PyTorch 源码学习:阅读经验 代码结构
分享自己在学习 PyTorch 源码时阅读过的资料。本文重点关注阅读 PyTorch 源码的经验和 PyTorch 的代码结构。因为 PyTorch 不同版本的源码实现有所不同,所以笔者在整理资料时尽可能按版本号升序,版本号见标题前[]。最新版本的源码实现还请查看 PyTorch 仓库。更多内容请参考:
- Ubuntu 22.04 LTS 源码编译安装 PyTorch
- pytorch/CONTRIBUTING.md 机翻
- PyTorch 源码学习
- PyTorch 源码学习:从 Tensor 到 Storage-CSDN博客
文章目录
- [1.0.1] Oldpan:Pytorch源码编译简明指南
- 核心文件夹
- third_party
- tools
- [1.7.1] 孙港丶丶:查看 Pytorch 源码
- [1.10.2] jhang的回答:如何阅读pytorch框架的源码?
- [2.0.0]吾乃阿尔法:一点 PyTorch 源码阅读心得
- [2.1.1]kiddyjinjin:pytorch 源码解读进阶版 - 总述
- [unknown] 小飞的回答:如何阅读pytorch框架的源码?
- [unknown] 小飞:PyTorch源码学习系列 - 1.初识
- 我理解的PyTorch架构
- PyTorch目录结构
- [unknown] clay001:pytorch源码阅读
- 待更新……
[1.0.1] Oldpan:Pytorch源码编译简明指南
具体内容见原文
以下是Pytorch源码包展开的目录结构(只展示了主要的一些文件夹),其中主要的源码都在以下展示的文件夹中:

其中使用红箭头标注的就是几个比较重要的核心库。下面简单介绍一下:
核心文件夹
核心文件夹主要是c10、aten、torch、caffe2.
为什么将c10放到最前面呢?
因为官方已经表明c10目录是最重要的源代码文件夹,也就是几乎所有的源代码都与这里的代码有关系,比如我们的类型定义,Pytorch最重要的Tensor的内存分配方式等等,都在这个文件夹中,官方也说到了,之后会慢慢将Aten中的代码移至这个文件夹,也就是说这个文件夹将包含Pytorch中最核心的代码。
而Aten文件夹则包含了一些实现了Tensor的底层(和c10类似),也包括了很多的层前向代码和后向实现的代码(例如卷积层的前向和后向操作代码),包括CPU和GPU端,总之都是C++的核心操作代码。
torch文件夹也同样重要,其中主要包含了一些稍微高层些的操作函数,例如torch.ones等,有C++和Python端,也包括了Python核心代码和包装代码,如果我们使用python版Pytorch的话,与这些代码接触就比较密切了。
而Caffe2则不用多说,caffe2则主要针对移动端设计了很多优化后的运算代码,模型融合、模型量化等等的代码,其后端有QNNPACK等一些针对移动端的底层运算库(有开发人员说GLOW也在caffe2后端考虑之内)。
third_party
Pytorch毕竟是大型的深度学习库,所以需要的依赖库也是有很多的,其中有很多我们耳熟能详的数值计算库(eigen、gemmlowp)、模型转换库(onnx、onnx-tensorrt)、并行训练库(gloo、nccl)、自家的底层端实现库(QNNPACK)以及绑定python端的pybind11等一系列所依赖的库。
当然还有很多库这里就不一一介绍了,总之,我们在编译的时候,Pytorch的编译代码会根据我们的设置在编译的时候,自动判断当前系统中是否存在需要的第三方库。如果不存在则使用这里的第三方库(直接编译并使用第三方库的diamante),这也是为什么我们需要执行git submodule update --init --recursive来下载所依赖第三库源码的原因。
tools
tools这个文件夹中的内容到底是做什么的,简单看一下官方的介绍:
This folder contains a number of scripts which are used as part of the PyTorch build process. This directory also doubles as a Python module hierarchy. 此文件夹包含许多用作PyTorch构建过程一部分的脚本。该目录还兼作Python模块层次结构。
其中包含了一些脚本生成代码工具(利用python)、用于编译一些组件的脚本和代码,还有一些开发人员需要的工具、以及AMD显卡帮助编译代码和一些特殊情况需要使用的工具等。在我们编译Pytorch源码的过程中会使用到这个文件夹中的代码。
有一点需要说明,那就是Pytorch利用了很多的代码生成,例如操作层函数的头文件NativeFunction.h等,所以tools中的代码生成脚本还是比较重要的。
提一个可能会使用到的脚本build_pytorch_libs.sh,这个脚本是用来编译libtorch库的,libtorch就是不需要python包装的使用C++的Pytorch库,方便于部署阶段使用。
关于tools中的文件就不具体介绍了,大家可以看一下其中的readme。
其他的文件夹就不多说了,相对上面的来说并不是很重要。
[1.7.1] 孙港丶丶:查看 Pytorch 源码
具体内容见原文

