【Spring详解三】默认标签的解析
三、默认标签的解析

# DefaultBeanDefinitionDocumentReader
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {importBeanDefinitionResource(ele);}else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {processAliasRegistration(ele);}else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {processBeanDefinition(ele, delegate);}else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {// recursedoRegisterBeanDefinitions(ele);}
}3.1 Bean标签的解析及注册
# DefaultBeanDefinitionDocumentReader
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);if (bdHolder != null) {bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);try {// Register the final decorated instance.BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());}catch (BeanDefinitionStoreException ex) {getReaderContext().error("Failed to register bean definition with name '" +bdHolder.getBeanName() + "'", ele, ex);}// Send registration event.getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));}
}刚开始看这个函数体时一头雾水,没有以前的函数那样的清晰的逻辑,我们细致的理下逻辑,大致流程如下:
- 首先委托BeanDefinitionParserDelegate类的parseBeanDefinitionElement方法进行元素的解析,返回BeanDefinitionHolder类型的实例bdHolder,经过这个方法后bdHolder实例已经包含了我们配置文件中的各种属性了,例如class,name,id,alias等。
- 当返回的bdHolder不为空的情况下若存在默认标签的子节点下再有自定义属性,还需要再次对自定义标签进行解析。
- 当解析完成后,需要对解析后的bdHolder进行注册,注册过程委托给了BeanDefinitionReaderUtils的registerBeanDefinition方法。
- 最后发出响应事件,通知相关的监听器已经加载完这个Bean了。

3.1.1 解析BeanDefinition

# BeanDefinitionParserDelegate
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {// 解析 ID 属性String id = ele.getAttribute(ID_ATTRIBUTE);// 解析 name 属性String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);// 分割 name 属性List<String> aliases = new ArrayList<>();if (StringUtils.hasLength(nameAttr)) {String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);aliases.addAll(Arrays.asList(nameArr));}String beanName = id;if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {beanName = aliases.remove(0);if (logger.isDebugEnabled()) {......}}// 检查 name 的唯一性if (containingBean == null) {checkNameUniqueness(beanName, aliases, ele);}// 解析 属性,构造 AbstractBeanDefinitionAbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);if (beanDefinition != null) {// 如果 beanName 不存在,则根据Spring中提供的命名规则生成对应的beanNameif (!StringUtils.hasText(beanName)) {try {if (containingBean != null) {beanName = BeanDefinitionReaderUtils.generateBeanName(beanDefinition, this.readerContext.getRegistry(), true);}else {beanName = this.readerContext.generateBeanName(beanDefinition);String beanClassName = beanDefinition.getBeanClassName();if (beanClassName != null &&beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {aliases.add(beanClassName);}}if (logger.isDebugEnabled()) {......}}catch (Exception ex) {......}}String[] aliasesArray = StringUtils.toStringArray(aliases);// 封装 BeanDefinitionHolderreturn new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);}return null;
}- 提取元素中的id和name属性
- 进一步解析其他所有属性并统一封装到GenericBeanDefinition类型的实例中
- 如果检测到bean没有指定beanName,那么使用默认规则为此bean生成beanName。
- 将获取到的信息封装到BeanDefinitionHolder的实例中。
