分布式环境下定时任务扫描时间段模板创建可预订时间段
🎯 本文详细介绍了场馆预定系统中时间段生成的实现方案。通过设计场馆表、时间段模板表和时间段表,系统能够根据场馆的提前预定天数生成未来可预定的时间段。为了确保任务执行的唯一性和高效性,系统采用分布式锁机制和定时任务,避免重复生成时间段。通过流式查询优化大数据处理,减少内存占用和网络延迟。同时,使用唯一复合索引保证时间段生成的幂等性,避免重复插入。为提高系统性能,引入二级缓存和Redis管道技术,加速数据查询和缓存预热,确保用户在预定时间段时获得快速响应。整体方案兼顾了系统的稳定性、高效性和可扩展性。
文章目录
- 简介
- 数据表设计
- 定时任务
- 根据时间段模板创建时间段
- MySQL流式查询
- 时间段生成如何保证幂等性
- 二级缓存
- Redis管道
- 代码实现
简介
在场馆管理员创建了时间段模板之后,需要使用定时任务,每天定时生成未来可接受预定的时间段
数据表设计
【场馆表】
该表存储了 提前可预定天数(advance_booking_day),为什么要存储这个,是因为生成时间段的时候,需要参考该字段生成多少天内的时间段
DROP TABLE IF EXISTS `venue`;
CREATE TABLE `venue`(`id` bigint NOT NULL COMMENT 'ID',`create_time` datetime,`update_time` datetime,`is_deleted` tinyint default 0 COMMENT '逻辑删除 0:没删除 1:已删除',`organization_id` bigint NOT NULL COMMENT '所属机构ID',`name` varchar(30) NOT NULL COMMENT '场馆名称',`type` char(4) NOT NULL COMMENT '场馆类型 1:篮球馆(场) 2:足球场 3:羽毛球馆(场) 4:排球馆(场)100:体育馆 1000:其他',`address` varchar(255) NOT NULL COMMENT '场馆地址',`description` varchar(255) DEFAULT '' COMMENT '场馆描述,也可以说是否提供器材等等',`open_time` varchar(2000) NOT NULL COMMENT '场馆营业时间',`phone_number` varchar(11) NULL DEFAULT '' COMMENT '联系电话',`status` tinyint NOT NULL COMMENT '场馆状态 0:关闭 1:开放 2:维护中',`is_open` tinyint NOT NULL COMMENT '是否对外开放 0:否 1:是 如果不对外开放,需要相同机构的用户才可以预定',`advance_booking_day` int NOT NULL COMMENT '提前可预定天数,例如设置为1,即今天可预订明天的场',`start_booking_time` time NOT NULL COMMENT '开放预订时间',PRIMARY KEY (`id`) USING BTREE
)
【时间段模板表】
在这里需要使用 已生成到的日期(last_generated_date)来记录已经生成到的日期,避免重复生成时间段。比如说advance_booking_day=7,在 1月1 的时候,其实就已经生成了 [1月2, 1月8] 的时间段数据,那 1月2 的时候,其实只需要生成 1月9 的时间段即可
DROP TABLE IF EXISTS `time_period_model`;
CREATE TABLE `time_period_model`( `id` bigint NOT NULL COMMENT 'ID',`create_time` datetime,`update_time` datetime,`is_deleted` tinyint default 0 COMMENT '逻辑删除 0:没删除 1:已删除',`price` decimal(10,2) NOT NULL COMMENT '该时间段预订使用价格(元)',`partition_id` bigint NOT NULL COMMENT '场区id',`begin_time` time NOT NULL COMMENT '时间段开始时间HH:mm(不用填日期)',`end_time` time NOT NULL COMMENT '时间段结束时间HH:mm(不用填日期)', `effective_start_date` date NOT NULL COMMENT '生效开始日期', `effective_end_date` date NOT NULL COMMENT '生效结束日期', `last_generated_date` date COMMENT '已生成到的日期',`status` tinyint default 0 COMMENT '0:启用;1:停用', PRIMARY KEY (`id`) USING BTREE,INDEX `idx_partition_id` (`partition_id`)
);
【时间段表】
之所以要创建唯一复合索引,是因为怕重复生成时间段,为什么会出现重复生成时间段的情况,看到后面就明白了
DROP TABLE IF EXISTS `time_period`;
CREATE TABLE `time_period`( `id` bigint NOT NULL COMMENT 'ID',`create_time` datetime,`update_time` datetime,`is_deleted` tinyint default 0 COMMENT '逻辑删除 0:没删除 1:已删除',`partition_id` bigint NOT NULL COMMENT '场区id',`price` decimal(10,2) NOT NULL COMMENT '该时间段预订使用价格(元)',`stock` int NOT NULL COMMENT '库存',`booked_slots` bigint unsigned NOT NULL DEFAULT 0 COMMENT '已预订的场地(位图表示)',`period_date` date NOT NULL COMMENT '预定日期', `begin_time` time NOT NULL COMMENT '时间段开始时间HH:mm(不用填日期)',`end_time` time NOT NULL COMMENT '时间段结束时间HH:mm(不用填日期)', PRIMARY KEY (`id`) USING BTREE,INDEX `idx_partition_id` (`partition_id`),UNIQUE INDEX `idx_unique_partition_period_time` (`partition_id`, `period_date`, `begin_time`, `end_time`)
);
定时任务
由于项目是微服务架构,在开发定时任务的时候需要考虑任务执行的唯一性,否则集群的所有机器都会执行同一个任务,浪费计算机算力,可以通过直接加一个分布式锁,只让集群中的一台机器执行整个定时任务,但是如果这样的话,其他机器处于空闲状态。为了提高机器的利用率和定时任务的执行效率,这里将不同表的时间段模板扫描工作交与不同机器实现
【实现思路】
- 第一次定时任务:机器通过对表加锁,如果可以加锁成功,则扫描时间段模板进行时间段生成。注意,加锁时设置过期时间为2小时,如果任务执行完成,将锁状态设置1,同时过期时间设置更长
- 第二次定时任务:用来兜底,避免第一次定时任务执行时有机器宕机,其负责的任务并没有完成。第二次扫描就是找出没有执行完成的任务,重新执行一遍。在第二次定时任务时,要么任务已经执行完成,其任务状态被设置为1,要么没有执行,其锁状态已经过期
package com.vrs.config.scheduled;import com.vrs.constant.RedisCacheConstant;
import com.vrs.service.TimePeriodModelService;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import java.util.concurrent.TimeUnit;/*** @Author dam* @create 2024/11/17 16:44*/
@Component
