【LangChain】Chapter4 - Question and Answer Over Documents
说在前面
文档问答,是常见的一类LLM应用,给定一段可能是从 PDF文件、网页或某公司内部文档库中提取的文本,使用LLM回答关于这些文档内容的问题。这样的应用非常的强大,它可以将LLM与完全没被训练的数据相结合,可以灵活的适应你的应用场景。这样的应用需要我们引入更多的 LangChain组件来实现,例如 Embedding model 和 Vector Stores(向量存储)这也是 LangChain中最受欢迎的链之一。(视频时长15:06)
注: 所有的示例代码文件课程网站上都有(完全免费),并且是配置好的 Juptyernotebook 环境和配置好的 OPENAI_API_KEY,不需要自行去花钱租用,建议代码直接上课程网站上运行。 课程网站
另外,LLM 的结果并不总是相同的。在执行代码时,可能会得到与视频中略有不同的答案。
Main Content
本节首先将演示一个简单的文档问答示例。然后详细结合代码介绍其文档问答的原理。在介绍有多个文档的情况下的文档问答方法。其中涉及到 Embedding 和 Vector Datasets 两个重要部分。
基于文档的问答示例
1.导入环境变量。
import osfrom dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
# account for deprecation of LLM model
import datetime
# Get the current date
current_date = datetime.datetime.now().date()# Define the date after which the model should be set to "gpt-3.5-turbo"
target_date = datetime.date(2024, 6, 12)# Set the model variable based on the current date
if current_date > target_date:llm_model = "gpt-3.5-turbo"
else:llm_model = "gpt-3.5-turbo-0301"
2.导入必要的库。其中 RetrievalQA 将帮助检索文档;CSVLoader 用于加载CSV文件;vectorstroes 用于向量存储,有很多不同类型的向量存储,这里我们从使用 DocArrayInMemorySearch 开始,这个向量存储是内存存储,不需要连接任何的外部数据库,容易上手;display 和 markdown 用于在 Jupyter Notebook 中显示信息。