# BeanDefinitionParserDelegate
public AbstractBeanDefinition parseBeanDefinitionElement(Element ele, String beanName, @Nullable BeanDefinition containingBean) {this.parseState.push(new BeanEntry(beanName));String className = null;//解析class属性if (ele.hasAttribute(CLASS_ATTRIBUTE)) {className = ele.getAttribute(CLASS_ATTRIBUTE).trim();}String parent = null;//解析parent属性if (ele.hasAttribute(PARENT_ATTRIBUTE)) {parent = ele.getAttribute(PARENT_ATTRIBUTE);}try {//创建用于承载属性的AbstractBeanDefinition类型的GenericBeanDefinition实例AbstractBeanDefinition bd = createBeanDefinition(className, parent);//硬编码解析bean的各种属性parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);//设置description属性bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));//解析元素parseMetaElements(ele, bd);//解析lookup-method属性parseLookupOverrideSubElements(ele, bd.getMethodOverrides());//解析replace-method属性parseReplacedMethodSubElements(ele, bd.getMethodOverrides());//解析构造函数的参数parseConstructorArgElements(ele, bd);//解析properties子元素parsePropertyElements(ele, bd);//解析qualifier子元素parseQualifierElements(ele, bd);bd.setResource(this.readerContext.getResource());bd.setSource(extractSource(ele));return bd;}catch (ClassNotFoundException ex) {error("Bean class [" + className + "] not found", ele, ex);}catch (NoClassDefFoundError err) {error("Class that bean class [" + className + "] depends on not found", ele, err);}catch (Throwable ex) {error("Unexpected failure during bean definition parsing", ele, ex);}finally {this.parseState.pop();}return null;
}3.1.1.1 创建用于承载属性的BeanDefinition


# BeanDefinitionParserDelegate
protected AbstractBeanDefinition createBeanDefinition(@Nullable String className, @Nullable String parentName)throws ClassNotFoundException {return BeanDefinitionReaderUtils.createBeanDefinition(parentName, className, this.readerContext.getBeanClassLoader());
}# BeanDefinitionReaderUtils
public static AbstractBeanDefinition createBeanDefinition(@Nullable String parentName, @Nullable String className, @Nullable ClassLoader classLoader) throws ClassNotFoundException {GenericBeanDefinition bd = new GenericBeanDefinition();bd.setParentName(parentName);if (className != null) {if (classLoader != null) {bd.setBeanClass(ClassUtils.forName(className, classLoader));}else {bd.setBeanClassName(className);}}return bd;
}3.1.1.2 解析各种属性

# BeanDefinitionParserDelegate
public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName,@Nullable BeanDefinition containingBean, AbstractBeanDefinition bd) {//解析singleton属性if (ele.hasAttribute(SINGLETON_ATTRIBUTE)) {error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);}//解析scope属性else if (ele.hasAttribute(SCOPE_ATTRIBUTE)) {bd.setScope(ele.getAttribute(SCOPE_ATTRIBUTE));}else if (containingBean != null) {// Take default from containing bean in case of an inner bean definition.bd.setScope(containingBean.getScope());}//解析abstract属性if (ele.hasAttribute(ABSTRACT_ATTRIBUTE)) {
bd.setAbstract(TRUE_VALUE.equals(ele.getAttribute(ABSTRACT_ATTRIBUTE)));}//解析lazy_init属性String lazyInit = ele.getAttribute(LAZY_INIT_ATTRIBUTE);if (DEFAULT_VALUE.equals(lazyInit)) {lazyInit = this.defaults.getLazyInit();}bd.setLazyInit(TRUE_VALUE.equals(lazyInit));//解析autowire属性String autowire = ele.getAttribute(AUTOWIRE_ATTRIBUTE);bd.setAutowireMode(getAutowireMode(autowire));//解析dependsOn属性if (ele.hasAttribute(DEPENDS_ON_ATTRIBUTE)) {String dependsOn = ele.getAttribute(DEPENDS_ON_ATTRIBUTE);bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, MULTI_VALUE_ATTRIBUTE_DELIMITERS));}//解析autowireCandidate属性String autowireCandidate = ele.getAttribute(AUTOWIRE_CANDIDATE_ATTRIBUTE);if ("".equals(autowireCandidate) || DEFAULT_VALUE.equals(autowireCandidate)) {String candidatePattern = this.defaults.getAutowireCandidates();if (candidatePattern != null) {String[] patterns = StringUtils.commaDelimitedListToStringArray(candidatePattern);bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));}}else {bd.setAutowireCandidate(TRUE_VALUE.equals(autowireCandidate));}//解析primary属性if (ele.hasAttribute(PRIMARY_ATTRIBUTE)) {bd.setPrimary(TRUE_VALUE.equals(ele.getAttribute(PRIMARY_ATTRIBUTE)));}//解析init_method属性if (ele.hasAttribute(INIT_METHOD_ATTRIBUTE)) {String initMethodName = ele.getAttribute(INIT_METHOD_ATTRIBUTE);bd.setInitMethodName(initMethodName);}else if (this.defaults.getInitMethod() != null) {bd.setInitMethodName(this.defaults.getInitMethod());bd.setEnforceInitMethod(false);}//解析destroy_method属性if (ele.hasAttribute(DESTROY_METHOD_ATTRIBUTE)) {String destroyMethodName = ele.getAttribute(DESTROY_METHOD_ATTRIBUTE);bd.setDestroyMethodName(destroyMethodName);}else if (this.defaults.getDestroyMethod() != null) {bd.setDestroyMethodName(this.defaults.getDestroyMethod());bd.setEnforceDestroyMethod(false);}//解析factory_method属性if (ele.hasAttribute(FACTORY_METHOD_ATTRIBUTE)) {bd.setFactoryMethodName(ele.getAttribute(FACTORY_METHOD_ATTRIBUTE));}//解析factory_bean属性if (ele.hasAttribute(FACTORY_BEAN_ATTRIBUTE)) {bd.setFactoryBeanName(ele.getAttribute(FACTORY_BEAN_ATTRIBUTE));}return bd;
}3.1.1.3 解析子元素meta

<bean id="demo" class="com.yhl.myspring.demo.bean.MyBeanDemo"><property name="beanName" value="bean demo1"/><meta key="demo" value="demo"/>
</bean># BeanDefinitionParserDelegate
public void parseMetaElements(Element ele, BeanMetadataAttributeAccessor attributeAccessor) {// 获取当前节点的所有元素NodeList nl = ele.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);// 提取metaif (isCandidateElement(node) && nodeNameEquals(node, META_ELEMENT)) {Element metaElement = (Element) node;String key = metaElement.getAttribute(KEY_ATTRIBUTE);String value = metaElement.getAttribute(VALUE_ATTRIBUTE);// 使用key、value构造BeanMetadataAttributeBeanMetadataAttribute attribute = new BeanMetadataAttribute(key, value);// 记录信息attribute.setSource(extractSource(metaElement));attributeAccessor.addMetadataAttribute(attribute);}}
}3.1.1.4 解析子元素lookup-method

//testLookUp.xml
<bean id="getBeanTest" class="com.xxx.lookupmethod.GetBeanTest"> <lookup-method bean="Kobe" name="getPlayer"/> </bean>
<bean id="Kobe" class="com.xxx.lookupmethod.Kobe"></bean>//测试类
class Player {public void who () {System.out.println("I am player");}
}
class Kobe {public void who () {System.out.println("I am kobe");}
}
public abstract class GetBeanTest {public void who () {this.getPlayer().who();}public abstract Player getPlayer ();
}class TestMain {public static void main(String[] args) {ApplicationContext applicationContext = new ClassPathXmlApplicationContext("testLookUp.xml");GetBeanTest getBeanTest = applicationContext.getBean("getBeanTest", GetBeanTest.class);getBeanTest.who();}
}子元素lookup-method似乎并不是很常用,但是在某些时候它的确是非常有用的,通常称它为获取器注入,引用《Spring in Action》中的一句话:获取器注入是一种特殊的方法注入,它是一个方法声明为返回某种类型的bean,但是实际要返回的bean是在配置文件里面配置的,此方法在涉及有些可插拔的功能上,解除程序依赖。parseLookupOverrideSubElements(ele, bd.getMethodOverrides()); 代码如下:
# BeanDefinitionParserDelegate
public void parseLookupOverrideSubElements(Element beanEle, MethodOverrides overrides) {NodeList nl = beanEle.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (isCandidateElement(node) && nodeNameEquals(node, LOOKUP_METHOD_ELEMENT)) {Element ele = (Element) node;String methodName = ele.getAttribute(NAME_ATTRIBUTE);String beanRef = ele.getAttribute(BEAN_ELEMENT);LookupOverride override = new LookupOverride(methodName, beanRef);override.setSource(extractSource(ele));overrides.addOverride(override);}}
