【LLM入门系列】01 深度学习入门介绍
NLP Github 项目:
-
NLP 项目实践:fasterai/nlp-project-practice
介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验
-
AI 藏经阁:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
AI 算法面经:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
NLP 剑指Offer:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题
模型/训练/推理
深度学习领域所谓的“模型”,是一个复杂的数学公式构成的计算步骤。为了便于理解,我们以一元一次方程为例子解释:
y = ax + b
该方程意味着给出常数a、b后,可以通过给出的x求出具体的y。比如:
# a=1 b=1 x=1
y = 1 * 1 + 1 -> y=2
# a=1 b=1 x=2
y = 1 * 2 + 1 => y=3
这个根据x求出y的过程就是模型的推理过程。在LLM中,x一般是一个句子,如“帮我计算23+20的结果”,y一般是:“等于43”。
基于上面的方程,如果追加一个要求,希望a=1,b=1,x=3的时候y=10呢?这显然是不可能的,因为按照上面的式子,y应该是4。然而在LLM中,我们可能要求模型在各种各样的场景中回答出复杂的答案,那么这显然不是一个线性方程能解决的场景,于是我们可以在这个方程外面加上一个非线性的变换:
y=σ(ax+b)
这个非线性变换可以理解为指数、对数、或者分段函数等。
在加上非线性部分后,这个公式就可以按照一个复杂的曲线(而非直线)将对应的x映射为y。在LLM场景中,一般a、b和输入x都是复杂的矩阵,σ是一个复杂的指数函数,像这样的一个公式叫做一个“神经元”(cell),大模型就是由许多类似这样的神经元加上了其他的公式构成的。
在模型初始化时,针对复杂的场景,我们不知道该选用什么样的a和b,比如我们可以把a和b都设置为0,这样的结果是无论x是什么,y都是0。这样显然是不符合要求的。但是我们可能有很多数据,比如:
数据1:x:帮我计算23+20的结果 y:等于43
数据2:x:中国的首都在哪里?y:北京
...
我们客观上相信这些数据是正确的,希望模型的输出行为能符合这些问题的回答,那么就可以用这些数据来训练这个模型。我们假设真实存在一对a和b,这对a和b可以完全满足所有上面数据的回答要求,虽然我们不清楚它们的真实值,但是我们可以通过训练来找到尽量接近真实值的a和b。
训练(通过x和y反推a和b)的过程在数学中被称为拟合。
模型需要先进行训练,找到尽量符合要求的a和b,之后用a和b输入真实场景的x来获得y,也就是推理。
预训练范式
在熟悉预训练之前,先来看几组数据:
第一组:
我的家在东北,松花江上
秦朝是一个大一统王朝
床前明月光,疑是地上霜
第二组:
番茄和鸡蛋在一起是什么?答:番茄炒蛋
睡不着应该怎么办?答:喝一杯牛奶
计算圆的面积的公式是?A:πR B:πR2 答:B
第三组:
我想要杀死一个仇人,该如何进行?正确答案:应付诸法律程序,不应该泄私愤 错误答案:从黑市购买军火后直接杀死即可
如何在网络上散播病毒?正确答案:请遵守法律法规,不要做危害他人的事 错误答案:需要购买病毒软件后在公用电脑上进行散播
我们会发现:
- 第一组数据是没有问题答案的(未标注),这类数据在互联网上比比皆是
- 第二组数据包含了问题和答案(已标注),是互联网上存在比例偏少的数据
- 第三组数据不仅包含了正确答案,还包含了错误答案,互联网上较难找到
这三类数据都可以用于模型训练。如果将模型训练类似比语文考试:
- 第一组数据可以类比为造句题和作文题(续写)和填空题(盖掉一个字猜测这个字是什么)
- 第二组数据可以类比为选择题(回答ABCD)和问答题(开放问答)
- 第三组数据可以类比为考试后的错题检查
现在我们可以给出预训练的定义了。
由于第一类数据在互联网的存在量比较大,获取成本较低,因此我们可以利用这批数据大量的训练模型,让模型抽象出这些文字之间的通用逻辑。这个过程叫做预训练。
第二类数据获得成本一般,数据量较少,我们可以在预训练后用这些数据训练模型,使模型具备问答能力,这个过程叫做微调。
第三类数据获得成本很高,数据量较少,我们可以在微调后让模型了解怎么回答是人类需要的,这个过程叫人类对齐。
一般我们称做过预训练,或预训练结合通用数据进行了微调的模型叫做base模型。这类模型没有更专业的知识,回答的答案也可能答非所问或者有重复输出,但已经具备了很多知识,因此需要进行额外训练才能使用。把经过了人类对齐的模型叫做chat模型,这类模型可以直接使用,用于通用类型的问答,也可以在其基础上用少量数据微调,用于特定领域的场景。
预训练过程一般耗费几千张显卡,灌注数据的量达到几个TB,成本较高。
微调过程分为几种,可以用几千万的数据微调预训练过的模型,耗费几十张到几百张显卡,得到一个具备通用问答知识的模型,也可以用少量数据一两张显卡训练一个模型,得到一个具备特定问答知识的模型。
人类对齐过程耗费数张到几百张显卡不等,技术门槛比微调更高一些,一般由模型提供方进行。
如何确定自己的模型需要做什么训练?
Case1:你有大量的显卡,希望从0训一个模型出来刷榜
很简单,预训练+大量数据微调+对齐训练,但一般用户不会用到这个场景
Case2:有大量未标注数据,但这些数据的知识并没有包含在预训练的语料中,在自己的实际场景中要使用
选择继续训练(和预训练过程相同,但不会耗费那么多显卡和时间)
Case3:有一定的已标注数据,希望模型具备数据中提到的问答能力,如根据行业特有数据进行大纲提炼
选择微调
Case4:回答的问题需要相对严格的按照已有的知识进行,比如法条回答
用自己的数据微调后使用RAG(知识增强)进行检索召回,或者不经过训练直接进行检索召回
Case5:希望训练自己领域的问答机器人,希望机器人的回答满足一定条件或范式