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.vectorstores import DocArrayInMemorySearch
from IPython.display import display, Markdown
from langchain.llms import OpenAI
3.导入CSV文件。这是一个户外服装产品目录的CSV文件,我们将用它和LLM结合使用。
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
4.导入 VectorStoreIndexCreator,使用它可以方便的创建一个向量存储。
from langchain.indexes import VectorstoreIndexCreator
5.使用 VectorStoreIndexCreator创建一个向量存储。详细步骤如下:
- 第一步,指定一个向量存储类,这里使用上面提到的
DocArrayInMemorySearch。 - 第二步,创建向量存储后,调用
DataLoader传入一个包含一个或多个加载器的列表。
index = VectorstoreIndexCreator(vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
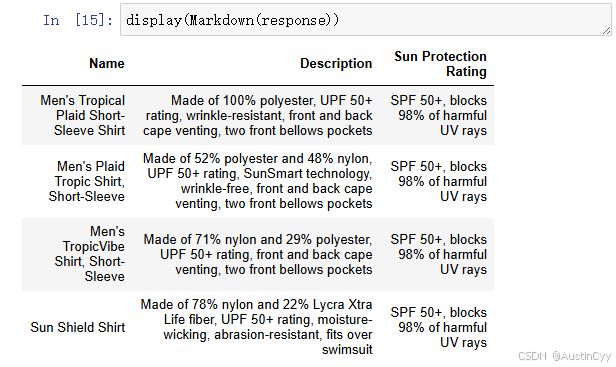
6.创建好向量存储后,我们创建提问 query。
query ="Please list all your shirts with sun protection \
in a table in markdown and summarize each one."
7.这里跟视频中不一样,因为相关库的版本更新所以,我们需要重新设置一下模型。然后获得向模型提问得到 response。
llm_replacement_model = OpenAI(temperature=0, model='gpt-3.5-turbo-instruct')response = index.query(query, llm = llm_replacement_model)
8.用 markdown 的形式展示得到的 response。
display(Markdown(response))
我们得到了一个 Markdown 格式的表格,列出来所有具有防晒功能的衬衫的名称和描述。符合我们提出的问题,成功基于文档的内容进行问答。
基于文件的问答的原理
