聚类系列 (二)——HDBSCAN算法详解
在进行组会汇报的时候,为了引出本研究动机(论文尚未发表,暂不介绍),需要对DBSCAN、OPTICS、和HDBSCAN算法等进行详细介绍。在查询相关资料的时候,发现网络上对于DBSCAN算法的介绍非常多与细致,但是对于OPTICS或者HDBCCAN算法的介绍要么是直接照抄一个在线文档的算法介绍,要么就是未能完整的讲出该算法的原理。为了能够给大家提供一个都能看懂的HDBSCAN算法介绍,于是有了该篇文章。
下面进入关于HDBSCAN算法的正文内容,主要包括:HDBSCAN算法提出的动机、HDBSCAN算法的原理、HDBSCAN算法的优缺点、HDBSCAN算法的优缺点、HDBSCAN算法的实例介绍等。
文章目录
- 从DBSCAN到HDBSCAN
- DBSCAN
- OPTICS
- OPTICS 算法的优化与原理
- HDBSCAN
- HDBSCAN 的引入
- HDBSCAN 算法的原理与具体步骤
- 1. 样本点互达距离计算(距离空间变换)
- 压缩层次聚类树
- 提取稳定簇(打标签)
- HDBSCAN算法的优势
- HDBSCAN算法的不足
- 总结
- Reference
从DBSCAN到HDBSCAN
DBSCAN
为了理解HDBSCAN,首先需要理解DBSCAN算法的原理。
DBSCAN(Density-based Spatial Clustering of Applications with Noise)是一种基于密度扩展的聚类算法。顾名思义,从该算法名称中可以发现,该算法的核心思想在于样本密度的定义以及如何基于样本的密度扩展类簇。
DBSCAN算法认为类簇是由一系列被稀疏区域分隔开来的密集区域组成的。
该算法通过两个关键参数:Eps(邻域半径)和MinPts(邻域内包含的最小样本数量),定义样本的密度。
-
如果一个样本点在用户指定的邻域半径中,包含至少MinPts个样本,那么该样本被定义为一个**核心对象**。核心样本邻域内的其他样本被称为直接可达对象 。如何直接可达对象满足Eps和MinPts参数约束,其也是一个核心对象。核心对象可以用来吸引其他对象加入同一个簇。
-
对于位于核心对象邻域内、但是不满足核心对象定义的样本,被称为边界对象。
-
既不是核心对象,也不是边界对象的样本则被称为噪声点。通过该定义,可以发现DBSCAN算法能够识别噪声点的原因。
DBSCAN算法的原理就是通过寻找核心对象,并不断扩展加入核心对象邻域内的样本(判断是否为核心对象,然后继续扩展),从而形成一个簇。不在任何核心对象邻域内的样本且无法形成核心对象的样本则被视为异常值,不被分配到任何簇。
DBSCAN算法能够发现任意形状和大小的簇,并且能够识别噪声,对噪声具有很强的鲁棒性。但是同时,由于这两个参数是全局的,导致DBSCAN算法无法发现不同密度(尤其是密度差异较大、并且与密集簇邻近分布)的簇。
此外,这两个参数的设置依赖于对数据集的先验认知(也可以使用网格搜索等方法进行参数优化)。
OPTICS
为了克服DBSCAN算法参数设置的局限性,学者Ankerst等提出了OPTICS(Ordering Points to Identify the Clustering Structure)算法。OPTICS 是 DBSCAN 的一种改进版本,它不再需要通过固定的全局参数(Eps 和 MinPts)来定义密度,而是通过一种排序方式来揭示数据集中的聚类结构,从而解决DBSCAN算法参数设置的困难。
OPTICS 算法的优化与原理
OPTICS 的核心思想是通过记录每个点的 核心距离(Core Distance)和 可达距离(Reachability Distance),以一种可视化的方式展示数据的聚类结构。具体来说:
-
核心距离 (Core Distance):
- 对于一个点,如果其邻域内有足够的点(至少 MinPts 个点),则核心距离定义为该点到其邻域内第 MinPts 个最近点的距离(点到邻域内点的最大距离)。
- 如果一个点的邻域内不足 MinPts 个点,则核心距离未定义Undefined(表示为无穷大)。
-
可达距离 (Reachability Distance):
-
对于两个点 A 和 B,点 B 相对于点 A 的可达距离是点 A 的核心距离和点 A 到点 B 的欧氏距离之间的较大值。
-
直观上,可达距离表示一个点从另一个点“被密度连接”的难易程度,量化了两个样本点之间被密集区域所连接的最大距离。可达距离越小,说明两个点之间连线经过的稀疏区域越小,它们之间的密集程度越高。
-

