Mysql--基础篇--多表查询(JOIN,笛卡尔积)
在MySQL中,多表查询(也称为联表查询或JOIN操作)是数据库操作中非常常见的需求。通过多表查询,你可以从多个表中获取相关数据,并根据一定的条件将它们组合在一起。MySQL支持多种类型的JOIN操作,每种JOIN都有不同的用途和行为。
1、JOIN的基本概念
JOIN是一种用于从多个表中检索数据的操作。它允许你根据某些条件将两个或多个表中的行组合在一起。JOIN操作的核心思想是基于表之间的关联字段(通常是外键)来匹配行,并返回符合条件的结果集。
(1)、关联字段
- 主键(Primary Key):唯一标识表中每一行的字段。
- 外键(Foreign Key):一个表中的字段,引用另一个表的主键。外键用于建立表与表之间的关系。
(2)、JOIN类型
MySQL支持以下几种主要的JOIN类型:
- 内连接(INNER JOIN):只返回两个表中满足连接条件的行。
- 左连接(LEFT JOIN):返回左表中的所有行,即使右表中没有匹配的行,结果集中右表的列将填充为NULL。
- 右连接(RIGHT JOIN):返回右表中的所有行,即使左表中没有匹配的行,结果集中左表的列将填充为NULL。
- 全外连接(FULL OUTER JOIN):返回两个表中的所有行,无论是否满足连接条件。MySQL 不直接支持FULL OUTER JOIN,但可以通过UNION实现类似的效果。
- 交叉连接(CROSS JOIN):返回两个表的笛卡尔积,即每个表中的每一行都与另一个表中的每一行组合。
2、JOIN的语法
(1)、内连接(INNER JOIN)
内连接是最常用的JOIN类型,它只返回两个表中满足连接条件的行。
示例:
假设我们有两个表employees和departments,其中employees表包含员工信息,departments表包含部门信息。employees表中的department_id字段是外键,引用了departments表的id字段。
sql:
-- 查询所有有部门的员工及其所属部门名称
SELECT employees.name, departments.name AS department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.id;
结果:
只返回那些有对应部门的员工信息。如果某个员工没有分配到任何部门,则该员工不会出现在结果集中。
(2)、左连接(LEFT JOIN)
左连接返回左表中的所有行,即使右表中没有匹配的行。对于右表中没有匹配的行,结果集中右表的列将填充为NULL。
示例:
查询所有员工及其所属部门名称,即使某些员工没有分配到部门
sql:
SELECT employees.name, departments.name AS department_name
FROM employees
LEFT JOIN departments ON employees.department_id = departments.id;
结果:
返回所有员工的信息。对于没有分配到部门的员工,department_name列将显示为NULL。
(3)、右连接(RIGHT JOIN)
右连接返回右表中的所有行,即使左表中没有匹配的行。对于左表中没有匹配的行,结果集中左表的列将填充为NULL。
示例:
查询所有部门及其员工,即使某些部门没有员工
sql:
SELECT employees.name, departments.name AS department_name
FROM employees
RIGHT JOIN departments ON employees.department_id = departments.id;
结果:
返回所有部门的信息。对于没有员工的部门,employees.name 列将显示为 NULL。
(4)、全外连接(FULL OUTER JOIN)
全外连接返回两个表中的所有行,无论是否满足连接条件。MySQL不直接支持FULL OUTER JOIN,但可以通过 UNION 实现类似的效果。
示例:
