LlamaFactory可视化模型微调-Deepseek模型微调+CUDA Toolkit+cuDNN安装
LlamaFactory
https://llamafactory.readthedocs.io/zh-cn/latest/

安装
必须保证版本匹配,否则到训练时,找不到gpu cuda。
否则需要重装。下面图片仅供参考。因为cuda12.8装了没法用,重新搞12.6
| cuda | cudnn | pytorch |
|---|---|---|
| 12.6 | 9.6 | 12.6 |
| 最新:12.8 | 9.7.1 | 无 |
Windows
CUDA 安装
打开
设置,在关于中找到Windows规格 保证系统版本在以下列表中:
windows11 如下

支持版本号
Microsoft Windows 11 21H2
Microsoft Windows 11 22H2-SV2
Microsoft Windows 11 23H2
Microsoft Windows 10 21H2
Microsoft Windows 10 22H2
Microsoft Windows Server 2022
安装之前确认版本
在命令提示符也就是cmd中输入nvidia-smi.exe,查看你电脑支持的cuda最高版本。(第一行最后)
这个的话必须要有显卡!

选择对应的版本下载并根据提示安装。


如果自己使用不了最新版本,根据自己配置,下载对应的版本,如下图:

安装CUDA完成
打开 cmd 输入 nvcc -V ,若出现类似内容则安装成功。

否则,检查系统环境变量,保证 CUDA 被正确导入。
cuDNN安装
cuDNN(CUDA Deep Neural Network library)是一个由NVIDIA开发的深度学习GPU加速库,旨在为深度学习任务提供高效、标准化的原语(基本操作)来加速深度学习框架在NVIDIA GPU上的运算。

选择对应版本进行下载。如果当前界面没有你需要的版本,可访问如下历史版本页面进行下载:
https://developer.nvidia.com/rdp/cudnn-archive
解压后,目录结构如图:

将目录bin、lib、include复制到CUDA的安装目录下(LICENSE除外),可以先对CUDA安装目录下的这三个目录做备份,以免出现覆盖无法恢复。如图:
默认安装:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8

最后将如下path添加到环境变量Path中:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\libnvvp
验证
配置完成后,我们可以验证是否配置成功,主要使用CUDA内置的deviceQuery.exe 和 bandwithTest.exe:
首先win+R启动cmd,cd到CUDA安装目录下的…\extras\demo_suite,然后分别执行bandwidthTest.exe和deviceQuery.exe,应该得到下图:
执行测试CUDA是否可用GPU


LLaMA-Factory 安装
在安装 LLaMA-Factory 之前,请确保您安装了下列依赖:
运行以下指令以安装 LLaMA-Factory 及其依赖:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
如果出现环境冲突,请尝试使用 pip install --no-deps -e . 解决
LLaMA-Factory 校验
完成安装后,可以通过使用 llamafactory-cli version 来快速校验安装是否成功
如果您能成功看到类似下面的界面,就说明安装成功了。

Windows
QLoRA
如果您想在 Windows 上启用量化 LoRA(QLoRA),请根据您的 CUDA 版本选择适当的 bitsandbytes 发行版本。
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
FlashAttention-2
如果您要在 Windows 平台上启用 FlashAttention-2,请根据您的 CUDA 版本选择适当的 flash-attention 发行版本。
其他依赖

