使用Apache Mahout制作 推荐引擎
目录
创建工程
基本概念
关键概念
基于用户与基于项目的分析
计算相似度的方法
协同过滤
基于内容的过滤
混合方法
创建一个推荐引擎
图书评分数据集
加载数据
从文件加载数据
从数据库加载数据
内存数据库
协同过滤
基于用户的过滤
基于项目的过滤
添加自定义规则到推荐引擎
评估
在线学习引擎
基于内容的过滤
完整代码
推荐引擎可能是当今初创公司应用最多的一种数据科学方法。有两项主要技术用来创建一个 推系统:基于内容的过滤与协同过滤。基于内容的过滤算法使用项目属性寻找带有相似属性的 项目协同过滤算法关注的是用户的评分或者其他用户的行为,它基于拥有类似行为的用户喜好 与购买物品进行推荐。 本章先讲解基本概念,它们是理解推荐引擎原理必需的内容;然后演示如何使用Apache Mahout中的各种算法实现快速创建一个可扩展的推荐引擎。本章内容涵盖如下主题:
如何创建一个推荐引擎
准备Apache Mahout
基于内容的方法
协同过滤方法
到本章结束时,你将知道我们的问题适合使用哪种推荐引擎进行解决,以及如何快速创建这 样个推荐引擎。
创建工程
接着上一篇文章工程,pom添加:
<dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-mr</artifactId><version>0.10.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-integration</artifactId><version>0.7</version></dependency><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.16.1</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency>
基本概念
推荐引擎的目标是向用户展示他们感兴趣的项目。与搜索引擎不同的是,相关内容通常出现 在一个网站中,用户不必创建查询来请求它。因为推荐引擎会观察用户的行为,并且在用户不知 情的情况下为他们创建查询。
可以这么说,推荐引擎最著名的例子就是www.amazon.com,它使用多种方法为用户做个性 化推荐。