查询所有员工及其所属部门,以及所有部门及其员工
sql:
SELECT employees.name, departments.name AS department_name
FROM employees
LEFT JOIN departments ON employees.department_id = departments.id
UNION
SELECT employees.name, departments.name AS department_name
FROM employees
RIGHT JOIN departments ON employees.department_id = departments.id;
结果:
返回所有员工和部门的信息。对于没有分配到部门的员工,department_name列将显示为NULL;对于没有员工的部门,employees.name列将显示为NULL。
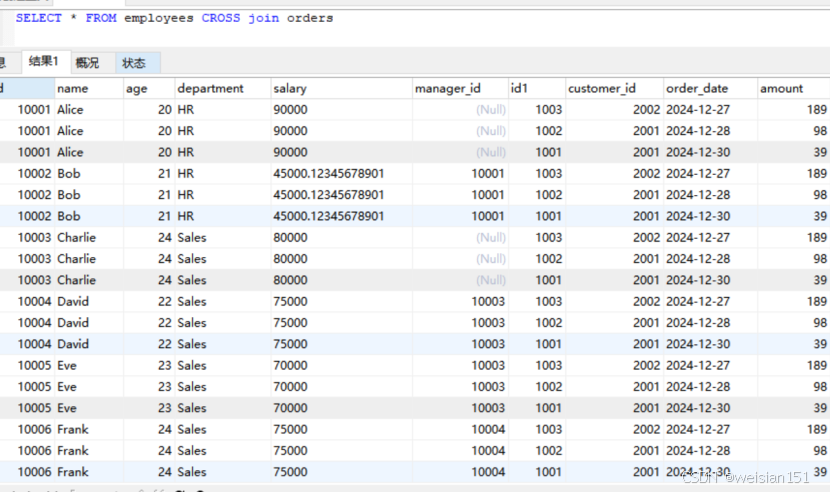
(5)、交叉连接(CROSS JOIN)
交叉连接返回两个表的笛卡尔积,即每个表中的每一行都与另一个表中的每一行组合。
示例:
查询所有员工与所有部门的组合
sql:
SELECT employees.name, departments.name AS department_name
FROM employees
CROSS JOIN departments;
结果:
返回每个员工与每个部门的组合,结果集的行数等于employees表的行数乘以 departments表的行数。
3、多表查询的高级用法
(1)、多表JOIN
你可以在一个查询中连接多个表。只需在FROM子句中依次添加多个JOIN语句即可。
示例:
假设我们有三个表:employees(员工表)、departments(部门表)和salaries(工资表)。我们希望查询每个员工的姓名、所属部门名称以及他们的工资。
sql:
SELECT employees.name, departments.name AS department_name, salaries.salary
FROM employees
INNER JOIN departments ON employees.department_id = departments.id
INNER JOIN salaries ON employees.id = salaries.employee_id;
结果:
返回每个员工的姓名、所属部门名称以及他们的工资。
(2)、自连接(Self Join)
自连接是指一个表与自身进行连接。这通常用于处理具有层次结构的数据,例如员工的上下级关系。
示例:
假设employees表中有一个manager_id字段,表示每个员工的上级领导。我们希望查询每个员工及其上级领导的姓名。
sql:
SELECT e1.name AS employee_name, e2.name AS manager_name
FROM employees e1
LEFT JOIN employees e2 ON e1.manager_id = e2.id;
结果:
返回每个员工及其上级领导的姓名。对于没有上级领导的员工,manager_name列将显示为NULL。
(3)、子查询(Subquery)
子查询是指在一个查询中嵌套另一个查询。子查询可以用于过滤、聚合等操作。
示例:
假设我们想查询工资高于平均工资的员工。
sql:
SELECT employees.name, salaries.salary
FROM employees
INNER JOIN salaries ON employees.id = salaries.employee_id
WHERE salaries.salary > (SELECT AVG(salary) FROM salaries);
结果:
返回工资高于平均工资的员工及其工资。
4、JOIN的性能优化
多表查询可能会对性能产生影响,尤其是在处理大量数据时。为了提高多表查询的性能,可以采取以下几种优化措施:
(1)、索引优化
-
