基于pytorch的深度学习基础3——模型创建与nn.Module
三 模型创建与nn.Module
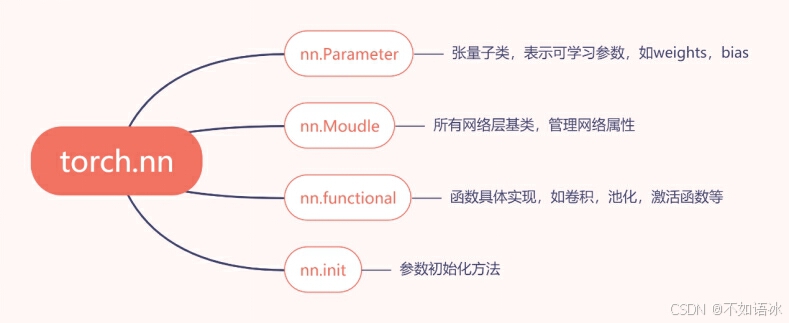
3.1 nn.Module
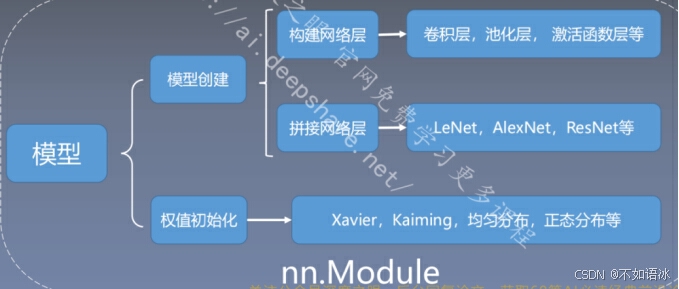
模型构建两要素:
- 构建子模块——__init()__
- 拼接子模块——forward()
一个module可以有多个module;
一个module相当于一个运算,都必须实现forward函数;
每一个module有8个字典管理属性。
self._parameters = OrderedDict()
self._buffers = OrderedDict()
self._backward_hooks = OrderedDict()
self._forward_hooks = OrderedDict()
self._forward_pre_hooks = OrderedDict()
self._state_dict_hooks = OrderedDict()
self._load_state_dict_pre_hooks = OrderedDict()
self._modules = OrderedDict()
3.2 网络容器
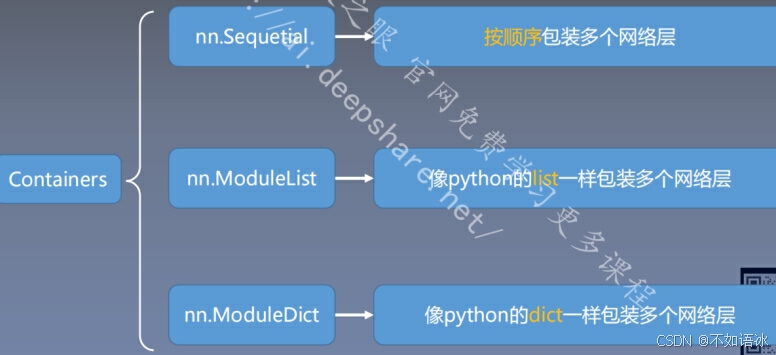
nn.Sequential()
是nn.Module()的一个容器,用于按照顺序包装一组网络层;
顺序性:网络层之间严格按照顺序构建;
自带forward():
各网络层之间严格按顺序执行,常用于block构建
class LeNetSequential(nn.Module):
def __init__(self, classes):
super(LeNetSequential, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes),)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
nn.ModuleList()
是nn.Module的容器,用于包装网络层,以迭代方式调用网络层。
主要方法:
append():在ModuleList后面添加网络层;
extend():拼接两个ModuleList.
Insert():指定在ModuleList中插入网络层。
nn.ModuleList:迭代性,常用于大量重复网构建,通过for循环实现重复构建
class ModuleList(nn.Module):
def __init__(self):
super(ModuleList, self).__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)])
def forward(self, x):
for i, linear in enumerate(self.linears):
x = linear(x)
return x
nn.ModuleDict()
以索引方式调用网络层
主要方法:
• clear():清空ModuleDict
• items():返回可迭代的键值对(key-value pairs)
• keys():返回字典的键(key)
• values():返回字典的值(value)
• pop():返回一对键值,并从字典中删除
n.ModuleDict:索引性,常用于可选择的网络层
class ModuleDict(nn.Module):
def __init__(self):
super(ModuleDict, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict({
'relu': nn.ReLU(),
'prelu': nn.PReLU()
})
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return x
3.3卷积层
nn.ConV2d()
nn.Conv2d(in_channels, out_channels,kernel_size, stride=1,padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
in_channels:输入通道数,比如RGB图像是3,而后续的网络层的输入通道数为前一卷积层的输出通道数;
out_channels:输出通道数,等价于卷积核个数
kernel_size:卷积核尺寸
stride:步
padding:填充个数
dilation:空洞卷积大小
groups:分组卷积设置
bias:偏置
conv_layer = nn.Conv2d(3, 1, 3) # input:(i, o, size) weights:(o, i , h, w)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
这里使用 input*channel 为 3,output_channel 为 1 ,卷积核大小为 3×3 的卷积核nn.Conv2d(3, 1, 3),使用nn.init.xavier_normal*()方法初始化网络的权值。
我们通过`conv_layer.weight.shape`查看卷积核的 shape 是`(1, 3, 3, 3)`,对应是`(output_channel, input_channel, kernel_size, kernel_size)`。所以第一个维度对应的是卷积核的个数,每个卷积核都是`(3,3,3)`。虽然每个卷积核都是 3 维的,执行的却是 2 维卷积。
转置卷积nn.ConvTranspose2d
转置卷积又称为反卷积(Deconvolution)和部分跨越卷积(Fractionally-stridedConvolution) ,用于对图像进行上采样(UpSample)
为什么称为转置卷积?
假设图像尺寸为4*4,卷积核为3*3,padding=0,stride=1
正常卷积:
![]()
转置卷积:
假设图像尺寸为2*2,卷积核为3*3,padding=0,stride=1

