53倍性能提升!TiDB 全局索引如何优化分区表查询?
作者: Defined2014 原文来源: https://tidb.net/blog/7077577f
什么是 TiDB 全局索引
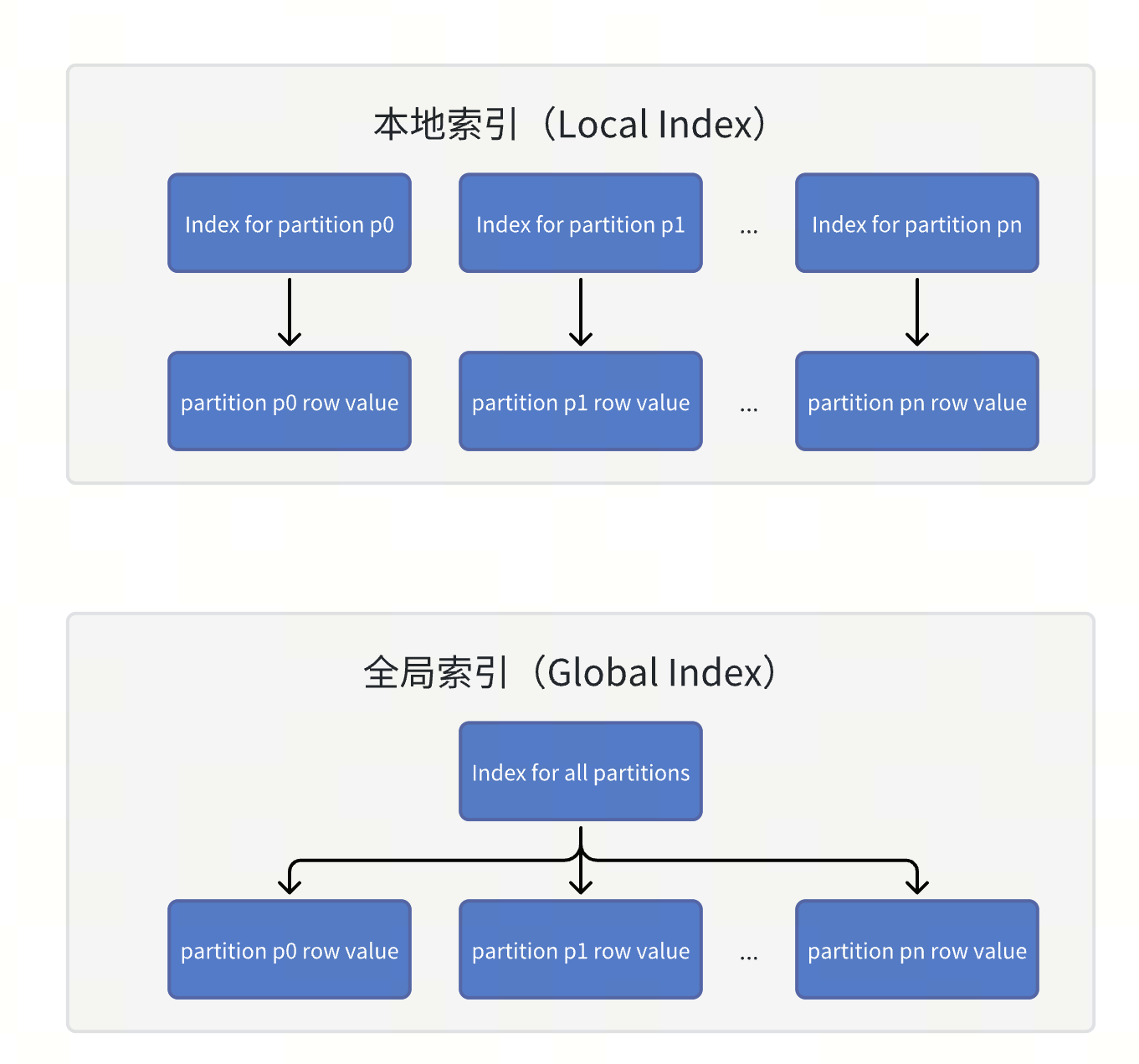
在 TiDB 中,全局索引是一种定义在分区表上的索引类型,它允许索引分区与表分区之间建立一对多的映射关系,即一个索引分区可以对应多个表分区。这与 TiDB 早期版本中的本地索引(Local Index)不同,本地索引的索引分区与表分区之间是一对一的映射关系,即一个分区对应一个局部的索引块。
全局索引能覆盖整个表的数据,使得主键和唯一键在不包含分区键的情况下仍能保持全局唯一性。此外,全局索引可以在一次操作中访问多个分区的索引数据,而无需对每个分区的本地索引逐一查找,显著提升了针对非分区键的查询性能。
下图简单展示了本地索引和全局索引的区别
TiDB 全局索引的发展历程
- v7.6.0 版本之前 :TiDB 仅支持分区表的本地索引。这意味着,对于分区表上的唯一键,必须包含表分区表达式中的所有列。如果查询条件中没有使用分区键,那么查询将不得不扫描所有分区,这会导致查询性能下降。
- v7.6.0 版本 :引入了系统变量
tidb_enable_global_index,用于开启全局索引功能。然而,当时该功能仍在开发中,不推荐用户启用。 - v8.3.0 版本 :全局索引功能作为实验性特性发布。用户可以通过在创建索引时显式使用
GLOBAL关键字来创建全局索引。 - v8.4.0 版本 :全局索引功能正式成为一般可用(GA)特性。用户可以直接使用
GLOBAL关键字创建全局索引,而无需再设置系统变量tidb_enable_global_index。从这个版本开始,该系统变量被弃用,并且始终为ON。 - v8.5.0 版本 :全局索引功能支持了包含分区表达式中的所有列。
- v9.0.0 版本 :全局索引功能支持了非唯一索引的情况。在分区表中,除聚簇索引外都可以被创建为全局索引。
TiDB 全局索引的语法
在 TiDB 中,创建全局索引(Global Index)时,可以在 CREATE INDEX 或 ALTER TABLE 语句中使用 GLOBAL 关键字,或在建表时通过 GLOBAL 关键字或 /*T![global_index] GLOBAL */ 注释指定。
创建全局索引的语法:
CREATE [UNIQUE] INDEX index_name ON table_name (column_list) [GLOBAL];
ALTER TABLE table_name ADD [UNIQUE] INDEX index_name (column_list) [GLOBAL];
示例:
- 创建全局唯一索引:
CREATE UNIQUE INDEX idx_global ON employees (email) GLOBAL;
此语句在 employees 表的 email 列上创建一个全局唯一索引,确保每个电子邮件地址在整个表中唯一。
- 添加全局索引:
ALTER TABLE orders ADD INDEX idx_global_order_date (order_date) GLOBAL;
此语句向 orders 表添加一个名为 idx_global_order_date 的全局索引,索引列为 order_date 。
- 在建表时创建全局索引:
CREATE TABLE `sbtest` (`id` int NOT NULL,`k` int NOT NULL DEFAULT '0',`c` char NOT NULL DEFAULT '',KEY `idx1` (`k`) GLOBAL,KEY `idx2` (`k`) /*T![global_index] GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY HASH (`id`) PARTITIONS 5;
此语句在创建 sbtest 表时同时创建了两个名为 idx1 和 idx2 的全局索引,两个索引的索引列都为 k 。
TiDB 全局索引的优势
提升查询性能
全局索引能够有效提高检索非分区列的效率。当查询涉及非分区列时,全局索引可以快速定位相关数据,避免了对所有分区的全表扫描,可以显著降低 cop task 的数量,这对于分区数量庞大的场景尤为有效。
经过测试,在分区数量为 100 的情况下,sysbench select_random_points 场景得到了 53 倍 的性能提升。
增强应用灵活性
全局索引的引入,消除了分区表上唯一键必须包含所有分区列的限制。这使得用户在设计索引时更加灵活,可以根据实际的查询需求和业务逻辑来创建索引,而不再受限于表的分区方案。这种灵活性有助于更好地优化查询性能,满足多样化的业务需求。
减少应用修改工作量
在数据迁移和应用修改过程中,全局索引可以减少对应用的修改工作量。如果没有全局索引,在迁移数据或修改应用时,可能需要调整分区方案或重写查询语句以适应索引的限制。有了全局索引之后,这些修改可以被避免,从而降低了开发和维护成本。
如在将 Oracle 数据库中的某张表迁移到 TiDB 时,因为 Oracle 支持全局索引,可能在某些表上存在一些不包含分区列的唯一索引,在迁移过程需要对表结构进行调整,以适应 TiDB 的分区表限制。然而,随着 TiDB 对全局索引的支持,用户只需简单地修改索引定义,将其设置为全局索引,即可与 Oracle 保持一致,从而显著降低迁移成本。
TiDB 全局索引的工作原理
基本思想
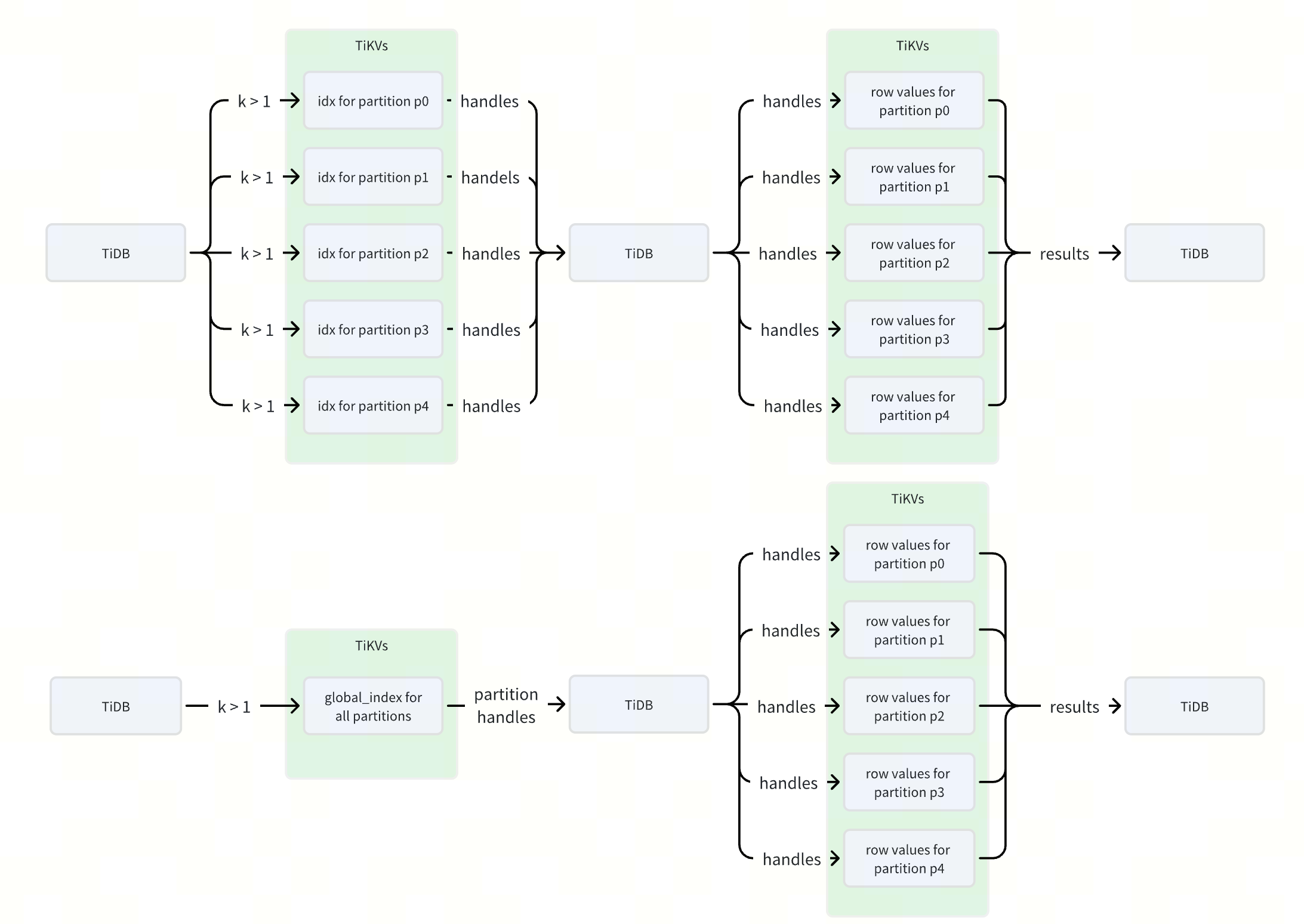
在 TiDB 的分区表中,本地索引的键值前缀是分区表的 ID 而全局索引的前缀是表的 ID。这样的改动确保了全局索引的数据在 TiKV 上分布是连续的,降低了查询索引时 RPC 的数量。
CREATE TABLE `sbtest` (`id` int(11) NOT NULL,`k` int(11) NOT NULL DEFAULT '0',`c` char(120) NOT NULL DEFAULT '',KEY idx(k),KEY global_idx(k) GLOBAL
) partition by hash(id) partitions 5;
以上面的表结构为例, idx 为普通索引, global_idx 为全局索引。索引 idx 的数据会分布在 5 个不同的 ranges 中,如 PartitionID1_i_xxx , PartitionID2_i_xxx 等,而索引 global_idx 的数据则会集中在一个 range ( TableID_i_xxx ) 内。
这样当我们进行 k 相关的查询时,如 select * from sbtest where k > 1 ,通过索引 idx 会构造 5 个不同的 ranges,而通过全局索引 global_idx 则只会构造 1 个 range,每个 range 在 TiDB 中对应一个或多个 RPC 请求,这样使用全局索引可以降低数倍的 RPC 请求数,从而提升查询索引的性能。
