调试开发板指南:
本章目录 步骤环境准备网络配置vscode配置步骤 (全图示例)开发板配置开始调试注意: 每次断开之后,开发板都需要重新启动gdbserver才可调试。 参考链接: 步骤 环境准备 将交叉编译链路径加入$PATH变量:确保系统能够找到所需的工具。 export PATH$PATH:/p…...

大表:适用于结构化数据的分布式存储系统
大家觉得有意义和帮助记得及时关注和点赞!!! 译者序摘要1 引言2 数据模型 2.1 行(Row)2.2 Column Families(列族) 2.2.1 设计2.2.2 column key 的格式:family:qualifier2.2.3 访问控制和磁盘/内存记账(acco…...

深入解析MVCC中Undo Log版本底层存储读取逻辑
一、引言 多版本并发控制(MVCC,Multi-Version Concurrency Control)是一种广泛应用于关系数据库管理系统中的并发控制技术。它通过保存数据的历史版本,使得在事务并发执行时,每个事务都能看到数据的一致性视图。在MVC…...

游戏引擎学习第64天
代码改的我看的比较懵 原视频可以去这个网站去看 https://guide.handmadehero.org/ 回顾我们在模拟区域方面的进展 在目前的情况下,如果有很多任务需要完成,可以进行分解。在昨天收到的改变中,决定将任务分解成模拟区域。模拟区域是可以随时…...

Effective C++ 条款33:避免遮掩继承而来的名称
文章目录 条款33:避免遮掩继承而来的名称为什么避免遮掩?如何避免遮掩?1. 使用 using 声明式2. 使用转交函数 (Forwarding Functions) 总结 条款33:避免遮掩继承而来的名称 在 C 中,派生类(derived class&…...
)
UEFI Spec 学习笔记---4 - EFI System Table(1)
4 - EFI System Table 本章节主要介绍的是 UEFI Image 的 Entry point(在 UEFI 固件执行的时候,都是直接调用入口函数并且执行从而调用其他的 driver)。 UEFI Image 主要是有三类:UEFI boot service driver、UEFI runtime drive…...

【微信小程序】3|首页搜索框 | 我的咖啡店-综合实训
首页-搜索框-跳转 引言 在微信小程序中,首页的搜索框是用户交互的重要入口。本文将通过“我的咖啡店”小程序的首页搜索框实现,详细介绍如何在微信小程序中创建和处理搜索框的交互。 1. 搜索函数实现 onClickInput函数在用户点击搜索框时触发&#x…...
独一无二,万字详谈——Linux之文件管理
Linux文件部分的学习,有这一篇的博客足矣! 目录 一、文件的命名规则 1、可以使用哪些字符? 2、文件名的长度 3、Linux文件名的大小写 4、Linux文件扩展名 二、文件管理命令 1、目录的创建/删除 (1)、目录的创建 ① mkdir…...

React:前端开发领域的璀璨之星
亲爱的小伙伴们😘,在求知的漫漫旅途中,若你对深度学习的奥秘、Java 与 Python 的奇妙世界,亦或是读研论文的撰写攻略有所探寻🧐,那不妨给我一个小小的关注吧🥰。我会精心筹备,在未来…...

C/C++ 数据结构与算法【哈夫曼树】 哈夫曼树详细解析【日常学习,考研必备】带图+详细代码
哈夫曼树(最优二叉树) 1)基础概念 **路径:**从树中一个结点到另一个结点之间的分支构成这两个结点间的路径。 **结点的路径长度:**两结点间路径上的分支数。 **树的路径长度:**从树根到每一个结点的路径…...

基于NodeMCU的物联网窗帘控制系统设计
最终效果 基于NodeMCU的物联网窗帘控制系统设计 项目介绍 该项目是“物联网实验室监测控制系统设计(仿智能家居)”项目中的“家电控制设计”中的“窗帘控制”子项目,最前者还包括“物联网设计”、“环境监测设计”、“门禁系统设计计”和“小…...

