Python3遍历文件夹提取关键字及其附近字符
要求:
1,遍历文件夹下所有的.xml文件
2,从.xml文件中提取关键字以及左右十个字符
3,输出到excel
一:遍历文件夹找到所有xml文件及其路径
for root, dirs, files in os.walk(self.inputFilePath):for file in files:targetFilePath = os.path.join(root, file)if not targetFilePath.endswith(".xml"):continuexmlFileData = open(targetFilePath,'r',encoding='utf-8').read()os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情
def walk(top, topdown=True, onerror=None, followlinks=False):参数解释:
- top – 是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)。
- topdown的默认值是“True”,表示首先返回根目录树下的文件,然后遍历目录树下的子目录。值设为False时,则表示先遍历目录树下的子目录,返回子目录下的文件,最后返回根目录下的文件。
- topdown设值不同,os.walk()返回的列表元素顺序不同(但不是相反),所以遍历后的结果也不同
- onerror – 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
- followlinks – 可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。
我们只传入一个目录参数,它会遍历当前目录,及其子目录。
返回的是一个三元组(root,dirs,files)
- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
二:对xml文件提取关键字及其左右的十个字符
xmlFileData = open(targetFilePath,'r',encoding='utf-8').read()
for m in re.finditer(self.keyWords, xmlFileData, re.I):#re.I标志是大小写不敏感extractKeywords = xmlFileData[m.start()-OFFSET:m.end()+OFFSET]self.keywordInfoList.append((targetFilePath,extractKeywords))用到了re模块的finditer方法,用过re模块的相信都用过findall()方法,该方法能一次性找出所有的正则匹配结果,但是也有局限性,其不能提供所在的位置,并且是一起返回的,如果有数万个一起返回来,就不太好处理了,因此要使用finditer()函数来实现每次只返回一个,并且返回所在的位置。
re.finditer(pattern, string, flags=0)参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |

针对re.finditer返回的迭代对象,每一个迭代子对象都有start和end方法,start定位到关键字开始的位置,end定位到关键字结尾的位置,我们再定义一个偏移值(建议用宏,可以统一修改)来提取关键字及其左右偏移的字符
三:写入excel
def writeToExcel(self):workBook = openpyxl.Workbook()sheetPos = 0for ele in self.keywordInfoList:oneLine = list()rootPathSplit = ele[0].split('\\')firstDirIndex = rootPathSplit.index(self.firstDirName)#获取当前目录的索引newSheet = rootPathSplit[firstDirIndex+1]if newSheet not in workBook.sheetnames:workSheet = workBook.create_sheet(newSheet, sheetPos)sheetPos += 1oneLine.extend(rootPathSplit[firstDirIndex+1:])oneLine.append(ele[1])workSheet.append(oneLine)print(oneLine)workBook.save("xmlExtractKeyword.xlsx")用到了openpyxl模块,下面给出常用的方法
创建:
from openpyxl import Workbook
# 实例化
wb = Workbook()
# 激活 worksheet
ws = wb.active打开已有:
from openpyxl import load_workbookwb2 = load_workbook('文件名称.xlsx')储存数据:
# 方式一:数据可以直接分配到单元格中(可以输入公式)
ws['A1'] = 42
# 方式二:可以附加行,从第一列开始附加(从最下方空白处,最左开始)(可以输入多行)
ws.append([1, 2, 3])
# 方式三:Python 类型会被自动转换
ws['A3'] = datetime.datetime.now().strftime("%Y-%m-%d")创建表(sheet):
# 方式一:插入到最后(default)
>>> ws1 = wb.create_sheet("Mysheet")
# 方式二:插入到最开始的位置
>>> ws2 = wb.create_sheet("Mysheet", 0)选择表(sheet):
# sheet 名称可以作为 key 进行索引
>>> ws3 = wb["New Title"]
>>> ws4 = wb.get_sheet_by_name("New Title")
>>> ws is ws3 is ws4
True查看表名(sheet):
# 显示所有表名
>>> print(wb.sheetnames)
['Sheet2', 'New Title', 'Sheet1']
# 遍历所有表
>>> for sheet in wb:
... print(sheet.title)更多方法请见:python-- openpyxl详解_像风一样的男人@的博客-CSDN博客
相关文章:
Python3遍历文件夹提取关键字及其附近字符
要求: 1,遍历文件夹下所有的.xml文件 2,从.xml文件中提取关键字以及左右十个字符 3,输出到excel 一:遍历文件夹找到所有xml文件及其路径 for root, dirs, files in os.walk(self.inputFilePath):for file in files:…...

