【计算机视觉技术 - 人脸生成】2.GAN网络的构建和训练
GAN 是一种常用的优秀的图像生成模型。我们使用了支持条件生成的 cGAN。下面介绍简单 cGAN 模型的构建以及训练过程。
2.1 在 model 文件夹中新建 nets.py 文件
import torch
import torch.nn as nn# 生成器类
class Generator(nn.Module):def __init__(self, nz=100, nc=3, ngf=128, num_classes=4):super(Generator, self).__init__()self.label_emb = nn.Embedding(num_classes, nz)self.main = nn.Sequential(nn.ConvTranspose2d(nz + nz, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8),nn.ReLU(True),nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),nn.Tanh())def forward(self, z, labels):c = self.label_emb(labels).unsqueeze(2).unsqueeze(3)x = torch.cat([z, c], 1)return self.main(x)# 判别器类
class Discriminator(nn.Module):def __init__(self, nc=3, ndf=64, num_classes=4):super(Discriminator, self).__init__()self.label_emb = nn.Embedding(num_classes, nc * 64 * 64)self.main = nn.Sequential(nn.Conv2d(nc + 1, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 2),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 4),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(ndf * 4, 1, 4, 1, 0, bias=False),nn.Sigmoid())def forward(self, img, labels):c = self.label_emb(labels).view(labels.size(0), 1, 64, 64)x = torch.cat([img, c], 1)return self.main(x)2.2新建cGAN_net.py
import torch
import torch.nn as nn
from torch.optim import Adam
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR# ===========================
# Conditional DCGAN 实现
# ===========================
class cDCGAN:def __init__(self, data_root, batch_size, device, latent_dim=100, num_classes=4):self.device = deviceself.batch_size = batch_sizeself.latent_dim = latent_dimself.num_classes = num_classes# 数据加载器self.train_loader = self.get_dataloader(data_root)# 初始化生成器和判别器self.generator = self.build_generator().to(device)self.discriminator = self.build_discriminator().to(device)# 初始化权重self.generator.apply(self.weights_init)self.discriminator.apply(self.weights_init)# 损失函数和优化器self.criterion = nn.BCELoss()self.optimizer_G = Adam(self.generator.parameters(), lr=0.0001, betas=(0.5, 0.999))self.optimizer_D = Adam(self.discriminator.parameters(), lr=0.0001, betas=(0.5, 0.999))# 学习率调度器self.scheduler_G = StepLR(self.optimizer_G, step_size=10, gamma=0.5) # 每10个epoch学习率减半self.scheduler_D = StepLR(self.optimizer_D, step_size=10, gamma=0.5)def get_dataloader(self, data_root):transform = transforms.Compose([transforms.Resize(128),transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))])dataset = datasets.ImageFolder(root=data_root, transform=transform)return DataLoader(dataset, batch_size=self.batch_size, shuffle=True,num_workers=8, pin_memory=True, persistent_workers=True)@staticmethoddef weights_init(model):"""权重初始化"""if isinstance(model, (nn.Conv2d, nn.Linear)):nn.init.normal_(model.weight.data, 0.0, 0.02)if model.bias is not None:nn.init.constant_(model.bias.data, 0)def train_step(self, epoch, step, num_epochs):"""单次训练步骤"""self.generator.train()self.discriminator.train()G_losses, D_losses = [], []for i, (real_img, labels) in enumerate(self.train_loader):# 确保 real_img 和 labels 在同一设备real_img = real_img.to(self.device)labels = labels.to(self.device)batch_size = real_img.size(0)# # 标签 11.19 15:11:12修改# valid = torch.ones((batch_size, 1), device=self.device)# fake = torch.zeros((batch_size, 1), device=self.device)# 标签平滑# smooth_valid = torch.full((batch_size, 1), 1, device=self.device) # 平滑真实标签# smooth_fake = torch.full((batch_size, 1), 0, device=self.device) # 平滑伪造标签# smooth_valid = torch.full((batch_size, 1), torch.rand(1).item() * 0.1 + 0.9, device=self.device)# smooth_fake = torch.full((batch_size, 1), torch.rand(1).item() * 0.1, device=self.device)# smooth_valid = torch.full((batch_size, 1), max(0.7, 1 - epoch * 0.001), device=self.device)# smooth_fake = torch.full((batch_size, 1), min(0.3, epoch * 0.001), device=self.device)# 动态调整标签范围smooth_valid = torch.full((batch_size, 1), max(0.9, 1 - 0.0001 * epoch), device=self.device)smooth_fake = torch.full((batch_size, 