数据处理
https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html
目前我们支持 Alpaca 格式和 ShareGPT 格式的数据集。
Alpaca
-
指令监督微调数据集
指令监督微调(Instruct Tuning)通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。
instruction 列对应的内容为人类指令, input 列对应的内容为人类输入, output 列对应的内容为模型回答。下面是一个例子
"alpaca_zh_demo.json" {"instruction": "计算这些物品的总费用。 ","input": "输入:汽车 - $3000,衣服 - $100,书 - $20。","output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。" },进行指令监督微调时, instruction 列对应的内容会与 input 列对应的内容拼接后作为最终的人类输入,即人类输入为 instruction\ninput。而 output 列对应的内容为模型回答。 在上面的例子中,人类的最终输入是:
计算这些物品的总费用。 输入:汽车 - $3000,衣服 - $100,书 - $20。模型的回答是:
汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。如果指定,
system列对应的内容将被作为系统提示词。history列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]} ]下面提供一个 alpaca 格式 多轮 对话的例子,对于单轮对话只需省略 history 列即可。
[{"instruction": "今天的天气怎么样?","input": "","output": "今天的天气不错,是晴天。","history": [["今天会下雨吗?","今天不会下雨,是个好天气。"],["今天适合出去玩吗?","非常适合,空气质量很好。"]]} ]对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
```"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"} } -
预训练数据集

-
偏好数据集
-
KTO 数据集
-
多模态数据集
ShareGPT
- 指令监督微调数据集
- 偏好数据集
- OpenAI格式
WebUI
LLaMA-Factory 支持通过 WebUI 零代码微调大语言模型。 在完成 安装 后,您可以通过以下指令进入 WebUI:
llamafactory-cli webui

http://localhost:7860/
WebUI 主要分为四个界面:训练、评估与预测、对话、导出。

训练模型
在开始训练模型之前,您需要指定的参数有:
- 模型名称及路径
- 训练阶段
- 微调方法
- 训练数据集
- 学习率、训练轮数等训练参数
- 微调参数等其他参数
- 输出目录及配置路径
随后,您可以点击 开始 按钮开始训练模型。
关于
断点重连:适配器断点保存于output_dir目录下,请指定 适配器路径 以加载断点继续训练。如果您需要使用自定义数据集,请在
data/data_info.json中添加自定义数据集描述并确保 数据集格式 正确,否则可能会导致训练失败。
示例
在example目录中有大量的示例可供参考。
参照配置
NOTE: 学习率 5e-5 = 0.0005 太小了,梯度下降慢。这里调整到0.001.下图是0.001 的loss函数下降的图。
- 梯度下降就是对损失函数求最小值的过程。

LLaMA-Factory\examples\README_zh.md记录各种微调配置和执行脚本
数据集例子
这里直接使用原有的identity文件微调
替换原LLaMA-Factory\data\identity.json文件中:{{name}} 为 小羽,{{author}} 为 嘉羽很烦