nn.ConvTranspose2d(in_channels, out_channels,
kernel_size,
stride=1,
padding=0,
output_padding=0,
groups=1,
bias=True,
dilation=1, padding_mode='zeros')
输出尺寸计算:
![]()
![]()
# flag = 1
flag = 0
if flag:
conv_layer = nn.ConvTranspose2d(3, 1, 3, stride=2) # input:(i, o, size)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
print("卷积前尺寸:{}\n卷积后尺寸:{}".format(img_tensor.shape, img_conv.shape))
img_conv = transform_invert(img_conv[0, 0:1, ...], img_transform)
img_raw = transform_invert(img_tensor.squeeze(), img_transform)
plt.subplot(122).imshow(img_conv, cmap='gray')
plt.subplot(121).imshow(img_raw)
plt.show()
3.4池化层nn.MaxPool2d && nn.AvgPool2d
池化运算:对信号进行 “收集”并 “总结”,类似水池收集水资源,因而
得名池化层
“收集”:多变少
“总结”:最大值/平均值
nn.MaxPool2d
nn.MaxPool2d(kernel_size, stride=None,
padding=0, dilation=1,
return_indices=False,
ceil_mode=False)
主要参数:
• kernel_size:池化核尺寸
• stride:步长
• padding :填充个数
• dilation:池化核间隔大小
• ceil_mode:尺寸向上取整
• return_indices:记录池化像素索引
# flag = 1
flag = 0
if flag:
maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2)) # input:(i, o, size) weights:(o, i , h, w)
img_pool = maxpool_layer(img_tensor)
nn.AvgPool2d
nn.AvgPool2d(kernel_size,
stride=None,
padding=0,
ceil_mode=False,
count_include_pad=True,
divisor_override=None)
主要参数:
• kernel_size:池化核尺寸
• stride:步长
• padding :填充个数
• ceil_mode:尺寸向上取整
• count_include_pad:填充值用于计算
• divisor_override :除法因子
avgpoollayer = nn.AvgPool2d((2, 2), stride=(2, 2)) # input:(i, o, size) weights:(o, i , h, w)
img_pool = avgpoollayer(img_tensor)
img_tensor = torch.ones((1, 1, 4, 4))
avgpool_layer = nn.AvgPool2d((2, 2), stride=(2, 2), divisor_override=3)
img_pool = avgpool_layer(img_tensor)
print("raw_img:\n{}\npooling_img:\n{}".format(img_tensor, img_pool))
nn.MaxUnpool2d
功能:对二维信号(图像)进行最大值池化
上采样
主要参数:
• kernel_size:池化核尺寸
• stride:步长
• padding :填充个数
# pooling
img_tensor = torch.randint(high=5, size=(1, 1, 4, 4), dtype=torch.float)
maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2), return_indices=True)
img_pool, indices = maxpool_layer(img_tensor)
# unpooling
img_reconstruct = torch.randn_like(img_pool, dtype=torch.float)
maxunpool_layer = nn.MaxUnpool2d((2, 2), stride=(2, 2))
img_unpool = maxunpool_layer(img_reconstruct, indices)
print("raw_img:\n{}\nimg_pool:\n{}".format(img_tensor, img_pool))
print("img_reconstruct:\n{}\nimg_unpool:\n{}".format(img_reconstruct, img_unpool))
3.5线性层
nn.Linear(in_features, out_features, bias=True)
功能:对一维信号(向量)进行线性组合
主要参数:
• in_features:输入结点数
• out_features:输出结点数
• bias :是否需要偏置
计算公式:y = 𝒙𝑾𝑻 + 𝒃𝒊𝒂s
inputs = torch.tensor([[1., 2, 3]])
linear_layer = nn.Linear(3, 4)
linear_layer.weight.data = torch.tensor([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.],
[4., 4., 4.]])
linear_layer.bias.data.fill_(0.5)
output = linear_layer(inputs)
print(inputs, inputs.shape)
print(linear_layer.weight.data, linear_layer.weight.data.shape)
print(output, output.shape)
3.6 激活函数层
nn.Sigmoid
nn.tanh:
nn.ReLU
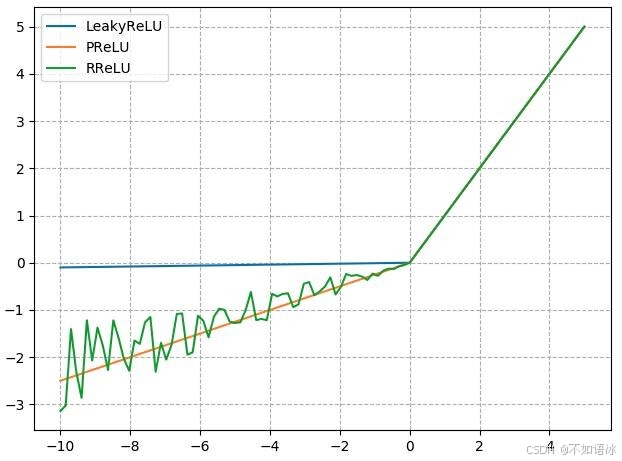
nn.LeakyReLU
negative_slope: 负半轴斜率
nn.PReLU
init: 可学习斜率
nn.RReLU
lower: 均匀分布下限
upper:均匀分布上限
参考资料
深度之眼课程
相关文章:
基于pytorch的深度学习基础3——模型创建与nn.Module
三 模型创建与nn.Module 3.1 nn.Module 模型构建两要素: 构建子模块——__init()__拼接子模块——forward() 一个module可以有多个module; 一个module相当于一个运算,都必须实现forward函数; 每一个mod…...

