快速搭建GPU环境 | docker、k8s中使用gpu
目录
- 一、裸机部署
- 安装 GPU Driver
- 安装 CUDA Toolkit
- 测试
- 二、Docker 环境
- 安装 nvidia-container-toolkit
- 配置使用该 runtime
- 三、 k8s 环境
- 安装 device-plugin
- 安装 GPU 监控
一、裸机部署
裸机中要使用上 GPU 需要安装以下组件:
- GPU Driver
- CUDA Toolkit
二者的关系如 NVIDIA 官网上的这个图所示:

GPU Driver 包括了 GPU 驱动和 CUDA 驱动,CUDA Toolkit 则包含了 CUDA Runtime。
GPU 作为一个 PCIE 设备,只要安装好之后,在系统中就可以通过 lspci 命令查看到,先确认机器上是否有 GPU:
lspci|grep NVIDIA

可以看到,该设备有1张 Tesla V100 GPU。
安装 GPU Driver
首先到 NVIDIA 驱动下载 下载对应的显卡驱动:


复制下载链接
wget https://cn.download.nvidia.com/tesla/550.144.03/nvidia-driver-local-repo-ubuntu2204-550.144.03_1.0-1_amd64.deb
sudo apt update && sudo apt upgrade -y
sudo apt install -y build-essential dkms
sudo dpkg -i nvidia-driver-local-repo-ubuntu2204-550.144.03_1.0-1_amd64.deb
安装 NVIDIA 驱动:
sudo apt install -y nvidia-driver-550
nvidia-smi

至此,我们就安装好 GPU 驱动了,系统也能正常识别到 GPU。
这里显示的 CUDA 版本表示当前驱动最大支持的 CUDA 版本。
安装 CUDA Toolkit
对于深度学习程序,一般都要依赖 CUDA 环境,因此需要在机器上安装 CUDA Toolkit。
也是到 NVIDIA CUDA Toolkit 下载 下载对应的安装包,选择操作系统和安装方式即可

wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.debsudo
dpkg -i cuda-keyring_1.1-1_all.debsudo
apt-get updatesudo
apt-get -y install cuda-toolkit-12-4
配置下 PATH


测试
整个调用链:

代码测试:
import torchdef check_cuda_with_pytorch():"""检查 PyTorch CUDA 环境是否正常工作"""try:print("检查 PyTorch CUDA 环境:")if torch.cuda.is_available():print(f"CUDA 设备可用,当前 CUDA 版本是: {torch.version.cuda}")print(f"PyTorch 版本是: {torch.__version__}")print(f"检测到 {torch.cuda.device_count()} 个 CUDA 设备。")for i in range(torch.cuda.device_count()):print(f"设备 {i}: {torch.cuda.get_device_name(i)}")print(f"设备 {i} 的显存总量: {torch.cuda.get_device_properties(i).total_memory / (1024 ** 3):.2f} GB")print(f"设备 {i} 的显存当前使用量: {torch.cuda.memory_allocated(i) / (1024 ** 3):.2f} GB")print(f"设备 {i} 的显存最大使用量: {torch.cuda.memory_reserved(i) / (1024 ** 3):.2f} GB")else:print("CUDA 设备不可用。")except Exception as e:print(f"检查 PyTorch CUDA 环境时出现错误: {e}")if __name__ == "__main__":check_cuda_with_pytorch()

二、Docker 环境
调用链从 containerd --> runC 变成 containerd --> nvidia-container-runtime --> runC 。
nvidia-container-runtime 在中间拦截了容器 spec,就可以把 gpu 相关配置添加进去,再传给 runC 的 spec 里面就包含 gpu 信息了。

Ubuntu 上安装 Docker:30 sudo apt install -y apt-transport-https ca-certificates curl software-properties-common31 curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg32 echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null33 apt update34 apt install -y docker-ce docker-ce-cli containerd.io35 systemctl enable docker
安装 nvidia-container-toolkit
# 1. Configure the production repository
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list# Optionally, configure the repository to use experimental packages
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list# 2. Update the packages list from the repository
sudo apt-get update# 3. Install the NVIDIA Container Toolkit packages
sudo apt-get install -y nvidia-container-toolkit
配置使用该 runtime
支持 Docker, Containerd, CRI-O, Podman 等 CRI。
具体见官方文档 container-toolkit#install-guide
这里以 Docker 为例进行配置:
旧版本需要手动在 /etc/docker/daemon.json 中增加配置,指定使用 nvidia 的 runtime。
{"runtimes": {"nvidia": {"args": [],"path": "nvidia-container-runtime"}}
}
新版 toolkit 带了一个nvidia-ctk 工具,执行以下命令即可一键配置:
sudo nvidia-ctk runtime configure --runtime=docker
然后重启 Docker 即可
systemctl restart docker
Docker 环境中的 CUDA 调用:

从图中可以看到,CUDA Toolkit 跑到容器里了,因此宿主机上不需要再安装 CUDA Toolkit。
使用一个带 CUDA Toolkit 的镜像即可。
最后我们启动一个 Docker 容器进行测试,其中命令中增加 --gpu参数来指定要分配给容器的 GPU。
--gpu 参数可选值:--gpus all:表示将所有 GPU 都分配给该容器
--gpus "device=<id>[,<id>...]":对于多 GPU 场景,可以通过 id 指定分配给容器的 GPU,例如 --gpu "device=0" 表示只分配 0 号 GPU 给该容器
GPU 编号则是通过nvidia-smi 命令进行查看
这里我们直接使用一个带 cuda 的镜像来测试,启动该容器并执行nvidia-smi 命令
docker run --rm --gpus all nvidia/cuda:12.0.1-runtime-ubuntu22.04 nvidia-smi
正常情况下应该是可以打印出容器中的 GPU 信息:

三、 k8s 环境
在 k8s 环境中使用 GPU,则需要在集群中部署以下组件:
gpu-device-plugin 用于管理 GPU,device-plugin 以 DaemonSet 方式运行到集群各个节点,以感知节点上的 GPU 设备,从而让 k8s 能够对节点上的 GPU 设备进行管理。
gpu-exporter:用于监控 GPU

