利用 Python 爬虫获取按关键字搜索淘宝商品的完整指南
在电商数据分析和市场研究中,获取商品的详细信息是至关重要的一步。淘宝作为中国最大的电商平台之一,提供了丰富的商品数据。通过 Python 爬虫技术,我们可以高效地获取按关键字搜索的淘宝商品信息。本文将详细介绍如何利用 Python 爬虫技术获取淘宝商品信息,并提供详细的代码示例。
一、项目背景与目标
淘宝平台上的商品信息对于商家、市场研究人员以及消费者都具有重要价值。通过分析这些数据,可以了解市场趋势、消费者需求以及竞争对手情况。本项目的目标是利用 Python 爬虫技术,自动化地获取按关键字搜索的淘宝商品信息,并将其存储到本地文件或数据库中,以便进行后续的数据分析和挖掘。
二、技术选型与开发环境搭建
(一)技术选型
-
Python 语言:Python 语言具有简洁易读、丰富的库支持和强大的社区资源,是编写爬虫程序的首选语言之一。
-
requests 库:
requests是一个简洁易用的 HTTP 库,支持多种 HTTP 方法,能够模拟浏览器行为,实现与网页服务器的通信。 -
BeautifulSoup 库:
BeautifulSoup是一个用于解析 HTML 和 XML 文档的库,适用于从网页中提取和操作数据。 -
pandas 库:
pandas是一个强大的数据处理库,适用于数据清洗、转换和存储。 -
selenium 库:
selenium是一个用于自动化测试的工具,可以模拟用户在浏览器中的操作,适用于动态网页的爬取。
(二)开发环境搭建
-
Python 开发工具:安装并配置 Python,确保 Python 环境变量正确设置。推荐使用 PyCharm 或 Visual Studio Code 等集成开发环境(IDE),它们提供了代码编辑、调试、项目管理等便捷功能。
-
安装第三方库:通过 pip 安装
requests、BeautifulSoup、pandas和selenium等第三方库。pip install requests beautifulsoup4 pandas selenium
三、爬虫程序设计与实现
(一)分析网页结构
在编写爬虫程序之前,我们需要对淘宝商品搜索结果页面的 HTML 结构进行深入分析。通过浏览器的开发者工具(如 Chrome 的开发者工具),查看搜索结果页面的 HTML 源代码,了解各个关键信息(如商品标题、价格、销量等)所在的 HTML 元素及其对应的 CSS 类名、ID 等属性。
(二)编写爬虫程序
1. 使用 selenium 模拟搜索
由于淘宝的商品搜索结果页面是动态加载的,因此需要使用 selenium 来模拟用户在浏览器中的搜索操作。
Python复制
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time# 启动 Chrome 浏览器
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ['enable-automation'])
driver = webdriver.Chrome(options=options)
driver.get('https://www.taobao.com')
driver.maximize_window()# 等待用户手动登录
input('请手动登录淘宝,登录完成后按回车键继续...')# 搜索关键字
def search_keyword(keyword):input_element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))input_element.clear()input_element.send_keys(keyword)search_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_SearchForm button")))search_button.click()time.sleep(5) # 等待搜索结果加载完成# 示例:搜索关键字
search_keyword('苹果手机')2. 解析搜索结果页面
使用 BeautifulSoup 解析搜索结果页面,提取商品的关键信息。
from bs4 import BeautifulSoup
import pandas as pddef parse_search_results():html = driver.page_sourcesoup = BeautifulSoup(html, 'html.parser')items = soup.select('.m-itemlist .items .item')data = []for item in items:title = item.select_one('.title').text.strip()price = item.select_one('.price').text.strip()deal = item.select_one('.deal-cnt').text.strip()shop = item.select_one('.shop').text.strip()location = item.select_one('.location').text.strip()data.append({'title': title,'price': price,'deal': deal,'shop': shop,'location': location})return data# 示例:解析搜索结果