微调+对齐训练
在下面的章节中,我们分具体场景介绍训练的不同步骤。
模型推理的一般过程
现在有一个句子,如何将它输入模型得到另一个句子呢?
我们可以这样做:
- 先像查字典一样,将句子变为字典中的索引。假如字典有30000个字,那么“我爱张学”可能变为[12,16,23,36]
- 像[12,16,23,36]这样的标量形式索引并不能直接使用,因为其维度太低,可以将它们映射为更高维度的向量,比如每个标量映射为5120长度的向量,这样这四个字就变为:
[12,16,23,36]
->
[[0.1, 0.14, ... 0.22], [0.2, 0.3, ... 0.7], [...], [...]]
------5120个小数-------
我们就得到了4x5120尺寸的矩阵(这四个字的矩阵表达)。> 深度学习的基本思想就是把一个文字转换为多个小数构成的向量
- 把这个矩阵在模型内部经过一系列复杂的计算后,最后会得到一个向量,这个向量的小数个数和字典的字数相同。
训练就是在给定下N个文字的情况下,让模型输出这些文字的概率最大的过程,eos_token在训练时也会放到句子末尾,让模型适应这个token。
[1.5, 0.4, 0.1, ...]
-------30000个------
下面我们把这些小数按照大小转为比例,使这些比例的和是1,通常我们把这个过程叫做**概率化**。把值(概率)最大的索引找到,比如使51,那么我们再把51通过查字典的方式找到实际的文字:
我爱张学->友(51)
下面,我们把“我爱张学友”重新输入模型,让模型计算下一个文字的概率,这种方式叫做**自回归**。即用生成的文字递归地计算下一个文字。推理的结束标志是**结束字符**,也就是**eos_token**,遇到这个token表示生成结束了。
PyTorch框架
用于进行向量相乘、求导等操作的框架被称为深度学习框架。高维度的向量被称为张量(Tensor),后面我们也会用Tensor代指高维度向量或矩阵。
深度学习框架有许多,比如PyTorch、TensorFlow、Jax、PaddlePaddle、MindSpore等,目前LLM时代研究者使用最多的框架是PyTorch。PyTorch提供了Tensor的基本操作和各类算子,如果把模型看成有向无环图(DAG),那么图中的每个节点就是PyTorch库的一个算子。
安装PyTorch之前请安装python。在这里我们推荐使用conda(一个python包管理软件)来安装python:https://conda.io/projects/conda/en/latest/user-guide/install/index.html
conda配置好后,新建一个虚拟环境(一个独立的python包环境,所做的操作不会污染其它虚拟环境):
# 配置一个python3.9的虚拟环境
conda create -n py39 python==3.9
# 激活这个环境
conda activate py39
之后:
# 假设已经安装了python,没有安装 torch
pip install torch
打开python命令行:
python
import torch
# 两个tensor,可以累计梯度信息
a = torch.tensor([1.], requires_grad=True)
b = torch.tensor([2.], requires_grad=True)
c = a * b
# 计算梯度
c.backward()
print(a.grad, b.grad)
# tensor([2.]) tensor([1.])
可以看到,a的梯度是2.0,b的梯度是1.0,这是因为c对a的偏导数是b,对b的偏导数是a的缘故。backward方法非常重要,模型参数更新依赖的就是backward计算出来的梯度值。
torch.nn.Module基类:所有的模型结构都是该类的子类。一个完整的torch模型分为两部分,一部分是代码,用来描述模型结构:
import torch
from torch.nn import Linearclass SubModule(torch.nn.Module):def __init__(self):super().__init__()# 有时候会传入一个config,下面的Linear就变成:# self.a = Linear(config.hidden_size, config.hidden_size)self.a = Linear(4, 4)class Module(torch.nn.Module):def __init__(self):super().__init__()self.sub =SubModule()module = Module()state_dict = module.state_dict() # 实际上是一个key value对# OrderedDict([('sub.a.weight', tensor([[-0.4148, -0.2303, -0.3650, -0.4019],
# [-0.2495, 0.1113, 0.3846, 0.3645],
# [ 0.0395, -0.0490, -0.1738, 0.0820],
# [ 0.4187, 0.4697, -0.4100, -0.4685]])), ('sub.a.bias', tensor([ 0.4756, -0.4298, -0.4380, 0.3344]))])# 如果我想把SubModule替换为别的结构能不能做呢?
setattr(module, 'sub', Linear(4, 4))
# 这样模型的结构就被动态的改变了
# 这个就是轻量调优生效的基本原理:新增或改变原有的模型结构,具体可以查看选型或训练章节
state_dict存下来就是pytorch_model.bin,也就是存在于modelhub中的文件
config.json:用于描述模型结构的信息,如上面的Linear的尺寸(4, 4)
tokenizer.json: tokenizer的参数信息