在使用LLM对文档进行问答操作时,我们会想到,LLM一次只能接受几千个单词,我们该如何去让LLM 对一个很大的文档的所有内容进行问答?
为解决这个问题,我们需要用到 Embedding 和 Vector Datasets (向量存储)。下面我将通过具体的代码来详细讲解这部分的实现原理。
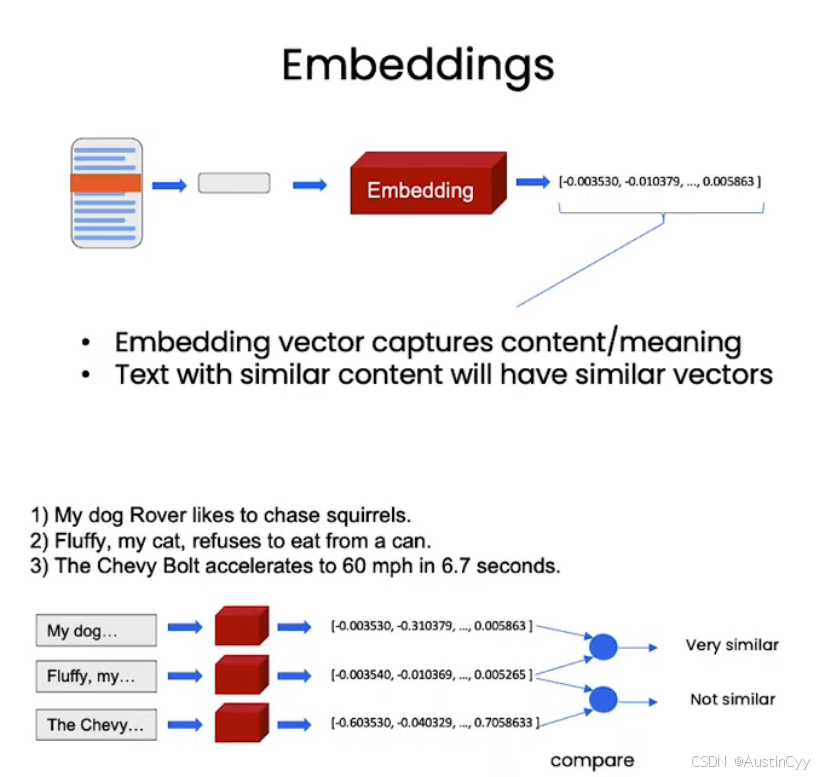
Embeddings
Embedding 中文叫做 嵌入。我们此处用到的 Embedding 主要是 NLP 当中的 Embedding 概念,功能是 将一段文本转换成数字,即用一组数字表示文本。
- 这组数字捕捉了它所代表的文字片段的内容含义。
- 内容相似的文本片段会有相似的向量值。
- 我们可以在向量空间中比较文本片段。
- 通过向量相似度,我们可以轻松地找出哪些文本片段相似。
- 我们可以利用这种技术从文档中找出跟问题相似地文本片段,一起传递给LLM 来帮助回答问题。
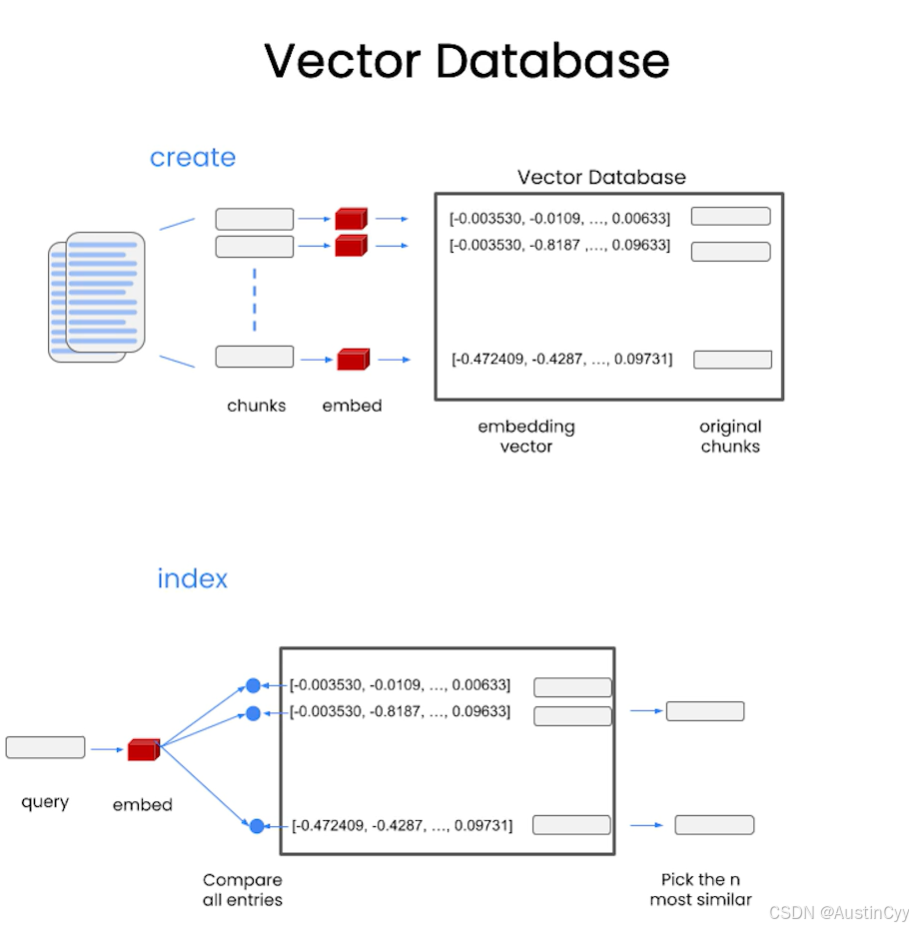
Vector Database
Vector Database(向量存储库)向量存储库是一种存储方式,可以存储我们在前面创建地那种 Embedding 后的数字数组。
- 在向量数据库中新建数据的方式,就是将文档拆分成快,每块生成 Embedding,然后把 Embedding 和原始块一起存储到数据库中。
- 当我们在处理大一点的文档时,首先要将其拆分成较小的文本块,因为可能无法将整个文档的内容都传给语言模型。所以需要把文档拆分成小块,这样每次就只用把最相关的几块内容传递给 语言模型。然后把每个文本块生成一个 Embedding, 然后将这些 Embedding 存储在向量数据库中。 这就是我们创建索引的过程。
- 索引创建后,我们可以用它来找到与查询内容做相关的几个文本片段:当一个查询进来时,我们首先将查询的内容生成 Embedding,得到一个数字数组。然后将这个数字数组与向量数据库中的所有向量进行比较,选择最相似的前若干个文本块。
文件问答原理演示
拿到这些文本块后,将这些文本块和原始的查询内容一起传递给语言模型,这样可以让语言模型根据检索出来的文档内容生成最终答案。
我根据上面的这个过程创建了下面的链,作为演示,来理解底层发生了什么。
1.创建一个文档加载器,加载前面提到的产品描述的CSV文件,用作后面问答的文档数据。
from langchain.document_loaders import CSVLoader
loader = CSVLoader(file_path=file)
我们可以使用这个文档加载器,查看单个文档,单个文档对应CSV文件中的一个产品。
docs = loader.load()
查看第一个文档。
docs[0]