@RequiredArgsConstructor
@Slf4j
public class TimePeriodScheduledTasks {private final TimePeriodModelService timePeriodModelService;private final StringRedisTemplate stringRedisTemplate;private int tableNum = 16;/*** 在每天凌晨1点执行* 扫描数据库的时间段模板,生成可预定的时间段*/@Scheduled(cron = "0 0 1 * * ?")public void timePeriodGenerator1() {for (int i = 0; i < tableNum; i++) {timePeriodGenerate(i);}}/*** 兜底一次,保证时间段都生成成功了* 扫描数据库的时间段模板,生成可预定的时间段*/@Scheduled(cron = "0 0 4 * * ?")public void timePeriodGenerator2() {for (int i = 0; i < tableNum; i++) {// 获取当前表的状态String status = stringRedisTemplate.opsForValue().get(String.format(RedisCacheConstant.VENUE_TIME_PERIOD_GENERATE_KEY, i));// 如果状态为 "1",说明任务已经完成,跳过if ("1".equals(status)) {continue;}// 如果还没有完成,尝试获取锁并执行任务timePeriodGenerate(i);}}/*** 时间段生成* @param tableIndex*/private void timePeriodGenerate(int tableIndex) {// 0状态设置2小时就过期,方便没有执行完成的任务在兜底时可以重新执行boolean isSuccess = stringRedisTemplate.opsForValue().setIfAbsent(String.format(RedisCacheConstant.VENUE_TIME_PERIOD_GENERATE_KEY, tableIndex),"0", 2, TimeUnit.HOURS).booleanValue();if (isSuccess) {try {// --if-- 设置键成功,说明集群中的其他机器还没有扫描当前表,由当前机器执行// 执行时间段生成timePeriodModelService.generateTimePeriodByModel(tableIndex);// 时间段生成成功,设置状态为1,过期时间段也设置长一点,方便兜底时检测stringRedisTemplate.opsForValue().set(String.format(RedisCacheConstant.VENUE_TIME_PERIOD_GENERATE_KEY, tableIndex),"1", 6, TimeUnit.HOURS);} catch (Exception e) {// 如果任务执行失败,删除锁,以便其他机器可以重试stringRedisTemplate.delete(String.format(RedisCacheConstant.VENUE_TIME_PERIOD_GENERATE_KEY, tableIndex));log.error("时间段生成失败,表编号:{},错误信息:{}", tableIndex, e.getMessage(), e);}} else {// 如果锁已被占用,检查任务是否已完成String currentStatus = stringRedisTemplate.opsForValue().get(String.format(RedisCacheConstant.VENUE_TIME_PERIOD_GENERATE_KEY, tableIndex));if (!"1".equals(currentStatus)) {log.warn("表编号:{} 的任务未完成,但锁已被占用,可能由其他机器处理中", tableIndex);}}}
}
根据时间段模板创建时间段
MySQL流式查询
首先要解决的事情是:如何高效扫描时间段模板表?
很容易想到的是,分页查询时间段模板,一批一批进行时间段生成,还可以套一个多线程,并行执行不同批次的任务。但分页查询有一个最大的缺点,在处理大数据时,每次分页都需要执行完整的查询并跳过前面的记录,尤其是深分页时,查询效率非常低下。
为了优化这个问题,本文使用流式查询来处理。
流式查询是一种处理和传输查询结果的方式,它允许客户端逐行接收来自数据库的数据,而不是一次性获取整个结果集。这种方式可以显著减少内存占用和网络延迟,优化资源使用,并且能够更快地响应用户请求,特别适合处理大规模数据集或实时性要求高的应用场景。通过流式查询,即使面对海量数据,应用程序也能保持高效和流畅的用户体验。相较于分页查询,它效率高的一个原因是,它每次查询都是从上一条数据开始,而不是每次从头来过
时间段生成如何保证幂等性
由于在扫描时间段模板生成时间段时,服务器可能发生宕机,在兜底时,可能该任务再次被集群中的其他机器执行。但是由于部分时间段模板其实已经被第一台机器扫描过,相应的时间段也已经创建完成,在兜底时,如何保证已创建的时间段不会再被重复生成,最简单的一种实现方式:给partition_id, period_date, begin_time, end_time生成唯一复合索引,这样重复创建时间段时,插入数据库就会失败。
还有一个问题,为了提高数据插入效率,使用了批量插入策略,即累积一定的数据量才进行插入。但 Mybatis Plus 提供的saveBatch函数是原子性的,要么全部插入成功,要么全部插入失败。由于部分时间段可能已经被第一台机器创建完成,兜底时插入数据库可能出现唯一索引异常,这样会导致其他没有创建过的时间段也插入失败。因此我们需要自己实现一段SQL,让批量插入时,及时部分数据插入异常,也不影响其他数据
<insert id="insertBatchIgnore">INSERT IGNORE INTO time_period (id,create_time,update_time,is_deleted,partition_id,price,stock,booked_slots,period_date,begin_time,end_time) VALUES<foreach collection="timePeriodDOList" item="item" separator=",">(#{item.id},NOW(),NOW(),0,#{item.partitionId},#{item.price},#{item.stock},#{item.bookedSlots},#{item.periodDate},#{item.beginTime},#{item.endTime})</foreach>
</insert>
二级缓存
在生成未来时间段时,需要查询advance_booking_day才知道要生成未来多少天的时间段,由于很多时间段模板可能都来源于同一个分区、同一个场馆,为了加速这个查询,可以使用缓存来提高效率,即第一次查询之后将分区ID对应的场馆信息存储起来,第二次获取就很快了。
但如果每次从Redis缓存中加载数据,需要多次网络I/O,为了进一步的效率提升,可以使用本地缓存 HashMap 来进一步优化,即每次先从本地缓存中查询,查询不到再去 Redis 缓存中加载。
二级缓存策略:
- 首先使用本地缓存(如
HashMap)存储分区ID对应的场馆信息,以实现极快的查询速度; - 当本地缓存未命中时,再从Redis缓存中加载数据。Redis作为第二级缓存,提供了比数据库更快的数据访问速度,并且能够跨多个实例共享缓存数据,确保了数据的一致性和高可用性。
Redis管道
在创建时间段时,还需要做的一件事是缓存预热,即将相应的时间段库存、时间段信息添加到 Redis 缓存中,保证用户在预定时间段时有较快的响应速度,而不是预定时再去数据库中查询放到缓存中。
由于需要添加大量时间段的缓存,如果每个数据都单独提交给 Redis,会导致大量的网络 I/O 操作,从而降低效率。因此,是否有一种类似于数据库批量插入的方式来优化这一过程?
