DeepSeek v3为何爆火?如何用其集成Milvus搭建RAG?


最近,DeepSeek v3(一个MoE模型,拥有671B参数,其中37B参数被激活)模型全球爆火。
作为一款能与Claude 3.5 Sonnet,GPT-4o等模型匹敌的开源模型DeepSeek v3不仅将其算法开源,还放出一份扎实的技术报告,详尽描述了DeepSeek是如何进行大模型架构、算法工程协同设计,部署,训练,数据处理等方面的思考,堪称是一份DeepSeek给开源社区送上的年末大礼。
本篇文章,我们会对DeepSeek v3的亮点进行梳理,并对其RAG搭建流程与效果,做一个简单的示例。
01.
DeepSeek v3的亮点

亮点一:超低的训练成本,将带来算力的极大富余
相比于海外大厂动辄上万甚至上十万的H100集群(例如Meta使用了16K的H100训练Llama3.1 405B),DeepSeek仅仅使用了2048张丐版显卡H800就在14.8T数据上训练了一个处于第一梯队的开源模型。以下是DeepSeek v3的训练成本数据。

不难看出,基于以上数据,传统对大模型对算力的供需预测推演直接被推翻,过去Scaling law曲线所估算出的GPU需求数量会出现极大冗余。
那么问题来了,DeepSeek v3是如何做到的?
亮点二:颠覆GPT架构,极致的工程设计
在去年,大模型领域普遍认为模型的设计已经收敛到Decoder-only的GPT架构,但DeepSeek依然没有放弃对模型架构的进一步探索。
这一次V3的设计延用了V2提出的MLA(Multi-head Latent Attention),这是一种通过低秩压缩键值对来减少缓存需求的创新架构,以提高Transformer模型的推理效率。
另外,此次的MoE模型规格也比之前大了许多(V3 671B, V2 236B),也体现出了对这个架构拥有更多的信心和经验。DeepSeek V3将除前三层外的所有 FFN 层替换为 MoE 层。每个 MoE 层包含 1 个共享专家和 256 个路由专家。在路由专家中,每个 token 将激活 8 个专家,并确保每个 token 最多会被发送到 4 个节点。
同时,论文还对如何在系统中设计将这种架构进行推理的性能优化也进行了详尽的描述。
DeepSeek V3使用了多token预测(MTP),即每个 token 除了精确预测下一个 token 外,还会预测一个额外的 token,通过投机采样的方式提高推理效率。
关于如何使用FP8进行模型训练这个各个大模型工程团队头痛的问题,DeepSeek V3也对自己的实践有细致的描述,对这部分感兴趣的朋友强烈推荐阅读论文原文。
亮点三:通过蒸馏推理模型进行后训练
自从OpenAI发布了o1模型之后,业界开始逐渐兴起了探索这种内置思维琏(CoT)的模型,它不断对中间结果探索分析的过程仿佛人的“慢思考”。DeepSeek同样也开发了类似的R1模型,在DeepSeek V3中,DeepSeek创新性地通过在后训练阶段使用R1得到的高质量答案来提高了自身的性能。这一点也非常有趣。
众所周知,类似o1的开源模型大部分都是从基础模型利用CoT结合强化学习的技巧训练出来提高了推理效果,而现在又通过蒸馏推理模型获得了下一代更好的基础模型,这一种模型和数据质量互相交织的发展模式贯穿着机器学习发展的历史,而还将继续被见证。
而以发掘非结构化数据价值的厂商Zilliz也相信对于数据和知识的高效管理,将会一直在智能化浪潮发展中扮演着重要的角色。
看到10K$的后训练成本,相信许多致力于微调专属大模型的厂商都跃跃欲试,在这里我们也来看一下DeepSeek V3的后训练过程,整个流程也比传统的SFT要复杂一些。整个过程分成了SFT阶段(监督学习)以及RL阶段(强化学习),在SFT阶段,他们将数据分成了两种类型,推理数据以及非推理数据
推理数据:
包括数学,编程这些问题,DeepSeek训练了针对性的专家模型,并使用专家模型为每一个问题生成了两种格式的学习数据。
<problem, original response>
<system prompt, problem, R1 response>
非推理数据:
对于非推理任务(如创意写作和简单问答),作者利用DeepSeek-V2.5模型生成初步响应,并聘请人工标注员对其准确性进行验证
训练的流程:
SFT阶段,使用基于专家模型生成的SFT样本,进行初步的监督微调。通过这些训练数据,模型学习如何根据问题和回答生成精确的推理响应。
RL阶段,使用高温采样来生成响应,这些响应融合了来自原始数据和R1生成数据的模式。在RL阶段,会使用LeetCode编译器来检查编程的答案,以及一些规则来去检查数学问题的答案,对于开放性问题, 会用一个奖励模型来去判断。该过程帮助模型在没有显式系统提示的情况下进行推理,经过数百次RL步骤,模型学会如何平衡准确与简洁性的答案。
完成RL训练后,作者实施拒绝采样策略(过滤掉模型认为低质量的数据),以从生成的样本中挑选出高质量的SFT数据。这些数据用于最终模型的微调。
不难发现,做好一个高质量的后训练,下的功夫远远不止10k$的训练算力。
DeepSeek V3虽然拥有可以与闭源模型匹敌的性能,但是部署它依然不是一个简单的事,即使作者已经为了推理优化做了许多工作,但搭建一个DeepSeek V3的服务(考虑到它671B的参数量),成本依然不低。
02.
使用Milvus和DeepSeek搭建RAG
接下来,我们将展示如何使用Milvus和DeepSeek构建检索增强生成(RAG)pipeline。
2.1 准备
2.1.1 依赖和环境
pip install --upgrade pymilvus[model] openai requests tqdm如果您使用的是Google Colab,要启用刚刚安装的依赖项,您可能需要重启运行环境(单击屏幕顶部的“Runtime”菜单,然后从下拉框中选择“Restart session”)。
DeepSeek启动了OpenAI风格的API。您可以登录官网并将api密钥 DEEPSEEK_API_KEY准备为环境变量。
import osos.environ["DEEPSEEK_API_KEY"] = "***********"2.1.2 准备数据
我们使用Milvus文档2.4. x(https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip)中的FAQ页面作为RAG中的私有知识,这是搭建一个入门RAG pipeline的优质数据源。
首先,下载zip文件并将文档解压缩到文件夹milvus_docs。
! wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
! unzip -q milvus_docs_2.4.x_en.zip -d milvus_docs我们从文件夹milvus_docs/en/faq中加载所有markdown文件,对于每个文档,我们只需简单地使用“#”来分隔文件中的内容,就可以大致分隔markdown文件各个主要部分的内容。
from glob import globtext_lines = []for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):with open(file_path, "r") as file:file_text = file.read()text_lines += file_text.split("# ")2.1.3 准备LLM和embedding模型