下图更加直观地展示了在使用 idx 和 global_idx 两个不同索引执行 select * from sbtest where k > 1 查询语句在 RPC 请求和数据流转过程中的差异。
编码方式
在 TiDB 中,索引项被编码为键值对。对于分区表,每个分区在 TiKV 层被视为一个独立的物理表,拥有自己的 partitionID 。因此,分区表的索引项也被编码为:
唯一键
Key:
- PartitionID_indexID_ColumnValuesValue:
- IntHandle- TailLen_IntHandle- CommonHandle- TailLen_IndexVersion_CommonHandle非唯一键
Key:
- PartitionID_indexID_ColumnValues_HandleValue:
- IntHandle- TailLen_Padding- CommonHandle- TailLen_IndexVersion
在全局索引中,索引项的编码方式有所不同。为了使全局索引的键布局与当前索引键编码保持兼容,新的索引编码布局为:
唯一键
Key:
- TableID_indexID_ColumnValuesValue:
- IntHandle- TailLen_PartitionID_IntHandle- CommonHandle- TailLen_IndexVersion_CommonHandle_PartitionID非唯一键
Key:
- TableID_indexID_ColumnValues_HandleValue:
- IntHandle- TailLen_PartitionID- CommonHandle- TailLen_IndexVersion_PartitionID
这种编码方式使得全局索引的键以 TableID 开头,而 PartitionID 被放置在 Value 中。这样设计的优点是,它与现有的索引键编码方式兼容,但同时也带来了一些挑战,例如在执行 DROP PARTITION, TRUNCATE PARTITION 等 DDL 操作时,由于索引项不连续,需要进行额外的处理。
TiDB 全局索引的限制与注意事项
影响部分 DDL 性能
当分区表中存在全局索引时,执行诸如 DROP PARTITION(删除分区)、TRUNCATE PARTITION(清空分区)、REORG PARTITION(重组分区)等部分 DDL 操作时,需要同步更新全局索引的值,这会显著增加 DDL 操作的执行时间。
在 v8.5.0 默认参数下,测试显示对包含全局索引的 sysbench 表执行 DROP PARTITION 或 TRUNCATE PARTITION 操作时, oltp_read_write 负载的性能会下降 15% 至 20%。
聚簇索引 (Clustered Index)
聚簇索引不能成为全局索引,是因为如果聚簇索引是全局索引,则表将不再分区。这是因为聚簇索引的键是分区级别的行数据的键,但全局索引是表级别的,这就造成了冲突。如果需要将主键设置为全局索引,则需要显式设置该主键为非聚簇索引,如 PRIMARY KEY(col1, col2) NONCLUSTERED GLOBAL 。
性能测试数据
-
select_random_pointsin sysbench
示例表结构