}3.1.1.5 解析子元素replaced-method

方法替换:可以在运行时用新的方法替换现有的方法,与之前look-up不同的是,replace-method不但可以动态的替换返回实体bean,而且还能动态的更改原有方法的逻辑,我们看下使用:
//原有的changeMe方法
public class TestChangeMethod {public void changeMe(){System.out.println("ChangeMe");}
}
//新的实现方法
public class ReplacerChangeMethod implements MethodReplacer {@Overridepublic Object reimplement(Object o, Method method, Object[] objects) throws Throwable {System.out.println("I Replace Method");return null;}
}
//新的配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsd"><bean id="changeMe" class="com.wangjiafu.spring.TestChangeMethod"><replaced-method name="changeMe" replacer="replacer"/></bean><bean id="replacer" class="com.wangjiafu.spring.ReplacerChangeMethod"></bean>
</beans>
//测试方法
public class TestDemo {public static void main(String[] args) {ApplicationContext context = new ClassPathXmlApplicationContext("replaced-method.xml");TestChangeMethod test =(TestChangeMethod) context.getBean("changeMe");test.changeMe();}
}接下来我们看下解析replaced-method的方法代码:
# BeanDefinitionParserDelegate
public void parseReplacedMethodSubElements(Element beanEle, MethodOverrides overrides) {NodeList nl = beanEle.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (isCandidateElement(node) && nodeNameEquals(node, REPLACED_METHOD_ELEMENT)) {Element replacedMethodEle = (Element) node;String name = replacedMethodEle.getAttribute(NAME_ATTRIBUTE);String callback = replacedMethodEle.getAttribute(REPLACER_ATTRIBUTE);ReplaceOverride replaceOverride = new ReplaceOverride(name, callback);// Look for arg-type match elements.List<Element> argTypeEles = DomUtils.getChildElementsByTagName(replacedMethodEle, ARG_TYPE_ELEMENT);for (Element argTypeEle : argTypeEles) {String match = argTypeEle.getAttribute(ARG_TYPE_MATCH_ATTRIBUTE);match = (StringUtils.hasText(match) ? match : DomUtils.getTextValue(argTypeEle));if (StringUtils.hasText(match)) {replaceOverride.addTypeIdentifier(match);}}replaceOverride.setSource(extractSource(replacedMethodEle));overrides.addOverride(replaceOverride);}}
}我们可以看到无论是 lookup-method 还是 replaced-method 都是构造了 MethodOverride(ReplaceOverride为其实现类) ,并最终记录在了 AbstractBeanDefinition 中的 methodOverrides 属性中。
3.1.1.6 解析子元素constructor-arg

# BeanDefinitionParserDelegate
public void parseConstructorArgElement(Element ele, BeanDefinition bd) {//提前index属性String indexAttr = ele.getAttribute(INDEX_ATTRIBUTE);//提前type属性String typeAttr = ele.getAttribute(TYPE_ATTRIBUTE);//提取name属性String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);if (StringUtils.hasLength(indexAttr)) {try {int index = Integer.parseInt(indexAttr);if (index < 0) {error("'index' cannot be lower than 0", ele);}else {try {this.parseState.push(new ConstructorArgumentEntry(index));//解析ele对应的元素属性Object value = parsePropertyValue(ele, bd, null);ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);if (StringUtils.hasLength(typeAttr)) {valueHolder.setType(typeAttr);}if (StringUtils.hasLength(nameAttr)) {valueHolder.setName(nameAttr);}valueHolder.setSource(extractSource(ele));if (bd.getConstructorArgumentValues().hasIndexedArgumentValue(index)) {error("Ambiguous constructor-arg entries for index " + index, ele);}else {bd.getConstructorArgumentValues().addIndexedArgumentValue(index, valueHolder);}}finally {this.parseState.pop();}}}catch (NumberFormatException ex) {error("Attribute 'index' of tag 'constructor-arg' must be an integer", ele);}}else {try {this.parseState.push(new ConstructorArgumentEntry());Object value = parsePropertyValue(ele, bd, null);ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);if (StringUtils.hasLength(typeAttr)) {valueHolder.setType(typeAttr);}if (StringUtils.hasLength(nameAttr)) {valueHolder.setName(nameAttr);}valueHolder.setSource(extractSource(ele));bd.getConstructorArgumentValues().addGenericArgumentValue(valueHolder);}finally {this.parseState.pop();}}
}- 首先提取index、type、name等属性
- 根据是否配置了index属性解析流程不同
- 如果配置了index属性,解析流程如下:
- 使用parsePropertyValue(ele, bd, null)方法读取constructor-arg的子元素。
- 使用ConstructorArgumentValues.ValueHolder封装解析出来的元素。
- 将index、type、name属性也封装进ValueHolder中,然后将ValueHoder添加到当前beanDefinition的ConstructorArgumentValues的indexedArgumentValues,而indexedArgumentValues是一个map类型。
- 如果没有配置index属性,将index、type、name属性也封装进ValueHolder中,然后将ValueHoder添加到当前beanDefinition的ConstructorArgumentValues的genericArgumentValues中。
- 如果配置了index属性,解析流程如下:
# BeanDefinitionParserDelegate
public Object parsePropertyValue(Element ele, BeanDefinition bd, @Nullable String propertyName) {String elementName = (propertyName != null) ?"<property> element for property '" + propertyName + "'" :"<constructor-arg> element";// Should only have one child element: ref, value, list, etc.NodeList nl = ele.getChildNodes();Element subElement = null;for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);//略过description和meta属性if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT) &&!nodeNameEquals(node, META_ELEMENT)) {// Child element is what we're looking for.if (subElement != null) {error(elementName + " must not contain more than one sub-element", ele);}else {subElement = (Element) node;}}}//解析ref属性boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE);//解析value属性boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE);if ((hasRefAttribute && hasValueAttribute) ||((hasRefAttribute || hasValueAttribute) && subElement != null)) {error(elementName +" is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele);}if (hasRefAttribute) {String refName = ele.getAttribute(REF_ATTRIBUTE);if (!StringUtils.hasText(refName)) {error(elementName + " contains empty 'ref' attribute", ele);}//使用RuntimeBeanReference来封装ref对应的beanRuntimeBeanReference ref = new RuntimeBeanReference(refName);ref.setSource(extractSource(ele));return ref;}else if (hasValueAttribute) {//使用TypedStringValue 来封装value属性TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE));valueHolder.setSource(extractSource(ele));return valueHolder;}else if (subElement != null) {//解析子元素return parsePropertySubElement(subElement, bd);}else {// Neither child element nor "ref" or "value" attribute found.error(elementName + " must specify a ref or value", ele);return null;}
}- 首先略过decription和meta属性
- 提取constructor-arg上的ref和value属性,并验证是否存在
- 存在ref属性时,用RuntimeBeanReference来封装ref
- 存在value属性时,用TypedStringValue来封装value
- 存在子元素时,对于子元素的处理使用了方法parsePropertySubElement(subElement, bd);,其代码如下:
# BeanDefinitionParserDelegate
public Object parsePropertySubElement(Element ele, @Nullable BeanDefinition bd) {return parsePropertySubElement(ele, bd, null);
}
