如何通过 Kafka 将数据导入 Elasticsearch
作者:来自 Elastic Andre Luiz

将 Apache Kafka 与 Elasticsearch 集成的分步指南,以便使用 Python、Docker Compose 和 Kafka Connect 实现高效的数据提取、索引和可视化。
在本文中,我们将展示如何将 Apache Kafka 与 Elasticsearch 集成以进行数据提取和索引。我们将概述 Kafka、其生产者(producers)和消费者(consumers)的概念,并创建一个日志索引,其中将通过 Apache Kafka 接收和索引消息。该项目以 Python 实现,代码可在 GitHub 上找到。
先决条件
- Docker 和 Docker Compose:确保你的机器上安装了 Docker 和 Docker Compose。
- Python 3.x:运行生产者和消费者脚本。
Apache Kafka 简介
Apache Kafka 是一个分布式流媒体平台,具有高可扩展性和可用性以及容错能力。在 Kafka 中,数据管理通过主要组件进行:
- Broker/代理:负责在生产者和消费者之间存储和分发消息。
- Zookeeper:管理和协调 Kafka 代理,控制集群的状态、分区领导者和消费者信息。
- Topics/主题:发布和存储数据以供使用的渠道。
- Consumers 及 Producers/消费者和生产者:生产者向主题发送数据,而消费者则检索该数据。