「1」线性代数(期末复习)
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 第一章 行列式 行列式是一个数,是一个结果三阶行列式的计算:主对角线的乘…...

C++7:STL-模拟实现vector
目录 vector的成员变量 构造函数 reserve size() capacity() push_back 一些小BUG 赋值操作符重载 析构函数 【】操作符重载 resize pop_back Insert 迭代器失效 erase 二维数组问题 总结一下 vector,翻译软件会告诉你它的意思是向量,但其…...

笑死,面试官又问我SpringBoot自动配置原理
面试官:好久没见,甚是想念。今天来聊聊SpringBoot的自动配置吧? 候选者:嗯,SpringBoot的自动配置我觉得是SpringBoot很重要的“特性”了。众所周知,SpringBoot有着“约定大于配置”的理念,这一…...
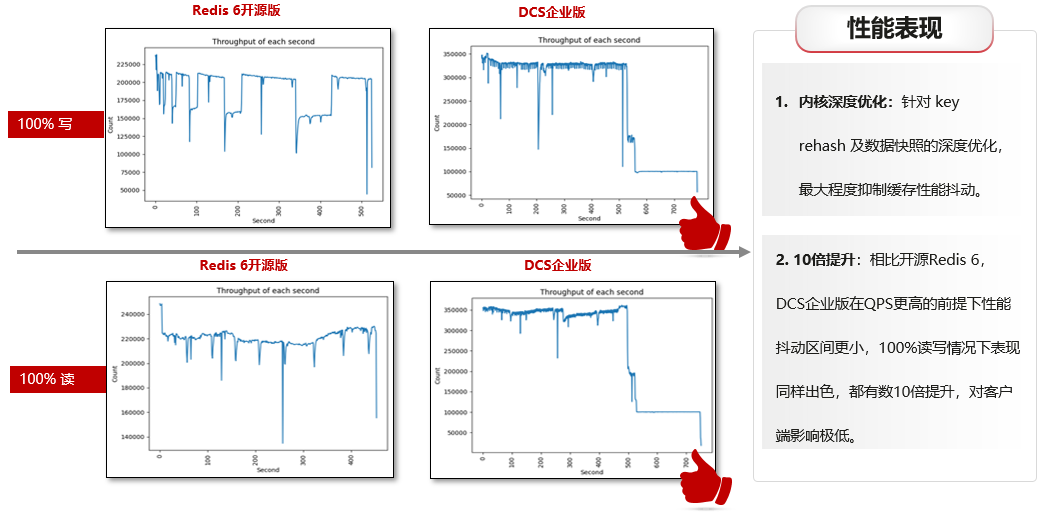
分布式缓存服务DCS-企业版性能更强,稳定性更高
背景介绍 近年来,随着各行业业务需求急速增加,数据量和并发访问量呈指数级增长,原来只能依附于关系型数据库的传统“缓存”逐渐难以支撑上层业务,开源Redis也面临着如“容量有限”、 “可靠性有限”、 “数据重复拷贝,…...

