分布式数据存储基础与HDFS操作实践(副本)
以下为作者本人撰写的报告,步骤略有繁琐,不建议作为参考内容,可以适当浏览,进一步理解。
一、实验目的
1、理解分布式文件系统的基本概念和工作原理。
2、掌握Hadoop分布式文件系统(HDFS)的基本操作。
3、学习如何在HDFS上进行文件的上传、下载、查看和管理。
二、实验环境准备
1、JAVA环境准备:确保Java Development Kit (JDK) 已安装并配置好环境变量。
2、Hadoop环境准备:安装并配置Hadoop环境,确保Hadoop的各个组件可以在伪分布式模式下运行。
三、实验教材参考
《大数据存储》,谭旭,人民邮电出版社,2022,ISBN 978-7-115-59414-3。
四、实验内容与步骤
1、 Hadoop的安装与配置
1. 根据教材《大数据存储》中的指导,完成Hadoop的安装。

2. 配置Hadoop以运行在伪分布式模式。
2.1 记录节点1的IP地址

节点1的IP地址为10.185.34.80
2.2 记录节点2的IP地址

节点2的IP地址为10.185.34.81
2.3 记录节点3的IP地址

节点3的IP地址为10.185.34.82
2.4 配置主机名称
主机1 名称配置

主机2名称配置

主机3名称配置

配置完名称后,重启主机。

2.5 节点1主机名与IP地址映射文件配置

检测配置是否成功


配置成功。
主机2和主机3的步骤相同,此处省略。
2.6 配置SSH免密码登录
2.6.1 节点秘钥配置及分发
使用下面代码生成使用rsa加密方式的秘钥
echo -e "\n"|ssh-keygen -t rsa -N "" >/dev/null 2>&1
查看秘钥

通过下面的命令将公钥文件发送到本机,创建root免密钥通道
ssh-copy-id -i /root/.ssh/id_rsa.pub root@realtime-1

将公钥文件发送到其他两个节点。其他两个节点进行相同的操作。此处省略。
2.6.2 登录测试



2.7 配置JDK
2.7.1 创建工作路径

2.7.2 解压安装包
![]()
2.7.3 配置环境变量
在.bashrc文件中写入下列内容:

把环境变量配置文件分发到其他两个节点。

2.7.4 更新环境变量

2.7.5 验证JDK是否配置成功


2.8 NTP服务配置
2.8.1 NTP服务配置
主机1中NTP服务配置。


主机2中NTP服务配置。

主机3中NTP服务配置。

2.8.2 启动NTP服务
在主机1中启动NTP服务。

在主机2中启动NTP服务。

在主机3中启动NTP服务。
![]()
2.8.3 NTP服务状态查看

2.9 SElinux安全配置
关闭节点的SElinux的安全设置。

2.10 安装配置ZooKeeper集群
2.10.1 解压安装包

查看解压后的文件内容

2.10.2 数据存储目录创建
创建数据存储目录data和日志存储目录logs

2.10.3 主机myid编号文件创建

2.10.4 zookeeper 配置文件编辑
通过命令vi /usr/cx/zookeeper-3.4.6/conf/zoo.cfg 创建并打开zoo.cfg配置文件,并在文件中写入下列内容

2.10.5 文件分发
通过下面命令将节点1的zookeeper文件包分发到节点2中。
scp -r /usr/cx/zookeeper-3.4.6 root@realtime-2:/usr/cx/

通过下面命令将节点1的zookeeper文件包分发到节点3中
scp -r /usr/cx/zookeeper-3.4.6 root@realtime-3:/usr/cx/

2.10.6 环境变量配置
通过命令 vi ~/.bashrc 使用vi编辑器打开 ~/.bashrc文件,将文件编辑为下图内容

通过命令将环境变量配置文件分发到其他节点

2.10.7 更新环境变量

2.10.8 验证环境变量是否配置成功


三个节点上的zookeeper环境变量均配置成功
2.11 zookeeper启动及状态查看
2.11.1 zookeeper启动

三个节点上的zookeeper启动成功
2.11.2 zookeeper运行状态查看

由结果得出,节点2是作为leader角色运行,其他两个节点是作为follower角色运行。
2.12 配置hadoop集群
2.12.1 数据存储目录创建
创建Hadoop元数据存储目录namenode,Hadoop数据存储目录datanode,创建JournalNode数据存储目录journalnode,创建任务调度的日志存储目录hadoop-yarn。

