Cypher入门
文章目录
- Cypher入门
- 创建数据
- 查询数据
- match
- optional match
- where
- 分页
- with
- 更新数据
- 删除数据
- 实例:好友推荐
Cypher入门
- Cypher是Neo4j的查询语言。
创建数据
- 在Neo4j中使用create命令创建节点、关系、属性数据。
create (n {name:$value}) return n //创建节点,节点的属性是name,n为该节点的变量,创建完成后返回该节点

create (n:$Tag {name:$value}) //创建节点,指定标签

create (n)-[r:knows{name:$value}]->(m) //创建n指向m的关系,并且指定关系类型为:KNOWS

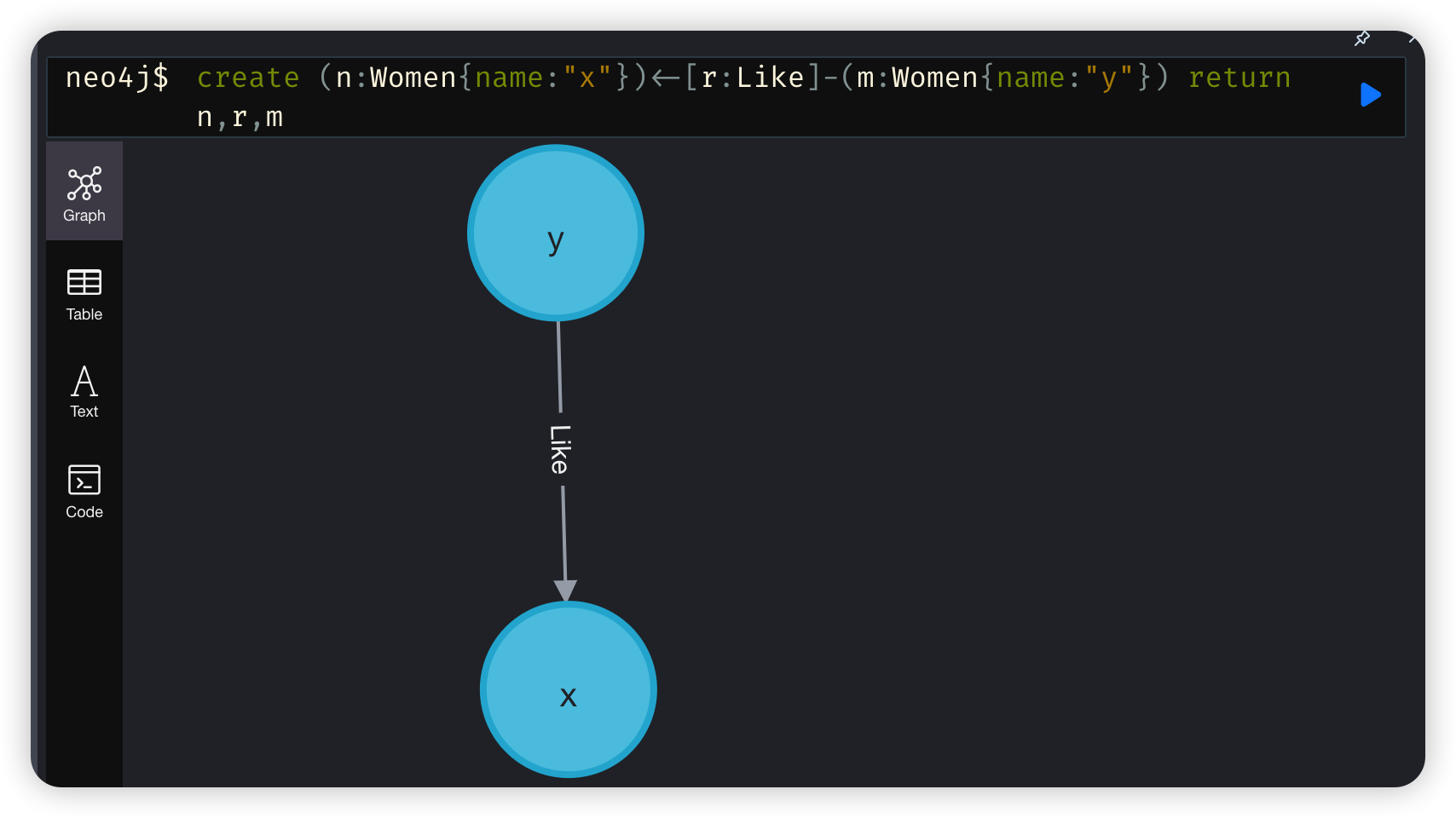

查询数据
match
[match where] //条件查询
[option match where] //选择查询,查询不到使用null代替
[with [order by] [skip] [limit]] //查询的结果以管道的方式传递给下面的语句,聚合查询必须使用with
return [order by] [skip] [limit] //返回、排序、跳过、返回个数
- MATCH 语句通过模式(Patter)来检家数据库。它常与带有约束或者断言的 WHERE语句一起使用,这使得匹配的模式更具体。断言是模式描述的一部分,不能看作是匹配结果的过滤器。
- MATCH 可以出现在查询的开始或者末尾,也可能位于 WITH 之后。如果它在语句开头,此时不会绑定任何数据。Neo4j将设计一个搜索去找到匹配这个语句以及 WHERE 中指定断言的结果。这将牵涉数据库的扫描,搜索特定标签的节点或者搜索一个索引以找到匹配模式的开始点,这个搜索找到的节点和关系可作为一个“绑定模式元素(Bound Patter Elements)”。它可以用于匹配一些子图的模式,也可以用于任何进一步的 MATCH 语句,
