从论文到实践:Stable Diffusion模型一键生成高质量AI绘画

🏡作者主页:点击!
🤖编程探索专栏:点击!
⏰️创作时间:2024年12月24日10点02分
神秘男子影,
秘而不宣藏。
泣意深不见,
男子自持重,
子夜独自沉。
论文源地址有视频:
链接![]() https://www.aspiringcode.com/content?id=17143966705089&uid=6b9a21ad66fd4803800b486d5469a7aa
https://www.aspiringcode.com/content?id=17143966705089&uid=6b9a21ad66fd4803800b486d5469a7aa
AI绘画一键生成美图-变成画家
本地部署SD模型,一键即可生成自己想要绘制的图画,本文包括论文原理讲解和代码复现
论文讲解
论文题目:High-Resolution Image Synthesis with Latent Diffusion Models(基于潜在扩散模型的高分辨率图像合成)
论文被计算机视觉顶会CVPR 2022收录
Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。它建立在自注意力机制和扩散过程的基础上。它的设计灵感来自于扩散过程模型(Diffusion Models),这些模型在自然图像建模领域取得了巨大成功。
Stable Diffusion通过一系列的扩散步骤来生成图像。在每一步中,模型逐渐“扩散”图像,从含有较少信息的噪声开始,到包含更多细节的图像。在每个扩散步骤中,模型需要预测图像的条件分布,并根据这个条件分布生成下一个扩散步骤的输入。
背景介绍
在生成模型的研究中,扩散过程模型和自注意力机制是两个备受关注的领域。扩散过程模型是一种基于随机过程的生成模型,通过模拟随机过程的演化来生成图像,它在自然图像建模领域取得了巨大的成功。而自注意力机制则是一种强大的神经网络组件,能够有效地捕捉输入序列中不同位置之间的依赖关系,被广泛应用于自然语言处理和计算机视觉领域。
近年来,研究人员开始探索如何将扩散过程模型和自注意力机制结合起来,以进一步提高生成模型的性能和生成图像的质量。在这个背景下,Stable Diffusion应运而生,简称SD模型。
Stable Diffusion的提出
Stable Diffusion是一种基于扩散过程和自注意力机制的生成模型,旨在生成高质量的图像。它采用了一系列扩散步骤来逐渐生成图像,每个步骤中模型需要预测图像的条件分布,并生成下一个扩散步骤的输入。通过结合自注意力机制,Stable Diffusion能够有效地捕捉图像中不同位置之间的关联信息,从而生成更加真实和细节丰富的图像。
Stable Diffusion在图像生成领域的应用
Stable Diffusion不仅可以用于生成高质量的图像,还可以应用于多种图像生成任务,包括图像修复、超分辨率重建、图像合成等。其灵活的生成过程和强大的生成能力使其成为图像生成领域的一项重要研究成果,并在各种实际应用中展现出巨大潜力。
在下文中,我们将更深入地探讨Stable Diffusion的工作原理、实现细节以及相关的实验结果,以帮助读者更好地理解这一新颖的生成模型,并探讨其在未来的发展方向和应用前景。
经过微调后Stable Diffusion模型可以生成各种风格的图像,先来看生成效果:


上图是模型的框架图,模型的步骤和讲解如下
1、训练自编码模型(AutoEncoder)
- 首先,通过训练一个自编码模型,包括编码器和解码器部分。编码器负责将输入图像压缩成潜在表示(latent representation),而解码器则负责将潜在表示解码成原始像素空间的图像。
- 这一步骤是为了将图像压缩到低维的潜在表示空间,为后续的diffusion操作做准备。
2、感知压缩(Perceptual Compression)
- 利用训练好的自编码模型对图片进行压缩,将其转换到潜在表示空间。
- 在潜在表示空间上进行操作,这个过程被称为感知压缩,因为它通过自编码器模型来实现压缩,同时保留了重要的图像特征。
3、潜在表示空间上的diffusion操作
- 在潜在表示空间上进行diffusion操作,其过程与标准的扩散模型类似。
- 扩散模型的具体实现为time-conditional UNet,这是一种结合了时间条件信息的UNet结构,用于在潜在表示空间上进行图像生成。
图片感知压缩
图片感知压缩(Perceptual Image Compression)是一种通过忽略图像中的高频信息,保留重要和基础特征来实现高效压缩的方法。这种方法在生成模型中起到了关键作用,通过降低模型训练和采样的计算复杂度,使得模型能够在较短的时间内生成高质量的图像,从而降低了模型的落地门槛。
方法原理
- 感知压缩利用预训练的自编码模型(如变分自编码器,VAE)来学习图像的潜在表示空间。这个潜在表示空间是在感知上等同于图像空间的,但维度更低。
- 在这个潜在表示空间中,自编码模型保留了图像的重要特征,同时忽略了一些不太重要的高频信息。这种压缩方式使得模型训练和采样的计算复杂度大幅降低。
方法优势
- 感知压缩只需要训练一个通用的自编码模型,就可以应用于不同的扩散模型训练中,也可以用于不同的图像生成任务。这种通用性使得该方法在多种场景下都十分有效。
- 除了标准的无条件图像生成任务外,感知压缩还可以方便地应用于各种图像到图像(如修复、超分辨率重建)和文本到图像(如文本生成图像)的任务中。
训练过程
- 基于感知压缩的扩散模型的训练通常是一个两阶段的过程。首先,需要训练一个自编码器来学习图像的潜在表示空间。在这一阶段中,为了避免潜在表示空间出现高度的异化,通常会采用KL正则化(KL-reg)和矢量量化正则化(VQ-reg)等方法。
- 在Stable Diffusion中,主要采用AutoencoderKL这种实现,这个实现结合了KL正则化的方法,用于训练自编码器。
潜在扩散模型
扩散模型可以被理解为一种时序去噪自编码器,其主要目标是根据输入图像去预测一个对应的去噪后的变体,或者说预测噪音,其中噪音是输入图像的噪音版本。其相应的目标函数可以被表述如下:

这里, x_t是模型预测的下一个时间步的图像,x_t-1 是当前时间步的输入图像,ε_t 是从均匀分布中采样得到的噪音。
在潜在扩散模型中,引入了预训练的感知压缩模型。这个感知压缩模型包括一个编码器E和一个解码器D。在训练过程中,编码器 负责将输入图像压缩成潜在表示,解码器则负责将潜在表示 解码成图像。这样,模型就能够在潜在表示空间中学习。相应的目标函数可以被表述如下:

在这里,z_t 是模型预测的下一个时间步的潜在表示,x_t-1 是当前时间步的输入图像,E_ϕ 是编码器,D_ϕ 是解码器,ϕ是编码器和解码器的参数。这样的目标函数结构使得模型能够在潜在表示空间中进行操作,同时通过解码器将潜在表示转换回图像空间。
条件机制
通过引入条件信息来控制图片合成的过程。为了实现这一点,论文提出了拓展的条件时序去噪自编码器(conditional denoising autoencoder)。通过这种方法,我们可以引入条件变量c,并将其作为输入来控制图像的生成过程。
通过在 UNet 主干网络上增加 cross-attention 机制来实现条件图片生成。这个过程可以理解为,在生成图像的过程中,模型会重点关注与条件变量相关的信息,从而在图像生成过程中加入条件的影响。为了能够处理来自多个不同模态的条件变量,论文引入了一个领域专用编码器(domain specific encoder),用来将不同模态的条件变量 ?c 映射为一个统一的中间表示。这样一来,我们可以很方便地引入各种形态的条件,比如文本、类别、布局等等。
总之,条件图片生成任务的目标函数可以根据模型的具体设计而有所不同,但通常会涉及到最小化生成图像与目标图像之间的差异,同时考虑到条件变量对图像生成过程的影响。
实验结果

模型生成效果如上图,展示了来自不同数据集(CelebAHQ、FFHQ、LSUN-Churches、LSUN-Bedrooms和类别条件的ImageNet)上训练的LDMs(Latent Diffusion Models)生成的样本。这些样本的分辨率均为256×256像素。

这个图表展示了在ImageNet数据集上,通过观察类别条件下的不同下采样因子 f,对类别条件下的扩散模型(LDM,Latent Diffusion Models)进行训练的情况。图中显示了在进行了200万个训练步骤后的结果。这些模型使用了不同的下采样因子(如LDM-1、LDM-4、LDM-16等),这直接影响了模型的感知压缩程度。