预览片段:
[{"instruction": "hi","input": "","output": "Hello! I am 小羽, an AI assistant developed by 嘉羽很烦. How can I assist you today?"},{"instruction": "hello","input": "","output": "Hello! I am 小羽, an AI assistant developed by 嘉羽很烦. How can I assist you today?"},...
对话模板选择deepseek3,官方有说明

这里注意一下
- 需要LlamaFactory在那个目录启动,这里test-dataset就放在那个目录
- 目录下需要包含dataset_info.json. 这是数据集描述文件。参考:安装目录下
data/dataset_info.json{"identity": {"file_name": "identity.json"} }

预览一下数据集,是否争取正确 修改输出目录
修改输出目录

修改配置后,点击开始按钮,等待进度条训练完毕即可。CPU也能训练,但是时间太慢,有条件的最好用GPU,速度快
评估预测与对话
评估预测选项卡:
模型训练完毕后,您可以通过在评估与预测界面通过指定 模型 及 适配器 的路径在指定数据集上进行评估。
您也可以通过在对话界面指定 模型、 适配器 及 推理引擎 后输入对话内容与模型进行对话观察效果。
【windows 报错】,不影响之下 chat步骤可以回答出期望的结果即可
chat选项卡:


到这一步,已经加载 训练后模型了。进行问题测试。

可以看到,我们的 身份识别 训练微调数据已经整合进 模型中了。
导出
如果您对模型效果满意并需要导出模型,您可以在导出界面通过指定 模型、 适配器、 分块大小、 导出量化等级及校准数据集、 导出设备、 导出目录 等参数后点击 导出 按钮导出模型。

到处文件目录

Ollama安装教程
Ollama教程
Ollama部署微调模型步骤
1. 模型构建
- 使用
ModelFile文件定义模型参数和上下文。 - 通过
ollama create命令将模型导入到 Ollama 中。
将生成的ModelFile文件放到外部:

如果没有新建:
内容进入到ollama 模型页 https://ollama.com/library/deepseek-r1:1.5b/blobs/369ca498f347
copy template内容

下面内容导出时,llamafactory自动生成的。因为本地装了ollama。
需要修改From ,默认是 . 【自测不行】,可能需要修改成绝对路径【可行】
temperature参数DeepSeek-R1官方建议给0.6
# ollama modelfile auto-generated by llamafactory
# 必须是model.safetersors文件的目录。即我们导出的目录
FROM D:\model\fine-tune\DeepSeek-R1-1.5B-Distill-kong-idendityTEMPLATE """<|begin▁of▁sentence|>{{ if .System }}{{ .System }}{{ end }}{{ range .Messages }}{{ if eq .Role "user" }}<|User|>{{ .Content }}<|Assistant|>{{ else if eq .Role "assistant" }}{{ .Content }}<|end▁of▁sentence|>{{ end }}{{ end }}"""PARAMETER stop "<|end▁of▁sentence|>"
PARAMETER num_ctx 4096进入cmd中执行命令
```shell
ollama create DeepSeek-R1-1.5B-Distill-kong-idendity -f ModelFile
```

可以看到,模型已经导入到ollama中。我们就可以ollama启动运行我们微调的大模型,提供open ai 接口调用了
