MotionCtrl: A Unified and Flexible Motion Controller for Video Generation 论文解读
目录
一、概述
二、相关工作
三、前置知识
1、LVDM Introduction
2、LVDM Method
3、LVDM for Short Video Generation
4、Hierarchical LVDM for Long Video Generation
5、训练细节
6、推理过程
四、MotionCtrl
1、CMCM
2、OMCM
3、训练策略
五、实验
一、概述

MotionCtrl是一个统一和灵活的视频生成运动控制器可以独立控制相机运动和物体运动,解决了以往方法中要么只关注一种类型的运动,要么无法区分两者之间的差异性。
以往的视频中的运动控制,如AnimateDiff、Gen-2、PikaLab主要通过独立的LoRA,或者引入额外的相机参数来触发相机运动控制。VideoComposer和DragNUWA补充了相机运动和物体运动两部分,但是缺乏明确的区别,无法实现精细多样化的运动控制。
而MotionCtrl提供了三个优势:
(1)它可以有效且独立地控制相机和物体运动,实现细粒度调整和多样化的运动组合
(2)它使用相机姿态和轨迹作为运动条件,这不会影响物体的视觉外观
(3)它是一个相对通用的模型,可以适应各种相机姿态和轨迹,无需进一步微调
精确的相机运动和物体运动控制存在两个问题:一考虑相机运动和物体运动的明显差异,由于相机运动和物体运动存在明显区别,相机运动是指整个场景在时间维度均进行全局变换,而物体运动涉及场景中特定对象在时间维度的移动,通常表示为物体相关的一组像素的轨迹。二由于现有数据集没有完整注释的视频片段,caption,相机姿态,物体运动轨迹。所以需要创建一个全面的数据集。
是否可以先segment每一个物体,并对这一部分像素进行物体运动计算,在叠加到全局的运动轨迹上。
二、相关工作
早期视频生成主要依赖GANs和VAEs,近期基本转变为扩散模型,或者依赖于已训练好的扩散模型。
近期的可控视频生成领域,有一些方法参考特定模版学习运动,但受模版限制,另外通过引入额外的运动矢量来进行运动控制,以及通过基于初始图像和文本提示来生成视频,但不能精确分离相机运动和物体运动控制。
三、前置知识
1、LVDM Introduction
LVDM应该是继VDM扩散模型第一次引入视频生成领域后,再次将隐式扩散模型引入视频生成,在此之前都是GANs的天下。
LVDM通过提出视频潜在空间中操作的分层框架,可以使得模型生成超出训练长度的更长的视频,并且在短视频和长视频生成中领先当时的VDM和一众GANs模型,后续也应用到VideoCrafter和MotionCtrl模型中。
2、LVDM Method
首先这个模型中可以分别实现无条件视频生成和有条件视频生成。
训练AE过程:
首先使用一个轻量级的3D AutoEncoder来压缩视频,包括encoder和decoder,他们都是有多层3D 卷积构成。输入一段视频,先经过视频encoder得到潜在空间
,其中
,
是空间和时间下采样因子。解码器
用于解码样本,(技术细节,为了确保自编码器是时间上等变的,所以所有3D 卷积都保证重复填充)。
在训练过程中,单独训练AE模块,利用重建损失(MSE+LPIPS)和对抗性损失(消除像素级重建损失模糊)计算。

3、LVDM for Short Video Generation
对于短视频的生成,就是类似VDM的结构。经过encoder后,特征不断加噪,并引入3Dunet中,然后最后一层进decoder。

4、Hierarchical LVDM for Long Video Generation
上述框架用来生成短视频,长度受到训练所指定的frame决定,所以提出了一个分层的条件LVDM,通过自回归方式,依赖前一个token来生成下一个token,通过输入短视频,得到插帧的长视频。
首先在通道维度添加了一个二进制掩码,来指定他是条件帧还是预测帧,也就是输入的短视频帧,还是预测的高斯噪音帧,并通过随机将不同二进制掩码设置为1或0,此时就得到不同的,这样可以训练扩散模型为无条件视频生成和有条件的视频预测。
在这里要解释什么是条件帧,在论文中使用任意时间s,s是扩散时间步t内的一小部分时间,在训练中作为条件,经过s时间的加噪后得到
,并与
根据掩码m进行加权,之后得到的特征输入到3D U-Net来计算噪声。
具体来说,将二进制掩码m全都设置为0,那么覆盖在条件上就是无条件的扩散模型训练,当输入条件帧k帧,预测后面n-k帧,那么就是通过条件帧预测后面的帧,防止提前知道后面的帧。
最后计算输入的与预测的
的MSE Loss。
分层LVDM的结构图如下,上面的解释应该都是Prediction 3D U-Net的解释。

