Mysql--运维篇--日志管理(连接层,SQL层,存储引擎层,文件存储层)
MySQL提供了多种日志类型,用于记录不同的活动和事件。这些日志对于数据库的管理、故障排除、性能优化和安全审计非常重要。
一、错误日志 (Error Log)
作用:
记录MySQL服务器启动、运行和停止期间遇到的问题和错误信息。
查看:
- 默认情况下,错误日志的位置可以通过show variables like ‘log_error’;命令来查看。
- 或者直接在配置文件(通常是my.cnf或my.ini)中查找log_error变量的值。
示例:
show variables like 'log_error';
运行结果:

找到路径,打开文件:

二、查询日志 (General Query Log)
作用:
记录所有发送到服务器的SQL语句,包括查询、更新等操作。它可以帮助你了解用户执行了哪些操作,但开启后会影响性能,因此通常只在调试时使用。
查看:
- 可以通过SHOW VARIABLES LIKE ‘general_log%’;来查看是否启用了查询日志以及它的位置。
- 使用SET GLOBAL general_log = ‘ON’;启用查询日志,SET GLOBAL general_log = ‘OFF’;禁用。
- 日志内容可以实时查看,例如tail -f /path/to/mysql.log。
示例:
SHOW VARIABLES LIKE 'general_log%';
运行结果:

三、慢查询日志 (Slow Query Log)
作用:
记录那些执行时间超过指定阈值的SQL查询。这对于识别和优化性能瓶颈非常有用。
查看:
- 使用SHOW VARIABLES LIKE ‘slow_query_log%’;来检查慢查询日志的状态和位置。
- SET GLOBAL slow_query_log = ‘ON’;启用慢查询日志,SET GLOBAL slow_query_log = ‘OFF’;禁用。
- 你可以设置long_query_time变量来定义“慢”的标准,默认是10秒,但是可以通过SET GLOBAL long_query_time = N;调整,其中N是你想要的时间秒数。
- 还可以利用mysqldumpslow工具或者第三方工具如pt-query-digest来分析慢查询日志。
示例:
SHOW VARIABLES LIKE 'slow_query_log%';
运行结果:

四、二进制日志 (Binary Log, Binlog)
作用:
记录所有对数据库结构或数据进行更改的操作(DDL和DML),比如INSERT、UPDATE、DELETE等。主要用于复制(Replication)、恢复(Recovery)和审计(Audit)。
查看:
- 使用SHOW BINARY LOGS;列出所有的二进制日志文件。
- 使用SHOW MASTER STATUS;查看当前正在使用的二进制日志文件。
- 使用mysqlbinlog工具读取和解析二进制日志的内容,例如mysqlbinlog /path/to/binlog-file。
示例:
SHOW BINARY LOGS;
运行结果:

五、中继日志 (Relay Log)
作用:
在主从复制环境中,从库会将主库的二进制日志中的事件复制到自己的中继日志中,然后再应用这些事件。这使得从库能够与主库保持同步。
查看:
- 使用SHOW SLAVE STATUS;可以查看有关从库状态的信息,包括中继日志的文件名和位置。
- 类似于二进制日志,可以使用mysqlbinlog工具来查看中继日志的内容。
六、重做日志 (InnoDB Redo Log)
1、概述
重做日志是InnoDB用于确保事务持久性的关键组件。它记录了所有对数据页的物理修改操作,确保在系统崩溃后可以重新应用这些修改,恢复数据的一致性。
特点:
- 位置:重做日志文件通常位于ib_logfile0和ib_logfile1中。
- Redo日志不是文本格式的日志,不能直接查看其内容。
- 大小:每个重做日志文件的大小由innodb_log_file_size参数控制,默认值为48MB。
- 数量:可以通过innodb_log_files_in_group参数指定重做日志文件的数量,默认为2。
2、工作原理
(1)、记录修改:每当对数据页进行修改时,InnoDB会先将修改操作记录到重做日志中。重做日志记录的是物理修改,而不是逻辑操作。
(2)、循环写入:重做日志采用循环写入的方式。当一个日志文件写满后,InnoDB会切换到下一个日志文件继续写入。所有日志文件写满后,InnoDB会回到第一个日志文件,覆盖旧的日志记录。
(3)、检查点(Checkpoint):为了防止重做日志被无限期地循环覆盖,InnoDB使用检查点机制。检查点是指重做日志的某个位置,所有在此之前修改的数据页都必须已经刷新到磁盘。通过这种方式,InnoDB可以确保在系统崩溃后能够从检查点开始恢复数据。
(4)、崩溃恢复:在系统崩溃后,InnoDB会在启动时读取重做日志,重新应用未完成的事务,恢复数据的一致性。这个过程称为前滚恢复(Roll Forward Recovery)。
3、配置参数
innodb_log_file_size:
- 功能:设置每个重做日志文件的大小。
- 推荐值:建议根据工作负载调整。对于高并发写入场景,可以适当增大该值,以减少日志切换的频率。默认值为48MB。
innodb_log_files_in_group:
- 功能:设置重做日志文件的数量。
- 推荐值:默认为2,通常不需要调整。如果需要更大的日志空间,建议增加单个日志文件的大小,而不是增加日志文件的数量。
innodb_flush_log_at_trx_commit:
- 功能:控制事务提交时是否立即刷新重做日志到磁盘。
- 取值:
- 0:不刷新重做日志,性能最好,但安全性最低。如果系统崩溃,可能会丢失最近的事务。
- 1(默认):每次事务提交时都刷新重做日志到磁盘,确保数据的安全性,但性能稍差。
- 2:每次事务提交时将重做日志写入操作系统缓存,但不立即刷新到磁盘。适合追求性能的场景,但在系统崩溃时可能会丢失最近的事务。
innodb_log_buffer_size:
- 功能:设置重做日志缓冲区的大小。重做日志缓冲区用于暂存尚未写入磁盘的重做日志记录。
- 推荐值:默认为8MB,可以根据工作负载适当调整。较大的缓冲区可以减少磁盘I/O次数,提升写性能。
4、优化建议
- 增大innodb_log_file_size:对于高并发写入场景,建议增大重做日志文件的大小,以减少日志切换的频率。较大的日志文件可以容纳更多的事务,减少磁盘I/O次数。
- 调整innodb_flush_log_at_trx_commit:根据应用场景选择合适的值。如果你的应用对数据安全要求较高,建议保持默认值1;如果你的应用对性能要求较高,且可以容忍少量数据丢失,可以选择2或0。
- 使用O_DIRECT刷新方法:通过innodb_flush_method = O_DIRECT配置,绕过操作系统的缓存,直接将重做日志写入磁盘,减少双重缓存问题,提升性能。
七、回滚日志 (InnoDB Undo Log)
1、概述
回滚日志是InnoDB用于实现事务的回滚和多版本并发控制(MVCC)的关键组件。它记录了事务的旧版本数据,确保未提交的事务不会影响数据库的状态,并支持多个事务同时读取不同的数据版本。
作用:Undo日志保存了旧版本的数据,以便在需要时回滚事务或提供多版本并发控制(MVCC)。这对于保证事务的ACID特性至关重要。
特点:
- 位置:回滚段存储在系统UNDO表空间中,通常是ibdata1文件的一部分。
- 和Redo日志一样,Undo日志也不是以文本形式存储的,所以不能直接查看。
- 类型:
- 插入回滚段:用于记录插入操作的旧版本数据。
- 更新回滚段:用于记录更新操作的旧版本数据。
2、工作原理
(1)、记录旧版本数据:每当对数据进行插入、更新或删除操作时,InnoDB会将旧版本数据记录到回滚日志中。这些旧版本数据用于实现事务的回滚和多版本并发控制(MVCC)。
(2)、事务回滚:如果事务未提交或发生错误,InnoDB可以根据回滚段中的旧版本数据,将数据恢复到事务开始时的状态。
(3)、多版本并发控制(MVCC):InnoDB使用回滚段来支持多版本并发控制。当多个事务同时读取同一行数据时,InnoDB会根据事务的隔离级别返回合适的数据版本。例如,在读已提交(Read Committed)隔离级别下,事务只能看到已经提交的数据;而在可重复读(Repeatable Read)隔离级别下,事务在整个生命周期内都能看到相同的数据版本。
(4)、清理旧版本数据:当事务提交后,回滚段中的旧版本数据不再需要,InnoDB会定期清理这些数据,释放空间。
3、配置参数
innodb_undo_tablespaces:
- 功能:设置独立的回滚表空间的数量。启用该参数后,回滚段将存储在独立的.ibd文件中,而不是系统表空间中。(表空间中包含三种类型:数据,索引,回滚段)
- 推荐值:默认为0,表示回滚段存储在系统表空间中。如果你有大量长时间运行的事务,建议启用独立的回滚表空间,以减少系统表空间的碎片化问题。
innodb_undo_log_truncate:
- 功能:控制是否定期截断回滚段。启用该参数后,InnoDB会定期清理不再需要的回滚段,释放空间。
- 推荐值:默认为OFF,建议在生产环境中启用该参数,以减少回滚段的占用空间。
innodb_max_undo_log_size:
- 功能:设置回滚段的最大大小。当回滚段超过该大小时,InnoDB会自动截断回滚段,释放空间。
- 推荐值:默认为1GB,可以根据工作负载适当调整。
4、优化建议
- 启用独立回滚表空间:如果你有大量长时间运行的事务,建议启用独立的回滚表空间,以减少系统表空间的碎片化问题。独立的回滚表空间可以更好地管理和优化回滚段的存储。
- 定期截断回滚段:启用innodb_undo_log_truncate参数,定期清理不再需要的回滚段,释放空间。这有助于减少回滚段的占用空间,提升性能。
- 调整回滚段大小:根据工作负载调整innodb_max_undo_log_size参数,确保回滚段不会占用过多的空间。对于大事务或长事务较多的场景,可以适当增大该值。
八、审计日志 (Audit Log)
作用:
记录用户的登录尝试、权限变更和其他安全相关的活动。并不是所有版本的MySQL都自带审计日志功能,某些企业版可能包含这个特性,或者可以通过插件实现。
查看:
- 如果安装了审计插件,可以通过特定的命令或API来访问审计日志。
- 具体的查看方法取决于所使用的插件或解决方案。
乘风破浪会有时,直挂云帆济沧海!!!
相关文章:
Mysql--运维篇--日志管理(连接层,SQL层,存储引擎层,文件存储层)
MySQL提供了多种日志类型,用于记录不同的活动和事件。这些日志对于数据库的管理、故障排除、性能优化和安全审计非常重要。 一、错误日志 (Error Log) 作用: 记录MySQL服务器启动、运行和停止期间遇到的问题和错误信息。 查看: 默认情况下…...