3. 模型启动
- 使用
ollama run命令启动微调后的模型DeepSeek-R1-1.5B-Distill-kong-idendity:latest。
执行启动命令:
ollama run DeepSeek-R1-1.5B-Distill-kong-idendity:latest

4. API调用Ollama

调用地址:POST localhost:11434/api/chat
body: 修改自己的微调模型测试
{"model":"DeepSeek-R1-1.5B-Distill-kong-idendity", // 模型名称,ollama上显示的名字"stream": true, // 是否流式,true流式返回"temperature": 0.6, // 思维发散程度"top_p":0.95, // 一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果"messages":[ // 上下文{"role":"user","content":"你是谁?"}]
}
通过以上步骤,我们成功地将微调后的模型部署到 Ollama 中,并通过 API 接口进行调用和测试。
下一站
完成了LlamaFactory webui 可视化模型微调的所有步骤
相关文章:
LlamaFactory可视化模型微调-Deepseek模型微调+CUDA Toolkit+cuDNN安装
LlamaFactory https://llamafactory.readthedocs.io/zh-cn/latest/ 安装 必须保证版本匹配,否则到训练时,找不到gpu cuda。 否则需要重装。下面图片仅供参考。因为cuda12.8装了没法用,重新搞12.6 cudacudnnpytorch12.69.612.6最新…...

算法12-贪心算法
一、贪心算法概念 贪心算法(Greedy Algorithm)是一种在每一步选择中都采取当前状态下最优的选择,从而希望导致全局最优解的算法。贪心算法的核心思想是“局部最优,全局最优”,即通过一系列局部最优选择,最…...

js实现点击音频实现播放功能
目录 1. HTML 部分:音频播放控件 2. CSS 部分:样式设置 3. JavaScript 部分:音频控制 播放和暂停音频: 倒计时更新: 播放结束后自动暂停: 4. 总结: 完整代码: 今天通过 HTML…...

matlab平面波展开法计算的二维声子晶体带隙
平面波展开法计算的二维声子晶体带隙,分别是正方与圆形散射体形成正方格子声子晶体,最后输出了能带图的数据,需要自己用画图软件画出来。 列表 平面波展开法计算二维声子晶体带隙/a2.m , 15823 平面波展开法计算二维声子晶体带隙/a4.m , 942…...

Spring Boot (maven)分页3.0版本 通用版
前言: 通过实践而发现真理,又通过实践而证实真理和发展真理。从感性认识而能动地发展到理性认识,又从理性认识而能动地指导革命实践,改造主观世界和客观世界。实践、认识、再实践、再认识,这种形式,循环往…...

解决DeepSeek服务器繁忙问题
目录 解决DeepSeek服务器繁忙问题 一、用户端即时优化方案 二、高级技术方案 三、替代方案与平替工具(最推荐简单好用) 四、系统层建议与官方动态 用加速器本地部署DeepSeek 使用加速器本地部署DeepSeek的完整指南 一、核心原理与工具选择 二、…...
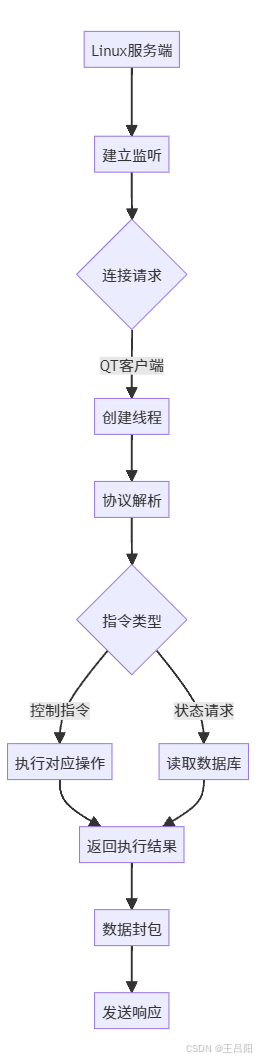
小项目第一天
总体实现流程图 智能称重模块流程图 定位追踪模块流程图 防盗报警模块流程图 密码解锁模块流程图 跨平台通信流程图...

家里WiFi信号穿墙后信号太差怎么处理?
一、首先在调制解调器(俗称:猫)测试网速,网速达不到联系运营商; 二、网线影响不大,5类网线跑500M完全没问题; 三、可以在卧室增加辅助路由器(例如小米AX系列)90~200元区…...

教育小程序+AI出题:如何通过自然语言处理技术提升题目质量
随着教育科技的飞速发展,教育小程序已经成为学生与教师之间互动的重要平台之一。与此同时,人工智能(AI)和自然语言处理(NLP)技术的应用正在不断推动教育内容的智能化。特别是在AI出题系统中,如何…...