1), min(0.1, 0.0001 * epoch), device=self.device)# 替换以下两处代码valid = smooth_validfake = smooth_fake# ========== 训练判别器 ==========real_pred = self.discriminator(real_img, labels)# d_real_loss = self.criterion(real_pred, valid)d_real_loss = self.criterion(real_pred, valid - 0.1 * torch.rand_like(valid))noise = torch.randn(batch_size, self.latent_dim, device=self.device)# gen_labels = torch.randint(0, self.num_classes, (batch_size,), device=self.device)gen_labels = torch.randint(0, self.num_classes, (batch_size,), device=self.device) + torch.randint(-1, 2, (batch_size,), device=self.device)gen_labels = torch.clamp(gen_labels, 0, self.num_classes - 1) # 确保标签在范围内gen_img = self.generator(noise, gen_labels)fake_pred = self.discriminator(gen_img.detach(), gen_labels)# d_fake_loss = self.criterion(fake_pred, fake)d_fake_loss = self.criterion(fake_pred, fake + 0.1 * torch.rand_like(fake))d_loss = (d_real_loss + d_fake_loss) / 2self.optimizer_D.zero_grad()d_loss.backward()self.optimizer_D.step()D_losses.append(d_loss.item())# ========== 训练生成器 ==========gen_pred = self.discriminator(gen_img, gen_labels)g_loss = self.criterion(gen_pred, valid)self.optimizer_G.zero_grad()g_loss.backward()self.optimizer_G.step()G_losses.append(g_loss.item())print(f'第 {epoch}/{num_epochs} 轮, Batch {i + 1}/{len(self.train_loader)}, 'f'D Loss: {d_loss:.4f}, G Loss: {g_loss:.4f}')step += 1return G_losses, D_losses, stepdef build_generator(self):"""生成器"""return Generator(latent_dim=self.latent_dim, num_classes=self.num_classes)def build_discriminator(self):"""判别器"""return Discriminator(num_classes=self.num_classes)def load_model(self, model_path):"""加载模型权重"""checkpoint = torch.load(model_path, map_location=self.device)self.generator.load_state_dict(checkpoint['generator_state_dict'])self.optimizer_G.load_state_dict(checkpoint['optimizer_G_state_dict'])self.discriminator.load_state_dict(checkpoint['discriminator_state_dict'])self.optimizer_D.load_state_dict(checkpoint['optimizer_D_state_dict'])epoch = checkpoint['epoch']print(f"加载了模型权重,起始训练轮次为 {epoch}")return epochdef save_model(self, epoch, save_path):"""保存模型"""torch.save({'epoch': epoch,'scheduler_G_state_dict': self.scheduler_G.state_dict(),'scheduler_D_state_dict': self.scheduler_D.state_dict(),'generator_state_dict': self.generator.state_dict(),'optimizer_G_state_dict': self.optimizer_G.state_dict(),'discriminator_state_dict': self.discriminator.state_dict(),'optimizer_D_state_dict': self.optimizer_D.state_dict(),}, save_path)print(f"模型已保存至 {save_path}")# ===========================
# 生成器
# ===========================
class Generator(nn.Module):def __init__(self, latent_dim=100, num_classes=4, img_channels=3):super(Generator, self).__init__()self.latent_dim = latent_dimself.label_emb = nn.Embedding(num_classes, num_classes)self.init_size = 8self.l1 = nn.Linear(latent_dim + num_classes, 256 * self.init_size * self.init_size)self.conv_blocks = nn.Sequential(nn.BatchNorm2d(256),nn.Upsample(scale_factor=2),nn.Conv2d(256, 128, 3, padding=1),nn.BatchNorm2d(128),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(128, 64, 3, padding=1),nn.BatchNorm2d(64),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(64, 32, 3, padding=1),nn.BatchNorm2d(32),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(32, img_channels, 3, padding=1),nn.Tanh())def forward(self, noise, labels):labels = labels.to(self.label_emb.weight.device)label_embedding = self.label_emb(labels)x = torch.cat((noise, label_embedding), dim=1)x = self.l1(x).view(x.size(0), 256, self.init_size, self.init_size)return self.conv_blocks(x)# ===========================