HTTP基本原理
目录URL简单定义格式HTTP和HTTPSHTTP的请求过程。请求响应响应体HTTP2.0总结URL 简单定义 通过一个链接,使我们可以找到网络上的某个资源,这个链接就是URL。 格式 URL并不是随便写的,而是有固定的格式。基本的组成格式如下。 schme://[us…...
最新版本详细保姆级安装教程)
【云原生】Kubernetes(k8s)最新版本详细保姆级安装教程
前言 Kubernetes简称k8s,是一个开源的,用于管理云平台中多个主机上的容器化的应用,k8s目标是让部署容器化的应用简单并且高效,k8s提供了应用部署,规划,更新,维护的一种机制。 本文是总结了在安…...
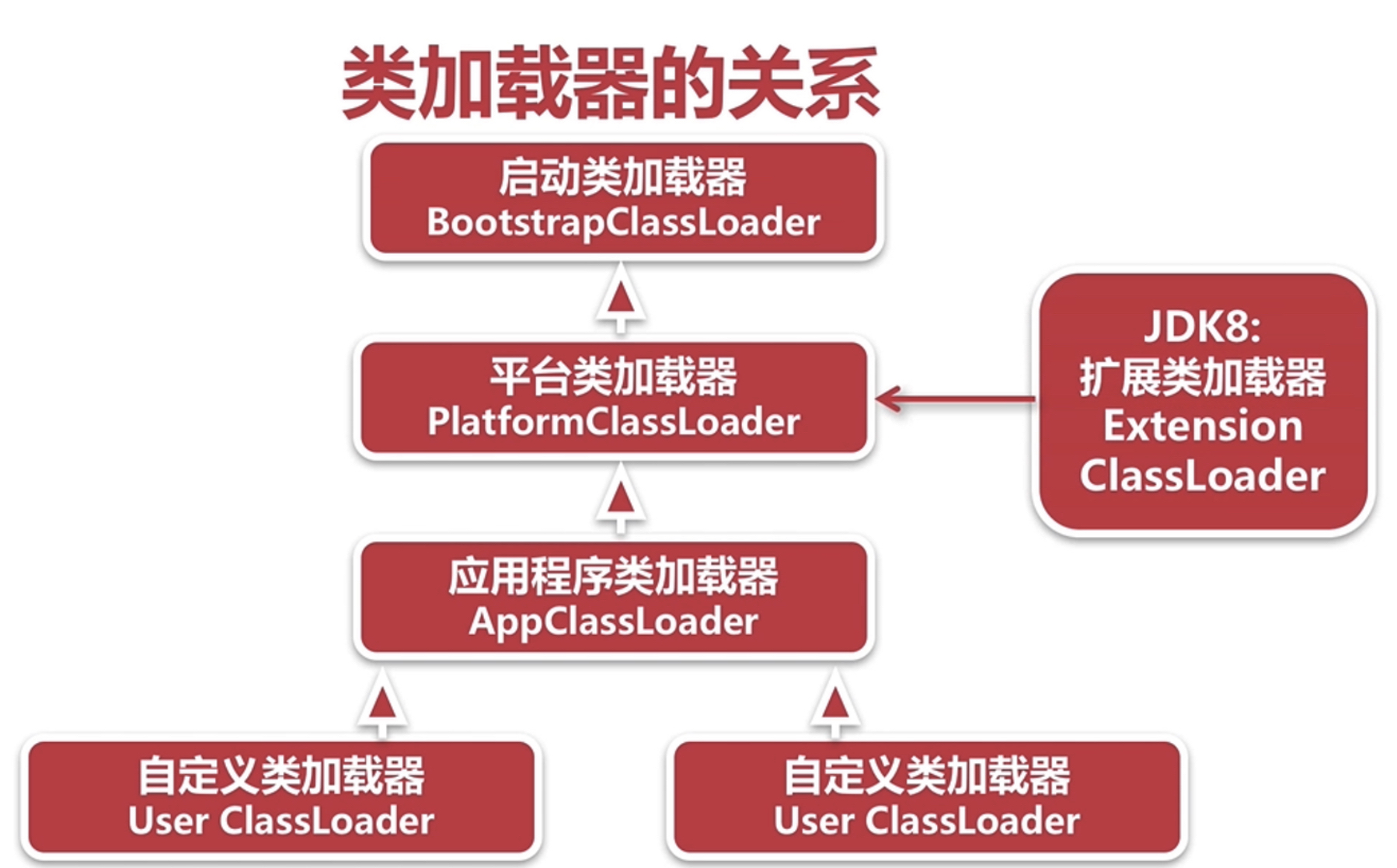
JVM - 类加载,连接和初始化