向我们展示了一种商品推荐的例子——“购买这件商品的顾客还买了……”。这是 一个基于项目的协同推荐的例子,在这种推荐方式下,与特定项目相似的项目都会得到推荐。相 关内容稍后讲解。
关键概念
推荐引擎需要如下4个输入做出推荐:
使用属性描述的项目信息;
用户资料,比如年龄范围、性别、位置、朋友等;
用户交互,比如评级、浏览、标记、比较、保存、电邮;
显示项目上下文,比如项目的分类与地理位置。
获得这些输入后,推荐引擎将其组合在一起,帮助我们回答如下问题:
购买、观看、浏览、收藏过这个项目的用户还买了、看了、浏览了、收藏了……
与这个项目类似的项目
你可能认识的其他用户
和你类似的其他用户
下面详细介绍这种组合是如何工作的。
基于用户与基于项目的分析
创建推荐引擎时要搞清楚,推荐引擎尝试推荐一个特定项目时,搜索的是相关项目还是相关 用户。
基于项目的分析中,引擎的主要任务是找出那些与特定项目类似的项目;而基于用户的分 析中,引擎首先要找出那些与特定用户类似的用户。比如,先找出那些带有相同资料信息(年 龄、性别等)或行为历史(买了、看了、浏览了等)的用户,然后将相同项目推荐给其他类似 用户。 这两种方法都要求计算一个相似矩阵(similarity matrix),具体取决于分析的是项目属性还 是用户行为。
下面深入了解具体应该如何做。
计算相似度的方法
计算相似度(similarity)的基本方法有3种:
协同过滤算法关注的是用户评分或其他用户的行为,并且基于拥有类似行为的用户喜好 与购买的物品进行推荐;
基于内容的过滤算法使用项目属性寻找带有相似属性的项目;
组合了协同过滤与基于内容的过滤的混合方法。
接下来,详细学习每一种方法。
协同过滤
协同过滤只基于用户评级或其他用户的行为,基于拥有相似行为的用户喜好与购买的物品进 行推荐。
协同过滤的主要优点是不依赖于项目内容,因此可以准确推荐复杂项目,而无需了解项目本 身,比如电影。它基于的假设是“人们过去认可的将来也会认可”“他们喜欢与过去喜欢的项目 相似的项目”。
这个方法的主要缺点就是所谓的冷启动(cold start),也就是说,如果想创建一个精确的协 同过滤系统,算法往往需要先有大量用户评分。因此,产品的第一个版本中通常不会使用协同过 滤,直到有了相当数量的数据积累之后才会使用。
基于内容的过滤
另一方面,基于内容的过滤建立在项目的描述与用户偏好资料之上,按照如下步骤进行组合: 首先,使用属性描述项目并找出相似项目,我们选用一个距离测度(比如余弦距离或皮尔逊相关 系数,详细内容请参考第1章有关距离测度的内容)测量项目之间的距离。接着,将用户资料输 入方程式。鉴于用户喜欢的项目类型的反馈,我们引入权重指示特定项目属性的重要程度。比如, “潘多拉电台流媒体服务应用”基于内容的过滤技术使用400多个属性创建电台。起初,一个用户 通过特定属性挑选了一支歌曲,并通过提供反馈突出重要的歌曲属性。
这个方法最初只需要很少的用户反馈信息,因此它能有效避免冷启动问题。
混合方法
那么,应该如何选择协同过滤方法与基于内容的过滤方法呢?借助协同过滤方法可以从用户 对一个内容源的行为了解用户喜好,并通过用户偏好找出其他类型的内容。基于内容的过滤方法 仅限于推荐同类型的内容,并且用户已经在使用这种类型。这对于不同的使用案例是有价值的, 比如基于用户正在浏览的新闻推荐新闻文章是有用的。但如果能够再进一步,基于正在浏览的新 闻推荐其他类型的资源(比如图书、电影),这将会更有用。
协同过滤与基于内容的过滤不是相互排斥的,某些情况下,我们可以将二者组合以产生更有 效的结果。比如,Netflix使用协同过滤分析相似用户的搜索与观看模式。此外,还使用基于内容 的过滤向用户推荐高评分影片。
混合技术有很多,比如加权混合、切换混合、分区混合、特征组合、特征扩充、级联混合、 分层混合等。机器学习与数据挖掘社区中,推荐系统一直是个活跃版块,数据科学会议上也会专 门为它设立分会场。Adomavicius 与 Tuzhilin ( 2005 )的 Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions论文,你可以很好地了 解这些技术。论文中,作者讨论了不同方法与基本算法,并且提供了更多有价值的参考论文。需 要认真了解某个特定方法时,为了获取更多技术细节,你可以阅读弗朗西斯科·里奇等人合著的 《推荐系统:技术、评估及高效算法》。
创建一个推荐引擎
为了演示基于内容的过滤与协同过滤方法,下面创建一个图书推荐引擎。
图书评分数据集
将使用图书评分数据集(Ziegler等,2005),它由一个爬虫程序收集了4周而得到。该数 据集包含的数据涉及Book-Crossing网站的278 858个会员与1 157 112个评分,这些评分既有隐含 的也有明确的,涵盖271 379个不同的ISBN。用户数据经过匿名化处理,但含有人口统计信息。
Book-Crossing数据集包含3个文件,网站中对于这3个文件的描述如下。
BX-Users:包含用户。请注意,用户ID(User-ID)被匿名化处理,由字符串换为整数。 如果存在统计数据则给出(位置与年龄),否则这些字段就是NULL值。
BX-Books:图书通过各自不同的ISBN号码加以识别。无效ISBN已经被从数据集中移走。 而且,给出了一些基于内容的信息(图书名称、图书作者、出版年份、出版商),这些信 息是从Amazon Web Service那里得到的。请注意,如果图书有多个作者,则只提供第一作 者。此外还给出了指向封面图片的 URL 连接,有三种不同形式: Image-URL-S 、 Image-URL-M、Image-URL-L,即小、中、大。这些URL指向Amazon网站。
BX-Book-Ratings:包含图书的评分信息。有些评分(Book-Rating)很明确,使用数字1~10 表示(分值越高表示越值得阅读);有些评分不明,使用0表示。
加载数据
根据数据的存储位置(文件或数据库),有两种不同的数据加载方法可以选用。首先详细讲 解如何从文件加载数据,包括如何处理自定义格式。之后快速了解如何从数据库加载数据。
从文件加载数据
可以使用FileDataModel类从文件加载数据,文件中的数据以逗号进行分隔,每一行顺序包含userID、itemID、preference(可选)、timestamp(可选),格式如下:
userID, itemID[, preference[, timestamp]]
可选项preference是一个二元偏好值,也就是说,对于某本书,用户要么“喜欢”,要么“不 喜欢”,没有喜爱程度的差别。
以#开始的行或空行都会被忽略。数据行也可以包含其他字段,但这些字段会被忽略。
DataModel类可以接受如下类型:
userID、itemID是long类型
preference是double类型
timestamp是long类型
如果你能提供上面这种格式的数据集,那就可以简单地使用如下代码加载数据:
DataModel model = new FileDataModel(new File(path));
这个类不适合用于加载大量数据,比如几千万行数据。需要加载大量数据时,使用带有JDBC 支持的DataModel与数据库会更合适。
现实情况下,我们无法保证提供给我们的输入数据中,userID与itemID总为整型值。比如, 示例中,itemID对应于ISBN书号,它可以唯一地标识一本图书,那么就不是整型值。默认情况 下,FileDataModel不适合处理这种数据。
下面 考虑 itemID 是 字 符串 时应 该如何 处理 。我们 要定 义自己 的数 据模型 ,对 FileDataModel做扩展,重载readItemIDFromString(String)方法,读入字符串形式的 itemID值,而后将其转换为long型值并返回。为了将String转化为long,我们要对Mahout中 的AbstractIDMigrator辅助类做扩展,这个类的设计初衷就是为了完成这个任务。
对AbstractIDMIgrator类做扩展:
// ItemMemIDMigrator 类继承自 AbstractIDMigrator,用于管理长整型ID和字符串ID之间的映射关系。
public class ItemMemIDMigrator extends AbstractIDMigrator {// 使用 FastByIDMap 来存储长整型ID和字符串ID之间的映射关系。private FastByIDMap<String> itemIDMap;// 构造函数,初始化 itemIDMap,设置初始容量为 10000。public ItemMemIDMigrator() {this.itemIDMap = new FastByIDMap<String>(10000);}// 存储长整型ID和字符串ID之间的映射关系。// @param longID 长整型ID// @param stringID 字符串IDpublic void storeMapping(long longID, String stringID) {itemIDMap.put(longID, stringID);}// 初始化单个字符串ID的映射关系。// @param stringID 字符串ID// @throws TasteException 如果发生异常public void singleInit(String stringID) throws TasteException {// 将字符串ID转换为长整型ID,并存储映射关系。storeMapping(toLongID(stringID), stringID);}// 根据长整型ID获取对应的字符串ID。// @param l 长整型ID// @return 对应的字符串ID// @throws TasteException 如果发生异常@Overridepublic String toStringID(long l) throws TasteException {// 从 itemIDMap 中获取长整型ID对应的字符串ID。return this.itemIDMap.get(l);}
}对FileDataModel做扩展:
// StringItemIdFileDataModel 类继承自 FileDataModel,用于处理文件数据模型,特别是处理字符串形式的物品ID。
public class StringItemIdFileDataModel extends FileDataModel {// 用于管理长整型ID和字符串ID之间映射关系的 ItemMemIDMigrator 实例。public ItemMemIDMigrator itemMemIDMigrator;// 构造函数,初始化文件数据模型,并指定分隔符。// @param dataFile 数据文件// @param delimiterRegex 分隔符的正则表达式// @throws IOException 如果文件读取失败public StringItemIdFileDataModel(File dataFile, String delimiterRegex) throws IOException {super(dataFile, delimiterRegex);}// 从字符串中读取物品ID,并将其转换为长整型ID。// @param value 字符串形式的物品ID// @return 长整型形式的物品ID@Overrideprotected long readItemIDFromString(String value) {// 如果 itemMemIDMigrator 为空,则初始化一个新的 ItemMemIDMigrator 实例。if (Objects.isNull(itemMemIDMigrator)) {itemMemIDMigrator = new ItemMemIDMigrator();}// 将字符串形式的物品ID转换为长整型ID。long readValue = itemMemIDMigrator.toLongID(value);try {// 检查长整型ID是否已经存在于 itemMemIDMigrator 中。// 如果不存在,则调用 singleInit 方法初始化映射关系。if (Objects.isNull(itemMemIDMigrator.toStringID(readValue))) {itemMemIDMigrator.singleInit(value);}} catch (Exception e) {// 捕获并打印异常。e.printStackTrace();}// 返回长整型形式的物品ID。return readValue;}// 根据长整型ID获取对应的字符串形式的物品ID。// @param key 长整型ID// @return 字符串形式的物品ID// @throws TasteException 如果发生异常public String getItemIdAsString(long key) throws TasteException {// 通过 itemMemIDMigrator 获取长整型ID对应的字符串形式的物品ID。return itemMemIDMigrator.toStringID(key);}
}以上就是所有准备工作。
从数据库加载数据
除了从文件加载数据之外,还可以从数据库中加载数据,这需要用到一个JDBC数据模型。 本章不会详细讲解安装数据库、连接数据库等内容,只大致了解应该怎样做。 由于数据库连接器存在于一个单独的包——mahout-integration中,所以首先要把这个 包添加到项目的依赖列表。打开pom.xml文件,添加如下依赖关系:
<dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-integration</artifactId><version>0.7</version></dependency>由于要连接MySQL数据库,所以还需要向项目添加一个用于处理数据库连接的包。
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency>现在,我们已经把需要的所有包都准备好了,接下来创建连接。
public static DataModel loadFromDB() throws Exception {MysqlDataSource dbsource = new MysqlDataSource();dbsource.setUser("user");dbsource.setPassword("pass");dbsource.setServerName("localhost");dbsource.setDatabaseName("my_db");DataModel dataModelDB = new MySQLJDBCDataModel(dbsource,"taste_preferences", "user_id", "item_id", "preference","timestamp");return dataModelDB;}Mahout集成了针对各种数据库的JDBCDataModel实现,使得我们可以通过JDBC访问这些数 据库。默认情况下,这个类假定在JNDI名称jdbc/taste之下有DataSource可用,允许我们使 用一个taste_preferences表访问数据库,格式如下:
CREATE TABLE taste_preferences ( user_id BIGINT NOT NULL,
item_id BIGINT NOT NULL, preference REAL NOT NULL, PRIMARY KEY (user_id, item_id) ) CREATE INDEX taste_preferences_user_id_index ON taste_preferences (user_id); CREATE INDEX taste_preferences_item_id_index ON taste_preferences (item_id);
内存数据库
最后,数据模型也可以在内存中动态创建并保存。可以从一个用户偏好数组创建数据库,这 个偏好数组保存着用户对一组项目的评分。 整个创建过程如下:首先,创建一个FastByIdMap散列表,它映射到存储一组用户偏好的 数组PreferenceArray。
接下来,为用户新建一个偏好数组,存储用户评分。初始化这个数组时,必须给出占用内存 大小的参数。
接下来,为当前偏好(0号位置)设置用户ID。其实,这将为所有偏好设置用户ID。
为当前偏好(0号位置)设置项目ID。
为当前偏好(0号位置)设置偏好值。
继续为用户设置其他项目.
最后,添加用户偏好到散列映射.
接着,使用偏好散列映射初始化GenericDataModel
public DataModel loadInMemory() {FastByIDMap<PreferenceArray> preferences = new FastByIDMap<PreferenceArray>();PreferenceArray prefsForUser1 = new GenericUserPreferenceArray(10);prefsForUser1.setUserID(0, 1L);prefsForUser1.setItemID(0, 101L);prefsForUser1.setValue(0, 3.0f);prefsForUser1.setItemID(1, 102L);prefsForUser1.setValue(1, 4.5F);preferences.put(1L, prefsForUser1); // use userID as the key//TODO: add others usersDataModel dataModel = new GenericDataModel(preferences);return dataModel;}协同过滤
可以使用Mahout中的org.apache.mahout.cf.taste包创建推荐引擎,这个包之前是一个 名叫Taste的单独项目,现已并入Mahout中被继续开发。
基于Mahout的协同过滤引擎接收用户对某些项目的偏好(嗜好),返回用户可能喜欢的其他 项目。比如,一个销售图书或CD的网站使用Mahout后,可以很轻松地根据顾客以往的购物数据 找出他们可能感兴趣的CD。
下面这几个关键抽象在顶级包中都定义有相应的Mahout接口。
DataModel:表示与用户及其项目偏好相关的信息仓库。
UserSimilarity:定义两个用户之间的相似度。
ItemSimilarity:定义两个项目之间的相似度。
UserNeighborhood:为给定用户计算邻近用户。
Recommender:为用户推荐项目。
