【优先算法】专题——前缀和
目录
一、【模版】前缀和
参考代码:
二、【模版】 二维前缀和
参考代码:
三、寻找数组的中心下标
参考代码:
四、除自身以外数组的乘积
参考代码:
五、和为K的子数组
参考代码:
六、和可被K整除的子数组
参考代码:
七、连续数组
参考代码:
八、矩阵区域和
参考代码:
总结
一、【模版】前缀和
【模版】前缀和
题目描述:

数组的元素是从标为1开始的,n是数组的个数,q是查询的次数,查询l到r这段区间的和。

解法一:暴力解法,直接查找l到r这段区间之和,但是效率太低,查询q次每次遍历一遍数组时间复杂度O(q*N)n和q的数据范围是1到10^5,暴力解法过不了。

解法二:前缀和,快速求出数组中某一个连续区间的和,时间复杂度O(q)+O(N)
第一步:预处理出来一个前缀和数组,我们要要求1到3的和我们用dp[i-1]+arr[i]就是1到3的和了。
dp[i]表示:表示[1,i]区间内所有元素的和。
dp[i] = dp[i-1] + arr[i]

第二步:使用前缀和数组
如下比如我们要查找l~r这段区间的和那么我们直接去dp数组取出下标为r的这个元素,此元素就是1~r的之和我们减去l-1得到的就是l~r这段区间之和。

这里还有一个问题就是为什么下标要从1开始计数:为了处理边界情况
初始化:添加虚拟结点(辅助结点)

参考代码:
#include <iostream>
#include <vector>
using namespace std;int main()
{//1.读入数据int n,q;cin>>n>>q;vector<int>arr(n+1);for(int i = 1;i<= n;i++) cin>>arr[i];//2.预处理出来一个前缀和数组vector<long long>dp(n+1); //防止溢出for(int i = 0;i<=n;i++) dp[i] = dp[i-1] + arr[i];//3.使用前缀和数组int l,r;while(q--){cin>>l>>r;cout<<dp[r] -dp[l-1]<<endl;}}时间复杂度:O(q)+O(n)
二、【模版】 二维前缀和
题目链接:二维前缀和
题目描述:

题目解析:
1.从第一行第一列开始到第二列,到二行二列。(如下)
2.从第一行第一列开始到第三列,到三行三列。
3.从第一行第二列开始到4列,到三行四列。

算法原理:
解法一:暴力解法,模拟,让我求哪段区间我就加到哪段区间,如下比如让我们全部求出来那就从头加到尾,时间复杂度高,这道题过不了因为时间复杂度为O(n*m*q)

解法二:前缀和
1.预处理出来一个前缀和矩阵
dp[i][j]表示:从[1,1]位置到[i,j]位置,这段区间里面所有元素和。
如下图我们把它抽象出来,这里我们分为四块面积分别为A、B、C、D,我们要求得dp[i][j]这段区间的和,我们A+B+C+D就等于dp[i][j],我们求B和C这段区间的和是不太好求的,所以我们这样求(A+B) + (A + C) + D - A这里减A是因为多算了一个A所以要减掉,A+B这段区间的值非常好求就是dp[i-1][j]这个位置,A+C就是dp[i][j-1]再加上D这个位置的值就是数组里面的arr[i][j]减去A也就是dp[i-1][j-1],这样就推出了我们预处理的公式。如下图:

2.使用前缀和矩阵
如下假如我们要求D这段区间的和那么我们又被分成了四个部分,竟然要求D这段区间的和我们就A+B+C+D求得结果之后我们先减去上面这部分就是A+B这部分因为A+B这部分可以直接算出了,也就是下图绿色小方块那个位置,在减去A+C这部分但是这样我们发现多减了一个A所以我们要加上一个A,D = A+B+C+D - (A+B)-(A+C)+A(通分之后就等于D),A+B+C+D其实就等于dp[x2][y2]然后减去A+B也就是dp[x1 - 1][y2]再减去A+C也就是dp[x2][y1-1]在加上A也就是dp[x1-1][y1-1],我们直接套用公式就能用O(1)的时间复杂度得出结果。