确保连接字段上有索引:在JOIN操作中,连接条件中的字段(如外键)应该有索引。索引可以显著提高查询的执行速度。
-
覆盖索引:如果查询中涉及的列都在索引中,MySQL可以直接从索引中获取数据,而不需要访问实际的表数据。这种情况下,查询性能会大幅提升。
(2)、避免不必要的列
- 只选择需要的列:在SELECT语句中,尽量只选择你需要的列,而不是使用 SELECT *。这样可以减少I/O操作,提升查询性能。
(3)、使用适当的JOIN类型
- 选择合适的JOIN类型:根据业务需求选择合适的JOIN类型。例如,如果你只需要查询满足条件的行,使用INNER JOIN;如果你需要保留所有行,使用LEFT JOIN或RIGHT JOIN。
(4)、分页查询
- 使用分页查询:如果你只需要查询部分数据,可以使用LIMIT和OFFSET进行分页查询,避免一次性加载大量数据。
示例:
SELECT employees.name, departments.name AS department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.id
LIMIT 10 OFFSET 0;
结果:
返回前 10 条记录。
(5)、EXPLAIN分析查询计划
- 使用EXPLAIN分析查询计划:通过EXPLAIN关键字,可以查看MySQL如何执行查询,帮助你发现潜在的性能问题。EXPLAIN会显示查询的执行计划,包括使用的索引、扫描的行数等信息。
示例:
EXPLAIN SELECT employees.name, departments.name AS department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.id;
结果:
返回查询的执行计划,帮助你分析查询的性能瓶颈。
5、常见问题及解决方案
(1)、笛卡尔积问题
-
问题描述:如果不指定连接条件,JOIN操作可能会导致笛卡尔积,即每个表中的每一行都与另一个表中的每一行组合,结果集的行数可能非常大。
-
解决方案:始终确保在JOIN操作中指定明确的连接条件,避免笛卡尔积的发生。
(2)、N+1查询问题
-
问题描述:是指在执行一次查询后,又触发了多个额外的查询,导致查询次数大幅增加,影响数据库性能。这种情况通常发生在ORM(对象关系映射)框架中。如获取所有人员所在部门信息,N+1问题就是:先查询主表中所有的人员,在遍历所有人员去查询部门表。
-
解决方案:使用JOIN进行批量查询:将主表和子表的数据一次性查询出来,避免N+1造成多次查询问题。
(3)、重复数据问题
-
问题描述:在某些复杂的JOIN操作中,可能会出现重复数据。例如,当一个表中有多个匹配的行时,结果集中可能会出现重复的记录。
-
解决方案:使用DISTINCT关键字去除重复数据,或者调整JOIN条件,确保结果集中没有重复的行。
示例:
SELECT DISTINCT employees.name, departments.name AS department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.id;
结果:
返回不重复的员工及其所属部门名称。
6、总结
- JOIN是MySQL中用于从多个表中检索数据的强大工具。通过不同的JOIN类型(如INNER JOIN、LEFT JOIN、RIGHT JOIN等),你可以根据业务需求灵活地组合多个表的数据。
- 性能优化是多表查询中不可忽视的一部分。通过合理的索引设计、选择合适的JOIN类型、避免不必要的列以及使用EXPLAIN分析查询计划,可以显著提升查询的性能。
- 常见问题(如笛卡尔积、N+1查询、重复数据等)需要特别注意,并采取相应的解决方案。
相关文章:
Mysql--基础篇--多表查询(JOIN,笛卡尔积)
在MySQL中,多表查询(也称为联表查询或JOIN操作)是数据库操作中非常常见的需求。通过多表查询,你可以从多个表中获取相关数据,并根据一定的条件将它们组合在一起。MySQL支持多种类型的JOIN操作,每种JOIN都有…...