public Object parsePropertySubElement(Element ele, @Nullable BeanDefinition bd, @Nullable String defaultValueType) {//判断是否是默认标签处理if (!isDefaultNamespace(ele)) {return parseNestedCustomElement(ele, bd);}//对于bean标签的处理else if (nodeNameEquals(ele, BEAN_ELEMENT)) {BeanDefinitionHolder nestedBd = parseBeanDefinitionElement(ele, bd);if (nestedBd != null) {nestedBd = decorateBeanDefinitionIfRequired(ele, nestedBd, bd);}return nestedBd;}else if (nodeNameEquals(ele, REF_ELEMENT)) {// A generic reference to any name of any bean.String refName = ele.getAttribute(BEAN_REF_ATTRIBUTE);boolean toParent = false;if (!StringUtils.hasLength(refName)) {// A reference to the id of another bean in a parent context.refName = ele.getAttribute(PARENT_REF_ATTRIBUTE);toParent = true;if (!StringUtils.hasLength(refName)) {error("'bean' or 'parent' is required for <ref> element", ele);return null;}}if (!StringUtils.hasText(refName)) {error("<ref> element contains empty target attribute", ele);return null;}RuntimeBeanReference ref = new RuntimeBeanReference(refName, toParent);ref.setSource(extractSource(ele));return ref;}//idref元素处理else if (nodeNameEquals(ele, IDREF_ELEMENT)) {return parseIdRefElement(ele);}//value元素处理else if (nodeNameEquals(ele, VALUE_ELEMENT)) {return parseValueElement(ele, defaultValueType);}//null元素处理else if (nodeNameEquals(ele, NULL_ELEMENT)) {// It's a distinguished null value. Let's wrap it in a TypedStringValue// object in order to preserve the source location.TypedStringValue nullHolder = new TypedStringValue(null);nullHolder.setSource(extractSource(ele));return nullHolder;}//array元素处理else if (nodeNameEquals(ele, ARRAY_ELEMENT)) {return parseArrayElement(ele, bd);}//list元素处理else if (nodeNameEquals(ele, LIST_ELEMENT)) {return parseListElement(ele, bd);}//set元素处理else if (nodeNameEquals(ele, SET_ELEMENT)) {return parseSetElement(ele, bd);}//map元素处理else if (nodeNameEquals(ele, MAP_ELEMENT)) {return parseMapElement(ele, bd);}//props元素处理else if (nodeNameEquals(ele, PROPS_ELEMENT)) {return parsePropsElement(ele);}else {error("Unknown property sub-element: [" + ele.getNodeName() + "]", ele);return null;}
}3.1.1.7 解析子元素property

# BeanDefinitionParserDelegate
public void parsePropertyElements(Element beanEle, BeanDefinition bd) {NodeList nl = beanEle.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (isCandidateElement(node) && nodeNameEquals(node, PROPERTY_ELEMENT)) {parsePropertyElement((Element) node, bd);}}
}public void parsePropertyElement(Element ele, BeanDefinition bd) {String propertyName = ele.getAttribute(NAME_ATTRIBUTE);if (!StringUtils.hasLength(propertyName)) {error("Tag 'property' must have a 'name' attribute", ele);return;}this.parseState.push(new PropertyEntry(propertyName));try {//不允许多次对同一属性配置if (bd.getPropertyValues().contains(propertyName)) {error("Multiple 'property' definitions for property '" + propertyName + "'", ele);return;}Object val = parsePropertyValue(ele, bd, propertyName);PropertyValue pv = new PropertyValue(propertyName, val);parseMetaElements(ele, pv);pv.setSource(extractSource(ele));bd.getPropertyValues().addPropertyValue(pv);}finally {this.parseState.pop();}
}3.1.1.8 解析子元素qualifier

<bean id="myTestBean" class="com.wangjiafu.spring.MyTestBean"><qualifier type="org.Springframework.beans.factory.annotation.Qualifier" value="gf" />
</bean>3.1.2 AbstractBeanDefinition 属性