目录 类加载和类加载器 概述 类加载要完成的功能 加载类的方式 类加载器 类加载器的关系 类加载器说明 双亲委派模型 工作过程如下: 双亲委派模型说明: 破坏双亲委派模型: 类连接和初始化 类连接主要验证的内容 类连接中的解析…...
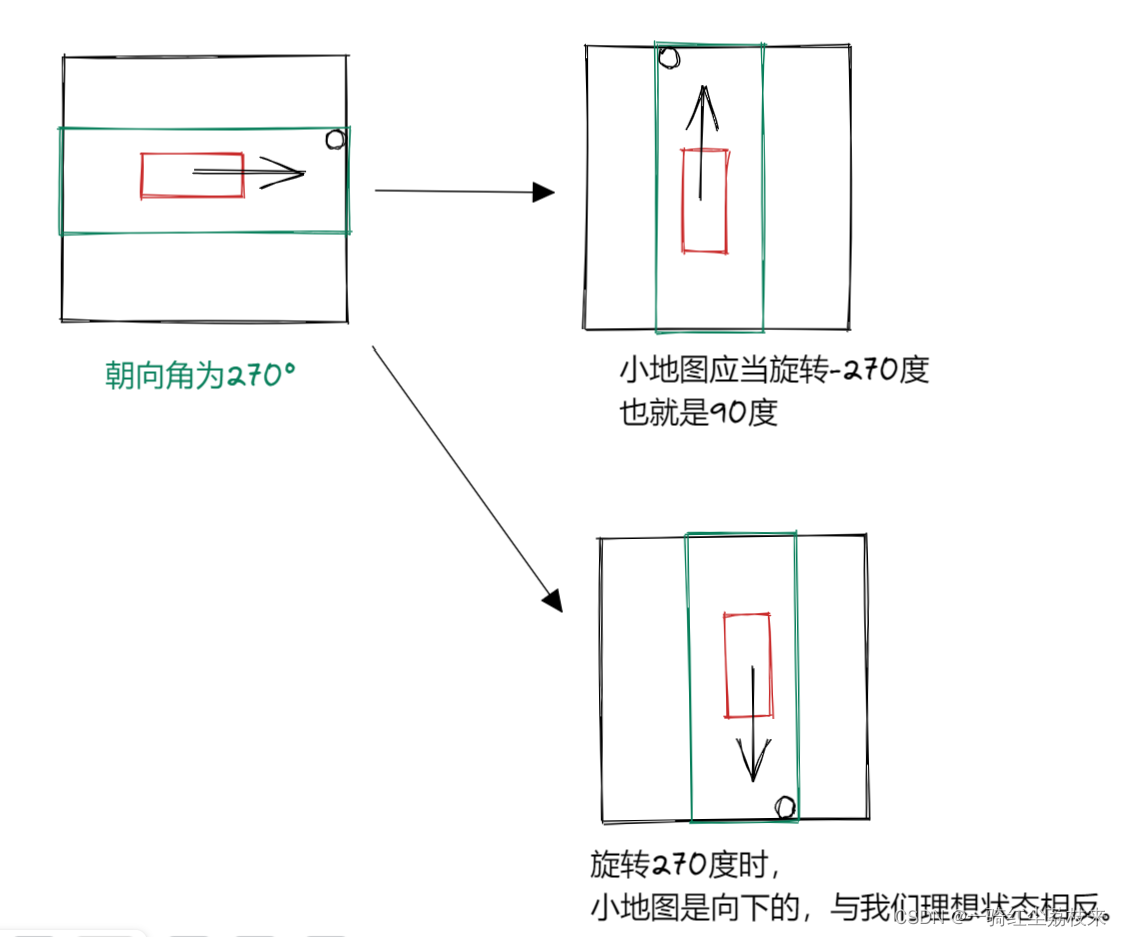
[carla]关于odometry坐标中的角度坐标系 以及 到地图的映射问题
1.获取车辆的Odometry原始信息 在carla中,通过订阅/carla/ego_vecle/odometry 可以查看车辆的全局位置信息,例如: > header: seq: 118872stamp: secs: 5946nsecs: 5720187frame_id: "map" child_frame_id: "ego_vehicle" pos…...