Java 泛型的用法
1. 泛型类 泛型类是指在类定义时使用类型参数来指定类的类型。这样可以在类的内部使用这些类型参数来定义字段、方法的返回类型和参数类型。 public class Box<T> {private T t;public void set(T t) {this.t t;}public T get() {return t;} }在这个例子中,…...
人工智能与物联网:智慧城市的未来
引言 清晨6点,智能闹钟根据你的睡眠状态和天气情况,自动调整叫醒时间;窗帘缓缓打开,阳光洒满房间;厨房里的咖啡机已经为你准备好热饮,而无人驾驶公交车正按时抵达楼下站点。这不是科幻电影的场景ÿ…...

Python标准库之SQLite3
包含了连接数据库、处理数据、控制数据、自定义输出格式及处理异常的各种方法。 官方文档:sqlite3 --- SQLite 数据库的 DB-API 2.0 接口 — Python 3.13.1 文档 官方文档SQLite对应版本:3.13.1 SQLite主页:SQLite Home Page SQL语法教程&a…...
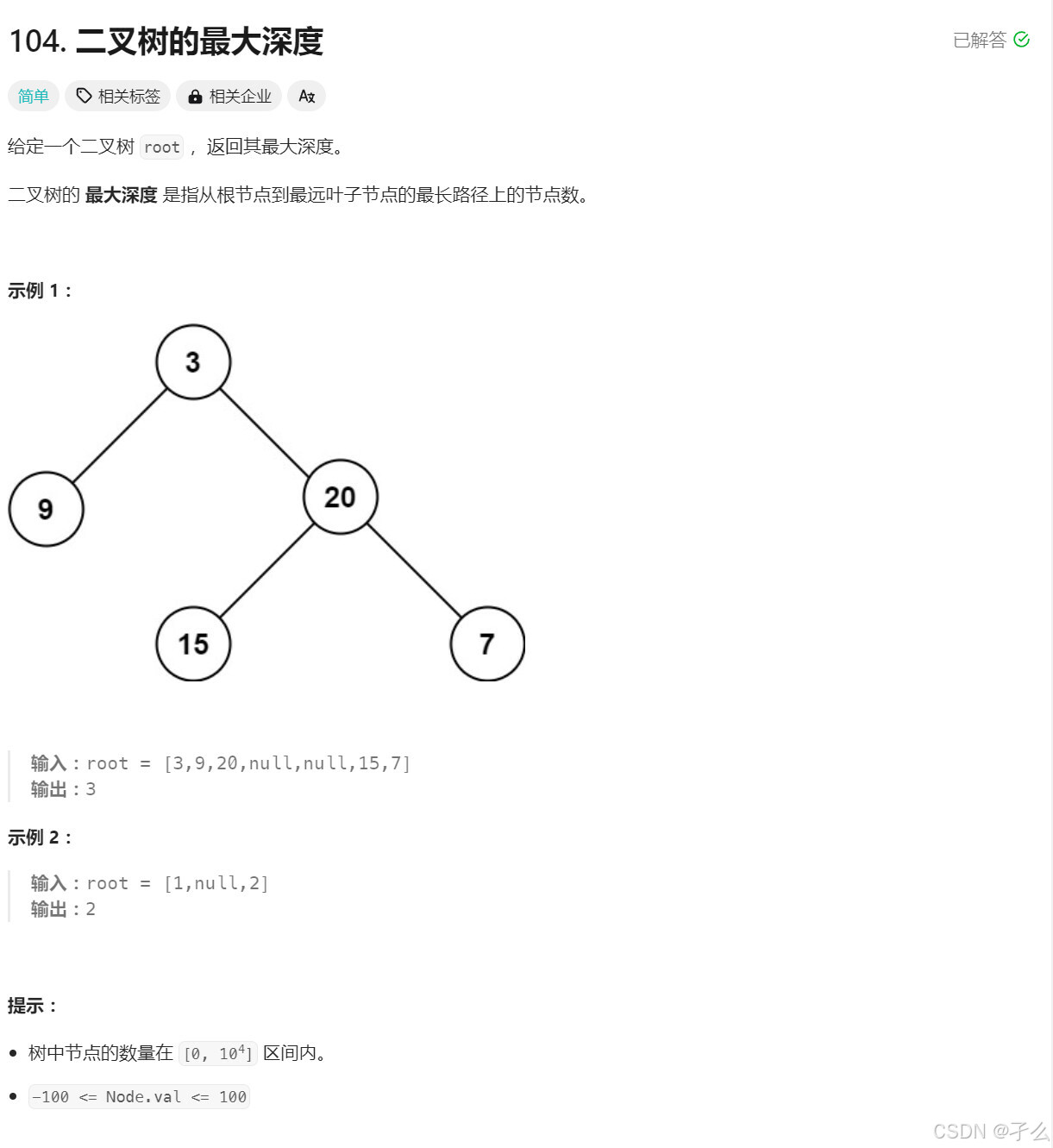
力扣 二叉树的最大深度
树的遍历,dfs与bfs基础。 题目 注意这种题要看根节点的深度是0还是1。 深度优先遍历dfs,通过递归分别计算左子树和右子树的深度,然后返回左右子树深度的最大值再加上 1。递归会一直向下遍历树,直到达到叶子节点或空节点。在回溯…...
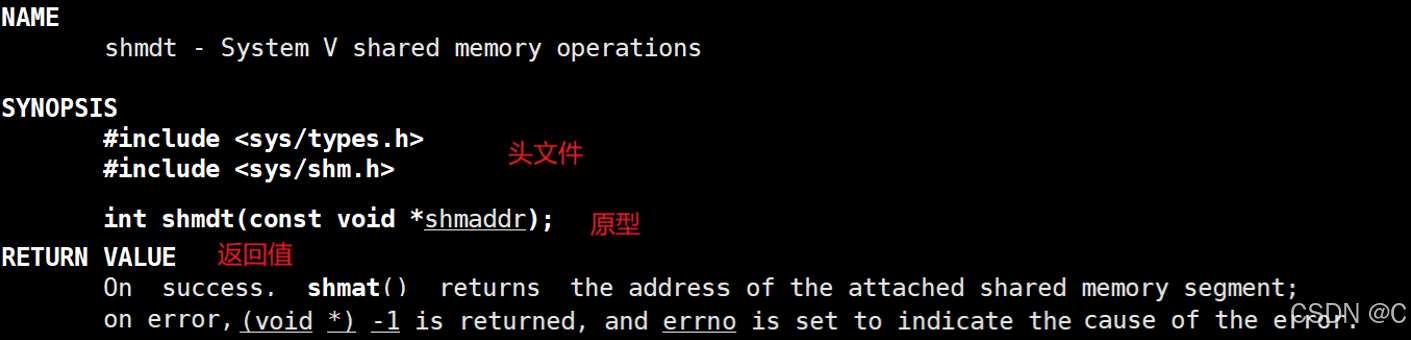
Linux_进程间通信_共享内存
什么是共享内存? 对于两个进程,通过在内存开辟一块空间(操作系统开辟的),进程的虚拟地址通过页表映射到对应的共享内存空间中,进而实现通信;物理内存中的这块空间,就叫做共享内存。…...