Debian-linux运维-docker安装和配置
腾讯云搭建docker官方文档:https://cloud.tencent.com/document/product/213/46000 阿里云安装Docker官方文档:https://help.aliyun.com/zh/ecs/use-cases/install-and-use-docker-on-a-linux-ecs-instance 天翼云常见docker源配置指导:htt…...

Docker完整技术汇总
Docker 背景引入 在实际开发过程中有三个环境,分别是:开发环境、测试环境以及生产环境,假设开发环境中开发人员用的是jdk8,而在测试环境中测试人员用的时jdk7,这就导致程序员开发完系统后将其打成jar包发给测试人员后…...
在JavaScript文件中定义方法和数据(不是在对象里定以数据和方法,不要搞错了)
在对象里定以数据和方法看这一篇 对象字面量内定义属性和方法(什么使用const等关键字,什么时候用键值对)-CSDN博客https://blog.csdn.net/m0_62961212/article/details/144788665 下是在JavaScript文件中定义方法和数据的基本方式ÿ…...

python爬虫爬抖音小店商品数据+数据可视化
爬虫代码 爬虫代码是我调用的数据接口,可能会过一段时间用不了,欢迎大家留言评论,我会不定时更新 import requests import time cookies {token: 5549EB98B15E411DA0BD05935C0F225F,tfstk: g1vopsc0sQ5SwD8TyEWSTmONZ3cA2u6CReedJ9QEgZ7byz…...