DeepSeek采用了类OpenAI风格的API,您可以使用相同的API并对相应的LLM进行微调。
from openai import OpenAIdeepseek_client = OpenAI(api_key=os.environ["DEEPSEEK_API_KEY"],base_url="https://api.deepseek.com",
)选择一个embedding模型,使用milvus_model来做文本向量化。我们以DefaultEmbeddingFunction模型为例,它是一个预训练的轻量级embedding模型。
from pymilvus import model as milvus_modelembedding_model = milvus_model.DefaultEmbeddingFunction()生成测试向量,并输出向量维度以及测试向量的前几个元素。
test_embedding = embedding_model.encode_queries(["This is a test"])[0]
embedding_dim = len(test_embedding)
print(embedding_dim)
print(test_embedding[:10])768
[-0.04836066 0.07163023 -0.01130064 -0.03789345 -0.03320649 -0.01318448-0.03041712 -0.02269499 -0.02317863 -0.00426028]2.2 将数据加载到Milvus
2.2.1 创建集合
from pymilvus import MilvusClientmilvus_client = MilvusClient(uri="./milvus_demo.db")collection_name = "my_rag_collection"对于
MilvusClient需要说明:
将
uri设置为本地文件,例如./milvus. db,是最方便的方法,因为它会自动使用Milvus Lite将所有数据存储在此文件中。如果你有大规模数据,你可以在docker或kubernetes上设置一个更高性能的Milvus服务器。在此设置中,请使用服务器uri,例如
http://localhost:19530,作为你的uri。如果要使用Milvus的全托管云服务Zilliz Cloud,请调整
uri和token,分别对应Zilliz Cloud中的公共端点和Api密钥。
检查集合是否已经存在,如果存在则将其删除。
if milvus_client.has_collection(collection_name):milvus_client.drop_collection(collection_name)使用指定的参数创建一个新集合。
如果我们不指定任何字段信息,Milvus将自动为主键创建一个默认的id字段,并创建一个向量字段来存储向量数据。保留的JSON字段用于存储未在schema里定义的标量数据。
milvus_client.create_collection(collection_name=collection_name,dimension=embedding_dim,metric_type="IP", # Inner product distanceconsistency_level="Strong", # Strong consistency level
)2.2.2 插入数据
逐条取出文本数据,创建嵌入,然后将数据插入Milvus。
这里有一个新的字段“text”,它是集合schema中的非定义字段,会自动添加到保留的JSON动态字段中。
from tqdm import tqdmdata = []doc_embeddings = embedding_model.encode_documents(text_lines)for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):data.append({"id": i, "vector": doc_embeddings[i], "text": line})milvus_client.insert(collection_name=collection_name, data=data)Creating embeddings: 0%| | 0/72 [00:00<?, ?it/s]huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Creating embeddings: 100%|██████████| 72/72 [00:00<00:00, 246522.36it/s]
{'insert_count': 72, 'ids': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71], 'cost': 0}2.3 构建RAG
2.3.1 检索查询数据
让我们指定一个关于Milvus的常见问题。
question = "How is data stored in milvus?"在集合中搜索问题并检索语义top-3匹配项。
search_res = milvus_client.search(collection_name=collection_name,data=embedding_model.encode_queries([question]), # Convert the question to an embedding vectorlimit=3, # Return top 3 resultssearch_params={"metric_type": "IP", "params": {}}, # Inner product distanceoutput_fields=["text"], # Return the text field
)我们来看一下query的搜索结果
import jsonretrieved_lines_with_distances = [(res["entity"]["text"], res["distance"]) for res in search_res[0]
]
print(json.dumps(retrieved_lines_with_distances, indent=4))[[" Where does Milvus store data?\n\nMilvus deals with two types of data, inserted data and metadata. \n\nInserted data, including vector data, scalar data, and collection-specific schema, are stored in persistent storage as incremental log. Milvus supports multiple object storage backends, including [MinIO](https://min.io/), [AWS S3](https://aws.amazon.com/s3/?nc1=h_ls), [Google Cloud Storage](https://cloud.google.com/storage?hl=en#object-storage-for-companies-of-all-sizes) (GCS), [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs), [Alibaba Cloud OSS](https://www.alibabacloud.com/product/object-storage-service), and [Tencent Cloud Object Storage](https://www.tencentcloud.com/products/cos) (COS).