- Neo4j 将使用这些已知的元系来找到更进一步的未知元素。
- Cypher 是声明式的,因此查询本身不指定搜家的算法。Neo4i会自动地用最好的方法去找到开始节点和匹配模式。WHERE 中的断言可以在模式匹配之前、匹配中或者匹配后进行处理。这可以通过查询编译器来影响这个决定。
- 创建查询语句需要的数据
create (n:User {name:"张宇"}) create (n)-[:sing]->(:Song {title:"月亮惹的祸"}) create (n)-[:sing]->(:Song {title:"雨一直下"}) create (n)-[:sing]->(:Song {title:"大女人"}) create (n)-[:love]->(:User {name:"十一郎"}) - 查询所有节点
match (n) return n

- 查询所有User节点
match (n:User) return n

- 查询所有与“张宇”有关系的节点
match (n:User{name:"张宇"})--(m) return n,m

- 查询所有与张宇演唱的歌曲
match (n:User {name:"张宇"})-->(m:Song) return n,m

- 将查询赋值与变量
match p=(n:User {name:"张宇"})-->(m:Song) return p

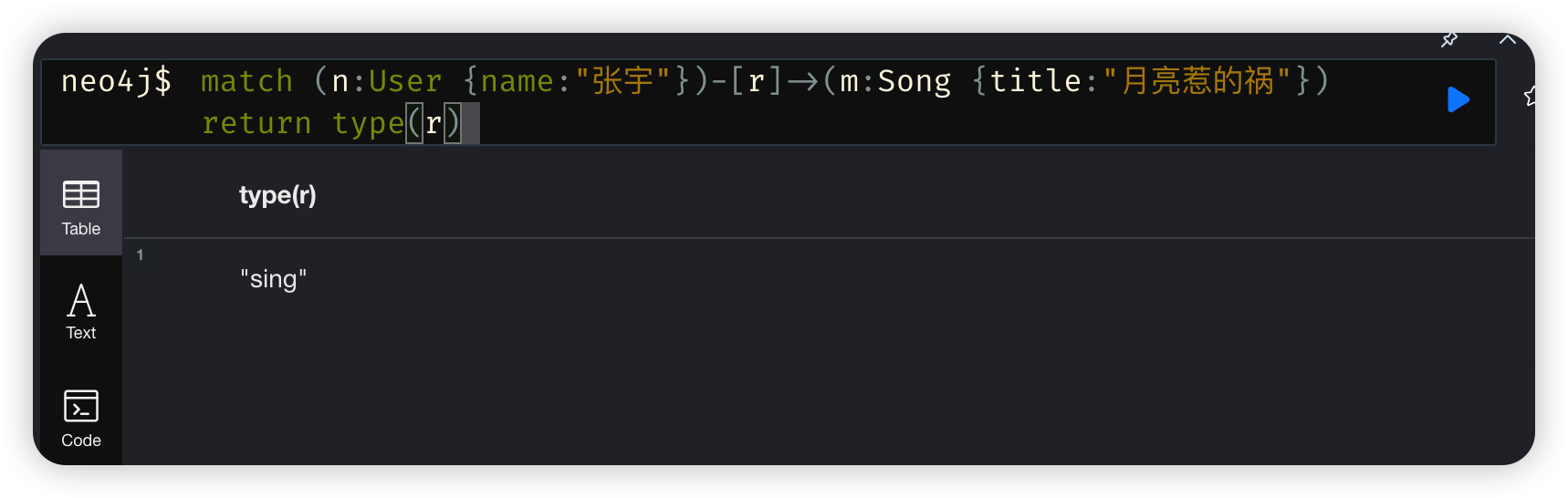
- 查询张宇与月亮惹的祸之间的关系
match (n:User {name:"张宇"})-[r]->(m:Song {title:"月亮惹的祸"}) return type(r)
- 指定关系标签查询
match (n:User {name:"张宇"})-[:sing]->(m) return n,m