CREATE TABLE `sbtest` (`id` int(11) NOT NULL,`k` int(11) NOT NULL DEFAULT '0',`c` char(120) NOT NULL DEFAULT '',`pad` char(60) NOT NULL DEFAULT '',PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,KEY `k_1` (`k`)/* Key `k_1` (`k`, `c`) GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
/* Partition by hash(`id`) partitions 100 */
/* Partition by range(`id`) xxxx */
负载 SQL
SELECT id, k, c, pad
FROM sbtest1
WHERE k IN (xx, xx, xx)
| Range Partition (100 partitions) | ||||
| Concurrency | 1 | 32 | 64 | Average RU |
| Clustered non-partitioned table | 225 | 19,999 | 30,293 | 7.92 |
| Clustered table range partitioned by PK | 68 | 480 | 511 | 114.87 |
Clustered table range partitioned by PK, with Global Index on k, c columns | 207 | 17,798 | 27,707 | 11.73 |
| Hash Partition (100 partitions) | ||||
| Concurrency | 1 | 32 | 64 | Average RU |
| Clustered non-partitioned table | 166 | 20361 | 28922 | 7.86 |
| Clustered table hash partitioned by PK | 60 | 244 | 283 | 119.73 |
Clustered table hash partitioned by PK, with Global Index on k, c columns | 156 | 18233 | 15581 | 10.77 |
- 通过上述测试可以看出,在高并发环境下,全局索引能够显著提升分区表查询性能,提升幅度可达 50 倍。同时,全局索引还能够显著降低资源(RU)消耗。随着分区数量的增加,这种性能提升的效果将愈加明显。
最佳实践
全局索引和本地索引
全局索引适用场景 :
- 数据归档不频繁 :例如,医疗行业的部分业务数据需要保存 30 年,通常按月分区,然后一次性创建 360 个分区,且很少进行
DROP或TRUNCATE操作。在这种情况下,使用全局索引更为合适,因为它能提供跨分区的一致性和查询性能。 - 查询需要跨分区的数据 :当查询需要访问多个分区的数据时,全局索引可以避免跨分区扫描,提高查询效率。
本地索引适用场景 :
- 数据归档需求 :如果数据归档操作很频繁,且主要查询集中在单个分区内,本地索引可以提供更好的性能。
- 需要使用分区交换功能 :在银行等行业,可能会将处理后的数据先写入普通表,确认无误后再交换到分区表,以减少对分区表性能的影响。此时,本地索引更为适用,因为在使用了全局索引之后,分区表将不再支持分区交换功能。
全局索引和聚簇索引
