【机器学习】自定义数据集 使用tensorflow框架实现逻辑回归并保存模型,然后保存模型后再加载模型进行预测
一、使用tensorflow框架实现逻辑回归
1. 数据部分:
- 首先自定义了一个简单的数据集,特征
X是 100 个随机样本,每个样本一个特征,目标值y基于线性关系并添加了噪声。 - tensorflow框架不需要
numpy数组转换为相应的张量,可以直接在模型中使用数据集。
2. 模型定义部分:
方案 1:model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])
解释:
- 此方案使用
tf.keras.Sequential构建模型,在列表中直接定义了一个Dense层,input_shape=(1,)表明输入数据的形状。 - 编译模型时,选择随机梯度下降(SGD)优化器和均方误差损失函数。
- 训练完成后,使用
sklearn的指标评估模型,并输出模型的系数和截距。
import tensorflow as tf
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score# 自定义数据集
X = np.random.rand(100, 1).astype(np.float32)
y = 2 * X + 1 + 0.3 * np.random.randn(100, 1).astype(np.float32)# 构建模型
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))
])# 编译模型
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),loss='mean_squared_error')# 训练模型
history = model.fit(X, y, epochs=1000, verbose=0)# 模型评估
y_pred = model.predict(X)
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 输出模型的系数和截距
weights, biases = model.layers[0].get_weights()
print(f"模型系数: {weights[0][0]}")
print(f"模型截距: {biases[0]}")
方案 2:model = tf.keras.Sequential()
解释:
- 这种方式先创建一个空的
Sequential模型,再使用add方法添加Dense层。 - 后续编译、训练、评估和输出模型参数的步骤与方案 1 类似。
import tensorflow as tf
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score# 自定义数据集
X = np.random.rand(100, 1).astype(np.float32)
y = 2 * X + 1 + 0.3 * np.random.randn(100, 1).astype(np.float32)# 构建模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(1, input_shape=(1,)))# 编译模型
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),loss='mean_squared_error')# 训练模型
history = model.fit(X, y, epochs=1000, verbose=0)# 模型评估
y_pred = model.predict(X)
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 输出模型的系数和截距
weights, biases = model.layers[0].get_weights()
print(f"模型系数: {weights[0][0]}")
print(f"模型截距: {biases[0]}")
方案 3:自定义模型类
解释:
- 继承
Model基类创建自定义模型类Linear,在__init__方法中定义Dense层。 call方法用于实现前向传播逻辑,类似于 PyTorch 中的forward方法。- 后续的编译、训练、评估和参数输出流程和前面方案一致。
import tensorflow as tf
from tensorflow.keras import Model
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score# 自定义数据集
X = np.random.rand(100, 1).astype(np.float32)
y = 2 * X + 1 + 0.3 * np.random.randn(100, 1).astype(np.float32)# 自定义模型类
class Linear(Model):def __init__(self):super(Linear, self).__init__()self.linear = tf.keras.layers.Dense(1)def call(self, x, **kwargs):x = self.linear(x)return x# 构建模型
model = Linear()# 编译模型
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),loss='mean_squared_error')# 训练模型
history = model.fit(X, y, epochs=1000, verbose=0)# 模型评估
y_pred = model.predict(X)
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 输出模型的系数和截距
weights, biases = model.linear.get_weights()
print(f"模型系数: {weights[0][0]}")
print(f"模型截距: {biases[0]}")
方案 4:函数式 API 构建模型
解释:
- 使用函数式 API 构建模型,先定义输入层,再定义
Dense层,最后使用Model类将输入和输出连接起来形成模型。 - 编译、训练、评估和参数输出的步骤和前面方案相同。注意这里通过
model.layers[1]获取Dense层的权重和偏置,因为第一层是输入层。
import tensorflow as tf
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score# 自定义数据集
X = np.random.rand(100, 1).astype(np.float32)
y = 2 * X + 1 + 0.3 * np.random.randn(100, 1).astype(np.float32)# 定义函数构建模型
def linear():input = tf.keras.layers.Input(shape=(1,), dtype=tf.float32)y = tf.keras.layers.Dense(1)(input)model = tf.keras.models.Model(inputs=input, outputs=y)return model# 构建模型
model = linear()# 编译模型
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),loss='mean_squared_error')# 训练模型