- 指定多种关系标签查询
match(n:User {name:"张宇"})-[:sing|:love]-> (m) return n,m

- 在关系查询中指定关系的深度
-[:TYPE*minHops..maxHops]->//查询有1~2层关系的节点 match (n:Person {name:"Keanu Reeves"}) -[r:ACTED_IN*1..2]-(m) return n,m,r //查询有2层关系的节点 match (n:Person {name:"Keanu Reeves"}) -[r:ACTED_IN*2]-(m) return n,m,r


- 查询两个节点之间的深度为1~10的路径
match (n:Person {name:"Keanu Reeves"}),(m:Person {name:"Danny DeVito"}),p = shortestPath((n)-[*1..10]-(m)) return p

- 查询两个节点之间最短的路径
match (n:Person {name:"Keanu Reeves"}),(m:Person {name:"Danny DeVito"}),p = shortestPath((n)-[*]-(m)) return p

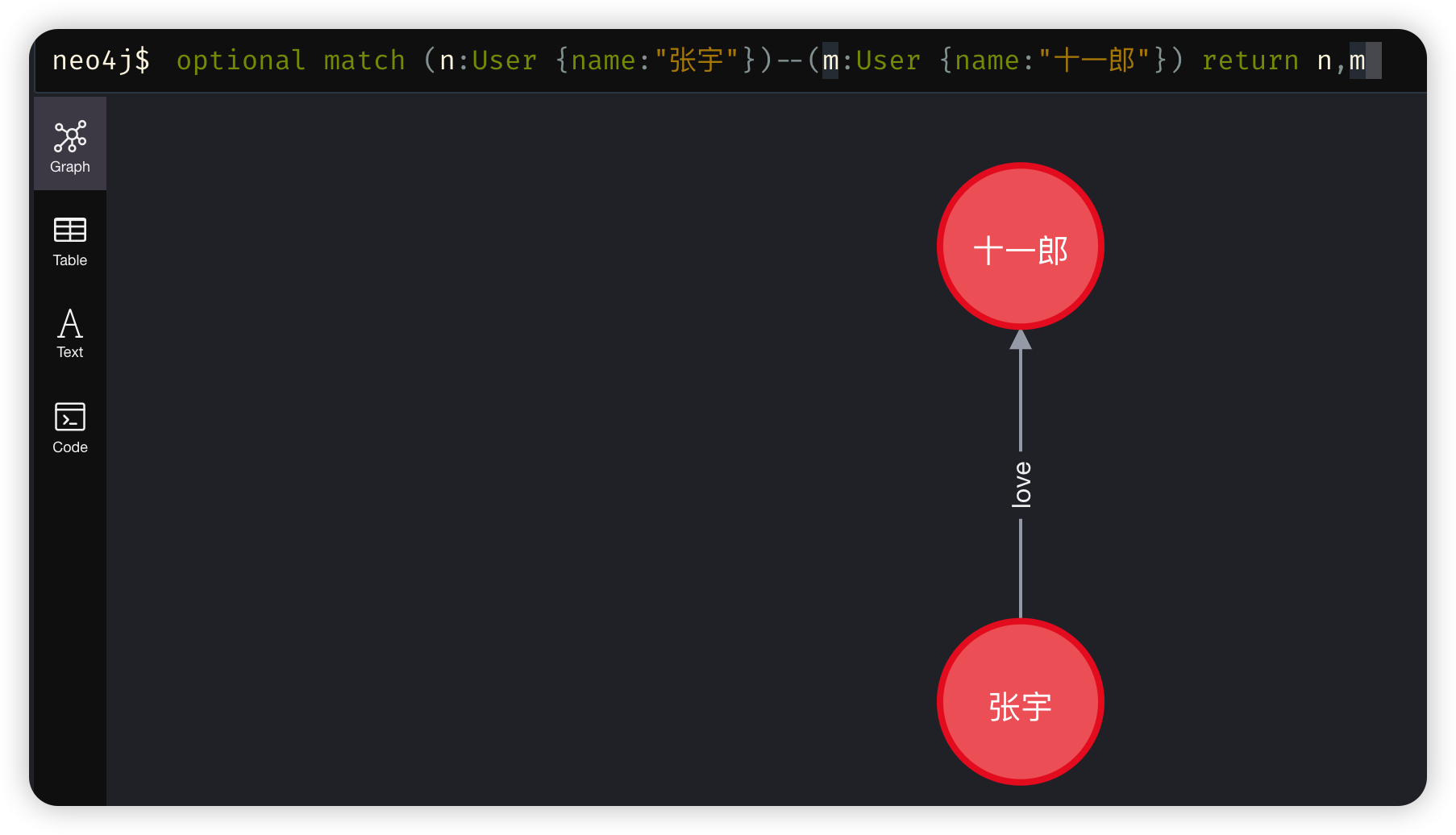
optional match
- OPTINAL MATCH 匹配模式,如果没有匹配到,OPTINAL MATCH 将用 null 作为未匹配到部分的值。OPTINAL MATCH 在 Cypher 中类似SQL 语句中的 outer join。要么匹配整个模式,要么都未匹配。
- WHERE 是模式描述的一部分,匹配的时候就会考虑到 WHERE 语句中的断言,而不是匹配之后。这对于有多个(OPTINAL)MATCH 语句的查询尤其重要,一定要将属于 MATCH 的 WHERE 语句与 MATCH 放在一起。
optional match (n:User {name:"张宇"})--(m:User {name:"十一郎"}) return n,m

where
- WHERE 在 MATCH 或者 OPTINAL MATCH 语句中添加约束,或者与 WITH 一起使用来过滤结果。
- WHERE 不能单独使用,它只能作为 MATCH、 OPTINAL MATCH、 START 和 WITH 的一部分。如果是在 WITH 和 START 中,它用于过滤结果。对于 MATCH 和 OPTINALMATCE, WHERE 为模式增加约束,它不能看作是匹配完成后的结果过滤。
