java05(类、泛型、JVM、线程)---java八股
类
Java中有哪些类加载器
JDK自带有三个类加载器:bootstrap ClassLoader、ExtClassLoader、AppClassLoader。
●BootStrapClassLoader是ExtClassLoader的父类加载器,默认负责加载%JAVA_HOME%lib下的jar包和class文件。
●ExtClassLoader是AppClassLoader的父类加载器,负责加载%JAVA_HOME%/lib/ext文件夹下的jar包和class类。
●AppClassLoader是自定义类加载器的父类,负责加载classpath下的类文件。
泛型
泛型中extends和super的区别
extends用于指定上界(上限),表示类型参数必须是某个类或接口的子类(或实现类)。super用于指定下界(下限),表示类型参数必须是某个类或接口的父类(或接口的父类)。T extends Number 表示 T 必须是 Number 或其子类。
<? super T> 使得我们可以将 T 或其子类的实例添加到该集合中。例如,如果 T 是 Integer,那么我们可以将 Integer 和其父类 Number 的实例添加到 List<? super Integer> 中。
super 确保了我们只能向集合中插入 T 类型的元素,不能读取具体的元素类型,因为你只能确认元素的类型为 Object 或 T 的父类。
JVM
java的运行时的数据区
Java的运行时数据区是JVM(Java虚拟机)在程序运行时所划分的内存区域。它主要包括以下几个部分:
方法区 (Method Area)
存储类信息、常量池、静态变量等数据。它是所有线程共享的区域,用来存放已经被加载到JVM中的类信息、方法信息、常量池等。
在JVM规范中,方法区也可以称作永久代 (Permanent Generation),但是在JDK 8以后,永久代被Metaspace所取代。堆 (Heap)
Java堆是JVM中最大的内存区域,所有对象和数组都在这里分配。它是所有线程共享的区域。堆的内存可以由GC(垃圾回收)进行管理,负责清理不再使用的对象。
堆主要分为两个部分:
- 年轻代 (Young Generation):存放新创建的对象。
- 老年代 (Old Generation):存放经过多次GC仍然存活的对象。
Java栈 (Java Stack)
每个线程都有自己的栈,栈中存储的是局部变量、方法调用和控制信息等。栈的大小由JVM参数进行设置。
栈中的数据分为:
- 局部变量区:用于存储方法的局部变量和部分参数。
- 方法调用信息:包括栈帧(Stack Frame)和执行过程中的相关信息。
程序计数器 (Program Counter Register)
每个线程都有一个程序计数器,它用来记录当前线程执行的字节码指令的地址。
当线程被切换时,程序计数器保存当前执行的指令地址,保证线程切换后能够继续执行。
它是唯一一个在jvm规范中没有规定任何OutOfMemoryError情况的区域本地方法栈 (Native Method Stack)
与Java栈类似,区别在于它用于处理Native方法(即非Java代码编写的方法)。Native方法栈用于存储本地方法调用的相关信息。这些区域协同工作,保证了Java程序的顺利执行,并通过垃圾回收机制等手段管理内存。
JVM中哪些是线程共享区
堆区和方法区是所有线程共享的
栈、本地方法栈、程序计数器是每个线程独有的
什么是 OutOfMemoryError(OOM)?
OutOfMemoryError 是 Java 中的一种运行时错误,表示 Java 虚拟机(JVM)无法再分配足够的内存来满足程序的内存请求。通常会出现在以下几种情况:
- 堆内存溢出(Heap OOM):JVM 的堆内存不足,无法分配更多对象。
- 方法区溢出(Metaspace OOM):JVM 的元空间(或类的加载区)不足,无法加载更多类或方法信息。
- 直接内存溢出:JVM 分配给直接内存(通过
ByteBuffer.allocateDirect)的内存不足。OOM 异常发生的情况
堆内存不足(
java.lang.OutOfMemoryError: Java heap space):
- 当 JVM 的堆内存不够用时,系统无法为新对象分配空间,进而导致 OOM 错误。此时,JVM 会尝试 GC(垃圾回收),但是如果回收后内存仍然不足,就会抛出该异常。
元空间不足(
java.lang.OutOfMemoryError: Metaspace):
- 在 Java 8 之后,类的元数据(如类定义)存储在元空间(Metaspace)中,而不是堆中。如果类的加载超过了 Metaspace 的限制,也会抛出 OOM 错误。
直接内存不足(
java.lang.OutOfMemoryError: Direct buffer memory):
- 使用
ByteBuffer.allocateDirect()分配直接内存时,如果没有足够的物理内存,JVM 会抛出OutOfMemoryError。
OOM 发生时,进程会不会挂掉?
通常情况下,OOM 会导致进程终止:
OutOfMemoryError是一个严重的错误,通常会导致 JVM 无法继续运行,因此会使进程退出。- 如果 JVM 无法分配足够的内存,它通常会抛出
OutOfMemoryError异常,这个异常是Error类型的,而不是Exception,意味着它通常不能被应用程序捕获并处理。- 应用程序无法处理 OOM 异常,这意味着一旦发生 OOM,JVM 会尝试终止进程,释放资源并输出错误信息。
JVM 如何响应 OOM 异常?
当
OutOfMemoryError被抛出时,JVM 通常会触发以下操作:
- 停止当前线程:当 OOM 发生时,当前线程会被终止。
- 打印错误日志:JVM 会打印出错误日志,指示哪种内存(堆、元空间、直接内存等)导致了 OOM。
- 终止进程:由于
OutOfMemoryError是一种Error,它通常会导致应用程序退出,进程会被挂掉。
如何处理 OOM?
虽然 OOM 通常不能被捕获或处理,但可以采取以下措施以减少发生 OOM 的概率:
- 优化内存使用:避免内存泄漏,减少不必要的大对象创建,合理使用内存。
- 配置 JVM 内存参数:通过设置
-Xmx(最大堆内存)、-Xms(初始堆内存)、-XX:MaxMetaspaceSize等参数来控制 JVM 的内存分配。- GC 调优:使用合适的垃圾回收策略来减少内存的碎片化。
- 使用外部监控工具:例如,使用 JConsole、VisualVM 等工具来监控内存使用情况,及时发现潜在的内存问题。
一个对象从加载到JVM,再到被GC清除,都经历了什么过程?
- 首先把字节码文件内容加载到方法区
- 然后再根据类信息在堆区创建对象
- 对象首先会分配在堆区中年轻代的Eden区,经过一次Minor GC后,对象如果存活,就会进入Suvivor区。在后续的每次Minor GC中,如果对象一直存活,就会在Suvivor区来回拷贝,每移动一次,年龄加1
- 当年龄超过15后,对象依然存活,对象就会进入老年代
- 如果经过Full GC,被标记为垃圾对象,那么就会被GC线程清理掉
怎么确定一个对象到底是不是垃圾?
- 引用计数算法: 这种方式是给堆内存当中的每个对象记录一个引用个数。引用个数为0的就认为是垃圾。这是早期JDK中使用的方式。引用计数无法解决循环引用的问题。
- 可达性算法: 这种方式是在内存中,从根对象向下一直找引用,找到的对象就不是垃圾,没找到的对象就是垃圾。
JVM有哪些垃圾回收算法?
- 1标记清除算法:
- a标记阶段:把垃圾内存标记出来
- b清除阶段:直接将垃圾内存回收。
- c这种算法是比较简单的,但是有个很严重的问题,就是会产生大量的内存碎片。
- 2复制算法:为了解决标记清除算法的内存碎片问题,就产生了复制算法。复制算法将内存分为大小相等的两半,每次只使用其中一半。垃圾回收时,将当前这一块的存活对象全部拷贝到另一半,然后当前这一半内存就可以直接清除。这种算法没有内存碎片,但是他的问题就在于浪费空间。而且,他的效率跟存活对象的个数有关。
- 3标记压缩算法:为了解决复制算法的缺陷,就提出了标记压缩算法。这种算法在标记阶段跟标记清除算法是一样的,但是在完成标记之后,不是直接清理垃圾内存,而是将存活对象往一端移动,然后将边界以外的所有内存直接清除。
什么是STW?
STW: Stop-The-World,是在垃圾回收算法执行过程当中,需要将JVM内存冻结的一种状态。在STW状态下,JAVA的所有线程都是停止执行的-GC线程除外,native方法可以执行,但是,不能与JVM交互。GC各种算法优化的重点,就是减少STW,同时这也是JVM调优的重点。
JVM参数有哪些?
JVM参数大致可以分为三类:
1标注指令: -开头,这些是所有的HotSpot都支持的参数。可以用java -help 打印出来。
2非标准指令: -X开头,这些指令通常是跟特定的HotSpot版本对应的。可以用java -X 打印出来。
3不稳定参数: -XX 开头,这一类参数是跟特定HotSpot版本对应的,并且变化非常大。
线程
说说对线程安全的理解
线程安全(Thread Safety)是指多个线程同时访问某个对象时,该对象的状态不会受到线程的干扰,并且不会导致错误的行为或数据不一致。
换句话说,线程安全的程序在多线程环境下运行时,不会因为线程的切换和并发访问导致问题。
对守护线程的理解
线程分为用户线程和守护线程,用户线程就是普通线程,守护线程就是JVM的后台线程,比如垃圾回收线程就是一个守护线程,守护线程会在其他普通线程都停止运行之后自动关闭。我们可以通过设置thread.setDaemon(true)来把一个线程设置为守护线程。
ThreadLocal的底层原理
- ThreadLocal是Java中所提供的线程本地存储机制,可以利用该机制将数据缓存在某个线程内部,该线程可以在任意时刻、任意方法中获取缓存的数据
- ThreadLocal底层是通过ThreadLocalMap来实现的,每个Thread对象(注意不是ThreadLocal对象)中都存在一个ThreadLocalMap,Map的key为ThreadLocal对象,Map的value为需要缓存的值