对于Interpolation 3D U-Net来说,改变是mask sampling部分,插值模型在每两个稀疏帧之间的中间帧将二进制掩码设置为0。
5、训练细节
我们分别使用8和4的空间和时间下采样因子。我们首先训练一个3D AE,然后固定其权重,然后开始在短视频片段上训练无条件LVDM。之后,从无条件模型中分别微调Prediction 3D U-Net和Interpolation 3D U-Net。
6、推理过程
首先输入条件利用短视频模型部分,得到短视频片段,之后再利用分层长视频模型部分,经过短视频加噪多轮丢入Prediction 3D U-Net,之后再将潜在空间丢入 Interpolation 3D U-Net,得到连续的潜在空间信息,最后接VideoDecoder输出连续视频帧。
四、MotionCtrl
MotionCtrl框架扩展了LVDM中的去噪U-Net结构,并加入了相机运动控制模块CMCM和物体运动控制模块OMCM。其中CMCM模块通过将RT连接到Temporal Transformer部分的第二个自注意力机制(Temporal Transformer部分由两个自注意力模块构成),也就是Temporal Transformer部分的输入,并应用定制的轻量级全连接层来提取LVDM的相机姿态序列进行后续处理,OMCMC利用卷积层和降采样从Trajs中获得多尺度特征,并在空间通道上整合到LVDM的卷积层中,来指导物体的运动。
另外直接给定一个文本提示,经过CLIP后转变为视频的5通道格式,引导LVDM从提示相对应的噪声中生成视频,这样相机姿态控制的RT引入时间层,控制相机移动,物体的运动由Trajs控制,引入卷积层。下图(a)中马沿着设定的轨迹移动,背景向着相机移动的反方向(向左)移动。

1、CMCM
CMCM(Camera Motion Control Module)相机运动控制模块。首先取一组相机姿态,其中由于旋转矩阵3*3,平移矩阵3*1,所以flatten后总维度就是3*3+3*1=12维,这也就是
。
另外U-Net每一个时间模块的第一个自注意力机制的输出就是,之后看上面(b)图CMCM解释,经过rearrange+concat,然后接FC+Att2,得到输出。
2、OMCM
OMCM(Object Motion Control Module)对象运动控制模块。
轨迹解释:通过Trajs轨迹来控制生成的视频的物体运动,一般来说一个轨迹表示为一系列空间位置的序列,其中而
,表示x和y在轨迹图的尺寸范围内。另外为了表示速度,引入了u和v来表示两个方向的速度,因为帧与帧之间的时间固定,所以速度就表示为位移/帧时间,
。
![]()
对于OMCM模块的解释:由多个卷积+降采样组成,并将这里面的特征输入到U-Net下采样层,以平衡生成视频的量化和物体运动控制能力。
3、训练策略
为了通过文本提示生成视频时实现相机和物体运动的控制,训练数据集需要字幕、相机姿态、物体运动轨迹等。目前没有这么完整的数据集,所以引入了一种多步骤的训练策略。
训练CMCM模块,只需要一个包含字幕和相机姿态标注的视频片段的训练数据集。采用了Realestate10K数据集,但存在场景多样性有限和缺乏字幕的问题。
解决方法:
(1)采用了CMCM模块,冻结LVDM的大部分参数,但保留temporal transformer的第二个自注意力模块可训练,来保证原有LVDM的生成质量。由于temporal transformer主要集中于全局运动的学习,所以Realestate10K发散性小,不会影响LVDM的生成质量。

(2)对于字幕的问题,利用Blip2,为Realestate10K数据集生成字幕。
训练OMCM模块,需要一个包含字幕和物体运动轨迹的视频剪辑数据集,但暂无有效的开源数据集。所以利用ParicleSfM来合成WebVid数据集中的物体运动轨迹,WebVid是一个配有字幕的大型视频数据集,用于T2V工作。ParicleSfM包含一个基于轨迹的运动分割模块,可以用于过滤出动态场景中影响相机轨迹产生的动态轨迹,利用这一模块合成了大约24.3w个视频运动物体轨迹。
由于这个轨迹比较密集,所以做了后处理,随机采样(稀疏化)+高斯滤波(避免稀疏轨迹分散而无法有效训练)

