文献分享集:跨模态的最邻近查询RoarGraph
文章目录
- 1. \textbf{1. } 1. 导论
- 2. \textbf{2. } 2. 对 OOD \textbf{OOD} OOD负载的分析与验证
- 3. RoarGraph \textbf{3. RoarGraph} 3. RoarGraph
1. \textbf{1. } 1. 导论
1.1. \textbf{1.1. } 1.1. 研究背景
1️⃣跨模态检索:
- 含义:使用某个模态的数据作为 query \text{query} query,返回另一个模态中语义相似的内容
- 示例:输入
"Apple"后,返回苹果的照片2️⃣模态差距 (gap) \text{(gap)} (gap):不同模态数据即使映射到同一语义空间(比如用 CLIP \text{CLIP} CLIP),其分布特征仍差距显著
\quad
3️⃣两种 ANN \text{ANN} ANN
- 单模态 ANN \text{ANN} ANN:查询向量分布 ↔ ID \xleftrightarrow{\text{ID}} ID 基础数据分布,即查询来源于与数据库数据相同的分布
- 跨模态 ANN \text{ANN} ANN:查询向量分布 ↔ OOD \xleftrightarrow{\text{OOD}} OOD 基础数据分布,即查询来源于与数据库数据不同的分布
1.2. \textbf{1.2. } 1.2. 本文的研究
1️⃣研究动机:当前 SOTA \text{SOTA} SOTA的 ANN \text{ANN} ANN都是单模态的,在 OOD \text{OOD} OOD负载上表现差
2️⃣研究内容
- OOD \text{OOD} OOD工作负载分析:跨模态后性能下降,源于查询过远 + + +标签分散 → \text{→} →收敛变慢 / / /跳数增加
类型 查询 ↔ 距离 \boldsymbol{\xleftrightarrow{距离}} 距离 基础数据 查询最邻近 i ↔ 距离 \boldsymbol{i\xleftrightarrow{距离}} i距离 查询最邻近 查询 ↔ 分布 \boldsymbol{\xleftrightarrow{分布}} 分布 基础数据 单模态 ANN \text{ANN} ANN 近(基本假设) 近(基本假设) ID \text{ID} ID 跨模态 ANN \text{ANN} ANN 远(实验得到) 远(实验得到) OOD \text{OOD} OOD - RoarGraph \text{RoarGraph} RoarGraph的提出:
- 原理:让查询参与图构建 → \text{→} →将[查询点 ↔ \xleftrightarrow{} 基础点]邻接关系投影到基础点 → \text{→} →形成仅有基础点的图
- 意义:让空间上很远但是查询上很近的点相连,从而能高效处理 OOD-ANNS \text{OOD-ANNS} OOD-ANNS
- 效果:在跨模态数据集上实现了 QPS \text{QPS} QPS和 Recall \text{Recall} Recall指标的提升
1.3. \textbf{1.3. } 1.3. 有关工作
方法 核心思想 优缺点 束搜索终止 利用查询训练分类模型判断何时终止搜索 提升效率,但训练成本较高 图卷积 (GCN) \text{(GCN)} (GCN) 引入 GCN \text{GCN} GCN学习最优搜索路径 路径优化明显,但训练成本较高 GCN+RL \text{GCN+RL} GCN+RL 强化学习与 GCN \text{GCN} GCN结合引导搜索路由 提升效果显著,但训练成本较高 GraSP \text{GraSP} GraSP 概率模型与子图采样学习边重要性 性能优化明显,但索引构建成本高 ScaNN \text{ScaNN} ScaNN 结合向量量化和 PQ \text{PQ} PQ进行分区与压缩 压缩与搜索性能高效,但依赖调参