基于用户的过滤
通过初始化前面提到的组件,可以实现一个最基本的基于用户的协同过滤器,具体步骤如下。
首先,加载数据模型.
接着,定义计算用户关联性的方法,比如使用皮尔逊相关系数
然后,定义如何指出哪些用户是相似的,即评分彼此相近的用户。
接下来,使用数据模型、邻居、相似对象初始化GenericUserBasedRecommender默认引 擎,代码如下
String filePath = ClassUtils.getDefaultClassLoader().getResource("BX-Book-Ratings.csv").getPath();StringItemIdFileDataModel dataModel = new StringItemIdFileDataModel(new File(filePath), ";");ItemSimilarity similarity = new PearsonCorrelationSimilarity(dataModel);ItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, similarity);以上就是全部代码,至此,第一个最基本的推荐引擎就做好了.
public static void userBased() throws Exception {String filePath = ClassUtils.getDefaultClassLoader().getResource("BX-Book-Ratings.csv").getPath();StringItemIdFileDataModel model = new StringItemIdFileDataModel(new File(filePath), ";");UserSimilarity similarity = new PearsonCorrelationSimilarity(model);UserNeighborhood neighborhood = new ThresholdUserNeighborhood(0.1, similarity, model);UserBasedRecommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);IDRescorer rescorer = new MyRescorer();// List recommendations = recommender.recommend(2, 3, rescorer);long userID = 276704;// 276704;//212124;//277157;int noItems = 10;System.out.println("Rated items:");for (Preference preference : model.getPreferencesFromUser(userID)) {String itemISBN = model.getItemIdAsString(preference.getItemID());System.out.println("Item: " + books.get(itemISBN) + " | Item id: " + itemISBN + " | Value: " + preference.getValue());}System.out.println("\nRecommended items:");List<RecommendedItem> recommendations = recommender.recommend(userID,noItems);for (RecommendedItem item : recommendations) {String itemISBN = model.getItemIdAsString(item.getItemID());System.out.println("Item: " + books.get(itemISBN) + " | Item id: " + itemISBN + " | Value: " + item.getValue());}}下面讨论应该如何调用推荐 引擎。首先,打印用户已经评分的项目,以及提供给这位用户的10个推荐项目。
IDRescorer rescorer = new MyRescorer();String itemISBN = "042513976X";long itemID = dataModel.readItemIDFromString(itemISBN);int noItems = 10;System.out.println("Recommendations for item: " + books.get(itemISBN));System.out.println("Most similar items:");List<RecommendedItem> recommendations = recommender.mostSimilarItems(itemID, noItems);for (RecommendedItem item : recommendations) {itemISBN = dataModel.getItemIdAsString(item.getItemID());System.out.println("Item: " + books.get(itemISBN) + " | Item id: " + itemISBN + " | Value: " + item.getValue());}上面代码输入如下推荐项目及其分数:
Rated items:
Item: The Handmaid's Tale | Item id: 0395404258 | Value: 0.0
Item: Get Clark Smart : The Ultimate Guide for the Savvy Consumer | Item id: 1563526298 | Value: 9.0
Item: Plum Island | Item id: 0446605409 | Value: 0.0
Item: Blessings | Item id: 0440206529 | Value: 0.0
Item: Edgar Cayce on the Akashic Records: The Book of Life | Item id: 0876044011 | Value: 0.0
Item: Winter Moon | Item id: 0345386108 | Value: 6.0
Item: Sarah Bishop | Item id: 059032120X | Value: 0.0
Item: Case of Lucy Bending | Item id: 0425060772 | Value: 0.0
Item: A Desert of Pure Feeling (Vintage Contemporaries) | Item id: 0679752714 | Value: 0.0
Item: White Abacus | Item id: 0380796155 | Value: 5.0
Item: The Land of Laughs : A Novel | Item id: 0312873115 | Value: 0.0
Item: Nobody's Son | Item id: 0152022597 | Value: 0.0
Item: Mirror Image | Item id: 0446353957 | Value: 0.0
Item: All I Really Need to Know | Item id: 080410526X | Value: 0.0
Item: Dreamcatcher | Item id: 0743211383 | Value: 7.0
Item: Perplexing Lateral Thinking Puzzles: Scholastic Edition | Item id: 0806917695 | Value: 5.0
Item: Obsidian Butterfly | Item id: 0441007813 | Value: 0.0Recommended items:
23:13:56.438 [main] DEBUG org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender - Recommending items for user ID '276704'
23:13:56.996 [main] DEBUG org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender - Recommendations are: [RecommendedItem[item:185076364212086120, value:10.0], RecommendedItem[item:-591612556174026052, value:10.0], RecommendedItem[item:8244501488765029498, value:10.0], RecommendedItem[item:-6934465359805634419, value:10.0], RecommendedItem[item:2057628558693255423, value:10.0], RecommendedItem[item:-2687357165449897826, value:10.0], RecommendedItem[item:-3143413626485789003, value:10.0], RecommendedItem[item:-7096625993756755430, value:9.86375], RecommendedItem[item:3619295664714735210, value:9.708363], RecommendedItem[item:-6076948342511691177, value:9.708363]]
Item: Keeper of the Heart | Item id: 0380774933 | Value: 10.0
Item: Bleachers | Item id: 0385511612 | Value: 10.0
Item: Salem's Lot | Item id: 0451125452 | Value: 10.0
Item: The Girl Who Loved Tom Gordon | Item id: 0671042858 | Value: 10.0
Item: Mind Prey | Item id: 0425152898 | Value: 10.0
Item: It Came From The Far Side | Item id: 0836220730 | Value: 10.0
Item: Faith of the Fallen (Sword of Truth, Book 6) | Item id: 081257639X | Value: 10.0
Item: The Talisman | Item id: 0345444884 | Value: 9.86375
Item: Hamlet | Item id: 067172262X | Value: 9.708363
Item: Untamed | Item id: 0380769530 | Value: 9.708363基于项目的过滤
项目相似性(ItemSimilarity)是接下来要讨论的重点。基于项目的推荐器很有用,因为它 们能够充分利用项目本身之间的关系:它们将计算建立在项目的相似性而非用户的相似性之上, 项目的相似性是相对稳定的。项目的相似性可以预先计算,不需要实时重新计算。
因此,如果打算使用ItemSimilarity这个类,强烈建议使用GenericItemSimilarity类,这个类可以预先计算项目的相似性。也可以使用PearsonCorrelationSimilarity类,这个类会实时计算相似性。但对于大量数据,你会发现它的计算速度慢得让人难以忍受。
public static ItemBasedRecommender getRecommender() throws Exception {String filePath = ClassUtils.getDefaultClassLoader().getResource("BX-Book-Ratings.csv").getPath();StringItemIdFileDataModel dataModel = new StringItemIdFileDataModel(new File(filePath), ";");ItemSimilarity similarity = new PearsonCorrelationSimilarity(dataModel);ItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, similarity);IDRescorer rescorer = new MyRescorer();String itemISBN = "042513976X";long itemID = dataModel.readItemIDFromString(itemISBN);int noItems = 10;System.out.println("Recommendations for item: " + books.get(itemISBN));System.out.println("Most similar items:");List<RecommendedItem> recommendations = recommender.mostSimilarItems(itemID, noItems);for (RecommendedItem item : recommendations) {itemISBN = dataModel.getItemIdAsString(item.getItemID());System.out.println("Item: " + books.get(itemISBN) + " | Item id: " + itemISBN + " | Value: " + item.getValue());}return recommender;}Recommendations for item: Close to the Bone
Most similar items:
Item: Private Screening | Item id: 0345311396 | Value: 1.0
Item: Heartstone | Item id: 0553569783 | Value: 1.0
Item: Clockers / Movie Tie In | Item id: 0380720817 | Value: 1.0
Item: Rules of Prey | Item id: 0425121631 | Value: 1.0
Item: The Next President | Item id: 0553576666 | Value: 1.0
Item: Orchid Beach (Holly Barker Novels (Paperback)) | Item id: 0061013412 | Value: 1.0
Item: Winter Prey | Item id: 0425141233 | Value: 1.0
Item: Night Prey | Item id: 0425146413 | Value: 1.0
Item: Presumed Innocent | Item id: 0446359866 | Value: 1.0
Item: Dirty Work (Stone Barrington Novels (Paperback)) | Item id: 0451210158 | Value: 1.0上述输出结果中,可以看到输出的一组项目与我们选择的特定项目是相似的。
添加自定义规则到推荐引擎
我们经常会遇到这样的问题:一些业务规则需要提高所选项目的分数。比如,图书数据集中新 到了一本书,我们想给它一个更高的分数。对此,可以使用IDRescorer接口实现完成这个任务。 rescore(long, double):从参数接收itemID与原始分数,返回调整后的分数。 isFiltered(long):若推荐不包含指定项目,则返回true,否则返回false。
// 自定义的重新评分器类,实现 IDRescorer 接口,用于对推荐结果进行重新评分。
class MyRescorer implements IDRescorer {// 判断某个项目是否被过滤,如果返回 true,则该项目将被过滤掉,不参与推荐。// @param itemId 项目ID// @return 如果项目被过滤,返回 true;否则返回 falsepublic boolean isFiltered(long itemId) {return false;}// 对原始评分进行重新评分,可以基于某些条件调整评分。// @param itemId 项目ID// @param originalScore 原始评分// @return 重新评分后的值public double rescore(long itemId, double originalScore) {if (bookIsNew(itemId)) {originalScore *= 1.3;}return Math.random();}// 判断书籍是否是新的,根据项目ID返回一个布尔值。// @param itemId 项目ID// @return 如果书籍是新的,返回 true;否则返回 falseprivate boolean bookIsNew(long itemId) {// TODO Auto-generated method stubreturn false;}
}评估
你可能想知道,如何才能保证推荐引擎返回的推荐项目是靠谱的。准确检测推荐有效程度的 唯一方法就是,在拥有实际用户的真实系统中做A/B测试。比如,A组收到一个随机推荐的项目, 而B组收到我们的推荐引擎推荐的项目。
由于这并非总是可行的,也不实际,所以可以使用脱机统计评估进行估计。一种方法是使用 第1章介绍的k折交叉验证。将数据集分成多个子集,其中一些用来训练我们的推荐引擎,其余的 测试它对未知用户的推荐效果。
