Python Pandas(3):DataFrame
1 介绍
DataFrame 是 Pandas 中的另一个核心数据结构,类似于一个二维的表格或数据库中的数据表。它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引),提供了各种功能来进行数据访问、筛选、分割、合并、重塑、聚合以及转换等操作。DataFrame 是一个非常灵活且强大的数据结构,广泛用于数据分析、清洗、转换、可视化等任务。
1.1 DataFrame 特点
- 二维结构:
DataFrame是一个二维表格,可以被看作是一个 Excel 电子表格或 SQL 表,具有行和列。可以将其视为多个Series对象组成的字典。 - 列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串或 Python 对象等。
- 索引:
DataFrame可以拥有行索引和列索引,类似于 Excel 中的行号和列标。 - 大小可变:可以添加和删除列,类似于 Python 中的字典。
- 自动对齐:在进行算术运算或数据对齐操作时,
DataFrame会自动对齐索引。 - 处理缺失数据:
DataFrame可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示。 - 数据操作:支持数据切片、索引、子集分割等操作。
- 时间序列支持:
DataFrame对时间序列数据有特别的支持,可以轻松地进行时间数据的切片、索引和操作。 - 丰富的数据访问功能:通过
.loc、.iloc和.query()方法,可以灵活地访问和筛选数据。 - 灵活的数据处理功能:包括数据合并、重塑、透视、分组和聚合等。
- 数据可视化:虽然
DataFrame本身不是可视化工具,但它可以与 Matplotlib 或 Seaborn 等可视化库结合使用,进行数据可视化。 - 高效的数据输入输出:可以方便地读取和写入数据,支持多种格式,如 CSV、Excel、SQL 数据库和 HDF5 格式。
- 描述性统计:提供了一系列方法来计算描述性统计数据,如
.describe()、.mean()、.sum()等。 - 灵活的数据对齐和集成:可以轻松地与其他
DataFrame或Series对象进行合并、连接或更新操作。 - 转换功能:可以对数据集中的值进行转换,例如使用
.apply()方法应用自定义函数。 - 滚动窗口和时间序列分析:支持对数据集进行滚动窗口统计和时间序列分析。

1.2 创建DataFrame
DataFrame 构造方法如下:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
data:DataFrame 的数据部分,可以是字典、二维数组、Series、DataFrame 或其他可转换为 DataFrame 的对象。如果不提供此参数,则创建一个空的 DataFrame。index:DataFrame 的行索引,用于标识每行数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。columns:DataFrame 的列索引,用于标识每列数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。dtype:指定 DataFrame 的数据类型。可以是 NumPy 的数据类型,例如np.int64、np.float64等。如果不提供此参数,则根据数据自动推断数据类型。copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。
1.2.1 使用列表创建
import pandas as pddata = [['Google', 10], ['Bing', 12], ['Wiki', 13]]# 创建DataFrame
df = pd.DataFrame(data, columns=['Site', 'Age'])# 使用astype方法设置每列的数据类型
df['Site'] = df['Site'].astype(str)
df['Age'] = df['Age'].astype(float)print(df)

1.2.2 使用字典创建
import pandas as pddata = {'Site': ['Google', 'Bing', 'Wiki'], 'Age': [10, 12, 13]}df = pd.DataFrame(data)print(df)
1.2.3 使用ndarrays 创建
import numpy as np
import pandas as pd# 创建一个包含网站和年龄的二维ndarray
ndarray_data = np.array([['Google', 10],['Bing', 12],['Wiki', 13]
])# 使用DataFrame构造函数创建数据帧
df = pd.DataFrame(ndarray_data, columns=['Site', 'Age'])# 打印数据帧
print(df)
1.2.4 使用字典(key/value)
import pandas as pddata = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]df = pd.DataFrame(data)print(df)

没有对应的部分数据为 NaN。
1.2.5 从 Series 创建 DataFrame
import pandas as pd# 从 Series 创建 DataFrame
s1 = pd.Series(['Alice', 'Bob', 'Charlie'])
s2 = pd.Series([25, 30, 35])
s3 = pd.Series(['New York', 'Los Angeles', 'Chicago'])
df = pd.DataFrame({'Name': s1, 'Age': s2, 'City': s3})
print(df)
1.3 loc属性
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]
}# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])

返回结果其实就是一个 Pandas Series 数据。也可以返回多行数据,使用 [[ ... ]] 格式,... 为各行的索引,以逗号隔开:
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]
}# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)# 返回第一行和第二行
print(df.loc[[0, 1]])

返回结果其实就是一个 Pandas DataFrame 数据。我们可以指定索引值,如下实例:
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]
}df = pd.DataFrame(data, index=["day1", "day2", "day3"])print(df)