- 数据排序:
- OPTICS 通过一个类似于 DBSCAN 的过程对数据进行排序,优先处理核心距离较小的点(即更密集区域的点),将点按照密度从高到低进行访问。
- 每个点在被访问时,会更新其邻域中未访问点的可达距离。
- 密度聚类结构:
- OPTICS 不直接输出聚类结果,而是生成一个可视化的“可达距离图”(Reachability Plot)。通过观察图中呈现的“山谷”(低可达距离的区域),可以识别不同密度的簇。

OPTICS算法的优点包括:不需要提前固定Eps参数,可以通过核心距离和可达距离动态调整密度阈值,能够发现不同密度的簇。其次,与 DBSCAN 类似,OPTICS 也能够识别噪声点(即在可达距离图中位于高可达距离的点)。
然而,OPTICS算法也存在一定的局限性,主要体现在:**复杂度较高(**需要维护可达距离和排序)。其次,簇提取困难(OPTICS输出一个有序的点序列,不显式给出聚类结果,仍需要额外的步骤和方法从序列中提取真正的簇)。参数敏感性(仍然需要指定参数minPts,其选择对最终聚类结果有很大影响,尤其是在处理高维数据或密度分布不均匀的数据集时)。可达距离的局限性(不对称,仅考虑了从一个点到另一个点的距离)
HDBSCAN
HDBSCAN 的引入
为了进一步改进密度聚类算法的灵活性和效率,学者们提出了 HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)算法。HDBSCAN 是 DBSCAN 的一种层次化扩展,结合了密度聚类和层次聚类的思想,其核心在于通过一个密度分层树(Density Hierarchy Tree)来表征数据的聚类结构。
- 密度定义的改进:
- HDBSCAN使用相对密度的概念,而不是固定的绝对密度阈值(如DBSCAN的固定Eps参数)。相对密度考虑了数据点与其核心距离(core distances)的比较,而不是单纯的邻域半径,这使得算法能够自动适应不同区域的密度差异。
- 通过计算互达距离(Mutual Reachability Distance)来定义点之间的密度连接关系,而不是简单的欧式距离。互达距离更加稳健(保持密集区域的数据点密度不变,降低稀疏区域的数据点的密度),能过更好处理不同密度的区域,从而识别出不同密度的轨迹。(互达距离其实是对OPTICS算法中可达距离的一种改进,同时考虑两个样本点的局部点分布)
- 密度层次化聚类:
- HDBSCAN 通过对密度逐步降低的过程进行跟踪,生成一个密度分层树。
- 在密度分层树中,叶子节点代表高密度区域的簇,而根节点表示整个数据集。
- 自动化簇提取:
- 与 OPTICS 需要手动观察可达距离图不同,HDBSCAN 提供了一个自动化的簇提取方法,通过定义一个稳定性指标(Stability)来评估每个簇的持久性,并自动选择最稳定的簇作为最终聚类结果。
HDBSCAN 算法的原理与具体步骤
关于HDBSCAN算法的原理与步骤,目前网络上最出名的两个博客分别是:https://www.biaodianfu.com/hdbscan.html和https://hdbscan.readthedocs.io/en/latest/how_hdbscan_works.html,前者其实是后者的中文版。网络上的其他博客大多也会这两个内容的搬运,本文在撰写的过程中也难免会借鉴其中的内容,但是会加上自己对该算法的思考以及更加详细的原理讲解,确保提供一个大家都能看到的HDBSCAN原理介绍博客。
1. 样本点互达距离计算(距离空间变换)
在开源的各种聚类算法的代码库中,我们可以发现有一个参数metric,该参数的可取值包括:Euclidean, pre-computed 等。其中pre-computed表示提前计算好样本数据之间的距离,直接输入一个 N ∗ N N*N N∗N的距离矩阵 (其中 N N N是样本数据的数量)。该距离可以是欧式距离,网络距离,曼哈顿距离等。
在HDBSCAN算法中,需要将输入的预先计算好的原始距离矩阵(如欧式距离)进行一个距离空间转换(原始距离空间转换为互达距离(mutual reachability distance)空间)。距离空间转换旨在更好地识别数据中的密集区域和稀疏区域。
距离空间转换需要解决以下两个问题:
- 密度差异问题:在同一数据集中,可能存在密度相差很大的聚类。简单使用原始距离可能会导致密度较低的聚类被忽略。距离空间转换可以"放大"稀疏区域,使得不同密度的聚类能够被更好地识别。
- 噪声数据识别问题:噪声数据通常分布较为稀疏,与聚类之间的距离较远。使用原始距离可能难以区分噪声与真实聚类。距离空间转换通过"压缩"密集区域,从而使噪声点与聚类之间的距离差异更加明显,有助于识别噪声数据。
HDBSCAN算法采用了一种称为互达距离(mutual reachability distance)的距离空间转换方式。具体来说,对于任意两个样本点 p p p和 q q q,首先计算他们各自的核心距离,反应其局部密度:
- 计算点 p p p到其所有 k k k近邻点的核心距离,取最大值作为 p p p的核心距离 c o r e k ( p ) core_k(p) corek(p)
- 计算点 q q q到其所有 k k k近邻点的核心距离,取最大值作为 q q q的核心距离 c o r e k ( q ) core_k(q) corek(q)
然后取他们的核心距离和原始距离之间的最大值作为互达距离。可以看出,互达距离“放大了"稀疏区域的距离,同时"压缩"了密集区域内的距离。这种转换能更好地反映数据本身的密度分布特征,有利于后续的聚类分析。
d m r e a c h − k ( p , q ) = m a x { c o r e k ( p ) , c o r e k ( q ) , d ( p , q ) } d_{mreach-k}(p,q)=max\{{core_k(p),core_k(q),d(p,q)}\} dmreach−k(p,q)=max{corek(p),corek(q),d(p,q)}