\n\nMetadata are generated within Milvus. Each Milvus module has its own metadata that are stored in etcd.\n\n###",0.6572665572166443],["How does Milvus flush data?\n\nMilvus returns success when inserted data are loaded to the message queue. However, the data are not yet flushed to the disk. Then Milvus' data node writes the data in the message queue to persistent storage as incremental logs. If `flush()` is called, the data node is forced to write all data in the message queue to persistent storage immediately.\n\n###",0.6312146186828613],["How does Milvus handle vector data types and precision?\n\nMilvus supports Binary, Float32, Float16, and BFloat16 vector types.\n\n- Binary vectors: Store binary data as sequences of 0s and 1s, used in image processing and information retrieval.\n- Float32 vectors: Default storage with a precision of about 7 decimal digits. Even Float64 values are stored with Float32 precision, leading to potential precision loss upon retrieval.\n- Float16 and BFloat16 vectors: Offer reduced precision and memory usage. Float16 is suitable for applications with limited bandwidth and storage, while BFloat16 balances range and efficiency, commonly used in deep learning to reduce computational requirements without significantly impacting accuracy.\n\n###",0.6115777492523193]
]2.3.2 使用LLM获取RAG响应
将检索到的文档转换为字符串格式。
context = "\n".join([line_with_distance[0] for line_with_distance in retrieved_lines_with_distances]
)为LLM定义系统和用户提示。这个提示是由从Milvus检索到的文档组装而成的。
SYSTEM_PROMPT = """
Human: You are an AI assistant. You are able to find answers to the questions from the contextual passage snippets provided.
"""
USER_PROMPT = f"""
Use the following pieces of information enclosed in <context> tags to provide an answer to the question enclosed in <question> tags.
<context>
{context}
</context>
<question>
{question}
</question>
"""使用DeepSeek提供的deepseek-chat模型根据提示生成响应。
response = deepseek_client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system", "content": SYSTEM_PROMPT},{"role": "user", "content": USER_PROMPT},],
)
print(response.choices[0].message.content)In Milvus, data is stored in two main categories: inserted data and metadata.1. **Inserted Data**: This includes vector data, scalar data, and collection-specific schema. The inserted data is stored in persistent storage as incremental logs. Milvus supports various object storage backends for this purpose, such as MinIO, AWS S3, Google Cloud Storage (GCS), Azure Blob Storage, Alibaba Cloud OSS, and Tencent Cloud Object Storage (COS).2. **Metadata**: Metadata is generated within Milvus and is specific to each Milvus module. This metadata is stored in etcd, a distributed key-value store.Additionally, when data is inserted, it is first loaded into a message queue, and Milvus returns success at this stage. The data is then written to persistent storage as incremental logs by the data node. If the `flush()` function is called, the data node is forced to write all data in the message queue to persistent storage immediately.太好了!现在我们已经成功使用Milvus和DeepSeek构建了一个RAG pipeline。
作者介绍