Redis 管道(Pipeline)是一种用于优化客户端与 Redis 服务器之间通信的技术,它允许客户端一次性发送多个命令给服务器,并在所有命令执行完毕后一次性接收所有的回复。这种方式减少了客户端与服务器之间的往返时间,尤其是在需要执行大量命令时,能够显著提高性能。
/*** 使用管道来批量将数据存储到Redis中** @param timePeriodDOList*/
@Override
public void batchPublishTimePeriod(List<TimePeriodDO> timePeriodDOList) {if (timePeriodDOList == null || timePeriodDOList.size() == 0) {return;}/// 将时间段存放到数据库中
// this.saveBatch(timePeriodDOList);baseMapper.insertBatchIgnore(timePeriodDOList);/// 将时间段信息放到缓存中// 创建一个管道回调RedisCallback<Void> pipelineCallback = connection -> {// 开始管道connection.openPipeline();for (TimePeriodDO timePeriodDO : timePeriodDOList) {// 时间段开始时间long timePeriodStartMill = DateUtil.combineLocalDateAndLocalTimeToDateTimeMill(timePeriodDO.getPeriodDate(), timePeriodDO.getBeginTime());// 计算从现在到时间段开始还有多少毫秒 + 余量(86400000表示一天)//todo 待确认 cacheTimeSecond 是否一定为正数long cacheTimeSecond = (timePeriodStartMill - System.currentTimeMillis() + 86400000) / 1000;// 时间段信息connection.setEx(String.format(RedisCacheConstant.VENUE_TIME_PERIOD_KEY, timePeriodDO.getId()).getBytes(),cacheTimeSecond,JSON.toJSONString(timePeriodDO).getBytes());// 库存connection.setEx(String.format(RedisCacheConstant.VENUE_TIME_PERIOD_STOCK_KEY, timePeriodDO.getId()).getBytes(),cacheTimeSecond,JSON.toJSONString(timePeriodDO.getStock()).getBytes());}// 执行管道中的所有命令connection.closePipeline();return null;};// 使用StringRedisTemplate执行管道回调stringRedisTemplate.execute(pipelineCallback);
}
代码实现
package com.vrs.service.impl;import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.vrs.constant.RedisCacheConstant;
import com.vrs.convention.exception.ClientException;
import com.vrs.convention.page.PageResponse;
import com.vrs.convention.page.PageUtil;
import com.vrs.domain.dto.req.TimePeriodModelListReqDTO;
import com.vrs.domain.entity.PartitionDO;
import com.vrs.domain.entity.TimePeriodDO;
import com.vrs.domain.entity.TimePeriodModelDO;
import com.vrs.domain.entity.VenueDO;
import com.vrs.mapper.TimePeriodModelMapper;
import com.vrs.service.PartitionService;
import com.vrs.service.TimePeriodModelService;
import com.vrs.service.TimePeriodService;
import com.vrs.service.VenueService;
import com.vrs.utils.DateUtil;
import com.vrs.utils.SnowflakeIdUtil;
import groovy.util.logging.Slf4j;
import lombok.Cleanup;
import lombok.RequiredArgsConstructor;
import lombok.SneakyThrows;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;import javax.sql.DataSource;
import java.math.BigDecimal;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;/*** @author dam* @description 针对表【time_period_model_0】的数据库操作Service实现* @createDate 2024-11-17 14:29:46*/
@Service
@RequiredArgsConstructor
@Slf4j
public class TimePeriodModelServiceImpl extends ServiceImpl<TimePeriodModelMapper, TimePeriodModelDO>implements TimePeriodModelService {private final DataSource dataSource;private final TimePeriodService timePeriodService;private final StringRedisTemplate stringRedisTemplate;private final PartitionService partitionService;private final VenueService venueService;/*** 流式处理*/@Override@SneakyThrowspublic void generateTimePeriodByModel(int tableIndex) {// 获取 dataSource Bean 的连接@Cleanup Connection conn = dataSource.getConnection();@Cleanup Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);stmt.setFetchSize(Integer.MIN_VALUE);long start = System.currentTimeMillis();// 查询sql,只查询关键的字段String sql = "SELECT id,price,partition_id,begin_time,end_time,effective_start_date,effective_end_date,last_generated_date FROM time_period_model_" + tableIndex + " where is_deleted = 0 and status = 0";@Cleanup ResultSet rs = stmt.executeQuery(sql);HashMap<Long, Integer> partitionIdAndAdvanceBookingDayMap = new HashMap<>();List<TimePeriodDO> timePeriodDOInsertBatch = new ArrayList<>();List<TimePeriodModelDO> timePeriodDOModelUpdateBatch = new