2.之前我们虽然讲过对文档进行分块操作,但是这里因为文档已经很小了,所以我们不需要再分块了,直接生成 Embedding。要生成 Embedding,我们将使用 OpenAIEmbedding 类。这里导入并初始化这个类。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
为理解 Embedding 是如何工作的,我们查看一段特定的文本生成的 Embedding 是什么样子的。
使用 embed_query 方法为特定文本生成 Embedding。
embed = embeddings.embed_query("Hi my name is Harrison")
可以看到这个 Embedding,有超过一千个(1536) 个不同的元素。
print(len(embed))

可以看到每个元素都是一个不同的数字。这些数字就是这段文字的Embedding, 是一个1536维向量。
print(embed[:5])

3.给刚才加载的所有文本片段生成 Embedding,并将它们存储在一个向量存储器中。通过在向量存储器上调用 from_documents 方法来实现这一点。这个方法需要一个文档列表、一个Embedding对象,然后我们将创建一个向量存储器。
db = DocArrayInMemorySearch.from_documents(docs, embeddings
)
4.现在可以使用这个向量存储器来找到与输入的查询内容类似的文本片段。
query = "Please suggest a shirt with sunblocking"
在向量存储器上调用 similarity_search 方法并传入查询的内容,就可以查询到一个文档列表。
docs = db.similarity_search(query)
我们看到他返回了四个文档。
len(docs)

我们查看第一个文档,看到的确是一件关于防晒的衣服。
docs[0]

5.如何利用这个来回答我们自己文档中的问题呢?
首先,要从向量存储器中创建一个检索器 Retriever。检索器是一个通用接口,这个接口定义了一个接受查询内容并返回相似文档的方法。实现检索器的方法有很多种,基于向量存储和 Embedding的检索是其中的一种。
retriever = db.as_retriever()
我们想要返回一个自然语言的回应,要导入一个语言模型,我们使用 ChatOpenAI。
llm = ChatOpenAI(temperature = 0.0, model=llm_model)
接下来我们手动把检索出来的文档合并成一段文本。将所有文档中的内容连接起来,并将结果保存到一个变量中。
qdocs = "".join([docs[i].page_content for i in range(len(docs))])
然后我们会将这个变量的内容和一个问题一起传给LLM,问题内容是:请用 Markdown表格列出所有具有防晒功能的衬衫,并为这些衬衫写一份摘要。“
response = llm.call_as_llm(f"{qdocs} Question: Please list all your \
shirts with sun protection in a table in markdown and summarize each one.")
display(Markdown(response))
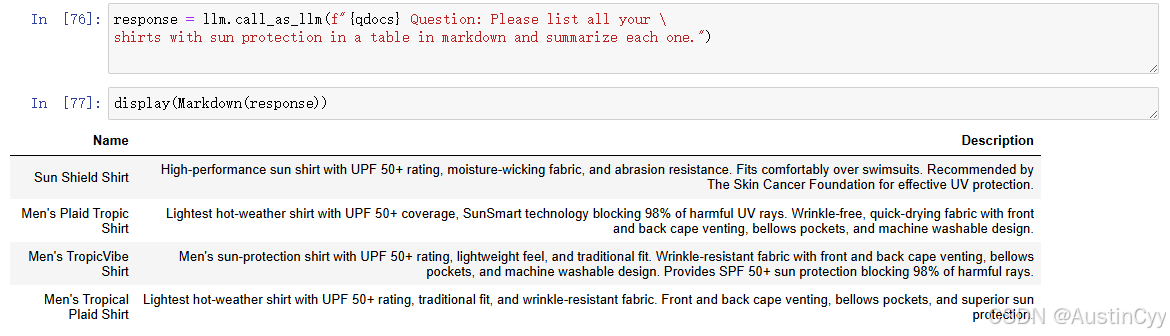
注: 一开始我得到的结果如下,后面我发现将 llm = ChatOpenAI(temperature = 0.0, model=llm_model) 中的 temperature 改大,就可以得到上面的结果了。

6.我们将上面的这些步骤封装成一个 Chain。创建检索链 RetrievalQA,这个链会对查询进行检索,然后在检索到的文档上进行问答。
- 语言模型用于最后的文本生成
- 传入链类型
stuff。stuff是最简单的方法,他在调用语言模型时,将所有的文档内容都一起放到上下文中。后文有详细介绍。 - 传入一个检索器,用于检索文档并将结果传递给语言模型
verbose=Ture打印详细日志
qa_stuff = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, verbose=True
)
创建一个查询,得到查询结果。
query = "Please list all your shirts with sun protection in a table \
in markdown and summarize each one."
response = qa_stuff.run(query)
display(Markdown(response))

