Vript-Hard——一个基于高分辨率和详细字幕的视频理解算法
一、概述
多模态学习的最新进展促进了对视频理解和生成模型的研究。随之而来的是,对高分辨率视频和详细说明所建立的高质量数据集的需求激增。然而,由于时间因素的影响,视频与文本的配对不像图像那样容易。准备视频和文本配对是一项困难得多的任务。例如,旅游视频博客(vlog)包括许多旅行准备、住宿和参观旅游景点的场景。为这些视频提供详细而恰当的字幕需要花费大量的时间和精力,因为必须查看视频并根据场景为其添加字幕。因此,目前的情况是,大多数基于视频-文本对建立的传统数据集都是包含简化字幕的短视频。
为了克服这一挑战,本文建立了一个视频-文本数据集Vript,该数据集适用于较长的视频,并且比以前建立的数据集具有更详细的说明。Vript 的注释基于视频脚本的格式,对于每个场景,不仅关注内容,还关注镜头类型和摄像机运动。与传统的数据集不同,本文对未经修剪的视频进行了详细注释,每个场景都有大约 145 个字的长标题。除了视觉信息外,旁白还被转录为文本,并辅以视频标题作为背景信息,从而提高了字幕的信息含量和准确性。
现有研究表明,详细的标题有助于改善视觉和语言关联/映射。然而,如上所述,大多数数据集只包含简短的字幕,并没有密集而详细的注释。因此,本文采用了三种新方法来改进视频与文本之间的关联/映射
- 使用视频脚本
- 通过对多个连续场景进行采样,并将相应的字幕串联起来以生成更长的文本,从而制作出更长的视频。
- 旁白转录
- 结合旁白转录和视频输入。
- 视频时间戳。共轭作用
- 输入旁白和视频时间戳作为附加信息。
在这些方法的基础上,本文还建立了一个名为 "Vriptor "的视频字幕模型,它可以为短视频和长视频生成密集而详细的字幕,在开源模型中达到了 SOTA 性能。
它还提出了一个视频理解基准Vript-Hard,其中包括三个任务(幻觉评估、长视频推理和事件重排),比传统基准更具挑战性。
源码地址:https://github.com/mutonix/Vript.git
论文地址:https://arxiv.org/abs/2406.06040
二、视频字幕详细说明
在构建 Vript 的过程中,本文的目标是尽可能详细地注释视频,以便通过字幕将视频可视化。视频中的每个场景都有字幕描述,重点不是粗略的字幕,而是详细的动作和交互。这里可以描述各种信息,包括物体和人物的外观、环境、光线和视频风格。
它还关注摄像机是如何移动来捕捉图像的。以往的研究将图像字幕用于视频字幕,而没有利用视频特有的摄像机移动信息。例如,对于一个男人骑自行车的视频片段,仅仅解释 "一个穿深蓝色衬衫的男人骑着一辆黑色自行车在路上行驶 "和 "当镜头转到特写镜头时,一个穿深蓝色衬衫的男人骑着一辆黑色自行车 "是不够的。更具体的描述会更有用,例如 “当镜头拉远时,我们看到的是该男子在公路上的概貌,背景是群山”。这样,有关摄像机行为的信息就被添加到了内容中,从而提高了视频字幕的质量。
可以说,将静态情况与摄像机行为信息结合起来,近似于在视频脚本中描述一个场景。因此,Vript 使用 PySceneDetect 根据视频脚本的格式将视频划分为多个场景,并为每个场景标注有关静态情况和摄像机行为的说明。我们称之为 “视频脚本”。然后,本文从 HD-VILA-100M 中选择了10,000 个完整的 YouTube视频,并从 YouTube Shorts 和 TikTok 中选择了1,500 个短视频作为视频数据。GPT-4V 还用于为每个场景注释以下信息。
- 标题:场景摘要(最多 10 个字)
- 内容:约 150 字的详细描述。
- 拍摄类型:全景、特写等。
- 摄像机移动:摇镜头、变焦等。
为了给视频添加高质量的脚本,未经剪辑的视频(长度从 5 秒到 2.9 小时不等)从头到尾都有密集的注释。除视频帧外,还添加了外部信息以帮助注释:使用 Whisper 转录的旁白和视频标题将原始视频内容输入模型。这些外部信息大大减少了错觉,提高了字幕的准确性,使模型能够更好地理解视频内容和视觉信息。
例如,如下图所示,仅凭场景-010 画面无法猜测碗中加入了哪些配料。旁白中的信息显示配料是蛋黄酱和芥末,从而提高了右上角面板中字幕的准确性。