关于 覆铜与导线之间间距较小需要增加间距 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/144776995 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

uniapp中Nvue白屏问题 ReferenceError: require is not defined
uniapp控制台输出如下 exception function:createInstanceContext, exception:white screen cause create instanceContext failed,check js stack ->Uncaught ReferenceError: require is not defined 或者 exception function:createInstanceContext, exception:white s…...

在 Windows 上,如果忘记了 MySQL 密码 重置密码
在 Windows 上,如果忘记了 MySQL 密码,可以通过以下方法重置密码: 方法 1:以跳过权限验证模式启动 MySQL 并重置密码 停止 MySQL 服务: 打开 命令提示符 或 PowerShell,输入以下命令停止 MySQL 服务&#…...

《PyTorch:从基础概念到实战应用》
《PyTorch:从基础概念到实战应用》 一、PyTorch 初印象二、PyTorch 之历史溯源三、PyTorch 核心优势尽显(一)简洁高效,契合思维(二)易于上手,调试便捷(三)社区繁荣&#…...

前端:改变鼠标点击物体的颜色
需求: 需要改变图片中某一物体的颜色,该物体是纯色; 鼠标点击哪个物体,哪个物体的颜色变为指定的颜色,利用canvas实现。 演示案例 代码Demo <!DOCTYPE html> <html lang"en"><head>&l…...

Java-33 深入浅出 Spring - FactoryBean 和 BeanFactory BeanPostProcessor
点一下关注吧!!!非常感谢!!持续更新!!! 大数据篇正在更新!https://blog.csdn.net/w776341482/category_12713819.html 目前已经更新到了: MyBatisÿ…...

HTML4笔记
尚硅谷 一、前序知识 1.认识两位先驱 2.计算机基础知识 3.C/S架构与B/S架构 4.浏览器相关知识 5.网页相关概念 二、HTML简介 1.什么是HTML? 2.相关国际组织(了解) 3.HTML发展历史(了解)** 三、准备工作 1.常用电脑设置 2.安装Chrome浏览器 四、HTML入门 1.HTML初体验 2.H…...

python报错ModuleNotFoundError: No module named ‘visdom‘
在用虚拟环境跑深度学习代码时,新建的环境一般会缺少一些库,而一般解决的方法就是直接conda install,但是我在conda install visdom之后,安装是没有任何报错的,conda list里面也有visdom的信息,但是再运行代…...

linux-21 目录管理(一)mkdir命令,创建空目录
对linux而言,对一个系统管理来讲,最关键的还是文件管理。那所以我们接下来就来看看如何实现文件管理。当然,在文件管理之前,我们说过,文件通常都放在目录下,对吧?所以先了解目录,可能…...

总结-常见缓存替换算法
缓存替换算法 1. 总结 1. 总结 常见的缓存替换算法除了FIFO、LRU和LFU还有下面几种: 算法优点缺点适用场景FIFO简单实现可能移除重要数据嵌入式系统,简单场景LRU局部性原理良好维护成本高,占用更多存储空间内存管理,浏览器缓存L…...

【Vue】如何在 Vue 3 中使用组合式 API 与 Vuex 进行状态管理的详细教程
如何在 Vue 3 中使用组合式 API 与 Vuex 进行状态管理的详细教程。 安装 Vuex 首先,在你的 Vue 3 项目中安装 Vuex。可以使用 npm 或 yarn: npm install vuexnext --save # or yarn add vuexnext创建 Store 在 Vue 3 中,你可以使用 creat…...
:如何支持多语言)
VSCode 插件开发实战(十五):如何支持多语言
前言 在软件开发中,多语言支持(i18n)是一个非常重要的功能。无论是桌面应用、移动应用,还是浏览器插件,都需要考虑如何支持不同国家和地区的用户,软件应用的多语言支持(i18n)已经成…...

面试241228
面试可参考 1、cas的概念 2、AQS的概念 3、redis的数据结构 使用场景 不熟 4、redis list 扩容流程 5、dubbo 怎么进行服务注册和调用,6、dubbo 预热 7如何解决cos上传的安全问题kafka的高并发高吞吐的原因ES倒排索引的原理 spring的 bean的 二级缓存和三级缓存 spr…...