Pandas 可以使用 loc 属性返回指定索引对应到某一行:
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]
}df = pd.DataFrame(data, index=["day1", "day2", "day3"])# 指定索引
print(df.loc["day2"])

2 DataFrame 方法
| 方法名称 | 功能描述 |
|---|---|
head(n) | 返回 DataFrame 的前 n 行数据(默认前 5 行) |
tail(n) | 返回 DataFrame 的后 n 行数据(默认后 5 行) |
info() | 显示 DataFrame 的简要信息,包括列名、数据类型、非空值数量等 |
describe() | 返回 DataFrame 数值列的统计信息,如均值、标准差、最小值等 |
shape | 返回 DataFrame 的行数和列数(行数, 列数) |
columns | 返回 DataFrame 的所有列名 |
index | 返回 DataFrame 的行索引 |
dtypes | 返回每一列的数值数据类型 |
sort_values(by) | 按照指定列排序 |
sort_index() | 按行索引排序 |
dropna() | 删除含有缺失值(NaN)的行或列 |
fillna(value) | 用指定的值填充缺失值 |
isnull() | 判断缺失值,返回一个布尔值 DataFrame |
notnull() | 判断非缺失值,返回一个布尔值 DataFrame |
loc[] | 按标签索引选择数据 |
iloc[] | 按位置索引选择数据 |
at[] | 访问 DataFrame 中单个元素(比 loc[] 更高效) |
iat[] | 访问 DataFrame 中单个元素(比 iloc[] 更高效) |
apply(func) | 对 DataFrame 或 Series 应用一个函数 |
applymap(func) | 对 DataFrame 的每个元素应用函数(仅对 DataFrame) |
groupby(by) | 分组操作,用于按某一列分组进行汇总统计 |
pivot_table() | 创建透视表 |
merge() | 合并多个 DataFrame(类似 SQL 的 JOIN 操作) |
concat() | 按行或按列连接多个 DataFrame |
to_csv() | 将 DataFrame 导出为 CSV 文件 |
to_excel() | 将 DataFrame 导出为 Excel 文件 |
to_json() | 将 DataFrame 导出为 JSON 格式 |
to_sql() | 将 DataFrame 导出为 SQL 数据库 |
query() | 使用 SQL 风格的语法查询 DataFrame |
duplicated() | 返回布尔值 DataFrame,指示每行是否是重复的 |
drop_duplicates() | 删除重复的行 |
set_index() | 设置 DataFrame 的索引 |
reset_index() | 重置 DataFrame 的索引 |
transpose() | 转置 DataFrame(行列交换) |
import pandas as pd# 创建 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40],'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df = pd.DataFrame(data)# 查看前两行数据
print('--------查看前两行数据--------')
print(df.head(2))# 查看 DataFrame 的基本信息
print('--------查看 DataFrame 的基本信息--------')
print(df.info())# 获取描述统计信息
print('--------获取描述统计信息--------')
print(df.describe())# 按年龄排序
print('--------按年龄排序--------')
df_sorted = df.sort_values(by='Age', ascending=False)
print(df_sorted)# 选择指定列
print('--------选择指定列--------')
print(df[['Name', 'Age']])# 按索引选择行
print('--------按索引选择行--------')
print(df.iloc[1:3]) # 选择第二到第三行(按位置)# 按标签选择行
print('--------按标签选择行--------')
print(df.loc[1:2]) # 选择第二到第三行(按标签)# 计算分组统计(按城市分组,计算平均年龄)
print('--计算分组统计(按城市分组,计算平均年龄)--')
print(df.groupby('City')['Age'].mean())# 处理缺失值(填充缺失值)
df['Age'] = df['Age'].fillna(30)# 导出为 CSV 文件
df.to_csv('output.csv', index=False)