# 判别器
# ===========================
class Discriminator(nn.Module):def __init__(self, img_channels=3, num_classes=4):super(Discriminator, self).__init__()self.label_embedding = nn.Embedding(num_classes, img_channels)self.model = nn.Sequential(nn.Conv2d(img_channels * 2, 64, 4, stride=2, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 128, 4, stride=2, padding=1),nn.BatchNorm2d(128),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(128, 256, 4, stride=2, padding=1),nn.BatchNorm2d(256),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(256, 512, 4, stride=2, padding=1),nn.BatchNorm2d(512),nn.LeakyReLU(0.2, inplace=True))self.output_layer = nn.Sequential(nn.Linear(512 * 8 * 8, 1),nn.Sigmoid())def forward(self, img, labels):labels = labels.to(self.label_embedding.weight.device)label_embedding = self.label_embedding(labels).unsqueeze(2).unsqueeze(3)label_embedding = label_embedding.expand(-1, -1, img.size(2), img.size(3))x = torch.cat((img, label_embedding), dim=1)x = self.model(x).view(x.size(0), -1)return self.output_layer(x)2.3新建cGAN_trainer.py
import os
import torch
import argparse
from cGAN_net import cDCGAN
from utils import plot_loss, plot_result
import timeos.environ['OMP_NUM_THREADS'] = '1'def main(args):# 初始化设备和训练参数device = torch.device(args.device if torch.cuda.is_available() else 'cpu')model = cDCGAN(data_root=args.data_root, batch_size=args.batch_size, device=device, latent_dim=args.latent_dim)# 添加学习率调度器scheduler_G = torch.optim.lr_scheduler.StepLR(model.optimizer_G, step_size=10, gamma=0.5)scheduler_D = torch.optim.lr_scheduler.StepLR(model.optimizer_D, step_size=10, gamma=0.5)start_epoch = 0# 如果有保存的模型,加载if args.load_model and os.path.exists(args.load_model):start_epoch = model.load_model(args.load_model) + 1# 恢复调度器状态scheduler_G_path = f"{args.load_model}_scheduler_G.pt"scheduler_D_path = f"{args.load_model}_scheduler_D.pt"if os.path.exists(scheduler_G_path) and os.path.exists(scheduler_D_path):scheduler_G.load_state_dict(torch.load(scheduler_G_path))scheduler_D.load_state_dict(torch.load(scheduler_D_path))print(f"成功恢复调度器状态:{scheduler_G_path}, {scheduler_D_path}")else:print("未找到调度器状态文件,使用默认调度器设置")print(f"从第 {start_epoch} 轮继续训练...")print(f"开始训练,从第 {start_epoch + 1} 轮开始...")# 创建保存路径os.makedirs(args.save_dir, exist_ok=True)os.makedirs(os.path.join(args.save_dir, 'log'), exist_ok=True)# 训练循环D_avg_losses, G_avg_losses = [], []for epoch in range(start_epoch, args.epochs):G_losses, D_losses, step = model.train_step(epoch, step=0, num_epochs=args.epochs)# 计算平均损失D_avg_loss = sum(D_losses) / len(D_losses) if D_losses else 0.0G_avg_loss = sum(G_losses) / len(G_losses) if G_losses else 0.0D_avg_losses.append(D_avg_loss)G_avg_losses.append(G_avg_loss)# 保存损失曲线图plot_loss(start_epoch, args.epochs, D_avg_losses, G_avg_losses, epoch + 1, save=True,save_dir=os.path.join(args.save_dir, "log"))# 生成并保存图片labels = torch.tensor([0, 1, 2, 3]).to(device)if (epoch + 1) % args.save_freq == 0: # 每隔一定轮次保存生成结果z = torch.randn(len(labels), args.latent_dim, device=device) # 随机生成噪声plot_result(model.generator, z, labels, epoch + 1, save_dir=os.path.join(args.save_dir, 'log'))# 每10个epoch保存模型if (epoch + 1) % args.save_interval == 0:timestamp = int(time.time())save_path = os.path.join(args.save_dir, f"cgan_epoch_{epoch + 1}_{timestamp}.pth")model.save_model(epoch + 1, save_path)print(f"第 {epoch + 1} 轮的模型已保存,保存路径为 {save_path}")# 更新学习率调度器scheduler_G.step()scheduler_D.step()if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument('--data_root', type=str, default='data/crop128', help="数据集根目录")parser.add_argument('--save_dir', type=str, default='./chkpt/cgan_model', help="保存模型的目录")parser.add_argument('--load_model', type=str, default=None, help="要加载的模型路径(可选)")parser.add_argument('--epochs', type=int, default=1000, help="训练的轮数")parser.add_argument('--save_interval', type=int, default=10, help="保存模型检查点的间隔(按轮数)")parser.add_argument('--batch_size', type=int, default=64, help="训练的批次大小")parser.add_argument('--device', type=str, default='cuda', help="使用的设备(如 cuda 或 cpu)")parser.add_argument('--latent_dim', type=int, default=100, help="生成器的潜在空间维度")parser.add_argument('--save_freq', type=int, default=1, help="每隔多少轮保存一次生成结果(默认: 1)")args = parser.parse_args()main(args)结果分析:


2.4中间结果可视化处理
新建utils.py,编写绘制中间结果和中间损失线图的函数,代码如下:
import matplotlib.pyplot as plt
import numpy as np
import os
import torchdef denorm(x):out = (x + 1) / 2return out.clamp(0, 1)def plot_loss(start_epoch, num_epochs, d_losses, g_losses, num_epoch, save=False, save_dir='celebA_cDCGAN_results/', show=False):"""绘制损失函数曲线,从 start_epoch 到 num_epochs。Args:start_epoch: 起始轮次num_epochs: 总轮次d_losses: 判别器损失列表g_losses: 生成器损失列表num_epoch: 当前训练轮次save: 是否保存绘图save_dir: 保存路径show: 是否显示绘图"""fig, ax = plt.subplots()ax.set_xlim(start_epoch, num_epochs)ax.set_ylim(0, max(np.max(g_losses), np.max(d_losses)) * 1.1)plt.xlabel(f'Epoch {num_epoch + 1}')plt.ylabel('Loss values')plt.plot(d_losses, label='Discriminator')plt.plot(g_losses, label='Generator')plt.legend()if save:if not os.path.exists(save_dir):os.makedirs(save_dir)save_fn = os.path.join(save_dir, f'cDCGAN_losses_epoch.png')plt.savefig(save_fn)if show:plt.show()else:plt.close()def plot_result(generator, z, labels, epoch, save_dir=None, show=False):"""生成并保存或显示生成的图片结果。Args:generator: 生成器模型z: 随机噪声张量labels: 标签张量epoch: 当前训练轮数save_dir: 保存图片的路径(可选)show: 是否显示生成的图片(可选)"""# 调用生成器,生成图像generator.eval() # 设置为评估模式with torch.no_grad():gen_images = generator(z, labels) # 同时传入 z 和 labelsgenerator.train() # 恢复训练模式# 图像反归一化gen_images = denorm(gen_images)# 绘制图片fig, ax = plt.subplots(1, len(gen_images), figsize=(15, 15))for i in range(len(gen_images)):ax[i].imshow(gen_images[i].permute(1, 2, 0).cpu().numpy()) # 转换为可显示格式ax[i].axis('off')# 保存或显示图片if save_dir:os.makedirs(save_dir, exist_ok=True)save_path = os.path.join(save_dir, f'epoch_{epoch}.png')plt.savefig(save_path)if show:plt.show()plt.close(fig)执行 cGAN_trainer.py 文件,完成模型训练。
相关文章:
【计算机视觉技术 - 人脸生成】2.GAN网络的构建和训练
GAN 是一种常用的优秀的图像生成模型。我们使用了支持条件生成的 cGAN。下面介绍简单 cGAN 模型的构建以及训练过程。 2.1 在 model 文件夹中新建 nets.py 文件 import torch import torch.nn as nn# 生成器类 class Generator(nn.Module):def __init__(self, nz100, nc3, n…...