展示了在CelebA-HQ和ImageNet数据集上,不同压缩程度的LDMs(Latent Diffusion Models)在推断速度和样本质量之间的比较。图中的左侧部分是CelebA-HQ数据集的结果,右侧部分是ImageNet数据集的结果。不同的标记代表使用DDIM采样器进行的{10、20、50、100、200}个采样步骤,沿着每条线从右到左进行计数。
代码复现
环境配置
基本的环境配置要点如下
- 最好使用显卡的电脑,没有显卡SD模型生成图像较慢。(本人使用1660 Ti 显卡 6G显存可跑SD模型,速度比较快了,大家可以参考此配置)
- 电脑能够访问github,并安装git工具,方便下载代码。(如果不能访问,附件中有我整理的代码包(已经配置好且安装了汉化插件),即开即用。)
- 安装好编程语言工具python,可以直接安装,也可以使用Conda环境
1、在Windows下需要配置有Python环境,建议使用Conda环境
# 创建一个sd环境,方便后续安装包
conda create –n sd python=3.10.9
# 激活sd环境
activate sd2、拉取官方的代码,如果不能拉取代码,可我整理好的附件使用。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git13、安装代码运行所需要的包(已成功下载官方代码或者下载了我整理好的代码包)
成功下载代码包后,打开"stable-diffusion-webui"文件夹,点击webui-user.bat文件,一定注意点击webui-user.bat,后缀是bat的文件(Windows安装文件),而不是sh的(sh是Linux的安装文件)。

安装一般需要等待1个半小时左右,耐心等待安装结束。
安装结束,一般浏览器会自动打开网页,如果没有打开,请在浏览器输入http://127.0.0.1:7860,正常运行,命令行页面提示的地址。

即可见到启动页面
下面是官方代码的启动页面,我整理的代码是已经安装好汉化插件,汉化过的,方便使用

下面是使用整理好的附件的代码启动的页面,已经集成了中英文双语汉化插件,方便使用。

提示词准备
提示词可以根据用户自己的喜好设定,比如设置生成猫狗的图像、动漫图像。不过提示词的设定是一门技术,好的提示词,能够引导模型生成符合要求的图像。提示词要是英文的。
这里推荐一个提示词和模型下载网站 https://civitai.com/,在这个网站上可以下载自己喜欢风格的模型,也可以方便获取提示词,可以基于别人写好的提示词修改。
下面就是一个“majicMIX realistic 麦橘写实”的模型,可以生成写实风格的图像。

提示词一般要准备正面提示词和负面提示词
正面提示词(我们想要的内容)例如:
1girl,hair with bangs,black long dress,orange background,负面提示词(我们不要的内容)例如
(worst quality:2),(low quality:2),(normal quality:2),lowres,watermark,准备好提示词,我们就可以设置模型生成的参数

生成的参数控制模型的应该怎样生成
针对不同风格图像要有不同的参数,例如

模型下载
下载模型文件majicmixRealistic_v7.safetensors到stable-diffusion-webui\models\Stable-diffusion文件夹下

放在stable-diffusion-webui\models\Stable-diffusion文件夹下,一定要注意,放在该文件夹,才能检测到。

生成图像
以上都设置完毕后,即可点击生成按钮,开始绘画
点击生成按钮生成效果如下所示:

绘画效果
下面是生成图像的高清图:
本次绘画过程中,共进行6次生成,除第一次生成效果不太好外,其余效果都很好,可以生成根据提示不同风格的图像

总结
以上就是Stable diffusion模型的论文和代码复现的讲解。
这篇论文和代码,都是很好玩的,可以帮助我们绘制想要的图画,满足我们一键成为画家的愿望。
整理的代码在附件中,可以直接安装上面的教程使用。
参考链接
Stable Diffusion论文 链接
相关文章:
从论文到实践:Stable Diffusion模型一键生成高质量AI绘画
🏡作者主页:点击! 🤖编程探索专栏:点击! ⏰️创作时间:2024年12月24日10点02分 神秘男子影, 秘而不宣藏。 泣意深不见, 男子自持重, 子夜独自沉。 论文源地址有视频: 链接h…...