history = model.fit(X, y, epochs=1000, verbose=0)# 模型评估
y_pred = model.predict(X)
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 输出模型的系数和截距
weights, biases = model.layers[1].get_weights()
print(f"模型系数: {weights[0][0]}")
print(f"模型截距: {biases[0]}")
3. 训练和评估部分:
- 使用
fit方法对模型进行训练,verbose=0表示不显示训练过程中的详细信息,训练过程中的损失信息会存储在history对象中。 - 通过多个 epoch 进行训练,每个 epoch 包含前向传播、损失计算、反向传播和参数更新。
- 使用
predict方法进行预测,计算均方误差和决定系数评估模型性能,通过model.linear.get_weights()获取模型的系数和截距。
二、保存tensorflow框架逻辑回模型
方式 1:保存为 HDF5 文件(后缀名 .h5)
这种方式会保存模型的结构、权重以及训练配置(如优化器、损失函数等),加载时可以直接得到一个完整可用的模型。
import tensorflow as tf
import numpy as np# 自定义数据集
# 生成 1000 个样本,每个样本有 2 个特征
X = np.random.randn(1000, 2).astype(np.float32)
# 根据特征生成标签
y = (2 * X[:, 0] + 3 * X[:, 1] > 0).astype(np.float32).reshape(-1, 1)# 构建逻辑回归模型
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(2,), activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X, y, epochs=100, batch_size=32, verbose=1)# 保存模型为 HDF5 文件
model.save('logistic_regression_model.h5')# 加载 HDF5 文件模型
loaded_model = tf.keras.models.load_model('logistic_regression_model.h5')# 生成新的测试数据
X_test = np.random.randn(100, 2).astype(np.float32)
y_test = (2 * X_test[:, 0] + 3 * X_test[:, 1] > 0).astype(np.float32).reshape(-1, 1)# 进行预测
y_pred_probs = loaded_model.predict(X_test)
y_pred = (y_pred_probs > 0.5).astype(np.float32)# 计算准确率
accuracy = tf.keras.metrics.BinaryAccuracy()
accuracy.update_state(y_test, y_pred)
print(f"预测准确率: {accuracy.result().numpy()}")
代码解释
- 数据生成与模型构建:生成自定义数据集,构建并编译逻辑回归模型,然后进行训练。
- 保存模型:使用
model.save('logistic_regression_model.h5')将模型保存为 HDF5 文件。 - 加载模型:使用
tf.keras.models.load_model('logistic_regression_model.h5')加载保存的模型。 - 预测与评估:生成新的测试数据,使用加载的模型进行预测,并计算预测准确率。
方式 2:只保存参数
这种方式只保存模型的权重参数,不保存模型的结构和训练配置。加载时需要先定义与原模型相同结构的模型,再将保存的参数加载到新模型中。
import tensorflow as tf
import numpy as np# 自定义数据集
# 生成 1000 个样本,每个样本有 2 个特征
X = np.random.randn(1000, 2).astype(np.float32)
# 根据特征生成标签
y = (2 * X[:, 0] + 3 * X[:, 1] > 0).astype(np.float32).reshape(-1, 1)# 构建逻辑回归模型
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(2,), activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X, y, epochs=100, batch_size=32, verbose=1)# 只保存模型参数
model.save_weights('logistic_regression_weights.h5')# 重新定义相同结构的模型
new_model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(2,), activation='sigmoid')
])# 编译新模型
new_model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 加载保存的参数到新模型
new_model.load_weights('logistic_regression_weights.h5')# 生成新的测试数据
X_test = np.random.randn(100, 2).astype(np.float32)
y_test = (2 * X_test[:, 0] + 3 * X_test[:, 1] > 0).astype(np.float32).reshape(-1, 1)# 进行预测
y_pred_probs = new_model.predict(X_test)
y_pred = (y_pred_probs > 0.5).astype(np.float32)# 计算准确率
accuracy = tf.keras.metrics.BinaryAccuracy()
accuracy.update_state(y_test, y_pred)
print(f"预测准确率: {accuracy.result().numpy()}")
代码解释
- 数据生成与模型构建:同样生成自定义数据集,构建并编译逻辑回归模型,进行训练。
- 保存参数:使用
model.save_weights('logistic_regression_weights.h5')只保存模型的权重参数。 - 重新定义模型:重新定义一个与原模型结构相同的新模型,并进行编译。
- 加载参数:使用
new_model.load_weights('logistic_regression_weights.h5')将保存的参数加载到新模型中。 - 预测与评估:生成新的测试数据,使用加载参数后的新模型进行预测,并计算预测准确率。
通过以上两种方式,可以根据实际需求选择合适的模型保存方法。
三、加载tensorflow框架逻辑回归模型
方案 1:加载保存为 HDF5 文件的模型
当用户将模型保存为 HDF5 文件(后缀名 .h5)时,使用 tf.keras.models.load_model 函数可以直接加载整个模型,包括模型的结构、权重以及训练配置。