7.整个基于文档的问答查询过程可以用一行代码完成,就跟我最开始的示例一样。这就是LangChain的好处,既可以简单的实现,也可以把每一步单独拆解出来。
response = index.query(query, llm=llm)
display(Markdown(response))

8.在生成索引时,我们也可以手动去创建索引,指定Embedding类型,更换向量存储类型等,这使得我们具有更大的灵活性。
index = VectorstoreIndexCreator(vectorstore_cls=DocArrayInMemorySearch,embedding=embeddings,
).from_loaders([loader])
基于文档问答的方法
Stuff method
stuff 方法很简单,只需要把所有的内容都放到 prompt中,然后发送给 LLM 得到返回结果即可。虽然简单,清晰,但不是在所有情况下效果都特别好。
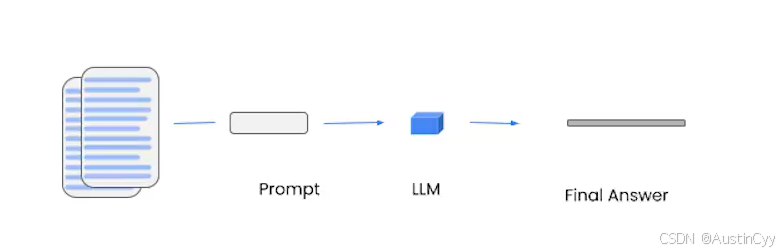
在我们上面的例子中,我们获取文档时只得到了四个相对较小的文档。如果我想在许多不同类型的分块上进行同样类型的问题问答该怎么办呢?下面补充介绍三种方法。
- Map_reduce
- Refine
- Map_rerank
Map_reduce
map_reduce 简单来说,就是对所有的分块把每一块的内容连同问题一起传递给语言模型,得到一个独立返回结果。然后每一块得到的结果都合并在一起,再使用语言模型来对这些结果进行总结,得到最终答案。
map_reduce 非常强大,因为他可以处理任意数量的文档。同时它可以并行处理多个分块。但是它需要更多的调用语言模型。并且把所有文档都独立处理,这可能并不总是最理想的结果。
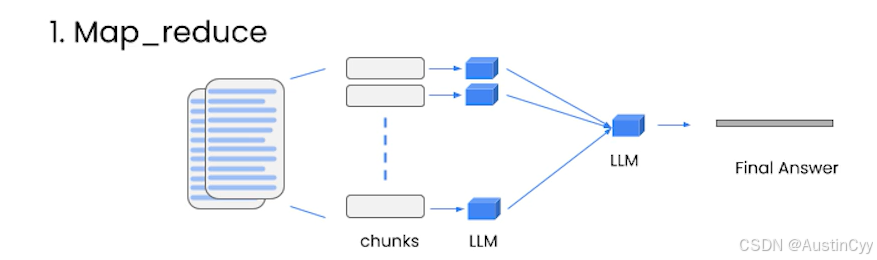
Refine
也是用来处理多个文档的方法。它的处理方式是迭代进行的,基于前一个文档的答案,去做一下次的回复。所以这对于需要整合信息,以及随着时间推移构建答案非常有用。但是,这个方法通常会导致更长的答案。另外,因为每一个文档无法被独立调用,必须依赖前面的结果,所以它通常需要更多的时间,并且调用次数与 map_reduce 一样多。
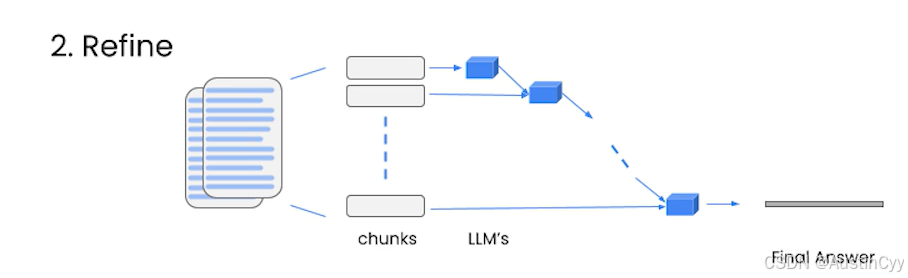
Map_rerank
在 map_rerank 中,对于每个文档,你只需对语言模型进行一次调用,另外还需要让它返回一个评分,然后选择最高分的结果。你需要告诉给它指令:”如果与文档相关,分数应该很高“,并且需要具体优化哪部分指令,让语言模型知道分数应该是多少。与 map_reduce 方法类似,所有的调用都是独立的。所以我们可以批量处理,而且速度相对较快。缺点是一样的,需要多次调用模型,花费会比较高。
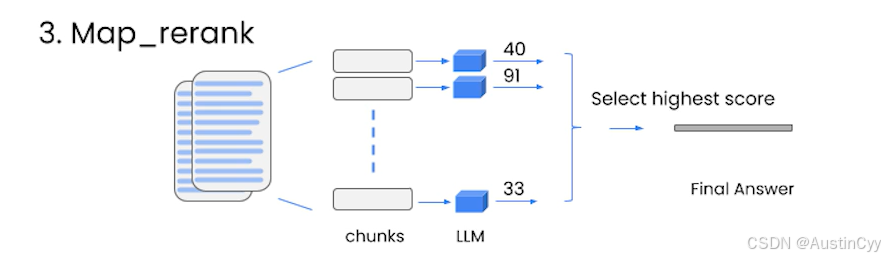
总结
本节介绍了如何使用 LangChain 构建基于文档的LLM问答应用。其中的重点为 Embedding 和 Vector Databse 这两个重要模块的理解和使用,以及对常用的LangChain的文档问答方法的理解和使用。在LangChain中,我们可以充分利用各个方法的特性,将其构建成不同的链来使用,以发挥最大的效能。
相关文章:
【LangChain】Chapter4 - Question and Answer Over Documents
说在前面 文档问答,是常见的一类LLM应用,给定一段可能是从 PDF文件、网页或某公司内部文档库中提取的文本,使用LLM回答关于这些文档内容的问题。这样的应用非常的强大,它可以将LLM与完全没被训练的数据相结合,可以灵活…...