在新的距离空间中,基于数据点之间的互达距离构建一个最小生成(MST)。每个节点代表一个数据点,边的权重为两个节点之间的互达距离。
数据点之间的互达距离矩阵首先会形成一个加权的完全连通图(图上任意两个节点都是连通的)。为了有效地表示数据点的密度连接关系并降低计算复杂度,需要从完全连通图中提取一个最小生成树(MST)。
最小生成树提供了一种划分数据的自然方式。通过移除MST中权重最大的边,整个图就被分割成了两个连通分量,对应着两个密集的数据簇。重复这个过程,移除下一个最大权重的边,整个图就被进一步分割成更多的连通分量。这个连续的裁剪过程会产生一个分层的簇结构,从而揭示出数据的层次聚类关系。
在具体实现中,可以选择Prime算法构建生成树。Prime算法的原理为:
-
选择一个任意节点作为起始节点,并将其添加到
MST中。 -
创建一个优先队列
Q,用于存储与MST中节点相邻的边,并按照边的权重(互达距离)升序排列。 -
将起始节点的所有邻边添加到
Q中。 -
重复以下步骤,直到
MST中包含n-1条边:-
从
Q中取出权重最小的边。 -
如果该边连接的另一个节点不在
MST中,则将该边和节点添加到MST中,并将该节点的邻边添加到Q中。
-
生成的MST包含了所有数据点,并且边的权重总和最小。这棵树保留了数据点之间最重要的密度连接信息,并为后续的层次聚类提供了基础。
注意:MST可能不是唯一的,如果有多个权重相同的最小生成树,算法会返回其中一个。
下图给出了一个简单的构建的最小生成树的示例:[在这里插入图片描述](https://i-

基于最小生成树构建层次聚类树(Hierarchy Tree)是HDBSCAN算法的核心步骤。最小生成树的每个节点表示一个数据点,边的权重表示数据点之间的互达距离。为了生成层次聚类树,可以按照如下步骤:
-
初始化:将 MST 中的每条边按照其权重(即两点之间的可达距离)排序。
-
构建层次结构:初始化一个森林,每个数据点都是一个独立的簇。然后便利排序后的MST,从权重最小的边开始,逐步添加边到聚类树中。每当添加一条边时,都会有两种可能情况:
- 该边连接的两个点属于两个不同的簇,则将这两个簇合并为一个新簇;
- 该边连接的两个点在同一个簇内,则不进行合并操作。
重复这个过程,直到遍历完所有的边,得到一个包含多层次结构的层次树结构。
如下的GIF图是基于上述示例的最小生成树构建层次聚类树的动态过程。