import tensorflow as tf
import numpy as np# 生成一些示例数据用于预测
X_test = np.random.randn(100, 2).astype(np.float32)
y_test = (2 * X_test[:, 0] + 3 * X_test[:, 1] > 0).astype(np.float32).reshape(-1, 1)# 加载保存为 HDF5 文件的模型
loaded_model = tf.keras.models.load_model('logistic_regression_model.h5')# 进行预测
y_pred_probs = loaded_model.predict(X_test)
y_pred = (y_pred_probs > 0.5).astype(np.float32)# 计算准确率
accuracy = tf.keras.metrics.BinaryAccuracy()
accuracy.update_state(y_test, y_pred)
print(f"预测准确率: {accuracy.result().numpy()}")
代码解释
- 数据准备:生成一些示例数据
X_test和对应的标签y_test,用于后续的预测和评估。 - 模型加载:使用
tf.keras.models.load_model('logistic_regression_model.h5')加载之前保存为 HDF5 文件的模型。 - 预测与评估:使用加载的模型对测试数据进行预测,将预测概率转换为标签,然后计算预测准确率。
方案 2:加载只保存的参数(权重和偏置)
当用户只保存了模型的参数(权重和偏置)时,需要先定义一个与原模型结构相同的新模型,然后使用 load_weights 方法将保存的参数加载到新模型中。
import tensorflow as tf
import numpy as np# 生成一些示例数据用于预测
X_test = np.random.randn(100, 2).astype(np.float32)
y_test = (2 * X_test[:, 0] + 3 * X_test[:, 1] > 0).astype(np.float32).reshape(-1, 1)# 重新定义相同结构的模型
new_model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(2,), activation='sigmoid')
])# 编译新模型
new_model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 加载保存的参数
new_model.load_weights('logistic_regression_weights.h5')# 进行预测
y_pred_probs = new_model.predict(X_test)
y_pred = (y_pred_probs > 0.5).astype(np.float32)# 计算准确率
accuracy = tf.keras.metrics.BinaryAccuracy()
accuracy.update_state(y_test, y_pred)
print(f"预测准确率: {accuracy.result().numpy()}")
代码解释
- 数据准备:同样生成示例数据
X_test和y_test用于预测和评估。 - 模型定义与编译:重新定义一个与原模型结构相同的新模型
new_model,并进行编译,设置优化器、损失函数和评估指标。 - 参数加载:使用
new_model.load_weights('logistic_regression_weights.h5')将之前保存的参数加载到新模型中。 - 预测与评估:使用加载参数后的新模型对测试数据进行预测,将预测概率转换为标签,最后计算预测准确率。
通过以上两种方案,可以根据不同的保存方式正确加载 TensorFlow 模型。
四、完整流程
1. 实现思路
① 导入必要的库
在开始之前,需要导入 TensorFlow 用于构建和训练模型,NumPy 用于数据处理,以及一些评估指标相关的库。
② 生成自定义数据集
自定义数据集可以根据具体需求生成,这里以一个简单的二维数据集为例,每个样本有两个特征,标签为 0 或 1。
③ 构建逻辑回归模型
一共有4种方式,案例使用其中的TensorFlow的tf.keras.Sequential 构建模型,在列表中直接定义了一个 Dense 层,input_shape=(1,) 表明输入数据的形状。
④ 训练模型
使用生成的数据集对模型进行训练。
⑤ 保存模型
可以选择将模型保存为 HDF5 文件或只保存模型的参数,案例为保存为 HDF5 文件。
⑥ 加载模型并进行预测
此案例为加载 HDF5 文件模型
2. 代码示例
import tensorflow as tf
import numpy as np
from sklearn.metrics import accuracy_score# 生成 1000 个样本,每个样本有 2 个特征
X = np.random.randn(1000, 2).astype(np.float32)
# 根据特征生成标签
y = (2 * X[:, 0] + 3 * X[:, 1] > 0).astype(np.float32).reshape(-1, 1)# 构建逻辑回归模型
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(2,), activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X, y, epochs=100, batch_size=32, verbose=1)# 保存模型
model.save('logistic_regression_model')# 加载模型
loaded_model = tf.keras.models.load_model('logistic_regression_model')# 生成新的测试数据
X_test = np.random.randn(100, 2).astype(np.float32)
y_test = (2 * X_test[:, 0] + 3 * X_test[:, 1] > 0).astype(np.float32).reshape(-1, 1)# 进行预测
y_pred_probs = loaded_model.predict(X_test)
y_pred = (y_pred_probs > 0.5).astype(np.float32)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"预测准确率: {accuracy}")3. 代码解释
① 数据集生成:
使用 np.random.randn 生成具有两个特征的随机样本,根据特征的线性组合生成标签。
② 模型构建:
使用 tf.keras.Sequential 构建一个简单的逻辑回归模型,包含一个具有 sigmoid 激活函数的全连接层。
③ 模型编译:
使用 adam 优化器和 binary_crossentropy 损失函数进行编译,并监控准确率指标。
④ 模型训练:
使用 fit 方法对模型进行训练,指定训练轮数和批次大小。
⑤ 模型保存:
使用 model.save 方法将模型保存到指定目录。
⑥ 模型加载与预测:
使用 tf.keras.models.load_model 加载保存的模型,生成新的测试数据进行预测,并计算预测准确率。
相关文章:

【机器学习】自定义数据集 使用tensorflow框架实现逻辑回归并保存模型,然后保存模型后再加载模型进行预测
一、使用tensorflow框架实现逻辑回归 1. 数据部分: 首先自定义了一个简单的数据集,特征 X 是 100 个随机样本,每个样本一个特征,目标值 y 基于线性关系并添加了噪声。tensorflow框架不需要numpy 数组转换为相应的张量࿰…...

.NET Core缓存
目录 缓存的概念 客户端响应缓存 cache-control 服务器端响应缓存 内存缓存(In-memory cache) 用法 GetOrCreateAsync 缓存过期时间策略 缓存的过期时间 解决方法: 两种过期时间策略: 绝对过期时间 滑动过期时间 两…...
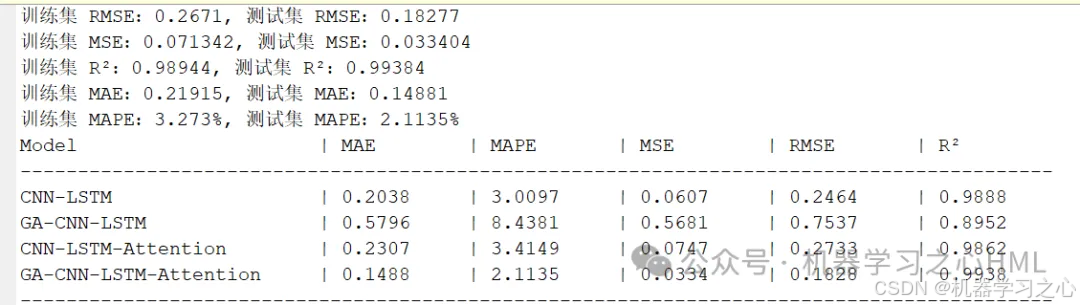
GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比
GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比 目录 GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比预测效果基本介绍程序设计参考资料 预测效果 基本介绍 基于GA-CNN-LST…...