由于聚簇索引和全局索引的原理限制,一个索引不能同时作为聚簇索引和全局索引。然而,这两种索引在不同查询场景中能提供不同的性能优化。在遇到需要同时兼顾两者的需求时,我们可以将分区列添加到聚簇索引中,同时创建一个不包含分区列的全局索引。
假设我们有如下表结构:
CREATE TABLE `t` (`id` int DEFAULT NULL,`ts` timestamp NULL DEFAULT NULL,`data` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY RANGE (UNIX_TIMESTAMP(`ts`))
(PARTITION `p0` VALUES LESS THAN (1735660800)PARTITION `p1` VALUES LESS THAN (1738339200)...)
在上面的 t 表中, id 列的值是唯一的。为了优化点查和范围查询的性能,我们可以选择在建表语句中定义一个聚簇索引 PRIMARY KEY(id, ts) 和一个不包含分区列的全局索引 UNIQUE KEY id(id) 。这样在进行基于 id 的点查询时,会走全局索引 id ,选择 PointGet 的执行计划;而在进行范围查询时,聚簇索引则会被选中,因为聚簇索引相比全局索引少了一次回表操作,从而提升查询效率。
修改后的表结构如下所示:
CREATE TABLE `t` (`id` int NOT NULL,`ts` timestamp NOT NULL,`data` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`, `ts`) /*T![clustered_index] CLUSTERED */,UNIQUE KEY `id` (`id`) /*T![global_index] GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY RANGE (UNIX_TIMESTAMP(`ts`))
(PARTITION `p0` VALUES LESS THAN (1735660800),PARTITION `p1` VALUES LESS THAN (1738339200)...)
通过这种方式,我们既能优化基于 id 的点查询,又能提升范围查询的性能,同时确保表的分区列在基于时间戳的查询中能得到有效的利用。
总结
TiDB 全局索引是 TiDB 在分区表索引方面的重要特性,它通过允许索引分区与表分区之间提供一对多的映射关系,提供了更灵活的索引设计和更高效的查询性能。全局索引的引入,不仅提升了 TiDB 分区表在处理复杂查询和大数据量场景下的能力,还为用户在数据库设计和优化方面提供了更多的选择。
然而,全局索引也带来了一些挑战,如维护成本的增加。在使用全局索引时,需要根据具体的业务需求和数据特点,合理设计索引,权衡查询性能和数据修改性能,以达到最佳的数据库性能。
总之,TiDB 全局索引是一个强大且灵活的特性,能够帮助用户更好地优化数据库性能,满足多样化的业务需求。在实际应用中,合理使用全局索引,可以显著提升查询性能,提高数据库的整体效率。
相关文章:
53倍性能提升!TiDB 全局索引如何优化分区表查询?
作者: Defined2014 原文来源: https://tidb.net/blog/7077577f 什么是 TiDB 全局索引 在 TiDB 中,全局索引是一种定义在分区表上的索引类型,它允许索引分区与表分区之间建立一对多的映射关系,即一个索引分区可以对…...

