【Elasticsearch】inference ingest pipeline

Elasticsearch 的 Ingest Pipeline 功能允许你在数据索引之前对其进行预处理。通过使用 Ingest Pipeline,你可以执行各种数据转换和富化操作,包括使用机器学习模型进行推理(inference)。这在处理词嵌入、情感分析、图像识别等场景中非常有用。
### 使用 Inference Ingest Pipeline
以下是一个详细的步骤,展示如何使用 Inference Ingest Pipeline 在 Elasticsearch 中加载和使用预训练的机器学习模型来进行推理。
### 步骤 1: 准备机器学习模型
首先,你需要准备一个预训练的机器学习模型,并将其部署到 Elasticsearch 的机器学习模块中。Elasticsearch 支持多种模型格式,包括 TensorFlow、PyTorch、ONNX 等。
#### 示例:上传 TensorFlow 模型
1. **下载或训练模型**:确保你有一个 TensorFlow 模型文件(例如,`.pb` 文件)。
2. **上传模型**:使用 Elasticsearch 的机器学习 API 将模型上传到 Elasticsearch。
```json
PUT _ml/trained_models/my_word_embedding_model
{
"input": {
"field_names": ["text"]
},
"inference_config": {
"natural_language_inference": {
"results_field": "inference_results"
}
},
"model": {
"definition": {
"path": "path/to/your/model.pb"
}
}
}
```
### 步骤 2: 创建 Ingest Pipeline
创建一个 Ingest Pipeline,使用刚刚上传的模型进行推理。
```json
PUT _ingest/pipeline/word_embedding_pipeline
{
"description": "Pipeline to add word embeddings using a trained model",
"processors": [
{
"inference": {
"model_id": "my_word_embedding_model",
"target_field": "embedding"
}
}
]
}
```
### 步骤 3: 使用 Ingest Pipeline 索引数据
在索引数据时,指定使用创建的 Ingest Pipeline。
```json
POST word_embeddings/_doc?pipeline=word_embedding_pipeline
{
"word": "example"
}
```
### 示例:完整流程
以下是一个完整的示例,展示如何从头开始创建和使用 Inference Ingest Pipeline。
#### 1. 上传模型
```json
PUT _ml/trained_models/my_word_embedding_model
{
"input": {
"field_names": ["text"]
},
"inference_config": {
"natural_language_inference": {
"results_field": "inference_results"
}
},
"model": {
"definition": {
"path": "path/to/your/model.pb"
}
}
}
```
#### 2. 创建 Ingest Pipeline
```json
PUT _ingest/pipeline/word_embedding_pipeline
{
"description": "Pipeline to add word embeddings using a trained model",
"processors": [
{
"inference": {
"model_id": "my_word_embedding_model",
"target_field": "embedding"
}
]
}
```
#### 3. 创建索引
```json
PUT word_embeddings
{
"mappings": {
"properties": {
"word": {
"type": "keyword"
},
"embedding": {
"type": "dense_vector",
"dims": 100 // 根据你的词嵌入模型的维度设置
}
}
}
}
```
#### 4. 索引数据
```json
POST word_embeddings/_doc?pipeline=word_embedding_pipeline
{
"word": "example"
}
```
### 验证结果
你可以通过查询索引来验证数据是否正确索引,并且词嵌入向量是否已添加。
```json
GET word_embeddings/_search
{
"query": {
"match": {
"word": "example"
}
}
}
```
### 注意事项
1. **模型路径**:确保模型文件路径正确,并且 Elasticsearch 有权限访问该路径。
2. **模型格式**:Elasticsearch 支持多种模型格式,确保你使用的模型格式与 Elasticsearch 兼容。