- 如果在线程池中使用ThreadLocal会造成内存泄漏,因为当ThreadLocal对象使用完之后,应该要把设置的key,value,也就是Entry对象进行回收,但线程池中的线程不会回收,而线程对象是通过强引用指向ThreadLocalMap,ThreadLocalMap也是通过强引用指向Entry对象,线程不被回收,Entry对象也就不会被回收,从而出现内存泄漏,解决办法是,在使用了ThreadLocal对象之后,手动调用ThreadLocal的remove方法,手动清楚Entry对象
- ThreadLocal经典的应用场景就是连接管理(一个线程持有一个连接,该连接对象可以在不同的方法之间进行传递,线程之间不共享同一个连接)
并发、并行、串行之间的区别
串行:一个任务执行完,才能执行下一个任务
并行(Parallelism):两个任务同时执行
并发(Concurrency):两个任务整体看上去是同时执行,在底层,两个任务被拆成了很多份,然后一个一个执行,站在更高的角度看来两个任务是同时在执行的
造成死锁的几个原因:
死锁(Deadlock) 是指两个或多个线程在执行过程中,因争夺资源而互相等待,导致线程无法继续执行的情况。死锁会导致程序的执行陷入无限等待状态,影响系统的稳定性和性能。
死锁的四个必要条件
死锁发生的必要条件包括以下四个:
- 互斥条件(Mutual Exclusion):至少有一个资源必须处于非共享模式,即每次只能有一个线程使用该资源。
- 占有且等待条件(Hold and Wait):一个线程持有一个资源,同时等待另一个线程持有的资源。
- 非抢占条件(No Preemption):资源不能被强制从一个线程中剥夺,必须由线程自行释放。
- 循环等待条件(Circular Wait):存在一种线程循环等待的关系,线程
T1等待T2,线程T2等待T3,直到线程Tn等待T1,形成一个闭环。为了避免死锁,通常我们需要打破上述的至少一个条件。
Java死锁如何避免?
1. 破坏循环等待条件
- 通过规定线程获取资源的顺序来避免循环等待条件。例如,在系统中规定所有线程必须按一定的顺序请求资源。如果每个线程按照相同的顺序请求资源,那么就避免了死锁的发生。
2、使用定时锁
- 使用定时锁(
ReentrantLock的tryLock(long time, TimeUnit unit)方法)来避免线程长时间等待锁。如果在规定时间内无法获得锁,则放弃,避免死锁。3、采用资源分配图算法(如银行家算法)
- 对资源进行动态管理,使用类似银行家算法的方式,检查是否会导致死锁。如果当前的资源分配会导致死锁,则拒绝该请求。该方法需要复杂的资源分配图和算法支持,适用于需要严格管理资源分配的场景。
4、减少锁的持有时间
- 在执行临界区代码时,尽量减少持有锁的时间。只在必要的情况下持有锁,完成任务后立即释放锁。这不仅有助于减少死锁的发生,也能提高程序的并发性能。
5、使用工具检测死锁
- Java 提供了一些工具和技术来帮助开发人员检测死锁,例如:
- JVM监控工具:可以使用
jstack或者通过JConsole、VisualVM等工具监控线程的状态,发现是否有死锁。- 线程调度器:一些线程调度框架(如
ThreadMXBean)可以获取 JVM 的死锁信息。6、优化资源使用顺序
- 可以对系统资源进行排序或分配,确保所有线程都按照统一的顺序获取资源,避免因资源获取顺序不一致而产生循环等待。这样可以消除循环等待条件。
线程池的工作模式
线程池的工作原理通常包括以下几个部分:
- 任务队列:用于缓存等待执行的任务。队列的大小决定了能缓存多少个任务,而不会直接创建线程来执行任务。
- 核心线程数(corePoolSize):线程池在没有任务时,仍会保持这么多个线程处于活动状态,随时准备执行任务。
- 最大线程数(maximumPoolSize):线程池可以创建的最大线程数,超过这个值的任务会进入等待队列,或者根据拒绝策略处理。
如果线程池在任务到来时首先创建最大线程数,而不使用队列缓存任务,那么无论任务数量如何,都会立刻创建新线程,这不仅没有利用队列的缓冲作用,还可能在瞬间创建大量的线程,造成系统资源浪费。
线程池的底层工作原理
线程池内部是通过队列+线程实现的,当我们利用线程池执行任务时:
- 如果此时线程池中的线程数量小于corePoolSize,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务。
- 如果此时线程池中的线程数量等于corePoolSize,但是缓冲队列workQueue未满,那么任务被放入缓冲队列。
- 如果此时线程池中的线程数量大于等于corePoolSize,缓冲队列workQueue满,并且线程池中的数量小于maximumPoolSize,建新的线程来处理被添加的任务。
- 如果此时线程池中的线程数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量等于maximumPoolSize,那么通过 handler所指定的策略来处理此任务。
- 当线程池中的线程数量大于 corePoolSize时,如果某线程空闲时间超过keepAliveTime,线程将被终止。这样,线程池可以动态的调整池中的线程数
线程池为什么是先添加列队而不是先创建最大线程?