Pythong 解决Pycharm 运行太慢
Pythong 解决Pycharm 运行太慢 官方给Pycharm自身占用的最大内存设低估了限制,我的Pycharm刚开始默认是256mb。 首先找到自己的Pycharm安装目录 根据合适自己的改 保存,重启Pycharm...
库里存储的数据有大量回车时,该如何进行存取
如图,打印模板存了很多坐标性的字段数据: 大量带换行的文本数据存到库里之后取出,前端需要做非空、合法校验, 然后在循环中,使用eval 函数接收每一句字符串,去执行这句 JavaScript 代码。 let arrStr tem…...

【devops】Github Actions Secrets | 如何在Github中设置CI的Secret供CI的yaml使用
一、Github Actions 1、ci.yml name: CIon: [ push ]jobs:build:runs-on: ubuntu-lateststeps:- name: Checkout codeuses: actions/checkoutv3- name: Set up Gouses: actions/setup-gov4with:go-version: 1.23.0- name: Cache Go modulesuses: actions/cachev3with:path: |…...

体验 DeepSeek-R1:解密 1.5B、7B、8B 版本的强大性能与应用
文章目录 🍋引言🍋DeepSeek 模型简介🍋版本更新:1.5B、7B、8B 的区别与特点🍋模型评估🍋体验 DeepSeek 的过程🍋总结 🍋引言 随着大规模语言模型的持续发展,许多模型在性…...