2.12.2 解压安装文件
使用tar -zxvf /usr/software/hadoop-2.7.1.tar.gz -C /usr/cx命令解压Hadoop安装文件。

2.12.3 编辑hadoop配置文件
使用vi /usr/cx/hadoop-2.7.1/etc/hadoop/hadoop-env.sh命令对配置文件进行编辑。

将此处修改为jdk的安装路径。
使用命令vi /usr/cx/hadoop-2.7.1/etc/hadoop/hdfs-site.xml 配置hdfs-site.xml 文件进行配置。将下列内容添加到<configuration> 和 </configuration> 之间:
/*配置DataNode的数据存储目录,需要与上文创建的目录相对应*/
<property>
<name>dfs.datanode.data.dir</name>
<value>/hdfs/datanode</value>
</property>
/*配置数据块大小为256M*/
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
/*自定义的HDFS服务名,在高可用集群中,无法配置单一HDFS服务器入口,以需要指定一个逻辑上的服务名,当访问服务名时,会自动选择NameNode节点进行访问*/
<property>
<name>dfs.nameservices</name>
<value>HDFScluster</value>
</property>
/*配置NameNode的数据存储目录,需要与上文创建的目录相对应*/
<property>
<name>dfs.namenode.name.dir</name>
<value>/hdfs/namenode</value>
</property>
/*定义HDFS服务名所指向的NameNode主机名称*/
<property>
<name>dfs.ha.namenodes.HDFScluster</name>
<value>realtime-1,realtime-2</value>
</property>
/*设置NameNode的完整监听地址*/
<property>
<name>dfs.namenode.rpc-address.HDFScluster.realtime-1</name>
<value>realtime-1:8020</value>
</property>
/*设置NameNode的完整监听地址*/
<property>
<name>dfs.namenode.rpc-address.HDFScluster.realtime-2</name>
<value>realtime-2:8020</value>
</property>
/*设置NameNode的HTTP访问地址*/
<property>
<name>dfs.namenode.http-address.HDFScluster.realtime-1</name>
<value>realtime-1:50070</value>
</property>
/*设置NameNode的HTTP访问地址*/
<property>
<name>dfs.namenode.http-address.HDFScluster.realtime-2</name>
<value>realtime-2:50070</value>
</property>
/*设置主从NameNode元数据同步地址,官方推荐将nameservice作为最后的journal ID*/
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://realtime-1:8485;realtime-2:8485;realtime-3:8485/HDFScluster</value>
</property>
/*设置HDFS客户端用来连接集群中活动状态NameNode节点的Java类*/
<property>
<name>dfs.client.failover.proxy.provider.HDFScluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
/*设置SSH登录的私钥文件地址*/
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
/*启动fence过程,确保集群高可用性*/
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
/*配置JournalNode的数据存储目录,需要与上文创建的目录相对应*/
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/hdfs/journalnode</value>
</property>
/*设置自动切换活跃节点,保证集群高可用性*/
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
/*配置数据块副本数*/
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
/*将dfs.webhdfs.enabled属性设置为true,否则就不能使用webhdfs的LISTSTATUS、LIST FILESTATUS等需要列出文件、文件夹状态的命令,因为这些信息都是由namenode保存的*/
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
编辑完成后保存文件并退出vi编辑器。
使用命令vi /usr/cx/hadoop-2.7.1/etc/hadoop/core-site.xml 配置core-site.xml 文件进行配置。将下列内容添加到<configuration> 和 </configuration> 之间:
/*设置默认的HDFS访问路径,需要与hdfs-site.xml中的HDFS服务名相一致*/
<property>
<name>fs.defaultFS</name>
<value>hdfs://HDFScluster</value>
</property>
/*临时文件夹路径设置*/
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/tmp</value>
</property>
/*配置ZooKeeper服务集群,用于活跃NameNode节点的选举*/
<property>
<name>ha.zookeeper.quorum</name>
<value>realtime-1:2181,realtime-2:2181,realtime-3:2181</value>
</property>
/*设置数据压缩算法*/
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
/*设置使用hduser用户可以代理所有主机用户进行任务提交*/
<property>
<name>hadoop.proxyuser.hduser.host</name>
<value>*</value>
</property>
/*设置使用hduser用户可以代理所有组用户进行任务提交*/
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
编辑完成后保存文件并退出vi编辑器。
使用命令vi /usr/cx/hadoop-2.7.1/etc/hadoop/yarn-site.xml文件进行配置。将下列内容添加到<configuration> 和 </configuration> 之间:
/*设置NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行MapReduce程序*/
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
/*设置任务日志存储目录*/
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:///var/log/hadoop-yarn </value>
</property>
/*设置Hadoop依赖包地址*/
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_HOME/share/hadoop/common/*,$HADOOP_HOME/share/hadoop/common/lib/*,
HADOOP_HOME/share/hadoop/hdfs/*,$HADOOP_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_HOE/share/hadoop/mapreduce/*,$HADOOP_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_HOME/share/hadoop/yarn/*,$HADOOP_HOME/share/hadoop/yarn/lib/*
</value>
</property>
/*开启resourcemanager 的高可用性功能*/
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
/*标识集群中的resourcemanager,如果设置选项,需要确保所有的resourcemanager节点在配置中都有自己的逻辑id*/
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>YARNcluster</value>
</property>
/*设置resourcemanager节点的逻辑id*/
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
/*为每个逻辑id绑定实际的主机名称*/
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>realtime-1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>realtime-2</value>
</property>
/*指定ZooKeeper服务地址*/
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>realtime-1:2181,realtime-2:2181,realtime-3:2181</value>
</property>
/*指定resourcemanager的WEB访问地址*/
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>realtime-1:8089</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>realtime-2:8089</value>
</property>
/*设定虚拟内存与实际内存的比例,比例值越高,则可用虚拟内存就越多*/
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
/*设定单个容器可以申领到的最小内存资源*/
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>32</value>
</property>
/*设置当任务运行结束后,日志文件被转移到的HDFS目录*/
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>hdfs://HDFScluster/var/log/hadoop-yarn/apps</value>
</property>
/*设定资调度策略,目前可用的有FIFO、Capacity Scheduler和Fair Scheduler*/
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yan.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
/*设定每个任务能够申领到的最大虚拟CPU数目*/
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>8</value>
</property>
/*设置任务完成指定时间(秒)之后,删除任务的本地化文件和日志目录*/
<property>
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>600</value>
</property>
/*设置志在HDFS上保存多长时间(秒)*/
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>86400</value>
</property>
/*设定物理节点有2G内存加入资源池*/
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
编辑完成后保存文件并退出。
使用 cp /usr/cx/hadoop-2.7.1/etc/hadoop/mapred-site.xml.template /usr/cx/hadoop-2.7.1/etc/hadoop/mapred-site.xml 命令复制mapred-site.xml.template文件并重命名为mapred-site.xml。使用 vi 命令打开mapred-site.xml文件进行配置,在文件 <configuration>和</configuration>之间增加下列内容:
/*Hadoop对MapReduce运行框架一共提供了3种实现,在mapred-site.xml中通过"mapreduce.framework.name"这个属性来设置为"classic"、"yarn"或者"local"*/
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
使用 vi /usr/cx/hadoop-2.7.1/etc/hadoop/slaves 命令打开slaves文件进行配置。将文件中的内容更改为图中内容:

编辑完成后保存文件并退出。
2.12.4 文件分发
通过命令 scp -r /usr/cx/hadoop-2.7.1 root@realtime-n:/usr/cx/ 将节点1 的Hadoop文件包分到其他节点中。

2.12.5 配置Hadoop环境变量
通过命令 vi ~/.bashrc 使用vi编辑器编辑~/.bashrc文件,在文件中加入图中内容,编辑完成后保存并退出。

通过scp分发命令将节点1的环境变量文件分发到其他两个节点。

2.12.6 更新环境变量
执行图中命令,更新三个节点中的环境变量。

2.12.7 格式化HDFS
执行命令 hadoop namenode -format 格式化HDFS文件系统。

2.12.8 格式化zkfc元数据
执行命令 hdfs zkfc -formatZK 格式化zkfc元数据,在一个节点中进行处理即可。

2.19 Hadoop集群启用运行
2.19.1 启动HDFS相关服务
执行命令 start-dfs.sh 启动HDFS相关服务。

执行命令 jps 查看节点1中对应的相关服务。


执行命令 ssh realtime-2 "hadoop namenode -bootstrapStandby" 格式化Standby节点。

格式化Standby节点后,执行命令 ssh realtime-2 "hadoop-daemon.sh start namenode" 启动Standby节点的NameNode进程。

2.13.2 启动yarn相关服务
执行命令 start-yarn.sh 启动yarn相关服务。

执行命令 ssh realtime-2 "yarn-daemon.sh start resourcemanager" 在节点2中启动ResourceManager进程。