相关文章:
Python Pandas(3):DataFrame
1 介绍 DataFrame 是 Pandas 中的另一个核心数据结构,类似于一个二维的表格或数据库中的数据表。它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由…...
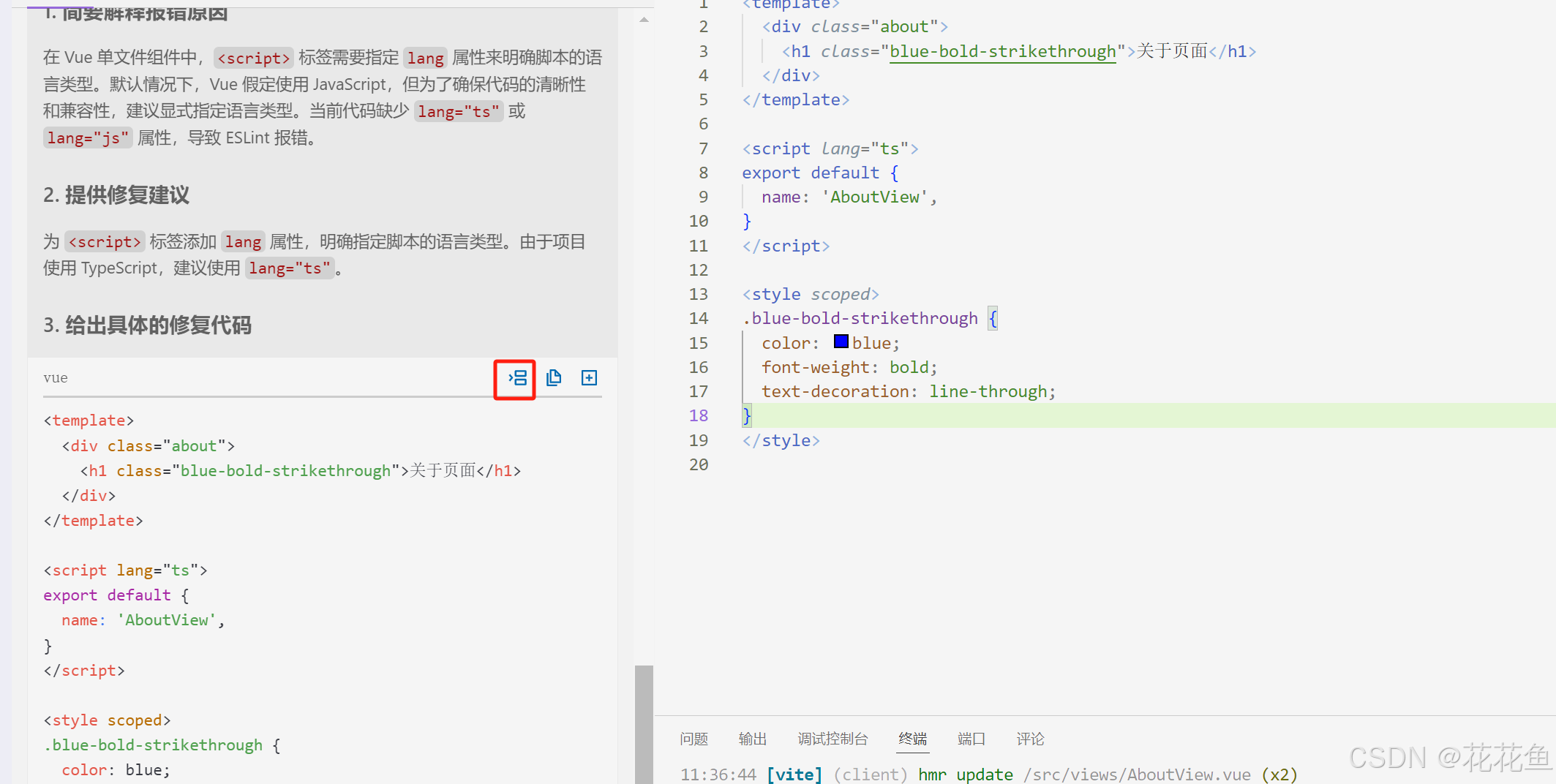
使用通义灵码 ai编程 来提高开发效率
1、我们先新建一个Hello,world的vue3项目(快速上手 | Vue.js) 创建好以后,运行以下界面: about界面如下,现在我们让灵码给我们修改一下这个字体的颜色及加点其它的样式: 2、先选中样式…...

【OpenCV】入门教学
🏠大家好,我是Yui_💬 🍑如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀 🚀如有不懂,可以随时向我提问,我会全力讲解~ ὒ…...

大数据项目4:基于spark的智慧交通项目设计与实现
项目概述 项目直达 www.baiyuntu.com 随着交通数据的快速增长,传统的交通管理方式已无法满足现代城市的需求。交通大数据分析系统通过整合各类交通数据,利用大数据技术解决交通瓶颈问题,提升交通管理效率。本项目旨在通过大数据技术&#…...

netcore openTelemetry+prometheus+grafana
一、netcore项目 二、openTelemetry 三、prometheus 四、grafana添加Dashborad aspire/src/Grafana/dashboards at main dotnet/aspire GitHub 导入:aspnetcore.json和aspnetcore-endpoint.json 效果:...

Spring Boot接入Deep Seek的API
1,首先进入deepseek的官网:DeepSeek | 深度求索,单击右上角的API开放平台。 2,单击API keys,创建一个API,创建完成务必复制!!不然关掉之后会看不看api key!!&…...

