数据结构理论篇(期末突击)
找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程(ಥ_ಥ)-CSDN博客
所属专栏: 学校课程突击
下面均是为了应付学校考试所用,如果有涉及部分知识点下面未说明,可以去我的数据结构专栏看看或者自行在网上查阅资料。
以下所有知识均是阅读大话数据结构所得。如果有小伙伴对这本书也感兴趣,可以去看看。
通过百度网盘分享的文件:大话数据结构-目录版.rar
链接:https://pan.baidu.com/s/1ge7HSe00tvj1U1S2zWnA8w?pwd=2580
提取码:2580
目录
树与二叉树章节相关
树与二叉树的转换
森林与二叉树的转换
树与森林的遍历
赫夫曼树(哈夫曼树)
图章节相关
查找章节相关
数据结构的相关理解(记忆)
算法
树与二叉树章节相关
我们前面学习的树都是特殊的二叉树,且都是采用孩子双亲表示法,而下面要学习的二叉树采用的是 孩子兄弟表示法,第一个节点表示孩子,第二个节点表示当前节点的兄弟节点。
typedef struct Node {int val; // 节点的值struct Node *child; // 指向第一个子节点的指针struct Node *brother; // 指向下一个兄弟节点的指针
} TreeNode;
树与二叉树的转换
一般的树都不是只有两个分叉的,而是存在多个分叉,但我们要想办法将多个分叉的树转换为二叉树就需要用到下面的方法:
1、加线。在同一层的相邻兄弟节点之间加上一根线,将其相连。
2、去线。若某个节点存在多个子节点, 将除第一个子节点之外的所有子节点之间的线全部去掉。
3、调整层次。

上述就是树转换为二叉树的过程。
二叉树转换为树,就是树转换为二叉树的逆过程。
1、加线。若某个节点存在左子节点,且该子节点的右子节点不为空,则将父节点与该子节点的右子节点相连。
2、去线。将所有与右子节点的相连的线全部去掉。
3、调整层次。

森林与二叉树的转换
森林是由若干棵树组成的,所以完全可以理解为,森林中的每一棵树都是兄弟,可以按照兄弟的处理办法来操作。
1、先将森林中的每棵树都转为二叉树;
2、再以第一棵树作为基准,将后续的树全部使用。

上图转换为二叉树的过程。
二叉树转换为森林也是逆着来。但首先得判断这二叉树是转换成一棵树,还是森林。如果根结点存在右子树,那么这棵二叉树就可以转为森林;反之,则不能转为森林,就是直接转为树了。
1、先将森林分裂成多棵二叉树。将根结点与右子树之间的连线断开,继续从右子树为起点,重复上述步骤,直至右子树为空。
2、将分裂出的每棵子树,全部使用二叉树转换为树的方法去转换每棵树。

树与森林的遍历
树的遍历方式分为两种,一种是先根遍历树,即先访问树的根结点,然后依次先根遍历根的每棵子树。另一种是后根遍历,即先依次后根遍历每棵子树,然后再访问根结点。
树的先根遍历,就是二叉树的先序遍历,而树的后根遍历,就是二叉树的后序遍历。

如果直接看不出来的话,还有一种方法,将树先转为二叉树,然后再对二叉树进行相应的遍历即可。 将图中的树转为二叉树之后,再去遍历结果还是一样的。
森林的遍历也分为两种方式:一种是前序遍历:先访问森林中第一棵树的根结点,然后再依次先根遍历根的每棵子树,再依次用同样方式遍历除去第一棵树的剩余树构成的森林。
后序遍历:是先访问森林中第一棵树,后根遍历的方式遍历每棵子树,然后再访问根结点,再依次同样方式遍历除去第一棵树的剩余树构成的森林。
森林的前序遍历就是对每个树都进行先根遍历,同理后序遍历就是对每棵树都进行后序遍历。