参考代码:
#include <iostream>
#include <vector>
using namespace std;int main()
{//1.读入数据int n = 0,m = 0,q = 0;cin>>n>>m>>q;vector<vector<long long>>arr(n+1,vector<long long>(m+1));for(int i = 1;i <=n;i++)for(int j = 1;j <=m ;j++)cin>>arr[i][j];//2.预处理前缀和矩阵vector<vector<long long>>dp(n+1,vector<long long>(m+1));//防止溢出for(int i = 1; i<=n; i++)for(int j = 1; j<=m ;j++)dp[i][j] = dp[i-1][j] + dp[i][j-1] + arr[i][j] - dp[i-1][j-1];//3.使用前缀和矩阵int x1=0,y1=0,x2=0,y2=0;while(q--){cin>> x1 >> y1 >> x2 >>y2;cout<<dp[x2][y2] - dp[x1-1][y2] - dp[x2][y1-1] + dp[x1-1][y1-1]<<endl;}return 0;}时间复杂为:O(n*m) + O(q)
三、寻找数组的中心下标
题目链接:寻找数组的中心下标
题目描述:

题目解析:
如下图两边都等于11那么就返回6的下标,如果全是0那么就返回最左边的下标也就是0因为有多个中心下标,不存在则返回-1

解法一:暴力解法,枚举中心下标左边相加的值是否等于右边相加的值,每次枚举一次中心下标都要左边相加右边相加,枚举下标时间复杂O(N),求和依旧使用O(N)的时间复杂度,最终时间复杂度O(N^2)。
解法二:前缀和
我们利用前缀和的思想来实现,竟然要求某一段区间的和那么前缀和预处理出来的那个数组不就可以,我们还要求后面那一段区间的和我们把前缀和改一下改成后缀和就可以了。
我们用f来表示前缀和数组:f[i]表示:[0,i-1]区间,所有元素的和。
f [i] = f [i-1] + nums[i-1]
g:后缀和数组:g[i]表示:[i+1,n-1]区间,所有元素的和
g [i] = g [i+1] + nums[i+1]

最后进行判断,枚举所有的中心下标从0~n-1然后判断f[i] == g[i],如果有很多中心下标要返回最左边的,所以我们枚举所有的中心下标i,然后判断f[i] == g[i],因为f[i]表示的就是左边所有元素的和g[i]保存的就是右边所有元素的和,判断是否相等如果相等返回i不相等继续往后面找,找到最后一个位置依旧没找到就返回-1
细节问题:
当我们的f等于0的时候我们代入上面发现会越界访问,0~-1这里没有元素所以f(0)= 0
当g等于n-1的时候我们代入上面也会发生越界访问,n-1的右边是没有任何元素的所以g(0) = 0
填写元素顺序,f表是正着填的从左到右,g表是倒着填的从右到左
参考代码:
class Solution {
public:int pivotIndex(vector<int>& nums) {int n = nums.size();vector<int>f(n),g(n);//1.预处理前缀和数组以及后缀和数组for(int i = 1;i<n;i++)f[i] = f[i-1] + nums[i-1];for(int j = n-2;j>= 0;j--)g[j] = g[j + 1] + nums[j+1];//2.使用for(int i = 0;i<n;i++){if(f[i] == g[i])return i;}return -1;}
};时间复杂度:O(N)
四、除自身以外数组的乘积
题目链接:除自身以外数组的乘积
题目描述:

举个例子:
除1以为2*3*4等于24,除2以外1*3*4等于12,除3以为1*2*4等于8,除4以为1*2*3等于6,题目已经提示我们了使用前缀和 后缀和。

解法一:暴力解法
暴力解法其实和我们上面举的例子一样,比如我们要求除第一个位置以外的值我们就从头遍历尾,要求第二个位置就从第一个开始遍历跳过我们自己然后依次遍历,以此类推。
但是时间复杂度太高了,O(N^2)