三、Vriptor算法实现
一般来说,在将图像映射到文本时,一个标题映射到一个视频。然而,现有的视频-文本数据集(如 Panda-70M、WebVid-10M)只有简单的标题,缺乏详细信息,这意味着图像-文本关系/映射不够充分。为了解决这个问题,本文研究了如何利用 Vript 数据集将视频映射为更多文本。其结果是建立了一个名为 Vriptor 的强大视频字幕模型,该模型在大型开源视频语言模型中达到了 SOTA 性能。
如果要对视频进行详细注释,有几种可能的方法来增加支持的文本量,其中之一就是将几个连续片段的字幕连接起来。然而,使用这种方法,由于字幕是单独注释的,因此连接字幕的上下文和含义可能不一致。因此,我们参照视频脚本的格式,将连续字幕重构为视频脚本中的场景。Vript 允许通过对若干连续片段进行采样来创建 “子脚本”。例如,十个连续的片段及其相应的 "字幕 "包含约 1,500 个单词,比较短的字幕长约 100 倍 。
由于 Vript 是通过输入旁白和视频帧来进行注释的,因此字幕包含旁白中的信息。
处理视频的常见大规模语言模型采用特定的采样技术来提取视频输入的多个帧,但这些模型对时间的感知能力较弱,只知道帧的顺序,而不知道帧的持续时间。因此,本文认为时间戳对于视频脚本支持非常重要,并在输入旁白和输出字幕中添加了视频时间戳。这使得模型更容易理解每个场景的开始和结束。
这些方法被整合到 Vriptor 的学习中。下图(复制如下)显示了四种不同的输入和输出组合:一个场景到一个字幕、一个场景+旁白到一个字幕、多个场景到一个脚本以及多个场景+旁白到一个脚本。所有组合都添加了时间戳。
我们还在 ST-LLM 的基础上对 Vriptor 进行了两个阶段的训练,并使用 Vript-HAL 和 MSR-VTT 对其字幕能力进行了评估。Vriptor 支持两种字幕类型:"描述整个视频 "和 “描述整个场景”。在描述整个视频时,Vriptor 会提供 100-150 字的一般描述。当逐个场景描述时,Vriptor 会为每个场景提供 100-150 字的详细描述。下表显示,与整个视频描述相比,Vriptor 在逐场景描述中提供了更详细的视频描述,从而提高了召回率。