ArrayList<>();int batchSize = 2000;SimpleDateFormat sdf = new SimpleDateFormat("HH:mm");// 每次获取一行数据进行处理,rs.next()如果有数据返回true,否则返回falsewhile (rs.next()) {// 获取数据中的属性long id = rs.getLong("id");long partitionId = rs.getLong("partition_id");Date beginTime = sdf.parse(rs.getString("begin_time"));Date endTime = sdf.parse(rs.getString("end_time"));BigDecimal price = rs.getBigDecimal("price");Date effectiveStartDate = rs.getDate("effective_start_date");Date effectiveEndDate = rs.getDate("effective_end_date");// 上次生成到的日期Date lastGeneratedDate = rs.getDate("last_generated_date");int advanceBookingDay = getAdvanceBookingDayByPartitionId(partitionIdAndAdvanceBookingDayMap, partitionId);PartitionDO partitionDO = partitionService.getPartitionDOById(partitionId);if (partitionDO == null) {continue;}// 如果当前分区存在可预订分区的缓存,这里进行删除,因为生成了新的,需要重新查询数据库stringRedisTemplate.delete(String.format(RedisCacheConstant.VENUE_TIME_PERIOD_BY_PARTITION_ID_KEY,partitionId));// 这里其实不需要每天定时任务,都把advanceBookingDay都生成一遍,例如今天已经生成了未来七天的时间段了,那么明天其实只需要生成第八天的时间段即可Date generateDate = null;for (int i = 1; i <= advanceBookingDay; i++) {// 获取要生成的日期generateDate = new Date(System.currentTimeMillis() + i * 24 * 60 * 60 * 1000);if (lastGeneratedDate != null && generateDate.before(lastGeneratedDate)) {// 如果对应日期的时间段已经被生成过了,直接跳过continue;}// 检查明天的日期是否在这个范围内boolean isInDateRange = generateDate.after(effectiveStartDate) && generateDate.before(effectiveEndDate);if (isInDateRange) {TimePeriodDO timePeriodDO = TimePeriodDO.builder().partitionId(partitionId).price(price).stock(partitionDO.getNum()).bookedSlots(0L).periodDate(DateUtil.dateToLocalDate(generateDate)).beginTime(DateUtil.dateToLocalTime(beginTime)).endTime(DateUtil.dateToLocalTime(endTime)).build();timePeriodDO.setId(SnowflakeIdUtil.nextId());timePeriodDOInsertBatch.add(timePeriodDO);if (timePeriodDOInsertBatch.size() >= batchSize) {// --if-- 数据量够了,存储数据库timePeriodService.batchPublishTimePeriod(timePeriodDOInsertBatch);timePeriodDOInsertBatch.clear();}}}if (generateDate != null) {// 批量更新时间段模板的最新生成日期TimePeriodModelDO timePeriodModelDO = new TimePeriodModelDO();timePeriodModelDO.setId(id);timePeriodModelDO.setPartitionId(partitionId);timePeriodModelDO.setLastGeneratedDate(generateDate);timePeriodDOModelUpdateBatch.add(timePeriodModelDO);if (timePeriodDOModelUpdateBatch.size() >= batchSize) {// --if-- 数据量够了,修改数据库this.updateLastGeneratedDateBatch(timePeriodDOModelUpdateBatch);timePeriodDOModelUpdateBatch.clear();}}}// 处理最后一波数据if (timePeriodDOInsertBatch.size() >= 0) {// 将时间段存储到数据库timePeriodService.batchPublishTimePeriod(timePeriodDOInsertBatch);timePeriodDOInsertBatch.clear();}if (timePeriodDOModelUpdateBatch.size() >= 0) {// --if-- 数据量够了,修改数据库this.updateLastGeneratedDateBatch(timePeriodDOModelUpdateBatch);timePeriodDOModelUpdateBatch.clear();}log.debug("流式生成时间段花费时间:" + ((System.currentTimeMillis() - start) / 1000));}private void updateLastGeneratedDateBatch(List<TimePeriodModelDO> timePeriodDOModelUpdateBatch) {if (timePeriodDOModelUpdateBatch == null || timePeriodDOModelUpdateBatch.size() == 0) {return;}baseMapper.updateLastGeneratedDateBatch(timePeriodDOModelUpdateBatch);}/*** 获取分区的提前预定时间* 使用二级缓存,本地缓存找不到,再去Redis中找,还找不到的话,去数据库中找** @param partitionIdAndAdvanceBookingDayMap* @param partitionId* @return*/private int getAdvanceBookingDayByPartitionId(HashMap<Long, Integer> partitionIdAndAdvanceBookingDayMap, long partitionId) {if (partitionIdAndAdvanceBookingDayMap.containsKey(partitionId)) {return partitionIdAndAdvanceBookingDayMap.get(partitionId);}VenueDO venueDO = venueService.getVenueDOByPartitionId(partitionId);partitionIdAndAdvanceBookingDayMap.put(partitionId, venueDO.getAdvanceBookingDay());return venueDO.getAdvanceBookingDay();}
}
相关文章:

分布式环境下定时任务扫描时间段模板创建可预订时间段
🎯 本文详细介绍了场馆预定系统中时间段生成的实现方案。通过设计场馆表、时间段模板表和时间段表,系统能够根据场馆的提前预定天数生成未来可预定的时间段。为了确保任务执行的唯一性和高效性,系统采用分布式锁机制和定时任务,避…...

SQL刷题笔记——高级条件语句
目录 1题目:SQL149 根据指定记录是否存在输出不同情况 2 作答解析 3 知识点 3.1 count函数 3.2 内连接与左连接 1题目:SQL149 根据指定记录是否存在输出不同情况 2 作答解析 #正确答案 select uid, incomplete_cnt, incomplete_rate from (select …...

与 Oracle Dataguard 相关的进程及作用分析
与 Oracle Dataguard 相关的进程及作用分析 目录 与 Oracle Dataguard 相关的进程及作用分析与 Oracle Dataguard 相关的进程及作用分析一、主库的进程1、LGWR 进程2、ARCH进程3、LNS 进程 二、备库的进程1、RFS 进程2、ARCH3、MRP(Managed Recovery Process&#x…...

游戏语音趋势解析,社交互动有助于营造沉浸式体验
语音交互的新架构出现 2024 年标志着对话语音 AI 取得了突破,出现了结合 STT → LLM → TTS 模型来聆听、推理和回应对话的协同语音系统。 OpenAI 的 ChatGPT 语音模式将语音转语音技术变成了现实,引入了基于音频和文本信息进行端到端预训练的模型&…...