解法二:前缀积
本题的思路和上题的思路一样,但是有些细节有变化。
1.预处理前缀积以及后缀积

我们不需要i位置的元素,只要0~i-1位置的元素即可。表示如下:
f:表示前缀积:f [0,i -1 ] 区间内所有元素的乘积
我们要求i-1位置的乘积的时候我们知道i-2位置的乘积让它乘以i-1位置的值就可以了
f[i] = f [i-1] * nums[i-1]
注意:我们上面的f [i-1 ]位置是上图i-2的位置,因为我们f[i]表示的是i-1位置。
我们知道了i+2位置的乘积之后用它乘以i+1位置的值即可。
g:表示后缀积:g[i]表示:[i+1,n-1]
g[i] = g[i+1] * nums[i+1]
2.使用
我们在i这个位置填写数据的时候我们用f[i] * g[i]因为f[i]表示左边的乘积g表示右边的乘积
3.细节问题
当我们i等于0的时候,其实会越界访问所以我们需要处理,那么我们f(0)给什么值合适上面那道题我们给的是0,这道题我们不能给0因为0*nums[i-1]还是0,那么会影响我们的结果所以我们要给1,f(0) = 1,g(n-1) = 1
参考代码:
class Solution {
public:vector<int> productExceptSelf(vector<int>& nums) {int n = nums.size();vector<int>f(n,1),g(n,1);vector<int> answer(n);//1.预处理前缀积 后缀积for(int i = 1;i<n;i++)f[i] = f[i-1] * nums[i-1];for(int i = n-2;i>=0;i--)g[i] = g[i+1] * nums[i+1];//2.使用for(int i = 0;i<n;i++){answer[i] = f[i] * g[i];}return answer;}
};时间复杂度:O(N)
五、和为K的子数组
题目链接:560. 和为 K 的子数组 - 力扣(LeetCode)
题目描述:

前缀和+哈希表

以i位置为结尾的所有的子数组在[0,i-1]区间内,有多少个前缀和等于sum[i] - k就有多少个和为k的子数组,哈希表中分别存储前缀和、次数。
细节问题:
1.在计算i位置之前,哈希表里面只保存[0,i-1]位置的前缀和
2.不用真的创建一个前缀和数组,用一个变量sum来标记前一个位置的前缀和即可
3.如果整个前缀和等于k那么我们需要提前把hash[0] = 1。<0,1>
注意:不能使用滑动窗口来做优化(双指针)因为有0和负数,如下图这种情况我们left不断向右移动,那么有可能中间还有子数组和为 k

参考代码:
class Solution {
public:int subarraySum(vector<int>& nums, int k) {unordered_map<int,int>hash;int sum = 0,ret = 0;hash[0] = 1;for(auto x : nums){sum += x;if(hash.count(sum - k)) ret += hash[sum - k];hash[sum]++;}return ret;}
};时间复杂度为 O(n),空间复杂度也为 O(n)
六、和可被K整除的子数组
题目链接:和可被K整除的子数组
题目描述:

补充知识:
1.同余定理:
(a - b) / p = k.....0 => a % p = b % p
举个例子:(26-12) / 7 => 26 % 7 = 12 % 7
7 % 2 = 1 -> 7 - 2 = 5 - 2 =3 -2 = 1
取余数的本质就是你这个数有多少个2的倍数就把2的倍数干掉,减到这个数比2小
(1+2 * 3) % 2 = 1(相当于有3个2的倍数,得出等式:(a + p * k) % p = a % p
证明:
(a- b) / p = k
a - b = p * k
a = b + p * k(左右相等,那么左右%p也相等)
a %p = (b + p * k) % p = b % p(p * k有k个p可以直接干掉)
2.C++,java:[负数 % 正数]的结果以及修正
负 % 正 = 负 修正 a % p + p 正负统一(a %p +p) % p(如果a为正数那么就多加了一个p所以再模一个p结果是不变的,如果是负数加上一个p刚好就是正确答案)
我们使用前缀和 + 哈希表
在[0,i-1]区间内,找到有多少个前缀和的余数等于(sun % k + k) % k,哈希表分别存储前缀和的余数、次数