下图显示了 Vriptor 为长视频加上长文字说明的能力。

下表最后两行(转载于下)显示,添加旁白后,模型可以提供更详细、更准确的描述。此外,字幕中专有名词的比例也增加了 14%。这表明,模型不仅能够通过分析物体的外观,还能通过分析旁白来推断物体的名称。
为了进一步检验时间戳的效果,我们训练了另一个没有附加时间戳的模型,并对这两个模型进行了比较。结果表明,整体视频描述能力略有提高,但逐个场景的描述能力显著提高。添加了时间戳的模型不太可能生成与之前场景重复的描述,因为它能理解每个场景的开始和结束,并能识别哪个场景对应哪个时间段。添加了时间戳的模型在 Vript-HAL 的召回率也高出 12%,这意味着没有添加时间戳的模型更容易忘记解释视频的某些部分。
四、Vript-Hard
随着多模态模型性能的提高,需要更复杂的基准来评估它们的能力。因此,本文提出了一个名为 "Vript-Hard "的新视频理解基准。该基准由三个具有挑战性的任务组成(HAL(幻觉评估)、RR(检索然后推理)和ERO(事件重新排序))。
它还评估了处理图像(如 BLIP2、InstructBLIP、Qwen-VL 和 LLaVA 1.6 34B)和视频(如 VideoChatGPT、VideoLLaMA、VideoChat、VideoChat2 和 ST-LLM)的大规模语言模型。我们正在开展工作。我们还对 Claude 3-Sonnet、Opus 和 GPT-4V 等闭源模型进行了评估。
4.1 Vript-HAL:评估基准
以前的研究已经调查了在处理图像的大规模语言模型中检测和评估幻觉的方法,而处理视频的大规模语言模型也报告了类似的幻觉问题。例如,处理视频的大规模语言模型在被要求描述视频时,可能会曲解对象和行为,并产生包含幻觉的描述。现有的字幕基准(如 MSR-VTT 和 MSVD)不足以评估幻觉,因为它们只有 10 个字或更少的简短字幕,而且缺乏细节。
为了应对这一挑战,我们正在建立一个名为 V "ript-HAL 的基准,该基准为每个 Vript-HAL 视频标注了约 250 个单词的字幕,比 MSR-VTT 长 25 倍。基于这种详细的地面实况字幕,我们可以了解处理视频的大规模语言模型是否会在字幕中产生幻觉。
传统的评估指标(如 BLEU、ROUGE、CIDEr)通过测量预测文本与地面实况文本之间的词语相似度来评估准确度,但不适合评估对象和动作是否被正确描述。因此,本文使用准确度分数来评估字幕中的名词(对象)和动词(动作)是否被正确描述。
由于不同模型的标题长度和细节各不相同,因此还引入了 "回忆 "功能,以衡量 "地面实况 "中物体和行为的描述程度。F1 分数也被计算为幻觉评估的总分。
具体来说,准确率是根据准确描述的对象和动作的数量计算的,召回率则用于评估根据基本事实描述的准确程度。在评估过程中,SpaCy 用于提取名词和动词,而句子转换器则用于创建词嵌入。如果预测结果与地面实况之间的余弦相似度高于一定水平,则认为描述正确。
Vript-HAL评估了处理许多图像的大型语言模型和处理视频的大型语言模型。下图显示,一些模型(如 BLIP2 和 VideoChat2)由于生成的字幕较短,细节较少,因此幻觉较少;Vriptor-W(整个视频)提供了一般描述,而 Vriptor-S(逐个场景)则描述了视频的许多细节、显示出较高的召回率。这两种模型在视频字幕方面的性能与 GPT-4V 不相上下。

4.2 Vript-RR:理解长视频的基准
对一段长视频的细节进行提问可能会产生歧义,例如,在不同的时间戳有多个符合问题的答案,或者答案会随着时间的推移而发生变化。这种模糊性是长视频理解基准(如 EgoShecma)中的常见问题。因此,本文提出了一种名为 Vript-RRR(先检索后推理)的新基准来解决这一问题。
基准首先会为模型提供一个提示,让其在视频中找到与问题相关的场景。该提示是对相关场景的详细描述。然后根据这些场景提出问题,从而消除歧义。在实际操作中,如下图所示,提示和问题与整个视频一起输入,然后模型直接输出答案。这个过程是端到端的。

Vript-RR 对每个问题都精心设计了至少一个推理步骤或额外处理(如文本阅读、详细检查),以评估大型语言模型处理视频的不同能力。问题的设计方式如下。
Vript-RR 包括两个基于视频输入的子任务:一个是针对整个视频的子任务,另一个是直接针对相关场景的子任务。 Vript-RR 同时提供选择格式和开放式问题。对于开放式输出,GPT-4 turbo 被用作判断标准,通过比较预测结果和地面实况来评估答案是否正确。
如下表所示,"场景 "一栏表示使用相关场景作为输入的结果,这是一项较为简单的任务, 因为它不需要模型搜索整个视频来查找相关场景。整段 "栏使用整段视频作为输入,要求模型使用提示来查找相关场景,这就要求模型具有理解整段视频的能力。