poi处理多选框进行勾选操作下载word以及多word文件压缩
一、场景 将数据导出word后且实现动态勾选复选框操作 eg: word模板 导出后效果(根据数据动态勾选复选框) 二、解决方案及涉及技术 ① 使用poi提供的库进行处理(poi官方文档) ② 涉及依赖 <!-- excel工具 --><depen…...

QT 键值对集合QMap
在QT中,可以使用QMap作为键值对的集合。QMap是Qt的一个模板类,它存储了键值对,并且可以通过键来快速查找值。 导入 #include <QMap> 以下是一些使用QMap的方法: 1.创建并初始化一个 QMap<int, QString> UserDepa…...

NetMQ里Push-Pull模式,消息隔一收一问题小记
问题: 本机环境下,在push端向pull端发送消息的过程中,发现同一个进程里的pusher和puller代码,可以准确地完成收发; 然而,将代码放在两个进程里,将pusher发送的消息从1计数,puller端竟…...

见微知著:Tripo 开创 3D 生成新时代
关于 VAST VAST 成⽴于 2023 年 3 ⽉,是⼀家致⼒于通⽤ 3D 大模型研发的 AI 公司,公司⽬标是通过打造⼤众级别的 3D 内容创作⼯具,建⽴ 3D 的 UGC 内容平台,让基于 3D 的空间成为⽤户体验、内容表达、提升新质⽣产⼒的关键要素。 2024 年初,VAST 推出数⼗亿参数级别的 3…...

消息队列与中间件:Java的秘密传输带
消息队列与中间件技术是分布式系统中的重要组件,它们主要解决应用耦合、异步消息处理、流量削峰等问题,并实现高性能、高可用、可伸缩和最终一致性的架构。 2.1 消息队列的基本概念 消息队列是一种应用程序间传递消息的技术,它允许应用程序发…...

Bytebase 3.1.0 - 通过 Google / GitHub SSO 功能开放给专业版
🚀 新功能 支持在 PostgreSQL DML/DDL 工单中选择执行角色。 在项目设置中增加 PostgreSQL 数据库租户模式配置选项。 在数据库页面和 SQL 编辑器为 ORACLE 数据库展示 package 元数据。 支持为环境配置颜色,方便区分。 新增管理员可关闭数据导出…...