这些组件共同构成了 Kafka 生态系统,为数据流提供了强大的框架。
项目结构
为了理解数据提取过程,我们将其分为几个阶段:
- 基础设施配置/Infrastructure Provisioning:设置 Docker 环境以支持 Kafka、Elasticsearch 和 Kibana。
- 创建生产者/Producer Creation:实现 Kafka 生产者,将数据发送到日志主题。
- 创建消费者/Consumer Creation:开发 Kafka 消费者以读取和索引 Elasticsearch 中的消息。
- 提取验证/Ingestion Validation:验证和确认已发送和已使用的数据。
使用 Docker Compose 进行基础设施配置
我们利用 Docker Compose 来配置和管理必要的服务。下面,你将找到 Docker Compose 代码,它设置了 Apache Kafka、Elasticsearch 和 Kibana 集成所需的每项服务,确保数据提取过程。
docker-compose.yml
version: "3"services:zookeeper:image: confluentinc/cp-zookeeper:latestcontainer_name: zookeeperenvironment:ZOOKEEPER_CLIENT_PORT: 2181kafka:image: confluentinc/cp-kafka:latestcontainer_name: kafkadepends_on:- zookeeperports:- "9092:9092"- "9094:9094"environment:KAFKA_BROKER_ID: 1KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST:${HOST_IP}:9092KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXTKAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXTKAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1elasticsearch:image: docker.elastic.co/elasticsearch/elasticsearch:8.15.1container_name: elasticsearch-8.15.1environment:- node.name=elasticsearch- xpack.security.enabled=false- discovery.type=single-node- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- ./elasticsearch:/usr/share/elasticsearch/dataports:- 9200:9200kibana:image: docker.elastic.co/kibana/kibana:8.15.1container_name: kibana-8.15.1ports:- 5601:5601environment:ELASTICSEARCH_URL: http://elasticsearch:9200ELASTICSEARCH_HOSTS: '["http://elasticsearch:9200"]'你可以直接从 Elasticsearch Labs GitHub repo 访问该文件。
使用 Kafka 生产器发送数据
生产器负责将消息发送到日志主题。通过批量发送消息,可以提高网络使用效率,允许使用 batch_size 和 linger_ms 设置进行优化,这两个设置分别控制批次的数量和延迟。配置 acks='all' 可确保消息持久存储,这对于重要的日志数据至关重要。
producer = KafkaProducer(bootstrap_servers=['localhost:9092'], # Specifies the Kafka server to connectvalue_serializer=lambda x: json.dumps(x).encode('utf-8'), # Serializes data as JSON and encodes it to UTF-8 before sendingbatch_size=16384, # Sets the maximum batch size in bytes (here, 16 KB) for buffered messages before sendinglinger_ms=10, # Sets the maximum delay (in milliseconds) before sending the batchacks='all' # Specifies acknowledgment level; 'all' ensures message durability by waiting for all replicas to acknowledge
)def generate_log_message():levels = ["INFO", "WARNING", "ERROR", "DEBUG"]messages = ["User login successful","User login failed","Database connection established","Database connection failed","Service started","Service stopped","Payment processed","Payment failed"]log_entry = {"level": random.choice(levels),"message": random.choice(messages),"timestamp": time.time()}return log_entrydef send_log_batches(topic, num_batches=5, batch_size=10):for i in range(num_batches):logger.info(f"Sending batch {i + 1}/{num_batches}")for _ in range(batch_size):log_message = generate_log_message()producer.send(topic, value=log_message)producer.flush()if __name__ == "__main__":topic = "logs"send_log_batches(topic)producer.close()当启动 producer 的时候,会批量的向 topic 发送消息,如下图:
INFO:kafka.conn:Set configuration …
INFO:log_producer:Sending batch 1/5
INFO:log_producer:Sending batch 2/5
INFO:log_producer:Sending batch 3/5
INFO:log_producer:Sending batch 4/5使用 Kafka Consumer 消费和索引数据
Consumer 旨在高效处理消息,消费来自日志主题的批次并将其索引到 Elasticsearch 中。使用 auto_offset_reset='latest',可确保 Consumer 开始处理最新消息,忽略较旧的消息,max_poll_records=10 将批次限制为 10 条消息。使用 fetch_max_wait_ms=2000,Consumer 最多等待 2 秒以积累足够的消息,然后再处理批次。
在其主循环中,Consumer 消费日志消息、处理并将每个批次索引到 Elasticsearch 中,确保持续的数据摄取。
consumer = KafkaConsumer('logs', bootstrap_servers=['localhost:9092'],auto_offset_reset='latest', # Ensures reading from the latest offset if the group has no offset storedenable_auto_commit=True, # Automatically commits the offset after processinggroup_id='log_consumer_group', # Specifies the consumer group to manage offset trackingmax_poll_records=10, # Maximum number of messages per batchfetch_max_wait_ms=2000 # Maximum wait time to form a batch (in ms)
)def create_bulk_actions(logs):for log in logs:yield {"_index": "logs","_source": {'level': log['level'],'message': log['message'],'timestamp': log['timestamp']}}if __name__ == "__main__":try:print("Starting message processing…")while True:messages = consumer.poll(timeout_ms=1000) # Poll receive messages# process each batch messagesfor _, records in messages.items():logs = [json.loads(record.value) for record in records]bulk_actions = create_bulk_actions(logs)response = helpers.bulk(es, bulk_actions)print(f"Indexed {response[0]} logs.")except Exception as e:print(f"Erro: {e}")finally:consumer.close()print(f"Finish")在 Kibana 中可视化数据
借助 Kibana,我们可以探索和验证从 Kafka 提取并在 Elasticsearch 中编入索引的数据。通过访问 Kibana 中的开发工具,你可以查看已编入索引的消息并确认数据符合预期。例如,如果我们的 Kafka 生产者发送了 5 个批次,每个批次 10 条消息,我们应该在索引中看到总共 50 条记录。
要验证数据,你可以在 Dev Tools 部分使用以下查询:
GET /logs/_search
{"query": {"match_all": {}}
}相应:

此外,Kibana 还提供了创建可视化和仪表板的功能,可帮助使分析更加直观和具有交互性。下面,你可以看到我们创建的一些仪表板和可视化示例,它们以各种格式展示了数据,增强了我们对所处理信息的理解。

使用 Kafka Connect 进行数据提取
Kafka Connect 是一种旨在促进数据源和目标(接收器)之间的集成的服务,例如数据库或文件系统。它使用预定义的连接器来自动处理数据移动。在我们的例子中,Elasticsearch 充当数据接收器。