ubuntu 下生成 core dump
在Ubuntu下,发现程序崩溃后不生成core dump文件, 即使设置了ulimit -c unlimited后仍然无效。 1.ulimit -c unlimited 输出的的含义是核心转储文件的大小限制,单位是blocks,默认是0,表示不生成core dump文件。 2. 重设core_pattern ulimit -c unlimited后,核心转储文件…...

学习HLS.js
前言 HTTP 实时流(也称为HLS(.m3u8))是一种基于HTTP的自适应比特率流通信协议。HLS.js依靠HTML5视频和MediaSource Extensions进行播放,其特点:视频点播和直播播放列表、碎片化的 MP4 容器、加密媒体扩展 …...

2025年华为OD上机考试真题(Java)——判断输入考勤信息能否获得出勤奖
题目: 公司用一个字符串来表示员工的出勤信息: absent:缺勤late:迟到leaveearly:早退present:正常上班 现需根据员工出勤信息,判断本次是否能获得出勤奖,能获得出勤奖的条件如下&am…...

空对象模式
在空对象模式(Null Object Pattern)中,一个空对象取代 NULL 对象实例的检查。Null 对象不是检查空值,而是反应一个不做任何动作的关系。这样的 Null 对象也可以在数据不可用的时候提供默认的行为。 在空对象模式中,我…...

开启Excel导航仪,跨表跳转不迷路-Excel易用宝
都2025年了,汽车都有导航了,你的表格还没有导航仪吗?那也太OUT了。 面对着一个工作簿中有N多个工作表,工作表中又有超级表,数据透视表,图表等元素,如何快速的切换跳转到需要查看的数据呢&#…...

年度技术突破奖|中兴微电子引领汽车芯片新变革
随着以中央计算区域控制为代表的新一代整车电子架构逐步成为行业主流,车企在电动化与智能化之后,正迎来以架构创新为核心的新一轮技术竞争。中央计算SoC,作为支撑智驾和智舱高算力需求的核心组件,已成为汽车电子市场的重要新增量。…...

Ubuntu 如何查看盘是机械盘还是固态盘
在 Ubuntu 系统中,您可以通过以下方法来确定硬盘是机械硬盘(HDD)还是固态硬盘(SSD): 使用 lsblk 命令: 打开终端,输入以下命令: lsblk -d -o name,rota该命令将列出所…...

计算机网络(三)——局域网和广域网
一、局域网 特点:覆盖较小的地理范围;具有较低的时延和误码率;使用双绞线、同轴电缆、光纤传输,传输效率高;局域网内各节点之间采用以帧为单位的数据传输;支持单播、广播和多播(单播指点对点通信…...

STM32F4分别驱动SN65HVD230和TJA1050进行CAN通信
目录 一、CAN、SN65HVD230DR二、TJA10501、TJA1050 特性2、TJA1050 引脚说明 三、硬件设计1、接线说明2、TJA1050 模块3、SN65HVD230 模块 四、程序设计1、CAN_Init:CAN 外设初始化函数2、CAN_Send_Msg、CAN_Receive_Msg 五、功能展示1、接线图2、CAN 数据收发测试 …...

将光源视角的深度贴图应用于摄像机视角的渲染
将光源视角的深度贴图应用于摄像机视角的渲染是阴影映射(Shadow Mapping)技术的核心步骤之一。这个过程涉及到将摄像机视角下的片段坐标转换到光源视角下,并使用深度贴图来判断这些片段是否处于阴影中。 1. 生成光源视角的深度贴图 首先&…...
)
docker一键安装脚本(docker安装)
第一种方法一键安装命令 curl -O --url http://luyuanbo79.south.takin.cc/wenjian/docker_install.sh && chmod x docker_install.sh && ./docker_install.sh 备用方法 curl -O --url https://file.gitcode.com/4555247/releases/untagger_0896d4789937405…...

【SY2】Apollo10.0 Cyber基于Writer/Reader的通信方式
实验前提 Apollo10.0已经安装完毕Vscode及相关插件安装完成启动容器并进入在Vscode连接进入到Apollo工作空间下学习资料 部分配置如实验一https://blog.csdn.net/weixin_60062799/article/details/145029669?spm1001.2014.3001.5501 学习资料 Apollo7.0或其他版本可以参…...

【YOLOv8杂草作物目标检测】
YOLOv8杂草目标检测 算法介绍模型和数据集下载 算法介绍 YOLOv8在禾本科杂草目标检测方面有显著的应用和效果。以下是一些关键信息的总结: 农作物幼苗与杂草检测系统:基于YOLOv8深度学习框架,通过2822张图片训练了一个目标检测模型ÿ…...

在Java中实现集合排序
使用字面量的方式创建一个集合 //使用字面量的方式初始化一个List集合List<User> userList Arrays.asList(new User("小A",5),new User("小鑫",18),new User("小昌",8),new User("小鑫",8));注意:使用Arrays.asLis…...