TCP/IP 协议演进中的瓶颈,权衡和突破
所有(去掉 “几乎” 修饰)问题都来自于生长速度的不一致,换句话说,膨胀不是均匀的,从而产生瓶颈甚至触碰极限,TCP/IP 从协议到实现面临的多方问题与动物体型不能无限大,摩天大楼不能无限高本质上一样。 如今被高性能网…...

软件测试面试八股文,查漏补缺(附文档)
大家好,最近有不少小伙伴在后台留言,准备面试了,又不知道从何下手!为了帮大家节约时间,特意准备了一份面试相关的资料,内容非常的全面,真的可以好好补一补,希望大家在都能拿到理想的…...
IDEA工具使用介绍、IDEA常用设置以及如何集成Git版本控制工具
文章目录 一、IDEA二、建立第一个 Java 程序三、IDEA 常用设置四、IDEA 集成版本控制工具(Git、GitHub)4.1 IDEA 拉 GitHub/Git 项目4.2 IDEA 上传 项目到 Git4.3 更新提交命令 一、IDEA 1、什么是IDEA? IDEA,全称为 IntelliJ ID…...
YOLOv10-1.1部分代码阅读笔记-transformer.py
transformer.py ultralytics\nn\modules\transformer.py 目录 transformer.py 1.所需的库和模块 2.class TransformerEncoderLayer(nn.Module): 3.class AIFI(TransformerEncoderLayer): 4.class TransformerLayer(nn.Module): 5.class TransformerBlock(nn.Module)…...

机器人革新!ModbusTCP转CCLINKIE网关揭秘
在当今这个科技日新月异的时代,机器人技术正以前所未有的速度发展着,它们在工业制造、医疗服务、家庭娱乐等多个领域扮演着越来越重要的角色。而随着机器人应用的普及和多样化,如何实现不同设备之间的高效通信成为了一个亟待解决的问题。开疆…...