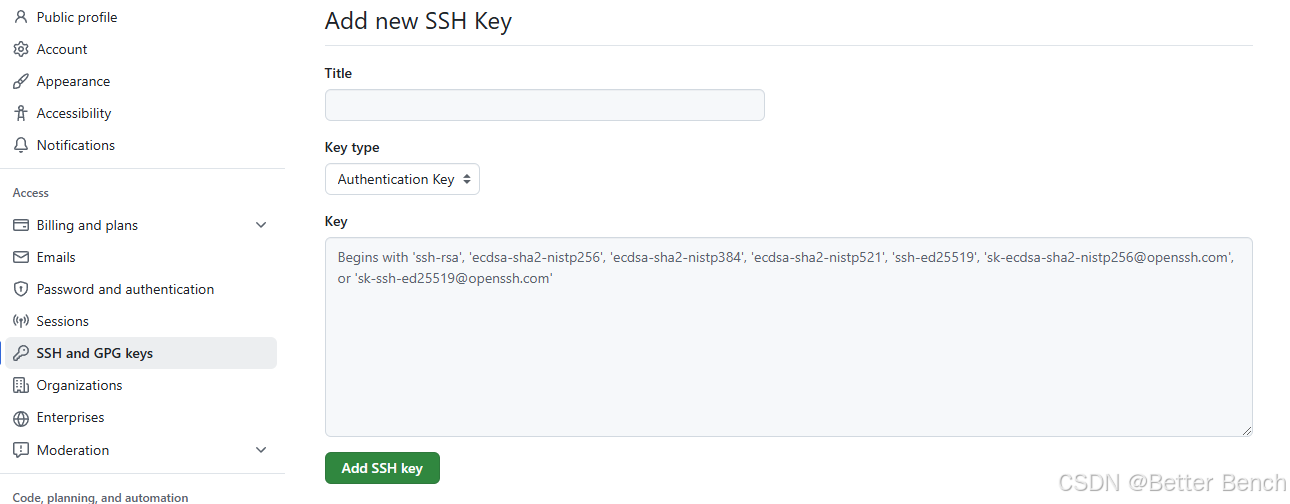
git Bash通过SSH key 登录github的详细步骤
1 问题 通过在windows 终端中的通过git登录github 不再是通过密码登录了,需要本地生成一个密钥,配置到gihub中才能使用 2 步骤 (1)首先配置用户名和邮箱 git config --global user.name "用户名"git config --global…...
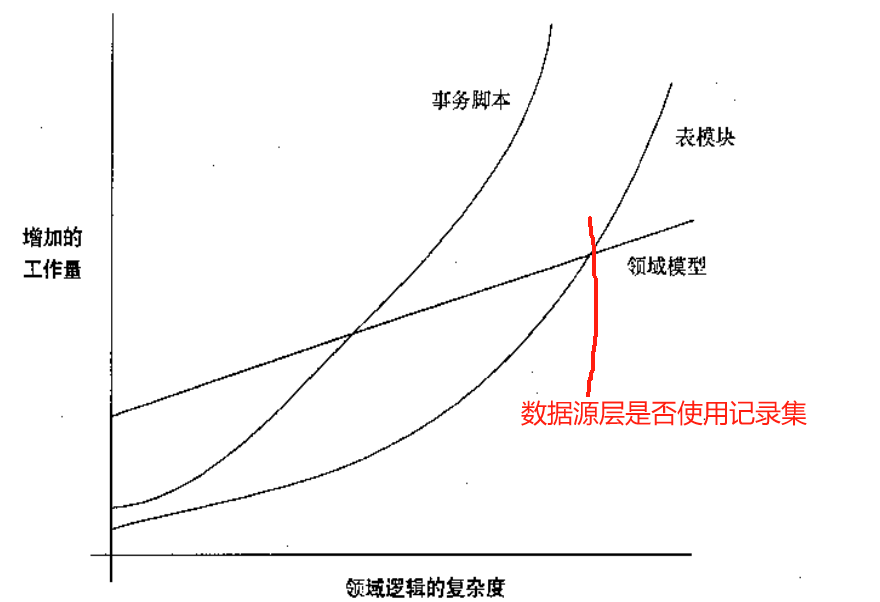
《企业应用架构模式》笔记
领域逻辑 表模块和数据集一起工作-> 先查询出一个记录集,再根据数据集生成一个(如合同)对象,然后调用合同对象的方法。 这看起来很想service查询出一个对象,但调用的是对象的方法,这看起来像是充血模型…...
 (void *)) _IO_funlockfile)
深入理解 C 语言函数指针的高级用法:(void (*) (void *)) _IO_funlockfile
深入理解 C 语言函数指针的高级用法 函数指针是 C 语言中极具威力的特性,广泛用于实现回调、动态函数调用以及灵活的程序设计。然而,复杂的函数指针声明常常让即使是有经验的开发者也感到困惑。本文将从函数指针的基本概念出发,逐步解析复杂…...