数据中台与数据治理服务方案[50页PPT]
本文概述了数据中台与数据治理服务方案的核心要点。数据中台作为政务服务数据化的核心,通过整合各部门业务系统数据,进行建模与加工,以新数据驱动政府管理效率提升与政务服务能力增强。数据治理则聚焦于解决整体架构问题,确保数据…...

【Qt】将控件均匀分布到圆环上
1. 关键代码 for(int i0; i<10; i){/*m_panLabelIcon - 大圆环控件m_slotsIcon[i] - 小圆控件*/QString idxStr QString::number(i1);m_slotsIcon[i] new QLabel(m_panLabelIcon);m_slotsIcon[i]->setFont(ftSlot);m_slotsIcon[i]->setText(idxStr);m_slotsIcon[i]-…...
)
第四、五章补充:线代本质合集(B站:小崔说数)
视频1:线性空间 原视频:【线性代数的本质】向量空间、基向量的几何解释_哔哩哔哩_bilibili 很多同学在学习线性代数的时候,会遇到一个困扰,就是不知道什么是线性空间。...

2025年贵州省职业院校技能大赛信息安全管理与评估赛项规程
贵州省职业院校技能大赛赛项规程 赛项名称: 信息安全管理与评估 英文名称: Information Security Management and Evaluation 赛项组别: 高职组 赛项编号: GZ032 1 2 一、赛项信息 赛项类别 囚每年赛 □隔年赛(□单数年…...
松鼠状态机流转-@Transit
疑问 状态from to合法性校验,都是在代码中手动进行的吗,不是状态机自动进行的? 注解中from状态,代表当前状态 和谁校验:上下文中初始状态 怎么根据注解找到执行方法的 分析代码,创建运单,怎…...

微信小程序调用 WebAssembly 烹饪指南
我们都是在夜里崩溃过的俗人,所幸终会天亮。明天就是新的开始,我们会变得与昨天不同。 一、Rust 导出 wasm 参考 wasm-bindgen 官方指南 https://wasm.rust-lang.net.cn/wasm-bindgen/introduction.html wasm-bindgen,这是一个 Rust 库和 CLI…...
)
# LeetCode Problem 2038: 如果相邻两个颜色均相同则删除当前颜色 (Winner of the Game)
LeetCode Problem 2038: 如果相邻两个颜色均相同则删除当前颜色 (Winner of the Game) 在本篇博客中,我们将深入探讨 LeetCode 第2038题——如果相邻两个颜色均相同则删除当前颜色。该问题涉及字符串处理与游戏策略,旨在考察如何在给定规则下判断游戏的…...

Redis面试相关
Redis开篇 使用场景 缓存 缓存穿透 解决方法一: 方法二: 通过多次hash来获取对应的值。 小结 缓存击穿 缓存雪崩 打油诗 双写一致性 两种不同的要求 强一致 读锁代码 写锁代码 强一致,性能低。 延迟一致 方案一:消息队列 方…...