线程池采用先添加到队列而不是先创建最大线程的设计,主要是为了提高资源利用率,减少线程创建的开销,避免系统过度消耗资源,并通过合理的线程调度提高系统性能。这样可以保证线程池在高并发情况下依然高效运作,避免线程争用、内存溢出等问题的发生。
提高资源利用率,减少线程创建的开销
- 线程的创建、销毁和上下文切换是有开销的。每次创建一个线程时,JVM 都需要分配内存并进行初始化,而销毁线程时又需要释放资源,这个过程本身就会消耗时间和系统资源。
- 如果线程池在任务到来时直接创建最大线程,意味着即使任务数量很少,线程池也会创建大量的线程,这不仅增加了系统开销,还可能导致内存不足等问题。
解决方案: 线程池采用队列来缓存任务,线程池中的线程可以复用,避免频繁创建和销毁线程。通过先将任务放入队列,线程池可以按需创建线程,只有在队列满且线程数小于最大线程数时才会创建新线程。
控制线程数目,避免资源过度消耗
- 如果线程池直接创建最大线程,系统的资源(如 CPU、内存)可能会因为线程数过多而受到压垮,尤其是在大量任务涌入时,系统可能会过度创建线程,导致线程争用,使得系统性能急剧下降。
- 通过先将任务放入队列,可以限制同时活跃的线程数目,并确保不会因为任务过多而瞬间消耗掉系统的所有资源。
ReentrantLock中的公平锁和非公平锁的底层实现
首先不管是公平锁和非公平锁,它们的底层实现都会使用AQS来进行排队,它们的区别在于:线程在使用lock()方法加锁时,如果是公平锁,会先检查AQS队列中是否存在线程在排队,如果有线程在排队,则当前线程也进行排队,如果是非公平锁,则不会去检查是否有线程在排队,而是直接竞争锁。
不管是公平锁还是非公平锁,一旦没竞争到锁,都会进行排队,当锁释放时,都是唤醒排在最前面的线程,所以非公平锁只是体现在了线程加锁阶段,而没有体现在线程被唤醒阶段。
ReentrantLock中tryLock()和lock()方法的区别
- tryLock()表示尝试加锁,可能加到,也可能加不到,该方法不会阻塞线程,如果加到锁则返回true,没有加到则返回false
- lock()表示阻塞加锁,线程会阻塞直到加到锁,方法也没有返回值
CountDownLatch和Semaphore的区别和底层原理
CountDownLatch表示计数器,可以给CountDownLatch设置一个数字,一个线程调用CountDownLatch的await()将会阻塞,其他线程可以调用CountDownLatch的countDown()方法来对CountDownLatch中的数字减一,当数字被减成0后,所有await的线程都将被唤醒。
对应的底层原理就是,调用await()方法的线程会利用AQS排队,一旦数字被减为0,则会将AQS中排队的线程依次唤醒。Semaphore表示信号量,可以设置许可的个数,表示同时允许最多多少个线程使用该信号量,通过acquire()来获取许可,如果没有许可可用则线程阻塞,并通过AQS来排队,可以通过release()方法来释放许可,当某个线程释放了某个许可后,会从AQS中正在排队的第一个线程开始依次唤醒,直到没有空闲许可。
Sychronized的偏向锁、轻量级锁、重量级锁
- 偏向锁:在锁对象的对象头中记录一下当前获取到该锁的线程ID,该线程下次如果又来获取该锁就可以直接获取到了
- 轻量级锁:由偏向锁升级而来,当一个线程获取到锁后,此时这把锁是偏向锁,此时如果有第二个线程来竞争锁,偏向锁就会升级为轻量级锁,之所以叫轻量级锁,是为了和重量级锁区分开来,轻量级锁底层是通过自旋来实现的,并不会阻塞线程
- 如果自旋次数过多仍然没有获取到锁,则会升级为重量级锁,重量级锁会导致线程阻塞
- 自旋锁:自旋锁就是线程在获取锁的过程中,不会去阻塞线程,也就无所谓唤醒线程,阻塞和唤醒这两个步骤都是需要操作系统去进行的,比较消耗时间,自旋锁是线程通过CAS获取预期的一个标记,如果没有获取到,则继续循环获取,如果获取到了则表示获取到了锁,这个过程线程一直在运行中,相对而言没有使用太多的操作系统资源,比较轻量。
Sychronized和ReentrantLock的区别
- 1sychronized是一个关键字,ReentrantLock是一个类
- 2sychronized会自动的加锁与释放锁,ReentrantLock需要程序员手动加锁与释放锁
- 3sychronized的底层是JVM层面的锁,ReentrantLock是API层面的锁
- 4sychronized是非公平锁,ReentrantLock可以选择公平锁或非公平锁
- 5sychronized锁的是对象,锁信息保存在对象头中,ReentrantLock通过代码中int类型的state标识来标识锁的状态
- 6sychronized底层有一个锁升级的过程
谈谈你对AQS的理解,AQS如何实现可重入锁?
- AQS是一个JAVA线程同步的框架。是JDK中很多锁工具的核心实现框架。
- 在AQS中,维护了一个信号量state和一个线程组成的双向链表队列。其中,这个线程队列,就是用来给线程排队的,而state就像是一个红绿灯,用来控制线程排队或者放行的。 在不同的场景下,有不用的意义。
- 在可重入锁这个场景下,state就用来表示加锁的次数。0标识无锁,每加一次锁,state就加1。释放锁state就减1。
相关文章:

java05(类、泛型、JVM、线程)---java八股
类 Java中有哪些类加载器 JDK自带有三个类加载器:bootstrap ClassLoader、ExtClassLoader、AppClassLoader。 ●BootStrapClassLoader是ExtClassLoader的父类加载器,默认负责加载%JAVA_HOME%lib下的jar包和class文件。 ●ExtClassLoader是AppClassLoade…...
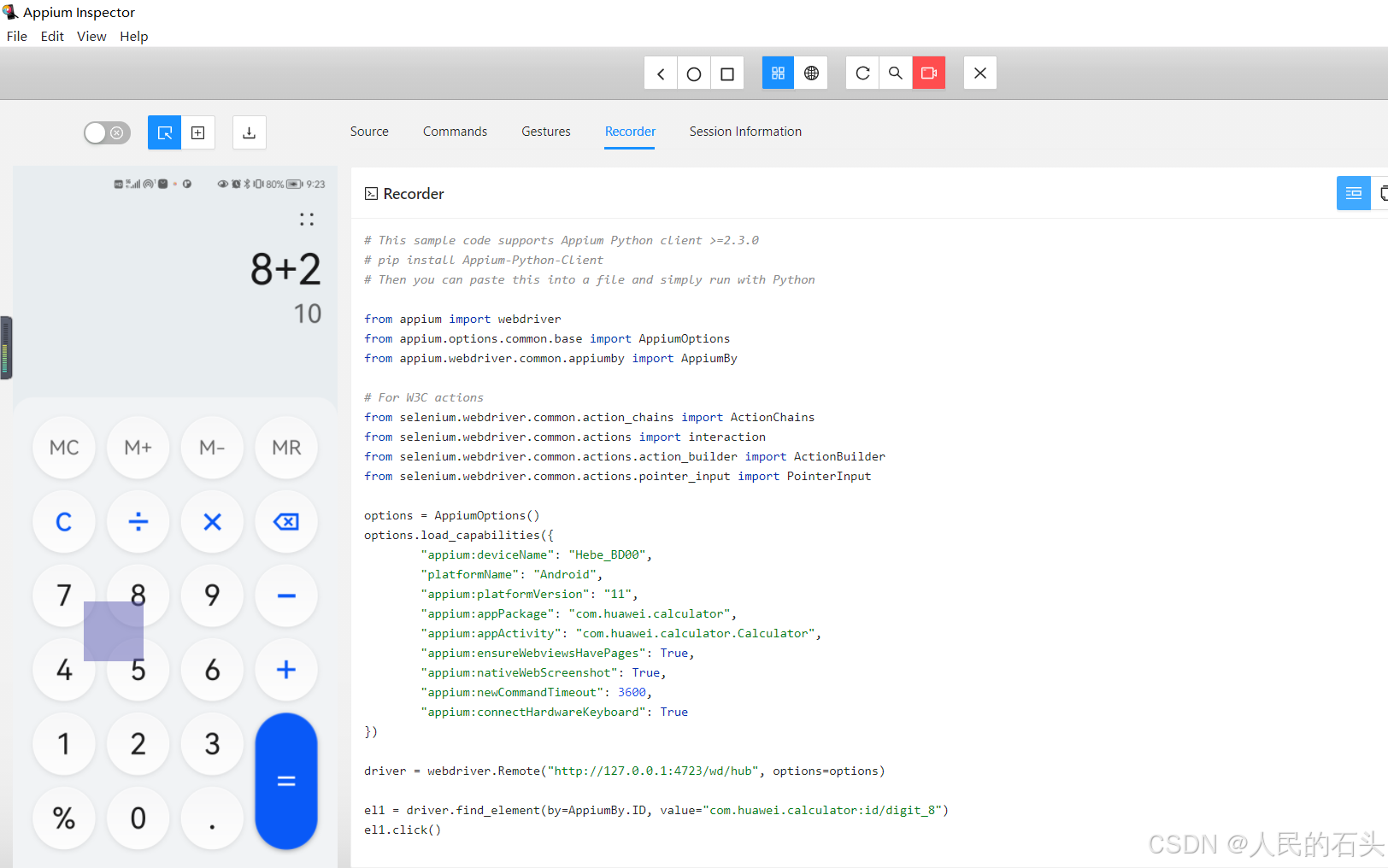
Python+appium实现自动化测试
目录 一、工具与环境准备 二、开始测试 1、插上手机,打开usb调试,选中文件传输,我这里用华为手机为例 2、启动Appium Server GUI编辑 3、启动 Inspector Session 4、录制脚本 使用Python和Appium进行自动化测试是一种常见的移动应用…...