喜报 | 擎创科技入围上海市优秀信创解决方案
近日,由上海市经信委组织的“2024年上海市优秀信创解决方案”征集遴选活动圆满落幕,擎创科技凭借实践经验优秀的《擎创夏洛克智能预警与应急处置解决方案》成功入选“2024年上海市优秀信创解决方案”名单。 为激发创新活力,发挥标杆作用&…...

windows10下使用沙盒多开uiautoanimation可行性验证
文章目录 ⭐前言⭐sandboxie下载使用⭐pyinstaller打包python的uiautoanimation成exe⭐结论⭐结束 ⭐前言 大家好,我是yma16,本文分享windows下使用沙盒多开uiautoanimation可行性验证。 背景 实现多开应用程序从而进行自动化控制,批量处理大…...

Godot PCK文件高效解包全攻略:从资源提取到实战应用
Godot PCK文件高效解包全攻略:从资源提取到实战应用 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 作为游戏开发者或爱好者,你是否曾遇到过想要分析或复用Godot引擎打包的游…...

不只是CTF:用Kali+Pwntools+GDB-Peda搭建你的第一个漏洞分析实验台
从CTF到实战:构建专业级二进制漏洞分析实验环境 在安全研究领域,CTF比赛中的Pwn挑战只是冰山一角。真正的价值在于将这些技能应用于现实世界的漏洞分析和利用。本文将带你搭建一个专业级的本地漏洞分析实验环境,这个环境不仅能应对CTF题目&a…...

GB28181国标协议实战:用WVP+ZLMediaKit搭建一个支持级联的轻量级视频中台
GB28181国标协议实战:构建轻量级视频中台的架构设计与实现 在安防监控与视频管理领域,GB28181协议已经成为设备互联互通的事实标准。对于需要整合多品牌设备、实现统一管理的技术团队而言,如何快速搭建一个稳定可靠的视频中台是项目落地的关键…...

GD32外部晶振配置不当引发串口乱码的时钟树深度解析与修复
1. 时钟树:微控制器的心跳发生器 第一次用GD32调串口的朋友,八成遇到过这样的场景:代码明明和官方例程一模一样,烧录后串口助手却疯狂输出乱码。这种时候千万别急着怀疑人生,问题的根源往往藏在那个不起眼的外部晶振配…...

FFTW3内存管理最佳实践:fftw_malloc与数据对齐技巧
FFTW3内存管理最佳实践:fftw_malloc与数据对齐技巧 【免费下载链接】fftw3 DO NOT CHECK OUT THESE FILES FROM GITHUB UNLESS YOU KNOW WHAT YOU ARE DOING. (See below.) 项目地址: https://gitcode.com/gh_mirrors/ff/fftw3 FFTW3(Fastest Fou…...

Agent--多轮对话系统设计6道高频考题解析
去年面试某大厂AI岗位,多轮对话这块被追问了好几道题,有些问题当时答得磕磕绊绊,回来后我把相关知识点重新梳理了一遍。这次复盘把面试中遇到的核心问题分享出来,希望对准备面试的同学有点帮助。真题现场: 面试刚开始&…...

烽火HG680-MC全分区TTL救砖指南:从黑屏到流畅运行的完整解决方案
1. 烽火HG680-MC救砖前的准备工作 遇到黑屏、卡LOGO的烽火HG680-MC盒子别急着扔,TTL线刷能救回90%的"砖机"。我经手过上百台同型号设备,先说说你手头要准备的"救命工具包": 硬件三件套:CH340G芯片的TTL转USB模…...

Alberta Wells数据集:从213,000个井位到全球环境监测,计算机视觉如何重塑油气设施追踪
1. 油气井监测的全球挑战与环境意义 想象一下,你正站在加拿大阿尔伯塔省广袤的草原上,脚下可能就隐藏着数十个被遗忘的油气井。这些钢铁结构的"时间胶囊"有的已经沉寂数十年,却仍在持续释放比二氧化碳强效84倍的甲烷气体。这就是全…...

Figma全中文界面解决方案:从安装到精通的实战指南
Figma全中文界面解决方案:从安装到精通的实战指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 作为一名中文设计师,你是否曾因Figma全英文界面而在操作时频繁…...

Java微服务Istio配置必须立即更新的4个安全补丁:CVE-2024-23652等高危漏洞绕过配置详解
第一章:Java微服务Istio配置安全补丁的紧急性与背景近年来,Java微服务架构在云原生环境中广泛应用,而Istio作为主流服务网格控制平面,承担着流量管理、可观测性与零信任安全策略实施的关键角色。然而,2024年披露的CVE-…...