爬虫实战:利用代理ip爬取推特网站数据
引言
亮数据-网络IP代理及全网数据一站式服务商屡获殊荣的代理网络、强大的数据挖掘工具和现成可用的数据集。亮数据:网络数据平台领航者![]() https://www.bright.cn/?promo=RESIYEAR50/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_yingjie202502
https://www.bright.cn/?promo=RESIYEAR50/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_yingjie202502
在跨境电商、社交媒体运营以及数据采集的过程中,我们经常会遇到被平台拦截的问题。这是因为各大平台为了保护其正常业务,防止恶意攻击或数据滥用,会限制非人类用户的访问频率。如果我们使用多账号登录或通过自动化工具频繁访问平台,系统很容易识别出异常行为,进而将我们的账号或IP地址列入黑名单,导致访问受限或直接被封禁。这种情况不仅影响了业务的正常开展,还可能导致数据采集中断,甚至丢失重要信息。面对这一问题,目前最有效的解决方案之一是使用动态IP。动态IP的核心优势在于,每次访问时都可以切换到一个新的IP地址,从而降低被平台识别和拦截的概率。与传统的商业数据中心IP不同,动态IP中有一类特殊的动态住宅IP,它们来自真实的家庭网络,能够更好地模拟普通用户的上网行为。
通过使用动态住宅IP服务,我们可以在进行社交媒体数据采集时,大幅减少被平台拦截的风险。无论是跨境电商的竞品分析,还是社交媒体运营的数据监控,动态住宅IP都能为我们提供更加稳定和高效的访问环境。接下来,我们将详细介绍如何配置和使用动态住宅IP服务,并完成社交平台的数据采集工作。
准备
首先我们需要配置动态住宅IP,我问了一下AI,推荐了几家常见的服务商,意义了解之后,我发现亮数据平台正好在促销,性价比是几家中最高的,这次我们就来试用一下。只需要注册账号即可开始使用。登录以后会跳转到工作台,在这里点击获取代理。

![]()

之后要进行简单的配置,这里我们只需要填写名称就可以了,其他选项大家可以根据需求选择。
动态住宅代理的计费模式是按照流量计算,使用期间可以随时切换IP地址。

配置好以后建议安装一下,这样可以提高安全性。当然不安装也不会太大的影响,后面需要的时候还可以再安装。

这样就配置好了。在这个页面可以找到我们的主机地址、用户名和密码,旁边有一个样例程序,可以修改它称为我们的爬虫程序。

配置好就可以开始配置社交平台API接口了。在平台中注册为开发者就可以拿到自己的token,在后面的访问需要使用它才能正常接入。

采集社交媒体数据
接下来就可以制作爬虫程序。首先我们需要将服务的参数设置好。
proxies = {'http': 'http://brd-customer-hl_a0a48734-zone-residential proxy1:9270yrzw8wyb@brd.superproxy.io:33335''https': 'https://brd-customer-hl_a0a48734-zone-residential proxy1:9270yrzw8wyb@brd.superproxy.io:33335'
}
我们本次的任务是抓取下图账号的所有帖子和每个帖子点赞数、转发数等指标。在开始之前,我们需要配置一下请求头参数,这个可以直接在网站中获得。在控制台中找到header和cookie的值复制出来就可以了。