该图来自:PyTorch internals : ezyang’s blog
- “torch/” 中的代码文件一般是pytorch python类的接口信息,其内容可以直接在编辑器中通过查看定义得到,但其只包括了接口的参数信息和注释,注释与官方文档中收到的内容相同;
- “torch/csrc/” 中含有python和c++衔接的代码,很多为编译时生成;
- “aten/src/ATen/” 中包括了torch中许多操作的C++或C实现,是我们查看pytorch许多函数实现需要关注的区域;
- “c10/” 中为torch最基本特性实现的部分,如张量的定义、数据类型的定义等。
因此,为查看torch函数的具体实现,需要查看"aten/src/ATen/" 部分的内核代码。
其中"native/“为C++风格的实现,”/TH"等主要为C风格的实现,Edwards 说开发人员在努力将"/TH"等中的操作迁移到"native/"中,至少在我使用的pytorch1.7.1中,"native/"覆盖了大部分的张量操作,如卷积、激活和损失等等。
如何查看"aten/src/ATen/native"中的函数操作?
- 首先可以在"aten/src/ATen/native/native_functions.yaml"这个注册文件中查看函数的框架,可以确定这个函数是否在"native/"中实现,这里的框架主要是用于代码生成。
- 直接搜索大法,搜索文件夹中所有文件的内容,找到你想要的函数。\
[1.10.2] jhang的回答:如何阅读pytorch框架的源码?
具体内容见原文
要想阅读 pytorch 框架的源码,最起码得先了解框架的调用栈,以 pytorch v1.10.2的 torch.nn.conv2d 为例,介绍一下python api 接口到底层 c++ 接口的调用依赖关系:
Python API:
torch.nn.Conv2d:
---> class Conv2d, (torch/nn/modules/conv.py)
---> F.conv2d, (torch/nn/functional.py)
---> def conv2d(input: Tensor, ...) -> Tensor: ..., (torch/_C/_VariableFunctions.pyi)
C++ API:
---> at::Tensor conv2d(...), (aten/src/ATen/native/Convolution.cpp: 579)
---> at::convolution(...), (aten/src/ATen/native/Convolution.cpp: 586)
---> at::Tensor convolution(...), (aten/src/ATen/native/Convolution.cpp:743)
---> at::_convolution(...), (aten/src/ATen/native/Convolution.cpp:754)
---> at::Tensor _convolution(...), (aten/src/ATen/native/Convolution.cpp:769)
---> at::cudnn_convolution(...), (aten/src/ATen/native/Convolution.cpp:860)
---> Tensor cudnn_convolution(...), (aten/src/ATen/native/cudnn/ConvShared.cpp:265)
---> cudnn_convolution_forward(...), (aten/src/ATen/native/cudnn/ConvShared.cpp:273)
---> Tensor cudnn_convolution_forward(...), (aten/src/ATen/native/cudnn/ConvShared.cpp:221)
---> raw_cudnn_convolution_forward_out(...), (aten/src/ATen/native/cudnn/ConvShared.cpp:258)
---> void raw_cudnn_convolution_forward_out(...), (aten/src/ATen/native/cudnn/Conv_v7.cpp:669)
---> split_batch_dim_to_32bit_out(...,raw_cudnn_convolution_forward_out_32bit), (aten/src/ATen/native/cudnn/Conv_v7.cpp:673)
---> void raw_cudnn_convolution_forward_out_32bit(...), (aten/src/ATen/native/cudnn/Conv_v7.cpp:625)
---> cudnnConvolutionForward(...), (aten/src/ATen/native/cudnn/Conv_v7.cpp:658)
python 端接口比较容易查找,对于 c++ api 接口的查找给与一些建议:
- 常用 op c++ 接口都位于
aten/src/ATen/native目录,而且该目录下有个native_functions.yaml, 记录了c++接口的调用依赖关系 - kernel 名搜索:通常我们也会通过 nvprof 查看调用 kernel 名逆向查找 c++调用接口
- 关键字搜索:以conv2d为例, 我们也会去搜索 Tensor conv2d 关键字来查找,方便将 python 端的最后一个接口与 c++ 端的第一个接口对应起来;
- 先验知识搜索,还需要拥有一些cudnn api的先验知识,比如我知道conv2d一定会调用 cudnnConvolutionForward 等接口, 然后搜该接口所在位置,然后逆向搜索 c++ api 接口即可
- c++ 接口的搜索一般只需要找到离 cuda kernel 或 cudnn/cublas API 最近的位置即可(所以方法 2,4是我们最常用的手段),从 python 接口到 c++ 接口的中间依赖关系没必要深究,因为其中做了很多封装,经常依赖 vscode 跳转时会断了依赖关系;
- 推荐使用vscode开发工具做好配置,方便c++/python 接口的跳转,有助于理解调用过程
[2.0.0]吾乃阿尔法:一点 PyTorch 源码阅读心得
具体内容见原文
PyTorch 的代码对初学者来说并不好读,原因在于:
- 有很多 C++ 代码是在编译过程中生成的;
- PyTorch 前端充分利用了 Python 的动态特性,比如 Python 函数可能经过 N 个装饰器修饰;
- 混合 Python/C++ 调用,比如从 Python 调 C++ 调 Python 再调 C++ 在 PyTorch 中是比较常见的事情;
以下是我读 PyTorch 源代码的一些经验,仅供参考:
-
明确目标: PyTorch代码很多,建议每次只读一个专题或者从一个特定的问题出发,比如 PyTorch AMP 是怎么实现的;
-
把握全局: 一上来直接读代码会有很多障碍,很多术语不明所以,先通读这个专题下官方的教程、文档,以及一些写的好的第三方博客,确保自己对这个专题下的内容有初步的认知。以下是一些初步了解 PyTorch 特定专题内容的比较好的资源:
- PyTorch 教程
- PyTorch 文档
- PyTorch 博客
- PyTorch 案例
- PyTorch 论坛
- PyTorch Youtube 频道
-
Debug Build: 一定要 build debug 版的 PyTorch,并保留在编译过程中生成的源代码,否则很难找到 PyTorch 函数调用栈中一些函数的来源;
此处省略细节,具体内容见原文
-
静态读代码: 有了完整的 PyTorch 源代码之后就可以开始读了,网上有很多 VSCode 教程,设置好 VSCode 的 Python 和 C++ 插件,方便在函数之间跳转,可以解决一大部分的函数跳转;
-
动态读代码: 静态读代码的问题是常常搞不清函数的执行流程,此时在运行过程中动态读执行过的代码就很有帮助,善用 gdb 和 pdb 可以有效辅助读源代码。
此处省略细节,具体内容见原文
-