同样如果直接看不出来的话,也可以先将森林转换为二叉树,然后再对二叉树进行先序遍历 与 中序遍历。这样得出的结果是一样的。 注意这里森林的后序遍历不是二叉树的后序遍历,而是中序遍历了。
注意:我们上面所说的树均不是二叉树,而是普通的树。只有当说是二叉树时,才表明这是二叉树。同样森林也不是由二叉树构成,而是由普通的树构成的。
赫夫曼树(哈夫曼树)
从树中一个结点到另一个结点之间的分支构成两个结点之间的路径,路径上的分支数目称做路径长度。树的路径长度就是从树根(根结点)到每一结点(叶子结点)的路径长度之和。针对带权路径来说,树的带权路径长度为树中所有叶子结点的带权路径长度之和。
假设有n个权值{W1,W2,...,Wn},构造一棵有n个叶子结点的二叉树,每个叶子结点带权Wk,每个叶子的路径长度为Ik,我们通常记作,则其中带权路径长度WPL最小的二叉树称做赫夫曼树。也被称为 哈夫曼树 与 最优二叉树。
考试中使用最多的就是去计算一棵树的带权路径长度。
那如何去构造一棵赫夫曼树呢?
1、将结点与权值绑定在一起。
2、找到结点权值最小的两个,连接在一起构造成一个新的结点(权值为两者之和)。
3、重复上述步骤,直至构造成一个完整的二叉树即可。
如下图所示:

注意:
1、将两个结点结合成一个新的结点时,下次再去找权值最小的两个结点就只能从结合的新结点与原来剩下的结点中去寻找。如果使用队列进行预处理的话,就是将队列中的两个权值最小的结点出队,然后再将结合的结点入队。
2、为了更好的处理,我们一般都会先将需要构造赫夫曼树的结点重新排序。上述图示只是为了更好的展示效果,实际的处理过程中,我们是使用优先级队列来处理的。
3、由于结点放置的左右顺序没有要求,因此最终所形成的赫夫曼树也是有不同的形状的,但是带权路径长度一定是最小的。
赫夫曼树构造出来之后,就可以求对应的加权路径长度,以及每个结点字符对应的赫夫曼编码了。
我们先来看赫夫曼树的加权路径长度(WPL)。其计算方法是将每个根结点到叶子结点的长度求出,然后乘上叶子结点的权值,最后将所有的结果相加就得到了WPL。

注意:为了做到不重不漏的计算出正确答案,我们最好是按照叶子结点从左到右的顺序来计算。
在学习赫夫曼编码之前,我们先来了解一下什么是编码?以及为什么需要编码?
编码是将数据从一种形式转换为另一种形式。例如,二进制编码就可以将不属于二进制的数据转换为属于二进制的数据。编码的作用主要是为了更好的传输与存储。这里的哈夫曼编码就是为了更好的传输。
在现实生活中,数据的传输都是先转换为二进制数据,然后通过光信号或者电信号发生出去,最后接收方再通过同样的方式将接受的光信号或者电信号转换为对应的二进制,最终在转换为相应的原始数据。

在上述情况下,便诞生了赫夫曼编码 与 赫夫曼树。赫夫曼编码既不会产生前缀不唯一的情况,也不会出现冗余。 赫夫曼编码是通过赫夫曼树得到的。这里的权值是每次字符出现的次数。我们还是拿最上面的那个赫夫曼树来举例。

其实现在我们再去看赫夫曼树的构造过程,使用权值最小的结点开始构造这样最终形成的编码也是最长的,但是权值小意味着出现的频率小,也就占用的编码长度短,因此采用赫夫曼树构造出来的树的带权路径长度一定是最短的。
注意:由于赫夫曼树的构造不止一种,因此对应字符的赫夫曼编码也是唯一的,但是带权路径长度一定是唯一且最短的。
除了上述构造赫夫曼树与对应的赫夫曼编码以及WPL之外,还常考的就是计算存储一段正文所需的二进制字节数(或者说存储这段正文所需的最小内存是多少)。
这种题目的思路是将对应字符出现的次数构造成一棵赫夫曼树,然后将对应字符的编码求出来,最后将编码长度乘以对应字符出现的次数整体求和就可以得到存储这段正文所需的内存,这里得到的是比特位的个数。