4.CSS文本属性
4.1文本颜色 div { color:red; } 属性值预定义的颜色值red、green、blue、pink十六进制#FF0000,#FF6600,#29D794RGB代码rgb(255,0,0)或rgb(100%,0%,0%) 4.2对齐文本 text-align 属性用于设置元素内文本内容的水平对齐方式。 div{ text-align:center; } 属性值解释left左对齐ri…...

Mongo高可用架构解决方案
Mongo主从复制哪些事(仅适用特定场景) 对数据强一致性要求不高的场景,一般微服务架构中不推荐 master节点可读可写操作,当数据有修改时,会将Oplog(操作日志)同步到所有的slave节点上。那么对于从节点来说仅只读,所有slave节点从master节点同步数据,然而从节点之间互相…...

Rabbitmq 业务异常与未手动确认场景及解决方案
消费端消费异常,业务异常 与 未手动确认是不是一个场景,因为执行完业务逻辑,再确认。解决方案就一个,就是重试一定次数,然后加入死信队列。还有就是消费重新放入队列,然后重新投递给其他消费者,…...

linux,centos7.6安装禅道
1.cd /opt 2.wget https://www.zentao.net/dl/zentao/18.5/ZenTaoPMS.18.5.zbox_64.tar.gz 3.tar xvzf ZenTaoPMS.18.5.zbox_64.tar.gz 4./opt/zbox/zbox --aport 4005 --mport 3307 start 安全组开启一下两个端口 –aport 4005:设置Apache启动端口为4005 –mport 3…...

java基础之代理
代理模式(Proxy Pattern) 简介 是一种结构型设计模式,主要用于为某对象提供一个代理对象,以控制对该对象的访问。通过引入一个代理对象来控制对原对象的访问。代理对象在客户端和目标对象之间充当中介,负责将客户端的…...

计算机网络——期末复习(6)期末考试样例2(含答案)
一、单项选择题(每题1分,共10小题,共计10分) 1.因特网多播采用的管理协议是( )协议。 A.UDP B.BGP C.IGMP D.TCP 2.采用CIDR时,某计算机的IP地址是202.35.79.88/19,该计算机所处子网的地址是( )。 A.202.35.0.…...
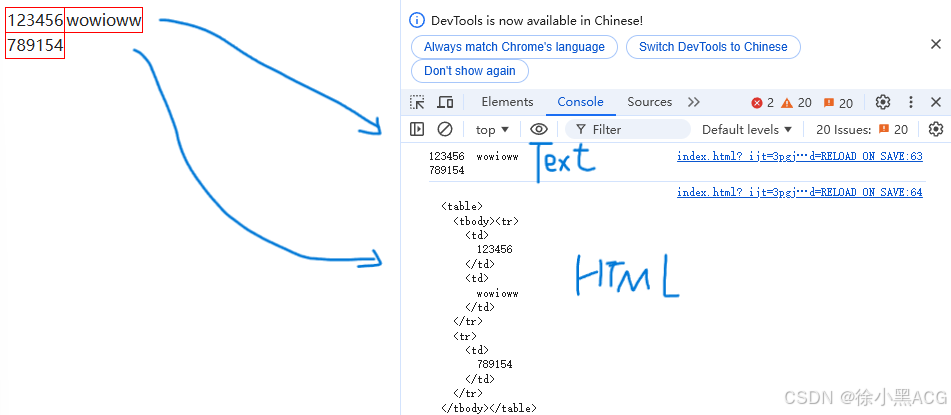
JavaScript 获取DOM对象
html的标签被js获取到之后就变成了js对象,对象里面包含了标签的属性和方法 。同一时间获取多个对象则会翻译一个数组,数组元素是对象 获取方法 1. const a document.getElementById("id"),根据标签的id来获取。因为id是唯一的、…...