JWT包中的源码分析【Golang】
前言 最近在学web编程的途中,经过学长提醒,在进行登陆(Login)操作之后,识别是否登陆的标识应该要放入authorization中,正好最近也在学鉴权,就顺便来看看源码了。 正文 1. 代码示例 在进行分…...

SpringBoot数据字典字段自动生成对应code和desc
效果:接口会返回orderType,但是这个orderType是枚举的类型(1,2,3,4),我想多返回一个orderTypeDesc给前端展示,这样前端就可以直接拿orderTypeDesc使用了。 1. 定义注解 …...

TencentOS 2.4 final 安装mysql8.0备忘录
准备 tencentOS 2.4 与Red Hat Enterprise Linux 7 是兼容的。 我们首先从oracle官网上下载mysql的源文件。 下载完成后你会得到以下文件: mysql84-community-release-el7-1.noarch.rpm 安装 首先你需要切换到root用户下。 1.安装源文件 yum localinstall my…...

Hadoop HA安装配置(容器环境),大数据职业技能竞赛模块A平台搭建,jdk+zookeeper+hadoop HA
HA概述 (1) 所谓HA(High Availablity),即高可用(7*24小时不中断服务)。 (2) 实现高可用最关键的策略是消除单点故障,HA严格来说应该分为各个组件的HA机制,H…...

使用javascript读取波形文件数据,并生成动态的波形图
代码如下: // HTML5 Canvas 动态波形生成器 // 使用JS读取波形文件并生成动态波形// 创建Canvas并设置上下文 const canvas document.createElement(canvas); canvas.width 800; canvas.height 400; document.body.appendChild(canvas); const ctx canvas.getC…...

服务器系统维护与安全配置
一、硬件系统的安全防护 硬件的安全问题也可以分为两种,一种是物理安全,一种是设置安全。 1、物理安全 物理安全是指防止意外事件或人为破坏具体的物理设备,如服务器、交换机、路由器、机柜、线路等。机房和机柜的钥匙一定要管理…...

大模型Weekly 03|OpenAI o3发布;DeepSeek-V3上线即开源!
大模型Weekly 03|OpenAI o3发布;DeepSeek-V3上线即开源!DeepSeek-V3上线即开源;OpenAI 发布高级推理模型 o3https://mp.weixin.qq.com/s/9qU_zzIv9ibFdJZ5cTocOw?token47960959&langzh_CN 「青稞大模型Weekly」,持…...

Spring Boot自定义注解获取当前登录用户信息
写在前面 在项目开发过程中,难免都要获取当前登录用户的信息。通常的做法,都是开发一个获取用户信息的接口。 如果在本项目中,多处都需要获取登录用户的信息,难不成还要调用自己写的接口吗?显然不用! 以…...

js创建二维空数组
js创建二维空数组 错误使用原因分析分析1举个例子:解释: 正确创建二维数组总结: 错误使用 今天在写代码的时候,需要创建一个长度为2的空二维数组,我当时第一反应就是,使用let arr new Array(2).fill([])&…...

AF3 checkpoint_blocks函数解读
checkpoint_blocks 函数实现了一种分块梯度检查点机制 (checkpoint_blocks),目的是通过分块(chunking)执行神经网络模块,减少内存使用。在深度学习训练中,梯度检查点(activation checkpointing)是一种显存优化技术。该代码可以: 对神经网络的块(blocks)按需分块,并对…...

下载并使用CICFlowMeter提取网络流特征(Windows版本)
CICFlowMeter简介 CICFlowMeter是一款流量特征提取工具,从原始的pcap包中聚合流,并提取流特征到csv格式的文件中。使用CICFlowMeter提取的特征有助于后续基于网络流的分析与建模 官方github地址:https://github.com/ahlashkari/CICFlowMete…...

深入了解JSON-LD:语义化网络数据的桥梁
目录 前言1. JSON-LD概述1.1 什么是JSON-LD?1.2 JSON-LD的优势 2. JSON-LD的核心概念2.1 上下文(Context)2.2 词汇表(Vocabulary)2.3 标注语言(Markup Language) 3. JSON-LD的语法与结构3.1 基本…...