根据如图所示的层次聚类树,为了得到不同的簇,我们可以直接画一条水平线将层次树切分为不同的簇(其实就是根据一个单一的互达距离的阈值将层次树分为不同的子树,每个子树表示一个簇),如下图所示。

但是这样根据一个全局、单一的互达距离阈值,存在以下问题:
- 无法处理不同密度的簇。由于使用了全局阈值,在密集区域可能会将不同的簇合并在一起,而在稀疏区域可能会将本应属于同一簇的点分割开来。
- 噪声点可能会被错误地划分到某个簇中。全局阈值无法很好地区分真正的簇和噪声点。
- 无法识别层次结构中最稳定的簇 - 某些簇可能在较宽的距离范围内都保持稳定,而另一些簇可能仅在特定距离下才显著。单一阈值无法捕获这种差异。
因此,我们需要一个更加稳健的方法从构建的聚类层次结构中提取簇。
压缩层次聚类树
在层次聚类树构建完成后,需要进行树的压缩,即将一颗大的层次树压缩为多个小的子簇结构。
在压缩树的过程中,HDBSCAN定义了一个参数:minimum cluster size,用于控制层次聚类树的拆分,这是一个自顶向下的过程。具体来说:
- ① 从层次树的根节点开始,将整个数据集视为一个大簇。
- ② 对于当前簇,如果其包含的数据点数量小于minimum cluster size,则将其标记为"噪声簇",不予考虑。
- ③ 如果当前簇的大小大于或等于minimum cluster size,则进一步检查它的子节点(子簇):
- 如果所有子簇的大小都小于minimum cluster size,则将当前簇标记为一个稳定簇,保留下来。
- 如果存在子簇的大小大于或等于minimum cluster size,则对这些大的子簇递归执行步骤②和③,继续向下拆分。
- ④ 重复步骤②和③,直到没有可拆分的大簇为止。
- 最终,层次树被拆分成多个互不相交的子树,每个子树的根节点都minimum cluster size的约束。
通过这种自顶向下的拆分策略,HDBSCAN逐步将原始的整体层次树压缩为规模较小、互不重叠的子树结构。每个子树代表一个相对稳定、大小合理的簇。同时,噪声簇和过小的簇被剔除。
通过这种方式,HDBSCAN能够自动确定合适的簇数量,而不需要人为指定簇数或其他聚类参数。生成的簇的形状、大小和密度也可以是任意的。
该压缩过程的关键是minimum cluster size参数,它控制着簇被切分或保留的阈值。较大的值会导致更大规模、更扁平的簇,较小的值会产生更多层次细节。因此,可以根据具体应用场景调整该参数来获得理想的聚类粒度。
提取稳定簇(打标签)
虽然通过上述压缩树的方式,我们将一颗大的层次树分解为多个小的子簇(每个子簇满足minimum cluster size约束),但是这样会忽略簇的稳定性与生命周期,因为我们希望所提取的簇不仅能够稳定存在而且具有更长的生命周期,能在较大密度范围内保持簇的稳定性。为了达到这目标,HDBSCAN引入了对簇稳定性与生命周期的考量。
具体来说,HDBSCAN 引入两个重要概念:簇的稳定性和用于度量簇稳定性的指标 λ {λ} λ。
λ {λ} λ被定义为数据点之间互达距离的倒数,即 λ = 1 / d i s t a n c e λ=1/distance λ=1/distance。基于 λ {λ} λ,HDBSCAN通过引入 λ b i r t h {λ_{birth}} λbirth和 λ d e a t h {λ_{death}} λdeath和 λ p {λ_p} λp 对簇的稳定性和生命周期进行了量化,其中:
- λ b i r t h {λ_{birth}} λbirth 指使得当前簇作为独立簇存在的最大 λ {λ} λ值。
- λ d e a t h {λ_{death}} λdeath 指使当前簇不再作为一个独立簇(簇的消失)、开始分裂为更小子簇的λ值,即当前簇失去独立性的密度阈值。这个值表示在该密度水平下,簇不再作为一个独立的实体存在,而是被分解为更小的子簇。
- λ p {λ_p} λp 则是指簇中数据点 p p p "脱离簇’'时的 λ {λ} λ值。对于簇内的每个点 p p p,其 λ λ λ 值介于 λ b i r t h {λ_{birth}} λbirth和 λ d e a t h {λ_{death}} λdeath, λ p {λ_p} λp实际上反映了点 p p p到所在簇的最小“边缘”距离。如果 p p p接近 λ b i r t h {λ_{birth}} λbirth,说明点 p p p 处于簇的内部,离群倾向较小;如果 λ p {λ_p} λp接近 λ d e a t h {λ_{death}} λdeath,说明点 p p p 处于簇的边缘,离群倾向较大,如果 λ p {λ_p} λp大于 λ d e a t h {λ_{death}} λdeath,说明点 p p p 已经不再属于该簇。 λ p {λ_p} λp
值可以作为评估点 p p p 相对于簇的内外倾向的一个度量标准。HDBSCAN利用了这一度量,在提取稳定簇时,保留 λ p {λ_p} λp值较小的内部点,剔除 λ p {λ_p} λp值较大的边缘噪音点,从而获得相对稳定的簇结构。
因此,簇的稳定性(stability)可以定义为:
s c l u s t e r = ∑ p ∈ c l u s t e r ( λ p − λ b i r t h ) s_{cluster}=\sum_{p∈cluster} (λ_p-λ_{birth}) scluster=p∈cluster∑(λp−λbirth)
当所有点的 λ p {λ_p} λp都等于 λ d e a t h {λ_{death}} λdeath时, s c l u s t e r = 0 s_{cluster}=0 scluster=0, 表示簇内所有点具有相同的密度水平。否则 s c l u s t e r s_{cluster} scluster小于0,因为 λ b i r t h ≤ λ p {λ_{birth}}≤{λ_p} λbirth≤λp≤ λ d e a t h {λ_{death}} λdeath,所以 s c l u s t e r ≤ 0 s_{cluster}≤0 scluster≤0。