王翔宇
Zilliz 算法工程师
推荐阅读




相关文章:
DeepSeek v3为何爆火?如何用其集成Milvus搭建RAG?
最近,DeepSeek v3(一个MoE模型,拥有671B参数,其中37B参数被激活)模型全球爆火。 作为一款能与Claude 3.5 Sonnet,GPT-4o等模型匹敌的开源模型DeepSeek v3不仅将其算法开源,还放出一份扎实的技术…...

linux-centos-安装miniconda3
参考: 最新保姆级Linux下安装与使用conda:从下载配置到使用全流程_linux conda-CSDN博客 https://blog.csdn.net/qq_51566832/article/details/144113661 Linux上删除Anaconda或Miniconda的步骤_linux 删除anaconda-CSDN博客 https://blog.csdn.net/m0_…...

html+css+js网页设计 美食 好厨艺西餐美食企业网站模板6个页面
htmlcssjs网页设计 美食 好厨艺西餐美食企业网站模板6个页面 网页作品代码简单,可使用任意HTML辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad 等任意html编辑软件进行运行及修改编辑等操作)。 …...

QT-窗口嵌入外部exe
窗口类: #pragma once #include <QApplication> #include <QWidget> #include <QVBoxLayout> #include <QProcess> #include <QTimer> #include <QDebug> #include <Windows.h> #include <QWindow> #include <…...
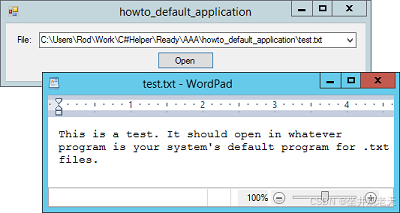
C#中使用系统默认应用程序打开文件
有时您可能希望程序使用默认应用程序打开文件。 例如,您可能希望显示 PDF 文件、网页或互联网上的 URL。 System.Diagnostics.Process类的Start方法启动系统与文件关联的应用程序。 例如,如果文件扩展名为.txt,则系统会在 NotePad、WordPa…...

如何在 Ubuntu 22.04 上配置 Logrotate 高级教程
简介 本教程将教你如何在 Ubuntu 22.04 上进行 Logrotate 的高级配置。 日志管理对于维护系统性能和确保你的日志不会占用太多磁盘空间至关重要。在 Ubuntu 上,logrotate 是一个强大的工具,它可以通过轮转、压缩和删除旧日志来自动管理日志文件。在本教…...

java项目之校园管理系统的设计与实现(源码+文档)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的校园管理系统的设计与实现。项目源码以及部署相关请联系风歌,文末附上联系信息 。 项目简介: springboot校园…...