图章节相关
深度优先遍历 与 广度优先遍历的区别:
深度优先遍历的思想体现在"深",当遍历到一个新的顶点时,不会继续往当前路径去遍历,而是直接沿着新顶点的路径去遍历剩下的顶点了。
广度优先遍历的思想体现在"广",当遍历到一个新的顶点时,会将该顶点相邻的所有顶点都尝试去遍历一遍。
普利姆算法 与 克鲁斯卡尔算法的区别:
普利姆算法是需要确定一个顶点,从该顶点出发,寻找局部权值最小的边(与已知顶点相连的边),直至构成最小生成树。
克鲁斯卡尔算法是在图中所有的边中,选取一个权值最小的边,因此并不需要确定顶点出发。
顶点的度:
在有向图中,顶点的度包括了出度与入度,而在无向图中顶点的图只需要看出度或者入度即可。
关键路径:
概念:在项目网络图中,关键路径是从项目开始到结束的最长序列(边权值和最大)。这个路径上的任务总持续时间最长。
求关键路径一般就是求其的序列,而求关键路径长度时,才会去求具体的边权和。
关键活动是指关键路径上的顶点。
若一个有向无环图的关键路径有几条时,当要求加快进度缩短工期时,应如何才能做到?必须同时提高几条关键路径上的活动。
关键活动速度的提高在什么情况下才有效?在不改变关键路径路径的情况下才有效。
注意:关键路径只存在于有向无环图中。对于无向图或者有向成环图不存在这样的概念。
拓扑排序:
每次选入度为0的点,然后删除这个点和它的出边。接着继续在图中选择一个入度为0的点,并删除其出边,直至图中不存在点。
注意:拓扑排序只针对有向无环图才能生效,如果图中存在环,就不能使用拓扑排序或者说拓扑排序的结果不存在。

对上图进行拓扑排序:
1、选择入度为0的点: a;
2、删除a 与 其的出边(这里也可以认为是全部的边,因为其不存在入边);
3、从 b 与 c 中选择一个点即可,继续重复上述步骤。
最终拓扑排序的结果为(其中一种):a b c e d。
我们也可以看一下对于存在环的图是啥样的:

对上图进行拓扑排序:
1、选择入度为0的点: a;
2、删除a 与 其的出边(这里也可以认为是全部的边,因为其不存在入边);
3、c d e 都不满足入度为0的点,这个要求,因此没法继续拓扑排序了。
拓扑排序也常用来判断图中是否存在环。
查找章节相关
二叉搜索树:

1、求在等概率情况下的查找成功的平均查找长度:
查找成功的情况只能出现在树中有节点存在的情况才行,而查找本质上就是遍历整棵树。对于第一层的结点来说,查找一次即可,对于第二层的结点来说查找两次即可,依次类推,对于第n层的结点查找成功的次数是n。对于查找成功的平均查找长度就是将这棵树的结点全部查找所需的次数,然后除以节点的个数,就是最终的结果。
上面这棵树查找成功的平均查找长度:ASL = (1*1 + 2*2 + 3*4 + 4*2 + 5*1) / 10 = 3
2、求在等概率情况下的查找不成功的平均查找长度:
查找不成功就是指不是树中存在,那怎么知道不在树中存在呢?当查找到空节点时,就证明查找失败了。查找不成功的平均长度就是空节点的查找次数之和除以空节点的个数。注意的是,对于处于第n层的空节点来说,查找的次数是 n-1,而不是n。ASL = (6*3 + 3*4 + 2*5) / 11 = 3.64(约为)
二分查找:
对于有序表(12 ,18 , 24 , 35 , 47, 50, 62, 83, 90 ,115,134),在等概率的情况下:
1)请画出折半查找树(判定树);
2)求采用折半查找法时成功和不成功的平均查找长度。
3)当用折半查找法查找90时需要进行多少次查找可以确定成功?
4)查找100时需要进行多少次查找才能确定不成功?
1、对于 折半查找树画法,是根据二分查找(折半查找)的顺序来的。将二分查找取的数,作为当前子树的根结点。左区间就作为左子树,右区间就作为右子树。

2、查找成功与不成功的平均查找长度和前面的二叉搜索树是一样的做法,都是计算树中节点的查找的次数之和 除以 节点的个数。
ASL不成功 =(4*3 + 8*4)/ 12 = 3.67 ASL成功 =(1*1 + 2*2 + 4*3 + 4*4)/ 11 = 3
3、4:当我们画出折半查找树之后,就可以直接对照树来进行判断了。
90 是属于第二层,那么查找的次数就是2次。
100 是属于 第四层的空节点,查找的次数为3次。
哈希表:
设哈希(Hash)表的地址范围为0~17,哈希函数为:H(K)=K MOD 16。K为关键字,用线性探测法再散列法处理冲突,输入关键字序列:(10,24,32,17,31,30,46,47,40,63,49)造出Hash表,试回答下列问题:
- 画出哈希表的示意图;
- 若查找关键字63,需要依次与哪些关键字进行比较?
- 若查找关键字60,需要依次与哪些关键字比较?
- 假定每个关键字的查找概率相等,求查找成功时的平均查找长度。
1、画出哈希表:根据映射函数 + 线性探测法,将哈希表的图给画出来即可:

2、查找63,就是先通过哈希映射函数将对应的下标求出来,key = 15,先查找到31,不对;继续往后找:46 47 32 17 63,一共找了6次。
3、查找60,同样是通过哈希映射函数计算出下标,key = 12,查找到12的位置为空,就说明不存在这个元素,只需要比较一次。
4、计算平均查找长度就是将所有元素查找成功的次数之和 除以 元素的个数。哈希表中没有冲突的元素只需要查找一次,冲突的元素加上线性探测的次数即为最终的查找次数。
ASL= (6×1+2+3+3+3+6=6+2+3+3+3+6)/ 11 = 23 / 11 ≈ 2.09
数据结构的相关理解(记忆)
1、简述线性结构与非线性结构的不同点
答:线性结构反映结点间的逻辑关系是 一对一的,非线性结构反映结点间的逻辑关系是多对多的。
2、数据结构中讲述的结构主要有哪四种?这四种又分别属于哪二个大类?请分别给出这二类结构中你学了哪些结构?
答:
1)数据结构中的结构主要有以下四种:集合、线性表、树与图。
2)这四种又分别属于线性与非线二个大类,其中线性表属于线性结构,树与图属于非线性结构。
3)线性结构学了:线性表、栈、队列、串、数组
非线性结构学了:树、图
3、一般来说,一个问题往往有多种不同的算法,我们如何评价这些算法的好坏并能从中得到较好的算法呢?
答:评价一个算法的好坏主要从二个方面进行:一个方面是时间,这个主要用时间复杂度来度量;另一个方面是空间,这个主要用空间复杂度不度量;考虑一个算法的优劣主要是从时间复杂度方面来考虑。
4、数据结构中的存储结构主要有哪二种?它们分别通过什么来实现?他们各有什么特点与优缺点?
答:
1)数据结构中的存储结构主要有静态结构与动态结构
2)静态结构主要通过数组来实现,动态结构主要通过链表来实现;
3)静态结构的特点:逻辑上相邻的元素在存储上一定相邻;动态结构的特点:逻辑上相邻的元素在存储上不一定相邻
4)静态结构的优点:能随机访问,缺点是:插入删除要移动大量的元素;动态结构的优点:插入删除不需要移动元素,缺点是:不能随机访问元素
算法
// 一、使用C语言对链表进行排序
// 1、结构体的定义
typedef struct ListNode {int data;struct ListNode *next;
} ListNode, *List;// 2、排序的主逻辑
void sort(List L) {// 如果链表为空,或者只有一个结点则无需排序if (L == NULL || L->next == NULL) {return;}ListNode *p, *q;// 外层循环for (p = L->next; p != NULL; p = p->next) {// 内层循环for (q = p->next; q != NULL; q = q->next) {// 如果数据较大,交换数据if (p->data > q->data) {int tmp = p->data;p->data = q->data;q->data = tmp;}}}
}// 2、将两个集合合并
typedef struct list {ElemType *elem; // 集合元素int length; // 有效元素个数int listsize; // 集合的大小
}sqList// 将 la 和 lb 线性表归并到 la
void mergelist_sq(sqlist &la, sqlist lb) {ElemType *pa, *pb, *pc, *pa_last, *pb_last;pa = la.elem;pb = lb.elem;pa_last = la.elem + la.length - 1;pb_last = lb.elem + lb.length - 1;// 合并后的表从 la 的末尾开始插入pc = pa_last + 1;// 归并 lb 到 lawhile (pb <= pb_last) {pa = la.elem;// 在 la 中查找是否有与 pb 相等的元素while (pa <= pa_last) {if (*pa == *pb) {break;}pa++;}// 如果 la 中没有相等的元素,则将 pb 插入 laif (pa > pa_last) {*pc++ = *pb;la.length++;}pb++;}
}注意:使用 Hoare法、 挖坑法 对同一组序列进行快速排序时,最终排序的结果是一样的,但是中间排序的结果可能会不一样。
若一组记录的排序码为(46, 79, 56, 38, 40, 84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为:()
A、 38, 40, 46, 56, 79, 84
B、 40, 38, 46, 79, 56, 84
C、 40, 38, 46, 56, 79, 84
D、 40, 38, 46, 84, 56, 79
1、Hoare法版:

2、挖坑法版:

上图题目的答案是C,采取的挖坑法。
好啦!本期 数据结构理论篇(期末突击) 的学习之旅 就到此结束啦!我们下一期再一起学习吧!
相关文章:
数据结构理论篇(期末突击)
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏: 学校课程突击 下面均是为了应付学校考试所用,如果有涉及部分知识点下面未说明,可以去我的数据结构专栏看看或者自行在…...