results = parse_search_results()
df = pd.DataFrame(results)
df.to_csv('taobao_search_results.csv', index=False, encoding='utf-8-sig')3. 翻页操作
通过 selenium 实现自动翻页,获取更多商品信息。
def turn_page(page_number):try:print(f"正在翻页到第 {page_number} 页")page_input = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager .input.J_Input")))page_input.clear()page_input.send_keys(page_number)go_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager .btn.J_Btn")))go_button.click()time.sleep(5) # 等待页面加载完成except Exception as e:print(f"翻页失败:{e}")# 示例:翻页操作
for page in range(2, 6): # 翻到第 2 到 5 页turn_page(page)results = parse_search_results()df = pd.DataFrame(results)df.to_csv(f'taobao_search_results_page_{page}.csv', index=False, encoding='utf-8-sig')(三)异常处理与重试机制
在爬虫程序运行过程中,可能会遇到各种异常情况,如网络请求超时、HTML 解析错误等。为了提高程序的稳定性和可靠性,我们需要在代码中添加异常处理逻辑,并实现重试机制。
from selenium.common.exceptions import TimeoutExceptiondef safe_parse_search_results():try:return parse_search_results()except TimeoutException:print("页面加载超时,正在重试...")time.sleep(5)return safe_parse_search_results()except Exception as e:print(f"解析搜索结果失败:{e}")return []四、爬虫程序优化与性能提升
(一)合理设置请求间隔
在爬取数据时,需要合理设置请求间隔,避免对淘宝服务器造成过大压力,同时也降低被网站封禁 IP 的风险。可以在每次翻页或请求之间设置适当的等待时间,如等待 1 - 3 秒。
time.sleep(random.randint(1, 3)) # 随机等待 1 - 3 秒(二)使用代理 IP
为了进一步降低被封禁 IP 的风险,可以使用代理 IP 服务器。通过代理 IP 发送请求,可以隐藏真实的 IP 地址,使爬虫程序更加稳定地运行。
from selenium.webdriver.common.proxy import Proxy, ProxyTypeproxy = Proxy()
proxy.proxy_type = ProxyType.MANUAL
proxy.http_proxy = "代理 IP 地址:代理端口号"
proxy.ssl_proxy = "代理 IP 地址:代理端口号"capabilities = webdriver.DesiredCapabilities.CHROME
proxy.add_to_capabilities(capabilities)driver = webdriver.Chrome(desired_capabilities=capabilities)五、实践案例与数据分析
(一)实践案例
在实际应用中,我们利用上述 Python 爬虫程序对淘宝平台上按关键字搜索的商品进行了信息爬取。通过模拟用户搜索操作、解析搜索结果页面和自动翻页,成功获取了商品标题、价格、销量、店铺名称等详细信息。这些数据被存储到本地的 CSV 文件中,为后续的数据分析和市场研究提供了有力支持。
(二)数据分析
基于爬取到的商品数据,我们进行了多维度的数据分析。通过对商品价格的统计分析,了解了市场定价情况;分析商品销量分布,识别了热门商品;统计店铺分布情况,了解了市场格局。这些分析结果为商家优化产品策略、制定营销计划提供了有力依据,同时也为市场研究人员提供了宝贵的市场洞察。
六、总结与展望
通过 Python 爬虫技术,我们成功实现了对淘宝商品信息的自动化爬取,并进行了有效的数据分析。这一实践不仅展示了 Python 爬虫的强大功能,也为电商领域的数据挖掘提供了新的思路和方法。未来,我们可以进一步优化爬虫程序,提高数据爬取的效率和准确性;同时,结合更先进的数据分析技术,如机器学习和数据挖掘算法,深入挖掘商品数据中的潜在价值,为电商行业的决策提供更有力的支持。
希望本文能帮助读者快速上手并实现淘宝商品信息的爬取和分析。如果有任何问题或建议,欢迎随时交流。
相关文章:

利用 Python 爬虫获取按关键字搜索淘宝商品的完整指南
在电商数据分析和市场研究中,获取商品的详细信息是至关重要的一步。淘宝作为中国最大的电商平台之一,提供了丰富的商品数据。通过 Python 爬虫技术,我们可以高效地获取按关键字搜索的淘宝商品信息。本文将详细介绍如何利用 Python 爬虫技术获…...

什么是幂等性
幂等性(Idempotence)是一个在数学、计算机科学等多个领域都有重要应用的概念,下面从不同领域为你详细介绍其含义。 数学领域 在数学中,幂等性是指一个操作或函数进行多次相同的运算,其结果始终与进行一次运算的结果相…...
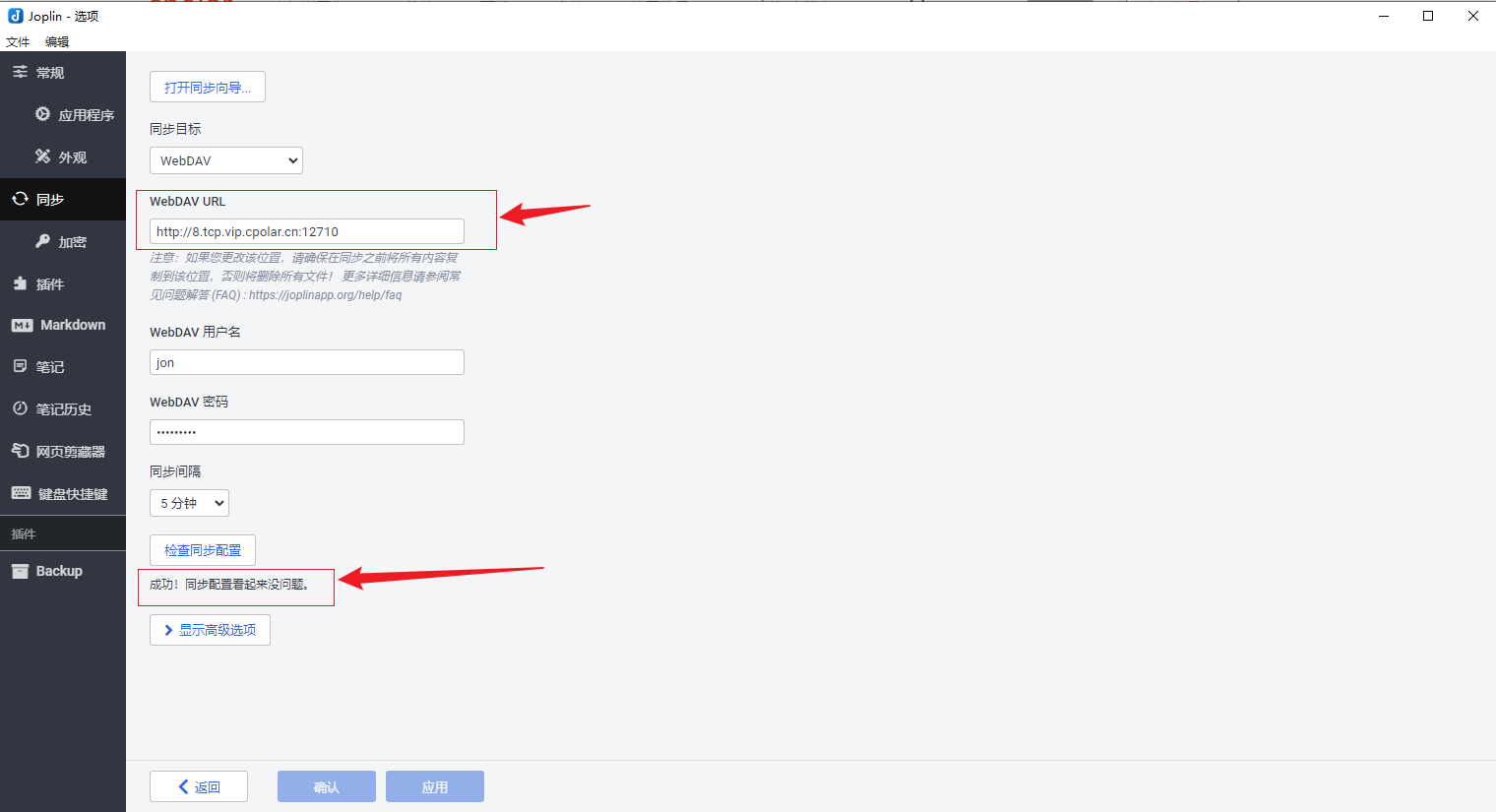
群晖NAS如何通过WebDAV和内网穿透实现Joplin笔记远程同步
文章目录 前言1. 检查群晖Webdav 服务2. 本地局域网IP同步测试3. 群晖安装Cpolar工具4. 创建Webdav公网地址5. Joplin连接WebDav6. 固定Webdav公网地址7. 公网环境连接测试 前言 在数字化浪潮的推动下,笔记应用已成为我们记录生活、整理思绪的重要工具。Joplin&…...