- 设置属性条件
match (n:Song) where n.title='雨一直下' return n

- 设置布尔条件
match (n:Song) where n.title='雨一直下' or n.title='大女人' return n

- 关系属性过滤
match (n:Person) -[r:ACTED_IN]-> (m:Movie) where r.roles=['Neo'] return n,r,m

- 属性以xxx开头、包含xxx
match (n:Person) where n.name starts with 'K' return n

match (n:Person) where n.name contains 'un' return n

- 属性比较
match (n:Person) where n.born >1980 return n match (n:Person) where n.born>1970 and n.born >1990 return n


分页
- 在Neo4j中进行分页查询,可以使用SKIP和LIMIT子句
MATCH (p:Person) RETURN p.name ORDER BY p.name SKIP $skip LIMIT $limit - SKIP用于跳过指定的记录数,通常你根据页码计算这个值。例如,如果每页显示10条记录,第二页的skip值为10,第三页的skip值为20,以此类推。
- LIMIT用于限制查询结果的数量,即每页要显示的记录数。
match (n:Person) return n order by n.born desc skip 5 limit 10

match (n:Person) with n order by n.born desc limit 10 return n

with
- WITH 语句将分段的查询部分连接在一起,查询结果从一部分以管道形式传递给另外一部分作为开始点。
- 使用 WITH 可以在将结果传递到后续查询之前对结果进行操作。操作可以是改变结果的形式或者数量。WITH 的一个常见用法就是限制传递给其他 MATCH 语句的结果数。通过结合 ORDER BY 和 LIMIT,可获取排在前面的x个结果。
match (n:Person {name:"Keanu Reeves"}) --(m:Movie)
with m,n limit 3
match (m)--(k)
return k,m,n