大部分逻辑和上题差不多
参考代码:
class Solution {
public:int subarraysDivByK(vector<int>& nums, int k) {unordered_map<int,int>hash;hash[0] = 1;//0这个数的余数int sum = 0,ret = 0;for(auto x : nums){sum += x;//算出当前位置的前缀和int r = (sum % k + k) % k;//修正后的余数if(hash.count(r)) ret +=hash[r%k];//统计结果hash[r]++;}return ret;}
};时间复杂度为 O(n),空间复杂度也为 O(n)
七、连续数组
题目链接:连续数组
题目描述:

我们把问题转化一下:
1.将所有的0修改为-1
2.在数组中,找出最长的子数组,使子数组中所有的元素和为0
和为k的子数组 ->和为0的子数组
前缀和 + 哈希表
1.哈希表中分别存储前缀和、下标
2.使用完之后,丢进哈希表
3.如果有重复的<sum,i>只保留前面的那一对<sum,i>
4.默认的前缀和为0的情况hash[0] = -1,当我们的这段区间和为sum的时候我们要去0的前面也就是-1的位置找和为0的子区间(存的下标)

5.长度计算i - j + 1 - 1 => i - j

参考代码:
class Solution {
public:int findMaxLength(vector<int>& nums) {unordered_map<int,int> hash;hash[0] = -1; //默认有一个前缀和为0的情况int sum = 0,ret = 0;for(int i = 0 ; i<nums.size();i++){sum += nums[i] == 0 ? -1 : 1;if(hash.count(sum)) ret = max(ret,i - hash[sum]);else hash[sum] = i;}return ret;}
};八、矩阵区域和
题目链接:矩阵区域和
题目描述:

题目要求:以5为中心分别像上左下右分别扩展k个单位,围城一个长方形的所有元素的和,这是假设k = 1,那么扩展一个单位。
假设求1这个位置,上左下右分别扩展1个单位,然后围成一个正方形,最后相加即可。1+2+4+5

求2这个位置,上左下右分别扩展1个单位然后围成正方形,相加即可,超出矩阵的范围不需要。1+2+3+4+5+6
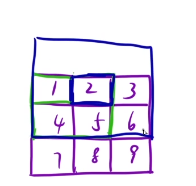
求5这个位置,上左下右分别扩展1个单位然后围成正方形,相加即可。1+2+3+4+5+6+7+8+9

解法:使用二维前缀和
dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + mat[i][j]
因为多加了一个dp[i-1][j-1]所以再减去一个dp[i-1][j-1]。
如上就是初始化前缀和矩阵的递推公式,直接代入公式即可。

answer= dp[x2][y2] - dp[x1-1][y2] - dp[x2][y1-1] + dp[x1-1][y1-1]
这里加dp[x1-1][y1-1]是因为多减了一个dp[x1-1][y1-1]所以要加上

1.我们要求ans[i][j]位置
我们(i-k,j-k)用(x1,y2)表示
因为这个区间可能会越界,也就是说是(0,0)这个位置的时候我们不能越过,所以我们求一个最大值,如果小于0那么取最大值还是0如果大于0那么就是一个合法的区间。
x1 = max(0,i-k)
y1 = max(0,j-k)
我们(i+k,j+k)用(x2,y2)表示
我们的i+k,j+k可能会超过我们的(m-1,n-1)所以我们需要让它回到我们的m-1,n-1
x2 = min(m-1,i+k)
y2 = min(n-1,j+k)

2.映射位置
当我们dp数组要填1,1这个位置的值我们要去mat数组0,0这个位置找。dp(x,y) -> mat(x-1,y-1)。
所以我们需要把dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + mat[i][j]改为dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + mat[i-1][j-1]