Mahout实现了RecommenderEvaluator类,这个类将一个数据集划分成两部分,第一部分 默认为数据的90%,用于生成推荐;其余部分则与评估的偏好值做比较,以测试匹配效果。这个 类不直接接受recommender对象,需要创建一个类实现RecommenderBuilder接口,它为一个 给定的DataModel对象(稍后用于测试)创建一个recommender对象。接下来,让我们看看如 何实现。
首先,创建一个实现RecommenderBuilder接口的类。需要实现buildRecommender方法, 它会返回一个recommender.
recommender对象的类后,我们就可以对RecommenderEvaluator的实例做初始 化。这个类的默认实现是AverageAbsoluteDifferenceRecommenderEvaluator类,用于在 用户的预测评分与实际评分之间计算平均绝对差值。下面代码显示了如何将上面这些内容组合在 一起,以进行Hold-Out测试。
首先,加载数据模型.
接着,初始化evaluator实例.
初始化BookRecommender对象,实现RecommenderBuilder接口
最后,调用evaluate()方法,该方法接收如下参数。
RecommenderBuilder : 该 对象实现了 RecommenderBuilder , 用 于创建待测 试的 recommender。
DataModelBuilder:要使用的DataModelBuilder,若为null,将使用默认的DataModel 实现。
DataModel:用于测试的数据集。
trainingPercentage:表示生成推荐的每个用户偏好所占的比例,其他的则与估计的 偏好值做比较,以评估recommender的性能。
evaluationPercentage:评估中参与的用户在数据模型中所占的比例。
evaluate()方法返回一个double值, 一般来说,值越小,匹配得越好。
// 评估推荐器public static void evaluateRecommender() throws Exception {String filePath = ClassUtils.getDefaultClassLoader().getResource("BX-Book-Ratings.csv").getPath();StringItemIdFileDataModel dataModel = new StringItemIdFileDataModel(new File(filePath), ";");RecommenderEvaluator evaluator = new AverageAbsoluteDifferenceRecommenderEvaluator();RecommenderBuilder builder = new BookRecommender();double result = evaluator.evaluate(builder, null, dataModel, 0.9, 1.0);System.out.println(result);}在线学习引擎
在线学习引擎中的“在线”两字是什么意思呢?上面讲到的推荐引擎对于已有的用户有很好 的工作效果,但对于那些新注册的用户推荐效果不佳。我们肯定也想为这些新用户做一些合理的 推荐。创建一个推荐实例代价很大(它肯定比一个普通的网络请求需要花更长时间),因此不能 每次都创建一个新推荐。
幸运的是,Mahout允许我们向数据模型添加临时用户。一般设置如下:
使用当前数据定期重建整个推荐,比如每天或每小时,具体取决于耗费多长时间。
做推荐时,检查系统中是否有这个用户。
若有,像往常一样结束推荐。
若没有,则创建临时用户,填入偏好,并做推荐。
如果你的内存有限,第一部分(定期重建推荐器)其实很难办到:创建新推荐器时,你需要 在内存中保留数据的两个副本(为了可以处理来自旧推荐器的请求)。然而,由于这对推荐真的 没什么用,所以就不细讲了。
对于临时用户,可以使用一个PlusAnonymousConcurrentUserDataModel类实例包装我 们的数据模型。这个类允许获得一个临时用户ID,以后必须释放这个ID,以便可以重用(这样的 ID数目是有限制的)。得到ID后,必须填写偏好,然后可以像以前一样开始推荐:
// OnlineRecommendation 类是一个在线推荐系统的实现,负责为用户提供个性化的推荐。
public class OnlineRecommendation {// 定义数据文件的路径,使用 ClassUtils 获取默认类加载器的资源路径。public static String PATH = ClassUtils.getDefaultClassLoader().getResource("BX-Book-Ratings.csv").getPath();// 推荐器对象,用于执行推荐操作。Recommender recommender;// 并发用户的数量,默认为 100。int concurrentUsers = 100;// 每次推荐的物品数量,默认为 10。int noItems = 10;// 构造函数,初始化推荐系统。// @throws IOException 如果文件读取失败public OnlineRecommendation() throws IOException {// 创建数据模型对象,使用 StringItemIdFileDataModel 类来处理字符串形式的物品ID。DataModel model = new StringItemIdFileDataModel(new File(PATH), ";");// 创建支持并发和匿名用户的数据模型对象,允许指定并发用户的数量。PlusAnonymousConcurrentUserDataModel plusModel = new PlusAnonymousConcurrentUserDataModel(model, concurrentUsers);// 此处未实现推荐器的初始化,需要在实际使用时完成。// recommender = ...;}// 为指定用户生成推荐列表。// @param userId 用户ID// @param preferences 用户的首选项数组// @return 推荐的项目列表// @throws Exception 如果推荐过程中发生异常public List<RecommendedItem> recommend(long userId, PreferenceArray preferences) throws Exception {// 检查用户是否存在于数据模型中。if (userExistsInDataModel(userId)) {// 如果用户存在,直接调用推荐器的推荐方法,返回推荐结果。return recommender.recommend(userId, noItems);} else {// 如果用户不存在,则将其视为匿名用户。// 获取支持匿名用户的数据模型对象。PlusAnonymousConcurrentUserDataModel plusModel = (PlusAnonymousConcurrentUserDataModel) recommender.getDataModel();// 从数据模型中获取一个可用的匿名用户ID。Long anonymousUserId = plusModel.takeAvailableUser();// 将首选项数组的用户ID设置为匿名用户ID。PreferenceArray temp = preferences;temp.setUserID(0, anonymousUserId);// 将匿名用户的首选项设置到数据模型中。plusModel.setTempPrefs(temp, anonymousUserId);// 为匿名用户生成推荐列表。List<RecommendedItem> results = recommender.recommend(userId, noItems);// 释放匿名用户ID,使其可以被其他请求重用。plusModel.releaseUser(anonymousUserId);// 返回推荐结果。return results;}}// 检查用户是否存在于数据模型中。// 注意:此方法尚未实现,默认返回 false。// @param userId 用户ID// @return 如果用户存在,返回 true;否则返回 falseprivate boolean userExistsInDataModel(long userId) {// TODO Auto-generated method stubreturn false;}
}基于内容的过滤
Mahout框架不包含基于内容的过滤,主要是因为,如何定义相似项目是由你自己决定的。如 果想定义一个基于内容的项目到项目相似度,需要实现自己的ItemSimilarity。比如,我们的 图书数据集中,针对图书相似度,可能制定如下规则: 若类型相同,则将相似度加0.15; 若作者相同,则将相似度加0.50。
下面实现我们自己的相似度测度,如下
public class MyItemSimilarity implements ItemSimilarity {@Overridepublic double itemSimilarity(long itemID1, long itemID2) {// 假设 lookupMyBook 方法会返回 MyBook 对象MyBook book1 = lookupMyBook(itemID1);MyBook book2 = lookupMyBook(itemID2);double similarity = 0.0;// 根据相同类型增加相似度if (book1.getGenre().equals(book2.getGenre())) {similarity += 0.15;}// 根据相同作者增加相似度if (book1.getAuthor().equals(book2.getAuthor())) {similarity += 0.50;}// 你可以根据其他属性进一步调整相似度计算return similarity;}@Overridepublic double[] itemSimilarities(long itemID, long[] itemIDs) throws TasteException {// 这里可以根据 itemID 和 itemIDs 数组计算多个相似度double[] similarities = new double[itemIDs.length];for (int i = 0; i < itemIDs.length; i++) {similarities[i] = itemSimilarity(itemID, itemIDs[i]);}return similarities;}@Overridepublic long[] allSimilarItemIDs(long itemID) throws TasteException {// 这里可以根据 itemID 找出所有相似的 itemID// 例如,找到所有相似度大于某个阈值的 itemIDreturn new long[0]; // 需要根据实际逻辑实现}@Overridepublic void refresh(Collection<Refreshable> collection) {// 刷新方法,可以根据需要实现}// 假设你有一个方法来查找 MyBook 对象private MyBook lookupMyBook(long itemID) {// 这里需要根据实际逻辑实现return new MyBook(); // 示例返回一个空的 MyBook 对象}// 假设你有一个 MyBook 类@Dataprivate static class MyBook {private String genre;private String author;}
}然后,使用这个ItemSimilarity替换LogLikelihoodSimilarity或其他GenericItem- Based Recommender的实现。以上就是在Mahout框架中做基于内容的推荐。
此处给出的示例是基于内容推荐的一种最简单的形式。还有一种方法可以用来创建基于内容 的用户画像(content-based profile of users),它建立在项目特征的加权向量基础之上。权重表示 每个特征对于用户的重要程度,这可以从单独评分的内容向量计算出来。
完整代码
// ItemMemIDMigrator 类继承自 AbstractIDMigrator,用于管理长整型ID和字符串ID之间的映射关系。
public class ItemMemIDMigrator extends AbstractIDMigrator {// 使用 FastByIDMap 来存储长整型ID和字符串ID之间的映射关系。private FastByIDMap<String> itemIDMap;// 构造函数,初始化 itemIDMap,设置初始容量为 10000。public ItemMemIDMigrator() {this.itemIDMap = new FastByIDMap<String>(10000);}// 存储长整型ID和字符串ID之间的映射关系。// @param longID 长整型ID// @param stringID 字符串IDpublic void storeMapping(long longID, String stringID) {itemIDMap.put(longID, stringID);}// 初始化单个字符串ID的映射关系。// @param stringID 字符串ID// @throws TasteException 如果发生异常public void singleInit(String stringID) throws TasteException {// 将字符串ID转换为长整型ID,并存储映射关系。storeMapping(toLongID(stringID), stringID);}// 根据长整型ID获取对应的字符串ID。// @param l 长整型ID// @return 对应的字符串ID// @throws TasteException 如果发生异常@Overridepublic String toStringID(long l) throws TasteException {// 从 itemIDMap 中获取长整型ID对应的字符串ID。return this.itemIDMap.get(l);}
}// StringItemIdFileDataModel 类继承自 FileDataModel,用于处理文件数据模型,特别是处理字符串形式的物品ID。
public class StringItemIdFileDataModel extends FileDataModel {// 用于管理长整型ID和字符串ID之间映射关系的 ItemMemIDMigrator 实例。public ItemMemIDMigrator itemMemIDMigrator;// 构造函数,初始化文件数据模型,并指定分隔符。// @param dataFile 数据文件// @param delimiterRegex 分隔符的正则表达式// @throws IOException 如果文件读取失败public StringItemIdFileDataModel(File dataFile, String delimiterRegex) throws IOException {super(dataFile, delimiterRegex);}// 从字符串中读取物品ID,并将其转换为长整型ID。// @param value 字符串形式的物品ID// @return 长整型形式的物品ID@Overrideprotected long readItemIDFromString(String value) {// 如果 itemMemIDMigrator 为空,则初始化一个新的 ItemMemIDMigrator 实例。if (Objects.isNull(itemMemIDMigrator)) {itemMemIDMigrator = new ItemMemIDMigrator();}// 将字符串形式的物品ID转换为长整型ID。long readValue = itemMemIDMigrator.toLongID(value);try {// 检查长整型ID是否已经存在于 itemMemIDMigrator 中。// 如果不存在,则调用 singleInit 方法初始化映射关系。if (Objects.isNull(itemMemIDMigrator.toStringID(readValue))) {itemMemIDMigrator.singleInit(value);}} catch (Exception e) {// 捕获并打印异常。e.printStackTrace();}// 返回长整型形式的物品ID。return readValue;}// 根据长整型ID获取对应的字符串形式的物品ID。// @param key 长整型ID// @return 字符串形式的物品ID// @throws TasteException 如果发生异常public String getItemIdAsString(long key) throws TasteException {// 通过 itemMemIDMigrator 获取长整型ID对应的字符串形式的物品ID。return itemMemIDMigrator.toStringID(key);}
}// OnlineRecommendation 类是一个在线推荐系统的实现,负责为用户提供个性化的推荐。