更新数据
- 更新数据是使用set语句进行标签、属性更新。set操作是等幂性的。
match (n:User {name:"张宇"})
set n.age=40
return n

- 所有User节点年龄增加1
match (n:User) set n.age=n.age+1

- 通过set增加标签
match (n:User) set n:User2 return n

- 通过remove移除标签
match (n:User) remove n:User2 return n

match (n:User) remove n.age return n
- 没有age属性设置age=20
match (n:User) where n.age is null set n.age=20 return n

删除数据
- 删除数据通过delete、detach delete完成。其中delete不能删除有关系的节点,删除关系就需要detach delete
- 删除User标签下的所有数据
match (n:User) detach delete n - 删除单个节点 无法删除有关系的节点
match (n:User {name:"张宇"}) delete n - 删除节点和关系,只适用于少量数据
match (n:User {name:"张宇"}) detach delete n - 删除所有节点(谨慎使用)
match (n) detach delete n
实例:好友推荐
- 在社交网站中常常会有这样的功能,”你可能认识的人〞。图数据库是非常适合这样的场景的,接下来我们就尝试着使用Neo4j实现简化版的好友推荐。
CREATE (u1:User {name: "郭靖"})
CREATE (u2:User {name: "令狐冲"})
CREATE (u3:User {name: "岳不群"})
CREATE (u4:User {name: "左冷禅"})
CREATE (u5:User {name: "东方不败"})
CREATE (u6:User {name: "风清扬"})
CREATE (u7:User {name: "张无忌"})
CREATE (u8:User {name: "谢逊"})
CREATE (u9:User {name: "杨道"})
CREATE (u10:User {name: "乔峰"})CREATE
(u1)-[:FRIEND_OF]->(u2),
(u1)-[:FRIEND_OF]->(u3),
(u2)-[:FRIEND_OF]->(u4),
(u2)-[:FRIEND_OF]->(u5),
(u3)-[:FRIEND_OF]->(u6),
(u3)-[:FRIEND_OF]->(u7),
(u5)-[:FRIEND_OF]->(u8),
(u8)-[:FRIEND_OF]->(u9),
(u3)-[:FRIEND_OF]->(u10)