我们在填ans数据的时候使用dp数组需要+1因为ans(0,0)对应dp(1,1)位置。(x,y) -> (x+1,y+1)。
这里有两种方式:
方法一:
answer[i][j] = dp[x2+1][y2+1] - dp[x1-1+1][y2+1]-dp[x2+1][y1-1+1] +dp [x1-1+1][y1-1+1];
方法二:我们在求下标那里进行+1即可,然后直接在dp数组拿值即可
x1 = max(0,i-k)+1
y1 = max(0,j-k)+1
x2 = min(m-1,i+k)+1
y2 = min(n-1,j+k) +1
参考代码:
class Solution {
public:vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k) {int m = mat.size(),n = mat[0].size();//1.预处理前缀和矩阵vector<vector<int>> dp(m+1,vector<int>(n+1));for(int i = 1;i <= m;i++)for(int j = 1;j<=n;j++)dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + mat[i-1][j-1];//2.使用vector<vector<int>> answer(m,vector<int>(n));for(int i = 0;i < m;i++){for(int j = 0;j<n;j++){int x1 = max(0,i-k) + 1,y1 = max(0,j-k)+1;int x2 = min(m-1,i+k) + 1,y2 = min(n-1,j+k)+1;answer[i][j] = dp[x2][y2] - dp[x1-1][y2]-dp[x2][y1-1] +dp [x1-1][y1-1];}}return answer;}
};总结
前缀和这个算法,重要思想就是预处理,当我们在解决一个问题的时候不太好解决的时候我们可以先预处理一下,预处理之后在解决效率是非常高的,直接解决时间复杂度是N^2级别,预处理一下直接变O(N),这种就是典型的用空间换时间,因为我们多创建了一个数组,但是时间复杂度提高了一个级别。
相关文章:
【优先算法】专题——前缀和
目录 一、【模版】前缀和 参考代码: 二、【模版】 二维前缀和 参考代码: 三、寻找数组的中心下标 参考代码: 四、除自身以外数组的乘积 参考代码: 五、和为K的子数组 参考代码: 六、和可被K整除的子数组 参…...

gitea - fatal: Authentication failed
文章目录 gitea - fatal: Authentication failed概述run_gitea_on_my_pkm.bat 笔记删除windows凭证管理器中对应的url认证凭证启动gitea服务端的命令行正常用 TortoiseGit 提交代码备注END gitea - fatal: Authentication failed 概述 本地的git归档服务端使用gitea. 原来的用…...

基于Spring Security 6的OAuth2 系列之八 - 授权服务器--Spring Authrization Server的基本原理
之所以想写这一系列,是因为之前工作过程中使用Spring Security OAuth2搭建了网关和授权服务器,但当时基于spring-boot 2.3.x,其默认的Spring Security是5.3.x。之后新项目升级到了spring-boot 3.3.0,结果一看Spring Security也升级…...

蓝桥与力扣刷题(234 回文链表)
题目:给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。 示例 1: 输入:head [1,2,2,1] 输出:true示例 2: 输入&…...

Google C++ Style / 谷歌C++开源风格
文章目录 前言1. 头文件1.1 自给自足的头文件1.2 #define 防护符1.3 导入你的依赖1.4 前向声明1.5 内联函数1.6 #include 的路径及顺序 2. 作用域2.1 命名空间2.2 内部链接2.3 非成员函数、静态成员函数和全局函数2.4 局部变量2.5 静态和全局变量2.6 thread_local 变量 3. 类3.…...
-QT-C/C++ - QT Tab Widget)
Windows图形界面(GUI)-QT-C/C++ - QT Tab Widget
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 一、概述 1.1 什么是 QTabWidget? 1.2 使用场景 二、常见样式 2.1 选项卡式界面 2.2 动态添加和删除选项卡 2.3 自定义选项卡标题和图标 三、属性设置 3.1 添加页面&…...

【大数据技术】教程05:本机DataGrip远程连接虚拟机MySQL/Hive
本机DataGrip远程连接虚拟机MySQL/Hive datagrip-2024.3.4VMware Workstation Pro 16CentOS-Stream-10-latest-x86_64-dvd1.iso写在前面 本文主要介绍如何使用本机的DataGrip连接虚拟机的MySQL数据库和Hive数据库,提高编程效率。 安装DataGrip 请按照以下步骤安装DataGrip软…...

C++:结构体和类
在之前的博客中已经讲过了C语言中的结构体概念了,重复的内容在这儿就不赘述了。C中的结构体在C语言的基础上还有些补充,在这里说明一下,顺便简单地讲一下类的概念。 一、成员函数 结构体类型声明的关键字是 struct ,在C中结构体…...