Unity中如何判断URL是否为RTSP或RTMP流
技术背景 如何在Unity中判断一个字符串URL是否是RTSP或RTMP流。首先,RTSP通常以“rtsp://”开头,而RTMP则是“rtmp://”或者有时是“rtmps://”用于安全连接。 接下来,如何在C#中进行字符串的检查。最简单的方法应该是检查URL是否以这些协议…...

基于角色访问控制的UML 表示02
一个用户可以成为很多角色的成员,一个角色可以有许多用户。类似地,一个角色可以有多个权限,同一个权限可以被指派给多个角色。每个会话把一个用户和可能的许多角色联系起来。一个用户在激发他或她所属角色的某些子集时,建立了一个…...

【函数题】6-10 二分查找
6-10 二分查找 1 题目原文2 思路解析2.1 基本二分查找算法2.2 常用二分模板2.2.1 第一个大于等于目标值的元素下标2.2.2 第一个大于目标值的元素下标2.2.3 最后一个小于等于目标值的元素下标2.2.3 最后一个小于目标值的元素下标2.2.4 小结 3 代码实现3.1 本题代码实现3.1.1 递归…...

关于conda换镜像源,pip换源
目录 1. 查看当前下载源2. 添加镜像源2.1清华大学开源软件镜像站2.2上海交通大学开源镜像站2.3中国科学技术大学 3.删除镜像源4.删除所有镜像源,恢复默认5.什么是conda-forge6.pip换源 1. 查看当前下载源 conda config --show channels 如果发现多个 可以只保留1个…...