美食烹饪互动平台
本文结尾处获取源码。 一、相关技术 后端:Java、JavaWeb / Springboot。前端:Vue、HTML / CSS / Javascript 等。数据库:MySQL 二、相关软件(列出的软件其一均可运行) IDEAEclipseVisual Studio Code(VScode)Navica…...

【51单片机零基础-chapter5:模块化编程】
模块化编程 将以往main中泛型的代码,放在与main平级的c文件中,在h中引用. 简化main函数 将原来main中的delay抽出 然后将delay放入单独c文件,并单独开一个delay头文件,里面放置函数的声明,相当于收纳delay的c文件里面写的函数的接口. 注意,单个c文件所有用到的变量需要在该文…...

Redis中的主从/Redis八股
四、Redis主从 1.搭建主从架构 不像是负载均衡,这里是主从,是因为redis大多数是读少的是写 步骤 搭建实例(建设有三个实例,同一个ip不同端口号) 1)创建目录 我们创建三个文件夹,名字分别叫700…...

ROS笔记
自定义消息的发布 1.创建空间包 1.创建ROS工作空间: mkdir -p ~/catkin_ws/src cd ~/catkin_ws/ catkin_make source devel/setup.bash 创建工作空间,编译设置环境 2.创建工作空间中的ROS包: cd ~/catkin_ws/src catkin_create_pkg your_pa…...

在 Linux 上调试 C++ 程序
在 Linux 上调试 C 程序是一个常见的开发任务,Linux 提供了多种强大的工具来帮助你进行调试。以下是常用的调试方法和工具. 1. 使用 GDB (GNU Debugger) GDB 是最常用且功能强大的命令行调试器,适用于 C、C 和其他语言。它允许你逐步执行代码、设置断点…...
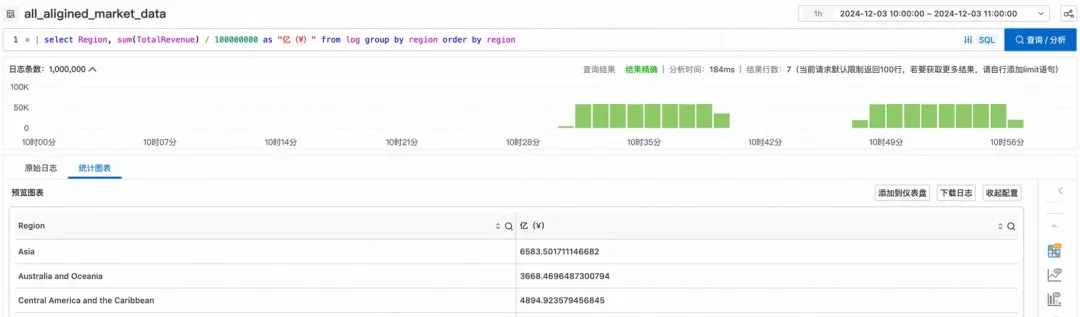
让跨 project 联查更轻松,SLS StoreView 查询和分析实践
作者:章建(处知) 概述 日志服务 SLS 是云原生观测和分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务。SLS 提供了多地域支持 [ 1] ,方便用户可以根据数据源就近接入 SLS 服务࿰…...

20240107-类型转换
1. 自动类型转换 不损失数据精度的前提下,可自动完成变量的类型转换;不损失数据精度指不将超出变量可表示范围的值赋给该变量。 2.强制类型转换 若出现精度损失,java不会自动完成类型转换,需强制进行,见下代码的第8…...