2. \textbf{2. } 2. 对 OOD \textbf{OOD} OOD负载的分析与验证
2.1. \textbf{2.1. } 2.1. 初步的背景及其验证
2.1.1. \textbf{2.1.1. } 2.1.1. 对模态差距的验证
1️⃣ OOD \text{OOD} OOD的量化
距离类型 衡量什么 如何理解 Wasserstein \text{Wasserstein} Wasserstein距离 两个分布间的差异 把一个分布搬到另一个的最小代价 Mahalanobis \text{Mahalanobis} Mahalanobis距离 一个向量到一个分布的距离 一个点相对于一个分布的异常程度 1️⃣实验 1 1 1:用 Wasserstein \text{Wasserstein} Wasserstein距离衡量 OOD \text{OOD} OOD特性
- 数据集:基础数据集中抽取的无交叉集 B 1 / B 2 B_1/B_2 B1/B2, OOD \text{OOD} OOD的查询集 Q Q Q
- 结果: Wasserstein ( B 1 , Q ) \text{Wasserstein}(B_1,Q) Wasserstein(B1,Q)和 Wasserstein ( B 2 , Q ) \text{Wasserstein}(B_2,Q) Wasserstein(B2,Q),大致是 Wasserstein ( B 1 , B 2 ) \text{Wasserstein}(B_1,B_2) Wasserstein(B1,B2)两倍
2️⃣实验 2 2 2:用 Mahalanobis \text{Mahalanobis} Mahalanobis距离衡量 OOD \text{OOD} OOD特性
- 数据集:满足分布 P P P的基础数据,来自 ID \text{ID} ID查询集的 q i d q_{id} qid,来自 OOD \text{OOD} OOD查询集的 q o o d q_{ood} qood
- 结果: Mahalanobis ( q id , P ) <Mahalanobis ( q ood , P ) \text{Mahalanobis}(q_{\text{id}},P)\text{<}\text{Mahalanobis}(q_{\text{ood}},P) Mahalanobis(qid,P)<Mahalanobis(qood,P)
2.1.2. SOTA-ANN \textbf{2.1.2. }\textbf{SOTA-ANN} 2.1.2. SOTA-ANN在 OOD \textbf{OOD} OOD任务上的表现
1️⃣对传统的 SOTA-ANN \text{SOTA-ANN} SOTA-ANN
索引方法 在 OOD \textbf{OOD} OOD上的表现(相比在 ID \textbf{ID} ID上) HNSW \text{HNSW} HNSW 性能显著下降,在 BeamSearch \text{BeamSearch} BeamSearch过程显著访问更多的结点(要经历更多跳) IVF-PQ \text{IVF-PQ} IVF-PQ 性能显著下降,需要更多的聚类数才能达到相同的 Recall \text{Recall} Recall 2️⃣对改进的 ANN \text{ANN} ANN:针对 OOD-ANNS \text{OOD-ANNS} OOD-ANNS的首个图索引 RobustVamana(OOD-DiskANN) \text{RobustVamana(OOD-DiskANN)} RobustVamana(OOD-DiskANN)
- 原理:先用 Vamana \text{Vamana} Vamana建图,然后再用 RobustStitch \text{RobustStitch} RobustStitch根据查询向量,连接新的边
- 性能:比 DiskANN \text{DiskANN} DiskANN在 OOD \text{OOD} OOD任务上提升了 40% \text{40\%} 40%性能,但是查询速度慢了 × 4 -10 {\text{×}4\text{-10}} ×4-10
2.2. \textbf{2.2. } 2.2. 对 OOD \textbf{OOD} OOD上 ANN \textbf{ANN} ANN工作负载的分析
2.2.1. OOD-ANNS \textbf{2.2.1. OOD-ANNS} 2.2.1. OOD-ANNS和 ID-ANNS \textbf{ID-ANNS} ID-ANNS的两个差异
1️⃣两种差异及实验结果
- OOD \text{OOD} OOD查询离其最邻近很远:即 δ ( q ood , i t h -NN ood ) ≫ δ ( q id , i t h -NN id ) \delta\left(q_{\text{ood}}, i^{t h} \text{-NN}_{\text{ood}}\right) \text{≫} \delta\left(q_{\text{id}}, i^{t h} \text{-NN}_{\text{id}}\right) δ(qood,ith-NNood)≫δ(qid,ith-NNid),左为 i = 1 i\text{=}1 i=1时的分布结果
- OOD \text{OOD} OOD查询的最邻近彼此原理: 10 0 t h -NN 100^{t h} \text{-NN} 100th-NN互相之间的平均距离,实验结果如右

2️⃣对差异的直观理解
- 简单(概念)示例:

- ID \text{ID} ID查询:查询与其最邻近在球面上,相互靠近
- ODD \text{ODD} ODD查询:查询在球心,其最邻近在球面上(由此距离较远且查询不多 + \text{+} +分散分布)
- 真实示例:真实数据 PCA \text{PCA} PCA降到二维的视图, ID \text{ID} ID查询更为集中
2.2.2. \textbf{2.2.2. } 2.2.2. 为何传统 SOTA-ANN \textbf{SOTA-ANN} SOTA-ANN在 ODD \textbf{ODD} ODD表现不佳
0️⃣传统 ANN \text{ANN} ANN的设计
- 基于两假设:查询 / / /数据同分布 + k +k +k个最近邻彼此相互靠近(邻居的邻居是邻居),刚好全反的
- 设计的思路:
- 建图:用 BeamSearch \text{BeamSearch} BeamSearch来构建 KNN \text{KNN} KNN图 → \text{→} →空间中相近的点转化为图中紧密连接的结点
- 搜索:从中心点开始 GreedySearch \text{GreedySearch} GreedySearch
1️⃣在基于图 ANN \text{ANN} ANN上: OOD \text{OOD} OOD会使得搜索空间增大
- 可识别搜索空间:包围当前访问结点 x x x的 B s ( x ) + B k ( 1 st -NN , R ) B^{s}(x)\text{+}B^{k}\left(1^{\text{st}}\text{-NN}, R\right) Bs(x)+Bk(1st-NN,R)
- 球 B k ( 1 st -NN , R ) B^{k}\left(1^{\text{st}}\text{-NN}, R\right) Bk(1st-NN,R):以 1 st -NN 1^{\text{st}}\text{-NN} 1st-NN为球心, k k k邻近间互相距离 δ ( i th -NN , j th -NN ) \delta\left(i^{\text{th}}\text{-NN}, j^{\text{th}}\text{-NN}\right) δ(ith-NN,jth-NN)最大值为半径
- 球 B s ( x ) B^{s}(x) Bs(x):以当前结点 x x x为圆心,以 δ ( x , i th -NN ) \delta\left(x, i^{\text{th}}\text{-NN}\right) δ(x,ith-NN)的最大值(到最远最邻近的距离)为半径
- OOD \text{OOD} OOD的影响:搜索空间大幅增大
- 对 B k B^{k} Bk:由于 OOD \text{OOD} OOD的性质 R ood ≫ R id R_{\text {ood }}\text{≫}R_{\text{id}} Rood ≫Rid,这一差异在体积层面放大到 ( R ood R id ) D \left(\cfrac{R_{\text {ood }}}{R_{\text{id}}}\right)^D (RidRood )D级别
- 对 B s B^{s} Bs:由于 OOD \text{OOD} OOD的性质 δ ( x , i th -NN ood ) ≫ δ ( x , i th -NN id ) \delta\left(x, i^{\text{th}}\text{-NN}_{\text{ood}}\right)\text{≫}\delta\left(x, i^{\text{th}}\text{-NN}_{\text{id}}\right) δ(x,ith-NNood)≫δ(x,ith-NNid),使得体积也大幅膨胀
- 对搜索过程的影响:
- 对于 ID \text{ID} ID查询:由于最近邻彼此靠近, GreedySearch \text{GreedySearch} GreedySearch可以使 B s ( x ) B^{s}(x) Bs(x)轻松收敛
起点 -> 近邻1 -> 近邻2 -> 近邻3 (一个小范围内)- 对于 OOD \text{OOD} OOD查询:最近邻方向分散难以收敛,需要更大的 Beam \text{Beam} Beam宽度 / / /搜索路径等
近邻2↗️ 起点 -> 近邻1 -> 近邻3 (分散在大范围内)↘️ 近邻42️⃣在基于划分 IVF \text{IVF} IVF上
- 原理上: IVF \text{IVF} IVF先将原数据分簇
- ID \text{ID} ID查询:最邻近集中在少数几个相邻簇中
- OOD \text{OOD} OOD查询:最邻近分散在多个不相邻簇中
- 实验上: OOD \text{OOD} OOD查询需要扫描更多的簇,性能下降 2.5 2.5 2.5倍