EdgeOne安全专项实践:上传文件漏洞攻击详解与防范措施
靶场搭建 当我们考虑到攻击他人服务器属于违法行为时,我们需要思考如何更好地保护我们自己的服务器。为了测试和学习,我们可以搭建一个专门的靶场来模拟文件上传漏洞攻击。以下是我搭建靶场的环境和一些参考资料,供大家学习和参考࿰…...

k8s部署rocketmq踩坑笔记
给团队部署一个rocketmq4.8.0. k8s上部署的broker,注册到nameserver上是自己的pod ip,导致本机连接到的broker的pod ip,这个ip k8s集群外的机器是无法联通的。 nameserver上注册的是这个pod ipv4 尝试将broker的配置brokerIP1修改为注册到na…...

Docker 通过创建Dockerfile 部署Jar包
1、创建Dockerfile 首先确保centos 安装docker,参考docker安装-CSDN博客 自己找个目录来存放Dockerfile mkdir Dockerfile 2、vim Dockerfile # 使用 OpenJDK 17 基础镜像 FROM jre17:v1.0# 设置工作目录 WORKDIR /app# 暴露端口 EXPOSE 8093# 设置容器内日志目录…...

shell脚本练习
题目 1、编写一个shell 脚本,检测 /tmp/size.log 文件。如果存在,显示它的内容;不存在则创建一个文件,将创建时间写入。 2、编写一个shell 脚本,实现批量添加 20个用户,用户名为user1-20,密码为user 后面跟…...

【计算机网络】lab4 Ipv4(IPV4的研究)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀计算机网络_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前言 2.…...

Python Json格式数据处理
示例:查看和编辑 JSON 文件的 Python 程序 import json from pprint import pprintdef load_json(file_path):"""加载并解析 JSON 文件。:param file_path: JSON 文件路径:return: 解析后的 JSON 对象(字典或列表)"&quo…...

【声音场景分类--论文阅读】
1.基于小波时频图特征在声音场景分类 基于小波时频图特征在声音场景分类任务中的表现 2.增强增强高效音频分类网络 https://arxiv.org/pdf/2204.11479v5 https://github.com/Alibaba-MIIL/AudioClassfication 音频分类网络如图4所示。在此阶段,主要重点是建立一…...
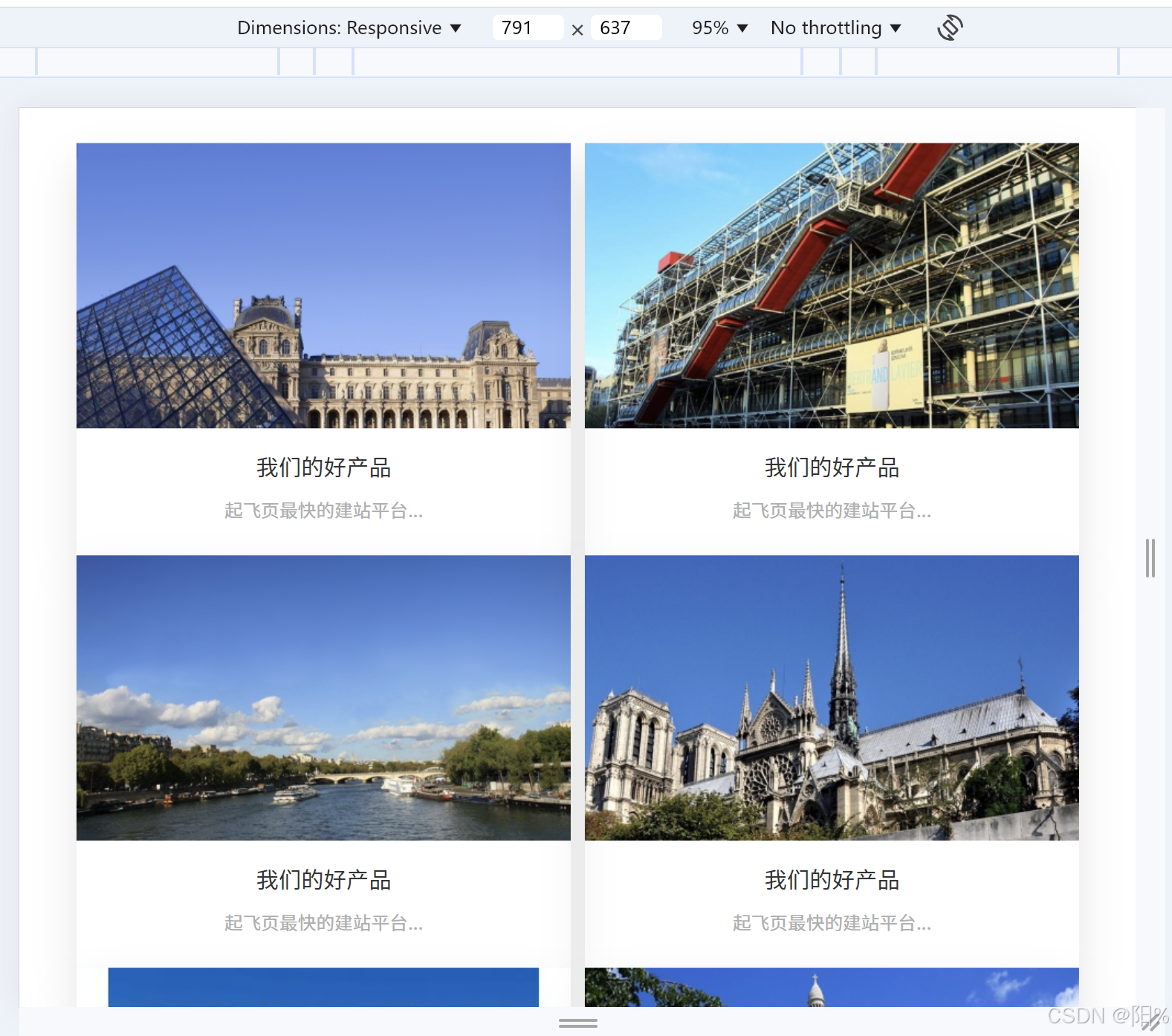
Web前端界面开发
前沿:介绍自适应和响应式布局 自适应布局:-----针对页面1个像素的变换而变化 就是我们上一个练习的效果 我们的页面效果,随着我们的屏幕大小而发生适配的效果(类似等比例) 如:rem适配 和 vw/vh适配 …...