一文讲明白朴素贝叶斯算法及其计算公式(入门普及)
1、贝叶斯算法 贝叶斯定理由英国数学家托马斯贝叶斯 ( Thomas Bayes) 提出的,用来描述两个条件概率之间的关系。通常,事件A在事件B 发生的条件下与事件 B 在事件 A 发生的条件下,它们两者的概率并不相同,但是它们两者之间存在一定…...
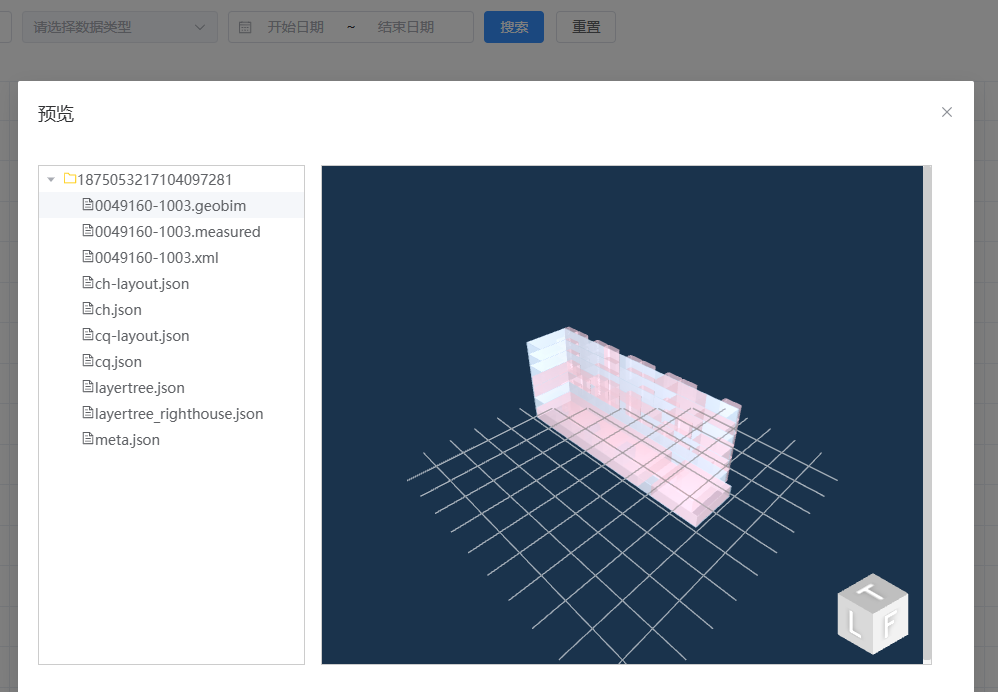
实际开发中,常见pdf|word|excel等文件的预览和下载
实际开发中,常见pdf|word|excel等文件的预览和下载 背景相关类型数据之间的转换1、File转Blob2、File转ArrayBuffer3、Blob转ArrayBuffer4、Blob转File5、ArrayBuffer转Blob6、ArrayBuffer转File 根据Blob/File类型生成可预览的Base64地址基于Blob类型的各种文件的下载各种类型…...

Python自学 - 递归函数
1 Python自学 - 递归函数 递归函数是一种在函数体内调用自己的函数,就像“左脚踩着右脚,再右脚踩着左脚… 嗯,你就可以上天了!”。递归函数虽然不能上天,但在处理某些场景时非常好用, 一种典型的场景就是遍…...

Spark-Streaming有状态计算
一、上下文 《Spark-Streaming初识》中的NetworkWordCount示例只能统计每个微批下的单词的数量,那么如何才能统计从开始加载数据到当下的所有数量呢?下面我们就来通过官方例子学习下Spark-Streaming有状态计算。 二、官方例子 所属包:org.…...