项目管理:用甘特图 “导航” 项目全程
项目全程管理是一个复杂而又系统的过程,它涵盖了从项目启动到结束的各个阶段,包括规划、执行、监控和收尾等一系列活动。 项目全程管理能够确保项目按时交付、控制成本、提高质量以及满足客户需求。通过有效的管理,项目团队可以避免资源浪费…...

v3.0.8- 「S+会员」新增专属运动秀,试试新穿搭吧- 与「好友」
v3.0.8 - 「S会员」新增专属运动秀,试试新穿搭吧 - 与「好友」互动支持前往对方所在的「在线运动房」 - 「运动秀工坊」新增智能背景抠图 - 「体育竞技」匹配中可以看到我和对手的装备 - 多项界面体验和性能优化 v2.0.17 - 班级运动场新增运动秀展示 - 班级玩法&…...

9-Gin 中自定义 Model --[Gin 框架入门精讲与实战案例]
在 Gin 框架中自定义 Model 通常指的是定义你自己的数据结构,这些结构体(Structs)将用来表示数据库中的表、API 请求的参数或响应的数据格式。下面是如何在 Gin 中创建和使用自定义 Model 的基本步骤。 自定义 Model 定义结构体 首先&…...

【VBA】EXCEL - VBA 创建 Sheet 表的 6 种方法,以及注意事项
目录 1. 创建一个新工作表,并将其添加到工作簿的末尾 2. 创建一个新工作表,并命名它 3. 创建一个新工作表,并将其插入到指定位置 4. 检查是否已有同名工作表,避免重复创建 5. 创建多个工作表 6. 基于现有模板创建新工作表 …...
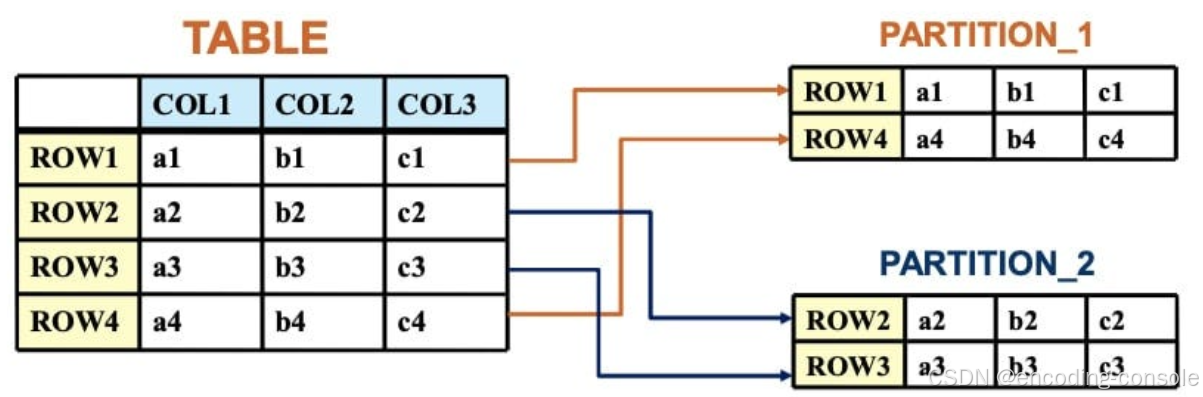
数据库中,group by 和partition by:数据分组和数据分区的区别
数据库中,group by 和partition by:数据分组和数据分区的区别 在大规模数据处理和分析的场景中,对数据进行分区和分组处理是非常常见的场景。 为了实现这一操作,在一些主流的关系型数据库管理系统中,提供了group by 和…...

【linux学习指南】Ext系列文件系统(四)路径分区链接
文章目录 🌠⽬录与⽂件名🌠路径解析🌠路径缓存🌠挂载分区🌉 ⽂件系统总结 🌠软硬连接🌉 硬链接🌉 软链接🌉 软硬连接对⽐🌉软硬连接的⽤途: &…...