Python 正则表达式
正则表达式主要用来查找和匹配字符串的。 一、正在表达式基础 字符 描述 示例 TIY\ 示意特殊序列(也可用于转义特殊字符)如:空白字符 "\s" . 任何字符(换行符除外) "he..o" ^ 起始于 "^h…...

spark03-读取文件数据分区数量个数原理
代码val conf: SparkConf new SparkConf().setMaster("local").setAppName("wordcount")val sc: SparkContext new SparkContext(conf)val rdd: RDD[String] sc.textFile("datas/1.txt",2)rdd.saveAsTextFile("output")数据格式 &a…...
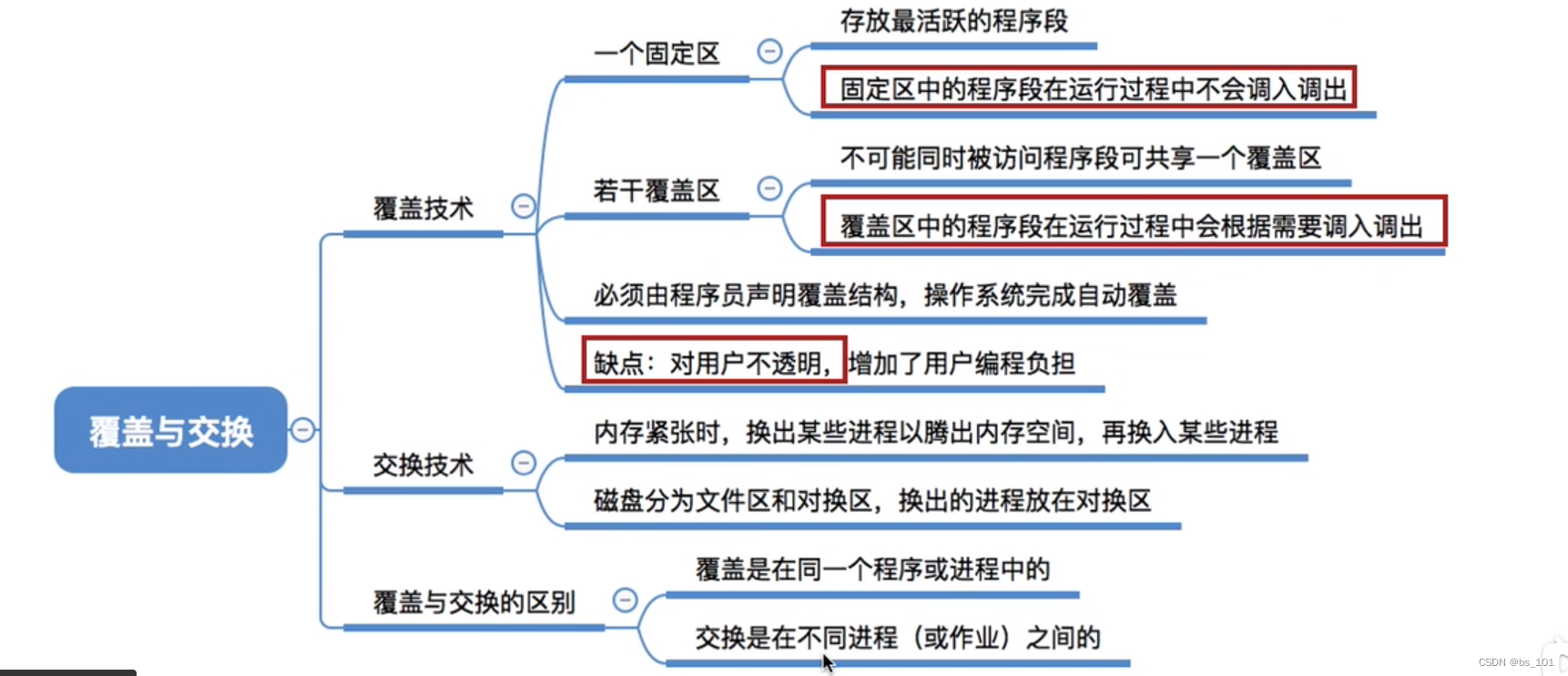
操作系统(day08)内存
存储单元 内存的几个基本概念 存储单元 内存地址从0开始,每个地址对应一个存储单元 存储单元大小根据计算机按照什么方式编址 按字节编址 则每个存储单元大小为一字节,即1B,即8个二进制位按字编址 看这个计算的字长是多少位,如…...
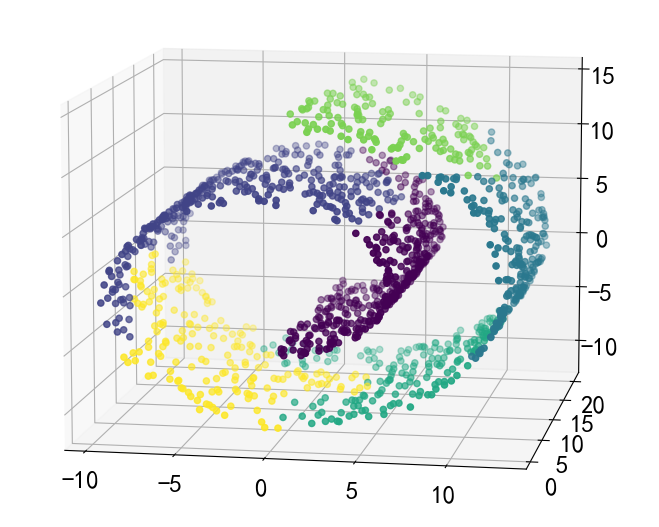
11- 聚类算法 (KMeans/DBSCAN/agg) (机器学习)
聚类算法 聚类算法和降维算法那都属于无监督算法。KMeans 是以一个值为中心, 然后所有其他点到该点距离最小值的累积和。 kmeans KMeans(n_clusters3) # n_clusters 分类数量 kmeans.fit(data.iloc[:,1:]) # 无监督,只需要给数据X就可以 DBSCAN 算法是…...