match (n:User) return n

- 查询郭靖好友
match (n:User {name:"郭靖"}) -[:FRIEND_OF]->(m) return *

- 查询郭靖好友关系为2~3层的用户
match (n:User {name:"郭靖"}) -[:FRIEND_OF*2..3]->(m) return m

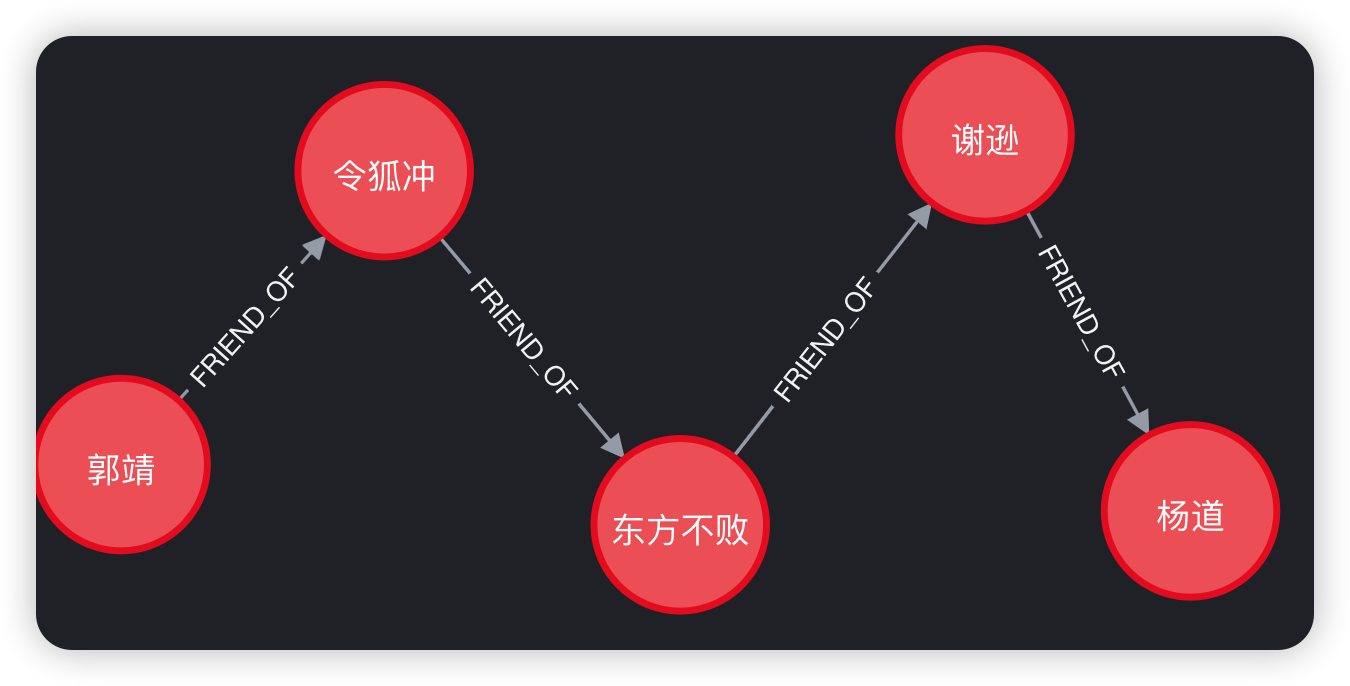
- 郭靖要想和杨道认识,最短的路径是什么?
match (u:User {name:"郭靖"}),(m:User {name:"杨道"}),
p=shortestPath((u)-[*]-(m))
return p
相关文章:
Cypher入门
文章目录 Cypher入门创建数据查询数据matchoptional matchwhere分页with 更新数据删除数据实例:好友推荐 Cypher入门 Cypher是Neo4j的查询语言。 创建数据 在Neo4j中使用create命令创建节点、关系、属性数据。 create (n {name:$value}) return n //创建节点&am…...

使用Z-score进行数据特征标准化
数据标准化是数据处理过程中非常重要的一步,尤其在构建机器学习模型时尤为关键。标准化的目的是将不同量纲的变量转换到相同的尺度,以避免由于量纲差异导致的模型偏差。Z-score标准化是一种常见且简单的标准化方法,它通过计算数据点与平均值的差异,并将其按标准差进行缩放,…...

初级数据结构:栈和队列
一、栈 (一)、栈的定义 栈是一种遵循后进先出(LIFO,Last In First Out)原则的数据结构。栈的主要操作包括入栈(Push)和出栈(Pop)。入栈操作是将元素添加到栈顶,这一过程中…...

【思维导图】java
学习计划:将目前已经学的知识点串成一个思维导图。在往后的学习过程中,不断往思维导图里补充,形成自己整个知识体系。对于思维导图里的每个技术知识,自己用简洁的话概括出来, 训练自己的表达能力。 面向对象三大特性 …...

Redis脑裂问题详解及解决方案
Redis是一种高性能的内存数据库,广泛应用于缓存、消息队列等场景。然而,在分布式Redis集群中,脑裂问题(Split-Brain)是一个需要特别关注的复杂问题。本文将详细介绍Redis脑裂问题的成因、影响及解决方案。 一、什么是…...

玩转大语言模型——配置图数据库Neo4j(含apoc插件)并导入GraphRAG生成的知识图谱
系列文章目录 玩转大语言模型——使用langchain和Ollama本地部署大语言模型 玩转大语言模型——ollama导入huggingface下载的模型 玩转大语言模型——langchain调用ollama视觉多模态语言模型 玩转大语言模型——使用GraphRAGOllama构建知识图谱 玩转大语言模型——完美解决Gra…...