Python数据序列化模块pickle使用
pickle 是 Python 的一个标准库模块,它实现了基本的对象序列化和反序列化。序列化是指将对象转换为字节流的过程,这样对象就可以被保存到文件中或通过网络传输。反序列化是指从字节流中恢复对象的过程。 以下是 pickle 模块的基本使用方法: …...

Spring Boot对访问密钥加解密——HMAC-SHA256
HMAC-SHA256 简介 HMAC-SHA256 是一种基于 哈希函数 的消息认证码(Message Authentication Code, MAC),它结合了哈希算法(如 SHA-256)和一个密钥,用于验证消息的完整性和真实性。 HMAC 是 “Hash-based M…...

智能材料科技:COMSOL金属的SPP技术及其降维降损解决方案的研究与实践
comsol金属spp降维降损。金属表面等离子体激元(SPP)的模拟总让人又爱又恨——高局域场增强的特性是真香,但三维全波仿真动不动就内存爆炸也是真头疼。最近在COMSOL里折腾SPP降维模型时发现,只要玩点几何骚操作,计算量能…...
)
WinForm实战:OxyPlot图表控件鼠标悬停显示坐标值(附完整代码)
WinForm实战:OxyPlot图表控件鼠标悬停显示坐标值(附完整代码) 在数据可视化应用中,实时交互功能往往能显著提升用户体验。当开发者需要在WinForm平台快速实现专业级图表时,OxyPlot.WindowsForms.Plot控件凭借其轻量级和…...

单片机电子产品开发全流程指南
基于单片机的电子产品开发全流程解析1. 项目概述现代电子产品设计中,单片机已成为实现复杂功能的核心器件。从智能家居设备到健康监测仪器,各类产品都依赖单片机实现可编程控制功能。本文将系统介绍基于单片机的电子产品开发全流程,涵盖从需求…...

网盘直链下载助手:告别限速困扰,八大平台一键高速下载终极指南
网盘直链下载助手:告别限速困扰,八大平台一键高速下载终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用&…...

视频转PPT智能提取工具:自动化幻灯片提取效率提升10倍的完整方案
视频转PPT智能提取工具:自动化幻灯片提取效率提升10倍的完整方案 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 在数字化学习和远程办公的时代,视频内容已成…...
和描述文件生成避坑指南:从App ID创建到真机测试UDID添加)
iOS证书(.p12)和描述文件生成避坑指南:从App ID创建到真机测试UDID添加
iOS证书与描述文件生成全流程解析:从核心概念到实战避坑 第一次接触iOS应用打包的开发者,往往会在证书和描述文件这一关卡住。明明按照教程一步步操作,却总是遇到各种报错——"证书无效"、"描述文件不匹配"、"设备未…...

DanKoe 视频笔记:写作技能:掌握写作,驾驭未来十年
概述 在本节课中,我们将要学习为什么写作是未来十年最重要的元技能,以及如何通过一个清晰的六步框架和一套实用的写作方法,开启你的个人写作事业。我们将探讨写作如何放大你的其他技能,并为你提供一套从零开始构建影响力的具体行…...
)
告别回调地狱:用Qt信号与槽重构你的第一个GUI应用(Qt6/C++实战)
重构GUI应用:Qt信号与槽的工程化实践 在传统C GUI开发中,我们常常陷入回调函数嵌套的泥潭——按钮点击触发事件处理函数,函数内部又调用其他模块,最终形成难以维护的"面条式代码"。Qt的信号与槽机制为这一困境提供了优雅…...

UniApp二维码生成避坑指南:解决常见Canvas渲染问题
UniApp二维码生成避坑指南:解决常见Canvas渲染问题 在移动应用开发中,二维码功能已成为用户交互的标配。UniApp作为跨平台开发框架,其Canvas组件在实现二维码生成时却存在诸多"暗礁"。本文将深入剖析五个典型场景下的Canvas渲染陷阱…...
)
150元搞定无人机自主避障?上交大开源方案实测(附部署教程)
150元打造无人机自主避障系统:开源方案实战指南 当大多数人还在为动辄上万元的无人机避障系统望而却步时,一个仅需150元计算硬件的开源方案正在创客圈掀起风暴。这不是实验室里的概念验证,而是经过真实环境测试、能部署在你家后院的技术方案。…...