《一文读懂PyTorch核心模块:开启深度学习之旅》
《一文读懂PyTorch核心模块:开启深度学习之旅》 一、PyTorch 入门:深度学习的得力助手二、核心模块概览:构建深度学习大厦的基石三、torch:基础功能担当(一)张量操作:多维数组的神奇变换(二)自动微分:梯度求解的幕后英雄(三)设备管理:CPU 与 GPU 的高效调度四、to…...
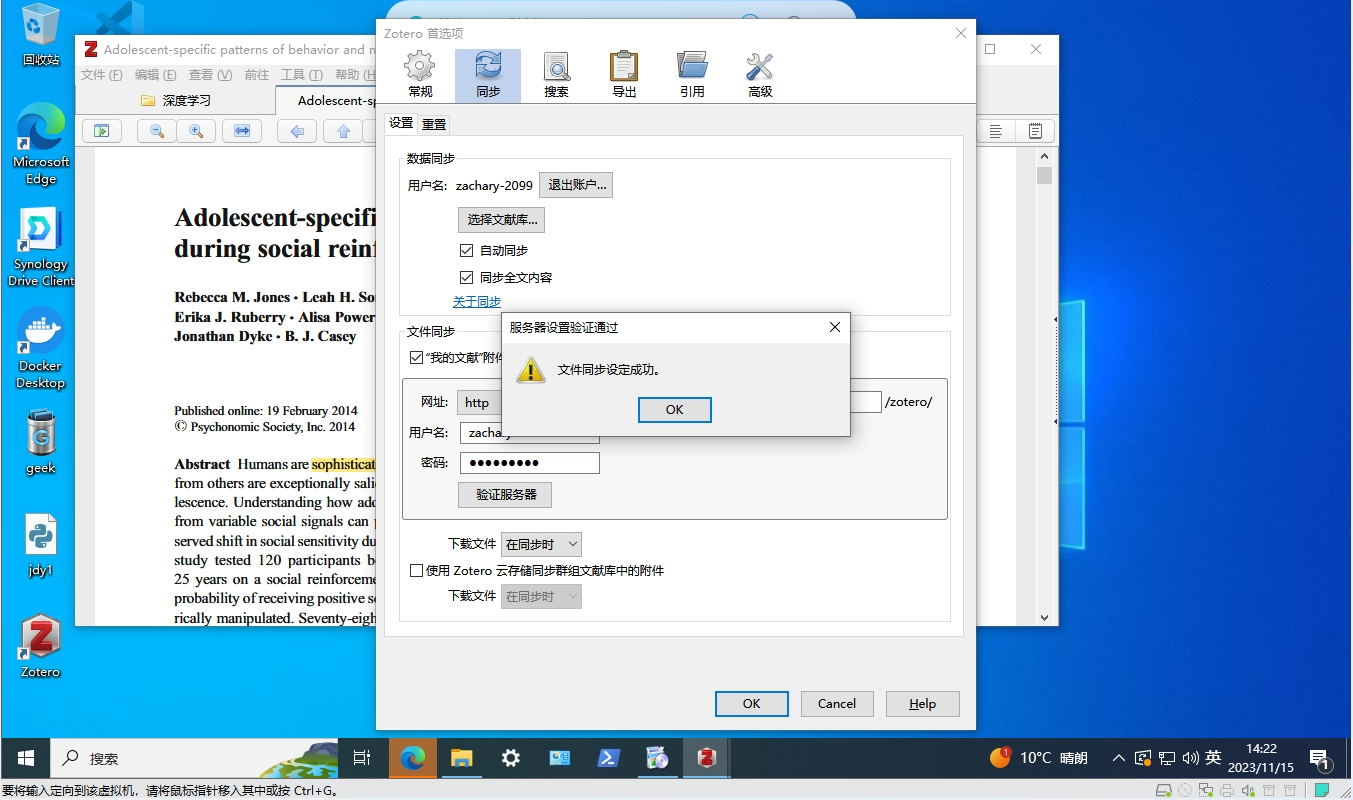
摆脱Zotero存储限制:WebDAV结合内网穿透打造个人文献管理云平台
文章目录 前言一、Zotero安装教程二、群晖NAS WebDAV设置三、Zotero设置四、使用公网地址同步Zotero文献库五、使用永久固定公网地址同步Zotero文献库 前言 如果你是科研工作者、学生或者任何需要频繁处理大量学术资料的人士,你一定对如何高效管理和引用文献感到头…...