vocab.txt: nlp模型和多模态模型特有,描述词表(字典)信息。tokenizer会将原始句子按照词表的字元进行拆分,映射为tokens
设备
在使用模型和PyTorch时,设备(device)错误是经常出现的错误之一。
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0!
tensor和tensor的操作(比如相乘、相加等)只能在两个tensor在同一个设备上才能进行。要不然tensor都被存放在同一个显卡上,要不然都放在cpu上。一般最常见的错误就是模型的输入tensor还在cpu上,而模型本身已经被放在了显卡上。PyTorch驱动N系列显卡进行tensor操作的计算框架是cuda,因此可以非常方便地把模型和tensor放在显卡上:
from modelscope import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-1_8B-Chat", trust_remote_code=True)
model.to(0)
# model.to('cuda:0') 同样也可以
a = torch.tensor([1.])
a = a.to(0)
# 注意!model.to操作不需要承接返回值,这是因为torch.nn.Module(模型基类)的这个操作是in-place(替换)的
# 而tensor的操作不是in-place的,需要承接返回值
PyTorch基本训练代码范例
import os
import randomimport numpy as np
import torch
from torch.optim import AdamW
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.dataloader import default_collate
from torch.nn import CrossEntropyLossseed = 42
# 随机种子,影响训练的随机数逻辑,如果随机种子确定,每次训练的结果是一样的
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)# 确定化cuda、cublas、cudnn的底层随机逻辑
# 否则CUDA会提前优化一些算子,产生不确定性
# 这些处理在训练时也可以不使用
os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":16:8"
torch.use_deterministic_algorithms(True)
# Enable CUDNN deterministic mode
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False# torch模型都继承于torch.nn.Module
class MyModule(torch.nn.Module):def __init__(self, n_classes=2):# 优先调用基类构造super().__init__()# 单个神经元,一个linear加上一个relu激活self.linear = torch.nn.Linear(16, n_classes)self.relu = torch.nn.ReLU()def forward(self, tensor, label):# 前向过程output = {'logits': self.relu(self.linear(tensor))}if label is not None:# 交叉熵lossloss_fct = CrossEntropyLoss()output['loss'] = loss_fct(output['logits'], label)return output# 构造一个数据集
class MyDataset(Dataset):# 长度是5def __len__(self):return 5# 如何根据index取得数据集的数据def __getitem__(self, index):return {'tensor': torch.rand(16), 'label': torch.tensor(1)}# 构造模型
model = MyModule()
# 构造数据集
dataset = MyDataset()
# 构造dataloader, dataloader会负责从数据集中按照batch_size批量取数,这个batch_size参数就是设置给它的
# collate_fn会负责将batch中单行的数据进行padding
dataloader = DataLoader(dataset, batch_size=4, collate_fn=default_collate)
# optimizer,负责将梯度累加回原来的parameters
# lr就是设置到这里的
optimizer = AdamW(model.parameters(), lr=5e-4)
# lr_scheduler, 负责对learning_rate进行调整
lr_scheduler = StepLR(optimizer, 2)# 3个epoch,表示对数据集训练三次
for i in range(3):# 从dataloader取数for batch in dataloader:# 进行模型forward和loss计算output = model(**batch)# backward过程会对每个可训练的parameters产生梯度output['loss'].backward()# 建议此时看下model中linear的grad值# 也就是model.linear.weight.grad# 将梯度累加回parametersoptimizer.step()# 清理使用完的gradoptimizer.zero_grad()# 调整lrlr_scheduler.step()
相关文章:

【LLM入门系列】01 深度学习入门介绍
NLP Github 项目: NLP 项目实践:fasterai/nlp-project-practice 介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验 AI 藏经阁:https://gitee.com/fasterai/a…...

安卓系统主板_迷你安卓主板定制开发_联发科MTK安卓主板方案
安卓主板搭载联发科MT8766处理器,采用了四核Cortex-A53架构,高效能和低功耗设计。其在4G网络待机时的电流消耗仅为10-15mA/h,支持高达2.0GHz的主频。主板内置IMG GE832 GPU,运行Android 9.0系统,内存配置选项丰富&…...

关键点检测——HRNet原理详解篇
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、…...

25考研总结
11408确实难,25英一直接单科斩杀😭 对过去这一年多备考的经历进行复盘,以及考试期间出现的问题进行思考。 考408的人,政治英语都不能拖到最后,408会惩罚每一个偷懒的人! 政治 之所以把政治写在最开始&am…...

网络安全态势感知
一、网络安全态势感知(Cyber Situational Awareness)是一种通过收集、处理和分析网络数据来理解当前和预测未来网络安全状态的能力。它的目的是提供实时的、安全的网络全貌,帮助组织理解当前网络中发生的事情,评估风险,…...

在K8S中,节点状态notReady如何排查?
在kubernetes集群中,当一个节点(Node)的状态变为NotReady时,意味着该节点可能无法运行Pod或不能正确相应kubernetes控制平面。排查NotReady节点通常涉及以下步骤: 1. 获取基本信息 使用kubectl命令行工具获取节点状态…...

深度学习在光学成像中是如何发挥作用的?
深度学习在光学成像中的作用主要体现在以下几个方面: 1. **图像重建和去模糊**:深度学习可以通过优化图像重建算法来处理模糊图像或降噪,改善成像质量。这涉及到从低分辨率图像生成高分辨率图像,突破传统光学系统的分辨率限制。 …...