压缩簇是自顶向下分裂的过程,提取簇则是自底向上合并簇和过程。
具体提取的过程如下:
① 自底向上遍历压缩树
② 对每个节点:
- 计算该节点的稳定性 s c l u s t e r s_{cluster} scluster;
- 计算其直接子节点的稳定性总和;
- 比较这两个值,选择稳定性更大的方案
- 当遇到“子簇稳定性之和 > 父簇自身稳定性”的情况时 (分裂成两个簇更好) :将保留子簇们作为独立的平坦簇输出,而放弃父簇(不会作为一个独立的簇输出)。
- 该簇的稳定性被设置为子簇稳定性之和
- 该簇的所有子簇保留"选定"状态。
- 当遇到“父簇稳定性 >= 子簇稳定性之和”的情况时 (两个子簇合并为一个簇更好) :将保留父簇作为平坦簇输出,而放弃子簇们(不会被单独输出)。
- 该簇被"选定";
- 该簇所有子簇的"选定"状态被取消;
- 当遇到“子簇稳定性之和 > 父簇自身稳定性”的情况时 (分裂成两个簇更好) :将保留子簇们作为独立的平坦簇输出,而放弃父簇(不会作为一个独立的簇输出)。
③ 遍历完成后,根节点处的"选定"簇就是要输出的平坦簇集合
这样的策略可以确保输出的每个平坦簇不仅满足最小簇大小,而且具有良好的生命周期和stability,即规模合理、内部紧密且在较大密度范围内保持稳定(稳定持久的簇结构)。同时,它避免了将稳定性较低的簇不适当地保留或合并。每个输出的平坦簇代表一个在全局上相对分离且内部相对紧凑的数据模式。
- 提取的簇满足最小尺寸要求
- 簇具有足够的稳定性
- 避免过度分裂或不当合并
- 保留数据中最显著的层次结构
HDBSCAN算法的优势
- HDBSCAN是一种基于密度的层次聚类算法,能够自动确定簇的数量,不需要提前指定簇的数量或者借助其他手段评估可能的簇数量。
- 与DBSCAN一样,能够发现任意形状的簇,但是相比DBSCAN算法无法区分不同密度的簇(尤其是密度差异较大的簇),HDBSCAN算法能够处理密度分布差异较大的数据集。
- 不同于 OPTICS,HDBSCAN 提供了自动的簇提取机制,无需手动调整参数或观察可达距离图。
- 更少的参数依赖,HDBSCAN 只需要一个主要参数 MinClusterSize(最小簇大小),易于设置。
HDBSCAN算法的不足
虽然HDBSCAN在处理不同形状和密度的簇方面表现出色,但也存在一些局限性:。
- **参数敏感性: **HDBSCAN 的性能仍受
min_cluster_size和min_samples参数的影响。min_cluster_size控制最小簇的大小,min_samples影响单个点的密度估计。不合适的参数设置可能导致识别出过少或过多的簇,或者产生不符合预期的簇结构。 - 计算复杂度: HDBSCAN 需要构建层次聚类树并计算每个点的核心距离,这在大型数据集上可能非常耗时。虽然有一些优化策略可以提高计算效率,但在大规模数据场景下,HDBSCAN 的计算成本仍然较高。
-
总结
DBSCAN、OPTICS 和 HDBSCAN 都是基于密度的聚类算法,它们在处理复杂数据分布、发现任意形状簇和识别噪声点方面表现良好。DBSCAN 是密度聚类的基础算法,OPTICS 改进了其对不同密度簇的适应性,而 HDBSCAN 进一步结合了层次聚类的思想,并提供了自动化的簇提取方法,适用于更广泛的场景。
Reference
[1] Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]//kdd. 1996, 96(34): 226-231.
[2] Campello R J G B, Moulavi D, Sander J. Density-based clustering based on hierarchical density estimates[C]//Pacific-Asia conference on knowledge discovery and data mining. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013: 160-172.
[3] Ankerst M, Breunig M M, Kriegel H P, et al. OPTICS: Ordering points to identify the clustering structure[J]. ACM Sigmod record, 1999, 28(2): 49-60.
[4] Schubert E, Sander J, Ester M, et al. DBSCAN revisited, revisited: why and how you should (still) use DBSCAN[J]. ACM Transactions on Database Systems (TODS), 2017, 42(3): 1-21.
[5] https://hdbscan.readthedocs.io/en/latest/how_hdbscan_works.html#condense-the-cluster-tree
[6] https://www.biaodianfu.com/hdbscan.html
相关文章:
聚类系列 (二)——HDBSCAN算法详解
在进行组会汇报的时候,为了引出本研究动机(论文尚未发表,暂不介绍),需要对DBSCAN、OPTICS、和HDBSCAN算法等进行详细介绍。在查询相关资料的时候,发现网络上对于DBSCAN算法的介绍非常多与细致,但…...