安装 device-plugin
device-plugin 一般由对应的 GPU 厂家提供,比如 NVIDIA 的 k8s-device-plugin
安装其实很简单,将对应的 yaml apply 到集群即可。
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.15.0/deployments/static/nvidia-device-plugin.yml
device-plugin 启动之后,会感知节点上的 GPU 设备并上报给 kubelet,最终由 kubelet 提交到 kube-apiserver。
因此我们可以在 Node 可分配资源中看到 GPU,就像这样:
root@test:~# k describe node test|grep Capacity -A7
Capacity:cpu: 48ephemeral-storage: 460364840Kihugepages-1Gi: 0hugepages-2Mi: 0memory: 98260824Kinvidia.com/gpu: 2pods: 110
除了常见的 cpu、memory 之外,还有nvidia.com/gpu, 这个就是 GPU 资源
安装 GPU 监控
安装 DCCM exporter 结合 Prometheus 输出 GPU 资源监控信息。
helm repo add gpu-helm-charts \https://nvidia.github.io/dcgm-exporter/helm-chartshelm repo updatehelm install \--generate-name \gpu-helm-charts/dcgm-exporter
查看 metrics
curl -sL http://127.0.0.1:8080/metrics
# HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz).# TYPE DCGM_FI_DEV_SM_CLOCK gauge# HELP DCGM_FI_DEV_MEM_CLOCK Memory clock frequency (in MHz).# TYPE DCGM_FI_DEV_MEM_CLOCK gauge# HELP DCGM_FI_DEV_MEMORY_TEMP Memory temperature (in C).# TYPE DCGM_FI_DEV_MEMORY_TEMP gauge
...
DCGM_FI_DEV_SM_CLOCK{gpu="0", UUID="GPU-604ac76c-d9cf-fef3-62e9-d92044ab6e52",container="",namespace="",pod=""} 139
DCGM_FI_DEV_MEM_CLOCK{gpu="0", UUID="GPU-604ac76c-d9cf-fef3-62e9-d92044ab6e52",container="",namespace="",pod=""} 405
DCGM_FI_DEV_MEMORY_TEMP{gpu="0", UUID="GPU-604ac76c-d9cf-fef3-62e9-d92044ab6e52",container="",namespace="",pod=""} 9223372036854775794
…
测试
在 k8s 创建 Pod 要使用 GPU 资源很简单,和 cpu、memory 等常规资源一样,在 resource 中 申请即可。
比如,下面这个 yaml 里面我们就通过 resource.limits 申请了该 Pod 要使用 1 个 GPU。
apiVersion: v1
kind: Pod
metadata:name: gpu-pod
spec:restartPolicy: Nevercontainers:- name: cuda-containerimage: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2resources:limits:nvidia.com/gpu: 1 # requesting 1 GPU
这样 kueb-scheduler 在调度该 Pod 时就会考虑到这个情况,将其调度到有 GPU 资源的节点。
启动后,查看日志,正常应该会打印 测试通过的信息,k8s 环境中就可以使用 GPU 了。
kubectl logs gpu-pod
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
相关文章:
快速搭建GPU环境 | docker、k8s中使用gpu
目录 一、裸机部署安装 GPU Driver安装 CUDA Toolkit测试 二、Docker 环境安装 nvidia-container-toolkit配置使用该 runtime 三、 k8s 环境安装 device-plugin安装 GPU 监控 一、裸机部署 裸机中要使用上 GPU 需要安装以下组件: GPU DriverCUDA Toolkit 二者的关…...
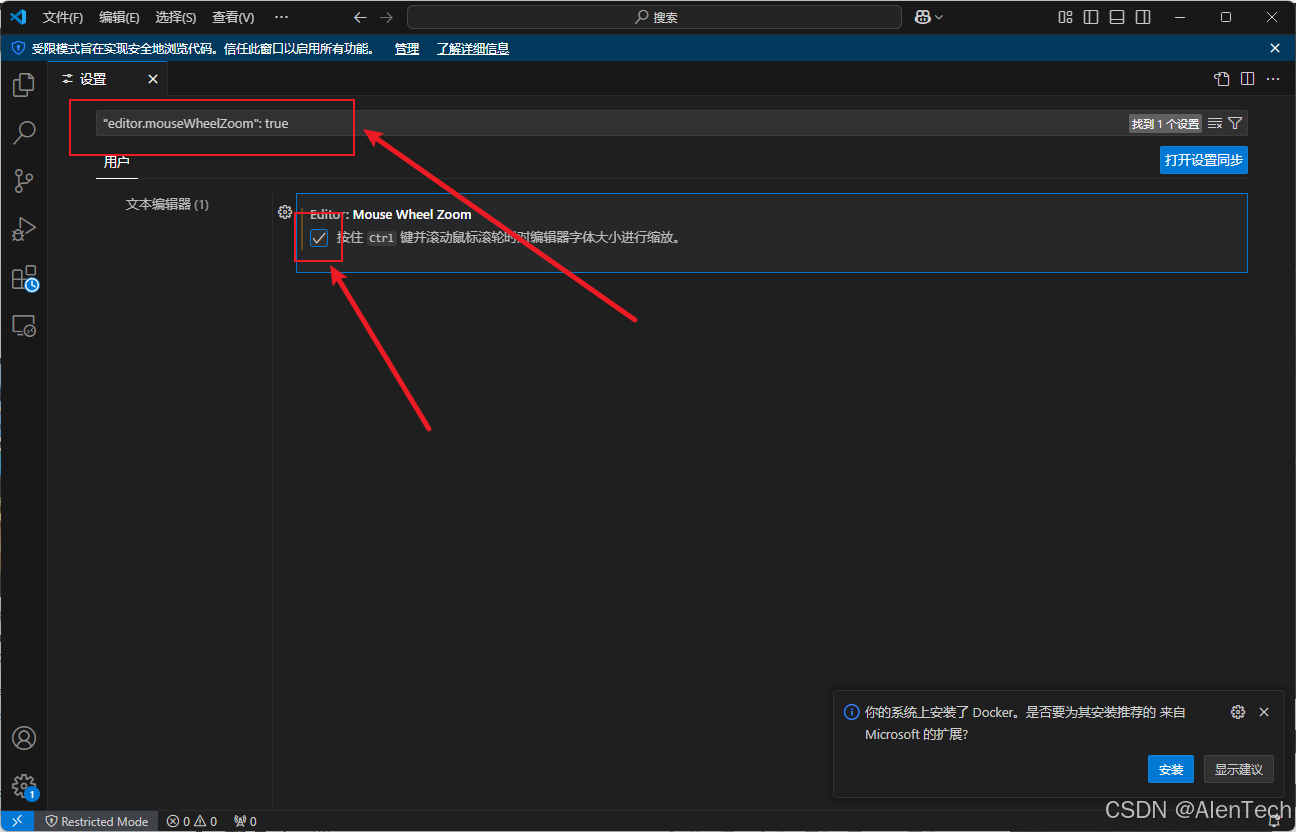
VSCode设置——通过ctrl+鼠标滚动改变字体大小(新版本的vs)
"editor.mouseWheelZoom": true 第一步: 第二步:...