在OMCM训练过程中,LVDM和CMCM都提前进行了训练,并且冻结,之后训练OMCM。
五、实验
该模块训练在16帧的序列,分辨率为256*256,模型建立在LVDM或者VideoCrafter1框架上。
在模型评估过程中,对简单的轨迹(放大、缩小、平移、顺时针、逆时针)和复杂轨迹都进行了评估。

另外对于相机运动轨迹部分,在复杂动作下(上图b),如果采用VideoComposer提取运动矢量模拟参考视频的相机运动,密集的运动矢量将无意间捕捉到物体的形状,比如训练数据集中Frame12中门的轮廓(b图一行第五个)会导致VideoComposer的埃菲尔铁塔生成出现几何错误(b图二行第五个),而MotionCtrl通过旋转平移矩阵引导,运动轨迹更加接近参考视频。
评估指标:FID(视觉质量)、FVD(时间一致性)、CLIPsim (与文本的语义相似度),CamMC(预测相机轨迹与GT之间的欧氏距离),ObjMC(预测目标轨迹与GT之间的欧氏距离)
AnimateDiff、VideoCompose、MotionCtrl的量化比较。

给定轨迹下的比较,VideoComposer还是存在偏差。(第四帧)

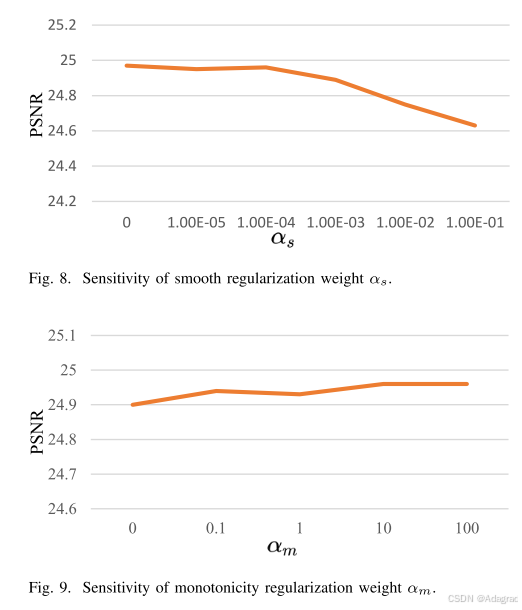
在OMCM下对于是否采用密集轨迹、还是直接采用稀疏轨迹,或者密集轨迹下采样稀疏轨迹的比较。

对于目标如果出现多个的情况,也可以通过多个目标轨迹处理。

参考项目:MotionCtrl
相关文章:
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation 论文解读
目录 一、概述 二、相关工作 三、前置知识 1、LVDM Introduction 2、LVDM Method 3、LVDM for Short Video Generation 4、Hierarchical LVDM for Long Video Generation 5、训练细节 6、推理过程 四、MotionCtrl 1、CMCM 2、OMCM 3、训练策略 五、实验 一、概述…...

LINUX线程操作
文章目录 线程的定义LINUX中的线程模型一对一模型多对一模型多对多模型 线程实现原理线程的状态新建状态(New)就绪状态(Runnable)运行状态(Running)阻塞状态(Blocked)死亡状态&#…...

在Lua中,Metatable元表如何操作?
Lua中的Metatable(元表)是一个强大的特性,它允许我们改变表(table)的行为。下面是对Lua中的Metatable元表的详细介绍,包括语法规则和示例。 1.Metatable介绍 Metatable是一个普通的Lua表,它用于…...
4D LUT: Learnable Context-Aware 4D LookupTable for Image Enhancement
摘要:图像增强旨在通过修饰色彩和色调来提高照片的审美视觉质量,是专业数码摄影的必备技术。 近年来,基于深度学习的图像增强算法取得了可喜的性能并越来越受欢迎。 然而,典型的努力尝试为所有像素的颜色转换构建统一的增强器。 它…...
)
瑞芯微rk3568平台 openwrt系统适配ffmpeg硬件解码(rkmpp)
瑞芯微rk3568平台 openwrt系统适配ffmpeg硬件解码(rkmpp) RK3568及rkmpp介绍编译安装mpp获取源码交叉编译安装 libdrmlibdrm-2.4.89 make 方式编译(cannot find -lcairo, 不推荐)下载源码编译编译错误: multiple definition of `nouveau debug‘错误cannot find -lcairo:…...
使用SuperMap制作地形图的详细教程
一、数据准备 本示例以山东为例,演示如何通过SuperMap iDesktopX制作一个好看的地形图。所有数据均来源于互联网公开数据,如有自己项目真实数据,可直接跳过数据下载进入下一步。 本示例所需数据包括: 数据类别 数据类型 DEM数据…...