3. **性能**:Inference Ingest Pipeline 可能会影响索引性能,特别是在处理大量数据时。考虑在生产环境中进行性能测试。
通过以上步骤,你可以在 Elasticsearch 中使用 Inference Ingest Pipeline 对数据进行预处理,从而实现词嵌入的自动计算和存储。希望这些示例和说明能帮助你更好地理解和使用 Elasticsearch 的 Inference Ingest Pipeline 功能。
当你执行以下查询时,Elasticsearch 会返回与 `word` 字段匹配 "example" 的所有文档及其相关信息。假设你已经按照前面的步骤创建了索引并插入了数据,查询结果将包含文档的 `_id`、`_source` 等字段。
### 查询示例
```json
GET word_embeddings/_search
{
"query": {
"match": {
"word": "example"
}
}
}
```
### 返回结果示例
假设你已经索引了一些文档,查询结果可能如下所示:
```json
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "word_embeddings",
"_type": "_doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"word": "example",
"embedding": [0.1, 0.2, ..., 0.100]
}
}
]
}
}
```
### 解释
- **`took`**: 查询花费的时间(毫秒)。
- **`timed_out`**: 查询是否超时。
- **`_shards`**: 分片信息,包括总分片数、成功分片数、跳过分片数和失败分片数。
- **`hits`**: 匹配的文档列表。
- **`total`**: 匹配的文档总数。
- **`max_score`**: 最高评分。
- **`hits`**: 匹配的文档列表,每个文档包含以下字段:
- **`_index`**: 文档所属的索引名称。
- **`_type`**: 文档类型(在Elasticsearch 7.x及更高版本中,类型总是`_doc`)。
- **`_id`**: 文档的唯一标识符。
- **`_score`**: 文档的相关性评分。
- **`_source`**: 文档的原始内容,包括所有字段及其值。
### 示例解释
假设你索引了一个文档,其中 `word` 字段为 "example",`embedding` 字段为 `[0.1, 0.2, ..., 0.100]`,查询结果将返回这个文档的信息。
- **`_index`**: 文档所属的索引名称,这里是 `word_embeddings`。
- **`_type`**: 文档类型,这里是 `_doc`。
- **`_id`**: 文档的唯一标识符,假设为 `1`。
- **`_score`**: 文档的相关性评分,这里是 `0.2876821`。
- **`_source`**: 文档的原始内容,包括 `word` 和 `embedding` 字段。
### 进一步操作
如果你需要进一步处理或过滤结果,可以在查询中添加更多的条件。例如,你可以使用 `size` 参数来限制返回的文档数量,或者使用 `sort` 参数来按特定字段排序。
```json
GET word_embeddings/_search
{
"query": {
"match": {
"word": "example"
}
},
"size": 10,
"sort": [
{ "_score": { "order": "desc" } }
]
}
```
希望这些解释和示例能帮助你更好地理解和使用 Elasticsearch 的查询结果。
PUT _ingest/pipeline/word_embedding_pipeline
{
"description": "Pipeline to add word embeddings using a trained model",
"processors": [
{
"inference": {
"model_id": "my_word_embedding_model",
"target_field": "embedding"
}
]
}这段是干嘛的?
这段代码用于在 Elasticsearch 中创建一个 Ingest Pipeline,该管道将在数据索引之前使用预训练的机器学习模型进行推理(inference),并将推理结果(词嵌入向量)添加到文档中。具体来说,这段代码做了以下几件事:
### 1. 创建 Ingest Pipeline
```json
PUT _ingest/pipeline/word_embedding_pipeline
{
"description": "Pipeline to add word embeddings using a trained model",
"processors": [
{
"inference": {
"model_id": "my_word_embedding_model",
"target_field": "embedding"
}
}
]
}
```
### 详细解释
- **`PUT _ingest/pipeline/word_embedding_pipeline`**:
- 这是一个 HTTP PUT 请求,用于创建一个新的 Ingest Pipeline。`word_embedding_pipeline` 是管道的名称,你可以根据需要选择一个合适的名称。
- **`description`**:
- 这是一个可选字段,用于描述管道的目的。在这里,描述为 "Pipeline to add word embeddings using a trained model",表示这个管道用于使用预训练模型添加词嵌入向量。
- **`processors`**:
- 这是一个数组,包含一个或多个处理器(processors)。每个处理器定义了一个数据处理步骤。
- **`inference`**:
- 这是一个处理器,用于执行机器学习模型的推理。它有两个主要参数:
- **`model_id`**: 指定要使用的预训练模型的 ID。在这个例子中,模型 ID 是 `my_word_embedding_model`。
- **`target_field`**: 指定将推理结果存储到文档中的哪个字段。在这个例子中,推理结果将存储在 `embedding` 字段中。
### 2. 使用 Ingest Pipeline 索引数据
一旦创建了 Ingest Pipeline,你可以在索引数据时指定使用该管道。这样,Elasticsearch 会在数据索引之前自动执行推理,并将结果添加到文档中。
```json
POST word_embeddings/_doc?pipeline=word_embedding_pipeline
{
"word": "example"
}
```
### 示例流程
1. **上传模型**:
- 首先,你需要将预训练的机器学习模型上传到 Elasticsearch。假设你已经上传了一个名为 `my_word_embedding_model` 的模型。
2. **创建 Ingest Pipeline**:
- 使用上述代码创建一个 Ingest Pipeline,该管道将使用 `my_word_embedding_model` 模型进行推理,并将结果存储在 `embedding` 字段中。
3. **索引数据**:
- 在索引数据时,指定使用创建的 Ingest Pipeline。Elasticsearch 将在数据索引之前执行推理,并将结果添加到文档中。
### 示例
假设你已经上传了一个名为 `my_word_embedding_model` 的模型,并创建了 `word_embedding_pipeline` 管道。以下是一个完整的示例:
#### 1. 上传模型
```json
PUT _ml/trained_models/my_word_embedding_model
{
"input": {
"field_names": ["text"]
},
"inference_config": {
"natural_language_inference": {
"results_field": "inference_results"
}
},
"model": {
"definition": {
"path": "path/to/your/model.pb"
}
}
}
```
#### 2. 创建 Ingest Pipeline
```json
PUT _ingest/pipeline/word_embedding_pipeline
{
"description": "Pipeline to add word embeddings using a trained model",
"processors": [
{
"inference": {
"model_id": "my_word_embedding_model",
"target_field": "embedding"
}
}
]
}
```
#### 3. 创建索引
```json
PUT word_embeddings
{
"mappings": {
"properties": {
"word": {
"type": "keyword"
},
"embedding": {
"type": "dense_vector",
"dims": 100 // 根据你的词嵌入模型的维度设置
}
}
}
}
```
#### 4. 索引数据
```json
POST word_embeddings/_doc?pipeline=word_embedding_pipeline
{
"word": "example"
}
```
### 验证结果
你可以通过查询索引来验证数据是否正确索引,并且词嵌入向量是否已添加。
```json
GET word_embeddings/_search
{
"query": {
"match": {
"word": "example"
}
}
}
```
### 返回结果示例
```json
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "word_embeddings",
"_type": "_doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"word": "example",
"embedding": [0.1, 0.2, ..., 0.100]
}
}
]
}
}
```
通过以上步骤,你可以在 Elasticsearch 中使用 Ingest Pipeline 自动处理数据,将词嵌入向量添加到文档中。希望这些解释和示例能帮助你更好地理解和使用 Ingest Pipeline。如果有任何进一步的问题,请随时提问!
相关文章:
【Elasticsearch】inference ingest pipeline
Elasticsearch 的 Ingest Pipeline 功能允许你在数据索引之前对其进行预处理。通过使用 Ingest Pipeline,你可以执行各种数据转换和富化操作,包括使用机器学习模型进行推理(inference)。这在处理词嵌入、情感分析、图像识别等场景…...