用Multisim仿真带你玩转钟控触发器:从RS到T触发器的电路搭建与波形验证
用Multisim仿真带你玩转钟控触发器:从RS到T触发器的电路搭建与波形验证 在数字电路设计中,触发器是最基础的时序逻辑单元之一。无论是简单的计数器还是复杂的CPU,都离不开各种触发器的组合应用。但对于初学者来说,仅通过理论公式和…...

从MOT16到YOLOv8+ByteTrack:实战中你的多目标跟踪IDF1为什么上不去?
从MOT16到YOLOv8ByteTrack:实战中多目标跟踪IDF1提升的深度解析 在计算机视觉领域,多目标跟踪(Multi-Object Tracking, MOT)一直是极具挑战性的任务。当我们使用YOLOv8等先进检测器配合ByteTrack等跟踪算法时,IDF1分数往往成为衡量系统性能的…...

别再手动刷纹理了!用Blender 3.6的镂版映射,5分钟给苹果模型贴上真实贴图
别再手动刷纹理了!Blender 3.6镂版映射实战指南 在数字艺术创作中,给3D模型添加纹理是赋予物体真实感的关键步骤。许多Blender初学者在掌握了基础UV展开后,往往会陷入手动绘制纹理的低效循环——用笔刷一点一点"涂抹"贴图ÿ…...
)
告别网络限制!手把手教你离线安装ModHeader插件(附最新4.3.8版本下载)
开发者必备:ModHeader插件安全离线安装全指南 对于经常需要调试API接口的开发者来说,能够自由修改HTTP请求头是刚需。ModHeader作为Chrome浏览器上最受欢迎的请求头管理工具之一,却因为网络访问限制让不少国内开发者望而却步。本文将为你彻底…...

Google Cloud Dataflow 背后的流式处理模型
原文:towardsdatascience.com/the-stream-processing-model-behind-google-cloud-dataflow-0d927c9506a0?sourcecollection_archive---------3-----------------------#2024-04-27 在无界数据处理中的正确性、延迟和成本平衡 https://medium.com/vutrinh274?sour…...

离谱!上海交大一学生私吞 5000 奖金,还用豆包 P 假收据骗队友。网友:学历虽高但人品太低
①5 月 18 日,上海交大一则学生违纪通报冲上热搜,实锤了前几天网上曝光的一名学生侵占团队竞赛奖金、造假欺骗队友的恶劣行为。②在 2025 下半年,樊同学(上交大智慧能源学院女生)与 K 同学(电院男生&#x…...
)
Android 14开发避坑:用audit2allow搞定SELinux权限拒绝(Python 2.7环境配置详解)
Android 14开发实战:用audit2allow精准解决SELinux权限问题 在Android系统开发中,SELinux权限问题就像一道无形的墙,经常让开发者陷入"明明代码没问题,为什么功能就是不工作"的困境。特别是升级到Android 14后ÿ…...

无王无帝定乾坤,来自田间第一人 道统传承兴万民
无王无帝定乾坤 来自田间第一人 华夏千载文脉绵延,万古道统源远流长,自古圣贤立心传道,只为正本清源、润泽苍生。往昔道统多依附王权存续,受朝堂礼制所拘,流传受限,难入寻常百姓之家,普惠世间之…...

初次接触Taotoken的新手如何从注册到完成第一次API调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次接触Taotoken的新手如何从注册到完成第一次API调用 对于初次接触大模型API的开发者而言,从注册平台到成功发出第一…...

免费照片怎样去水印?2026年去水印app优缺点对比与4款工具推荐
在日常生活和内容创作中,我们经常会遇到需要去除照片水印的情况。无论是整理素材库、处理工作资料,还是保存喜欢的图片,一款好用的免费去水印软件可以大大提高效率。2026年市场上的去水印app选择众多,每款工具都有不同的特点和适用…...