找到之后把它们打包在一个类中方便后面使用。
class CsxqTwitterKeywordSearch:def __init__(self,saveFileName,cookie_str):self.saveFileName = saveFileNameself.searchCondition = Noneself.headers = {'headers对应的参数'}self.cookies = self.cookie_str_to_dict(cookie_str)
接下来我们需要配置一下请求参数,这些需要通过cursor去网站获取。
def get_params(self,cursor):if cursor == "":variables = {"rawQuery": self.searchCondition, "count": 20,"querySource": "typed_query", "product": "Latest"}params = {"variables": json.dumps(variables,separators=(",",":")),"features": ""}else:variables = {"rawQuery": self.searchCondition, "count": 20, "cursor": cursor, "querySource": "typed_query", "product": "Latest"}params = {"variables": json.dumps(variables,separators=(",",":")),"features": ""}return params
之后使用获取到的参数访问并获取元数据,这里需要注意元数据是一个json表单。这里url部分需要将中间替换为自己的token 才能使用。
def get(self,cursor):self.headers["x-csrf-token"] = self.cookies['ct0']url = "https://x.com/i/api/graphql/6uoFezW1o4e-n-VI5vfksA/SearchTimeline"params = self.get_params(cursor)while True:try:response = requests.get(url,headers=self.headers,cookies=self.cookies,params=params,timeout=(3,10),proxies=proxies)if response.status_code == 429:time.sleep(60*20)if response.status_code == 200:data = response.json()return dataexcept Exception as e:print("搜索接口发生错误:%s" % e)
最后我们需要将目标数据从获取到的元数据中提取出来。这里我们需要提取的是内容、时间、点赞、评论、转发、用户名、简介、粉丝量和关注量,由于元数据是json表单所以只需要简单转换为字典就可以轻松获取。
def parse_data(self,entries):resultList = []def transTime(dd):GMT_FORMAT = '%a %b %d %H:%M:%S +0000 %Y'timeArray = datetime.datetime.strptime(dd, GMT_FORMAT)return timeArray.strftime("%Y-%m-%d %H:%M:%S")contentList = []for index, ent in enumerate(entries):try:entryId = ent.get('entryId', "")if 'tweet' in entryId:l_result = ent['content']['itemContent']['tweet_results']['result'] if ent['content'].get('itemContent') else Noneif l_result:contentList.append(l_result)elif "profile-conversation" in entryId:items = ent['content']['items']for i in items:l_result = i['item']['itemContent']['tweet_results']['result'] if i['item'].get('itemContent') else Noneif l_result:contentList.append(l_result)except:passfor l in contentList:try:result = l.get('tweet') if l.get('tweet') else llegacy = result['legacy']core = result['core']created_at = transTime(legacy.get('created_at'))full_text = legacy.get('full_text')note_tweet = result.get('note_tweet')favorite_count = legacy.get('favorite_count') # 点赞reply_count = legacy.get('reply_count') # 回复retweet_count = legacy.get('retweet_count', 0)quote_count = legacy.get('quote_count', 0)retweet_count = retweet_count + quote_countif note_tweet:try:full_text = note_tweet['note_tweet_results']['result']['text']except:passu_legacy = core['user_results']['result']['legacy']hash_uname = u_legacy.get('screen_name')description = u_legacy['description']friends_count = u_legacy['friends_count']followers_count = u_legacy.get('followers_count')item = {"内容":full_text,"时间": created_at,"点赞":favorite_count,"评论":reply_count,"转发":retweet_count,"用户名": hash_uname,"简介": description,\"粉丝量":followers_count,"关注量":friends_count}print("数据->",item)resultList.append(item)except:passself.save_data(resultList)
最后我们要将数据保存为一个本地csv文件。
def save_data(self, resultList):if resultList:df = pd.DataFrame(resultList)if not os.path.exists(f'./{self.saveFileName}.csv'):df.to_csv(f'./{self.saveFileName}.csv', index=False, mode='a', sep=",", encoding="utf_8_sig")else:df.to_csv(f'./{self.saveFileName}.csv', index=False, mode='a', sep=",", encoding="utf_8_sig",header=False)self.resultList = []print("保存成功")
整个流程通过一个入口函数控制,在运行的同时打印一些状态信息。
def run(self,word):cursor = ""page = 1while True:# if page > 2:# breakprint("正在爬取的页数:%s,cursor:%s"%(page,cursor))resqJson = self.get(cursor)if not resqJson:breakcursor,entries = self.get_cursor(resqJson)if entries:self.parse_data(entries)page += 1else:break
def main(self,fromDate,endDate):wordList = ["climate change"]start = 0for index,word in enumerate(wordList[start:],start):self.searchCondition = f"{word} lang:en until:{endDate} since:{fromDate}"print("搜索条件:",self.searchCondition)self.run(word)通过一个主函数执行整个程序,这里需要用户粘贴自己的cookie。
if __name__ == '__main__':cookie_str = '改成你自己的cookies'fromDate = "2024-08-10"endDate = "2024-10-13"saveFileName= "Tim_Cook"ctks = CsxqTwitterKeywordSearch(saveFileName,cookie_str)ctks.main(fromDate,endDate)
运行一下就可以获得结果,可以看到程序运行正常。