Obsidian PDF导出终极指南:从新手到专家的完整解决方案
Obsidian PDF导出终极指南:从新手到专家的完整解决方案 【免费下载链接】obsidian-better-export-pdf Obsidian PDF export enhancement plugin 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-better-export-pdf 还在为Obsidian笔记导出PDF时的格式…...
)
SITS2026闭门报告首度公开:自然语言转代码在金融/医疗/嵌入式三大高危场景的11项合规性断点(含GDPR与ISO/IEC 23894适配路径)
第一章:SITS2026闭门报告核心结论与行业影响 2026奇点智能技术大会(https://ml-summit.org) SITS2026闭门报告首次系统披露了大模型推理基础设施在超低延迟场景下的结构性瓶颈,指出当前主流服务框架中约68%的端到端延迟源于KV缓存跨设备同步开销&#…...

企业知识库构建新方案:StructBERT中文句向量工具在智能客服问答对匹配中的落地实践
企业知识库构建新方案:StructBERT中文句向量工具在智能客服问答对匹配中的落地实践 1. 项目背景与价值 在智能客服系统中,用户提问的方式千变万化,但核心意图往往相同。传统的关键词匹配方法经常遇到这样的问题:用户问"怎么…...

MSPM0 BSL烧录避坑指南:从CCS生成TI-TXT Hex到UniFlash成功下载的全流程解析
MSPM0 BSL烧录避坑指南:从CCS生成TI-TXT Hex到UniFlash成功下载的全流程解析 如果你正在使用MSPM0系列单片机,并且希望通过串口进行BSL(Bootloader)模式下的程序烧录,那么这篇文章将为你提供一份详尽的避坑指南。不同于…...

Spring AI ETL进阶:定制中文元数据增强与Milvus向量化存储实战
1. Spring AI ETL的核心价值与应用场景 在处理中文文本数据时,传统的ETL流程常常会遇到语义理解不准确、上下文丢失等问题。Spring AI提供的ETL框架通过模块化设计,让开发者能够轻松构建适合中文场景的数据处理流水线。我最近在一个知识库项目中实际应用…...

从零到一:3天用Unity和WPF打造专属Galgame播放器《Galplayer》实战手记
从零到一:3天用Unity和WPF打造专属Galgame播放器《Galplayer》实战手记 当你想在手机上流畅体验Galgame剧情,却发现现有播放器要么功能简陋,要么操作繁琐时,有没有想过自己动手打造一个专属播放器?本文将带你完整复盘…...

5步终极解决方案:快速排查Reloaded-II游戏启动故障
5步终极解决方案:快速排查Reloaded-II游戏启动故障 【免费下载链接】Reloaded-II Universal .NET Core Powered Modding Framework for any Native Game X86, X64. 项目地址: https://gitcode.com/gh_mirrors/re/Reloaded-II Reloaded-II作为新一代通用.NET …...

餐饮零售AI视觉助手Ostrakon-VL-8B:开箱即用,一键部署实战
餐饮零售AI视觉助手Ostrakon-VL-8B:开箱即用,一键部署实战 1. 为什么选择Ostrakon-VL-8B? 在餐饮零售行业,每天都有大量视觉数据需要处理:货架商品、门店环境、价格标签等。传统人工检查方式效率低、成本高且容易出错…...

代码数据质量断崖式下滑?这4类隐性污染源正 silently 毁掉你的微调效果,附检测脚本开源
第一章:智能代码生成训练数据构建 2026奇点智能技术大会(https://ml-summit.org) 高质量、结构化、语义丰富的代码语料是智能代码生成模型能力的基石。训练数据不仅需覆盖主流编程语言的语法范式与工程实践,还需蕴含真实开发场景中的意图-实现映射关系…...
)
树莓派4B无头模式极简指南:5分钟搞定SSH+WiFi预配置(含国内源加速)
树莓派4B无头模式极简配置:SSHWiFi预配置与国内源加速实战 1. 无头模式的核心价值与准备工作 无头模式(Headless Mode)彻底解放了树莓派对显示器和外设的依赖,让这块信用卡大小的计算机真正成为物联网项目的隐形引擎。想象一下&am…...