使用 Kafka Connect,我们可以简化数据提取过程,无需手动将数据提取工作流实施到 Elasticsearch 中。借助适当的连接器,Kafka Connect 允许将发送到 Kafka 主题的数据直接在 Elasticsearch 中编入索引,只需进行最少的设置,无需额外编码。
使用 Kafka Connect
要实现 Kafka Connect,我们将 kafka-connect 服务添加到我们的 Docker Compose 设置中。此配置的一个关键部分是安装 Elasticsearch 连接器,它将处理数据索引。
配置服务并创建 Kafka Connect 容器后,将需要一个 Elasticsearch 连接器的配置文件。此文件定义基本参数,例如:
- connection.url:Elasticsearch 的连接 URL。
- topics:连接器将监视的 Kafka 主题(在本例中为 “logs”)。
- type.name:Elasticsearch 中的文档类型(通常为 _doc)。
- value.converter:将 Kafka 消息转换为 JSON 格式。
- value.converter.schemas.enable:指定是否应包含架构。
- schema.ignore 和 key.ignore:在索引期间忽略 Kafka 架构和键的设置。
以下是在 Kafka Connect 中创建 Elasticsearch 连接器的 curl 命令:
curl --location '{{url}}/connectors' \
--header 'Content-Type: application/json' \
--data '{"name": "elasticsearch-sink-connector","config": {"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector","topics": "logs","connection.url": "http://elasticsearch:9200","type.name": "_doc","value.converter": "org.apache.kafka.connect.json.JsonConverter","value.converter.schemas.enable": "false","schema.ignore": "true","key.ignore": "true"}
}'通过此配置,Kafka Connect 将自动开始提取发送到 “logs” 主题的数据并在 Elasticsearch 中对其进行索引。这种方法允许完全自动化的数据提取和索引,而无需额外的编码,从而简化整个集成过程。
结论
集成 Kafka 和 Elasticsearch 为实时数据提取和分析创建了一个强大的管道。本指南提供了一种构建强大数据提取架构的基础方法,并在 Kibana 中实现无缝可视化和分析,以适应未来更复杂的要求。
此外,使用 Kafka Connect 使 Kafka 和 Elasticsearch 之间的集成更加简化,无需额外的代码来处理和索引数据。Kafka Connect 使发送到特定主题的数据能够以最少的配置自动在 Elasticsearch 中编入索引。
想要获得 Elastic 认证?了解下一次 Elasticsearch 工程师培训的时间!
Elasticsearch 包含许多新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在本地机器上试用 Elastic。
原文:How to ingest data to Elasticsearch through Kafka - Elasticsearch Labs
相关文章:
如何通过 Kafka 将数据导入 Elasticsearch
作者:来自 Elastic Andre Luiz 将 Apache Kafka 与 Elasticsearch 集成的分步指南,以便使用 Python、Docker Compose 和 Kafka Connect 实现高效的数据提取、索引和可视化。 在本文中,我们将展示如何将 Apache Kafka 与 Elasticsearch 集成以…...

嵌入式系统 第十二讲 块设备和驱动程序设计
• 块设备是Linux三大设备之一(另外两种是字符设备,网络设备),块 设备也是通过/dev下的文件系统节点访问。 • 块设备的数据存储单位是块,块的大小通常为512B至32KB不等。 • 块设备每次能传输一个或多个块,…...

攻防世界web第六题upload
这是题目,可以看出是个上传文件的题目,考虑文件上传漏洞,先随便上传一个文件试试,要求上传的是图片。 可以看到上传成功。 考虑用一句话木马解决,构造文件并修改后缀为jpg,然后上传。 <?php eval($_POST[attack])…...

人工智能-Python网络编程-HTTP
用Python创建自己的HTTP服务器 方案一 HTTP-Python官方 python -m http.server 80 方案二 HTTP-概念版 import socketIPV4_ADDR 192.168.124.7 IPV4_PORT 8888# TCP 服务端程序必须绑定端口号,否则客户端找不到这个 TCP 服务端程序 class ServerSocket(obje…...