AngularJS HTML DOM
关于《AngularJS HTML DOM》的文章,我找到了一些有用的信息。这篇文章主要介绍了AngularJS如何通过特定的指令与HTML DOM元素进行交互。以下是一些关键点: ng-disabled 指令:这个指令用于将应用程序数据绑定到HTML的disabled属性。例如&#…...

C语言延时实现
C语言延时实现 在C语言中,delay 函数通过空循环实现延时,而不是像其他高级语言(如Python)直接使用 sleep 函数。这种实现方式是基于单片机的特性和C语言的底层操作。下面详细解释为什么这种空循环可以实现延时,以及它…...

OSI模型的网络层中产生拥塞的主要原因?
( 1 )缓冲区容量有限;( 1.5 分) ( 2 )传输线路的带宽有限;( 1.5 分) ( 3 )网络结点的处理能力有限;( 1 分…...

机器学习周报-ModernTCN文献阅读
文章目录 摘要Abstract 0 提升有效感受野(ERF)1 相关知识1.1 标准卷积1.2 深度分离卷积(Depthwise Convolution,DWConv)1.3 逐点卷积(Pointwise Convolution,PWConv)1.4 组卷积(Grou…...
什么是网关路由
1.认识网关 网关(Gateway)和路由(Router)是两个相关但不同的概念。 一、网关(Gateway) 定义 网关是一个网络节点,它充当了不同网络之间的连接点。可以将其看作是一个网络的 “大门”…...

信号的产生、处理
一、信号的概念 信号是linux系统提供的一种,向指定进程发送特定事件的方式。收到信号的进程,要对信号做识别和处理。信号的产生是异步的,进程在工作过程中随时可能收到信号。 信号的种类分为以下这么多种(用指令kill -l查看&…...