日日顺供应链|想要看清供应链发展趋势,先回答这三个问题
技术变革如何支撑供应链及管理服务的发展? 数字化与科技化开始承托供应链管理能力的升级与变革? 如何从客户需求的纬度反推供应链及管理服务的模式变革?在过去的三年中,我国的供应链企业经受了最为极端的挑战,但当下&a…...

5守护进程与线程
进程组 多个进程的集合,第一个进程就是组长,组长进程的PID等于进程组ID。 进程组生存期:进程组创建到最后一个进程离开(终止或转移到另一个进程组)。与组长进程是否终止无关。 一个进程可以为自己或子进程设置进程组 ID 相关函数 pid_t …...
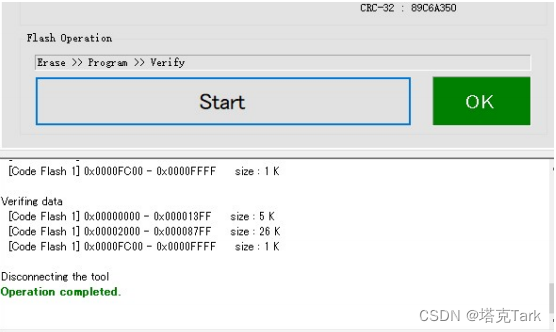
EZ-Cube简易款下载器烧写使用方法
一、硬件连接 跟目标芯片接4根线 VCC、GND、TOOL、REST 四根线,如果板子芯片自己外接电源的,VCC 线可以不接。 二、 安装烧写软件和驱动 烧写软件:https://download.csdn.net/download/Stark_/87444744?spm1001.2014.3001.5503 驱动程序&a…...
sql server安装并SSMS连接
博主简介:原互联网大厂tencent员工,网安巨头Venustech员工,阿里云开发社区专家博主,微信公众号java基础笔记优质创作者,csdn优质创作博主,创业者,知识共享者,欢迎关注,点赞ÿ…...

Python_pytorch (二)
python_pytorch 小土堆pytotch学习视频链接 from的是一个个的包(package) import 的是一个个的py文件(file.py) 所使用的一般是文件中的类(.class) 第一步实例化所使用的类,然后调用类中的方法(def) Torchvision 数据集 数据集使用(CI…...
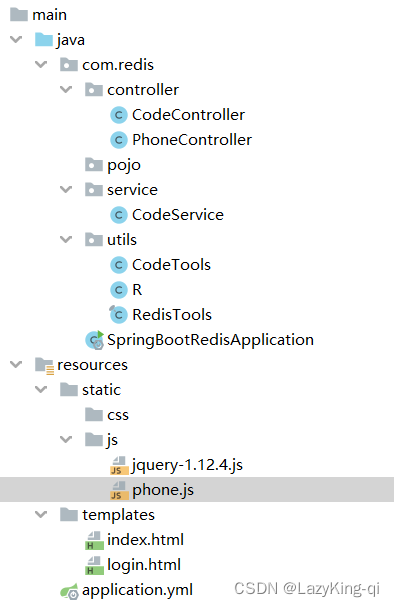
java手机短信验证,并存入redis中,验证码时效5分钟
目录 1、注册发送短信账号一个账号 2、打开虚拟机,将redis服务端打开 3、创建springboot工程,导入相关依赖 4、写yml配置 5、创建controller层,并创建controller类 6、创建service层,并创建service类 7、创建工具类&#x…...

kubectl命令控制远程k8s集群(Windows系统、Ubuntu系统、Centos系统)
文章目录1. 本地是linux2. 本地是Windows1. 本地是linux 安装kubectl命令 法一:从master的/usr/bin目录下拷贝kubectl文件到本机/usr/bin目录下法二:GitHub下载kubectl文件 在家目录下创建.kube目录config文件 法一:将master上对应用户的~/.…...