探索仓颉编程语言:功能、实战与展望
目录 引言 一.使用体验 二.功能剖析 1.丰富的数据类型与控制结构 2.强大的编程范式支持 3.标准库与模块系统 4.并发编程能力 三.实战案例 1.项目背景与目标 2.具体实现步骤 (1).导入必要的模块 (2).发送 HTTP 请求获取网页内容 (3).解析 HTML 页面提取文章信息 (…...

Unity-Editor扩展显示文件夹大小修复版 FileCapacity.cs
实战中是这样的,大项目, 容易定位美术大资产 (原版的代码有问题,每次点运行都会卡顿,大项目20S) //但其实获整个项目内容,1G都没有,有够省的(10年前的中型项目,一直有出DLC) using System; using System.Collections; using System.Collections.Generic; using Sy…...

BLE core 内容整理解释
本文内容比较杂散,只是做记录使用,后续会整理的有条理些 link layer 基本介绍 **Link Layer Control(链路层控制)**是蓝牙低功耗(BLE)协议栈的核心部分,负责实现设备间可靠、安全、低功耗的数…...

Linux CPU调度算法
简述 ● CPU数量 < 进程数 ● 每次CPU都要决定下一个运行的进程,这个选择叫做CPU调度;这个选择工作就叫做CPU调度程序 ● 如果一个进程中有多个线程的话,内核管理的线程就以线程为基本单位 ● 进程通常分为两种,一种长时间占…...

Linux套接字通信学习
Linux套接字通信 在网络通信的时候, 程序猿需要负责的应用层数据的处理(最上层),而底层的数据封装与解封装(如TCP/IP协议栈的功能)通常由操作系统、网络协议栈或相关网络库(如Socket库)实现。(程序员只需要…...

mybatis-plus 用法总结
MyBatis-Plus(简称 MP)是 MyBatis 的增强工具,旨在简化开发者的 CRUD 操作。它在 MyBatis 的基础上提供了更多的功能和便利性,如代码生成器、分页插件、性能分析插件等,使开发者能够更高效地进行数据库操作。MyBatis-P…...

小程序配置文件 —— 14 全局配置 - tabbar配置
全局配置 - tabBar配置 tabBar 字段:定义小程序顶部、底部 tab 栏,用以实现页面之间的快速切换;可以通过 tabBar 配置项指定 tab 栏的表现,以及 tab 切换时显示的对应页面; 在上面图中,标注了一些 tabBar …...