模式识别与机器学习
文章目录 考试题型零、简介1.自学内容(1)机器学习(2)机器学习和统计学中常见的流程(3)导数 vs 梯度(4)KL散度(5)凸优化问题 2.基本概念3.典型的机器学习系统4.前沿研究方向举例 一、逻辑回归1.线性回归2.逻辑回归3.随堂练习 二、贝叶斯学习基础1.贝叶斯公式2.贝叶斯决策3.分类器…...

eNSP之家----ACL实验入门实例详解(Access Control List访问控制列表)(重要重要重要的事说三遍)
ACL实验(Access Control List访问控制列表)是一种基于包过滤的访问控制技术,它可以根据设定的条件对接口上的数据包进行过滤,允许其通过或丢弃。访问控制列表被广泛地应用于路由器和三层交换机。 准备工作 在eNSP里面部署设备&a…...

STM32 I2C硬件配置库函数
单片机学习! 目录 前言 一、I2C_DeInit函数 二、I2C_Init函数 三、I2C_StructInit函数 四、I2C_Cmd函数 五、I2C_GenerateSTART函数 六、I2C_GenerateSTOP函数 七、I2C_AcknowledgeConfig函数 八、I2C_SendData函数 九、I2C_ReceiveData函数 十、I2C_Sen…...

特制一个自己的UI库,只用CSS、图标、emoji图 第二版
图: 代码: index.html <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>M…...

Hologres 介绍
Hologres 是 阿里云 提供的一款 实时数据分析平台,它结合了数据仓库(Data Warehouse)和流式计算(Stream Processing)的优势,专为大规模数据分析和实时数据处理而设计。Hologres 基于 PostgreSQL 构建&#…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

机器学习在犬类癌症筛查中的性能极限与挑战:基于血液数据的多癌种分析
1. 项目概述:当机器学习遇见犬类癌症筛查作为一名长期关注数据科学在生命科学领域应用的从业者,我常常被问及一个充满希望的问题:我们能否像分析人类健康数据一样,利用宠物的常规体检数据,通过机器学习提前发现癌症的蛛…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...

如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南
如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/GASShooter GASShooter是Un…...

使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点 在团队协作或管理多个AI应用项目时,一个常见的痛点是每个…...