DeepSeek与ChatGPT的全面对比
在人工智能(AI)领域,生成式预训练模型(GPT)已成为推动技术革新的核心力量。OpenAI的ChatGPT自发布以来,凭借其卓越的自然语言处理能力,迅速占据市场主导地位。然而,近期中国AI初创公…...

Spring AI发布!让Java紧跟AI赛道!
1. 序言 在当今技术发展的背景下,人工智能(AI)已经成为各行各业中不可忽视的重要技术。无论是在互联网公司,还是传统行业,AI技术的应用都在大幅提升效率、降低成本、推动创新。从智能客服到个性化推荐,从语…...

基于CT107D单片机综合训练平台的秒表设计
1. 项目简介 在CT107D单片机综合训练平台上,利用定时器T0、数码管模块和2个独立按键(J5的2-3短接),设计一个具有清零、暂停、启动功能的秒表。秒表显示格式为:分-秒-0.05秒(即50ms),…...

opensuse [Linux] 系统挂在新的机械硬盘
opensuse [Linux] 系统挂在新的机械硬盘 需求描述 自用电脑型号如下: 电脑:Precision Tower 7810 (Dell Inc.) CPU : Intel Xeon CPU E5-2686 v4 2.30GHz GPU: NVIDIA GeForce GTX 1070 Linux版本:Linux version 6.…...

时间序列分析(四)——差分运算、延迟算子、AR(p)模型
此前篇章: 时间序列分析(一)——基础概念篇 时间序列分析(二)——平稳性检验 时间序列分析(三)——白噪声检验 一、差分运算 差分运算的定义:差分运算是一种将非平稳时间序列转换…...

【CUDA】Triton
【CUDA】Triton 1. CUDA 与 Triton 的基本区别 CUDA 编程模型: 在传统的 CUDA 编程中,CUDA 是标量程序,带有阻塞线程(blocked threads)。 标量程序(Scalar Program):表示我们直接…...

Windows环境搭建ES集群
搭建步骤 下载安装包 下载链接:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.27-windows-x86_64.zip 解压 解压并复制出3份 es-node1配置 config/elasticsearch.yml cluster.name: xixi-es-win node.name: node-1 path.data: D:\\wor…...

langchain学习笔记之消息存储在内存中的实现方法
langchain学习笔记之消息存储在内存中的实现方法 引言背景消息存储在内存的实现方法消息完整存储:完整代码 引言 本节将介绍 langchain \text{langchain} langchain将历史消息存储在内存中的实现方法。 背景 在与大模型交互过程中,经常出现消息管理方…...

怎么在智能合约中植入deepseek
怎么在智能合约中植入deepseek 这里写目录标题 怎么在智能合约中植入deepseek方法概述具体步骤1. 部署大语言模型到链下2. 创建预言机(Oracle)a. 部署预言机节点b. 创建自定义预言机接口(Custom Oracle)3. 设计智能合约a. 编写Solidity代码b. 部署智能合约4. 调用流程注意事…...

驱动开发系列37 - Linux Graphics 2D 绘制流程(二)- 画布创建和窗口关联
一:概述 前面介绍Pixmap表示一块画布,是绘制发生的地方,本节看看驱动程序如何为画布分配内存/显存,以及如何与窗口关联的。 二:为画布分配BO 在系统启动时(用户登录系统之后,会重启Xorg),在 Xorg 服务器初始化时,要为屏幕创建根窗口的 Pixmap,并绑定到 GPU framebu…...

B. Longest Divisors Interval
time limit per test 2 seconds memory limit per test 256 megabytes Given a positive integer nn, find the maximum size of an interval [l,r][l,r] of positive integers such that, for every ii in the interval (i.e., l≤i≤rl≤i≤r), nn is a multiple of ii. …...