public class OnlineRecommendation {// 定义数据文件的路径,使用 ClassUtils 获取默认类加载器的资源路径。public static String PATH = ClassUtils.getDefaultClassLoader().getResource("BX-Book-Ratings.csv").getPath();// 推荐器对象,用于执行推荐操作。Recommender recommender;// 并发用户的数量,默认为 100。int concurrentUsers = 100;// 每次推荐的物品数量,默认为 10。int noItems = 10;// 构造函数,初始化推荐系统。// @throws IOException 如果文件读取失败public OnlineRecommendation() throws IOException {// 创建数据模型对象,使用 StringItemIdFileDataModel 类来处理字符串形式的物品ID。DataModel model = new StringItemIdFileDataModel(new File(PATH), ";");// 创建支持并发和匿名用户的数据模型对象,允许指定并发用户的数量。PlusAnonymousConcurrentUserDataModel plusModel = new PlusAnonymousConcurrentUserDataModel(model, concurrentUsers);// 此处未实现推荐器的初始化,需要在实际使用时完成。// recommender = ...;}// 为指定用户生成推荐列表。// @param userId 用户ID// @param preferences 用户的首选项数组// @return 推荐的项目列表// @throws Exception 如果推荐过程中发生异常public List<RecommendedItem> recommend(long userId, PreferenceArray preferences) throws Exception {// 检查用户是否存在于数据模型中。if (userExistsInDataModel(userId)) {// 如果用户存在,直接调用推荐器的推荐方法,返回推荐结果。return recommender.recommend(userId, noItems);} else {// 如果用户不存在,则将其视为匿名用户。// 获取支持匿名用户的数据模型对象。PlusAnonymousConcurrentUserDataModel plusModel = (PlusAnonymousConcurrentUserDataModel) recommender.getDataModel();// 从数据模型中获取一个可用的匿名用户ID。Long anonymousUserId = plusModel.takeAvailableUser();// 将首选项数组的用户ID设置为匿名用户ID。PreferenceArray temp = preferences;temp.setUserID(0, anonymousUserId);// 将匿名用户的首选项设置到数据模型中。plusModel.setTempPrefs(temp, anonymousUserId);// 为匿名用户生成推荐列表。List<RecommendedItem> results = recommender.recommend(userId, noItems);// 释放匿名用户ID,使其可以被其他请求重用。plusModel.releaseUser(anonymousUserId);// 返回推荐结果。return results;}}// 检查用户是否存在于数据模型中。// 注意:此方法尚未实现,默认返回 false。// @param userId 用户ID// @return 如果用户存在,返回 true;否则返回 falseprivate boolean userExistsInDataModel(long userId) {// TODO Auto-generated method stubreturn false;}
}// 自定义的重新评分器类,实现 IDRescorer 接口,用于对推荐结果进行重新评分。
class MyRescorer implements IDRescorer {// 判断某个项目是否被过滤,如果返回 true,则该项目将被过滤掉,不参与推荐。// @param itemId 项目ID// @return 如果项目被过滤,返回 true;否则返回 falsepublic boolean isFiltered(long itemId) {return false;}// 对原始评分进行重新评分,可以基于某些条件调整评分。// @param itemId 项目ID// @param originalScore 原始评分// @return 重新评分后的值public double rescore(long itemId, double originalScore) {if (bookIsNew(itemId)) {originalScore *= 1.3;}return Math.random();}// 判断书籍是否是新的,根据项目ID返回一个布尔值。// @param itemId 项目ID// @return 如果书籍是新的,返回 true;否则返回 falseprivate boolean bookIsNew(long itemId) {// TODO Auto-generated method stubreturn false;}
}public class BookRecommender implements RecommenderBuilder {public static Map<String, String> books;public static String PATH = ClassUtils.getDefaultClassLoader().getResource("BX-Books.csv").getPath();public static void main(String[] args) throws Exception {books = loadBooks(PATH);//userBased();getRecommender();evaluateRecommender();}// 加载书籍信息到Map中public static Map<String, String> loadBooks(String path) throws Exception {Map<String, String> map = new HashMap<String, String>();BufferedReader br = new BufferedReader(new FileReader(path));String line = "";while ((line = br.readLine()) != null) {String[] str = line.replace("\"", "").split(";");map.put(str[0], str[1]);}br.close();System.out.println("加载图书信息成功:" + map.size());return map;}// 获取推荐器public static ItemBasedRecommender getRecommender() throws Exception {String filePath = ClassUtils.getDefaultClassLoader().getResource("BX-Book-Ratings.csv").getPath();StringItemIdFileDataModel dataModel = new StringItemIdFileDataModel(new File(filePath), ";");ItemSimilarity similarity = new PearsonCorrelationSimilarity(dataModel);ItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, similarity);IDRescorer rescorer = new MyRescorer();String itemISBN = "042513976X";long itemID = dataModel.readItemIDFromString(itemISBN);int noItems = 10;System.out.println("Recommendations for item: " + books.get(itemISBN));System.out.println("Most similar items:");List<RecommendedItem> recommendations = recommender.mostSimilarItems(itemID, noItems);for (RecommendedItem item : recommendations) {itemISBN = dataModel.getItemIdAsString(item.getItemID());System.out.println("Item: " + books.get(itemISBN) + " | Item id: " + itemISBN + " | Value: " + item.getValue());}return recommender;}public static void userBased() throws Exception {String filePath = ClassUtils.getDefaultClassLoader().getResource("BX-Book-Ratings.csv").getPath();StringItemIdFileDataModel model = new StringItemIdFileDataModel(new File(filePath), ";");UserSimilarity similarity = new PearsonCorrelationSimilarity(model);UserNeighborhood neighborhood = new ThresholdUserNeighborhood(0.1, similarity, model);UserBasedRecommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);IDRescorer rescorer = new MyRescorer();// List recommendations = recommender.recommend(2, 3, rescorer);long userID = 276704;// 276704;//212124;//277157;int noItems = 10;System.out.println("Rated items:");for (Preference preference : model.getPreferencesFromUser(userID)) {String itemISBN = model.getItemIdAsString(preference.getItemID());System.out.println("Item: " + books.get(itemISBN) + " | Item id: " + itemISBN + " | Value: " + preference.getValue());}System.out.println("\nRecommended items:");List<RecommendedItem> recommendations = recommender.recommend(userID,noItems);for (RecommendedItem item : recommendations) {String itemISBN = model.getItemIdAsString(item.getItemID());System.out.println("Item: " + books.get(itemISBN) + " | Item id: " + itemISBN + " | Value: " + item.getValue());}}// 评估推荐器public static void evaluateRecommender() throws Exception {String filePath = ClassUtils.getDefaultClassLoader().getResource("BX-Book-Ratings.csv").getPath();StringItemIdFileDataModel dataModel = new StringItemIdFileDataModel(new File(filePath), ";");RecommenderEvaluator evaluator = new AverageAbsoluteDifferenceRecommenderEvaluator();RecommenderBuilder builder = new BookRecommender();double result = evaluator.evaluate(builder, null, dataModel, 0.9, 1.0);System.out.println(result);}public static DataModel loadFromDB() throws Exception {MysqlDataSource dbsource = new MysqlDataSource();dbsource.setUser("user");dbsource.setPassword("pass");dbsource.setServerName("localhost");dbsource.setDatabaseName("my_db");DataModel dataModelDB = new MySQLJDBCDataModel(dbsource,"taste_preferences", "user_id", "item_id", "preference","timestamp");return dataModelDB;}public DataModel loadInMemory() {// In-memory DataModel - GenericDataModelsFastByIDMap<PreferenceArray> preferences = new FastByIDMap<PreferenceArray>();PreferenceArray prefsForUser1 = new GenericUserPreferenceArray(10);prefsForUser1.setUserID(0, 1L);prefsForUser1.setItemID(0, 101L);prefsForUser1.setValue(0, 3.0f);prefsForUser1.setItemID(1, 102L);prefsForUser1.setValue(1, 4.5F);preferences.put(1L, prefsForUser1); // use userID as the key//TODO: add others users// Return preferences as new data modelDataModel dataModel = new GenericDataModel(preferences);return dataModel;}@Overridepublic Recommender buildRecommender(DataModel dataModel) throws TasteException {try {return BookRecommender.getRecommender();} catch (Exception e) {e.printStackTrace();}return null;}
}public class MyItemSimilarity implements ItemSimilarity {@Overridepublic double itemSimilarity(long itemID1, long itemID2) {// 假设 lookupMyBook 方法会返回 MyBook 对象MyBook book1 = lookupMyBook(itemID1);MyBook book2 = lookupMyBook(itemID2);double similarity = 0.0;// 根据相同类型增加相似度if (book1.getGenre().equals(book2.getGenre())) {similarity += 0.15;}// 根据相同作者增加相似度if (book1.getAuthor().equals(book2.getAuthor())) {similarity += 0.50;}// 你可以根据其他属性进一步调整相似度计算return similarity;}@Overridepublic double[] itemSimilarities(long itemID, long[] itemIDs) throws TasteException {// 这里可以根据 itemID 和 itemIDs 数组计算多个相似度double[] similarities = new double[itemIDs.length];for (int i = 0; i < itemIDs.length; i++) {similarities[i] = itemSimilarity(itemID, itemIDs[i]);}return similarities;}@Overridepublic long[] allSimilarItemIDs(long itemID) throws TasteException {// 这里可以根据 itemID 找出所有相似的 itemID// 例如,找到所有相似度大于某个阈值的 itemIDreturn new long[0]; // 需要根据实际逻辑实现}@Overridepublic void refresh(Collection<Refreshable> collection) {// 刷新方法,可以根据需要实现}// 假设你有一个方法来查找 MyBook 对象private MyBook lookupMyBook(long itemID) {// 这里需要根据实际逻辑实现return new MyBook(); // 示例返回一个空的 MyBook 对象}// 假设你有一个 MyBook 类@Dataprivate static class MyBook {private String genre;private String author;}
}相关文章:
使用Apache Mahout制作 推荐引擎
目录 创建工程 基本概念 关键概念 基于用户与基于项目的分析 计算相似度的方法 协同过滤 基于内容的过滤 混合方法 创建一个推荐引擎 图书评分数据集 加载数据 从文件加载数据 从数据库加载数据 内存数据库 协同过滤 基于用户的过滤 基于项目的过滤 添加自定…...