在Linux中,zabbix如何监控脑裂?
在Linux中,zabbix监控脑裂主要涉及对高可用(HA)系统中可能发生的节点间通信中断或不一致状态的监控。脑裂问题通常发生在具有冗余节点的高可用系统中,如集群、HA系统或分布式数据库系统,当节点之间失去通信时ÿ…...

C++基础概念复习
前言 本篇文章作基础复习用,主要是在C学习中遇到的概念总结,后续会继续补充。如有不足,请前辈指出,万分感谢。 1、什么是封装,有何优点,在C中如何体现封装这一特性? 封装是面向对象编程&…...

Earth靶场
打开靶机后使用 arp-scan -l 查询靶机 ip 我们使用 nmap 进行 dns 解析 把这两条解析添加到hosts文件中去,这样我们才可以访问页面 这样网站就可以正常打开 扫描ip时候我们发现443是打开的,扫描第二个dns解析的443端口能扫描出来一个 txt 文件 dirsear…...

JavaScript 日期格式
在 JavaScript 中,日期格式可以通过 Date 对象进行操作和格式化。下面是一些常见的 JavaScript 日期格式及其示例: 1. ISO 8601 格式 ISO 8601 是一种标准的日期和时间表示方法,格式为 YYYY-MM-DDTHH:mm:ss.sssZ,例如: let date = new Date(); console.log(date.toISOS…...

django vue3实现大文件分段续传(断点续传)
前端环境准备及目录结构: npm create vue 并取名为big-file-upload-fontend 通过 npm i 安装以下内容"dependencies": {"axios": "^1.7.9","element-plus": "^2.9.1","js-sha256": "^0.11.0&quo…...

xiaoya小雅超集使用夸克网盘缓存教程
距离上一次小白写到关于小雅的教程已经过去了一周的时间,这段时间里,有很多小伙伴都想知道怎么用夸克网盘作为小雅的缓存。 今天这不就来了吗? 这段时间确实是比较忙,毕竟快过年了嘛,辛辛苦苦一整年,至少…...

计算机基础知识复习1.4
数据库事务 #开启一个事务 start transaction #执行SQL语句 SQL1 SQL2 .. #提交事务 commit 类加载器 启动类加载器:负责加载Java的核心库 用C编写,是JVM的一部分,启动类加载器无法被Java程序直接引用 扩展类加载器:是Java语…...

SpringMVC(三)请求
目录 一、RequestMapping注解 1.RequestMapping的属性 实例 1.在这里创建文件,命名为Test: 2.复现-返回一个页面: 创建test界面(随便写点什么): Test文件中编写: 编辑 运行: 3.不返回…...

Node.js应用程序遇到了内存溢出的问题
vue 项目 跑起来,一直报错,内存溢出 在 文件node_modules 里 .bin > vue-cli-service.cmd 在依赖包这个文件第一行加上这个 node --max-old-space-size102400 "%~dp0\..\vue\cli-service\bin\vue-cli-service.js" %* node --max-old-s…...

如何构建云原生时空大数据平台?
在现代企业中,随着对技术的依赖日益加深,空间数据的重要性愈发显著。它通过结合地理成分(如纬度、经度、地址、邮编等)与业务数据,成为解决复杂问题的重要工具。地理空间数据可从多种来源获取,例如卫星影像…...
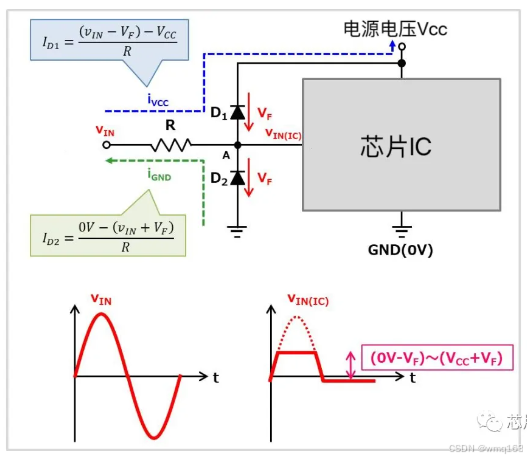
二极管钳位电路分享
二极管钳位(I/O的过压/浪涌保护等) 如果我们的电路环境接收外部输入信号容易受到噪声影响,那我们必须采取过压和浪涌保护措施,其中一个方式就是二极管钳位保护。 像上图,从INPUT输入的电压被钳位在-Vf与VCCVf之间&…...