【Windows Server实战】生产环境云和NPS快速搭建
前置条件 本文假定你已达成以下前提条件: 有域控DC。有证书服务器(AD CS)。已使用Microsoft Intune或者GPO为客户机申请证书。服务器上至少有两张网卡(如果用虚拟机做的测试环境,可以用一张HostOnly网卡做测试&#…...

[ESP32:Vscode+PlatformIO]新建工程 常用配置与设置
2025-1-29 一、新建工程 选择一个要创建工程文件夹的地方,在空白处鼠标右键选择通过Code打开 打开Vscode,点击platformIO图标,选择PIO Home下的open,最后点击new project 按照下图进行设置 第一个是工程文件夹的名称 第二个是…...

【NLP251】Transformer精讲 残差链接与层归一化
精讲部分,主要是对Transformer的深度理解方便日后从底层逻辑进行创新,对于仅应用需求的小伙伴可以跳过这一部分,不影响正常学习。 1. 残差模块 何凯明在2015年提出的残差网络(ResNet),Transformer在2016年…...

康德哲学与自组织思想的渊源:从《判断力批判》到系统论的桥梁
康德哲学与自组织思想的渊源:从《判断力批判》到系统论的桥梁 第一节:康德哲学中的自然目的论与自组织思想 核心内容: 康德哲学中的自然目的论和反思判断力概念,为现代系统论中的自组织思想提供了哲学基础,预见了复…...

SpringBoot 整合 SpringMVC:SpringMVC的注解管理
分类: 中央转发器(DispatcherServlet)控制器视图解析器静态资源访问消息转化器格式化静态资源管理 中央转发器: 中央转发器被 SpringBoot 自动接管,不需要我们在 web.xml 中配置: <servlet><servlet-name>chapter2&l…...

松灵机器人 scout ros2 驱动 安装
必须使用 ubuntu22 必须使用 链接的humble版本 #打开can 口 sudo modprobe gs_usbsudo ip link set can0 up type can bitrate 500000sudo ip link set can0 up type can bitrate 500000sudo apt install can-utilscandump can0mkdir -p ~/ros2_ws/srccd ~/ros2_ws/src git cl…...

使用 Numpy 自定义数据集,使用pytorch框架实现逻辑回归并保存模型,然后保存模型后再加载模型进行预测,对预测结果计算精确度和召回率及F1分数
1. 导入必要的库 首先,导入我们需要的库:Numpy、Pytorch 和相关工具包。 import numpy as np import torch import torch.nn as nn import torch.optim as optim from sklearn.metrics import accuracy_score, recall_score, f1_score2. 自定义数据集 …...

MapReduce简单应用(一)——WordCount
目录 1. 执行过程1.1 分割1.2 Map1.3 Combine1.4 Reduce 2. 代码和结果2.1 pom.xml中依赖配置2.2 工具类util2.3 WordCount2.4 结果 参考 1. 执行过程 假设WordCount的两个输入文本text1.txt和text2.txt如下。 Hello World Bye WorldHello Hadoop Bye Hadoop1.1 分割 将每个文…...

c语言(关键字)
前言: 感谢b站鹏哥c语言 内容: 栈区(存放局部变量) 堆区 静态区(存放静态变量) rigister关键字 寄存器,cpu优先从寄存器里边读取数据 #include <stdio.h>//typedef,类型…...

蓝桥杯思维训练营(一)
文章目录 题目总览题目详解翻之一起做很甜的梦 蓝桥杯的前几题用到的算法较少,大部分考察的都是思维能力,方法比较巧妙,所以我们要积累对应的题目,多训练 题目总览 翻之 一起做很甜的梦 题目详解 翻之 思维分析:一开…...

【C语言】结构体对齐规则
文章目录 一、内存对齐规则二、结构体的整体对齐: 一、内存对齐规则 1.第一个数据成员:结构体的第一个数据成员总是放置在其起始地址处,即偏移量为0的位置。 2.其他数据成员的对齐:每个后续成员的存储地址必须是其有效对齐值的整…...

2025-工具集合整理
科技趋势 github-rank 🕷️Github China/Global User Ranking, Global Warehouse Star Ranking (Github Action is automatically updated daily). 科技爱好者周刊 制图工具 D2 D2 A modern diagram scripting language that turns text to diagrams 文档帮助 …...