深度学习中的参数初始化
深度学习中的参数初始化主要是指初始化神经网络中的权重和偏置。权重和偏置通常分开初始化,偏置通常初始化为零或较小的常数值。 没有一种万能的初始化技术,因为最佳初始化可能因具体架构和要解决的问题而异。因此,尝试不同的初始化技术以了解…...

wpf 基于Behavior库 的行为模块
Microsoft.Xaml.Behaviors 是一个用于WPF(Windows Presentation Foundation)的行为库,它的主要作用是允许开发者在不修改控件源代码的情况下,为控件添加自定义的行为和交互逻辑。行为库的核心思想是通过定义可重用的行为组件&…...

【每日学点鸿蒙知识】导入cardEmulation、自定义装饰器、CallState状态码顺序、kv配置、签名文件配置
1、HarmonyOS 无法导入cardEmulation? 在工程entry mudule里的index.ets文件里导入cardEmulation失败 可以按照下面方式添加SystemCapability;在src/main/syscap.json(此文件需要手动创建)中添加如下内容 {"devices": {"gen…...

【SpringMVC】REST 风格
REST(Representational State Transfer,表现形式状态转换)是一种访问网络资源的格式。传统的资源描述方式通常如下: http://localhost/user/getById?id1http://localhost/user/saveUser 而 REST 风格的描述则更简洁:…...

IDEA修改编译版本
目录 一、序言 二、修改maven配置 1.修改 2.代码 三、pom文件配置 1.修改 2.代码 3.问题 一、序言 有两种方法可以帮助大家解决IDEA每次刷新maven的pom配置时,会发生发行源版本不正常的报错。个人推荐第二种,原因:第二种你刷新maven后…...

SkyWalking Agent 配置 Spring Cloud Gateway 插件解决日志错误
SkyWalking Agent 配置 Spring Cloud Gateway 插件解决日志错误 IDEA中启动网管时,需要配置VM启动参数,格式如下: # 配置 SkyWalking Agent 启动参数,以便将网关服务的性能数据上报到 SkyWalking 服务器。 -javaagent:/path/to/sk…...

canvas+fabric实现时间刻度尺(一)
前言 需求:显示一个时间刻度尺,鼠标移动会显示当前时间 技术:我们采用canvasfabric进行实现 效果 实现 1.创建canvas(设置宽高)设为全局变量 2.引入fabric包 3.画时间刻度尺(长方形横线) …...

傲雷亮相2024中国时尚体育季(珠海站),展现户外移动照明风采
2024年12月28-29日,2024中国时尚体育季(珠海站)国家级轮滑比赛在珠海金山体育公园成功举办。作为户外创新型移动照明领域的领导品牌,傲雷受邀参加了本次珠海金湾运动生活嘉年华的展览单元,与众多户外运动品牌同台展示。…...

YOLOv10-1.1部分代码阅读笔记-block.py
block.py ultralytics\nn\modules\block.py 目录 block.py 1.所需的库和模块 2.class DFL(nn.Module): 3.class Proto(nn.Module): 4.class HGStem(nn.Module): 5.class HGBlock(nn.Module): 6.class SPP(nn.Module): 7.class SPPF(nn.Module): 8.class C1(nn…...

@RestControllerAdvice注解
RestControllerAdvice 是 Spring 4 引入的一个组合注解,它结合了 ControllerAdvice 和 ResponseBody,专门用于处理 RestController 类型的控制器中的全局异常、全局数据绑定和全局模型属性等问题。在 Spring Boot 中,RestControllerAdvice 通…...

Enum枚举类与静态变量和静态数组的区别
Enum枚举类与静态变量和静态数组的区别 组成结构Enum枚举类静态变量静态数组 组成结构的区别相同之处不同之处 用法使用相同之处不同之处 组成结构 先来看下Enum枚举类,静态变量,静态数组的初始化过程,以下面为例子: public enu…...

uniapp——微信小程序读取bin文件,解析文件的数据内容(三)
微信小程序读取bin文件内容 读取用户选择bin文件,并解析数据内容,分包发送给蓝牙设备; 文章目录 微信小程序读取bin文件内容读取文件读取内容返回格式 API文档: getFileSystemManager 关于App端读取bin文件,请查看&…...

