LeetCode 热门100题-字母异位词分组
2.字母异位词分组
题目描述:
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
示例 1:
输入: strs =
["eat", "tea", "tan", "ate", "nat", "bat"]输出:
[["bat"],["nat","tan"],["ate","eat","tea"]]给定的是vector<string>类型的容器,输出的是vector<vector<string>>类型的容器。
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string,vector<string>> anagrams;for(const string& str:strs){string sortedstr = str;sort(sortedstr.begin(),sortedstr.end());anagrams[sortedstr].emplace_back(str);}vector<vector<string>> result;for(const auto&pair:anagrams){result.emplace_back(pair.second);}return result;
}
};实现逻辑:使用for循环遍历strs,对每一个strs[i]对应的单词进行sort排序,如tea和eat都会被排序为aet,对每个单词排序后的结果作为键,如果该键不存在于哈希表中,则创建新元素<key,value>,如果键已存在,则将新单词加入键所对应的vector中,比如开始遍历实例中给的vector容器时,eat和tea经过排序后,都对应aet这个键,遍历eat时,哈希表中开始创建了<aet,{eat}>,当遍历到tea时,哈希表就成了<aet,{eat,tea}>。而后再对遍历完所有strs后的哈希表进行遍历,将其所有元素中存在的值都加入result中,最后result就会成为[["bat"],["nat","tan"],["ate","eat","tea"]]的形式,那么只需返回result就行。
代码解释:
unordered_map<string,vector<string>> anagrams;创建string,vector<string>类型的哈希表anagrams;
for(const string& str:strs)使用for循环对strs中的每一个元素都取别名,const string& str:strs是C++中对容器元素进行遍历的代码。
sort(sortedstr.begin(),sortedstr.end());使用sort对sortedstr进行排序,这里是把sortedstr也当作了一个容器,不过是char类型,按照begin()和end()迭代器作为sort的起始和终结条件。如果sortedstr对应eat,排序后,它就成为aet。
anagrams[sortedstr].emplace_back(str);,按照键:sortedstr往哈希表中插入元素str,其实此时sortedstr也就是str所对应的排序好后的键,string sortedstr = str;这也就是为什么要加这一句代码。
----anagrams[sortedstr]:首先尝试在 anagrams 哈希表中查找键为 sortedstr 的元素。如果找到,则返回该键对应的 vector<string>;如果没有找到,则会创建一个新的 vector<string> 并将其与 sortedstr 键关联起来,然后返回这个新的向量。
----.emplace_back(str):这是在向由 anagrams[sortedstr] 返回的向量中添加元素的一种方式。emplace_back() 方法与push_back() 方法类似,都是向容器末尾添加元素。但是,emplace_back() 更加高效,因为它是在容器的末尾直接构造对象,而不是先创建对象再复制或移动它进入容器。这意味着如果 emplace_back() 的参数正好匹配要插入元素的构造函数参数,则可以直接在容器的存储空间上进行构造,避免不必要的拷贝或移动操作。
unordered_map<string,vector<string>> 类型的容器 anagrams。这里的pair 实际上代表 anagrams 中的每一个键值对(即每一个元素),其中 pair.first 对应键(在这个场景下是排序后的字符串),而 pair.second 对应值(即一组异位词组成的 vector<string>)。比如经过前面的代码,那么anagrams中元素的存在形式可能是这样的 [{abt,["bat"]},{ant,["nat","tan"]},{aet,["ate","eat","tea"]}],那么每一次遍历pair.second就对应着["bat"]、["nat","tan"]、["ate","eat","tea"]这几个容器。,而后将其插入至result中。
最后将result返回即可。
相关文章:

LeetCode 热门100题-字母异位词分组
2.字母异位词分组 题目描述: 给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。 字母异位词 是由重新排列源单词的所有字母得到的一个新单词。 示例 1: 输入: strs ["eat", "tea", "tan&q…...

耐张线夹压接图片智能识别
目录 一、图片压接部位定位1、图像准备2、人工标注3、训练4、推理5、UI界面 压接状态智能识别 一、图片压接部位定位 ,往往X射线照片是一个大图,进行图片压接部位定位目的是先找到需识别的部位,再进行识别时可排除其他图像部位的干扰&#x…...
)
ADC 的音频实验,无线收发模块( nRF24L01)
nRF24L01 采用 QFN20 封装,有 20 个引脚,以下是各引脚的详细介绍: 1. 电源引脚 ◦ VDD:电源输入端,一般接 3V 电源,为芯片提供工作电压,供电电压范围为 1.9V~3.6V。 ◦ VSS…...