【kafka实战】06 kafkaTemplate java代码使用示例
在 Spring Boot 中使用 KafkaTemplate 可以方便地向 Kafka 发送消息。下面为你详细介绍使用步骤和示例代码。 1. 创建 Spring Boot 项目 你可以使用 Spring Initializr(https://start.spring.io/ )来创建一个新的 Spring Boot 项目,添加以下…...

Java 23新特性
文章目录 Java 23新特性一、引言二、Markdown文档注释(JEP 467)示例 三、ZGC:默认的分代模式(JEP 474)1. 为什么要引入分代模式2. 使用分代模式的优势3. 如何启用分代模式 四、隐式声明的类和实例主方法(JE…...

bat脚本实现自动化漏洞挖掘
bat脚本 BAT脚本是一种批处理文件,可以在Windows操作系统中自动执行一系列命令。它们可以简化许多日常任务,如文件操作、系统配置等。 bat脚本执行命令 echo off#下面写要执行的命令 httpx 自动存活探测 echo off httpx.exe -l url.txt -o 0.txt nuc…...

[创业之路-285]:《产品开发管理-方法.流程.工具 》-1- IPD的功能列表以及导入步骤
一、概述: 对于没有IPD(集成产品开发)流程的公司来说,导入IPD需要循序渐进、有序进行,而不是一步到位。这是因为IPD不仅仅是一种新的产品开发流程,它还涉及到公司文化、组织结构、团队协作方式以及思维方式…...

Redis命令:列表模糊删除详解
前言 在Redis中,列表(List)是一种非常常用的数据结构,允许存储多个有序的元素。然而,在实际应用中,可能会遇到需要删除列表中符合某种模式的元素的需求。本文将详细介绍如何在Redis中实现列表的模糊删除。…...

Day36-【13003】短文,数组的行主序方式,矩阵的压缩存储,对称、三角、稀疏矩阵和三元组线性表,广义表求长度、深度、表头、表尾等
文章目录 本次课程内容第四章 数组、广义表和串第一节 数组及广义表数组的基本操作数组的顺序存储方式-借用矩阵行列式概念二维数组C语言对应的函数-通常行主序方式 矩阵的压缩存储对称矩阵和三角矩阵压缩存储后,采用不同的映射函数稀疏矩阵-可以构成三元组线性表三…...

大数据sql查询速度慢有哪些原因
1.索引问题 可能缺少索引,也有可能是索引不生效 2.连接数配置:连接数过少/连接池比较小 连接数过 3.sql本身有问题,响应比较慢,比如多表 4.数据量比较大 -这种最好采用分表设计 或分批查询 5.缓存池大小 可能是缓存问题ÿ…...

文件 I/O 和序列化
文件I/O C#提供了多种方式来读写文件,主要通过System.IO命名空间中的类来实现,下方会列一些常用的类型: StreamReader/StreamWriter:用于以字符为单位读取或写入文本文件。 BinaryReader/BinaryWriter:用于以二进制格…...

机器学习中的关键概念:通过SKlearn的MNIST实验深入理解
欢迎来到我的主页:【Echo-Nie】 本篇文章收录于专栏【机器学习】 1 sklearn相关介绍 Scikit-learn 是一个广泛使用的开源机器学习库,提供了简单而高效的数据挖掘和数据分析工具。它建立在 NumPy、SciPy 和 matplotlib 等科学计算库之上,支持…...

HELLOCTF反序列化靶场全解
level 2 <?php/* --- HelloCTF - 反序列化靶场 关卡 2 : 类值的传递 --- HINT:尝试将flag传递出来~# -*- coding: utf-8 -*- # Author: 探姬 # Date: 2024-07-01 20:30 # Repo: github.com/ProbiusOfficial/PHPSerialize-labs # email: adminhello-ctf.com…...

十二、Docker Compose 部署 SpringCloudAlibaba 微服务
一、部署基础服务 0、项目部署结构 项目目录结构如下: /home/zhzl_hebei/ ├── docker-compose.yml └── geochance-auth/└── Dockerfile└── geochance-auth.jar └── geochance-system/└── Dockerfile└── geochance-system.jar └── geochance-gateway/…...

VUE之插槽
1、默认插槽 <template><div class"father"></div><h3>父组件</h3><div class"content"><Category title"热门游戏列表"><ul><li v-for"g in games" :key"g.id">{{…...