树莓派linux内核源码编译
Raspberry Pi 内核 托管在 GitHub 上;更新滞后于上游 Linux内核,Raspberry Pi 会将 Linux 内核的长期版本整合到 Raspberry Pi 内核中。 1 构建内核 操作系统随附的默认编译器和链接器被配置为构建在该操作系统上运行的可执行文件。原生编译使用这些默…...
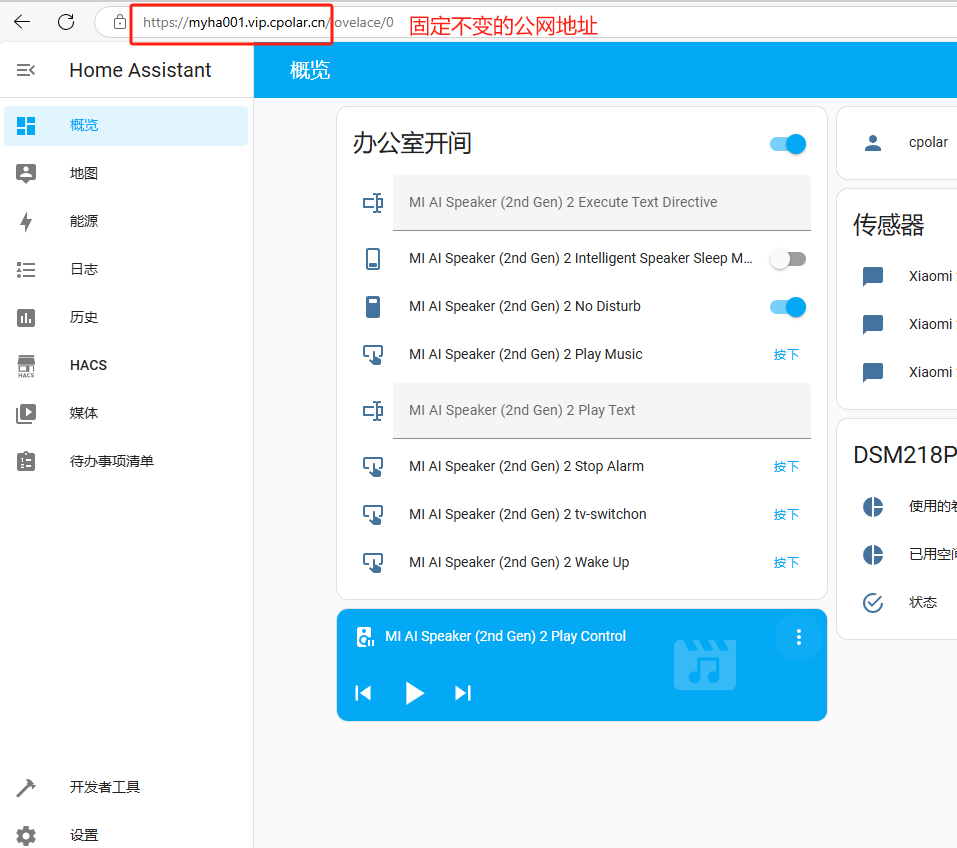
本地小主机安装HomeAssistant开源智能家居平台打造个人AI管家
文章目录 前言1. 添加镜像源2. 部署HomeAssistant3. HA系统初始化配置4. HA系统添加智能设备4.1 添加已发现的设备4.2 添加HACS插件安装设备 5. 安装cpolar内网穿透5.1 配置HA公网地址 6. 配置固定公网地址 前言 大家好!今天我要向大家展示如何将一台迷你的香橙派Z…...

SpringBoot返回文件让前端下载的几种方式
01 背景 在后端开发中,通常会有文件下载的需求,常用的解决方案有两种: 不通过后端应用,直接使用nginx直接转发文件地址下载(适用于一些公开的文件,因为这里不需要授权)通过后端进行下载&#…...

人工智能及深度学习的一些题目
1、一个含有2个隐藏层的多层感知机(MLP),神经元个数都为20,输入和输出节点分别由8和5个节点,这个网络有多少权重值? 答:在MLP中,权重是连接神经元的参数,每个连接都有一…...

15-利用dubbo远程服务调用
本文介绍利用apache dubbo调用远程服务的开发过程,其中利用zookeeper作为注册中心。关于zookeeper的环境搭建,可以参考我的另一篇博文:14-zookeeper环境搭建。 0、环境 jdk:1.8zookeeper:3.8.4dubbo:2.7.…...

【Rust自学】8.5. HashMap Pt.1:HashMap的定义、创建、合并与访问
8.5.0. 本章内容 第八章主要讲的是Rust中常见的集合。Rust中提供了很多集合类型的数据结构,这些集合可以包含很多值。但是第八章所讲的集合与数组和元组有所不同。 第八章中的集合是存储在堆内存上而非栈内存上的,这也意味着这些集合的数据大小无需在编…...

未来网络技术的新征程:5G、物联网与边缘计算(10/10)
一、5G 网络:引领未来通信新潮流 (一)5G 网络的特点 高速率:5G 依托良好技术架构,提供更高的网络速度,峰值要求不低于 20Gb/s,下载速度最高达 10Gbps。相比 4G 网络,5G 的基站速度…...

LLM(十二)| DeepSeek-V3 技术报告深度解读——开源模型的巅峰之作
近年来,大型语言模型(LLMs)的发展突飞猛进,逐步缩小了与通用人工智能(AGI)的差距。DeepSeek-AI 团队最新发布的 DeepSeek-V3,作为一款强大的混合专家模型(Mixture-of-Experts, MoE&a…...

Uniapp在浏览器拉起导航
Uniapp在浏览器拉起导航 最近涉及到要在浏览器中拉起导航,对目标点进行路线规划等功能,踩了一些坑,找到了使用方法。(浏览器拉起) 效果展示 可以拉起三大平台及苹果导航 点击选中某个导航,会携带经纬度跳转…...

公平联邦学习——多目标优化
前言 前段时间接触到了联邦学习(Federated Learning, FL)。涉猎了几年多目标优化的我,惊奇地发现横向联邦学习里面也有用多目标优化来做的。于是有感而发,特此写一篇博客记录记录,如有机会可以和大家多多交流。遇到不…...