对于每个 Vript-RR视频,我们都设计了一些问题,分别取自视频中 15%、40%、60% 和 85% 的场景。这样我们就可以研究场景在视频中的时间位置是否会影响 Vript-RR 的结果。该模型需要通过视觉标记而不是文本标记找到 “针”(相关场景)。在这项任务中,我们观察到当 "针 "位于长上下文的 15% 到 85% 之间时,模型的性能会明显下降,尤其是当文本长度至少超过 16K 标记时。如下图所示,当场景位于视觉标记中间(视频的 40% 和 60%)时,虽然视觉标记的数量远小于 16K 个,但大多数模型的性能都有所下降。

4.3 Vript-ERO:长视频时间理解基准
有些基准测试模型的时间理解能力。然而,这些基准测试主要集中在短片中动作的时间排序问题上,很少有人探索长视频中事件的时间理解问题。为了填补这一空白,本文提出了 Vript-ERO(事件重新排序)任务。在这项任务中,从一段长视频(2 分钟至 2 小时不等)中抽取三个具有不同时间戳的不同场景(平均 10 秒),并对它们的时间顺序进行调整。如下图所示,根据对特征视频和三个洗牌场景的详细描述,模型需要在理解整个视频的基础上回答场景的正确时间顺序。

在下表中(转载于后),"-"表示这些模型无法提供答案。与之前的任务不同,Vript-ERO 还包括对场景的长篇描述,这表明模型在处理长篇指令方面能力较弱。即使是得分较高的模型,也只有大约 20% 的问题可以按照所有三个场景的正确顺序来回答。
下图收集了答错的问题答案,并分析了原因。据观察,模型很容易被所提供的描述误解:在 31.4%的情况下,这是由于输入帧中缺少某些事件,因为 GPT-4V 等模型的输入图像数量有限。此外,在 25.1%的情况下,模型无法识别哪些场景应根据描述进行排序。

五、源码配置
5.1 环境安装
git clone https://github.com/mutonix/Vript.git
conda create -n vript python=3.8 -y
conda activate vript
pip install -r requirements.txt
python -m spacy download en_core_web_lg
5.2 测试调用
title = video_info["title"]
if title:title_instruction = f'from a video titled "{title}" '
else:title_instruction = ""for scene in scene_dir:content = []voiceover_instruction = ""if scene in voiceovers_dict and 'short' not in args.video_dir:voiceover = voiceovers_dict[scene]if voiceover['full_text'].strip():voiceover_text = voiceover['full_text'].strip() content.append({"type": "text", "text": f"Voice-over: {voiceover_text}\nVideo frames:"})voiceover_instruction = "voice-over and "else:voiceover_text = ""else:voiceover_text = ""scene_imgs = os.listdir(os.path.join(args.video_dir, vdir, scene))scene_imgs = [i for i in scene_imgs if i.endswith(".jpg")]scene_imgs = sorted(scene_imgs, key=lambda x: int(x.split('.')[0].split('_')[-1]))encoded_scene_imgs = []for scene_img in scene_imgs:encoded_scene_img = encode_image(os.path.join(args.video_dir, vdir, scene, scene_img))encoded_scene_imgs.append(encoded_scene_img)content.append({"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{encoded_scene_img}", "detail": "low"}})content.append({"type": "text", "text": f"""
Based on the {voiceover_instruction}successive frames {title_instruction}above, please describe:
1) the shot type (15 words)
2) the camera movement (15 words)
3) what is happening as detailed as possible (e.g. plots, characters' actions, environment, light, all objects, what they look like, colors, etc.) (150 words)
4) Summarize the content to title the scene (10 words)
Directly return in the json format like this:
{{"shot_type": "...", "camera_movement": "...", "content": "...", "scene_title": "..."}}. Do not describe the frames individually but the whole clip.
"""})messages=[{"role": "system","content": "You are an excellent video director that can help me analyze the given video clip."},{"role": "user","content": content}]
五.总结
近年来,多模态学习的进步使人们越来越关注理解和生成视频的模型。这导致了对具有高分辨率视频和详细说明的高质量视频文本数据集的需求激增。然而,由于视频中增加了时间成分,因此获取和注释视频-文本对要比获取和注释图像-文本对更加困难。例如,旅游视频博客包含许多事件,每个事件由不同的场景组成,如准备旅行或参观目的地。视频字幕需要花费大量的时间和精力来查看整个视频并标注细节。因此,传统的视频文本数据集通常只包含简短粗糙的描述。
为了克服这些挑战,本文提出了一个高质量的视频文本数据集 “Vript”,其中包含密集而详细的字幕。在此基础上,我们还建立了一个视频字幕模型 Vriptor 和一个具有挑战性的基准Vript-Hard,前者是性能最好的开源模型,后者用于评估处理视频的大规模语言模型的幻觉和长视频理解能力。Vriptor 擅长为短视频和长视频生成密集字幕,其性能在开源模型中名列前茅。
这项研究提出了一种加深视频与文本之间对应关系的新方法,不仅提高了视频字幕模型的性能,还为评估模型的理解能力提供了新的基准。它有望为未来的研究和实际应用做出贡献。
相关文章:
Vript-Hard——一个基于高分辨率和详细字幕的视频理解算法
一、概述 多模态学习的最新进展促进了对视频理解和生成模型的研究。随之而来的是,对高分辨率视频和详细说明所建立的高质量数据集的需求激增。然而,由于时间因素的影响,视频与文本的配对不像图像那样容易。准备视频和文本配对是一项困难得多…...