基于MCP协议实现AI助手个性化:Terminal Buddies项目实战解析
1. 项目概述:当你的终端伙伴遇见AI助手 如果你和我一样,每天有大量时间泡在终端和代码编辑器里,那么一个能带来些许乐趣和陪伴感的“数字伙伴”或许能点亮枯燥的编码时光。Terminal Buddies 正是这样一个巧妙结合了复古 ASCII 艺术、轻量级游…...

STK Astrogator模块避坑指南:从Target Sequence优化失败到成功收敛的5个关键设置
STK Astrogator模块避坑指南:从Target Sequence优化失败到成功收敛的5个关键设置 轨道优化是航天任务设计中的关键环节,而STK的Astrogator模块作为行业标准工具,其Target Sequence功能既能实现复杂机动规划,也常因参数设置不当导致…...

9 款 AI 写论文哪个好?2026 深度实测|虎贲等考 AI 凭真文献 + 真实图表 + 全流程实证,稳坐毕业论文首选
毕业季高频提问:9 款 AI 写论文哪个好?市面上工具看似大同小异,实则在文献真实性、实证图表、全流程覆盖、学术合规上差距巨大。通用大模型文献造假、普通工具无实证能力、小众平台功能残缺,选错轻则反复改稿,重则查重…...
)
AI大模型选型生死线(2026企业级部署避坑指南)
更多请点击: https://intelliparadigm.com 第一章:AI大模型选型生死线(2026企业级部署避坑指南) 企业在2026年落地AI大模型时,选型失误的代价已远超算力采购成本——模型架构错配、上下文长度硬伤、商用许可证模糊、推…...

Cropper.js进阶玩法:打造一个可撤销、可缩放、带滤镜的在线图片编辑器
Cropper.js进阶玩法:打造一个可撤销、可缩放、带滤镜的在线图片编辑器 在当今数字内容创作蓬勃发展的时代,轻量级在线图片编辑工具的需求与日俱增。Cropper.js作为一款优秀的JavaScript图片裁剪库,其潜力远不止于基础的裁剪功能。本文将带您深…...

从学生成绩表到销售报表:手把手教你用ag-grid列组/行组构建复杂业务表格
企业级销售报表实战:用ag-grid行组与列组构建动态分析系统 当业务数据从Excel迁移到前端可视化系统时,开发团队常面临多维分析的挑战。某零售企业曾因无法实时查看"华东区→浙江省→杭州市"三级维度下的季度销售趋势,导致错失库存调…...

Speechless:你的微博数字记忆永久保存方案,告别内容丢失焦虑
Speechless:你的微博数字记忆永久保存方案,告别内容丢失焦虑 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 你是否曾经历过精…...

BlueArchive-Cursors:开源鼠标主题的技术实现与扩展应用指南
BlueArchive-Cursors:开源鼠标主题的技术实现与扩展应用指南 【免费下载链接】BlueArchive-Cursors Custom mouse cursor theme based on the school RPG Blue Archive. 项目地址: https://gitcode.com/gh_mirrors/bl/BlueArchive-Cursors BlueArchive-Curso…...

探究MicroBlaze软核在DDR3中运行sleep函数异常延迟的根源与规避策略
1. 现象描述:从BRAM到DDR3的诡异延迟 第一次把MicroBlaze程序从BRAM搬到DDR3运行时,我遇到了一个让人抓狂的问题:原本精准的sleep(1)延时竟然变成了长达数秒的卡顿。这个现象特别容易在Vitis环境下开发网络应用(比如LwIP协议栈&am…...
)
STM32+RS485实战:用Modbus RTU协议读取液压传感器数据(附自动收发电路避坑)
STM32与RS485实战:从电路设计到Modbus RTU协议解析 液压传感器数据采集在工业自动化领域有着广泛应用,而RS485总线因其抗干扰能力强、传输距离远等优势成为首选通信方式。本文将深入探讨如何基于STM32微控制器搭建RS485硬件电路,并通过Modbus…...