PHP Array:精通数组操作
PHP Array:精通数组操作 PHP,作为一门流行的服务器端编程语言,提供了强大的数组处理能力。数组是PHP中非常灵活和强大的数据结构,它可以存储多个相同类型的值。在PHP中,数组不仅可以存储数字,还可以存储字…...

【使用命令配置java环境变量永久生效与脚本切换jdk版本】
java配置环境变量命令与脚本切换jdk版本 新建用户环境变量永久生效 setx JAVA8_HOME "D:\Java\jdk8" setx JAVA17_HOME "d:\Java\jdk-17" setx JAVA_HOME %JAVA8_HOME% setx CLASSPATH ".;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;"…...

STM32-笔记32-ESP8266作为服务端
esp8266作为服务器的时候,这时候网络助手以客户端的模式连接到esp8266,其中IP地址写的是esp8266作为服务器时的IP地址,可以使用ATCIFSR查询esp8266的ip地址,端口号默认写333。 当esp8266作为服务器的时候,需要完成哪些…...

RAG(Retrieval-Augmented Generation,检索增强生成)流程
目录 一、知识文档的准备二、OCR转换三、分词处理四、创建向量数据库五、初始化语言聊天模型1.prompt2.检索链3.对话 完整代码 知识文档的准备:首先需要准备知识文档,这些文档可以是多种格式,如Word、TXT、PDF等。使用文档加载器或多模态模型…...

【Python学习(六)——While、for、循环控制、指数爆炸】
Python学习(六)——While、for、循环控制、指数爆炸 本文介绍了While、for、循环控制、指数爆炸,仅作为本人学习时记录,感兴趣的初学者可以一起看看,欢迎评论区讨论,一起加油鸭~~~ 心中默念:Py…...

解释一下:运放的输入失调电流
输入失调电流 首先看基础部分:这就是同相比例放大器 按照理论计算,输入VIN=0时,输出VOUT应为0,对吧 仿真与理论差距较大,有200多毫伏的偏差,这就是输入偏置电流IBIAS引起的,接着看它的定义 同向和反向输入电流的平均值,也就是Ib1、Ib2求平均,即(Ib1+Ib2)/2 按照下面…...

力扣hot100——二分查找
35. 搜索插入位置 class Solution { public:int searchInsert(vector<int>& a, int x) {if (a[0] > x) return 0;int l 0, r a.size() - 1;while (l < r) {int mid (l r 1) / 2;if (a[mid] < x) l mid;else r mid - 1;}if (a[l] x) return l;else …...

PHP 使用集合 处理复杂数据 提升开发效率
在 PHP 中,集合(Collections)通常是通过数组或专门的集合类来实现的。 集合(Collection)是一种高级的数据结构,可以提供比普通数组更强大的操作和功能,特别是当你需要更复杂的数据处理时。 La…...

Unity 对Sprite或者UI使用模板测试扣洞
新建两个材质球: 选择如下材质 设置如下参数: 扣洞图片或者扣洞UI的材质球 Sprite或者UI的材质球 新建一个单独Hole的canvas,将SortOrder设置为0,并将原UI的canvans的SortOrder设置为1 对2DSprite则需要调整下方的参数 hole的O…...

unity学习3:如何从github下载开源的unity项目
目录 1 网上别人提供的一些github的unity项目 2 如何下载github上的开源项目呢? 2.1.0 下载工具 2.1.1 下载方法1 2.1.2 下载方法2(适合内部项目) 2.1.3 第1个项目 和第4项目 的比较 第1个项目 第2个项目 第3个项目 2.1.4 下载方法…...

PHP后执行php.exe -v命令报错并给出解决方案
文章目录 一、执行php.exe -v命令报错解决方案 一、执行php.exe -v命令报错 -PHP Warning: ‘C:\windows\SYSTEM32\VCRUNTIME140.dll’ 14.38 is not compatible with this PHP build linked with 14.41 in Unknown on line 0 解决方案 当使用PHP8.4.1时遇到VCRUNTIME140.dll…...