Elasticsearch:利用 AutoOps 检测长时间运行的搜索查询
作者:来自 Elastic Valentin Crettaz 了解 AutoOps 如何帮助你调查困扰集群的长期搜索查询以提高搜索性能。 AutoOps 于 11 月初在 Elastic Cloud Hosted 上发布,它通过性能建议、资源利用率和成本洞察、实时问题检测和解决路径显著简化了集群管理。 Au…...

python二元表达式 三元表达式
目录 二元表达式必须要有else,示例: 二元表达式: 三元表达式 可以嵌套成多元表达式 python 代码中,有时写 if else比较占行,把代码变一行的方法就是二元表达式, 二元表达式必须要有else,示例: if img is None:breakcv2.imwrite("aaa.jpg", img) if coun…...

计算机网络 (22)网际协议IP
一、IP协议的基本定义 IP协议是Internet Protocol的缩写,即因特网协议。它是TCP/IP协议簇中最核心的协议,负责在网络中传送数据包,并提供寻址和路由功能。IP协议为每个连接在因特网上的主机(或路由器)分配一个唯一的IP…...

【UI自动化测试】selenium八种定位方式
🏡个人主页:謬熙,欢迎各位大佬到访❤️❤️❤️~ 👲个人简介:本人编程小白,正在学习互联网求职知识…… 如果您觉得本文对您有帮助的话,记得点赞👍、收藏⭐️、评论💬&am…...