总结
上面的实战演示展示了配置动态住宅IP和社交平台API接口的方法,并演示了如何制作爬虫程序进行数据采集,包括设置参数、配置请求头和请求参数、获取元数据、提取目标数据以及将数据保存为本地CSV文件,通过粘贴自己的cookie即可运行程序。在这一过程中我们也看到了动态住宅IP的作用,在大量采集数据的时候,通过使用动态住宅IP服务,可以有效减少被平台识别和拦截的概率,不仅提高了数据采集的效率,还增强了隐匿性,从而更好地规避平台的限制。于此同时我们也测试了亮数据产品的可靠性,不论是在易用性和产品的丰富性上都有独到之处。不仅如此,亮数据还有一些爬虫工具可供使用,![]()
粉丝福利

相关文章:
爬虫实战:利用代理ip爬取推特网站数据
引言 亮数据-网络IP代理及全网数据一站式服务商屡获殊荣的代理网络、强大的数据挖掘工具和现成可用的数据集。亮数据:网络数据平台领航者https://www.bright.cn/?promoRESIYEAR50/?utm_sourcebrand&utm_campaignbrnd-mkt_cn_csdn_yingjie202502 在跨境电商、社…...
git使用,注意空格
第一节 安装完成后,找个目录用于存储,打开目录右击选择git bash here 命令1 姓名 回车 git config --global user.name "li" 命令2 邮箱 回车 git config --global user.email "888163.com" 命令3 初始化新仓库,下载克隆 回…...

138,【5】buuctf web [RootersCTF2019]I_<3_Flask
进入靶场 这段代码是利用 Python 的类继承和反射机制来尝试执行系统命令读取flag.txt文件内容 .__class__:空字符串对象调用__class__属性,得到str类,即字符串的类型。__class__.__base__:str类的__base__属性指向其基类…...

docker 运行 芋道微服务
创建文件夹 docker-ai 文件夹下放入需要jar包的文件夹及 docker-compose.yml 文件 docker-compose.yml 内容:我这里的是ai服务,所以将原先的文件内容做了变更,你们需要用到什么服务就在下面文件中进行更改即可 version: 3 services:yudao-g…...

C++ Primer 函数重载
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

【Rust中级教程】1.6. 内存 Pt.4:静态(static)内存与‘static生命周期标注
喜欢的话别忘了点赞、收藏加关注哦(加关注即可阅读全文),对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 1.6.1. 静态(static)内存 static内存实际上是一个统称,它指的是程序编译后的文…...

【设计模式】【行为型模式】解释器模式(Interpreter)
👋hi,我不是一名外包公司的员工,也不会偷吃茶水间的零食,我的梦想是能写高端CRUD 🔥 2025本人正在沉淀中… 博客更新速度 👍 欢迎点赞、收藏、关注,跟上我的更新节奏 🎵 当你的天空突…...

修改OnlyOffice编辑器默认字体
通过Docker修改OnlyOffice编辑器默认字体 问题描述详细方案1. 删除原生字体文件2. 创建字体目录3. 复制字体文件到容器中4. 执行字体更新脚本5. 重新启动容器 注意事项 问题描述 在OnlyOffice中,编辑器的默认字体可能不符合公司或个人的需求,通常会使用…...

React echarts柱状图点击某个柱子跳转页面
绘制echarts柱状图 在 ECharts 中,如果你想要在点击柱状图的某个柱子时进行页面跳转,你可以通过设置 series 中的 data 属性中的 itemStyle 或者使用 series 的 label 属性中的 emphasis 属性来实现。但是,直接在柱状图中实现点击跳转通常涉…...

wordpress主题插件开发中高频使用的38个函数
核心模板函数 get_header()/get_footer()/get_sidebar() – 加载模板部件 the_title()/the_content()/the_excerpt() – 显示文章标题、内容、摘要 the_post() – 循环中获取文章数据 bloginfo(‘url’) – 获取站点URL wp_head()/wp_footer() – 输出头部/尾部代码 wp_n…...