3. RoarGraph \textbf{3. RoarGraph} 3. RoarGraph
3.1. RoarGraph \textbf{3.1. RoarGraph} 3.1. RoarGraph的设计思路
1️⃣面向解决三种挑战
- 边的建立:如何连接查询 / / /基础两类结点,同时避免基础结点度数太高
- 搜索效率:查询结点要保持极高出度以覆盖基础节点,但同时也会大幅增加跳数 / / /内存开销
- 连通性:避免出现孤立结点,独立子图
1️⃣大致的设计流程
- 构建:建立查询 ↔ \boldsymbol{\xleftrightarrow{}} 基础二分图 → \text{→} →将邻接信息投影到基础点中 → \text{→} →增强连接
- 查询:同样是用 BeamSearch \text{BeamSearch} BeamSearch
3.2. RoarGraph \textbf{3.2. RoarGraph} 3.2. RoarGraph的构建: 三个阶段
3.2.1. \textbf{3.2.1. } 3.2.1. 阶段 1 \textbf{1} 1: 查询 ↔ \boldsymbol{\xleftrightarrow{}} 基础二分图构建
1️⃣二分图概述:
- 基本概念:将所有的点分为两个集合,所有边必须连接不同子集的点,不能内部连接
- 在此处:两子集查询结点 + + +基础节点,两种边[查询结点 → \text{→} →基础结点] + \text{+} +[查询结点 ← \text{←} ←基础结点]
2️⃣构建过程概述
\quad
- 预处理:计算每个查询向量的真实 N q -NN N_q\text{-NN} Nq-NN标签
- 边构建:
方向 操作 查询点 → \text{→} →基础点 查询点 → 连接 \xrightarrow{连接} 连接查询点的 N q -NN N_q\text{-NN} Nq-NN基础点 基础点 → \text{→} →查询点 查询点 ← 连接 \xleftarrow{连接} 连接查询点的 1 -NN 1\text{-NN} 1-NN基础点,查询点 → 断连 \xrightarrow{断连} 断连查询点的 1 -NN 1\text{-NN} 1-NN基础点 - 示例:
预处理: T1 -> X1, X2, X3 (Nq=3) 边构建: T1 -> X2, X3 T1 <- X12️⃣构建过程分析
- 结点度数的考量:
- 高查询结点出度:提高 N q N_q Nq值,增加[基础点 → 覆盖性 重叠性 \xrightarrow[覆盖性]{重叠性} 重叠性覆盖性查询点],使多基础点可由同一查询点联系
- 低基础节点出度:为了解决上述挑战 1 1 1,目的在于提高二分图上的搜索效率
- 边方向的考虑:不进行双向连接,避免二分图搜索时要去检查邻居的邻居( N q 2 N_q^2 Nq2)
预处理: T1 -> X1, X2, X3 (Nq=3) 边构建: T1 -> X1, X2, X3 T1 <- X1T1 <- X2T1 <- X33.2.2. \textbf{3.2.2. } 3.2.2. 阶段 2 \textbf{2} 2: 领域感知投影
1️⃣一些分析
- 优化动机:二分图内存消耗高(额外存储了查询节点),搜索路径长(需要额外经过查询结点)
- 关于投影:
- 目的:移除二分图中的查询结点,并保留从查询分布获得的邻近关系
- 方式:最简单的可将查询点所连的全部基础点全连接(度数太高),优化方法如领域感知投影
2️⃣投影过程:
- 预处理:
- 遍历查询点:获得与查询点相连的最邻近基础点
查询Q -> {B1, B2, B3, B4, B5} (Q连接了5个基础节点)- 选择中心点:即查询点的 1-NN \text{1-NN} 1-NN点,作为 Pivot \text{Pivot} Pivot
查询Q -> {B1, B2, B3, B4, B5} (Q连接了5个基础节点)👆pivot- 排序基础结点:将余下 N q -NN N_q\text{-NN} Nq-NN点,按与 Pivot \text{Pivot} Pivot的距离排序
- 感知投影:
- 连接:让中心点与余下点建立连接
B1 -> B2 (最近) B1 -> B3 (次近) B1 -> B4 (较远) B1 -> B5 (最远)- 过滤:保证与 Pivot \text{Pivot} Pivot连接方向的多样性

条件 含义 操作 Dist ( X , Y ) <Dist ( Pivot , Y ) \text{Dist}(X,Y)\text{<}\text{Dist}(\text{Pivot},Y) Dist(X,Y)<Dist(Pivot,Y) 该方向已有连接 则筛掉 Y Y Y(不与 Pivot \text{Pivot} Pivot建立连接) Dist ( X , Y ) >Dist ( Pivot , Y ) \text{Dist}(X,Y)\text{>}\text{Dist}(\text{Pivot},Y) Dist(X,Y)>Dist(Pivot,Y) 代表新的搜索方向 则保留 Y Y Y(可与 Pivot \text{Pivot} Pivot建立连接) - 填充:当 Pivot \text{Pivot} Pivot的出度小于度数限制,则又重新连接之前过滤掉的结点
3.2.3. \textbf{3.2.3. } 3.2.3. 连通性增强