MATLAB的数据类型和各类数据类型转化示例
一、MATLAB的数据类型 在MATLAB中 ,数据类型是非常重要的概念,因为它们决定了如何存储和操作数据。MATLAB支持数值型、字符型、字符串型、逻辑型、结构体、单元数组、数组和矩阵等多种数据类型。MATLAB 是一种动态类型语言,这意味着变量的数…...

UE求职Demo开发日志#19 给物品找图标,实现装备增加属性,背包栏UI显示装备
1 将用到的图标找好,放一起 DataTable里对应好图标 测试一下能正确获取: 2 装备增强属性思路 给FMyItemInfo添加一个枚举变量记录类型(物品,道具,装备,饰品,武器)--> 扩展DataT…...

C++泛型编程指南09 类模板实现和使用友元
文章目录 第2章 类模板 Stack 的实现2.1 类模板 Stack 的实现 (Implementation of Class Template Stack)2.1.1 声明类模板 (Declaration of Class Templates)2.1.2 成员函数实现 (Implementation of Member Functions) 2.2 使用类模板 Stack脚注改进后的叙述总结脚注2.3 类模板…...

使用MATLAB进行雷达数据采集可视化
本文使用轮趣科技N10雷达,需要源码可在后台私信或者资源自取 1. 项目概述 本项目旨在通过 MATLAB 读取 N10 激光雷达 的数据,并进行 实时 3D 点云可视化。数据通过 串口 传输,并经过解析后转换为 三维坐标点,最终使用 pcplayer 进…...

【Elasticsearch】allow_no_indices
- **allow_no_indices 参数的作用**: 该参数用于控制当请求的目标索引(通过通配符、别名或 _all 指定)不存在或已关闭时,Elasticsearch 的行为。 - **默认行为**: 如果未显式设置该参数,默认值为 …...

54【ip+端口+根目录通信】
上节课讲到,根目录起到定位作用,比如我们搭建一个php网站后,注册系统是由根目录的register.php文件执行,那么我们给这个根目录绑定域名https://127.0.0.1,当我们浏览器访问https://127.0.0.1/register.php时࿰…...

python算法和数据结构刷题[3]:哈希表、滑动窗口、双指针、回溯算法、贪心算法
回溯算法 「所有可能的结果」,而不是「结果的个数」,一般情况下,我们就知道需要暴力搜索所有的可行解了,可以用「回溯法」。 回溯算法关键在于:不合适就退回上一步。在回溯算法中,递归用于深入到所有可能的分支&…...

DeepSeek横空出世,AI格局或将改写?
引言 这几天,国产AI大模型DeepSeek R1,一飞冲天,在全球AI圈持续引爆热度,DeepSeek R1 已经是世界上最先进的 AI 模型之一,可与 OpenAI 的新 o1 和 Meta 的 Llama AI 模型相媲美。 DeepSeek-V3模型发布后,在…...

聚簇索引、哈希索引、覆盖索引、索引分类、最左前缀原则、判断索引使用情况、索引失效条件、优化查询性能
聚簇索引 聚簇索引像一本按目录排版的书,用空间换时间,适合读多写少的场景。设计数据库时,主键的选择(如自增ID vs 随机UUID)会直接影响聚簇索引的性能。 什么是聚簇索引? 数据即索引:聚簇索引…...

OpenAI 实战进阶教程 - 第四节: 结合 Web 服务:构建 Flask API 网关
目标 学习将 OpenAI 接入 Web 应用,构建交互式 API 网关理解 Flask 框架的基本用法实现 GPT 模型的 API 集成并返回结果 内容与实操 一、环境准备 安装必要依赖: 打开终端或命令行,执行以下命令安装 Flask 和 OpenAI SDK: pip i…...

python的pre-commit库的使用
在软件开发过程中,保持代码的一致性和高质量是非常重要的。pre-commit 是一个强大的工具,它可以帮助我们在提交代码到版本控制系统(如 Git)之前自动运行一系列的代码检查和格式化操作。通过这种方式,我们可以确保每次提…...