AQS公平锁与非公平锁之源码解析
AQS加锁逻辑 ReentrantLock.lock public void lock() {sync.acquire(1);}AbstractQueuedSynchronizer#acquire public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}addWaiter就是将节点加入…...

若依框架在企业中的应用调研
若依框架作为一款基于 Spring Boot 的轻量级 Java 快速开发框架,在企业级应用开发中发挥着重要作用。以下是对其在企业中应用的调研情况: 应用现状 广泛应用于多种管理系统:在众多企业中,若依框架常被用于构建各类后台管理系统&a…...

【Day23 LeetCode】贪心算法题
一、贪心算法 贪心没有套路,只有碰运气(bushi),举反例看看是否可行,(运气好)刚好贪心策略的局部最优就是全局最优。 1、分发饼干 455 思路:按照孩子的胃口从小到大的顺序依次满足…...

2025年PHP面试宝典,技术总结。
面试是进入职场的第一道坎,因为我本身学校太一般的问题在面试中遇到了各种不爽,和那些高学历的相比自己真是信心大跌。我面试的方向是php开发工程师,主要做网站后台、APP接口等。下面是我这段时间总结的面试方面的常考常问的知识点࿰…...

Qt中的按钮组:QPushButton、QToolButton、QRadioButton和QCheckBox使用方法(详细图文教程)
💪 图像算法工程师,专业从事且热爱图像处理,图像处理专栏更新如下👇: 📝《图像去噪》 📝《超分辨率重建》 📝《语义分割》 📝《风格迁移》 📝《目标检测》 &a…...

influxdb+grafana+jmeter
influxdb influxd先启动 启动完成后执行 influxdb的端口号 grafana的启动 通过grafana-server.exe启动grafana 启动后打开 http://localhost:8087/...

Net Core微服务入门全纪录(三)——Consul-服务注册与发现(下)
系列文章目录 1、.Net Core微服务入门系列(一)——项目搭建 2、.Net Core微服务入门全纪录(二)——Consul-服务注册与发现(上) 3、.Net Core微服务入门全纪录(三)——Consul-服务注…...

leetcode 479. 最大回文数乘积
题目如下 看完题目后没有想到取巧的办法所以尝试使用枚举法。 使用枚举法之前先回答两个问题: 1. 如何构造回文串? 2. 如何判断是否存在两个n位整数相乘可以得到这个回文串? 显然n位数与n位数相乘必然是2n位数也就是说最大回文整数长度必然…...

独立搭建UI自动化测试框架
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 今天给大家分享一个seleniumtestngmavenant的UI自动化,可以用于功能测试,也可按复杂的业务流程编写测试用例,今天此篇文章不过多…...

62,【2】 BUUCTF WEB [强网杯 2019]Upload1
进入靶场 此处考点不是SQL,就正常注册并登录进去 先随便传一个 进行目录扫描,我先用爆破代替 先随便后面写个文件名 为了提供payload位置 www.tar.gz真的存在 返回浏览器修改url就自动下载了 看到tp5,应该是ThinkPHP5框架 参考此博客的思路方法c[强网杯…...

Spring Boot 整合 ShedLock 处理定时任务重复执行的问题
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》…...

常见Arthas命令与实践
Arthas 官网:https://arthas.aliyun.com/doc/,官方文档对 Arthas 的每个命令都做出了介绍和解释,并且还有在线教程,方便学习和熟悉命令。 Arthas Idea 的 IDEA 插件。 这是一款能快速生成 Arthas命令的插件,可快速生成…...

Glide加载gif遇到的几个坑
Glide本身支持gif格式的动画加载,但是大多数情况下我们用Glide都是去加载一些静态图片,加载gif动态图的需求不是很多,因此这次使用Glide加载gif就遇到了一些令人匪夷所思的问题 问题一:加载gif图片会有明显的卡顿 通常情况下我们…...