腾讯云智能结构化 OCR:驱动多行业数字化转型的核心引擎
在当今数字化时代的汹涌浪潮中,数据已跃升为企业发展的关键要素,其高效、精准的处理成为企业在激烈市场竞争中脱颖而出的核心竞争力。腾讯云智能结构化 OCR 技术凭借其前沿的科技架构与卓越的功能特性,宛如一颗璀璨的明星,在交通、…...

19.3、Unix Linux安全分析与防护
目录 UNIX/Linux系统的安全分析与防护UNIX/Linux系统安全增强技术UNIX/Linux安全模块应用参考国产操作系统安全分析与防护 UNIX/Linux系统的安全分析与防护 unix和linux操作系统分成三层,分别是硬件层,系统内核层以及应用层。Windows系统也是分成三层&a…...

LeagueAkari:英雄联盟玩家的终极效率工具,3大核心技术革新游戏体验
LeagueAkari:英雄联盟玩家的终极效率工具,3大核心技术革新游戏体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Lea…...

SEONIB 如何重新定义电商卖家的全球增长路径
一个普遍存在的认知误区及其现实后果 在当前的数字商业环境中,存在一个广泛流传但极具误导性的观点,即搜索引擎优化是一项仅适用于大型企业或拥有专门技术团队的复杂工程。这种认知导致无数电商卖家——无论是独立站运营者、平台卖家,还是新…...

CompressO:如何在本地设备上安全高效地压缩视频与图片文件
CompressO:如何在本地设备上安全高效地压缩视频与图片文件 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/co/compres…...

Windows 上安装APK应用:告别模拟器,3种方法轻松搞定
Windows 上安装APK应用:告别模拟器,3种方法轻松搞定 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上直接运行Android应…...

Nano-Banana镜像免配置部署:Docker+Streamlit极简交互环境搭建
Nano-Banana镜像免配置部署:DockerStreamlit极简交互环境搭建 1. 引言:让结构拆解变得简单高效 如果你是一名设计师、工程师或创意工作者,一定遇到过这样的需求:需要将复杂的产品拆解成清晰的部件展示图。传统方法需要专业的3D建…...

Mintegral 广告平台 ROI 指数排名进入全球前四,多维度数据验证全球流量竞争力
2026年4月,全球知名移动营销归因机构 Singular 发布了《Singular ROI Index 2026》报告。程序化互动式广告平台 Mintegral 凭借稳定的流量质量、精准的触达能力以及出色的获客表现,成功入选“ROI 指数榜”和“MTA ROI 排行榜”两大榜单。从整体表现来看&…...
的3个高效安装技巧与实战避坑)
别再手动配置了!Dify插件市场(Marketplace)的3个高效安装技巧与实战避坑
别再手动配置了!Dify插件市场(Marketplace)的3个高效安装技巧与实战避坑 当团队协作规模扩大到5个以上Workspace时,插件管理就会从便利工具变成运维噩梦。上周处理的一个典型案例:某AI中台团队在同步更新20个Workspace的Google Search插件时&…...

AI 答疑助手优化实践:从 RAG 到 LightRAG 的全链路升级
本文针对传统RAG存在的意图识别模糊、知识碎片化及缺乏评测闭环等痛点,提出了一套系统性解决方案:首先,利用思维链(CoT)驱动的意图识别,将用户问题分解为多步逻辑查询并行检索,解决了上下文工程…...

# Bug 报告:openai-codex provider broken since 2026.4.5 �� Cloudflare challenge + missing OAuth scope /
Bug 报告:openai-codex provider broken since 2026.4.5 �� Cloudflare challenge + missing OAuth scope / openai-codex provider broken since 2026.4.5 - Cloudflare challenge + missing OAuth scope 链接: https://blog.csdn.net/cosmoslife 作者: cosmoslife 日期: 2…...

Clawdbot代理网关快速上手:5分钟部署Qwen3:32B本地大模型
Clawdbot代理网关快速上手:5分钟部署Qwen3:32B本地大模型 1. 为什么选择ClawdbotQwen3:32B组合 在本地部署大语言模型时,开发者常面临两个核心痛点:一是缺乏友好的交互界面,二是模型管理复杂。Clawdbot代理网关与Qwen3:32B的组合…...