react脚手架搭建react项目使用scss
1.create-react-app 创建的项目,webpack配置默认是隐藏的 ,如果要查看 或修改用npm run eject命令,因为create-react-app脚手架默认已经配置了scss、sass所以不用改webpack配置。如果用less 就需要自己添加配置 2.如果直接使用scss的文件会直接报错&…...

Vue.js 状态管理库Pinia
Pinia Pinia :Vue.js 状态管理库Pinia持久化插件-persist Pinia :Vue.js 状态管理库 Pinia 是 Vue 的专属状态管理库,它允许你跨组件或页面共享状态。 要使用Pinia ,先要安装npm install pinia在main.js中导入Pinia 并使用 示例…...

【Stable Diffusion部署至GNU/Linux】安装流程
以下是安装Stable Diffusion的步骤,以Ubuntu 22.04 LTS为例子。 显卡与计算架构介绍 CUDA是NVIDIA GPU的专用并行计算架构 技术层级说明CUDA Toolkit提供GPU编译器(nvcc)、数学库(cuBLAS)等开发工具cuDNN深度神经网络加速库(需单独下载)GPU驱动包含CUDA Driver(需与CUDA …...

【C/C++算法】从浅到深学习---滑动窗口(图文兼备 + 源码详解)
绪论:冲击蓝桥杯一起加油!! 每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本章是算法训练的第二章----滑动窗口,它的本质是双指针算法的衍生所以我将…...

计算机毕业设计SpringBoot+Vue.js房源推荐系统 房价预测 房源大数据分析可视化(源码+文档+运行视频+讲解视频)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

开源机器人+具身智能 解决方案+AI
开源机器人、具身智能(Embodied Intelligence)以及AI技术的结合,可以为机器人领域带来全新的解决方案。以下是这一结合的可能方向和具体方案: 1. 开源机器人平台 开源机器人平台为开发者提供了灵活的基础架构,可以在此基础上结合具身智能和AI技术。以下是一些常用的开源机…...

通过 VBA 在 Excel 中自动提取拼音首字母
在excel里面把表格里的中文提取拼音大写缩写怎么弄 在Excel中,如果你想提取表格中的中文字符并转换为拼音大写缩写(即每个汉字的拼音首字母的大写形式),可以通过以下步骤来实现。这项工作可以分为两个主要部分: 提取拼…...

华硕笔记本怎么一键恢复出厂系统_华硕笔记本一键恢复出厂系统教程
华硕笔记本怎么一键恢复出厂系统? 华硕一键恢复出厂系统是一个安全、高效、方便的恢复方式,让您轻松还原出厂设置,以获得更好的系统性能。如果您的华硕电脑遇到问题,可以使用华硕一键恢复出厂系统功能。下面小编就教大家华硕笔记本…...