2、启动Hadoop HDFS
1. 启动HDFS。

2. 验证HDFS是否成功启动,可以使用jps命令查看Java进程,确认NameNode和DataNode等进程是否运行。

出现以上内容表示启动成功。
3、HDFS基本操作实践
1. 目录操作:使用hdfs dfs -mkdir命令创建新的目录。

2. 文件上传:使用hdfs dfs -put命令上传本地文件到HDFS。

3. 文件下载:使用hdfs dfs -get命令下载HDFS上的文件到本地。

4. 文件查看:使用hdfs dfs -cat命令查看HDFS上的文件内容。

5. 文件删除:使用hdfs dfs -rm命令删除HDFS上的文件。

相关文章:
分布式数据存储基础与HDFS操作实践(副本)
以下为作者本人撰写的报告,步骤略有繁琐,不建议作为参考内容,可以适当浏览,进一步理解。 一、实验目的 1、理解分布式文件系统的基本概念和工作原理。 2、掌握Hadoop分布式文件系统(HDFS)的基本操作。 …...

Linux 进程前篇(冯诺依曼体系结构和操作系统)
目录 一.冯诺依曼体系结构 1.概念 2.硬件层面的数据流 3.总结加补充 二.操作系统 (Operating System) 1.概念 2.设计OS的目的 3.定位 4.操作系统的管理 5.计算机体系的层状结构 在我们认识进程之前,我们先了解什么是冯诺依曼体系结构 一.冯诺依曼体系结构…...

Springboot Redisson 分布式锁、缓存、消息队列、布隆过滤器
redisson-spring-boot-starter 是 Redisson 提供的 Spring Boot 集成包,旨在简化与 Redis 的交互,包括分布式锁、缓存、消息队列、布隆过滤器等功能的实现。 Maven 依赖 在 Spring Boot 项目中添加 redisson-spring-boot-starter 依赖: <…...
【C语言】_字符串拷贝函数strcpy
目录 1. 函数声明及功能 2. 使用示例 3. 注意事项 4. 模拟实现 4.1 第一版:基本功能判空const修饰 4.2 第二版:优化对于\0的单独拷贝 4.3 第三版:仿strcpy的char*返回值 1. 函数声明及功能 char * strcpy ( char * destination, cons…...

基于 Vue 的拖拽缩放卡片组件:实现思路、方法及使用指南
引言 在前端开发中,实现可交互的组件能够极大地提升用户体验。本文将介绍一个基于 Vue 封装的可缩放卡片组件,从实现思路、代码具体实现以及使用方法等方面进行详细阐述,帮助开发者更好地理解和运用这一组件。项目源码地址:https…...

nginx 实现 正向代理、反向代理 、SSL(证书配置)、负载均衡 、虚拟域名 ,使用其他中间件监控
我们可以详细地配置 Nginx 来实现正向代理、反向代理、SSL、负载均衡和虚拟域名。同时,我会介绍如何使用一些中间件来监控 Nginx 的状态和性能。 1. 安装 Nginx 如果你还没有安装 Nginx,可以通过以下命令进行安装(以 Ubuntu 为例࿰…...

Kafka客户端-“远程主机强迫关闭了一个现有的连接”故障排查及解决
Kafka客户端-“远程主机强迫关闭了一个现有的连接”故障排查及解决 1. 故障现象 Kafka客户端发送数据时,出现“远程主机强迫关闭了一个现有的连接”错误,导致数据发送失败。错误信息如下: 2. 故障排查 【1】. 查看服务网络状态 出现故障…...

Node.js - Express框架
1. 介绍 Express 是一个基于 Node.js 的 Web 应用程序框架,主要用于快速、简便地构建 Web 应用程序 和 API。它是目前最流行的 Node.js Web 框架之一,具有轻量级、灵活和功能丰富的特点。 核心概念包括路由,中间件,请求与响应&a…...

AWS Lambda
AWS Lambda 是 Amazon Web Services(AWS)提供的无服务器计算服务,它让开发者能够运行代码而不需要管理服务器或基础设施。AWS Lambda 会自动处理代码的执行、扩展和计费,开发者只需关注编写和部署代码,而无需担心底层硬…...

mysql 如何快速删除表数据
在数据库管理中, 经常会遇到需要删除大量数据的情况. 对于 MySQL 数据库而言, 如何高效快速地删除数据是一个值得深入探讨的问题. 本文将详细介绍几种在 MySQL 中快速删除数据的方法及相关注意事项. delete 语句 delete 语句可以删除符合条件的指定数据, 但是在删除大量数据…...