Flutter封装一个三方ViewPager学习
Flutter如何实现一个增强的 PageView,支持自定义页面切换动画。 前置知识点学习 CrossAxisAlignment CrossAxisAlignment 是 Flutter 中用于控制布局子组件在交叉轴(cross axis)方向上的对齐方式的一个枚举类。它主要在 Flex 布局模型中使…...

服务器数据恢复—离线盘数超过热备盘数导致raidz阵列崩溃的数据恢复
服务器数据恢复环境&故障: 一台配有32块硬盘的服务器在运行过程中突然崩溃不可用。经过初步检测,基本上确定服务器硬件不存在物理故障。管理员重启服务器后问题依旧。需要恢复该服务器中的数据。 服务器数据恢复环境: 1、将服务器中硬盘…...

nginx-nginx的缓存集成
缓存的概念 缓存就是数据交换的缓冲区,被称作cache,访用户想要获取数据时,就会先从缓存中去查询数据,如果缓存中有就会直接返回给用户,若果缓存中没有,则会发出请求从服务器中重新查询数据,将数…...

【Vim Masterclass 笔记01】Section 1:Course Overview + Section 2:Vim Quickstart
文章目录 Section 1:Course Introduction 课程概述S01L01 Course Overview 课程简介课程概要 S01L02 Course Download 课程资源下载S01L03 What Vim Is and Why You Should Learn It 何为 Vim?学来干啥?1 何为 Vim2 为何学 Vim Section 2&…...

【数据库系列】Spring Boot 中使用 MyBatis 详细指南
一、基础介绍 1.1 MyBatis MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 P…...

Azure Airflow 中配置错误可能会使整个集群受到攻击
网络安全研究人员在 Microsoft 的 Azure 数据工厂 Apache Airflow 中发现了三个安全漏洞,如果成功利用这些漏洞,攻击者可能会获得执行各种隐蔽操作的能力,包括数据泄露和恶意软件部署。 “利用这些漏洞可能允许攻击者以影子管理员的身份获得…...

Python跨年烟花
目录 系列文章 写在前面 技术需求 完整代码 下载代码 代码分析 1. 程序初始化与显示设置 2. 烟花类 (Firework) 3. 粒子类 (Particle) 4. 痕迹类 (Trail) 5. 烟花更新与显示 6. 主函数 (fire) 7. 游戏循环 8. 总结 注意事项 写在后面 系列文章 序号直达链接爱…...
)
【代码】Python|Windows 批量尝试密码去打开加密的 Word 文档(docx和doc)
文章目录 前言完整代码Githubdocxdoc 代码解释1. msoffcrypto 方法(用于解密 .docx 文件)read_secret_word_file 函数密码生成与解密尝试try_decrypt_file 函数 2. comtypes 方法(用于解密 .doc 文件)read_secret_word_file 函数注…...

java开发中注解汇总
注解作用位置注意mybatis Data Getter Setter ToString EqualsAndHashCode AllArgsConstructor NoArgsConstructor Data 代替:无参构造,get,set,toString,hashCode,equals Getter Setter 可放在类和方法上&…...
:外观模式)
C# 设计模式(结构型模式):外观模式
C# 设计模式(结构型模式):外观模式 (Facade Pattern) 在复杂系统中,往往会涉及到多个子系统、模块和类。这些子系统的接口和功能可能会让使用者感到困惑和复杂。在这种情况下,我们可以使用外观模式(Facade…...

PowerShell 常见问题解答
PowerShell 是微软开发的一种功能强大的命令行界面和脚本语言,广泛应用于系统管理和自动化任务。以下是一些使用 PowerShell 时常见的问题及其解决方法。 什么是 PowerShell? PowerShell 是基于 .NET 的命令行界面(CLI)和脚本语言…...