【JavaSE】图书管理系统
前言:为了巩固之前学习的java知识点,我们用之前学习的java知识点(方法,数组,类和对象,封装,继承,多态,抽象类,接口)来实现一个简单的图书管理系统…...

【C++数论】880. 索引处的解码字符串|2010
本文涉及知识点 数论:质数、最大公约数、菲蜀定理 LeetCode880. 索引处的解码字符串 给定一个编码字符串 s 。请你找出 解码字符串 并将其写入磁带。解码时,从编码字符串中 每次读取一个字符 ,并采取以下步骤: 如果所读的字符是…...

C++/stack_queue
目录 1.stack 1.1stack的介绍 1.2stack的使用 练习题: 1.3stack的模拟实现 2.queue的介绍和使用 2.1queue的介绍 2.2queue的使用 2.3queue的模拟实现 3.priority_queue的介绍和使用 3.1priority_queue的介绍 3.2priority_queue的使用 欢迎 1.stack 1.1stack…...

浅谈APP之历史股票通过echarts绘图
浅谈APP之历史股票通过echarts绘图 需求描述 今天我们需要做一个简单的历史股票收盘价格通过echarts进行绘图,效果如下: 业务实现 代码框架 代码框架如下: . 依赖包下载 我们通过网站下载自己需要的涉及的图标,勾选之后进…...

Ubuntu 20.04 x64下 编译安装ffmpeg
试验的ffmpeg版本 4.1.3 本文使用的config命令 ./configure --prefixhost --enable-shared --disable-static --disable-doc --enable-postproc --enable-gpl --enable-swscale --enable-nonfree --enable-libfdk-aac --enable-decoderh264 --enable-libx265 --enable-libx…...

【橘子Kibana】Kibana的分析能力Analytics简易分析
一、kibana是啥,能干嘛 我们经常会用es来实现一些关于检索,关于分析的业务。但是es本身并没有UI,我们只能通过调用api来完成一些能力。而kibana就是他的一个外置UI,你完全可以这么理解。 当我们进入kibana的主页的时候你可以看到这样的布局。…...

【STM32】-TTP223B触摸开关
前言 本文章旨在记录博主STM32的学习经验,我自身也在不断的学习当中,如果文章有写的不对的地方,欢迎各位大佬批评指正。 准备工作 今天这篇文章介绍的是触摸开关这一外围硬件。 ST-link调试器STM32最小系统板单路TTP223B触摸传感器模块LE…...

三星手机人脸识别解锁需要点击一下电源键,能够不用点击直接解锁吗
三星手机的人脸识别解锁功能默认需要滑动或点击屏幕来解锁。这是为了增强安全性,防止误解锁的情况。如果希望在检测到人脸后直接进入主界面,可以通过以下设置调整: 打开设置: 进入三星手机的【设置】应用。 进入生物识别和安全&a…...

Frida使用指南(三)- Frida-Native-Hook
1.Process、Module、Memory基础 1.Process Process 对象代表当前被Hook的进程,能获取进程的信息,枚举模块,枚举范围等 2.Module Module 对象代表一个加载到进程的模块(例如,在 Windows 上的 DLL,或在 Linux/Android 上的 .so 文件), 能查询模块的信息,如模块的基址、名…...

网络安全 | F5-Attack Signatures-Set详解
关注:CodingTechWork 创建和分配攻击签名集 可以通过两种方式创建攻击签名集:使用过滤器或手动选择要包含的签名。 基于过滤器的签名集仅基于在签名过滤器中定义的标准。基于过滤器的签名集的优点在于,可以专注于定义用户感兴趣的攻击签名…...

004 mybatis基础应用之全局配置文件
文章目录 配置内容properties标签typeAlias标签mappers标签 配置内容 SqlMapConfig.xml中配置的内容和顺序如下: properties(属性) settings(全局配置参数) typeAliases(类型别名) typeHandler…...