充分利用源代码中的日志、debug 选项、测试用例: 很多 PyTorch 模块都包含了丰富的日志和 debug 开关,这些日志和用于调试的消息可以帮助我们理解 PyTorch 的执行流程。除此之外,PyTorch 中包含了大量的测试用例,如果单纯看源代码无法理解程序的逻辑,看看其对应的测试用例可以帮助我们理解程序在做什么。
此处省略细节,具体内容见原文
-
及时求助: 如果经过上面的流程还无法了解某些代码的逻辑,要及时向社区求助,避免浪费过多时间。
-
学什么: 明确源代码中哪些东西值得我们学习和借鉴,读源代码时要特别注意这些方面,比如:
- 特定模块/功能的实现原理;
- 用到的算法;
- 一些 coding 技巧;
-
知行合一: You can’t understand it until you change it. 读源代码不是最终目的,充分利用从代码中获取的认知才是。有效的输出可以加深我们对代码的理解,一些可以参考的输出方式:
- 写一篇源码剖析的博客;
- 简化自己对源代码的认识,分享给其他人;
- 修改源代码,改进或添加一些功能,给 PyTorch 提交 PR;
- 亲手实现相同功能,写精简版的代码复现核心逻辑;
每一个读源代码的人都是不甘平凡的人,祝大家在这个“痛并快乐着”的过程中成长得更快、更多。
[2.1.1]kiddyjinjin:pytorch 源码解读进阶版 - 总述
具体内容见原文
pytorch官方给出的参考代码结构:pytorch/pytorch
源码解读的代码版本基于v2.1.1 版本:GitHub - pytorch/pytorch at v2.1.1
其中比较核心的4个目录简单介绍如下:
torch:python 代码部分, the frontend, 我们在代码中引入并使用的Python 模块(modules),基本都在这里torch/csrc: python bindings, 这部分C++代码实现了所谓的PyTorch前端(the frontend of PyTorch)。具体来说,这一部分主要桥接了Python逻辑的C++的实现,和一些PyTorch中非常重要的部分,比如自动微分引擎(autograd engine)和JIT编译器(JIT compiler)。aten/src/ATen: 是“A Tensor Library”的缩写,是一个C++库实现了Tensor的各种operations。ATen 内对operators的实现分成两类,一种是现代的C++实现版本(native),另一种是老旧的C实现版本(legacy)。c10: 是一个来自于Caffe2 和 ATen的双关语(Caffe 10),其中包含了PyTorch的核心抽象,比如 Tensor、Device、Allocator、Storage 等数据结构的实际实现部分。
进一步对c10/core 的代码结构进一步介绍如下:
Allocator.h/cpp: 提供memory管理的抽象类定义和实现。CPUAllocator.h/cpp: set/get CPU Allocator, 指定DefaultCPUAllocator。Device.h/cpp: 提供底层硬件的抽象类定义和实现。struct C10_API Device final表示张量所在的计算设备, 设备由类型唯一标识(cpu or cuda gpu, cuda 的话有index)
DeviceGuard.h: RAII guardDeviceType.h定义了21 种 DeviceType,包括我们常见的CPU,CUDA,XLA,HIP 等,应该会是逐渐增加的状态。DispatchKey.h定义了40+种 dispatcherkey set,是个 uint8_t,越高位优先级越高,用来给op路由,当调用一个op的时候,pytorch中的dispatch 机制会结合 DispatchKey 以及当时的场景(在什么硬件上?是推理还是训练?)分配到特定的执行算子上,这个机制保证了pytorch可以非常灵活的在不同的硬件和场景下切换。后面会详细讲讲,比较有意思。DispatchKeySet.hTensorOptions.h/cpp: 提供创建张量时的选项(如设备类型、数据类型等)的定义和相关操作。TensorImpl.h/cpp: 提供张量的具体实现。
其他:Backend.h(老旧版本的 Device.h/cpp, layout 信息),提供多种新旧互相转换接口
[unknown] 小飞的回答:如何阅读pytorch框架的源码?
具体内容见原文
分享下我个人学习经验
- 首先自己一定要编译源码,学会用GDB去调试代码。任何源码学习的第一步永远是将源码编译成功并运行起来。其次切记不要去看
setup.py文件,不要去看torch/__init__.py文件,不要去看C++编译配置文件。如果你没有丰富的相关工程开发经验,从你打开这些文件起,恭喜你,你已经被成功劝退了。初学者就应该老老实实先学习项目的设计思想和架构,忽略工程配置。 - 了解下Python语言如何与C/C++语言绑定。PyTorch底层核心代码都是用C/C++编写,如果你仅仅想学习的是Python部分的源码,那本回答就到此结束了,根据你python里的模块用到哪学到哪就行了。如果你想深入学习C/C++源码,这是一道必须迈过的坎。不理解的话你对PyTorch的认识永远是Python和C/C++两个孤零零的世界,无法联系起来。
- 先学习Tensor。Tensor是贯穿整个PyTorch最基本的数据结构,无论何时你都会遇到它。
- 了解算子。通过最简单的Tensor.Add 方法学习下Tensor函数是如何设计的。PyTorch里操作Tensor的函数被称之为算子,算子包含前向和后向计算。这里不要求完全弄懂算子,只需要了解相关流程就行。
- 学习Autograd。先了解计算图的概念,学习下PyTorch是如何创建和维护计算图。如何反向传播自动求解梯度更新权重。
学到这里你基本上对PyTorch C/C++底层架构有所了解,下面就是根据自己喜爱的方向去学习。
- 如果你想研究深度学习模型,去看Python torch.nn包里面的python源码就行。
- 如果你想研究算子实现,还记得我们前面学的Add方法了,找到你想了解的算子去深入,如果不关心速度,看下CPU代码就行,如果想学习如何优化就去了解cuda编程。
- 如果想学习分布式,就去研究下分布式相关的code。
其实从上面的流程看,只要你前5步都完成了,你自然而然就知道该如何去学习PyTorch框架源码。现在PyTorch源码很大,想在有限时间内一下子全看完不现实,必然要结合自己的实际情况有所侧重。
[unknown] 小飞:PyTorch源码学习系列 - 1.初识
具体内容见原文
PyTorch本身是一个Python扩展包,按照官方说法它主要具有以下两种特色:
- 支持GPU加速的张量(Tensor)计算
- 在一个类似磁带(前向和反向)的梯度自动计算(Autograd)系统上搭建深度神经网络
Tensor其实本质上就是一个多维数组。在数学上单个数据我们称之为标量,一维数据我们称之为向量,二维数据我们称之为矩阵。
如果PyTorch仅是支持GPU加速的Tensor计算框架,那它也就是NumPy的替代品而已。其最核心的功能就是Autograd系统,目前深度学习就是基于梯度反向传播理论来达到网络的自我训练。PyTorch的Autograd系统是创建了一个动态的计算图,用户只需要关注前向计算网络搭建,PyTorch会自动根据动态计算图去反向计算梯度并更新网络权重。
在设计之初PyTorch并没打算仅成为一个绑定C++框架的Python包,它紧密地将C++框架集成到python中。你可以在使用PyTorch的同时也结合使用NumPy/SciPy/scikit-learn这些优秀的科学计算包,同时你也可以用Python编写你自己的神经网络层(PyTorch神经网络相关的代码基本上都是Python编写)。
正如前面所说,PyTorch的计算图是动态的,当你写下一行Python代码的时候你就可以直接运行得到结果。对用户来说,PyTorch的世界就是一个简单的单线程同步非阻塞世界,你可以得到实时反馈,这对于刚开始接触深度学习的新手来说是非常贴心的功能,可以帮忙新手快速入门。
我理解的PyTorch架构
根据自己的理解简单画了下PyTorch的架构图,隐藏了部分细节。本系列也将主要围绕着这张架构图去学习PyTorch的具体实现。