SpringMVC新版本踩坑[已解决]
问题: 在使用最新版本springMVC做项目部署时,浏览器反复500,如下图: 异常描述: 类型异常报告 消息Request processing failed: java.lang.IllegalArgumentException: Name for argument of type [int] not specifie…...

一款利器提升 StarRocks 表结构设计效率
CloudDM 个人版是一款数据库数据管理客户端工具,支持 StarRocks 可视化建表,创建表时可选择分桶、配置数据模型。目前版本持续更新,在修改 StarRocks 表结构方面进一步优化,大幅提升 StarRocks 表结构设计效率。当前 CloudDM 个人…...

老牌软件,如今依旧坚挺
今天给大家介绍一个非常好用的老牌电脑清理软件,这个软件好多年之前就有人使用了。 今天找出来之后,发现还是那么的好用,功能非常强大。 Red Button 电脑清理软件 软件是绿色版,无需安装,打开这个图标就能直接使用了…...
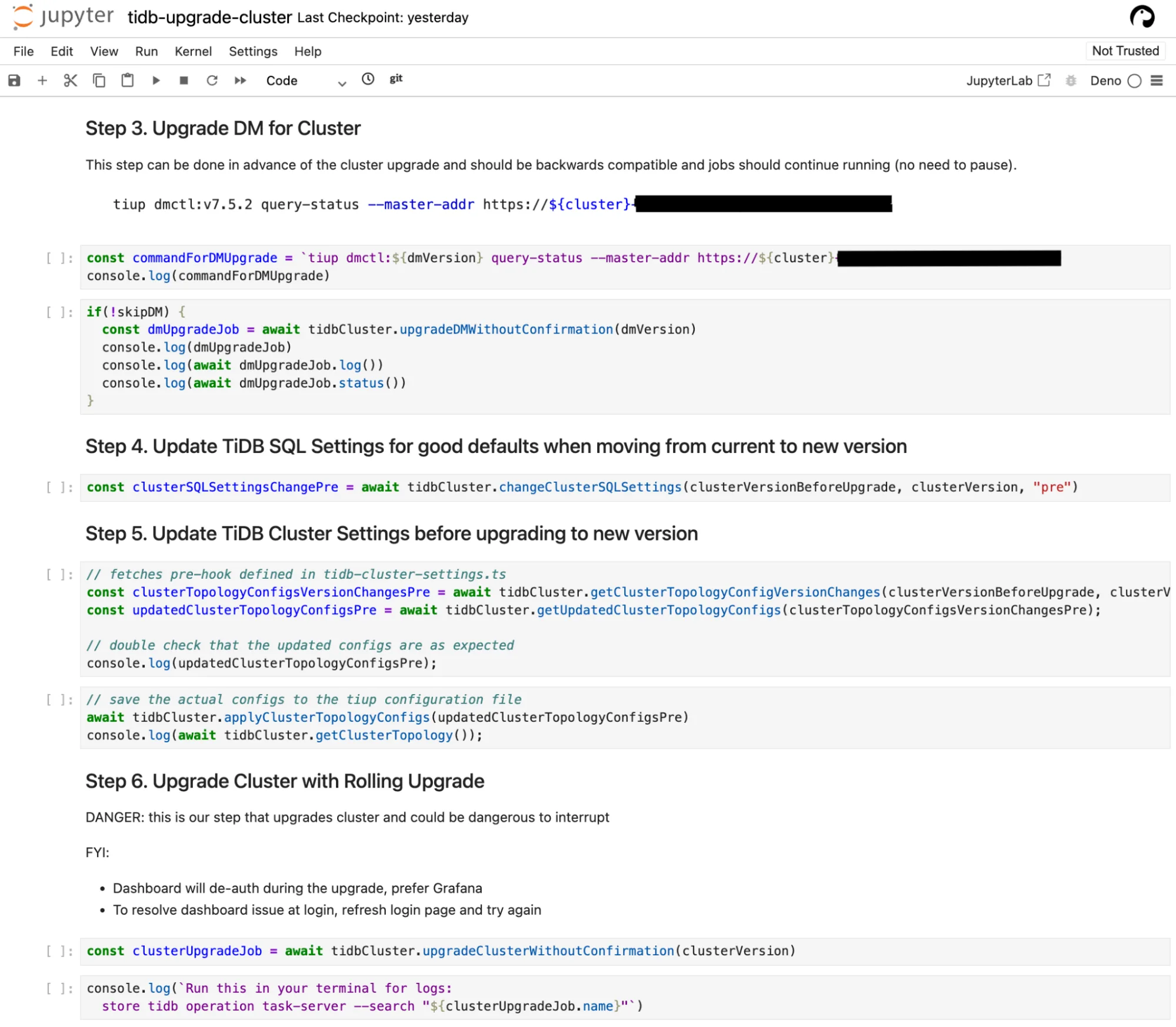
Plaid | 数据库切换历程:从 AWS Aurora MySQL 到 TiDB 的迁移之旅
原文来源: https://tidb.net/blog/231f2752 原文链接: https://plaid.com/blog/switching-to-tidb/ 翻译能力来自:Deepseek (ai.com ) 作者:Zander Hill Zander Hill 是 Plaid 的软件工程师和前工…...

MongoDB 扩缩容实战:涵盖节点配置、服务启动与移除操作
#作者:任少近 文章目录 一、扩容在245节点上配置配置config server:配置mongos启动config server安装工具mongosh添加245新节点到副本集配置分片副本集启动路由并分片 二、缩容Conf server上去掉server4shard上去掉server4mongos上去掉server4 一、扩容…...

Python学习心得字符串拼接的几种方法
一、字符串拼接的接种方法: 二、字符串拼接方法的运用: s1hello s2world #使用进行连接 print(s1s2)#使用字符串join()方法 print(.join([s1,s2]))#使用空字符串进行拼接print(*.join([hello,world,python]))#使用*进行拼接#直接拼接 print(helloworld)…...

USB2.03.0摄像头区分UVC相机在linux中的常用命令
这里是引用 一. USB2.0 & 3.0接口支持区分 1.1. 颜色判断 USB接口的颜色并不是判断版本的可靠标准,但根据行业常见规范分析如下: USB接口颜色与版本对照表: 接口颜色常见版本内部触点数量传输速度黑色USB2.04触点480 Mbps (60 MB/s)白…...

electron 学习
文章目录 1.注意项1.1 安装前最好设置一下代理 官网 tutorial https://www.electronjs.org/docs/latest/tutorial/tutorial-prerequisites 1.注意项 1.1 安装前最好设置一下代理 npm config set registry https://registry.npmmirror.com/...

美术教程2025
动画 必看 动画d【Unity初学者教程】如何制作 2D 游戏动画_哔哩哔哩_bilibili 如何在Unity中制作2D游戏动画 - 新手教程 - Blackthornprod_新手教程 可不看序列帧 【简明UNITY教程】2D游戏 动画制作实例详解_哔哩哔哩_bilibili unityspine 【Unity2D游戏开发教程】2D自定…...

CPT205 计算机图形学 OpenGL 3D实践(CW2)