public abstract class AbstractBeanDefinition extends BeanMetadataAttributeAccessorimplements BeanDefinition, Cloneable {// 此处省略静态变量以及final变量@Nullableprivate volatile Object beanClass;/*** bean的作用范围,对应bean属性scope*/@Nullableprivate String scope = SCOPE_DEFAULT;/*** 是否是抽象,对应bean属性abstract*/private boolean abstractFlag = false;/*** 是否延迟加载,对应bean属性lazy-init*/private boolean lazyInit = false;/*** 自动注入模式,对应bean属性autowire*/private int autowireMode = AUTOWIRE_NO;/*** 依赖检查,Spring 3.0后弃用这个属性*/private int dependencyCheck = DEPENDENCY_CHECK_NONE;/*** 用来表示一个bean的实例化依靠另一个bean先实例化,对应bean属性depend-on*/@Nullableprivate String[] dependsOn;/*** autowire-candidate属性设置为false,这样容器在查找自动装配对象时,* 将不考虑该bean,即它不会被考虑作为其他bean自动装配的候选者,* 但是该bean本身还是可以使用自动装配来注入其他bean的*/private boolean autowireCandidate = true;/*** 自动装配时出现多个bean候选者时,将作为首选者,对应bean属性primary*/private boolean primary = false;/*** 用于记录Qualifier,对应子元素qualifier*/private final Map<String, AutowireCandidateQualifier> qualifiers = new LinkedHashMap<>(0);@Nullableprivate Supplier<?> instanceSupplier;/*** 允许访问非公开的构造器和方法,程序设置*/private boolean nonPublicAccessAllowed = true;/*** 是否以一种宽松的模式解析构造函数,默认为true,* 如果为false,则在以下情况* interface ITest{}* class ITestImpl implements ITest{};* class Main {* Main(ITest i) {}* Main(ITestImpl i) {}* }* 抛出异常,因为Spring无法准确定位哪个构造函数程序设置*/private boolean lenientConstructorResolution = true;/*** 对应bean属性factory-bean,用法:* <bean id = "instanceFactoryBean" class = "example.chapter3.InstanceFactoryBean" />* <bean id = "currentTime" factory-bean = "instanceFactoryBean" factory-method = "createTime" />*/@Nullableprivate String factoryBeanName;/*** 对应bean属性factory-method*/@Nullableprivate String factoryMethodName;/*** 记录构造函数注入属性,对应bean属性constructor-arg*/@Nullableprivate ConstructorArgumentValues constructorArgumentValues;/*** 普通属性集合*/@Nullableprivate MutablePropertyValues propertyValues;/*** 方法重写的持有者,记录lookup-method、replaced-method元素*/@Nullableprivate MethodOverrides methodOverrides;/*** 初始化方法,对应bean属性init-method*/@Nullableprivate String initMethodName;/*** 销毁方法,对应bean属性destroy-method*/@Nullableprivate String destroyMethodName;/*** 是否执行init-method,程序设置*/private boolean enforceInitMethod = true;/*** 是否执行destroy-method,程序设置*/private boolean enforceDestroyMethod = true;/*** 是否是用户定义的而不是应用程序本身定义的,创建AOP时候为true,程序设置*/private boolean synthetic = false;/*** 定义这个bean的应用,APPLICATION:用户,INFRASTRUCTURE:完全内部使用,与用户无关,* SUPPORT:某些复杂配置的一部分* 程序设置*/private int role = BeanDefinition.ROLE_APPLICATION;/*** bean的描述信息*/@Nullableprivate String description;/*** 这个bean定义的资源*/@Nullableprivate Resource resource;
}3.1.3 默认标签中的自定义标签解析

<bean id="demo" class="com.wangjiafu.spring.MyTestBean"><property name="beanName" value="bean demo1"/><meta key="demo" value="demo"/><mybean:username="mybean"/></bean># BeanDefinitionParserDelegate
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(Element ele, BeanDefinitionHolder definitionHolder) {return decorateBeanDefinitionIfRequired(ele, definitionHolder, null);
}
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(Element ele, BeanDefinitionHolder definitionHolder, @Nullable BeanDefinition containingBd) {BeanDefinitionHolder finalDefinition = definitionHolder;// Decorate based on custom attributes first.NamedNodeMap attributes = ele.getAttributes();for (int i = 0; i < attributes.getLength(); i++) {Node node = attributes.item(i);finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);}// Decorate based on custom nested elements.NodeList children = ele.getChildNodes();for (int i = 0; i < children.getLength(); i++) {Node node = children.item(i);if (node.getNodeType() == Node.ELEMENT_NODE) {finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);}}return finalDefinition;