ElasticSearch基础和使用
ElasticSearch基础 1 初识ES相关组件 (1)Elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。Elasticsearch结合kibana、Logstash、Beats组件 也就是elastic stack(ELK) 广泛应…...

qt-C++笔记之QGraphicsScene和 QGraphicsView中setScene、通过scene得到view、通过view得scene
qt-C++笔记之QGraphicsScene和 QGraphicsView中setScene、通过scene得到view、通过view得scene code review! 文章目录 qt-C++笔记之QGraphicsScene和 QGraphicsView中setScene、通过scene得到view、通过view得scene1.`setScene` 方法2.通过 `scene` 获取它的视图 (`views()`)…...

小白win10安装并配置yt-dlp
需要yt-dlp和ffmpeg 注意存放路径最好都是全英文 win10安装并配置yt-dlp 一、下载1.下载yt-dlp2. fffmpeg下载 二、配置环境三、cmd操作四、yt-dlp下视频操作 一、下载 1.下载yt-dlp yt-dlp地址 找到win的压缩包点下载,并解压 2. fffmpeg下载 ffmpeg官方下载 …...

【kafka系列】broker
目录 Broker 接收生产者消息和返回消息给消费者的流程逻辑分析 Broker 处理生产者消息的核心流程 Broker 处理消费者消息的核心流程 关键点总结 Broker 接收生产者消息和返回消息给消费者的流程逻辑分析 Broker 处理生产者消息的核心流程 接收请求 Broker 的 SocketServer …...

用大模型学大模型05-线性回归
deepseek.com:多元线性回归的目标函数,损失函数,梯度下降 标量和矩阵形式的数学推导,pytorch真实能跑的代码案例以及模型,数据,预测结果的可视化展示, 模型应用场景和优缺点,及如何改进解决及改进方法数据推…...

Python实现AWS Fargate自动化部署系统
一、背景介绍 在现代云原生应用开发中,自动化部署是提高开发效率和保证部署质量的关键。AWS Fargate作为一项无服务器计算引擎,可以让我们专注于应用程序开发而无需管理底层基础设施。本文将详细介绍如何使用Python实现AWS Fargate的完整自动化部署流程。 © ivwdcwso (ID…...

国产编辑器EverEdit - 上下翻滚不迷路(历史编辑位置、历史光标位置回溯功能)
1 光标位置跳转 1.1 应用场景 某些场景下,用户从当前编辑位置跳转到别的位置查阅信息,如果要快速跳转回之前编辑位置,则可以使用光标跳转相关功能。 1.2 使用方法 1.2.1 上一个编辑位置 跳转到上一个编辑位置,即文本修改过的位…...
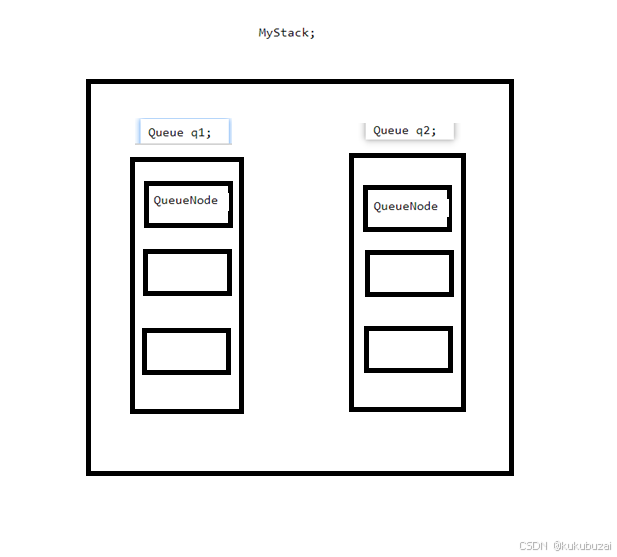
今日写题work05
题目:用队列实现栈 思路 队列的特点是先进先出,而栈的特点是后进先出。所以想要用队列实现模拟栈,我们可以使用两个队列,一个队列负责压栈,一个队列负责出栈。压栈很简单就是检空再调用队列的push就好,那出…...