关于 webservice 日志中 源IP是node IP的问题,是否能解决换成 真实的客户端IP呢
本篇目录 1. 问题背景2. 部署gitlab 17.52.1 添加repo源2.2 添加repo源 下载17.5.0的charts包2.3 修改values文件2.3.1 hosts修改如下2.3.2 appConfig修改如下2.3.3 gitlab下的sidekiq配置2.3.4 certmanager修改如下2.3.5 nginx-ingress修改如下2.3.6 <可选> prometheus修…...

Serializable接口
最近写项目的时候,发现有一些类要实现Serializable接口,一开始只是粗略的知道实现了Serializable接口,这个类的对象可以被序列化,但我比较轴,想知道这个接口到底有什么作用。 我点开这个接口发现什么方法都没有实现&am…...

如何操作github,gitee,gitcode三个git平台建立镜像仓库机制,这样便于维护项目只需要维护一个平台仓库地址的即可-优雅草央千澈
如何操作github,gitee,gitcode三个git平台建立镜像仓库机制,这样便于维护项目只需要维护一个平台仓库地址的即可-优雅草央千澈 问题背景 由于我司最早期19年使用的是gitee,因此大部分仓库都在gitee有几百个库的代码,…...
)
【HDU】1089 A+B for Input-Output Practice (I)
1089 AB for Input-Output Practice (I):以EOF结尾的输入 Problem Description Your task is to Calculate a b. Too easy?! Of course! I specially designed the problem for acm beginners. You must have found that some problems have the same titles with this one,…...

lua库介绍:数据处理与操作工具库 - leo
leo库简介 leo 模块的创作初衷旨在简化数据处理的复杂流程,提高代码的可读性和执行效率,希望leo 模块都能为你提供一系列便捷的工具函数,涵盖因子编码、多维数组创建、数据框构建、列表管理以及管道操作等功能。 要使用 Leo 模块,…...

逆向入门(1)C篇-正儿巴经的第1个实验
接触了这么久,第一次不是使用CV大法编写程序,认认真真的重头开始学习,记录一下找调试的感觉。 第一段代码,重温原码,反码和补码。 #include "stdafx.h"int main(int argc, char* argv[]) {char x -7;print…...

vue数据请求通用方案:axios的options都有哪些值
Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 Node.js 中。 在使用 Axios 发送请求时,可以通过传递一个配置对象来指定请求的各种选项。 以下是一些常用的 Axios 配置选项及其说明: 1.url: (必需)请求的 …...

使用R语言绘制标准的中国地图和世界地图
在日常的学习和生活中,有时我们常常需要制作带有国界线的地图。这个时候绘制标准的国家地图就显得很重要。目前国家标准地图服务系统向全社会公布的标准中国地图数据,是最权威的地图数据。 今天介绍的R包“ggmapcn”,就是基于最新公布的地图…...

【PyTorch】迁移学习、数据增强
PyTorch官网 介绍 PyTorch 是一个开源的机器学习库,由 Facebook 的人工智能研究实验室开发。它提供了两种主要的功能:张量计算(类似于 NumPy,但具有 GPU 加速)和基于动态计算图的深度学习工具。PyTorch 因其灵活性、…...

Lucas-Kanade光流法详解
简介:个人学习分享,如有错误,欢迎批评指正。 光流(Optical Flow)描述的是图像序列中各像素点随时间的运动情况,是计算机视觉中的基本问题之一。光流问题涉及尝试找出一幅图像中的许多点在第二幅图像中移动的…...

python多张图片生成/合成gif
你可以通过调整帧率来提高GIF的流畅度。默认情况下,代码中的帧率为每秒1帧(fps=1)。我们可以增加这个值来加快动画速度。 下面是修改后的代码,将帧率从每秒1帧提高到每秒5帧(你可以根据需要进一步调整): 在这个版本中,我添加了一个可选参数fps,默认值为5帧每秒。你可…...

iptable限制多个端口出站
iptable限制多个端口出站 安装包 rootiptable:/home/bb# apt-get update rootiptable:/home/bb# apt-get -y install iptables iptables-restoreweb准备 rootweb:/home/bb/test-iptables# docker run -itd --name web -p 80:80 -v ./web1/index.html:/usr/share/nginx/html…...

springmvc--请求参数的绑定
目录 一、创建项目,pom文件 二、web.xml 三、spring-mvc.xml 四、index.jsp 五、实体类 Address类 User类 六、UserController类 七、请求参数解决中文乱码 八、配置tomcat,然后启动tomcat 1. 2. 3. 4. 九、接收Map类型 1.直接接收Map类型 &#x…...
)
避坑指南:在Ubuntu 18.04上搞定RK3568的RKNN环境(附Python 3.6.x和Numpy 1.16.6配置)
RK3568开发环境避坑全指南:从零搭建RKNN-Toolkit2的终极方案 在边缘计算设备开发中,Rockchip的RK3568凭借其强大的NPU性能成为众多AI项目的首选平台。但初次接触RKNN开发套件的工程师们,往往会在环境配置阶段遭遇各种"暗坑"——从P…...