REMARK-LLM:用于生成大型语言模型的稳健且高效的水印框架
REMARK-LLM:用于生成大型语言模型的稳健且高效的水印框架 前言 提出这一模型的初衷为了应对大量计算资源和数据集出现伴随的知识产权问题。使用LLM合成类似人类的内容容易受到恶意利用,包括垃圾邮件和抄袭。 ChatGPT等大语言模型LLM的开发取得的进展标志着人机对话交互的范式…...

Android SPRD 工模测试修改
设备有两颗led灯,工模测试需全亮 vendor/sprd/proprietories-source/factorytest/testitem/led.cpp -13,6 13,10 typedef enum{#define LED_BLUE "/sys/class/leds/blue/brightness"#define LED_RED …...
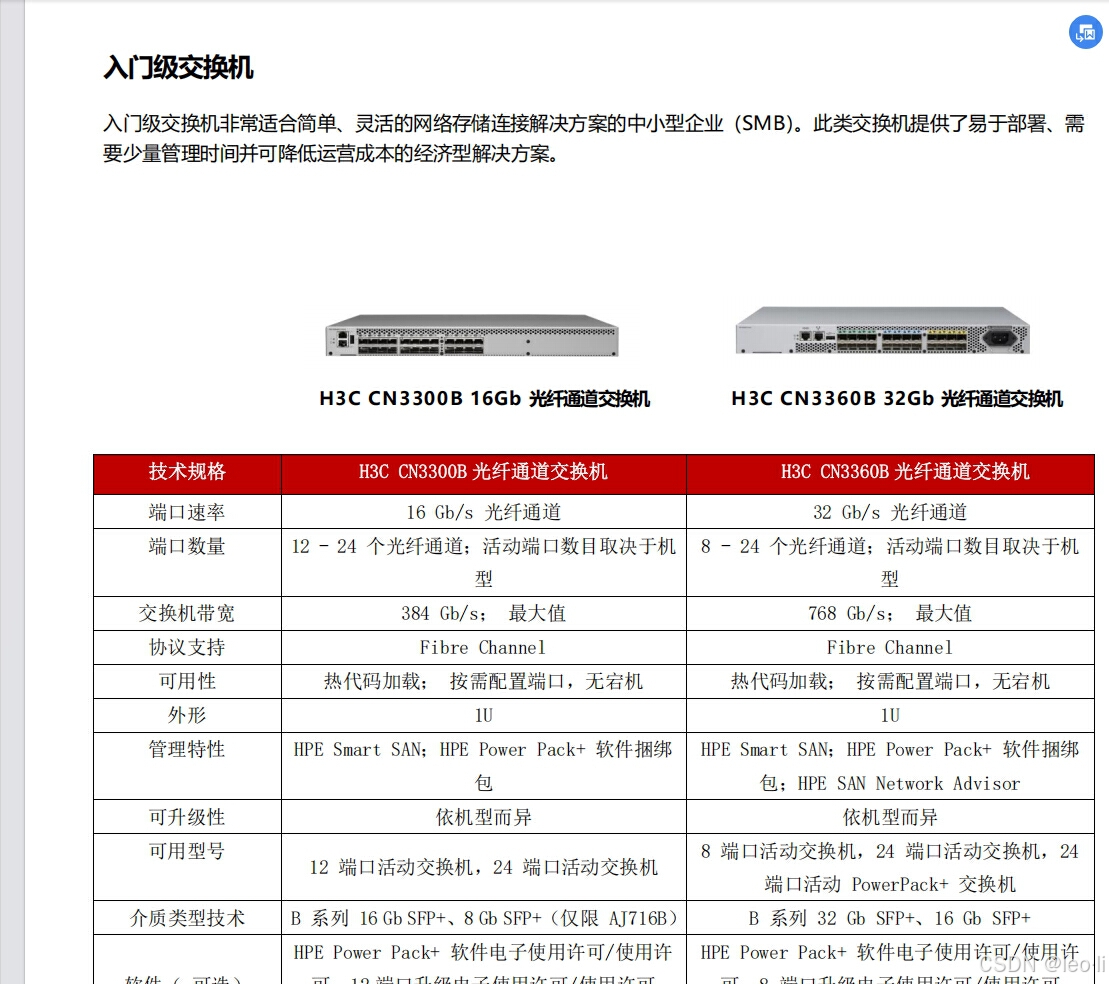
H3C CN3360B光纤存储交换机配置案例
这几天在项目里面遇到了一台光纤存储交换机,需要划Zone来实现服务器外接存储 接下来我就分享我在项目中的配置 我是通过交换机串口进去的,也可以通过网口,串口的配置我就不介绍了 网口配置的地址是:10.77.77.77/24 登入方式&…...
管理失效)
问题:Flask应用中的用户会话(Session)管理失效
我来分享一个常见的PythonWeb开发问题: 问题:Flask应用中的用户会话(Session)管理失效 这是一个在Flask开发中经常遇到的问题。当用户登录后,有时会话会意外失效,导致用户需要重复登录。 解决方案: 1. 首先&#x…...
)
Backend - C# 操作数据库 DB(ADO.NET、LINQ to SQL、EF)
目录 一、ADO.NET(传统) 二、LINQ to SQL(已过时) 三、EF(推荐) 常见的操作数据库的方法:有三种,分别是 ADO.NET、LINQ to SQL、EF 一、ADO.NET(传统) ADO.NE…...
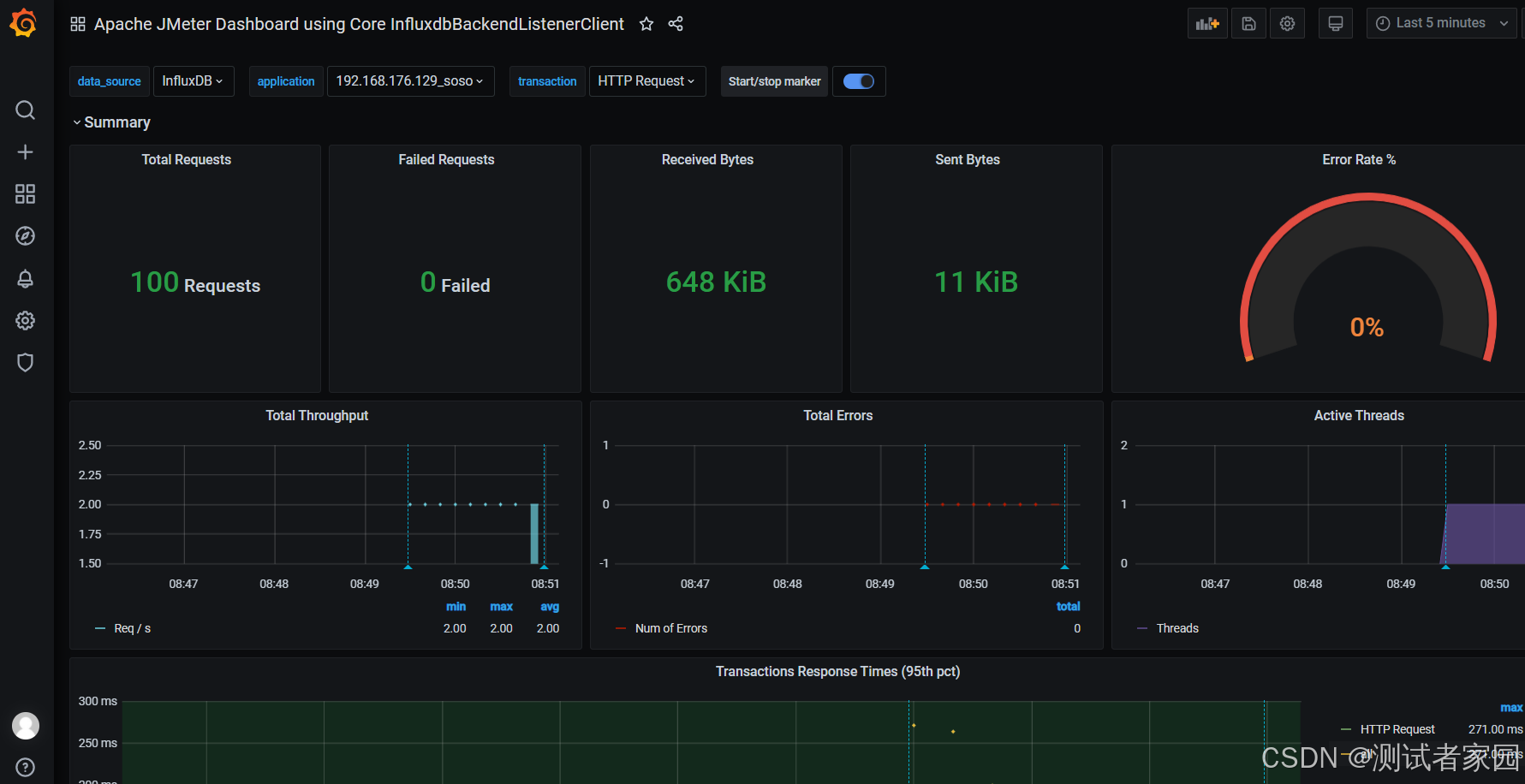
JMeter + Grafana +InfluxDB性能监控 (二)
您可以通过JMeter、Grafana 和 InfluxDB来搭建一个炫酷的基于JMeter测试数据的性能测试监控平台。 下面,笔者详细介绍具体的搭建过程。 安装并配置InfluxDB 您可以从清华大学开源软件镜像站等获得InfluxDB的RPM包,这里笔者下载的是influxdb-1.8.0.x86_…...