一共将PyTorch分成了四层,分别是
- 应用层(Python)。这应该是大家最熟悉的层,主要涉及到张量,Autograd以及神经网络。该层所有的源码都是由Python编写,这也符合前面所说的PyTorch设计思想-——将C++框架集成到Python里
- 实现接口层(C++)。该层的主要功能我认为有两个:
- Python 扩展。通过Python提供的C API将Python应用层与C++实现层绑定起来,使用户在享受Python语言提供的便捷优势时也可以同时享受到C++语言提供的性能优势
- Autograd系统实现。 PyTorch并没有在实现层中实现Autograd系统。在此层中PyTorch定义了动态有向图的基本组件Node和Edge,以及在此基础上封装了Function类和Engine类来实现Autograd
- 实现层(C++)。该层是PyTorch的核心层,定义了PyTorch运行过程中的核心库,包括Tensor的具体实现,算子实现(前向与后向运算)以及动态调度系统(Tensor的布局,硬件设备,数据类型)。Storage类主要是针对不同硬件数据存储的一种抽象。
- 硬件接口层。该层主要是硬件厂商基于自家硬件推出的运算接口。
PyTorch目录结构
PyTorch的源码托管于GitHub平台,其目前的代码量已经非常巨大。新手第一次接触的时候往往会因此被劝退,但其实里面很多文件和我们学习PyTorch源码并没有太多的直接关系,所以我们第一步就是要理清目录结构,专注于我们需要学习的内容。
torch:我们“import torch”后最熟悉的PyTorch库。所有非csrc文件夹下的内容都是标准的Python模块,对应我们架构图中的应用层csrc:该目录下都是C++源码,Python绑定C++的相关code都在这个目录里面,同时也包含了对PyTorch核心库的一些封装,对应我们架构图中的实现接口层csrc/autograd:梯度自动计算系统的C++实现autograd:梯度自动计算系统的Python前端源码,包含torch中支持的所有自动求导算子nn:建立在autograd系统上的神经网络库,包含了深度学习中常用的一些基础神经网络层。optim:机器学习中用到的优化算法库
aten:“a tensor library”的缩写,对应我们结构图中的实现层。从名字上也能知道,这个库设计之初主要是为Tensor服务。因为在实现接口层下面,所以这里的Tensor并不支持autogradsrc/Aten/core:aten的核心基础库。目前这个库里面的代码正在逐渐地迁移到c10目录下面src/Aten/native:PyTorch的算子库,这个目录下面的算子都是CPU的算子。对于一些专门CPU指令优化的算子会在子目录里面src/Aten/native/cuda:cuda算子实现
c10:“caffe2 aten”的缩写,PyTorch的核心库,支持服务端和移动端。tools:PyTorch中很多相似源码都是脚本通过模板自动生成的,这个文件夹下面就放着自动生成代码的脚本
[unknown] clay001:pytorch源码阅读
具体内容见原文
pytorch代码主要由C10(Caffe Tensor Library,最基础的Tenor库代码),ATen(A Tensor library for C++11,基于C10),torch三大部分组成。
torch.nn中包含各种神经网络层,激活函数,损失函数的类,使用时需要先创建对象。
torch.nn.functional中的接口可以直接调用函数而不用创建对象。
算子配置文件:pytorch/aten/src/Aten/native/native_functions.yaml中有关于各个算子的说明,同级目录下有这些算子的实现。每个算子有一些字段:func,variants,dispatch。