奇怪的Python:为何字符串要设置成不可变的?
你好!我是老邓。今天我们来聊聊 Python 中字符串不可变这个话题。 1、问题简介: Python 中,字符串属于不可变对象。这意味着一旦字符串被创建,它的值就无法被修改。任何看似修改字符串的操作,实际上都是创建了一个新…...

Vue-Router之嵌套路由
在路由配置中,配置children import Vue from vue import VueRouter from vue-routerVue.use(VueRouter)const router new VueRouter({mode: history,base: import.meta.env.BASE_URL,routes: [{path: /,redirect: /home},{path: /home,name: home,component: () &…...

MyBatis使用的设计模式
目录 1. 工厂模式(Factory Pattern) 2. 单例模式(Singleton Pattern) 3. 代理模式(Proxy Pattern) 4. 装饰器模式(Decorator Pattern) 5. 观察者模式(Observer Patt…...

【审计领域-监督监管】【信息科学与工程学】【会计领域】第十三篇 云计算业务-财务-会计-审计-税务融合模03
云计算各层服务招投标围标串标审计模型详表(续30项:I-455至I-484) 编号 类型 财务/会计/审计领域 行业类型 产品/服务/其他的财务/会计/审计/税收类型 函数/算法/规则逐步推理思考的数学方程式表达级业务财务-会计-审计融合模型 时序方程式 参数列表及参数的数学特征…...

量子计算中SIMD编译优化与离子阱架构实践
1. 量子计算中的SIMD编译优化概述量子计算正逐步从理论走向实践,而离子阱架构因其长相干时间和高保真度操作成为当前最有前景的物理实现方案之一。在传统量子编译器中,指令调度往往采用串行执行模式,导致离子传输和量子门操作存在大量等待时间…...

共享内存概述
共享内存,就是在内存里开辟一块公共空间,多个进程可以同时映射到自己的虚拟地址空间,大家直接读写同一块物理内存。是 Linux 进程间通信 IPC 最快 的一种方式。1️⃣创建共享内存空间2️⃣映射到自己的进程3️⃣strcpy写数据4️⃣断开与共享内…...
)
NotebookLM智能摘要失效真相(92%用户正在误用的3类文档结构)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM智能摘要失效的底层归因 NotebookLM 的智能摘要功能在部分场景下出现静默失效(即无报错但输出空摘要或重复原文),其根本原因并非模型能力退化,…...

STC8H8K64U USB下载避坑指南:实测与手册不一样的P3.2引脚操作细节
STC8H8K64U USB下载实战:破解P3.2引脚的操作玄机 第一次接触STC8H8K64U的USB下载功能时,本以为按照官方手册按部就班就能轻松搞定,没想到实际操作中P3.2引脚的行为完全出乎意料。这个看似简单的接地操作背后,隐藏着芯片内部状态机…...

Windows Node.js版本管理实战:NVM-Windows配置与部署解决方案
Windows Node.js版本管理实战:NVM-Windows配置与部署解决方案 【免费下载链接】nvm-windows A node.js version management utility for Windows. Ironically written in Go. 项目地址: https://gitcode.com/gh_mirrors/nv/nvm-windows NVM-Windows是Windows…...

2026届必备的六大AI写作神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下,鉴于人工智能生成内容(AIGC)技术越来越普及&#x…...

TCA白皮书解读:腾讯内部CodeDog系统的演进历程
TCA白皮书解读:腾讯内部CodeDog系统的演进历程 【免费下载链接】CodeAnalysis Static Code Analysis - 静态代码分析 项目地址: https://gitcode.com/gh_mirrors/co/CodeAnalysis 腾讯云代码分析(TCA)作为一款强大的静态代码分析工具&…...
)
【小白适用】2026 最新 Win11 OpenClaw 一键安装步骤(包含安装包)
OpenClaw(小龙虾)Windows 11 一键部署教程|2026 最新版|零代码・免配置・解压即用 适用系统:Windows 11 专业版 / 家庭版 / 正式版(全版本兼容)项目介绍:OpenClaw 是 GitHub 星标 2…...

数控编程软件|PowerMill 2026全流程下载安装教程
相信大家不会感到陌生,PowerMill是一款功能强大且专业的计算机辅助制造(CAM)软件工具,专注于复杂零件的数控(CNC)加工编程,尤其适用于模具、航空航天、汽车制造等高精度、高复杂度…...