分布式 IO 模块助力冲压机械臂产线实现智能控制
在当今制造业蓬勃发展的浪潮中,冲压机械臂产线的智能化控制已然成为提升生产效率、保障产品质量以及增强企业竞争力的关键所在。而分布式 IO 模块的应用,正如同为这条产线注入了一股强大的智能动力,开启了全新的高效生产篇章。 传统挑战 冲压…...

webrtc源码编译【linux/安卓】
编译webrtc库 环境ubuntu22.04 推荐在linux里运行一个docker容器,在新环境里搭建。 准备工作 #我使用了下面的安装命令。目前知道的必须需要的 git python3 unzip ninja jdk file lsb-release apt install -y git curl build-essential python3 python3-pip pyt…...

在 Windows 上设置 JAVA_HOME 环境变量
在 Windows 上设置 JAVA_HOME 环境变量 在 Windows 操作系统上设置 JAVA_HOME 环境变量是一个常见的步骤,尤其是在开发 Java 应用程序时。通过设置 JAVA_HOME,你可以方便地管理和使用 JDK(Java Development Kit),并且…...

如何优雅管理JetBrains IDE试用期?3种场景下的完美解决方案
如何优雅管理JetBrains IDE试用期?3种场景下的完美解决方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经因为JetBrains IDE试用期结束而不得不中断开发工作?当代码写到关键部…...

蓝牙与WiFi之外:为机器人选择合适的近距离无线通信技术
在现代机器人系统中,无线通信不仅是遥控与数据回传的通道,更是实现多机协同、环境感知和人机交互的神经中枢。然而,面对琳琅满目的无线技术——经典蓝牙(Bluetooth Classic)、低功耗蓝牙(BLE)、…...

别让格式毁掉你的毕业论文!Paperxie AI 排版:3 分钟复刻学校官方标准
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AIPPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 一、 本科生的痛:论文写完了,格式却能逼疯人 毕业论文的终极考验,从来都…...

OpenClaw夜间值守:Qwen3.5-9B监控服务器报警截图
OpenClaw夜间值守:Qwen3.5-9B监控服务器报警截图 1. 为什么需要AI值守夜间监控? 凌晨3点的服务器报警短信,可能是运维工程师最不愿看到的通知之一。传统监控系统虽然能发出警报,但往往存在两个痛点:一是误报率高&…...

产教融合共建失智老年人照护实训室实践路径
本文围绕产教融合模式,结合失智老年人照护岗位实际需求,从合作机制、空间布局、设备配置、教学实施、运营保障五个核心维度,给出可落地的失智老年人照护实训室共建实践路径,兼顾实用性与可操作性,助力院校与企业高效共…...

2025届必备的六大AI辅助写作平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 进行学术写作以及内容创作之际,使文本的AI生成痕迹得以降低,这是提升…...
)
Modbus协议避坑指南:功能码06写入失败的5个常见原因及解决方法(附Wireshark抓包分析)
Modbus协议避坑指南:功能码06写入失败的5个常见原因及解决方法(附Wireshark抓包分析) 在工业自动化领域,Modbus协议因其简单可靠的特点,成为设备通信的基石。而功能码06(写单个寄存器)作为最常用…...
退出处理机制与优化实践)
嵌入式程序main()退出处理机制与优化实践
1. 嵌入式程序执行的生命周期解析在裸机嵌入式开发中,程序执行流程与通用计算机存在本质差异。以8051架构为例,当开发者在Keil环境下编写一个简单的LED控制程序时,完整的执行链条包含以下几个关键阶段:硬件复位阶段(0x…...
)
PaddlePaddle-GPU环境配置:为什么你的显卡总是被识别成CPU?(附解决方案)
PaddlePaddle-GPU环境配置:为什么你的显卡总是被识别成CPU?(附解决方案) 刚拿到新显卡准备大展拳脚,却发现PaddlePaddle死活不认GPU,这种挫败感我太懂了。明明花大价钱买的显卡,结果深度学习训…...