Ubuntu 如何安装Snipaste截图软件
在Ubuntu上安装Snipaste-2.10.5-x86_64.AppImage的步骤如下: 1. 下载Snipaste AppImage 首先,从Snipaste的官方网站或GitHub Releases页面下载Snipaste-2.10.5-x86_64.AppImage文件。 2. 赋予执行权限 下载完成后,打开终端并导航到文件所在…...

【离散数学上机】T235,T236
T235题目:输入集合A和B,输出A到B上的所有单射函数。 问题描述 给定非空数字集合A和B,求出集合A到集合B上的所有单射函数。 输入格式 第一行输入m和n(空格间隔),分别为集合A和集合B中的元素个数;…...
)
【Android开发】安卓手机APP使用机器学习进行QR二维码识别(完整工程资料源码)
前言:本项目是一个 Android 平台的二维码扫描应用,具备二维码扫描和信息展示功能。借助 AndroidX CameraX 库实现相机的预览、图像捕获与分析,使用 Google ML Kit 进行二维码识别。为方便大家了解项目全貌,以下将介绍项目核心代码文件 MainActivity.java 和 AndroidManifes…...

【油猴脚本/Tampermonkey】DeepSeek 服务器繁忙无限重试(20250214优化)
目录 一、 引言 二、 逻辑 三、 源代码 四、 添加新脚本 五、 使用 六、 BUG 七、 优化日志 1.获取最后消息内容报错 2.对话框切换无法正常使用 一、 引言 deepseek演都不演了,每次第一次提问就正常,后面就开始繁忙了,有一点阴招全…...
为deepseek搭建本地页面
搭建页面的框架多种多样,例如python中的flask、django等,再如java中的spring框架等等。你使用什么语言、什么框架都无所谓,重要的是设计思路。这里UP以node.js中的express框架为例来为deepseek搭建一个本地页面。 一、ollama的下载、安装和加载 deepseek本地部署-CSDN博客…...
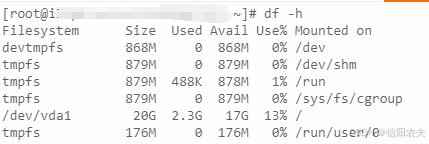
详解df -h命令
df -h 是 Linux 中用于查看文件系统磁盘空间使用情况的命令。以下是详细说明: 命令格式 df -h 选项说明 -h:以易读格式(如 KB、MB、GB)显示磁盘空间。 输出字段 Filesystem:文件系统的设备名或挂载点。 Size&…...

虚拟环境测试部署应用
一、作用 虚拟环境(env)在计算机领域,特别是在软件开发和测试中扮演着重要角色。它主要用于创建一个隔离的环境,使得开发者可以在不影响系统其余部分的情况下安装、配置和运行软件项目。以下是虚拟环境的一些主要作用: 1、依赖管理 不同的项目可能需要不同版本的库或框…...

CentOS本机配置为时间源
CentOS本机配置为时间源 安装chrony,默认已安装修改配置文件 /etc/chrony.conf客户端配置 安装chrony,默认已安装 yum -y install chrony修改配置文件 /etc/chrony.conf # cat /etc/chrony.conf | grep -Ev "^$|#" server ceph00 iburst dri…...

蓝桥杯备赛 Day14 素数环
信息学奥赛一本通(C版)在线评测系统 【题目描述】 输入正整数nn,把整数11,22,…,nn 组成一个环,使得相邻两个整数之和均为素数。 【输入】 输入正整数nn。 【输出】 输出任意一个满足条件的环。 【输入样例】 6 【输出样例】 …...

小程序canvas2d实现横版全屏和竖版逐字的签名组件(字帖式米字格签名组件)
文章标题 01 功能说明02 效果预览2.1 横版2.2 竖版 03 使用方式04 横向签名组件源码4.1 html 代码4.2 业务 Js4.3 样式 Css 05 竖向签名组件源码5.1 布局 Html5.2 业务 Js5.3 样式 Css 01 功能说明 技术栈:uniapp、vue、canvas 2d 需求: 实现横版的全…...

haproxy详解笔记
一、概述 HAProxy(High Availability Proxy)是一款开源的高性能 TCP/HTTP 负载均衡器和代理服务器,用于将大量并发连接分发到多个服务器上,从而提高系统的可用性和负载能力。它支持多种负载均衡算法,能够根据服务器的…...