架构技能(四):需求分析
需求分析,即分析需求,分析软件用户需要解决的问题。 需求分析的下一环节是软件的整体架构设计,需求是输入,架构是输出,需求决定了架构。 决定架构的是软件的所有需求吗?肯定不是,真正决定架构…...

新手入门指南:基于快马平台构建vmware17交互式安装教学应用
新手入门指南:基于快马平台构建VMware17交互式安装教学应用 作为一个刚接触虚拟化技术的新手,第一次安装VMware Workstation 17时可能会遇到不少困惑。从下载安装包到最终配置完成,整个过程涉及多个步骤,每个环节都可能出现各种问…...

抑制素A抗体如何提升妊娠中期唐氏综合征筛查的效能?
一、为何抑制素A成为妊娠期的重要生物标志物?抑制素A是一种由α和βA亚基通过二硫键连接形成的异源二聚体糖蛋白。在非妊娠期,它主要由卵巢颗粒细胞分泌,作为反馈调节因子,选择性地抑制垂体前叶分泌卵泡刺激素。进入妊娠状态后&am…...

AI Token Platform - AI Token 中转计费平台
AI Token Platform - AI Token 中转计费平台 AI Token Platform 是一款企业级 AI Token 中转与计费平台,深度融合 多模型 AI 网关、Kill Bill 计费引擎 与 企业级会员管理 三大核心能力。平台以"统一 API 接入 灵活计费策略 企业级会员体系"为核心理念…...

PyTorch 2.8镜像真实效果:物理实验→电磁场/流体力学可视化视频
PyTorch 2.8镜像真实效果:物理实验→电磁场/流体力学可视化视频 1. 开箱即用的专业级物理模拟环境 当你第一次启动这个基于RTX 4090D优化的PyTorch 2.8镜像时,最直接的感受就是"专业工具就该这样"。这个镜像不是普通的深度学习环境ÿ…...
)
SiameseAOE中文-base高性能部署:WebUI响应<800ms,吞吐达12QPS(RTX4090)
SiameseAOE中文-base高性能部署:WebUI响应<800ms,吞吐达12QPS(RTX4090) 今天要跟大家聊一个非常实用的工具——SiameseAOE通用属性观点抽取模型。你可能听说过信息抽取,但面对海量文本,如何快速、准确地…...
Pixel Aurora Engine真实案例:用‘蒸汽朋克猫武士’生成整套游戏美术资源
Pixel Aurora Engine真实案例:用蒸汽朋克猫武士生成整套游戏美术资源 1. 项目背景与工具介绍 Pixel Aurora Engine(像素极光引擎)是一款基于AI扩散模型的高端像素艺术生成工具。它采用复古的8-bit游戏机风格界面,却能产出专业级…...

杨立昆新模型杀疯了,1500万参数单GPU就能碾压大厂?
就在前几天,AI教父、图灵奖得主杨立昆刚发了个新模型,名叫LeWorldModel,论文一发出,整个圈子瞬间炸锅。说出来你们可能都不信——这货只有1500万参数,单块GPU几个小时就能训完,随便一个研究者都拉起来跑一遍…...

代码重构的艺术:在业务狂奔中如何优雅地还技术债
业务压力下的质量困局在快节奏的软件开发世界中,业务需求如同永不停歇的浪潮,推动着团队高速前行。为了抢占市场先机、快速响应变化,“先上线,再优化”几乎成了许多项目的默认模式。然而,这种模式背后,是以…...
)
告别默认样式:C# WinForm自定义最大化最小化关闭按钮实战(含资源文件管理技巧)
深度定制WinForm界面:从按钮替换到资源管理的完整解决方案 1. 为什么需要自定义窗体控制按钮? 在商业软件和创意应用中,用户界面的视觉体验往往决定了用户对产品的第一印象。WinForm作为.NET生态中成熟的桌面应用框架,其默认的窗体…...

OpenTiny NEXT 前端智能化系列直播征文开启,带你系统学习 AI 前端与 WebAgent
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...