文章目录 1. 介绍2. 设计3. 准备阶段4. 角色构建5. 场景构建6. 交互部分6.1 键盘交互6.2 鼠标交互6.3 鼠标点击出多级菜单进行交互 7. 缺点与问题7.1 程序bug7.2 游戏乐趣不足7.3 画面不够好看 8. 完整代码 1. 介绍 前面已经分享过了关于CPT205的CW1的2D作业,这次C…...

基于单片机的开关电源设计(论文+源码)
本次基于单片机的开关电源节能控制系统的设计中,在功能上设计如下: (1)系统输入220V; (2)系统.输出0-12V可调,步进0.1V; (3)LCD液晶显示实时电压ÿ…...

2025最权威的AI辅助写作方案实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 时下,人工智能技术已然深度涉足学术写作范畴。就毕业论文撰写来讲,AI…...

iGRPO框架:大语言模型推理效率的动态优化方案
1. 项目背景与核心价值最近在优化大语言模型推理效率时,发现传统方法存在明显的性能瓶颈。经过多次实验验证,我们团队开发了一套名为iGRPO的创新优化框架,通过自反馈机制实现了推理过程的动态调优。这种方法特别适合需要实时响应的高频交互场…...
预后的机制联系)
如何将CT-MPI影像组学特征与冠心病大血管及微循环机制建立关联,并进一步解释其与主要不良心血管事件(MACE)预后的机制联系
01导语各位同学,大家好。做影像组学,如果还停留在“提特征—建模型—算AUC”三板斧,那就像算命先生——算得再准,问起“凭什么”,也只能支支吾吾。别人一质疑:你那些纹理、百分位数到底代表什么生物学过程&…...

三分钟搞定网易云音乐NCM文件解密:Windows图形界面终极指南
三分钟搞定网易云音乐NCM文件解密:Windows图形界面终极指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲…...

DS3906数字电位器特性与应用全解析
1. DS3906数字电位器核心特性解析DS3906是Maxim Integrated公司推出的一款三通道非易失性数字电位器,采用伪对数响应曲线设计。与传统的线性数字电位器相比,这种特殊响应曲线使其在小步进调节场景中展现出独特优势。该器件内置EEPROM,可在断电…...

为AI智能体注入Power BI专家级能力:OpenClaw技能包全解析
1. 项目概述:为AI智能体注入Power BI专家级能力 如果你正在探索如何让AI助手(或者说,智能体)真正理解并操作像Power BI这样复杂的企业级商业智能工具,那么你很可能已经遇到了瓶颈。传统的提示词工程往往只能让大语言模…...

OpenClawWeChat:基于Wechaty的插件化微信机器人开发与部署实战
1. 项目概述与核心价值最近在折腾微信机器人,想找一个能稳定、灵活地处理消息,还能对接各种外部服务的方案。市面上工具不少,但要么功能单一,要么配置复杂,要么就是稳定性堪忧,动不动就被风控。直到我深度体…...

荷兰与英国高校:无需重训实现大模型安全模式动态切换能力
这项由拉德堡德大学、布里斯托大学与莱顿大学联合开展的研究,以预印本形式于2026年4月30日发布在arXiv平台,编号为arXiv:2604.27818v1,研究方向归属于计算机安全领域(cs.CR)。感兴趣的读者可通过该编号在arXiv上查阅完…...
的两种正确注册与刷新姿势)
告别数据丢失!ABAP ALV修改事件(Data Changed)的两种正确注册与刷新姿势
ABAP ALV数据修改事件全解析:两种高效注册与刷新策略实战 在SAP系统开发中,ALV(ABAP List Viewer)作为数据展示和交互的核心组件,其可编辑功能一直是企业级应用的关键需求。当用户修改ALV表格数据时,如何确…...

从零开始理解Cortex-M4/M7的栈指针:MSP与PSP在RTOS中的实战配置与避坑指南
Cortex-M4/M7双栈指针深度解析:RTOS任务隔离与安全切换实战 引言 在嵌入式实时操作系统(RTOS)开发中,栈管理是影响系统稳定性的核心要素。Cortex-M4/M7处理器独特的双栈指针设计——主栈指针(MSP)和进程栈指针(PSP),为任务隔离提供了硬件级支…...