快速提升网站收录:利用网站用户反馈机制
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/59.html 利用网站用户反馈机制是快速提升网站收录的有效策略之一。以下是一些具体的实施步骤和建议: 一、建立用户反馈机制 多样化反馈渠道: 设立在线反馈表、邮件…...

图漾相机——Sample_V1示例程序
文章目录 1.SDK支持的平台类型1.1 Windows 平台1.2 Linux平台 2.SDK基本知识2.1 SDK目录结构2.2 设备组件简介2.3 设备组件属性2.4 设备的帧数据管理机制2.5 SDK中的坐标系变换 3.Sample_V1示例程序3.1 DeviceStorage3.2 DumpCalibInfo3.3 NetStatistic3.4 SimpleView_SaveLoad…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...
架构与实现)
基于RAG与向量数据库的智能信息管理系统(IIMS)架构与实现
1. 项目概述:当AI成为你的“第二大脑”最近在折腾一个挺有意思的项目,叫“IIMS-By-AI”。乍一看这个标题,可能有点摸不着头脑,但拆解一下就能明白它的野心:IntelligentInformationManagementSystem, By AI。…...

终极指南:如何用wxhelper实现PC微信自动化与消息管理
终极指南:如何用wxhelper实现PC微信自动化与消息管理 【免费下载链接】wxhelper Hook WeChat / 微信逆向 项目地址: https://gitcode.com/gh_mirrors/wx/wxhelper wxhelper是一款强大的PC端微信逆向工程工具,通过DLL注入技术为开发者提供完整的微…...

基于vLLM与OpenAI API的LLM生产部署框架实战指南
1. 项目概述:一个面向生产环境的LLM部署框架最近在折腾大语言模型(LLM)的部署,发现了一个挺有意思的项目:run-llama/llama_deploy。这名字乍一看,可能会让人以为它只是用来部署Meta的Llama系列模型的&#…...

赛车电气系统设计的现代化转型与实践
1. 赛车电气系统设计的现状与挑战当人们谈论赛车技术时,脑海中浮现的往往是碳纤维车身、空气动力学套件或是大马力发动机。但在这光鲜亮丽的表象背后,电气系统才是现代赛车的"神经系统"。有趣的是,这个关键领域的设计方法却呈现出两…...

Midjourney玩具相机风格从翻车到封神:1个--v 6.1专属参数组合+2个隐藏式胶片颗粒注入指令+1套曝光补偿校准表
更多请点击: https://intelliparadigm.com 第一章:Midjourney玩具相机风格的视觉本质与审美悖论 失真即真实:玩具相机的光学哲学 玩具相机(Toy Camera)风格在 Midjourney 中并非简单模拟 Lomography 或 Holga 的物理…...

面向科学计算Agent的Harness数值稳定性校验
面向科学计算Agent的Harness数值稳定性校验关键词:科学计算Agent、Harness框架、数值稳定性校验、数值误差溯源、Agent-数值系统交互、可复现科学、边界条件自动化测试摘要:随着大语言模型(LLM)与多模态AI的崛起,科学计…...

Promises/A+完全指南:深入理解JavaScript异步编程标准规范
Promises/A完全指南:深入理解JavaScript异步编程标准规范 【免费下载链接】promises-spec An open standard for sound, interoperable JavaScript promises—by implementers, for implementers. 项目地址: https://gitcode.com/gh_mirrors/pr/promises-spec …...

独立开发者如何利用TaotokenTokenPlan降低项目试错成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken TokenPlan降低项目试错成本 对于独立开发者或小型团队而言,启动一个涉及大模型能力的项目…...
)
从布列松决定性瞬间到AI生成:Midjourney黑白摄影风格构建方法论(附可复用的5层Prompt结构模板)
更多请点击: https://intelliparadigm.com 第一章:从布列松决定性瞬间到AI生成的范式迁移 亨利卡蒂埃-布列松提出的“决定性瞬间”强调在精确的时间、空间与形式三重统一中捕捉不可复制的真实。这一美学范式统治摄影近百年,其内核是人类对意…...