深度学习中的正则化方法
最近看到了正则化的内容,发现自己对正则化的理解已经忘得差不多了,这里在整理一下,方便以后查阅。
深度学习中的正则化方法
- 1. L2 正则化(L2 Regularization)
- 2. L1 正则化(L1 Regularization)
- 3. L1 和 L2 正则化结合(Elastic Net)
- 4. Dropout 正则化
- 5. 数据增强(Data Augmentation)
- 6. 早停(Early Stopping)
- 7. Batch Normalization
- 8. 权重衰减(Weight Decay)
- 9. 梯度惩罚(Gradient Penalty)
- 10. 特征选择和降维
- 总结
- 相关博客
在深度学习中,正则化(Regularization)是用来防止模型过拟合的一种技术。过拟合是指模型在训练数据上表现很好,但在新数据或验证数据上表现差,无法泛化。正则化的主要目标是通过控制模型复杂度,使模型能够更好地处理未知数据。以下是几种常见的正则化方法:
1. L2 正则化(L2 Regularization)
- 原理:L2 正则化通过
在损失函数中添加所有模型参数的平方和,来惩罚过大的权重。常见的形式是:
L = L original + λ ∑ i w i 2 L = L_{\text{original}} + \lambda \sum_{i} w_i^2 L=Loriginal+λi∑wi2
其中 (L_{\text{original}}) 是原始损失函数,(w_i) 是模型的权重,(\lambda) 是正则化强度的超参数。 - 效果:L2 正则化倾向于将权重值压缩得比较小,减少模型的复杂度,从而提高泛化能力。
- 应用场景:L2 正则化广泛应用于神经网络的训练中,尤其是在回归问题中。
2. L1 正则化(L1 Regularization)
- 原理:L1 正则化通过
在损失函数中添加所有模型参数的绝对值和,来惩罚过大的权重。其形式为:
L = L original + λ ∑ i ∣ w i ∣ L = L_{\text{original}} + \lambda \sum_{i} |w_i| L=Loriginal+λi∑∣wi∣ - 效果:L1 正则化倾向于将一些权重推到零,这样可以实现特征选择(自动去除不重要的特征)。因此,L1 正则化适合处理高维稀疏数据。
- 应用场景:L1 正则化在特征选择和稀疏模型中非常有效。
3. L1 和 L2 正则化结合(Elastic Net)
- 原理:Elastic Net 是 L1 和 L2 正则化的结合,它结合了两者的优势,通常形式为:
L = L original + λ 1 ∑ i ∣ w i ∣ + λ 2 ∑ i w i 2 L = L_{\text{original}} + \lambda_1 \sum_{i} |w_i| + \lambda_2 \sum_{i} w_i^2 L=Loriginal+λ1i∑∣wi∣+λ2i∑wi2
其中, λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 分别控制 L1 和 L2 正则化的强度。 - 效果:Elastic Net 既可以进行特征选择(L1 正则化的作用),又能有效地控制模型的复杂度(L2 正则化的作用)。它对数据的特征具有较强的适应性。
- 应用场景:Elastic Net 常用于线性模型和回归问题中,特别是在特征数量远大于样本数量时。
4. Dropout 正则化
- 原理:Dropout 是一种在训练过程中随机“丢弃”部分神经元的方法。这意味着每次训练时,网络中某些神经元的输出会被随机设为零,从而
减少神经元之间的相互依赖。 - 效果:通过随机丢弃神经元,Dropout 可以有效防止过拟合,促使神经网络更加鲁棒。它通过减少神经网络的复杂性来提高泛化能力。
- 应用场景:Dropout 主要用于神经网络(尤其是深度神经网络和卷积神经网络),尤其是在面对较大数据集时非常有效。
5. 数据增强(Data Augmentation)
- 原理:数据增强通过在训练过程中对训练数据进行随机变换(如旋转、平移、缩放、翻转等),从而
生成更多的训练样本。 - 效果:数据增强可以扩充训练数据集,增加模型对多样化输入的鲁棒性,从而减少过拟合的风险。它尤其对计算机视觉任务(如图像分类、目标检测)有显著效果。
- 应用场景:数据增强广泛用于图像、语音和文本处理等任务中。
6. 早停(Early Stopping)
- 原理:早停方法通过监控模型在验证集上的表现,来决定何时停止训练。通常,当验证误差开始上升而训练误差继续下降时,就会停止训练。
- 效果:早停可以
防止模型在训练数据上过度拟合,从而提高模型的泛化能力。 - 应用场景:早停常用于神经网络训练过程中,尤其是在处理小型数据集时。
7. Batch Normalization
- 原理:Batch Normalization(批量归一化)是一种对每一层的输出进行规范化处理的方法,即通过将每一层的输出标准化为零均值和单位方差,从而
加速训练并使得网络更稳定。 - 效果:Batch Normalization 不仅有助于提高训练速度,还能起到正则化作用,减少过拟合。它能够减少对初始化和学习率的依赖。
- 应用场景:Batch Normalization 广泛用于深度神经网络和卷积神经网络的训练中。
8. 权重衰减(Weight Decay)
- 原理:权重衰减与 L2 正则化相似,它通过
在优化过程中引入权重的平方惩罚项来限制权重的大小,从而减少模型的复杂度。 - 效果:权重衰减能有效防止网络过拟合,尤其是在训练数据有限时。
- 应用场景:权重衰减广泛应用于深度学习的优化过程中,尤其是针对大规模模型。
9. 梯度惩罚(Gradient Penalty)
- 原理:梯度惩罚是对神经网络的梯度大小进行正则化的技术,目的是约束网络的梯度不至于过大,避免过拟合。
- 效果:通过对梯度的惩罚,梯度惩罚能促使模型学习到
更加平滑的决策边界,从而提高模型的泛化能力。 - 应用场景:梯度惩罚在对抗训练、生成对抗网络(GAN)和强化学习中具有广泛应用。
10. 特征选择和降维
- 原理:通过选择对预测有用的特征或对数据进行降维(如 PCA)来
减少模型的输入维度,从而降低模型复杂度。 - 效果:特征选择和降维可以减少过拟合,提高模型的可解释性和计算效率。
- 应用场景:广泛应用于机器学习中的监督学习任务,尤其是高维数据集的处理。
总结
正则化方法的目的是通过控制模型复杂度和限制模型的自由度,从而提高模型的泛化能力。不同的正则化方法适用于不同的应用场景,具体选择哪种方法通常依赖于问题的类型、数据集的大小、模型的结构等因素。通过合理应用正则化方法,可以有效避免模型过拟合,提高其在未知数据上的表现。
相关博客
深度模型中的正则化、梯度裁剪、偏置初始化操作
相关文章:

深度学习中的正则化方法
最近看到了正则化的内容,发现自己对正则化的理解已经忘得差不多了,这里在整理一下,方便以后查阅。 深度学习中的正则化方法 1. L2 正则化(L2 Regularization)2. L1 正则化(L1 Regularization)3.…...

前端报告 2024:全新数据,深度解析未来趋势
温馨提示: 此报告为国际版全球报告,其中所涉及的技术应用、工具偏好、开发者习惯等情况反映的是全球前端开发领域的综合态势。由于国内外技术发展环境、行业生态以及企业需求等存在差异,可能有些内容并不完全契合国内的实际情况,请大家理性阅读,批判性地吸收其中的观点与信…...

计算机网络之---子网划分与IP地址
子网划分与IP地址的关系 在计算机网络中,子网划分(Subnetworking)是将一个网络划分为多个子网络的过程。通过子网划分,可以有效地管理和利用IP地址空间,提高网络的性能、安全性和管理效率。 子网划分的基本目的是通过…...

计算机网络 (31)运输层协议概念
一、概述 从通信和信息处理的角度看,运输层向它上面的应用层提供通信服务,它属于面向通信部分的最高层,同时也是用户功能中的最低层。运输层的一个核心功能是提供从源端主机到目的端主机的可靠的、与实际使用的网络无关的信息传输。它向高层用…...
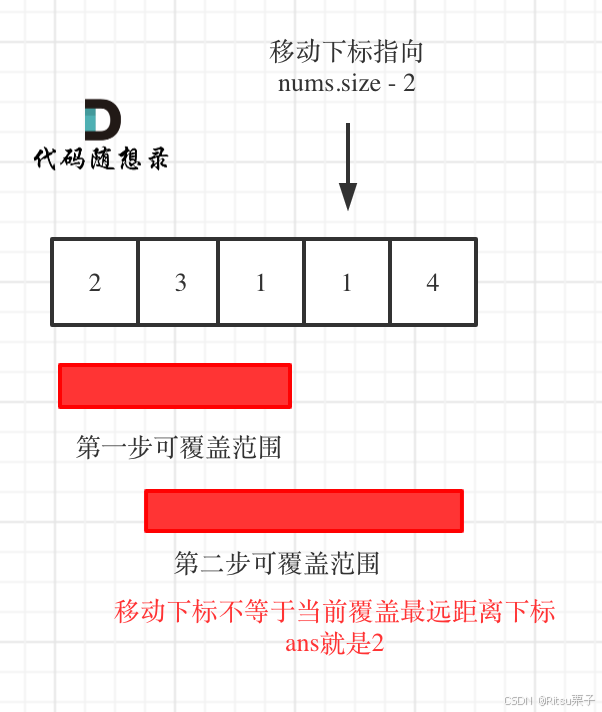
代码随想录算法训练营day28
代码随想录算法训练营 —day28 文章目录 代码随想录算法训练营前言一、122.买卖股票的最佳时机II二、55. 跳跃游戏三、跳跃游戏 II方法一方法二 1005. K 次取反后最大化的数组和总结 前言 今天是算法营的第28天,希望自己能够坚持下来! 今日任务&#x…...