Redis-十大数据类型
Reids数据类型指的是value的类型,key都是字符串 redis-server:启动redis服务 redis-cli:进入redis交互式终端 常用的key的操作 redis的命令和参数不区分大小写 ,key和value区分 1、查看当前库所有的key keys * 2、判断某个key是否存在 exists key 3、查…...
管道和FIFO)
linux系统编程(七)管道和FIFO
1、管道 使用系统调用pipe可以创建一个新管道: #include <unistd.h> int pipe(int filedes[2]);成功的pipe调用会在数组filedes中返回两个打开的文件描述符,读取端为filedes[0],写入端为filedes[1]。我们可以使用read/write系统调用在…...
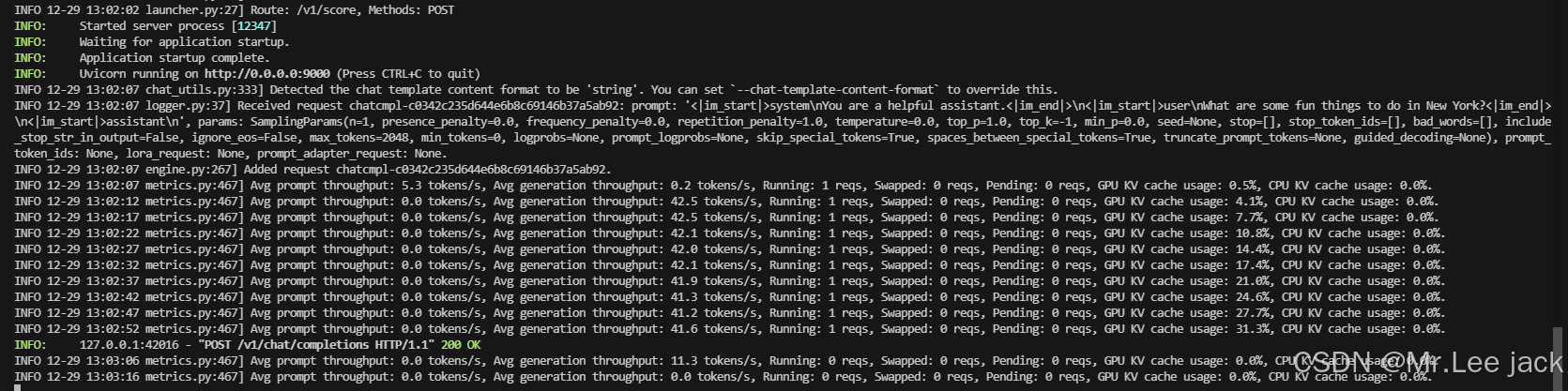
【vLLM大模型TPS测试三部曲】
安装 pip install vllm模型自行下载 例如: https://modelscope.cn/models/jackle/Qwen2.5-Coder-32B-GPTQ-Int4/ 部署测试 export VLLM_MODELQwen2.5-Coder-32B-GPTQ-Int4 # 启动 python3 -m vllm.entrypoints.openai.api_server --model $VLLM_MODEL --deviceauto --enf…...

Elasticsearch:使用 Ollama 和 Go 开发 RAG 应用程序
作者:来自 Elastic Gustavo Llermaly 使用 Ollama 通过 Go 创建 RAG 应用程序来利用本地模型。 关于各种开放模型,有很多话要说。其中一些被称为 Mixtral 系列,各种规模都有,而一种可能不太为人所知的是 openbiollm,这…...

Windows平台ROBOT安装
Windows环境下ROBOT的安装,按照下文进行部署ROBOT的前提是你的python已安装并且环境变量已设置好. 一、安装setuptools 1、下载后安装 https://pypi.python.org/pypi/setuptools/ 下载你需要的包 setuptools-75.6.0.tar.gz 解压下载的包在命令行中进入该包,敲击如下命令后…...

【动态规划篇】穿越算法迷雾:约瑟夫环问题的奇幻密码
欢迎拜访:羑悻的小杀马特.-CSDN博客 本篇主题:带你众人皆知的约瑟夫环问题 制作日期:2024.12.29 隶属专栏:C/C题海汇总 目录 引言: 一约瑟夫环问题介绍: 11问题介绍: 1.2起源与历史背景&…...
代码随想录算法训练营第51期第32天 | 理论基础、509. 斐波那契数、70. 爬楼梯、746. 使用最小花费爬楼梯
理论基础 动态规划:dp,每一个状态都是由上个状态推导出来的,因为我是先写完三道题再看理论的,所以有点感概; 确定dp数组(dp table)以及下标的含义确定递推公式dp数组如何初始化确定遍历顺序举…...

爱思唯尔word模板
爱思唯尔word模板 有时候并不一定非得latex https://download.csdn.net/download/qq_38998213/90199214 参考文献书签链接...

每日一题 354. 俄罗斯套娃信封问题
354. 俄罗斯套娃信封问题 需要对信封排序 ,重点是再宽度相同时,逐步减少其高度 class Solution { public:int maxEnvelopes(vector<vector<int>>& envelopes) {sort(envelopes.begin(),envelopes.end(),[](const vector<int>&a,const v…...