云原生环境中的DevOps最佳实践:从开发到运维的全流程优化
云原生环境中的DevOps最佳实践:从开发到运维的全流程优化 🔥 硬核开场 各位技术老铁们,今天咱们来聊聊云原生环境中的DevOps最佳实践。别跟我说你还在手动部署应用,那都2023年了!现在玩云原生,DevOps自动化…...

忍者像素绘卷效果评测:16-Bit美学下角色辨识度与动作张力表现
忍者像素绘卷效果评测:16-Bit美学下角色辨识度与动作张力表现 1. 评测概述 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工具,专为16-Bit复古风格设计。这款工具将传统忍者文化与像素艺术完美结合,创造出独特的视觉体验。本次评…...

HTML图片怎么用Bitbucket Pipelines发布_Bitbucket自动构建HTML站点
Bitbucket Pipelines 不能直接托管 HTML 站点,仅支持构建后推送到 GitHub Pages、Netlify 或自有服务器;需配置 SSH 密钥权限,用 git push 到 gh-pages 分支或 rsync 部署,并注意资源路径与 base URL 适配。Bitbucket Pipelines 能…...
 是字节跳动自研图像生成模型,Seedream API_KEY 怎么申请)
【人工智能】Seedream(即梦AI) 是字节跳动自研图像生成模型,Seedream API_KEY 怎么申请
Seedream(即梦AI) 是字节跳动自研图像生成模型,分国内火山引擎(火山方舟)官方、国际BytePlus、第三方中转平台三种API_KEY申请渠道,国内用户优先走火山引擎官方,无需翻墙、支持手机号、有免费额度,下面是完整详细步骤。 一、国内官方(火山引擎火山方舟,首选) Seed…...

CSS如何实现Less颜色函数自动计算渐变_使用lighten与darken实现视觉反馈
lighten() 和 darken() 按 HSL 的 L 分量线性调整亮度,非像素级明暗处理;需确保输入为 color 类型、慎用于高饱和色、避免链式调用,并配合 saturate 等增强视觉反馈。lighten() 和 darken() 在 Less 中怎么写才不翻车Less 的 lighten() 和 da…...

2026年降AI率工具排行榜怎么选?3招避开智商税
2026年毕业季一到,朋友圈、知乎、小红书上铺天盖地的"降AI率工具排行榜"就开始刷屏。今天这家说"全网第一",明天那家又"权威评测",榜单的前三名永远在换人。我帮三届学弟学妹选过工具,也自己踩过不少坑,今天就…...

算法训练营第六天
题目链接: https://leetcode.cn/problems/reverse-linked-list/ 视频链接: https://www.bilibili.com/video/BV1nB4y1i7eL 看到题目的第一想法: 一开始觉得不就是把链表倒过来吗?但真的上手写代码时,才发现问题没…...

为什么Top 5 IDE厂商2024 Q2集体升级“生成式推荐”?3个被忽略的实时反馈闭环设计,让推荐不再“猜”,而能“推演”
第一章:智能代码生成与代码推荐结合的范式跃迁 2026奇点智能技术大会(https://ml-summit.org) 传统代码补全工具依赖局部上下文统计建模,而新一代智能编程系统正将生成式大模型与实时语义感知推荐引擎深度耦合,实现从“词级预测”到“意图驱…...

全球变暖 BFS
全球变暖 问题描述 给定一张 NN 像素的海域照片,其中: . 表示海洋# 表示陆地 岛屿定义为上下左右四个方向上连通的陆地组成的区域。全球变暖导致岛屿边缘(即与海洋相邻的陆地)会被淹没。要求计算有多少岛屿会被完全淹没。 输…...