企业SSL 证书管理指南
文章从以下几个部分展开 SSL证书的用途和使用场景SSL证书的申请类型和实现方式SSL证书的管理SSL证书的续签 一、SSL 证书的用途和使用场景 1.1 为什么要使用 SSL 证书? 1. 数据安全 🛡️- 在 HTTP 传输中,TCP 包可以被截获,攻…...

Python Pandas(7):Pandas 数据清洗
数据清洗是对一些没有用的数据进行处理的过程。很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。数据清洗与预处理的常见步骤: 缺失值处理:识别并…...

南京观海微电子----整流滤波电路实用
01 变压电路 通常直流稳压电源使用电源变压器来改变输入到后级电路的电压。电源变压器由初级绕组、次级绕组和铁芯组成。初级绕组用来输入电源交流电压,次级绕组输出所需要的交流电压。通俗的说,电源变压器是一种电→磁→电转换器件。即初级的交流电转化…...

【python】向Jira测试计划下,附件中增加html测试报告
【python】连接Jira获取token以及jira对象 # 往 jira 测试计划下面,上传测试结果html def put_jira_file(plain_id):# 配置连接jiraconn ConnJira()jira conn.jira_login()[2]path jira.issue(O45- plain_id)attachments_dir os.path.abspath(..) \\test_API…...

探索ChatGPT背后的前端黑科技
由于图片和格式解析问题,可前往 阅读原文 在人工智能与互联网技术飞速发展的今天,像ChatGPT这样的智能对话系统已经成为科技领域的焦点。它不仅能够进行自然流畅的对话,还能以多种格式展示内容,为用户带来高效且丰富的交互体验。然…...

Agents Go Deep 智能体深入探索
Agents Go Deep 智能体深入探索 核心事件 OpenAI发布了一款先进的智能体“深度研究”,它能借助网络搜索和推理生成研究报告。 最新进展 功能特性:该智能体依据数百个在线资源生成详细报告,目前仅支持文本输出,不过很快会增加对图…...

DeepSeek全生态接入指南:官方通道+三大云平台
DeepSeek全生态接入指南:官方通道三大云平台 一、官方资源入口 1.1 核心交互平台 🖥️ DeepSeek官网: https://chat.deepseek.com/ (体验最新对话模型能力) 二、客户端工具 OllamaChatboxCherry StudioAnythingLLM …...

c++TinML转html
cTinML转html 前言解析解释转译html类定义开头html 结果这是最终效果(部分):  前言 在python.tkinter设计标记语言(转译2-html)中提到了将Ti…...

STM32硬件SPI函数解析与示例
1. SPI 简介 SPI(Serial Peripheral Interface)即串行外设接口,是一种高速、全双工、同步的通信总线,常用于微控制器与各种外设(如传感器、存储器等)之间的通信。STM32 系列微控制器提供了多个 SPI 接口&a…...
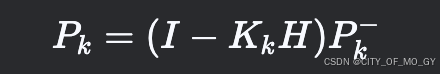
滤波器:卡尔曼滤波
卡尔曼滤波(Kalman Filter)是一种高效的递归算法,主要用于动态系统的状态估计。它通过结合系统模型和噪声干扰的观测数据,实现对系统状态的最优估计(在最小均方误差意义下)。以下从原理、使用场景和特点三个…...
深度学习框架探秘|TensorFlow vs PyTorch:AI 框架的巅峰对决
在深度学习框架中,TensorFlow 和 PyTorch 无疑是两大明星框架。前面两篇文章我们分别介绍了 TensorFlow(点击查看) 和 PyTorch(点击查看)。它们引领着 AI 开发的潮流,吸引着无数开发者投身其中。但这两大框…...

Windows环境管理多个node版本
前言 在实际工作中,如果我们基于Windows系统开发,同时需要维护老项目,又要开发新项目,且不同项目依赖的node版本又不同时,那么就需要根据项目切换不同的版本。本文使用Node Version Manager(nvm࿰…...

opencascade 源码学习BRepBuilderAPI-BRepBuilderAPI
BRepBuilderAPI BRepBuilderAPI 是一个用于构建和操作 BRep(边界表示法,Boundary Representation)拓扑数据结构的工具类。它提供了高级接口,用于创建几何形状(如顶点、边、面、实体等)以及进行扫掠&#x…...