func字段:表示算子的名称和输入输出类型variants字段:表示高级方法的使用方式,function表示可以用torch.xxx()的方式调用,method表示在tensor a上,用a.xxx()的方式调用
dispatch字段:分发的设备类型,CPU,CUDA等等
![[图片]](https://i-blog.csdnimg.cn/direct/ae1289f7d980477c81c4ad6662541b9e.png)
算子通常成对出现(正向和反向)。
python_module: nn表示将该方法自动生成到torch.nn.functional模块中,可以通过torch.nn.functional.leaky_relu的方式来调用。
反向算子配置文件:在tools/autograd/derivatives.yaml中添加算子和反向算子的对应关系。
![[图片]](https://i-blog.csdnimg.cn/direct/798e9dd6e97e460d84eebe74912298f5.png)
算子表层实现文件:aten/src/Aten/native/目录下的h和cpp文件。有些会按照功能实现在一起,比如Activation.cpp中包含了多个算子。在这些cpp实现中,用到了封装后的函数,会再往里调一层。
算子底层实现文件:aten/src/ATen/native/cpu/目录下,通常以xxx_kernel.cpp的形式存在。
待更新……
相关文章:
PyTorch 源码学习:阅读经验 代码结构
分享自己在学习 PyTorch 源码时阅读过的资料。本文重点关注阅读 PyTorch 源码的经验和 PyTorch 的代码结构。因为 PyTorch 不同版本的源码实现有所不同,所以笔者在整理资料时尽可能按版本号升序,版本号见标题前[]。最新版本的源码实现还请查看 PyTorch 仓…...