Phi-3-mini-128k-instruct实战案例:中小企业技术文档自动解析与结构化提取
Phi-3-mini-128k-instruct实战案例:中小企业技术文档自动解析与结构化提取 1. 项目背景与价值 对于中小企业而言,技术文档管理一直是个令人头疼的问题。工程师们经常需要从大量PDF、Word文档中提取关键信息,手动整理成结构化数据。这个过程…...

石墨烯这玩意儿在COMSOL里折腾起来挺有意思的,特别是搞太赫兹和近红外的同学估计都遇到过选模型的纠结。今天咱们就聊点实战经验,顺便甩点代码片段
Comsol石墨烯二维材料。 包含太赫兹德鲁得和近红外Kubo两种模型。 共7个案例,包含参考文献。先说说太赫兹波段常用的德鲁得模型,这货相当于把石墨烯当经典等离子体处理。在COMSOL里实现时,关键要设置表面电流密度: sigma_drude (…...

OpenClaw跨平台同步:GLM-4.7-Flash配置在多设备复用
OpenClaw跨平台同步:GLM-4.7-Flash配置在多设备复用 1. 为什么需要跨设备同步OpenClaw配置 去年冬天,我在家里配置好OpenClaw接入GLM-4.7-Flash模型后,第二天到办公室想继续调试时,发现所有配置都要从头再来。这种重复劳动让我意…...

在Windows和RV1126上部署ONNX肺部分割模型:一份OpenCV DNN与RKNN的完整对比实践
跨平台肺部分割模型部署实战:OpenCV DNN与RKNN技术选型指南 当医疗影像分析遇上边缘计算,开发者们常常面临一个关键抉择:如何在保证精度的前提下,将训练好的深度学习模型高效部署到不同计算平台?本文将以肺部分割模型为…...
)
保姆级教程:手把手教你安装并激活DevExpress 20.1.3(附资源与注册机使用避坑指南)
深度指南:DevExpress 20.1.3开发环境高效配置与资源管理 在.NET生态系统中,DevExpress始终以其强大的控件库和高效的开发工具占据重要地位。对于刚接触这个工具集的开发者来说,如何快速搭建一个稳定的开发环境往往成为项目启动的第一道门槛。…...

OpenClaw跨平台部署:nanobot镜像在mac/Windows双系统实测
OpenClaw跨平台部署:nanobot镜像在mac/Windows双系统实测 1. 为什么选择nanobot镜像 第一次听说nanobot这个轻量级OpenClaw镜像时,我正被本地部署大模型的资源消耗问题困扰。作为一个经常在macOS和Windows双系统切换的开发者,我需要一个能在…...

利用快马平台十分钟搭建树莓派环境监测系统原型
今天想和大家分享一个快速搭建树莓派环境监测系统的小实验。作为一个硬件爱好者,我经常用树莓派做各种物联网原型开发,但每次从零开始配置环境、写基础代码都很耗时。最近发现InsCode(快马)平台能帮我省去很多重复工作,特别适合快速验证想法。…...

咱就说中小厂房、仓库的火灾报警系统,用S7-200 PLC加组态王真的是性价比天花板——够稳定、好上手,成本还低,完全满足日常需求
基于S7-200 PLC和组态王火灾报警控制系统 我们主要的后发送的产品有,带解释的梯形图接线图原理图图纸,io分配,组态画面咱先从最基础的IO分配说起,直接给大家上我常用的分配表(都是经过3个项目验证的,靠谱…...

从‘各玩各的’到‘协同作战’:聊聊多传感器SLAM中坐标系对齐的那些‘坑’与最佳实践
从‘各玩各的’到‘协同作战’:多传感器SLAM坐标系对齐的工程实践指南 当激光雷达的轨迹点云与相机的视觉路径在三维空间中"貌合神离",工程师们往往面临一个关键抉择:是强行统一时间基准,还是重新建立空间映射关系&…...

抖音批量下载终极指南:免费无水印视频一键获取
抖音批量下载终极指南:免费无水印视频一键获取 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 你是否曾为保存喜欢的抖音视频而烦恼?面对心仪的内容创作者,想要收藏他们的…...