一文说清楚什么是Token以及项目中使用Token延伸的问题
首先可以参考我的往期文章,我这里说清楚了Cookie,Seesion,Token以及JWT是什么 其实Token你就可以理解成这是一个认证令牌就好了 详细分清Session,Cookie和Token之间的区别,以及JWT是什么东西_还分不清 cookie、sessi…...

大模型-Tool call、检索增强
大模型 Tool call 心知天气:https://www.seniverse.com/ 例子:调用天气接口 API from openai import OpenAI import requests import json """ ##### 天气接口 API 密钥获取:https://www.free-api.com/doc/558 ##### &quo…...

【算法】【区间和】acwing算法基础 802. 区间和 【有点复杂,但思路简单】
题目 假定有一个无限长的数轴,数轴上每个坐标上的数都是 0。 现在,我们首先进行 n 次操作,每次操作将某一位置 x 上的数加 c。 接下来,进行 m 次询问,每个询问包含两个整数 l 和 r,你需要求出在区间 [l,r] …...

Ubuntu22.04通过Docker部署Jeecgboot
程序发布环境包括docker、mysql、redis、maven、nodejs、npm等。 一、安装docker 1、用如下命令卸载旧Docker: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done 2、安装APT环境依赖包…...

HTML4
HTML 初体验 1.鼠标右键 > 新建 > 文本文档 > 输入以下内容,并保存 2.修改后缀为 .html ,然后双击打开即可 这里的后缀名,使用 .htm 也可以,但推荐使用更标准的 .html <marquee>尚硅谷,让天下没有难…...

STM32F10X 启动文件完整分析
最近在准备面试相关 顺便复盘总结一下之前的内容 启动文件在基于ARM的芯片是很重要的组成部分,它主要负责完成芯片上电启动时的一系列初始化工作和各种异常及中断的入口地址。 也是理解bootloader自举的关键点,所以需要理解一下 1. 向量表定义 启动文件…...

typescript快速入门之安装与运行
安装 安装ts环境,最好全局安装,这样就不需要开一个项目又安装 npm i -g typescript初始化 可以运行初始化配置文件,也可以手动生成;不生成的话会运行默认配置 使用默认配置 把ts文件转成js文件使用的是es3语言,语…...

React源码解读
配置React源码本地调试环境 本次环境构建采用了node版本为16、react-scripts 版本号为 3.4.4,源码下载地址 react源码调试: react源码调试环境 使用 create-react-app 脚手架创建项目 npx create-react-app react-test 进入刚刚下载的目录,弹射 crea…...
【DeepSeek-R1】 API申请(火山方舟联网版)
DeepSeek-R1 API申请(火山方舟联网版) 1、新建联网版应用2、开通信息增强服务3、开启联网内容插件4、创建接入点5、获取模型名称6、获取API Key 如果第一次注册账号,请先按照文章《【Deepseek-R1】 API申请(火山方舟)》…...

负载均衡集群——LVS-DR配置
一、简介 1.1 什么是集群? 两台及以上的计算机完成一个任务的模式称为集群。 常见的集群类型包括: LB(负载均衡)集群:按照不同的算法将前端的访问转发给后端计算点,使节点负载相对平衡。提高并发能力 缺…...

数据结构篇
链表 用数组模拟链表,看该链表结构,有几个域则用几个数组分别存储 单链表是只知道下一个元素位置,双链表还知道上一个链表位置 单链表 双向链表 左移右移 栈 模拟栈 判断括号序列 队列 模拟队列 递归 集合和哈希 集合就是哈希表 哈希表的实现…...

「软件设计模式」建造者模式(Builder)
深入解析建造者模式:用C打造灵活对象构建流水线 引言:当对象构建遇上排列组合 在开发复杂业务系统时,你是否经常面对这样的类:它有20个成员变量,其中5个是必填项,15个是可选项。当用户需要创建豪华套餐A&…...

Matlab 机器人 雅可比矩阵
工业机器人运动学与Matlab正逆解算法学习笔记(用心总结一文全会)(四)——雅可比矩阵_staubli机器人正逆向运动学实例验证matlab-CSDN博客 matlab求雅可比矩阵_六轴机械臂 矢量积法求解雅可比矩阵-CSDN博客 (63 封私信 / 80 条消息…...

DeepSeek 助力 Vue 开发:打造丝滑的面包屑导航(Breadcrumbs)
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...

IntelliJ IDEA 2024.1.4版无Tomcat配置
IntelliJ IDEA 2024.1.4 (Ultimate Edition) 安装完成后,调试项目发现找不到Tomcat服务: 按照常规操作添加,发现服务插件中没有Tomcat。。。 解决方法 1、找到IDE设置窗口 2、点击Plugins按钮,进入插件窗口,搜索T…...