1️⃣为何要增强:仅依赖于二分图的覆盖范围,投影图的连通性还太低,对 GreedySearch \text{GreedySearch} GreedySearch不友好
2️⃣增强的方法:
- 检索:从基础集的 Medoid \text{Medoid} Medoid开始,对每个基础点执行 BeamSearch \text{BeamSearch} BeamSearch得到最邻近(作为候选点)
- 连边:在不超过度数限制的前提下,让该基础点连接一定数量的候选点作
3.3. RoarGraph \textbf{3.3. RoarGraph} 3.3. RoarGraph性能的验证
3.3.1. \textbf{3.3.1. } 3.3.1. 实验设置
1️⃣数据集
数据集 描述 查询集 索引集 Text-to-Image \text{Text-to-Image} Text-to-Image 流行基准数据集,含图像和文本查询向量 官方 1 w 1\text{w} 1w条 余下不重叠数据 LAION \text{LAION} LAION 数百万对图像 − - −替代文本对 采样 1 w 1\text{w} 1w条 余下不重叠数据 WebVid \text{WebVid} WebVid 素材网站获取的字幕和视频对 采样 1 w 1\text{w} 1w条 余下不重叠数据 2️⃣超参数设置
模型 超参数列表 HNSW \text{HNSW} HNSW M = 32 M\text{=}32 M=32, efConstruction= 500 \text{efConstruction}\text{=}500 efConstruction=500 NSG \text{NSG} NSG R = 64 R\text{=}64 R=64, C = L = 500 C\text{=}L\text{=}500 C=L=500 τ -MNG \tau\text{-MNG} τ-MNG R = 64 R\text{=}64 R=64, C = L = 500 C\text{=}L\text{=}500 C=L=500, τ = 0.01 \tau\text{=}0.01 τ=0.01 RobustVamana \text{RobustVamana} RobustVamana R = 64 R\text{=}64 R=64, L = 500 L\text{=}500 L=500, α = 1.0 \alpha\text{=}1.0 α=1.0 RoarGraph \text{RoarGraph} RoarGraph N q = 100 N_q\text{=}100 Nq=100(最近邻候选数量), M = 35 M\text{=}35 M=35(出度约束), L = 500 L\text{=}500 L=500(候选集大小) 3️⃣性能指标: Recall@k \text{Recall@k} Recall@k和 QPS \text{QPS} QPS(检索速度)
3.3.2. \textbf{3.3.2. } 3.3.2. 实验结果
1️⃣ QPS \text{QPS} QPS与召回: RoarGraph \text{RoarGraph} RoarGraph最优(超过 RobustVamana \text{RobustVamana} RobustVamana), HNSW/NSG \text{HNSW/NSG} HNSW/NSG差不多, τ -MNG \tau\text{-MNG} τ-MNG最差

2️⃣跳数与召回: RoarGraph \text{RoarGraph} RoarGraph跳数显著减少,且随 Recall@ \text{Recall@} Recall@的 k k k增大,减少趋势下降

3️⃣消融实验:对比了二分图 / / /投影图 / / /完整图,可见通过邻域感知投影显著提升性能

4️⃣查询集规模:即查询集大小占基础集大小比重对索引性能的影响;可见起始模型对规模并不敏感

5️⃣在 ID \text{ID} ID负载上的性能: RoarGraph \text{RoarGraph} RoarGraph依旧能打,和 HNSW \text{HNSW} HNSW相当

6️⃣索引开销成本:使用 10 % 10\% 10%数据可大幅降低构建成本,同时保持搜索性能
\quad
3.4. RoarGraph \textbf{3.4. RoarGraph} 3.4. RoarGraph的一些讨论
1️⃣运用场景:结合大量历史查询数据,用多模态深度学习模型生成嵌入,部署在大型检索 / / /推荐系统
2️⃣更新机制:
- 初始搜索:
- 结点查询:将新插入下新基础节点 v v v作为查询,在基础数据集中搜索其最邻近
- 结点筛选:要求最邻近满足,曾在图构建过程中与至少一个查询点连接过的基础点
- 反向回溯:对该最邻近点,回溯到与其曾建立过连接的距离最近的查询点 q q q
- 子图构建:
- 二分子图:将 q ↔ N out ∪ v q\xleftrightarrow{}N_{\text {out}}\text{∪}v q Nout∪v整合为二分子图
- 邻域投影:将 v v v作为 Pivot \text{Pivot} Pivot按同样的方式,生成投影图
3️⃣删除操作:采用墓碑标记法 Tombstones \text{Tombstones} Tombstones,即被删结点任参与路由,但排除在搜索结果中


相关文章:

文献分享集:跨模态的最邻近查询RoarGraph
文章目录 1. \textbf{1. } 1. 导论 1.1. \textbf{1.1. } 1.1. 研究背景 1.2. \textbf{1.2. } 1.2. 本文的研究 1.3. \textbf{1.3. } 1.3. 有关工作 2. \textbf{2. } 2. 对 OOD \textbf{OOD} OOD负载的分析与验证 2.1. \textbf{2.1. } 2.1. 初步的背景及其验证 2.1.1. \textbf{2…...