关于Linux PAM模块下的pam_listfile
讲《Linux下禁止root远程登录访问》故事的时候,说好会另开一篇讲讲pam_listfile。我们先看看pam_listfile的man文档怎么介绍的。 下面这些就好比人物的简介,甚是恼人;让人看得不明就里,反正“他大舅他二舅都是他舅”。可以直接跳…...

OKHttp调用第三方接口,响应转string报错okhttp3.internal.http.RealResponseBody@4a3d0218
原因分析 通过OkHttp请求网络,结果请求下来的数据一直无法解析并且报错,因解析时String res response.body().toString() 将toString改为string即可!...

弱电与电力工程领域,如何通过工程项目管理软件提升效率
在弱电与电力工程领域,通过益企工程云等工程项目管理软件提升效率的方法主要体现在以下几个方面: 1.智能化管理 自动化流程:益企工程云通过自动化处理日常任务和流程,减少手动操作,提高工作效率。 智能预警ÿ…...

引领实时数据分析新时代:阿里云实时数仓 Hologres
在数字化和智能化转型的浪潮中,数据已成为企业决策和运营优化的重要资产。传统的数据仓库解决方案虽然在一定程度上能够帮助企业管理数据,但随着业务需求的不断变化,实时数据处理和高效分析的能力显得愈加重要。为了应对这一挑战,…...

什么是中间件中间件有哪些
什么是中间件? 中间件(Middleware)是指在客户端和服务器之间的一层软件组件,用于处理请求和响应的过程。 中间件是指介于两个不同系统之间的软件组件,它可以在两个系统之间传递、处理、转换数据,以达到协…...

css中的部分文字特性
文章目录 一、writing-mode二、word-break三、word-spacing;四、white-space五、省略 总结归纳常见文字特性,后续补充 一、writing-mode 默认horizontal-tbwriting-mode: vertical-lr; 从第一排开始竖着排,到底部再换第二排,文字与文字之间从…...
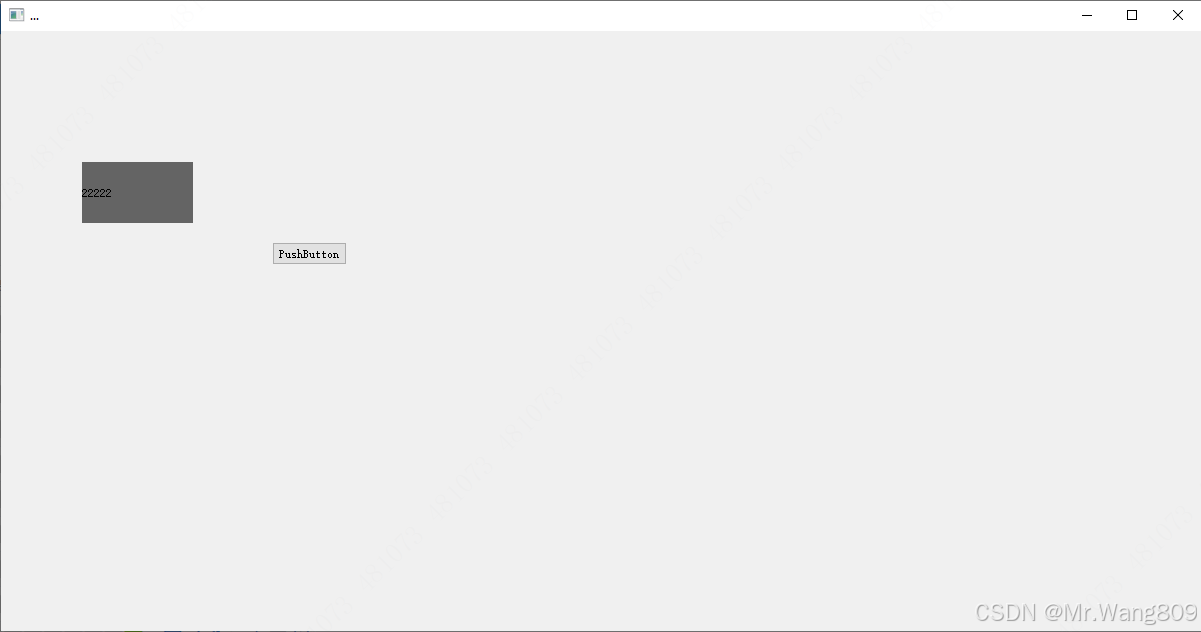
PyQt5 UI混合开发,控件的提升
PromoteLabelTest.py 提升的类 import sys from PyQt5.QtWidgets import QApplication, QWidget,QVBoxLayout,QTextEdit,QPushButton,QHBoxLayout,QFileDialog,QLabelclass PromoteLabel(QLabel):def __init__(self,parent None):super().__init__(parent)self.setText("…...