物联网网关Web服务器--lighttpd服务器部署与应用测试
以下是在国产ARM处理器E2000飞腾派开发板上部署 lighttpd 并进行 CGI 应用开发的步骤: 1、lighttpd简介 Lighttpd 是一款轻量级的开源 Web 服务器软件,具有以下特点和功能: 特点 轻量级:Lighttpd 在设计上注重轻量级和高效性&a…...

vmware虚拟机配置ubuntu 18.04(20.04)静态IP地址
VMware版本 :VMware Workstation 17 Pro ubuntu版本:ubuntu-18.04.4-desktop-amd64 主机环境 win11 1. 修改 VMware虚拟网络编辑器 打开vmware,点击顶部的“编辑"菜单,打开 ”虚拟化网络编辑器“ 。 选择更改设置&#…...

智能家居篇 一、Win10 VM虚拟机安装 Home Assistant 手把手教学
智能家居篇 一、Win10 VM虚拟机安装 Home Assistant 手把手教学 文章目录 [智能家居篇]( )一、Win10 VM虚拟机安装 Home Assistant 手把手教学 前言一.下载Vm版本的HomeAsistant安装包 二.打开Vmware选择新建虚拟机1.选择自定义高级2.选择16.x及以上3.选择稍后安装4.根据官网的…...

Flutter插件制作、本地/远程依赖及缓存机制深入剖析(原创-附源码)
Flutter插件在开发Flutter项目的过程中扮演着重要的角色,我们从 https://pub.dev 上下载添加到项目中的第三方库都是以包或者插件的形式引入到代码中的,这些第三方工具极大的提高了开发效率。 深入的了解插件的制作、发布、工作原理和缓存机…...

Python猜数小游戏
Python 实现的《猜数游戏》 介绍 本文将展示如何使用 Python 编写一个简单的《猜数游戏》。这个游戏将会生成一个1到10之间的随机数,用户有最多三次机会来猜测正确的数字。如果用户猜对了,游戏将结束并显示恭喜信息;如果没有猜对࿰…...
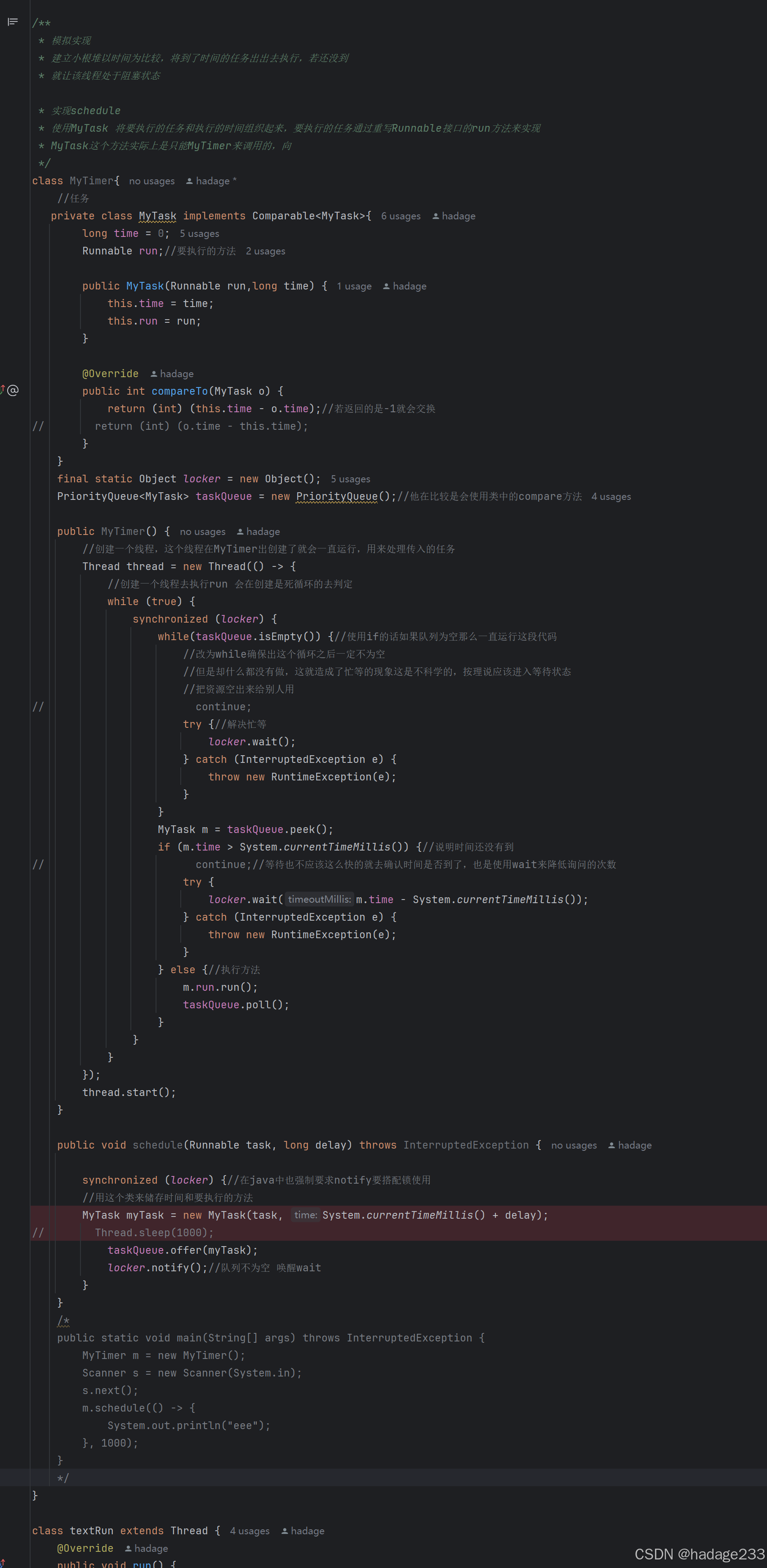
--- 用java实现一个计时器 ---
这里的计时器值得是当线程设定的时间过了之后,自动执行该线程的工作 设计 MyTimer 既然是要在指定的时间之后执行任务,那么传入的参数就应该有run方法(需要执行的任务),time(在多少时间之后执行ÿ…...