xdoj 判断字符串子串
判断字符串子串 问题描述 编写程序: 判断一个不大于 20 个字符的字符串是否是另一个不大于 20 个字符的字符串的子 串,如果是,则输出子串在父串的起始位置, 如果不是子串,则输出 No!。 输入说明 输入分 2 行: 第…...

n8n - AI自动化工作流
文章目录 一、关于 n8n关键能力n8n 是什么意思 二、快速上手 一、关于 n8n n8n是一个具有原生AI功能的工作流自动化平台,它为技术团队提供了代码的灵活性和无代码的速度。凭借400多种集成、原生人工智能功能和公平代码许可证,n8n可让您构建强大的自动化…...

asp.net core 属性路由和约定路由
在 ASP.NET Core 中,Web API 中的路由(Route)用于确定客户端请求的 URL 与服务器端处理逻辑之间的映射关系。路由机制在 Web API 的开发中非常重要,它帮助定义和管理不同请求路径如何触发特定的控制器和操作方法。 1. 路由概述 …...

【PS不常见教程】实操篇之通道抠图-抠黑色背景的图片
观前小提示:本文内容为我原创成果,若您需要转载或引用其中图片或文字内容,请记得标注来源是“璞子的家”哦,感谢您的尊重,理解与支持,谢谢啦! 如果没看过之前的文章,可以先看之前的两…...

电子电气架构 --- 整车整车网络管理浅析
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 所谓鸡汤,要么蛊惑你认命,要么怂恿你拼命,但都是回避问题的根源,以现象替代逻辑,以情绪代替思考,把消极接受现实的懦弱,伪装成乐观面对不幸的…...

【数据结构05】排序
系列文章目录 【数据结构05】排序 . 【算法思想04】二分查找 文章目录 系列文章目录[toc] 1. 基本思想与实现1.1 插入类排序1.1.1 直接插入排序(*)1.1.2 折半插入排序1.1.3 希尔排序(*) 1.2 交换类排序1.2.1 冒泡排序(…...

推荐系统的三道菜
推荐系统的本质就是在有太多展示内容的情况下,对内容的呈现进行排序。 它的排序依据主要有三个方面: 1. 用户信息 排序的主要依据就是用户感兴趣的程度。 要获知用户的兴趣点,就要搜集“用户信息”,比如用户的历史行为、身份信息、…...

ModuleNotFoundError: No module named XXX
我们在安装了某个包之后,还是提示找不到包 方法一: python -m pip install 包名 -i https://pypi.tuna.tsinghua.edu.cn/simple 方法二: conda install 包名 如果还是找不到包: 请检查环境:...
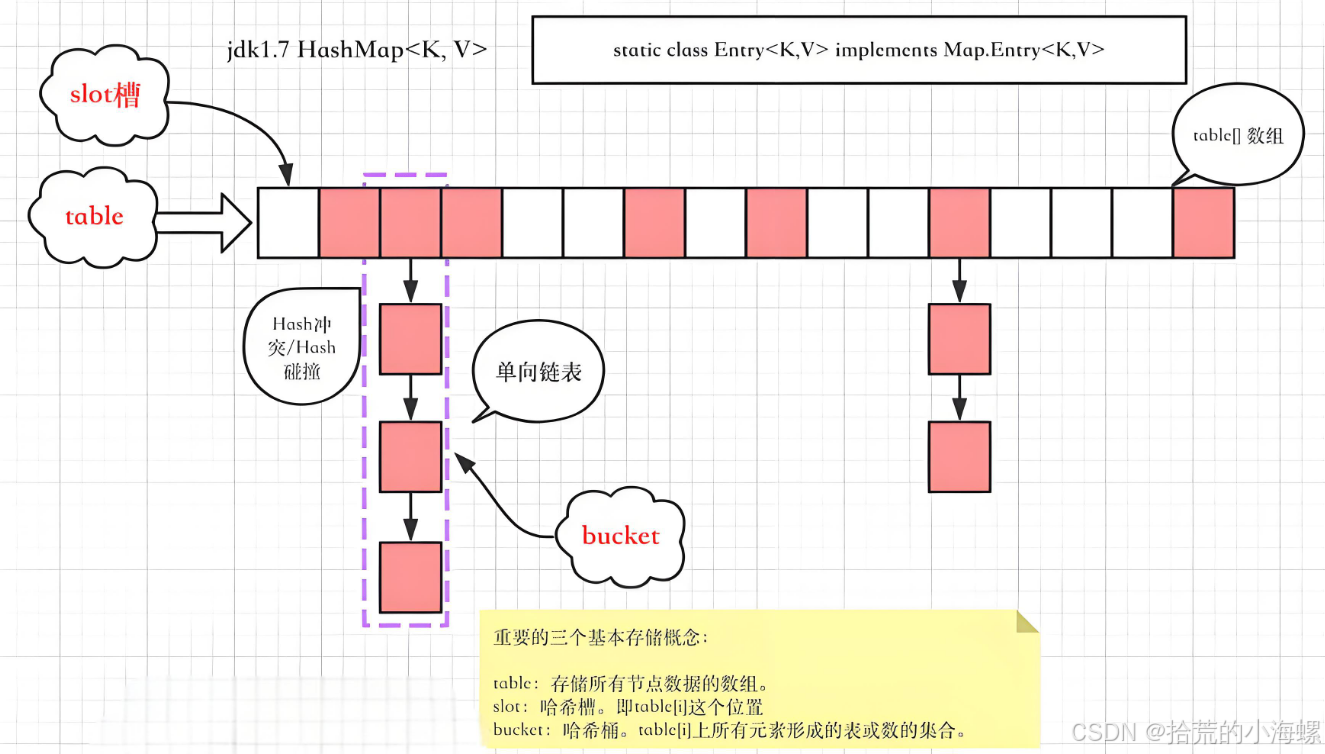
JAVA:HashMap在1.8做了哪些优化的详细解析
1、简述 HashMap 是 Java 中最常用的数据结构之一,它以键值对的形式存储数据,允许快速的插入、删除和查找操作。在 JDK 1.8 之前,HashMap 主要是基于数组加链表的结构实现的。然而,在面对大量哈希冲突时(即多个键的哈…...