SpringBoot集成ECDH密钥交换
简介 对称加解密算法都需要一把秘钥,但是很多情况下,互联网环境不适合传输这把对称密码,有密钥泄露的风险,为了解决这个问题ECDH密钥交换应运而生 EC:Elliptic Curve——椭圆曲线,生成密钥的方法 DH&…...

XC7Z010-2CLG400I Xilinx Zynq-7000 FPGA
XC7Z010-2CLG400I 可以理解为一颗“ARM 处理器 FPGA 可编程逻辑”合在一起的 SoC。它属于 Xilinx (赛灵思 AMD )Zynq-7000 家族里的 Z-7010 器件,核心特点就是把 双核 Arm Cortex-A9 MPCore 处理系统(PS) 和 7 系列可编程逻辑&am…...

Linux命令行玩转CAN总线:像查日志一样用grep分析candump实时数据流
Linux命令行玩转CAN总线:像查日志一样用grep分析candump实时数据流 在Linux系统管理领域,日志分析是每个开发者都熟悉的日常操作。当面对CAN总线这样的专业数据流时,其实可以运用同样的思维——将candump视为持续输出的数据源,用g…...

百考通:AI让每一份调研与设计都高效落地
在数字化时代,市场调研、产品设计、学术研究等场景中,问卷设计作为核心环节,直接影响着数据收集的质量与工作推进的效率。传统问卷设计往往面临流程繁琐、耗时耗力、问题设计不精准等痛点,而百考通(https://www.baikao…...

C# 环境:深入解析与应用
C# 环境:深入解析与应用 引言 C#(读作“C Sharp”)是一种由微软开发的高级编程语言,广泛应用于Windows平台的应用程序开发。自从2002年推出以来,C#已经成为了全球开发者喜爱的编程语言之一。本文将深入解析C#环境,包括其特点、应用场景以及开发环境搭建等。 C#环境概述…...

告别混乱!用这6个SAP屏幕跳转语句,让你的Fiori应用底层逻辑更清晰
告别混乱!用这6个SAP屏幕跳转语句,让你的Fiori应用底层逻辑更清晰 在SAP的演进历程中,从传统的ABAP Dialog编程到现代的Fiori/UI5应用开发,屏幕导航逻辑始终是系统交互设计的核心。对于同时维护传统模块和开发新Fiori界面的开发者…...

基于MYC-Y6ULX-V2核心板的工业运动控制系统实践
1. 项目概述:当工业运动控制遇上嵌入式核心板在工业自动化领域,运动控制系统是驱动设备精确执行动作的“大脑”和“神经中枢”。从数控机床的精密加工,到机器人的流畅轨迹,再到包装产线的快速分拣,其核心都依赖于一个稳…...

告别‘自消’:深入浅出聊聊协方差矩阵重建与对角加载如何拯救你的波束形成器
告别‘自消’:深入浅出聊聊协方差矩阵重建与对角加载如何拯救你的波束形成器 雷达工程师老张盯着屏幕上的波束图皱起了眉头——明明仿真时完美的指向性波束,在实际测试中却像被"咬掉一块"的月饼,目标信号区域出现了诡异的凹陷。这种…...

会议纪要整理不清?如何将会议成果转化为可落地任务
身边不少HR朋友都有过纪要整理的困扰,一场会议或面谈后,花费大量时间整理,最终产出的纪要却零散杂乱,无法提炼可落地的任务,导致会议效果大打折扣。结合半年多的实测体验,整理出一套零基础也能上手的高效方…...

NCMconverter终极指南:3步高效解密网易云音乐NCM加密格式
NCMconverter终极指南:3步高效解密网易云音乐NCM加密格式 【免费下载链接】NCMconverter NCMconverter将ncm文件转换为mp3或者flac文件 项目地址: https://gitcode.com/gh_mirrors/nc/NCMconverter NCMconverter是一款开源高效的音频格式转换工具,…...
)
别再写if-else了!用Simulink的If-Action子系统建模,代码生成更清晰(附完整模型搭建步骤)
告别if-else嵌套噩梦:用Simulink If-Action子系统实现优雅的条件逻辑建模 在嵌入式系统开发中,复杂的条件分支逻辑就像房间里的大象——每个人都见过,却很少有人愿意正面处理。想象一下:当你面对一个深度嵌套的if-else结构&#x…...