vite+vue3开发低版本浏览器不支持es6语法的问题排坑笔记
重要提示:请首先完整阅读完文章内容后再操作,以免不必要的时间浪费!切记!!!在使用vitevue3开发unapp项目时,发现低版本浏览器不兼容es6的语法,如“?.” “??” 等,为了…...
函数,格式输出符)
C语言中printf()函数,格式输出符
在 C 语言中,printf() 函数的格式输出符(格式说明符)用于控制输出的格式和数据类型。以下是常见的格式说明符及其用法: 基本格式符 打印各种类型的值 格式输出符数据类型说明%dint输出有符号十进制整数%uunsigned int输出无符号…...

AI 编程工具—Cursor 进阶篇 数据分析
AI 编程工具—Cursor 进阶篇 数据分析 上一节课我们使用Cursor 生成了北京房产的销售数据,这一节我们使用Cursor对这些数据进行分析,也是我们尝试使用Cursor 去帮我们做数据分析,从而进一步发挥Cursor的能力,来帮助我们完成更多的事情 案例一 房产销售数据分析 @北京202…...

青少年编程与数学 02-009 Django 5 Web 编程 20课题、测试
青少年编程与数学 02-009 Django 5 Web 编程 20课题、测试 一、软件测试二、自动化测试三、单元测试四、Django 单元测试(一)、创建测试用例(二)、运行测试(三)、常用测试功能 课题摘要: 本文全面介绍了软件…...

zookeeper watch
目录 回顾回调&观察者模式&发布订阅模式Zookeeper 客户端/ 服务端 watchgetChildren 为例最后归纳 回顾回调&观察者模式&发布订阅模式 回调的思想 类A的a()方法调用类B的b()方法类B的b()方法执行完毕主动调用类A的callback()方法 回调分为同步回调和异步回调…...

vue3.x 的shallowReactive 与 shallowRef 详细解读
在 Vue 3.x 中,shallowReactive 和 shallowRef 是两个用于创建浅层响应式数据的 API。它们与 reactive 和 ref 类似,但在处理嵌套对象时的行为有所不同。以下是它们的详细解读和示例。 1. shallowReactive 作用 shallowReactive 创建一个浅层响应式对…...
)
鸿蒙NEXT开发-界面渲染(条件和循环)
注意:博主有个鸿蒙专栏,里面从上到下有关于鸿蒙next的教学文档,大家感兴趣可以学习下 如果大家觉得博主文章写的好的话,可以点下关注,博主会一直更新鸿蒙next相关知识 目录 1. 渲染-条件渲染 1.1 基本介绍 1.2 使…...

python电影数据分析及可视化系统建设
博主介绍:✌程序猿徐师兄、8年大厂程序员经历。全网粉丝15w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

在本地校验密码或弱口令 (windows)
# 0x00 背景 需求是验证服务器的弱口令,如果通过网络侧校验可能会造成账户锁定风险。在本地校验不会有锁定风险或频率限制。 # 0x01 实践 ## 1 使用 net use 命令 可以通过命令行使用 net use 命令来验证本地账户的密码。打开命令提示符(CMD࿰…...

pytest测试专题 - 1.3 测试用例发现规则
<< 返回目录 1 pytest测试专题 - 1.3 测试用例发现规则 执行pytest命令时,可以不输入参数,或者只输入文件名或者目录名,pytest会自己扫描测试用例。那pytest基于什么规则找到用例呢? 文件名:满足文件名称为tes…...