jest使用__mocks__设置模拟函数不生效 解决方案
模拟文件 // __mocks__/axios.js const axios jest.fn(); axios.get jest.fn(); axios.get.mockResolvedValue({data: {undoList: [get data],}, }); export default axios; 测试文件 jest.mock(axios); import Axios from axios;test(mytest, () > {console.log("…...

javaEE-网络原理-1初识
目录 一.网络发展史 1.独立模式 2.网络互联 二.局域网LAN 1.基于网线直连: 2.基于集线器组件: 3.基于交换机组件: 4.基于交换机和路由器组件 编辑 三、广域网WAN 四、网络通信基础 1.ip地址 2.端口号: 3.协议 4.五…...

笔上云世界微服务版
目录 一、项目背景 二、项目功能 一功能介绍 三、环境准备 • 需要开发的端口 • Mysql 导入数据库 编辑 • Redis 编辑 • RabbitMQ 编辑 在创建blog虚拟主机(方法如下) • Nacos • Nginx 四、前端部署 五、后端部署 六、测试计划操作 一功能测试 二…...

linux安装redis及Python操作redis
目录 一、Redis安装 1、下载安装包 2、解压文件 3、迁移文件夹 4、编译 5、管理redis文件 6、修改配置文件 7、启动Redis 8、将redis服务交给systemd管理 二、Redis介绍 1、数据结构 ①字符串String ②列表List ③哈希Hash ④集合Set ⑤有序集合Sorted Set 2、…...

node.js内置模块之---stream 模块
stream 模块的作用 在 Node.js 中,stream 模块是一个用于处理流(stream)的核心模块。流是一种处理数据的抽象方式,允许程序处理大量数据时不会一次性将所有数据加载到内存中,从而提高性能和内存效率。通过流࿰…...

《learn_the_architecture_-_aarch64_exception_model》学习笔记
1.当发生异常时,异常级别可以增加或保持不变,永远无法通过异常来转移到较低的权限级别。从异常返回时,异常级别可能会降低或保持不变,永远无法通过从异常返回来移动到更高的权限级别。EL0级不进行异常处理,异常必须在比…...

【C++项目实战】贪吃蛇小游戏
一、引言 贪吃蛇,这款经典的电子游戏,自1976年诞生以来,一直受到全球玩家的喜爱。它的规则简单,玩法直观,但同时也充满了挑战性。在这篇文章中,我们将一起探索如何开发一个贪吃蛇游戏,无论是作为…...

Python基于matplotlib实现树形图的绘制
在Python中,你可以使用matplotlib库来绘制树形图(Tree Diagram)。虽然matplotlib本身没有专门的树形图绘制函数,但你可以通过组合不同的图形元素(如线条和文本)来实现这一点。 以下是一个简单的示例&#…...