计算机网络 (15)宽带接入技术
前言 计算机网络宽带接入技术是指通过高速、大容量的通信信道或网络,实现用户与互联网或其他通信网络之间的高速连接。 一、宽带接入技术的定义与特点 定义:宽带接入技术是指能够传输大量数据的通信信道或网络,其传输速度通常较高,…...
构建RESTful API:使用Flask和Django实现用户认证与授权)
前端Python应用指南(六)构建RESTful API:使用Flask和Django实现用户认证与授权
《写给前端的python应用指南》系列: (一)快速构建 Web 服务器 - Flask vs Node.js 对比(二)深入Flask:理解Flask的应用结构与模块化设计(三)Django vs Flask:哪种框架适…...

【Unity3D】基于UGUI——简易版 UI框架
https://github.com/AMikeW/BStandShaderResources/blob/master/milk_UIFramework.unitypackage UI框架支持如下功能: 1、层级控制 2、支持面板多次打开时,隐藏前一个打开的面板,当关闭面板时,能够恢复前一个打开面板状态 3、支…...

算法排序算法
文章目录 快速排序[leetcode 215数组中的第K个最大元素](https://leetcode.cn/problems/kth-largest-element-in-an-array/)分析题解快速排序 桶排序[leetcode 347 前K个高频元素](https://leetcode.cn/problems/top-k-frequent-elements/)分析题解 快速排序 leetcode 215数组…...

第3章 总线
总线的定义 为多个部件 分时共享 公共信息传送线路。 系统之间、模块之间、芯片内部用来传递信息信号线集合。 共享 总线上可连接多个部件 各部件间相互交换信息 都可通过总线来。 分时 同一时刻 总线上只能传 一个部件信息。 采用标准总线的优点 简化系统软硬件设计 从硬件角度…...

手机实时提取SIM卡打电话的信令声音-双卡手机来电如何获取哪一个卡的来电
手机实时提取SIM卡打电话的信令声音 --双卡手机来电如何获取哪一个卡的来电 一、前言 前面的篇章《手机实时提取SIM卡打电话的信令声音-智能拨号器的双SIM卡切换方案》中,我们论述了局域网SIP坐席通过手机外呼出去时,手机中主副卡的呼叫调度策略。 但…...

Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案
Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏内置分辨率选项太少而烦恼?是否想在窗口模式下获得全屏游戏…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

DriveBench:面向真实驾驶场景的长序列多智能体交互基准测试框架
1. 项目概述:从“世界基准”到“驾驶基准”的演进如果你在自动驾驶或者计算机视觉领域摸爬滚打过几年,一定对“基准测试”(Benchmark)这个词又爱又恨。爱的是,它提供了一个相对公平的擂台,让不同算法、不同…...

Claude API企业准入最后窗口期:2024Q3起强制启用OAuth 2.1+硬件级密钥绑定,现在不升级将无法续签
更多请点击: https://intelliparadigm.com 第一章:Claude API企业准入政策的演进与合规紧迫性 随着Anthropic对Claude模型商用边界的持续收束,企业级API接入正从“技术可用性”转向“治理可验证性”。2024年Q2起,所有新注册企业账…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

Blitz.js全栈开发框架:零API理念与Next.js深度集成实战
1. 项目概述:一个颠覆性的全栈开发框架如果你和我一样,在过去的几年里,一直在React生态圈里打转,从Create React App到Next.js,再到尝试自己搭建一套包含身份验证、数据层、API路由的完整应用,那你一定对那…...

基于 Next.js 的无头电商架构实战:从 Vercel Commerce 看现代全栈开发
1. 项目概述:一个面向未来的全栈电商起点如果你最近在琢磨着用 Next.js 搞一个电商网站,或者想找一个现代、开箱即用的全栈电商模板来启动项目,那你大概率已经听说过vercel/commerce这个仓库了。它不是某个具体的电商平台,而是一个…...

去中心化AI市场BloomBee:技术架构、挑战与开发者实践指南
1. 项目概述:当AI遇见去中心化,BloomBee想解决什么?最近在AI和Web3的交叉领域,一个名为BloomBee的项目引起了我的注意。它的名字很有意思,“Bloom”是开花、繁荣的意思,“Bee”是蜜蜂,合起来像是…...

CircuitPython嵌入式游戏开发:基于TileGrid的迷宫寻蛋与JSON数据持久化实践
1. 项目概述与核心价值如果你和我一样,对嵌入式开发充满热情,同时又对游戏开发抱有好奇心,那么将两者结合——在微控制器上编写一个完整的2D游戏——绝对是一次令人兴奋的挑战。这不仅仅是让LED闪烁或读取传感器数据,而是要在资源…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...