零基础学习人工智能
零基础学习人工智能是一个既充满挑战又极具潜力的过程。以下是一份详细的学习指南,旨在帮助零基础的学习者有效地踏入人工智能领域。 一、理解基本概念 在学习人工智能之前,首先要对其基本概念有一个清晰的认识。人工智能(AI)是…...
LeetCode热题100- 缺失的第一个正数【JavaScript讲解】
题目: 解题一: 如果不考虑时间复杂度和空间复杂度的话,我们最先想到的办法是先将该数组进行排序和去重,将最初的res结果值设置为1;将然后进行遍历,如果第一项不为1,则返回1,否则根…...

JAVA泛型介绍与举例
Java中,泛型用于编译阶段限制集合中元素的类型,或者限制类中某个属性的类型,编译过程中发生类型擦除,最终还是Object类型。 1. 集合中的泛型 集合默认可以存储任何类型的元素,即Object类型,当使用一个集合…...
测试用例CAPL代码全解析③】)
【ISO 14229-1:2023 UDS诊断(会话控制0x10服务)测试用例CAPL代码全解析③】
ISO 14229-1:2023 UDS诊断【会话控制0x10服务】_TestCase03 作者:车端域控测试工程师 更新日期:2025年02月15日 关键词:UDS诊断、0x10服务、诊断会话控制、ECU测试、ISO 14229-1:2023 TC10-003测试用例 用例ID测试场景验证要点参考条款预期…...

Vivado生成edif网表及其使用
介绍如何在Vivado中将模块设为顶层,并生成相应的网表文件(Verilog文件和edif文件),该过程适用于需要将一个模块作为顶层设计进行综合,并生成用于其他工程中的网表文件的情况。 例如要将fpga_top模块制作成网表给其它工…...

Win10环境借助DockerDesktop部署大数据时序数据库Apache Druid
Win10环境借助DockerDesktop部署最新版大数据时序数据库Apache Druid32.0.0 前言 大数据分析中,有一种常见的场景,那就是时序数据,简言之,数据一旦产生绝对不会修改,随着时间流逝,每个时间点都会有个新的…...

mac 意外退出移动硬盘后再次插入移动硬盘不显示怎么办
第一步:sudo ps aux | grep fsck 打开mac控制台输入如下指令,我们看到会出现两个进程,看进程是root的这个 sudo ps aux|grep fsck 第二步:杀死进程 在第一步基础上我们知道不显示u盘的进程是:62319,我们…...

力扣动态规划-32【算法学习day.126】
前言 ###我做这类文章一个重要的目的还是记录自己的学习过程,我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非常非常高滴!!! 习题 1.完全平方数 题目链接:279. 完全…...
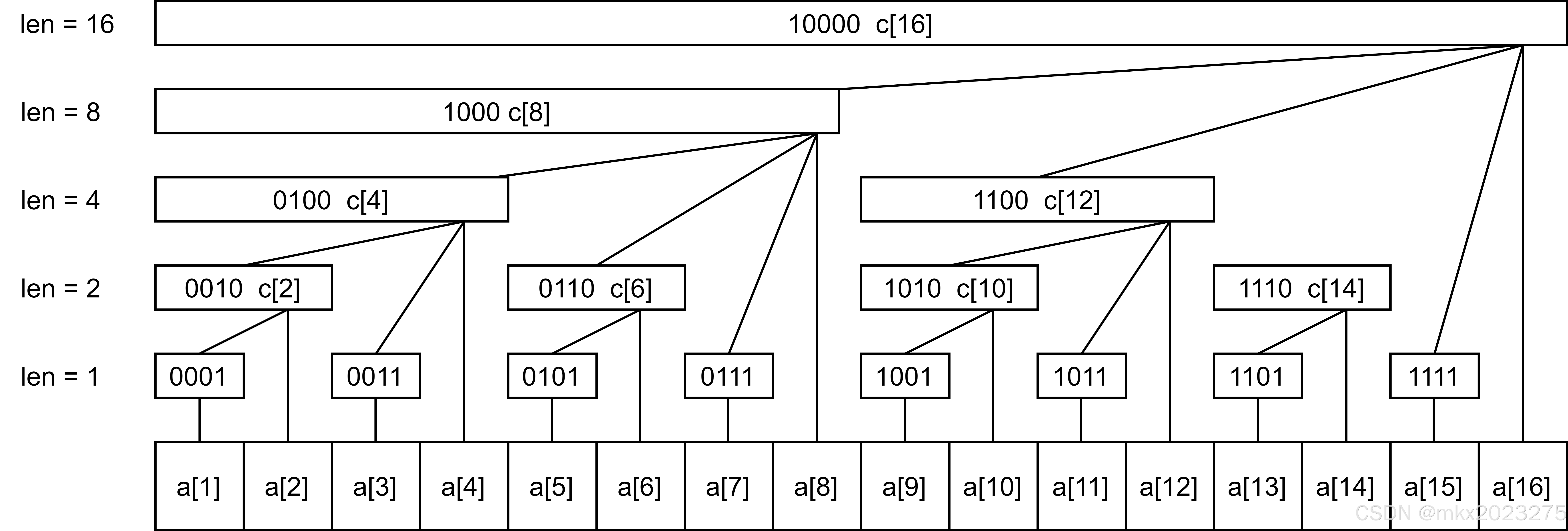
【算法进阶详解 第一节】树状数组
【算法进阶详解 第一节】树状数组 前言树状数组基础树状数组原理树状数组能够解决的问题 树状数组提高树状数组区间加,区间和操作二维树状数组 树状数组应用树状数组区间数颜色树状数组二维偏序 前言 树状数组在算法竞赛中十分常见,其能解决二维数点&am…...
)
保姆级教程:用Qt和QSsh库在Windows上打造你的第一个SSH客户端(附完整源码)
从零构建Qt SSH客户端:QSsh库编译与实战开发指南 对于需要远程管理Linux服务器的开发者而言,图形化SSH工具能显著提升工作效率。本文将手把手带你用Qt和QSsh库打造一个功能完整的SSH客户端,涵盖从环境搭建到功能实现的完整链路。不同于市面上…...