建立时间和保持时间
建立时间 在时钟有效沿到来之前,数据必须维持一段时间保持不变,这段时间就是建立时间 Tsetup 1 基本概念 建立时间(Setup Time): 在 SystemVerilog 中,建立时间是指在时钟信号的有效边沿(例如…...

vue,router路由传值问题,引用官方推荐
参考贴https://blog.csdn.net/m0_57033755/article/details/129927829 根据官方文档的更新日志,建议使用state传值 官方文档更新日志 实际的console结果 传值 router.push({ name: KnowledgeDetail, state: { params } });接收值 const historyParams histor…...

AIDD-人工智能药物设计-AlphaFold系列:年终回顾,AlphaFold迄今为止的实际应用案例
AlphaFold系列:年终回顾,AlphaFold迄今为止的实际应用案例 01 引言 AlphaFold由 DeepMind 团队开发,最初在蛋白质结构预测竞赛 CASP 中惊艳亮相。随着 AlphaFold2 和后续版本的迭代进步,其精度和通用性不断提升,逐渐走…...

Scala语言的面向对象编程
Scala语言的面向对象编程 引言 在当今的软件开发中,面向对象编程(OOP)是一种非常强大且广泛使用的编程范式。Scala是一种现代编程语言,结合了面向对象编程和函数式编程的特性,非常适合用于大规模软件的开发。本文将介…...

MySQL学习记录1【DQL和DCL】
SQL学习记录 该笔记从DQL处开始记录 DQL之前值得注意的点 字段 BETWEEN min AND max 可以查询区间[min, max]的数值如果同一个字段需要满足多个OR条件,可以采取 字段 IN(数值1, 数值2, 数值3....)LIKE语句 字段 LIKE ___%%% 表示模糊匹配,_匹配一个字段…...

验证码转发漏洞
开发人员有时候会以数组的形式接收用户的手机号并遍历执行,这时就可以在注册或登录页面填写两个手机号并点击发送验证码,这两个手机号会同时收到相同验证码,可以用任意一个手机号登录或注册,即验证码转发漏洞。 1、burpsuite内置…...

使用 C++ 实现神经网络:从基础到高级优化
引言 在现代机器学习中,神经网络已经成为最重要的工具之一。虽然 Python 提供了诸如 TensorFlow、PyTorch 等强大的机器学习库,但如果你想深入理解神经网络的实现原理,或者出于某些性能、资源限制的考虑,使用 C 来实现神经网络会是…...
)
【WRF运行报错】总结WRF运行时报错及解决方案(持续更新)
目录 ./real.exe错误1:ERROR while reading namelist physics./wrf.exe错误1:FATAL CALLED FROM FILE: <stdin> LINE: 2419 Warning: too many input landuse types参考./real.exe 错误1:ERROR while reading namelist physics 执行./real.exe时,报错如下: taski…...

Kotlin语言的循环实现
Kotlin语言中的循环实现 Kotlin是一种现代的、跨平台的编程语言,广泛应用于Android开发、后端服务及多种其他软件开发领域。与Java类似,Kotlin也支持多种循环结构,包括for循环、while循环和do while循环。掌握这些循环结构是每个Kotlin开发者…...

基于CNN的人脸识别考勤管理系统实现
随着技术的不断进步,人脸识别技术已经在各行各业得到了广泛的应用,尤其在 考勤管理 上,它提供了更加智能、便捷、精准的解决方案。本篇博客将介绍如何基于 PyQt5 和 MySQL 实现一个 人脸识别考勤系统,并通过具体代码展示如何通过图…...

Android基于回调的事件处理
Android 中的回调机制:基于回调的事件处理详解 在 Android 开发中,回调(Callback)是一种常见的事件处理机制,主要用于异步操作和事件通知。与传统的基于监听器的事件处理相比,回调机制更加灵活、通用&…...

postgis和地理围栏
postgis postgis是pg数据库的一个插件,除原数据类型外(int varchar)、新增了空间数据类型(geography和geometry)。比如我们新建一张道路表road(字段有名称varchar、建设时间timestamp、地理位置geometry),可以将道路名字、建设时间存进去,同…...

《鸿蒙系统AI技术:筑牢复杂网络环境下的安全防线》
在当今数字化时代,复杂网络环境给智能系统带来了诸多安全挑战,而鸿蒙系统中的人工智能技术却展现出强大的安全保障能力,为用户在复杂网络环境中的安全保驾护航。 微内核架构:安全基石 鸿蒙系统采用微内核架构,将核心…...