4. Go结构体使用
1、结构体的简介 结构体(Struct)是编程语言中常见的一种复合数据类型,它将不同类型的数据元素(成员)组合成一个单一的实体。通过结构体,程序员可以将具有不同类型和性质的信息绑定到一个对象中,…...

版本控制的重要性及 Git 入门
版本控制:软件开发的基石 在软件开发的浩瀚宇宙中,版本控制无疑是那颗最为闪耀的恒星,照亮了整个开发过程,成为现代软件开发不可或缺的基石。 历史追溯,定位问题根源 版本控制就像是一位不知疲倦的史官,…...

[NKU]C++安装环境 VScode
bilibili安装教程 vscode 关于C/C的环境配置全站最简单易懂!!大学生及初学初学C/C进!!!_哔哩哔哩_bilibili 1安装vscode和插件 汉化插件 2安装插件 2.1 C/C 2.2 C/C Compile run 2.3 better C Syntax 查看已…...

deepseek本地部署
DeepSeek本地部署详细指南 DeepSeek作为一款开源且性能强大的大语言模型,提供了灵活的本地部署方案,让用户能够在本地环境中高效运行模型,同时保护数据隐私,这里记录自己DeepSeek本地部署流程。 主机环境 cpu:amd 7500Fgpu:406…...
网络编程day1
实例: struct sockaddr_in addr {0};//初始化 addr.sin_family AF_INET;//设置地址族 addr.sin_port htons(8888);//设置端口号 addr.sin_addr.s_addr inet_addr("192.168.1.1"); //设置ip地址 bind(sock,(struct sockaddr *)&addr,sizeof(ad…...
;;“); 文件对话框显示乱码)
QFileDialog::getOpenFileName(this,“文件对话框“,“.“,“c++ files(*.cpp);;“); 文件对话框显示乱码
在使用 QFileDialog::getOpenFileName 时,如果文件对话框显示乱码,通常是因为编码问题。Qt 默认使用 UTF-8 编码,但如果你的系统或源代码文件的编码不一致,可能会导致乱码。 以下是几种可能的解决方法: 1. 确保源代码…...

Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别
Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维…...

开源监控面板OpenClaw:从架构设计到生产部署实战指南
1. 项目概述:一个开源监控面板的诞生 在运维和开发的世界里,监控面板就像是驾驶舱里的仪表盘。没有它,你就是在盲飞。今天要聊的这个项目 xingrz/openclaw-dashboard ,就是一个由社区驱动的开源监控面板解决方案。它的名字很有意…...

轻量级工作流编排引擎:从脚本管理到自动化流程的实践指南
1. 项目概述:从单体脚本到流程编排的进化 如果你和我一样,在数据工程、自动化运维或者机器学习模型训练这些领域摸爬滚打过几年,大概率会遇到一个相似的困境:手头的任务脚本越来越多,它们之间有的有依赖关系࿰…...

开源虚拟世界引擎Vircadia核心架构与部署实战指南
1. 项目概述:一个开源虚拟世界的核心引擎如果你对构建一个属于自己的、去中心化的虚拟世界感兴趣,那么你很可能已经听说过或者正在寻找一个合适的底层引擎。今天要聊的这个项目,就是这样一个领域的重量级选手:vircadia/vircadia-n…...

Google Labs Jules Awesome List:构建与维护高质量开发者资源清单指南
1. 项目概述:一份面向开发者的“Awesome List”清单在开源社区和开发者圈子里,有一个约定俗成的传统:当某个技术领域或工具生态变得足够庞大和复杂时,总会有热心的贡献者站出来,整理一份名为“Awesome List”的清单。这…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...

从开源AI导师项目GURU-Ai拆解:如何构建具备教学能力的智能体
1. 项目概述:一个“AI导师”的诞生与定位最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个平平无奇的AI工具仓库。但点进去细看,你会发现它的野心不小——它想做的不是又一个聊天机…...
)
别再让用户等上传!用@ffmpeg/ffmpeg在浏览器里直接压缩视频(附ThinkPHP项目实战)
浏览器端视频压缩实战:基于FFmpeg.wasm与ThinkPHP的高效集成方案 引言 在当今内容为王的互联网时代,视频已成为用户生成内容(UGC)的核心载体。然而,高清视频带来的大文件体积往往成为用户体验的瓶颈——上传等待时间长…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...