Git、Github和Gitee完整讲解:丛基础到进阶功能
第一部分:Git 是什么? 比喻:Git就像是一本“时光机日记本” 每一段代码的改动,Git都会帮你记录下来,像是在写日记。如果出现问题或者想查看之前的版本,Git可以带你“穿越回过去”,找到任意时间…...

MyBatis的工作流程是怎样的?
大家好,我是锋哥。今天分享关于【MyBatis的工作流程是怎样的?】面试题。希望对大家有帮助; MyBatis的工作流程是怎样的? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 MyBatis 的工作流程可以分为几个主要的步骤&…...

Maven 安装配置(完整教程)
文章目录 一、Maven 简介二、下载 Maven三、配置 Maven3.1 配置环境变量3.2 Maven 配置3.3 IDEA 配置 四、结语 一、Maven 简介 Maven 是一个基于项目对象模型(POM)的项目管理和自动化构建工具。它主要服务于 Java 平台,但也支持其他编程语言…...

分享如何通过Mq、Redis、XxlJob实现算法任务的异步解耦调度
一、背景 1.1 产品简介 基于大模型塔斯,整合传统的多项能力(NLP、OCR、CV等),构建以场景为中心的新型智能文档平台。通过文档审阅,实现结构化、半结构化和非结构化文档的信息获取、处理及审核,同时基于大…...

发布:大彩科技DN系列2.8寸高性价比串口屏发布!
一、产品介绍 该产品是一款2.8寸的工业组态串口屏,采用2.8寸液晶屏,分辨率为240*320,支持电阻触摸、电容触摸、无触摸。可播放动画,带蜂鸣器,默认为RS232通讯电平,用户短接屏幕PCB上J5短接点即可切换为TTL电…...

集合类不安全问题
ArrayList不是线程安全类,在多线程同时写的情况下,会抛出java.util.ConcurrentModificationException异常 解决办法: 1.使用Vector(ArrayList所有方法加synchronized,太重) 2.使用Collections.synchronized…...

【基于SprintBoot+Mybatis+Mysql】电脑商城项目之上传头像和新增收货地址
🧸安清h:个人主页 🎥个人专栏:【Spring篇】【计算机网络】【Mybatis篇】 🚦作者简介:一个有趣爱睡觉的intp,期待和更多人分享自己所学知识的真诚大学生。 目录 🚀1.上传头像 -持久…...

AI知识库和全文检索的区别
1、AI知识库的作用 AI知识库是基于人工智能技术构建的智能系统,能够理解、推理和生成信息。它的核心作用包括: 1.1 语义理解 自然语言处理(NLP):AI知识库能够理解用户查询的语义,而不仅仅是关键词匹配。 …...

20240817 联想 笔试
文章目录 1、选择题1.11.21.31.41.51.61.71.81.91.101.111.121.131.141.151.161.171.181.191.202、编程题2.12.2岗位:Linux开发工程师 题型:20 道选择题,2 道编程题 1、选择题 1.1 有如下程序,程序运行的结果为 (D) #include <stdio.h>int main() {int k = 3...

IntelliJ IDEA 安装与使用完全教程:从入门到精通
一、引言 在当今竞争激烈的软件开发领域,拥有一款强大且高效的集成开发环境(IDE)是开发者的致胜法宝。IntelliJ IDEA 作为 JetBrains 公司精心打造的一款明星 IDE,凭借其丰富多样的功能、智能精准的代码提示以及高效便捷的开发工…...

【JVM详解一】类加载过程与内存区域划分
一、简介 1.1 概述 JVM是Java Virtual Machine(Java虚拟机)的缩写,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。由一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域等组成。JVM屏蔽了与操作系统平台相关…...

250207-MacOS修改Ollama模型下载及运行的路径
在 macOS 上,Ollama 默认将模型存储在 ~/.ollama/models 目录。如果您希望更改模型的存储路径,可以通过设置环境变量 OLLAMA_MODELS 来实现。具体步骤如下: 选择新的模型存储目录:首先,确定您希望存储模型的目标目录路…...

Win10 部署llama Factory 推荐教程和遇到的问题
教程 【大模型微调】使用Llama Factory实现中文llama3微调_哔哩哔哩_bilibili 大模型微调!手把手带你用LLaMA-Factory工具微调Qwen大模型!有手就行,零代码微调任意大语言模型_哔哩哔哩_bilibili 遇到问题解决办法 pytorch gpu国内镜像下载…...

如何在Android Studio中开发一个简单的Android应用?
Android Studio是开发Android应用的官方集成开发环境(IDE),它提供了许多强大的功能,使得开发者能够高效地创建Android应用。如果你是Android开发的初学者,本文将引导你如何在Android Studio中开发一个简单的Android应用…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...