SQL SERVER__RSN 恢复的深入解析
1. RSN 的工作原理 RSN 是 SQL Server 内部用于跟踪和管理备份和恢复操作顺序的编号。每次数据库备份(包括完整备份、差异备份和事务日志备份)都会生成一个唯一的 RSN。SQL Server 在恢复过程中使用 RSN 来确保备份文件按正确的顺序应用,从而…...

面试加分项:Android Framework PMS 全面概述和知识要点
在Android面试时,懂得越多越深android framework的知识,越为自己加分。 目录 第一章:PMS 基础知识 1.1 PMS 定义与工作原理 1.2 PMS 的主要任务 1.3 PMS 与相关组件的交互 第二章:PMS 的核心功能 2.1 应用安装与卸载机制 2.2 应用更新与版本管理 2.3 组件管理 第…...
:圆弧轨迹平滑优化与MATLAB实践)
机械臂速成小指南(十九):圆弧轨迹平滑优化与MATLAB实践
1. 机械臂圆弧轨迹规划基础概念 机械臂的圆弧轨迹规划是工业自动化中的常见需求,比如在焊接、喷涂、装配等场景中,机械臂末端需要沿着圆弧路径运动。与直线轨迹相比,圆弧轨迹需要考虑更多的几何约束和运动连续性。 在实际应用中,圆…...

消费级GPU福音:百川2-13B-4bits+OpenClaw自动化测试报告
消费级GPU福音:百川2-13B-4bitsOpenClaw自动化测试报告 1. 为什么选择这个组合? 去年冬天,我盯着显卡监控软件里跳动的显存占用数字,突然意识到一个问题:大多数开源大模型对消费级GPU太不友好了。动辄20GB以上的显存…...

Mac开发者必备:OpenClaw对接Qwen3-32B实现Xcode日志自动分析
Mac开发者必备:OpenClaw对接Qwen3-32B实现Xcode日志自动分析 1. 为什么需要自动化Xcode日志分析 作为一个长期与Xcode打交道的iOS开发者,我每天至少有2小时耗在编译错误和运行时日志的排查上。那些冗长的符号化崩溃日志、晦涩的Swift类型推断错误、以及…...

COMSOL仿真石墨烯吸收器,带视频演示,一步一步教学,原文章来自于一篇二区文章。 图片展示为...
COMSOL仿真石墨烯吸收器,带视频演示,一步一步教学,原文章来自于一篇二区文章。 图片展示为原文献结果,均可复现,视频里面包括设计步骤,可以用来学习操作仿真操作最近在研究石墨烯吸收器的仿真,发…...

Harness Engineering 的三个 Scaling 维度:统一框架下的技术架构深度解析
当我们谈论「Harness Engineering」时,究竟在讨论什么?这个看似简单的问题,却揭示了当前AI agent领域最核心的架构挑战。 术语混乱的根源:同一个词,三件完全不同的事 2026年第一季度,OpenAI、Cursor和Ant…...

解放加密音乐:ncmdump的格式转换革新
解放加密音乐:ncmdump的格式转换革新 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 一、价值定位:破解NCM格式限制的技术方案 ncmdump作为一款开源工具,专为破解网易云音乐NCM加密格式而设计&am…...

Block Diffusion【202503】:在自回归与扩散语言模型之间插值【Interpolating Between Autoregressive and Diffusion LM】
块扩散:在自回归与扩散语言模型之间插值 Marianne Arriola† ∗ Aaron Kerem Gokaslan† Justin T. Chiu‡ Zhihan Yang† Zhixuan Qi† Jiaqi Han Subham Sekhar Sahoo† Volodymyr Kuleshov† 摘要 扩散语言模型因其并行生成和可控性的潜力,相比自回归模型具有独特…...

2026年在职研究生论文降AI工具推荐:理论与实践结合部分如何处理
2026年在职研究生论文降AI工具推荐:理论与实践结合部分如何处理 导师发消息说论文AI率超标的时候,我正在食堂吃饭。筷子都差点拿不稳。 后来用了三天时间研究在职研究生论文降AI,踩了不少坑但总算搞定了。最后稳定在用的就是嘎嘎降AI&#…...

Ubuntu24.04下Qt6高效安装指南:从镜像加速到依赖解决
1. 准备工作:系统检查与资源规划 在开始安装Qt6之前,我们需要先做好基础准备工作。很多新手容易忽略这个环节,结果安装到一半才发现磁盘空间不足或者系统版本不兼容。我自己就曾经吃过这个亏,当时安装到90%突然报错,排…...

2025届最火的六大降AI率工具横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在人工智能辅助写作的进程当中,所生成的内容常常呈现出机械性、重复性以及冗余修…...