地理优化实战:从选址到路径规划,用算法解决空间决策难题
1. 项目概述:当“地理”遇上“优化”最近在GitHub上看到一个挺有意思的项目,叫capt-marbles/geo-optimization。光看名字,就能嗅到一股浓浓的“交叉学科”味道——地理(Geo)和优化(Optimization)…...

Anime4KCPP:高性能动漫图像超分辨率工具的完整指南
Anime4KCPP:高性能动漫图像超分辨率工具的完整指南 【免费下载链接】Anime4KCPP A high performance anime upscaler 项目地址: https://gitcode.com/gh_mirrors/an/Anime4KCPP Anime4KCPP 是一款高性能的动漫图像超分辨率工具,采用基于 CNN 的算…...

外籍高管如何用10年攻克日本半导体市场:从破局到筑城的实战方法论
1. 从“破局者”到“筑城者”:一位外籍高管在日本半导体市场的十年征程 在半导体这个以“快”著称的行业里,四年时间足以让一个技术路线从蓝图变为古董,让一家明星初创公司从风口跌落,或者让一个市场格局彻底洗牌。2014年…...

Backblaze B2云存储管理:Claude技能实现智能审计与自动化运维
1. 项目概述最近在折腾云存储管理,特别是Backblaze B2,发现手动用命令行操作虽然灵活,但想快速盘点存储桶状态、找出冗余文件、检查安全配置,每次都得上网查命令,效率实在不高。正好看到Backblaze官方发布了一个Claude…...

别再只ping 127.0.0.1了!这5个环回地址的隐藏用法,开发测试效率翻倍
解锁127.0.0.0/8:开发者必备的环回地址高阶用法手册 当你在终端输入ping 127.0.0.1看到"Reply from 127.0.0.1"时,是否想过这个熟悉的地址背后还隐藏着整个未被充分利用的地址王国?作为开发者,我们每天都在与环回地址打…...

5分钟极速上手!NsEmuTools:NS模拟器一站式管理神器
5分钟极速上手!NsEmuTools:NS模拟器一站式管理神器 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 还在为NS模拟器的繁琐配置而烦恼吗?NsEmuTools就是为…...
)
告别ST-Link!用DAPLink玩转STM32调试与拖拽烧录(附固件升级指南)
从ST-Link到DAPLink:嵌入式开发者的效率革命 当你在深夜调试STM32时,是否曾因ST-Link的驱动问题而抓狂?或是为频繁插拔烧录器感到厌倦?DAPLink的出现,正在悄然改变嵌入式开发的游戏规则。这个由ARM主导的开源项目&…...
推出的一款 USB 3.0 主机控制器芯片,支持 xHCI 1.0 和 PCIe Gen2 接口标)
UPD720202K8-711-BAA-A 是瑞萨电子(Renesas Electronics)推出的一款 USB 3.0 主机控制器芯片,支持 xHCI 1.0 和 PCIe Gen2 接口标
UPD720202K8-711-BAA-A 是瑞萨电子(Renesas Electronics)推出的一款 USB 3.0 主机控制器芯片,支持 xHCI 1.0 和 PCIe Gen2 接口标准,适用于高性能 USB 接口扩展方案。 核心特性: 接口标准:USB 3.0&…...

AutoJS Pro9.3最新文档详解与入门教程
AutoJS Pro9.3最新文档详解与入门教程 关键词:AutoJS Pro9.3、AutoJS脚本开发、安卓自动化、AutoJS文档、AutoJS入门、AutoJS教程、手机自动化脚本 前言 最近在研究安卓自动化的时候,我重新把 AutoJS Pro 拿出来深度玩了一遍。以前用的还是比较旧的版本…...

AI代码审查实战:基于LLM的自动化代码质量提升方案
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫abczsl520/codex-review。光看名字,可能有点摸不着头脑,codex这个词在技术圈里通常和OpenAI的Codex模型有关,而review又指向了代码审查。所以,这个项目大…...