示例:JAVA调用deepseek
近日,国产AI DeepSeek在中国、美国的科技圈受到广泛关注,甚至被认为是大模型行业的最大“黑马”。在外网,DeepSeek被不少人称为“神秘的东方力量”。1月27日,DeepSeek应用登顶苹果美国地区应用商店免费APP下载排行榜,在…...

【提示工程】:如何有效与大语言模型互动
随着人工智能技术的快速发展,大语言模型(LLM)如 GPT 系列在各类任务中的应用越来越广泛。从文本生成到代码编写,从数据分析到内容创作,这些模型展现出了强大的能力。然而,要充分发挥大语言模型的潜力,关键在于如何设计高质量的提示词(Prompts)。这门技术被称为提示工程…...

操作系统—经典同步问题
补充 互斥信号量mutex初值均为1 同步信号量根据问题实际描述自己设计 生产者-消费者问题 问题描述:一组生产者进程和一组消费者进程 共享一个初始为空、大小为n的缓冲区。(缓冲区:临界资源) 只有缓冲区没满时,生产者…...

profinet工业通信协议网关:提升钢铁冶炼智能制造效率的利器
工业通信协议网关profinet转ethercat(稳联技术WL-PN-ECATM)在钢铁冶炼生产线中的智能应用实践 在现代钢铁冶炼生产中,复杂的设备互联和数据传输对生产效率和质量控制至关重要。本案例详细阐述了某大型钢铁集团通过工业通信协议网关实现生产线…...
)
Vue基础:计算属性(描述依赖响应式状态的复杂逻辑)
文章目录 引言computed() 方法期望接收一个 getter 函数可写计算属性:计算属性的 Setter计算属性的缓存机制调试 Computed引言 推荐使用计算属性来描述依赖响应式状态的复杂逻辑 computed 函数:它接受 getter 函数并为 getter 返回的值返回一个不可变的响应式 ref 对象。 c…...
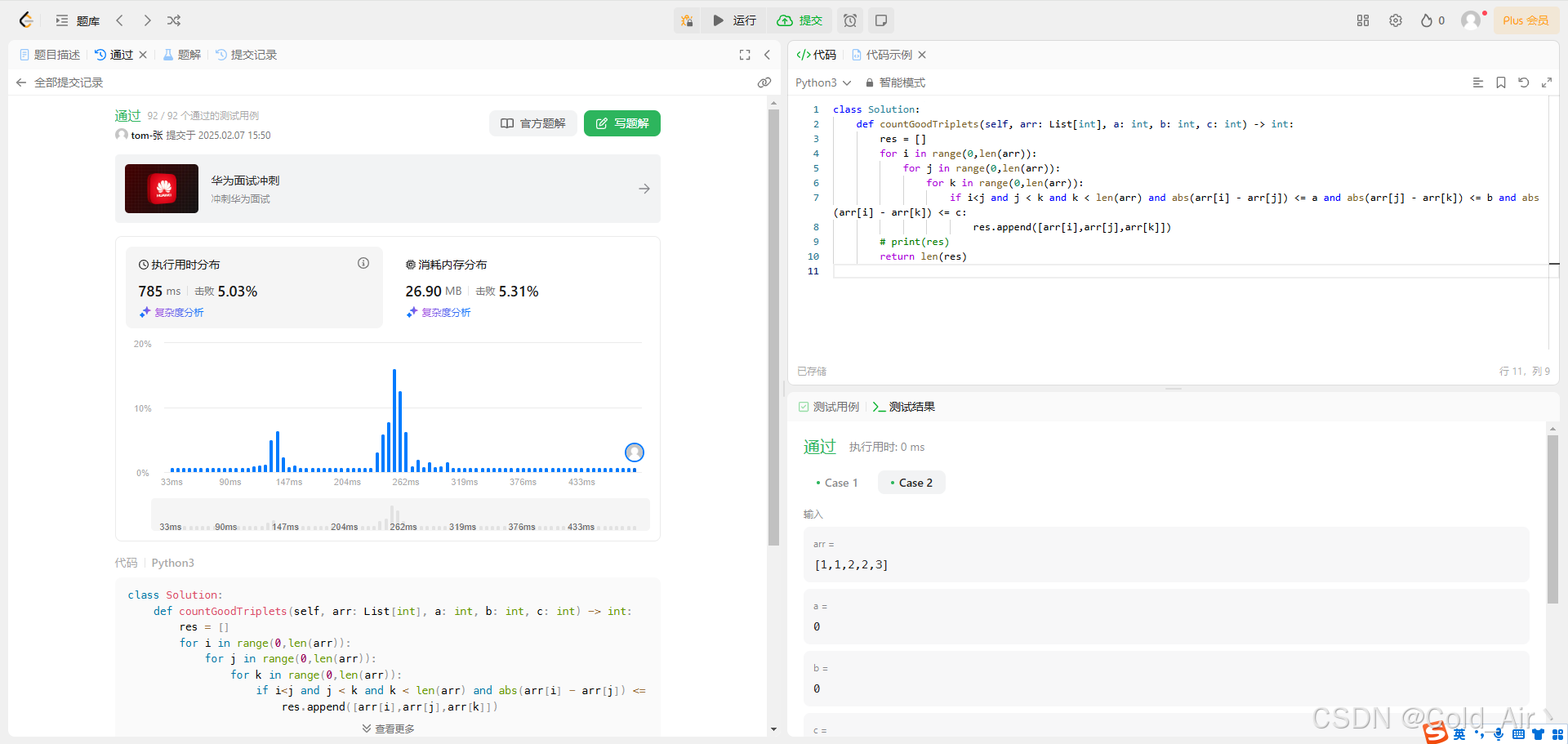
leetcode:1534. 统计好三元组(python3解法)
难度:简单 给你一个整数数组 arr ,以及 a、b 、c 三个整数。请你统计其中好三元组的数量。 如果三元组 (arr[i], arr[j], arr[k]) 满足下列全部条件,则认为它是一个 好三元组 。 0 < i < j < k < arr.length|arr[i] - arr[j]| &l…...