[C++语法基础与基本概念] std::function与可调用对象
std::function与可调用对象 函数指针lambda表达式std::function与std::bind仿函数总结std::thread与可调用对象std::async与可调用对象回调函数 可调用对象是指那些像函数一样可以直接被调用的对象,他们广泛用于C的算法,回调,事件处理等机制。…...

两个实用且热门的 Python 爬虫案例,结合动态/静态网页抓取和反爬策略,附带详细代码和实现说明
在这个瞬息万变的世界里,保持一颗探索的心,永远怀揣梦想前行。即使有时会迷失方向,也不要忘记内心深处那盏指引你前进的明灯。它代表着你的希望、你的信念以及对未来的无限憧憬。每一个不曾起舞的日子,都是对生命的辜负࿱…...

SpringBoot项目里,Apollo配置加载顺序的‘潜规则’与实战应用
SpringBoot项目中Apollo配置加载顺序的深度解析与高阶实践 在分布式系统架构中,配置管理一直是开发者需要面对的核心挑战之一。当SpringBoot遇上Apollo配置中心,看似简单的配置加载背后隐藏着一套精密的优先级规则体系。这些规则不仅影响着日常开发调试的…...
)
GB28181语音对讲实战:从SIP信令到PCMA音频流的完整抓包分析(附C++代码示例)
GB28181语音对讲实战:从SIP信令到PCMA音频流的完整抓包分析(附C代码示例) 在视频监控系统的开发中,语音对讲功能往往是实现双向实时通信的关键环节。GB28181标准作为国内广泛应用的视频监控联网标准,其语音对讲功能基于…...

透明背景图片制作方法大全:从零基础到高效批量处理
前几天,一位做电商的朋友问我怎样快速处理商品图片的背景。她手里有几百张产品照片,需要换成透明背景上架到各个平台,用传统方法根本来不及。这个问题其实戳中了很多人的痛点——无论是证件照换底色、电商商品去背景,还是社交媒体…...

智能手机号地理位置查询系统:基于ASP.NET的高效定位解决方案
智能手机号地理位置查询系统:基于ASP.NET的高效定位解决方案 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/g…...

ArkTS:在自定义组件内不能使用function定义函数
例如,在自定义组件内,用function定义函数,出现告警:我现在将function定义的函数移到组件外边:进行组件预览,日志输出了结果:...

程序员换新电脑资料准备
文章目录场景主要分类过程qq、微信、钉钉各个项目的vpn、公司内软件等jdkmaven、maven仓库项目资料谷歌浏览器etc、opt等tortoise gitgit bashpostmanatomideadbeaver等数据库连接工具xshell、Xterm等shell工具foxmail电脑安全管家等安全软件图片等私人资料最后一定记得将电脑清…...

agent-skills中的代码简化技术:提升代码可读性和可维护性的实用方法
agent-skills中的代码简化技术:提升代码可读性和可维护性的实用方法 【免费下载链接】agent-skills Production-grade engineering skills for AI coding agents. 项目地址: https://gitcode.com/GitHub_Trending/agentskill/agent-skills agent-skills是一个…...

终极TensorFlow资源指南:从入门到精通的精选项目架构全解析
终极TensorFlow资源指南:从入门到精通的精选项目架构全解析 【免费下载链接】awesome-tensorflow TensorFlow - A curated list of dedicated resources http://tensorflow.org 项目地址: https://gitcode.com/gh_mirrors/awe/awesome-tensorflow TensorFlow…...

嵌入式C++硬件交互与ROM优化实践
1. 嵌入式系统中的C硬件交互基础在嵌入式开发领域,C长期被视为"过于庞大"的语言,但现代嵌入式系统复杂度提升使得其优势逐渐显现。与C语言相比,C在保持相同执行效率的前提下,提供了更强大的抽象能力。我们来看一个典型场…...

一键部署本地大模型:从自动化脚本到实战部署全解析
1. 项目概述与核心价值最近在折腾本地大语言模型(LLM)的朋友,估计都绕不开一个词:一键部署。从早期的复杂脚本到如今的各种图形化工具,大家追求的目标都很一致——让技术门槛降下来,让更多人能轻松玩起来。…...