OPI4A,目标检测,口罩检测,mnn,YoloX
记得之前,使用了bubbling导师复现的python版yolox,训练了自建的口罩数据集,得到了h5文件,又转换成pb文件,再使用阿里巴巴的MNN,使用它的MNNConvert,转换成mnn文件 最终实现了,在树莓…...

C#与Vue2上传下载Excel文件
1、上传文件流程:先上传文件,上传成功,返回文件名与url,然后再次发起请求保存文件名和url到数据库 前端Vue2代码: 使用element的el-upload组件,action值为后端接收文件接口,headers携带session信…...

Linux(Centos7)安装Mysql/Redis/MinIO
安装Mysql 安装Redis 搜索Redis最先版本所在的在线安装yum库 查看以上两个组件是否是开机自启 安装MinIO 开源的对象存储服务,存储非结构化数据,兼容亚马逊S3协议。 minio --help #查询命令帮助minio --server --help #查询--server帮助minio serve…...

港科夜闻 | 香港科大与微软亚洲研究院签署战略合作备忘录,推动医学健康教育及科研协作...
关注并星标 每周阅读港科夜闻 建立新视野 开启新思维 1、香港科大与微软亚洲研究院签署战略合作备忘录,推动医学健康教育及科研协作。根据备忘录,双方将结合各自于科研领域的优势,携手推动医学健康领域的交流与合作。合作方向将涵盖人才培训、…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...
)
告别复杂模型:用Python+OpenCV+dlib实现简易驾驶员疲劳监测(附完整代码)
轻量级驾驶员疲劳监测系统:PythonOpenCVdlib实战指南 在长途驾驶或夜间行车时,疲劳是导致交通事故的重要因素之一。传统基于嵌入式设备的疲劳监测系统往往需要专用硬件,增加了开发成本和部署难度。本文将介绍如何利用Python生态中的OpenCV和d…...

数字合成器d-FORMANT:从模拟经典到数字复刻的工程实践
1. 项目概述:从模拟经典到数字复刻如果你对合成器稍有了解,或者对电子音乐制作背后的硬件感兴趣,那么“FORMANT”这个名字你一定不陌生。它最初是上世纪70年代由《Elektor》杂志发布的一款模拟单音合成器,以其清晰的模块化设计和出…...

茉莉花插件:如何让中文文献管理效率提升300%
茉莉花插件:如何让中文文献管理效率提升300% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献的元数据抓…...

初创公司如何通过Taotoken快速为产品原型注入多种AI能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何通过Taotoken快速为产品原型注入多种AI能力 对于初创公司而言,资源有限、时间紧迫是常态。产品原型的快速…...