BUU27 [SUCTF 2019]CheckIn1
题目是上传文件 直接上传muma.jpg还不成功: 好吧,那做一个图片马上去,换马以后发现还是不行,呃啊啊啊啊 干啥啥不行,搜wp第一名,哎 新面孔:exif_imagetype 函数在 PHP 中用于检测一个文件是否为…...

unity学习30:Audio Source, Audio clip 音效和音乐
目录 1 音乐相关必须要有 Audio listener 和Source 2 Scene里必须要有 Audio listener 3 Audio Source 3.1 Audio Source 就是音源,可播放的音乐clip 分类 3.2 创建Audio Source 3.3 各种属性 3.4 3D sound Settings 4 使用脚本来播放声音 4.1 声明AudioC…...

【Qt 常用控件】输入类控件1(QLineEdit和QTextEdit 输入框)
目录 1.QLineEdit 单行输入框 例:输入个人信息,通过按钮提交 例:为输入框设置验证器,检查输入的电话 例:验证两次输入的密码是否一致 例:是否显示密码按钮,toggled信号。 2.QTextEdit多行输入框 、QPl…...

openEuler22.03LTS系统升级docker至26.1.4以支持启用ip6tables功能
本文记录了openEuler22.03LTS将docker升级由18.09.0升级至26.1.4的过程(当前docker最新版本为27.5.1,生产环境为保障稳定性,选择升级到上一个大版本26的最新小版本)。 一、现有环境 1、系统版本 [rootlocalhost opt]# cat /etc…...

深入解析:如何利用 Java 爬虫按关键字搜索淘宝商品
在电商领域,通过关键字搜索商品是常见的需求。无论是商家分析竞争对手,还是消费者寻找心仪的商品,获取搜索结果中的商品信息都至关重要。本文将详细介绍如何利用 Java 爬虫按关键字搜索淘宝商品,并提供完整的代码示例。 一、Java…...

STM32上部署AI的两个实用软件——Nanoedge AI Studio和STM32Cube AI
1 引言 STM32 微控制器在嵌入式领域应用广泛,因为它性能不错、功耗低,还有丰富的外设,像工业控制、智能家居、物联网这些场景都能看到它的身影。与此同时,人工智能技术发展迅速,也逐渐融入各个行业。 把 AI 部署到 STM…...