Vue 2 + Webpack 项目中集成 ESLint 和 Prettier
在 Vue 2 Webpack 项目中集成 ESLint 和 Prettier 可以帮助你规范代码风格并自动格式化代码。以下是详细的步骤: 1. 安装 ESLint 和 Prettier 相关依赖 在项目根目录下运行以下命令,安装 ESLint、Prettier 和相关插件: npm install --save…...

Renesas RH850 EEL库的优点
文章目录 1. 磨损均衡(Wear Leveling)2. 数据抽象与易用性3. 后台维护与自动刷新4. 多优先级操作5. ECC 错误处理与数据完整性EEL 与 FDL 的协作机制1. 分层架构2. 存储池划分3. 协作流程4. 同步与互斥5. 性能优化实际应用场景示例场景:车辆里程存储总结1. 磨损均衡(Wear L…...

torch导出ONNX模型报错:OnnxExporterError: Module onnx is not installed
问题: 使用torch 导出模型为onnx文件时报错:torch.onnx.OnnxExporterError: Module onnx is not installed! 环境: 操作系统 Win10 python运行环境 Anacoda3 torch 2.6.0 torchvision …...

LabVIEW 用户界面设计基础原则
在设计LabVIEW VI的用户界面时,前面板的外观和布局至关重要。良好的设计不仅提升用户体验,还能提升界面的易用性和可操作性。以下是设计用户界面时的一些关键要点: 1. 前面板设计原则 交互性:组合相关的输入控件和显示控件&#x…...

CAN 总线技术综合研究报告
CAN总线技术综合研究报告 报告日期: 2026年5月14日 引言 在当今高度信息化和自动化的世界中,设备内部以及设备之间的可靠通信是实现复杂功能的基石。从汽车的动力控制到工厂的自动化生产线,都需要一个高效、可靠的通信网络来协调各个控制单元的工作。控制器局域网(Contr…...

2025届毕业生推荐的五大降AI率平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当前,在生成式AI普及应用这个阶段,内容辨识度偏高这种情况࿰…...

2026年,想找A研发公司?这些关键选择要点你不可不知!
在科技飞速发展的2026年,AI技术已经广泛应用于各个领域,众多企业都希望借助AI研发公司的力量来提升自身竞争力。然而,面对市场上众多的AI研发公司,如何做出正确的选择成为了一大难题。下面就为大家介绍一些选择AI研发公司的关键要…...

Python操控Photoshop的终极指南:如何用代码实现高效图像处理自动化
Python操控Photoshop的终极指南:如何用代码实现高效图像处理自动化 【免费下载链接】photoshop-python-api Python API for Photoshop. 项目地址: https://gitcode.com/gh_mirrors/ph/photoshop-python-api 如果你还在手动重复Photoshop操作,那么…...

开源AR虚拟试衣项目openclaw-genpark-ar-tryon核心技术解析与实践
1. 项目概述:当AR试衣遇见开源社区最近在逛GitHub的时候,偶然发现了一个挺有意思的项目,叫openclaw-genpark-ar-tryon。光看名字,一股浓浓的“开源”和“增强现实”味儿就扑面而来了。点进去一看,果然,这是…...

告别Windows!手把手教你用Proxmox虚拟机零成本体验深度Deepin 20.6
在Proxmox虚拟环境中优雅体验Deepin:技术爱好者的零成本尝鲜指南 对于技术爱好者而言,尝试新操作系统总伴随着两难:既想深度体验系统特性,又担心影响现有工作环境。Proxmox VE作为开源的虚拟化平台,配合Deepin这一国产…...

Windows Cleaner终极指南:5个技巧让C盘空间瞬间释放
Windows Cleaner终极指南:5个技巧让C盘空间瞬间释放 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设计的开源…...

PowerToys深度解析:Windows生产力工具集的高级配置与性能调优
PowerToys深度解析:Windows生产力工具集的高级配置与性能调优 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trending/po/Po…...

逆向工程实现GitHub Copilot HTTP API:解锁AI代码补全的无限集成可能
1. 项目概述:一个反向工程的“桥梁”如果你是一名开发者,并且对 GitHub Copilot 的智能代码补全能力印象深刻,但同时又希望能在自己偏爱的编辑器、IDE,甚至是命令行工具里直接调用它的能力,那么purocean/expose-github…...

开源技能管理工具rei-skills:从零构建个人技术能力图谱
1. 项目概述与核心价值 最近在折腾个人知识库和技能树管理,发现了一个挺有意思的开源项目 rootcastleco/rei-skills 。这项目名字乍一看有点神秘, rei 在日语里是“零”或“灵”的意思,结合 skills ,我理解它想表达的是一种…...