springCloud实战
一、Feign的实战 1、使用 1.1步骤 ①引入feign依赖 ②在启动类上加上EnableFeignClients注解,开启Feign客户端 ③编写FeignClient接口 1.2开启feign调用日志 只需在yml配置文件中开启配置即可 feign:client:default:loggerLevel: FULL #feign接口被调用时的…...

从优化算法到分布式训练-提升AI模型收敛速度的系统性分析【附核心实战代码】
本文收录于专栏:精通AI实战千例专栏合集 https://blog.csdn.net/weixin_52908342/category_11863492.html从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 每一个案例都附带关键代码,详细讲解供大家学习,希望可以帮…...

如何在 Windows 10/11 上录制带有音频的屏幕 [3 种简单方法]
无论您是在上在线课程还是参加在线会议,您都可能需要在 Windows 10/11 上录制带有音频的屏幕。互联网上提供了多种可选方法。在这里,本博客收集了 3 种最简单的方法来指导您如何在 Windows 10/11 上使用音频进行屏幕录制。请继续阅读以探索! …...
)
鸿蒙应用开发(2)
鸿蒙应用开发启航计划-CSDN博客 鸿蒙应用开发(1)-CSDN博客 没看过前两篇的,建议请先看上面。 如果你学习完了前两篇,那么你学习这篇文章,就很容易理解了。 这一篇文章将介绍声明式UI的 渲染控制。你需要了解的是&…...

单片机-LED点阵实验
要将第一个点点亮,则 1 脚接高电平 a 脚接低电平,则第一个点就亮了;如果要将第一行点亮,则第 1 脚要接高电平,而(a、b、c、d、e、f、g、h )这些引脚接低电平,那么第一行就会点亮&…...

微服务-Nacos(注册中心)
Nacos Nacos可以看作注册中心配置中心,比Eureka更加强大。 注册中心 在父工程中引入SpringCloudAlibaba的版本依赖 <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId&g…...

【Linux知识】shell编程知识科普
文章目录 概述文件格式语法及例子 文件读写文件读取文件写入错误处理 后台执行shell1. 使用 & 符号2. 使用 nohup 命令3. 使用 screen 或 tmux使用 screen使用 tmux 4. 使用 disown 命令5. 使用系统服务管理器(如 systemd) 概述 Linux shell脚本文件…...

小程序学习06——uniapp组件常规引入和easycom引入语法
目录 一 组件注册 1.1 组件全局注册 1.2 组件全局引入 1.3 组件局部引入 页面引入组件方式 1.3.1 传统vue规范: 1.3.2 通过uni-app的easycom 二 组件的类型 2.1 基础组件列表 一 组件注册 1.1 组件全局注册 (a)新建compoents文件…...

平安产险安徽分公司携手安徽中医药临床研究中心附属医院 共筑儿童安全防护网
为响应金融知识普及教育号召,平安产险安徽分公司联动安徽中医药临床研究中心附属医院,于近日在朝霞小学举办了一场儿童安全防范与健康守护活动。此次活动旨在提升学生的安全防范意识,守护儿童健康成长,同时有力推动金融知识与传统…...

Kimi-VL-A3B-Thinking应用场景:电商商品识别、教育答题与文档分析实操
Kimi-VL-A3B-Thinking应用场景:电商商品识别、教育答题与文档分析实操 1. 引言:当AI能“看懂”图片,你的工作会发生什么变化? 想象一下,你是一个电商运营,每天要处理上千张商品图片,手动打标签…...

Chainlink+Axelar双引擎驱动:DAO跨链治理进入「自动驾驶」时代
引言:DAO治理的「民主困境」与破局之道在2025年的Web3生态中,DAO(去中心化自治组织)已从实验性项目成长为管理超200亿美元资产的决策实体。然而,73%的DAO因投票机制低效而失败(数据来源:DeepDAO…...

PyFluent完整指南:如何用Python代码彻底改变你的CFD仿真工作流
PyFluent完整指南:如何用Python代码彻底改变你的CFD仿真工作流 【免费下载链接】pyfluent Pythonic interface to Ansys Fluent 项目地址: https://gitcode.com/gh_mirrors/pyf/pyfluent PyFluent作为Ansys Fluent的Python接口,为计算流体动力学工…...

用LabVIEW做个智能家居小系统:把温度报警、风扇控制和波形监控都集成到一个VI里
用LabVIEW构建智能家居监控系统:从模块化到集成化实战 在物联网技术快速渗透的今天,智能家居系统正从概念走向普及。对于工程师和学生而言,如何将分散的传感器、控制器整合为有机整体,是提升工程实践能力的关键跳板。LabVIEW作为…...

3.8B小模型大智慧:Phi-4-mini-reasoning数学推理服务SpringBoot一键部署
3.8B小模型大智慧:Phi-4-mini-reasoning数学推理服务SpringBoot一键部署 1. 为什么选择Phi-4-mini-reasoning? 在AI模型部署领域,我们常常面临一个两难选择:大模型效果虽好但资源消耗高,小模型轻量但能力有限。Phi-4…...

Folcolor:用14种色彩重新定义Windows文件管理的艺术
Folcolor:用14种色彩重新定义Windows文件管理的艺术 【免费下载链接】Folcolor Windows explorer folder coloring utility 项目地址: https://gitcode.com/gh_mirrors/fo/Folcolor 你是否曾在成百上千个黄色文件夹中迷失方向?是否曾花费宝贵时间…...

如何用GetQzonehistory一键备份QQ空间?终极数据保存指南
如何用GetQzonehistory一键备份QQ空间?终极数据保存指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否担心QQ空间里那些珍贵的青春记忆会随着时间流逝而消失&#x…...
)
基于stm32的加油站火灾预警系统设计(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T0752309M设计简介:本设计是基于stm32的加油站火灾预警系统设计,主要实现以下功能:通过温湿度传感器检测温湿度 通过烟雾…...

STM32F030K6T6 定时器触发ADC采样的DMA传输实战
1. 为什么需要定时器触发ADC采样? 在嵌入式开发中,ADC(模数转换器)采样是获取模拟信号的关键环节。传统的手动触发或查询式ADC采样存在两个明显痛点:一是需要CPU频繁介入,二是采样间隔难以精确控制。比如用…...

【AIAgent架构知识图谱集成终极指南】:20年架构师亲授3大落地陷阱与5步标准化接入法
第一章:AIAgent架构知识图谱集成全景认知 2026奇点智能技术大会(https://ml-summit.org) AI Agent 架构正从单任务响应模型演进为具备持续感知、推理与行动能力的自主认知体。知识图谱作为结构化世界知识的语义中枢,其与 AI Agent 的深度集成࿰…...