C++ Primer 成员访问运算符
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

芯科科技的BG22L和BG24L带来应用优化的超低功耗蓝牙®连接
全新的BG22L为常见蓝牙设备提供强大的安全性和处理能力,而BG24L支持先进的AI/ML加速和信道探测功能 2025年2月6日 – 致力于以安全、智能无线连接技术,建立更互联世界的全球领导厂商Silicon Labs(亦称“芯科科技”,NASDAQ&#x…...

java后端开发面试常问
面试常问问题 1 spring相关 (1)Transactional失效的场景 <1> Transactional注解默认只会回滚运行时异常(RuntimeException),如果方法中抛出了其他异常,则事务不会回滚(数据库数据仍然插…...

双非硕士的抉择:自学嵌入式硬件开发还是深入Linux C/C++走软开?
今天给大家分享的是一位粉丝的提问,双非硕研一是自学嵌入式走偏硬件还是说深入学习Linuxc/c走软开呢? 接下来把粉丝的具体提问和我的回复分享给大家,希望也能给一些类似情况的小伙伴一些启发和帮助。 粉丝提问: 老师好ÿ…...

Windows系统使用Git教程详解
使用 Git 可以帮助开发人员更好地进行版本控制和团队协作,下面是 Windows 上 Git 的详细使用教程。 安装 Git 首先,你需要在 Windows 上安装 Git。你可以从 Git 官网下载最新的安装包(https://git-scm.com/downloads),…...

避坑指南:连接UR5实体机械臂与ROS MoveIt时,你最容易忽略的这3个配置细节
避坑指南:连接UR5实体机械臂与ROS MoveIt时,你最容易忽略的这3个配置细节 当仿真环境中的UR5机械臂完美运行MoveIt规划路径,却在切换到实体设备时遭遇连接失败,这种落差感往往源于几个隐蔽的配置陷阱。本文将从工业现场调试经验出…...

技能管理框架skill-mix:用YAML与声明式配置构建可量化技能体系
1. 项目概述与核心价值最近在梳理团队的知识库和技能树时,我又一次深刻体会到,一个清晰、可量化、可追踪的技能管理体系对个人成长和团队效能有多重要。无论是作为技术负责人评估团队战斗力,还是作为一线开发者规划自己的学习路径,…...

通过curl命令直接测试Taotoken聊天补全接口的简易方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的简易方法 在开发或调试过程中,有时我们希望在无需引入完整SDK的轻量级环境…...

如何5分钟完成专业电路图:Draw.io ECE插件完全指南
如何5分钟完成专业电路图:Draw.io ECE插件完全指南 【免费下载链接】Draw-io-ECE Custom-made draw.io-shapes - in the form of an importable library - for drawing circuits and conceptual drawings in draw.io. 项目地址: https://gitcode.com/gh_mirrors/d…...

从CenterFusion到车道线检测:聊聊DLAseg模型里可变形卷积的实战调优心得
从CenterFusion到车道线检测:DLAseg模型中可变形卷积的工程实践与调优策略 在自动驾驶和计算机视觉领域,特征提取网络的设计直接影响着感知系统的性能上限。Deep Layer Aggregation (DLA) 作为特征融合的经典方法,通过层级聚合机制实现了多尺…...

MAA助手:解放双手的明日方舟全自动游戏管理工具实战指南
MAA助手:解放双手的明日方舟全自动游戏管理工具实战指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://g…...

【Flutter for OpenHarmony 跨平台征文】Flutter 血压数据模型设计 + WHO标准分类算法实战指南
【Flutter for OpenHarmony 跨平台征文】Flutter 血压数据模型设计 WHO标准分类算法实战指南 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net🎯 写在前面 嗨,大家好!我是上海某高校大一计算机专业的学生…...

87456238
8637452...
)
UWB定位标签天线怎么选?PATCH、PIFA、DIPOLE三种方案全对比(含NXP/Qorvo模组适配建议)
UWB定位标签天线选型指南:PATCH、PIFA、DIPOLE三大方案深度解析与工程决策 在物联网定位技术领域,超宽带(UWB)凭借其厘米级精度和强抗干扰能力,已成为工业定位、智能仓储和医疗设备追踪的核心解决方案。而天线作为UWB系统的"感官器官&qu…...

RPFM:重新定义全面战争MOD开发的工作流革命
RPFM:重新定义全面战争MOD开发的工作流革命 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: https://gitcode.com/g…...