前端与后端的对接事宜、注意事项
前端与后端的对接事宜、注意事项 一、对接核心流程(完整生命周期) #mermaid-svg-6yzij6OD8DKqiMLD {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-6yzij6OD8DKqiMLD .error-icon{fill:#552222;}#mermaid-svg-6yzi…...
与元学习(Meta-Learning)的基础理论与应用案例】)
【第13章:自监督学习与少样本学习—13.2 少样本学习(FSL)与元学习(Meta-Learning)的基础理论与应用案例】
凌晨三点的急诊室,值班医生李大夫正在使用AI辅助诊断系统——面对一张仅有3个标注病例的罕见皮肤病影像,系统竟然给出了95%置信度的准确诊断。这种"见微知著"的超能力,正是少样本学习技术创造的医学奇迹。 一、突破数据荒漠:少样本学习的生存法则 1.1 从人类学习…...

函数防抖和节流
所谓防抖,就是指触发事件后在 n 秒内函数只能执行一次, 如果在 n 秒内又触发了事件,则会重新计算函数执行时间, 短时间高频率触发只有最后一次触发成功 开发使用场景: 搜索框防抖 fn代表要被防抖或者节流的函数&#x…...

智能体通信协议SmartAgentProtocol:打破AI孤岛,构建标准化协作生态
1. 项目概述:一个面向智能体的通用通信协议最近在开源社区里,一个名为SmartAgentProtocol/smartagent的项目引起了我的注意。乍一看这个标题,你可能会觉得它又是一个关于“智能体”或“Agent”的框架,毕竟现在AI领域里各种Agent框…...
)
Python 3.12升级后pip直接罢工?一招‘ensurepip’命令救活你的包管理器(附详细步骤)
Python 3.12升级后pip罢工?官方推荐的终极修复方案 刚升级到Python 3.12的开发者们,是否遇到了一个令人抓狂的问题——pip命令突然无法使用了?这就像买了一辆新车却发现油箱盖打不开一样让人沮丧。别担心,这不是你一个人的问题&am…...

为什么有这么多以字母 “C” 为开头的编程语言?
在Reddit上有个提问:为什么有这么多以字母 “C” 为开头的编程语言?题主从4个月前开始学习编程,对编程语言的数量印象深刻,但后来他意识到有很多字母为“C”的编程语言,例如:C、C、CSS、Objective-C……这是…...

Maestro:基于声明式YAML的轻量级流程编排工具实践指南
1. 项目概述:一个面向开发者的流程编排利器 最近在梳理团队内部一些重复性的开发运维流程时,我一直在寻找一个能让我“偷懒”的工具。这些流程往往涉及多个步骤:比如代码提交后,自动触发代码质量扫描、依赖安全检查、构建Docker镜…...

如何高效解决游戏Mod加载问题:MelonLoader实战解决方案大全
如何高效解决游戏Mod加载问题:MelonLoader实战解决方案大全 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader MelonLo…...

A* 算法学习
在游戏中,有一个很常见地需求,就是要让一个角色从A点走向B点,我们期望是让角色走最少的路。嗯,大家可能会说,直线就是最短的。没错,但大多数时候,A到B中间都会出现一些角色无法穿越的东西&#…...

React Native应用架构设计终极指南:Deco IDE助你构建大型项目
React Native应用架构设计终极指南:Deco IDE助你构建大型项目 【免费下载链接】deco-ide The React Native IDE 项目地址: https://gitcode.com/gh_mirrors/de/deco-ide 在移动应用开发领域,React Native以其跨平台优势和高效开发流程赢得了众多开…...

题解:洛谷 P15799 [GESP202603 五级] 找数
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...

AIOS-Core:基于Node.js与TypeScript的AI智能体编排框架全解析
1. 项目概述:AIOS-Core,一个面向全栈开发的AI智能体编排框架如果你和我一样,长期在Web应用、自动化脚本和微服务架构之间反复横跳,那你一定对“上下文切换”和“工具链碎片化”这两个词深恶痛绝。前端要配构建工具,后端…...
从Halcon仿射变换到实战:手把手教你用hom_mat2d_rotate/translate实现图像任意旋转平移(附避坑指南)
从Halcon仿射变换到实战:手把手教你用hom_mat2d_rotate/translate实现图像任意旋转平移(附避坑指南) 在工业视觉检测和图像处理领域,仿射变换是实现精确定位、姿态校正的核心技术。Halcon作为行业标杆工具,提供了hom_m…...