体验 Taotoken 低延迟 API 调用为实时对话应用带来的流畅体感
体验 Taotoken 低延迟 API 调用为实时对话应用带来的流畅体感 1. 实时对话应用的技术挑战 在开发需要快速响应的聊天应用时,API 调用的延迟表现直接影响用户体验。传统方案中,开发者需要自行维护多个模型供应商的连接,处理不同接口的兼容性…...

novel-downloader:终极小说下载指南,永久保存你的阅读时光
novel-downloader:终极小说下载指南,永久保存你的阅读时光 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 你是否曾为心爱的小说突然消失而心痛?是…...

在自动化测试流程中集成多模型API调用以提升测试覆盖率
在自动化测试流程中集成多模型API调用以提升测试覆盖率 1. 自动化测试中多模型调用的必要性 现代软件产品与AI能力的结合日益紧密,但不同模型厂商的API行为可能存在细微差异。单一模型测试无法覆盖所有可能的交互场景,这为产品质量埋下隐患。通过Taoto…...
高阶通关实战)
重塑白板战役:2026大厂AI系统设计(System Design)高阶通关实战
当面试官递给你白板笔,传统的考核逻辑在2026年已经彻底翻篇。过去几年,准备海外或亚太区高阶研发面试的候选人,往往习惯于背诵“如何设计一个推特”或“如何构建一个调度系统”的经典范式。然而现在的考场上,题目早已迭代为“设计…...

【AISMM工业级部署手册】:含17个可即插即用的制造场景评估矩阵与合规性检查清单
更多请点击: https://intelliparadigm.com 第一章:AISMM模型在制造业落地的总体架构与核心价值 AISMM(Artificial Intelligence Supported Manufacturing Model)是一套面向离散制造场景的轻量化AI工程化框架,其核心设…...

观察 Taotoken 用量看板如何帮助团队进行资源消耗分析
观察 Taotoken 用量看板如何帮助团队进行资源消耗分析 1. 用量看板的核心功能 Taotoken 控制台的用量看板为团队管理员和项目负责人提供了多维度的资源消耗数据可视化。该功能默认展示最近30天的调用情况,支持按日、周、月粒度切换视图。主要数据维度包括总消耗 t…...

国产GPU开发者的必修课:手把手带你理解Mesa在Linux图形栈中的核心作用
国产GPU开发者的必修课:手把手带你理解Mesa在Linux图形栈中的核心作用 在国产化技术浪潮席卷而来的今天,图形处理器(GPU)作为计算生态的关键一环,其自主可控的重要性不言而喻。而Mesa作为开源图形驱动的事实标准&#…...

终极指南:3步快速破解极域电子教室限制的完整方案
终极指南:3步快速破解极域电子教室限制的完整方案 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer JiYuTrainer是一款专为对抗极域电子教室控制而设计的开源软件&#…...

收藏!AI时代,如何守住饭碗?这7个习惯助你强化思考力,小白程序员必看!
随着AI技术的快速发展,各行各业都在经历变革。文章指出,AI将抢走许多基础性工作,但无法替代人的思考力。作者从《高效能人士的七个习惯》出发,提出了七个强化思考力的习惯,包括积极主动、以终为始、要事第一、双赢思维…...