【岛屿个数——BFS / DFS,“外海”】
题目 推荐阅读 AcWing 4959. 岛屿个数(两种解法,通俗解释) - AcWing 1.岛屿个数 - 蓝桥云课 (lanqiao.cn) 代码 #include <bits/stdc.h> using namespace std; #define x first #define y second int dx4[4] {-1, 0, 1, 0}, dy4[4] …...

MySQL常用数据类型和表的操作
文章目录 (一)常用数据类型1.数值类2.字符串类型3.二进制类型4.日期类型 (二)表的操作1查看指定库中所有表2.创建表3.查看表结构和查看表的创建语句4.修改表5.删除表 (三)总代码 (一)常用数据类型 1.数值类 BIT([M]) 大小:bit M表示每个数的位数,取值范围为1~64,若…...

2025_1_27 C语言内存,递归,汉诺塔问题
1.c程序在内存中的布局 代码段(Code Segment) 位置:通常位于内存的最低地址。 用途:存储程序的可执行指令。 特点:只读,防止程序运行时被修改。数据段(Data Segment) 位置…...

Hermes Agent 连接 Taotoken 自定义供应商,完成环境变量配置
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 连接 Taotoken 自定义供应商,完成环境变量配置 基础教程类,指导用户在使用 Hermes Agent 时&…...

3D打印印章模具全攻略:从数字设计到硅胶翻模的实践指南
1. 项目概述:当3D打印遇上传统印章艺术我一直对融合数字制造与传统手工艺的项目特别着迷,最近花了不少时间折腾用3D打印模具来制作定制印章,整个过程就像在数字世界和物理世界之间架起了一座桥。简单来说,这个项目的核心思路是&am…...

Arm Neoverse CMN-700架构与寄存器配置详解
1. Arm Neoverse CMN-700架构概览在现代多核处理器设计中,如何高效实现缓存一致性一直是核心挑战。Arm Neoverse CMN-700(Coherent Mesh Network)作为第二代一致性网格网络IP,采用分布式架构解决了从16核到256核规模的数据一致性问…...

基于CircuitPython与ItsyBitsy M4打造可编程宏键盘:从硬件到代码全解析
1. 项目概述:打造你的专属输入利器 在键盘这个看似成熟的领域里,我们真的满足于厂商提供的“标准答案”吗?对于视频剪辑师、程序员、设计师或者硬核游戏玩家来说,一套固定的键位布局和功能,往往意味着效率的妥协。真正…...

ROFL-Player:终极免费英雄联盟回放播放器解决方案
ROFL-Player:终极免费英雄联盟回放播放器解决方案 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player ROFL-Player是一款专门为《…...

iOS 27 开放 AI 生态@ACP#小型化扩展黄金风口,IX8008全面超越 ASM2806,铸就嵌入式 AI 扩展核心
苹果 iOS 27 系统全面开放第三方 AI 模型自由切换,支持 Claude、Gemini、DeepSeek 等主流大模型深度接入,iPhone/iPad 成为全球最大 AI 流量入口。这一变革引爆小型 AI 扩展坞、嵌入式 AI 终端、便携存储扩展、迷你主机、车载 AI五大硬件新机遇。作为连接…...

源代码论文分享|图书管理系统!
这份「图书管理系统」源码和论文,适合你在最需要“有个靠谱参考”的时候打开。 不是那种只放一堆代码、让人自己猜怎么跑的资料,也不是标题写得很大、内容却很空的论文模板。它更像一份已经整理好的项目包:有源码、有论文,可以直…...

系统安装:安装Ubuntu 26.04 LTS
1. EFI以及UEFI,什么用途? https://baike.baidu.com/item/EFI/2025809 EFI(Extensible Firmware Interface,可扩展固件接口)是由英特尔公司开发的固件接口标准,用于替代传统BIOS以实现更高效的硬件初始化和…...

小红书内容采集神器:XHS-Downloader免费开源工具完全指南
小红书内容采集神器:XHS-Downloader免费开源工具完全指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...

从Crustocean/conch看轻量级工作流编排:DAG原理与Python实现
1. 项目概述:从“Crustocean/conch”看现代数据管道编排的演进最近在梳理团队的数据处理流程时,我又一次被那些错综复杂的脚本、定时任务和手动依赖检查搞得焦头烂额。这让我想起了几年前第一次接触“Crustocean/conch”这个项目时的情景。当时ÿ…...