CDP集群安全指南-动态数据加密
[〇]关于本文 集群的动态数据加密主要指的是加密通过网络协议传输的数据,防止数据在传输的过程中被窃取。由于大数据涉及的主机及服务众多。你需要更具集群的实际环境来评估需要为哪些环节实施动态加密。 这里介绍一种通过Cloudera Manager 的Auto-TLS功能来为整个…...
)
【shell编程】报错信息:Undefined Variable(包含6种解决方法)
大家好,我是摇光~ 当Shell脚本报错“Undefined Variable”时,是未定义变量的意思。 以下是对每个可能原因及其对应详细解决方案的详细解释: 原因1:拼写错误 原因: 脚本中变量名的拼写在使用和定义时不一致。例如&…...

Dubbo扩展点加载机制
加载机制中已经存在的一些关键注解,如SPI、©Adaptive> ©Activateo然后介绍整个加载机制中最核心的ExtensionLoader的工作流程及实现原理。最后介绍扩展中使用的类动态编译的实 现原理。 Java SPI Java 5 中的服务提供商https://docs.oracle.com/jav…...

WaveTools实战:鸣潮性能优化的5个技术秘诀
WaveTools实战:鸣潮性能优化的5个技术秘诀 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 问题定位:帧率异常的底层原因分析 作为《鸣潮》玩家,你是否遇到过这样的困扰…...

Kandinsky-5.0-I2V-Lite-5s技术解析:如何在24GB显存跑通完整图生视频栈
Kandinsky-5.0-I2V-Lite-5s技术解析:如何在24GB显存跑通完整图生视频栈 1. 开箱即用的轻量级图生视频方案 Kandinsky-5.0-I2V-Lite-5s是一款让静态图片动起来的AI工具。想象一下,你只需要上传一张照片,再简单描述想要的动态效果,…...

MODSERIAL:嵌入式UART高可靠缓冲与事件驱动库
1. MODSERIAL:面向嵌入式实时系统的高可靠性串行通信缓冲库MODSERIAL 是一个专为 ARM Cortex-M 系列微控制器(尤其是基于 mbed OS 和 STM32 HAL 生态)设计的轻量级、中断安全、线程安全的串行通信增强库。其核心目标并非替代标准 HAL_UART 或…...

【电气数据】电力网络充电站定价策略数据集
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

第三章、CLion+GCC+OpenOCD构建STM32标准库开发环境:从零到调试的完整实践
1. 环境准备与工具链安装 搭建STM32标准库开发环境的第一步,就是准备好所有必要的工具。这里我们需要三个核心组件:CLion作为集成开发环境、arm-none-eabi-gcc作为编译器、OpenOCD作为调试器。这三个工具的组合,可以让我们在Windows平台上获得…...

零基础玩转Qwen2.5-7B-Instruct:Streamlit可视化界面一键启动
零基础玩转Qwen2.5-7B-Instruct:Streamlit可视化界面一键启动 1. 项目概览 Qwen2.5-7B-Instruct是阿里通义千问推出的旗舰级大语言模型,拥有70亿参数规模,在逻辑推理、长文本创作、代码生成等专业场景展现出远超轻量模型的性能。本项目基于…...

我是如何突然把论文‘AI率’从85%降到6%?这6大保姆级教程,秒懂!
AI如今已成为大部分同学论文“提速神器”,但是不合规过度使用AI往往会导致论文AI率超标。如果你还在写初稿,一定要合理利用AI,让AI来搭建初稿框架,寻找灵感,整理数据,切勿过度使用AI。 今年知网,…...
)
从零理解自然数系统:用Python类模拟皮亚诺公理(含加法乘法实现)
从零构建自然数系统:用Python类实现皮亚诺公理与算术运算 在计算机科学中,自然数系统的构建是一个令人着迷的基础课题。当我们抛开编程语言内置的数字类型,仅用最基本的类和递归概念来重新定义自然数时,会惊讶地发现数学的抽象之美…...

203 异构车辆队列分布式 MPC 优化控制约束复现之旅
203 异构车辆队列分布式 MPC 优化控制约束 复现的代码 .m 文件在自动驾驶和智能交通领域,异构车辆队列的分布式模型预测控制(MPC)是个热门话题。今天就来聊聊基于复现代码(.m文件)对203异构车辆队列分布式MPC优化控制约…...

【DexGraspNet与多指手抓取算法详解】第三章 DexGraspNet数据集构建机理
目录 第三章 DexGraspNet数据集构建机理 第一部分 原理详解 3.1 数据生成流程总览 3.1.1 Asset准备与处理 3.1.1.1 ShapeNetSem物体库筛选 3.1.1.1.1 几何网格清理与流形检测 3.1.1.1.2 物理属性赋值(质量、质心) 3.1.1.2 视觉资产渲染管线 3.1.1.2.1 材质与纹理映射…...