【UE5 C++课程系列笔记】21——弱指针的简单使用
目录 概念 声明和初始化 转换为共享指针 打破循环引用 弱指针使用警告 概念 在UE C 中,弱指针(TWeakPtr )也是一种智能指针类型,主要用于解决循环引用问题以及在不需要强引用保证对象始终有效的场景下,提供一种可…...

【游戏设计原理】46 - 魔杖
幻想,人们可以通过多种形式来引发,比如文字,图片,绘画,语言等,但游戏与以上这些形式的区别,正如游戏与其他艺术形式的区别一样,游戏作为一种艺术和娱乐形式,其独特之处在…...
:AGI主权归属的区块链终局方案)
2026奇点大会唯一未删减技术圆桌实录(含OpenAI、Ethereum基金会、中科院自动化所三方闭门共识):AGI主权归属的区块链终局方案
第一章:2026奇点智能技术大会:AGI与区块链 2026奇点智能技术大会(https://ml-summit.org) AGI系统与去中心化身份的协同演进 在2026奇点智能技术大会上,核心议题之一是通用人工智能(AGI)如何依托区块链构建可信自主代…...

MongoPlus 教程
一、MongoPlus 简介MongoPlus 是一个基于 MyBatis-Plus 思想设计的 MongoDB ORM 框架,提供了类似 MyBatis-Plus 的便捷操作体验。⚠️ 注意:MyBatis-Plus 本身是针对关系型数据库(MySQL、PostgreSQL等)的增强工具,并不…...

赛元SC95F8617触摸库实战:从电机干扰到人体检测,我的按摩椅项目避坑实录
赛元SC95F8617触摸库实战:从电机干扰到人体检测,我的按摩椅项目避坑实录 按摩椅作为智能家居领域的热门产品,人体检测功能的可靠性直接影响用户体验。去年接手的一个高端按摩椅项目,让我深刻体会到赛元SC95F8617触摸库在复杂电磁环…...

别再只用PBKDF2了!聊聊国密标准GMT0091里的SM4和HMAC-SM3怎么用
国密算法实战:从PBKDF2到HMAC-SM3与SM4-CBC的迁移指南 金融级应用开发中,密钥派生与数据加密方案的选择直接影响系统安全性。当项目需要满足国密标准合规要求时,开发者常面临从国际通用算法向SM系列算法迁移的技术挑战。本文将手把手演示如何…...
)
从ISO9506到实际报文:手把手用Wireshark解码一个MMS数据包(含ASN.1/BER解析实战)
从ISO9506到实际报文:手把手用Wireshark解码一个MMS数据包(含ASN.1/BER解析实战) 当你面对工业控制网络中捕获的陌生流量时,能否准确识别出隐藏在TCP端口102背后的MMS协议通信?本文将带你从协议标准出发,通…...

有哪些适合继续教育学生的AI论文写作工具?求真实推荐
继续教育(成教、函授、自考)同学大多在职上班、时间碎片化、论文基础弱、预算有限、需要快速过查重 低 AI 痕迹、贴合实践案例,不用复杂科研,只求高效、合规、低成本、顺利毕业。本文全部为真实实测体验,严格按照你要…...

TuGraph图数据库:5大核心功能全面解析与快速上手指南
TuGraph图数据库:5大核心功能全面解析与快速上手指南 【免费下载链接】tugraph-db TuGraph: A High Performance Graph Database. 项目地址: https://gitcode.com/gh_mirrors/tu/tugraph-db 在当今数据驱动的时代,图数据库正成为处理复杂关系数据…...

靠谱的东莞高新技术企业认定技术支持公司
在东莞,越来越多的企业希望通过认定高新技术企业来提升自身竞争力,享受政策优惠。而选择一家靠谱的高新技术企业认定技术支持公司至关重要。下面为大家详细介绍相关内容,并重点推荐沐霖信息科技(广东)有限公司。高新技…...

JavaScript正则表达式实战:从EDUCODER关卡解析到日常开发应用
JavaScript正则表达式实战:从EDUCODER关卡解析到日常开发应用 正则表达式就像程序员的瑞士军刀,能在文本处理中解决各种棘手问题。第一次接触正则时,那些看似神秘的符号组合让我望而生畏,直到在EDUCODER平台通过实战关卡逐步掌握…...

SolidWorks参数化设计避坑指南:为什么你的VBA宏跑一次就报错?
SolidWorks参数化设计实战避坑:从VBA宏崩溃到工业级稳定的进阶指南 当你的参数化设计宏第一次成功运行时,那种成就感就像看着亲手组装的机器终于运转起来。但很快,现实会给你当头一棒——第二次运行就报错,第三次直接导致SolidWor…...