STM32学习之通用定时器
1.1通用定时器介绍 通用定时器具有基本定时器的所有特征,基本定时器只能递增计数,而通用定时器可以递减计数,可以中心对齐计数;也可以触发ADC和DAC,同时在更新事件,触发事件,输入捕获ÿ…...
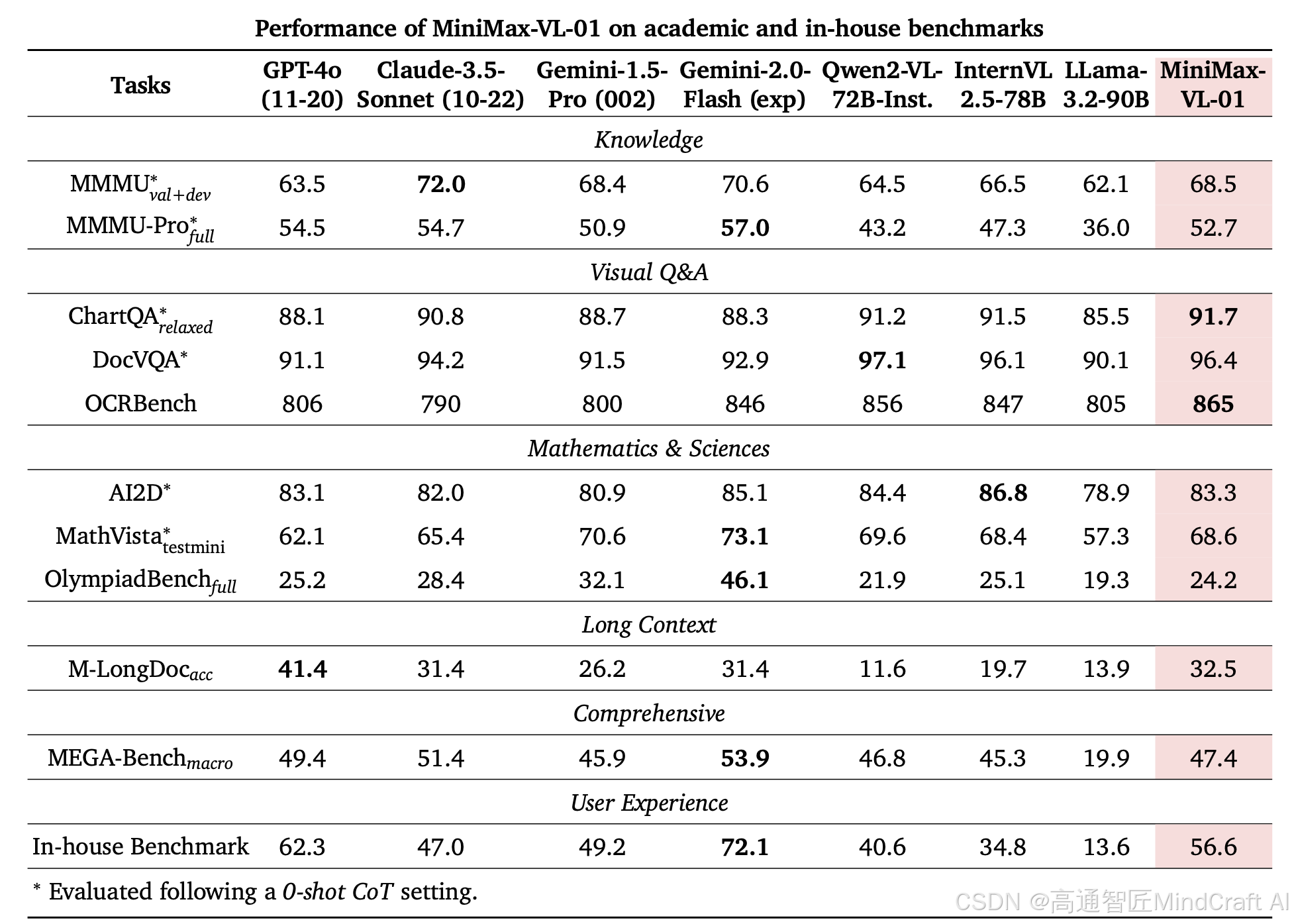
MiniMax-Text-01——模型详细解读与使用
MiniMax发布了最新的旗舰款模型,MiniMax-Text-01。这是一个456B参数的MOE模型,支持最大4M上下文。今天我们来解读一下这个模型,最后会讲一下模型的使用方式和价格。 先来看整体指标,以下图表分为三块指标,分别是文本能…...

Redis的Windows版本安装以及可视化工具
文章目录 redis安装redis安装包下载解压文件夹启动redis服务Redis路径配置环境变量打开redis客户端进行连接基础操作测试 redis可视化工具下载Redis Desktop Manager redis安装 redis安装包下载 windows版本readis下载:Releases tporadowski/redis 解压文件夹 我…...

tensorflow源码编译在C++环境使用
https://tensorflow.google.cn/install/source?hlzh-cn查看tensorflow和其他需要下载软件对应的版本,最好一模一样 1、下载TensorFlow源码 https://github.com/tensorflow/tensorflow 2、安装编译protobuf(3.9.2) protobuf版本要和TensorFlo…...

第四届机器学习、云计算与智能挖掘国际会议
一、会议信息 会议名称:第四届机器学习、云计算与智能挖掘国际会议(MLCCIM 2025) 会议地点:中国漠河 会议时间:2025年7月21-25日 支持单位:佛山市人工智能学会、佛山大学 二、大会主席 …...

#漏洞挖掘# 一文了解什么是Jenkins未授权访问!!!
免责声明 本教程仅为合法的教学目的而准备,严禁用于任何形式的违法犯罪活动及其他商业行为,在使用本教程前,您应确保该行为符合当地的法律法规,继续阅读即表示您需自行承担所有操作的后果,如有异议,请立即停…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...

中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程
中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 掌握中兴光猫的设备管理和权限获取能力是网络管理员和技术爱好者…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...