Chopstick工具:高效管理多Git仓库的批量操作与自动化实践
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫 chopstick ,作者是DustinMeyer1010。光看名字你可能会联想到筷子,但它的实际功能跟餐具可没半点关系。这是一个专门用于 代码仓库(Repository)克隆…...

【2026前沿】LTX 2.3 深度实战:结合 Gemma 4完全体 打造电影级文生视频/图生视频全流程
一、 为什么 LTX 2.3 是 2026 年视频生成的“性价比之王”?LTX 2.3 在保留了上一代高速生成特性的基础上,在 VAE(变分自编码器) 进行了重构。相比于 LTX 2.0,它的核心优势在于:原生纵向支持:不再…...

XMem实战教程:从DAVIS到YouTubeVOS数据集的完整评估流程
XMem实战教程:从DAVIS到YouTubeVOS数据集的完整评估流程 【免费下载链接】XMem [ECCV 2022] XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model 项目地址: https://gitcode.com/gh_mirrors/xm/XMem 你是否正在寻找一个强大…...

如何免费解密网易云音乐NCM文件:终极指南释放你的音乐自由
如何免费解密网易云音乐NCM文件:终极指南释放你的音乐自由 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾在网易云音乐下载了心爱的歌曲,却发现只能在特定客户端播放?那些加密的NCM格式文…...

XYBot V2:基于Python的插件化微信机器人框架开发与部署指南
1. 项目概述:一个功能丰富的微信机器人框架最近在折腾一个挺有意思的开源项目,叫XYBot V2。简单来说,它是一个基于Python的微信机器人框架,能让你在微信里实现各种自动化交互和趣味功能。项目作者HenryXiaoYang已经声明因个人原因…...

SVG 滤镜:全面解析与高效应用
SVG 滤镜:全面解析与高效应用 引言 SVG(可缩放矢量图形)作为一种广泛使用的图形格式,因其具有高度的可缩放性和跨平台性而备受青睐。SVG 滤镜作为 SVG 的一项强大功能,能够实现丰富的图形效果,提升图形的表…...

LLMs之Benchmarks:《ProgramBench: Can Language Models Rebuild Programs From Scratch?》翻译与解读
LLMs之Benchmarks:《ProgramBench: Can Language Models Rebuild Programs From Scratch?》翻译与解读 导读:ProgramBench 把软件工程 agent 的评测从“局部修补”推进到“从零重建程序”,通过程序文档、行为级测试和 agent-driven fuzzing …...

LLM应用可观测性实战:基于OpenTelemetry与OpenLLMetry的监控方案
1. 项目概述:当LLM应用遇见可观测性如果你正在开发或维护一个基于大语言模型的应用,那么下面这个场景你一定不陌生:用户反馈说“AI助手刚才的回答很奇怪”,或者“昨天还能正常调用的功能今天突然报错了”。你打开日志,…...

Memorix分布式内存缓存系统:架构解析与部署实践
1. 项目概述:Memorix,一个为现代应用设计的分布式内存缓存系统如果你正在构建一个需要处理高并发请求、对响应延迟有苛刻要求的应用,比如一个实时排行榜、一个秒杀系统,或者一个需要频繁读取用户会话的社交平台,那么你…...

企者不立,跨者不行,SAP UI5 开发里的克制、分寸与长久之道
老子这句话放到 SAP UI5 开发里看,并不是在劝开发者不进取,也不是叫我们少写功能、少做创新。它真正提醒的是,企业级前端开发最怕一种姿态,脚尖踮得很高,步子跨得很大,心里急着证明自己聪明,手上急着把每一个需求都做成个性化杰作。SAP UI5 最终运行在 SAP Fiori Launch…...