IP查询于访问控制保护你我安全
IP地址查询 查询方法: 命令行工具: ①在Windows系统中,我们可以使用命令提示符(WINR)查询IP地址,在弹窗中输入“ipconfig”命令查看本地网络适配器的IP地址等配置信息; ②在Linux系统中&…...

SpringBoot数据层解决方案
文章目录 1. 数据层解决方案2. 数据源技术 1. 数据层解决方案 现有数据层解决方案技术选型:Druid MyBatis-Plus MySQL 数据源:DruidDataSource持久化技术:MyBatis-Plus / MyBatis数据库:MySQL 下面的研究就分为三个层面进行研…...

深夜告警炸裂?这份Linux故障排查“作战地图”请收好匚
先唠两句:参数就像餐厅点单 把API想象成一家餐厅的“后厨系统”。 ? 路径参数/dishes/{dish_id} -> 好比你要点“宫保鸡丁”这道具体的菜,它是菜单(资源路径)的一部分。 查询参数/dishes?spicytrue&typeSichuan -> …...

用Python和PyTorch复现CVPR2019 DIM攻击:如何通过随机缩放和填充提升对抗样本的‘黑盒’攻击力
用Python和PyTorch实战CVPR2019 DIM攻击:从理论到代码的完整实现指南 对抗样本研究领域近年来发展迅猛,而CVPR2019提出的DIM(Diverse Input Method)方法因其出色的黑盒攻击能力成为经典。本文将带您从零开始,用PyTorch…...

Nucleus Co-Op:重新定义单机游戏的多人同屏革命
Nucleus Co-Op:重新定义单机游戏的多人同屏革命 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 想象一下这样的场景:你和朋…...
)
Zynq UltraScale实战:Linux A53与裸机R5共享内存的5个关键步骤(附代码)
Zynq UltraScale实战:Linux A53与裸机R5共享内存的5个关键步骤(附代码) 在异构计算架构中,Zynq UltraScale MPSoC凭借其独特的双核Cortex-A53与实时核Cortex-R5组合,成为工业控制、自动驾驶等领域的理想选择。但如何让…...
技术)
鸿蒙6的**星盾安全(StarShield)技术
鸿蒙6的星盾安全(StarShield)**** 是当前移动与全场景OS领域最体系化、最主动、最贴近用户真实场景的安全架构之一。它不是简单的“补丁式安全”,而是从芯片→内核→AI→用户场景的全链路纵深防御,核心价值在于:把安全…...

Qwen3.5-9B助力VSCode高效开发:CodeX风格智能编码实战
Qwen3.5-9B助力VSCode高效开发:CodeX风格智能编码实战 1. 为什么需要本地化智能编码助手 在软件开发过程中,代码补全和智能提示已经成为提升效率的刚需。但主流云端方案如GitHub Copilot存在几个痛点:网络延迟影响响应速度、企业代码安全顾…...

UDOP-large功能体验:如何用一句英文提问提取文档关键信息
UDOP-large功能体验:如何用一句英文提问提取文档关键信息 1. 引言:让AI帮你读文档 每天我们都会遇到需要从文档中提取信息的场景:可能是学术论文的标题和摘要,可能是发票上的关键数字,也可能是表格中的特定数据。传统…...
)
收藏!33岁十年传统程序员被裁后,靠大模型重获新生(小白/中年程序员必看)
33岁,深耕十年的传统程序员,在行业优化潮的席卷下,毫无征兆地收到了裁员通知。没有提前预警,没有缓冲时间,手里的离职证明,像一块巨石,砸碎了我以为“技术立身就能安身立命”的执念。 十年间&am…...

工业五官:11 老鸟血泪Tips + 新手避坑清单
11 老鸟血泪Tips + 新手避坑清单 卷一“工业生命的诞生——从大脑到五官”第三篇终于来了!工业五官——传感器的超级感知世界!PLC是大脑,机器人是舞伴,伺服是肌肉,那这些传感器就是“眼睛、耳朵、鼻子、手”啊!没它们,机器就是瞎子聋子,啤酒瓶来了也不知道推,哈哈。以…...

Intv_AI_MK11 硬件开发辅助:Proteus仿真与电路设计问题咨询
Intv_AI_MK11 硬件开发辅助:Proteus仿真与电路设计问题咨询 1. 硬件开发者的新助手 作为一名电子工程师,你是否经常在Proteus仿真中遇到各种头疼的问题?元器件选型拿不准、电路连接总是报错、仿真参数设置不合理...这些看似小问题往往能消耗…...