}# BeanDefinitionParserDelegate
public BeanDefinitionHolder decorateIfRequired(Node node, BeanDefinitionHolder originalDef, @Nullable BeanDefinition containingBd) {// 获取自定义标签的命名空间String namespaceUri = getNamespaceURI(node);// 过滤掉默认命名标签if (namespaceUri != null && !isDefaultNamespace(namespaceUri)) {// 获取相应的处理器NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);if (handler != null) {// 进行装饰处理BeanDefinitionHolder decorated =handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd));if (decorated != null) {return decorated;}}else if (namespaceUri.startsWith("http://www.springframework.org/")) {error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", node);}else {if (logger.isDebugEnabled()) {logger.debug("No Spring NamespaceHandler found for XML schema namespace [" + namespaceUri + "]");}}}return originalDef;
}public String getNamespaceURI(Node node) {return node.getNamespaceURI();
}public boolean isDefaultNamespace(@Nullable String namespaceUri) {//BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";return (!StringUtils.hasLength(namespaceUri) || BEANS_NAMESPACE_URI.equals(namespaceUri));
}3.1.4 注册解析的BeanDefinition

# BeanDefinitionReaderUtils
public static void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)throws BeanDefinitionStoreException {// Register bean definition under primary name.//使用beanName做唯一标识注册String beanName = definitionHolder.getBeanName();registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());// Register aliases for bean name, if any.//注册所有的别名String[] aliases = definitionHolder.getAliases();if (aliases != null) {for (String alias : aliases) {registry.registerAlias(beanName, alias);}}
}3.1.4.1 通过beanName注册BeanDefinition

# DefaultListableBeanFactory
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)throws BeanDefinitionStoreException {// 校验 beanName 与 beanDefinitionAssert.hasText(beanName, "Bean name must not be empty");Assert.notNull(beanDefinition, "BeanDefinition must not be null");if (beanDefinition instanceof AbstractBeanDefinition) {try {// 校验 BeanDefinition// 这是注册前的最后一次校验了,主要是对属性 methodOverrides 进行校验((AbstractBeanDefinition) beanDefinition).validate();}catch (BeanDefinitionValidationException ex) {throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,"Validation of bean definition failed", ex);}}BeanDefinition oldBeanDefinition;// 从缓存中获取指定 beanName 的 BeanDefinitionoldBeanDefinition = this.beanDefinitionMap.get(beanName);/*** 如果存在*/if (oldBeanDefinition != null) {// 如果存在但是不允许覆盖,抛出异常if (!isAllowBeanDefinitionOverriding()) {throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +"': There is already [" + oldBeanDefinition + "] bound.");}//else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTUREif (this.logger.isWarnEnabled()) {this.logger.warn("Overriding user-defined bean definition for bean '" + beanName +"' with a framework-generated bean definition: replacing [" +oldBeanDefinition + "] with [" + beanDefinition + "]");}}// 覆盖 beanDefinition 与 被覆盖的 beanDefinition 不是同类else if (!beanDefinition.equals(oldBeanDefinition)) {if (this.logger.isInfoEnabled()) {this.logger.info("Overriding bean definition for bean '" + beanName +"' with a different definition: replacing [" + oldBeanDefinition +"] with [" + beanDefinition + "]");}}else {if (this.logger.isDebugEnabled()) {this.logger.debug("Overriding bean definition for bean '" + beanName +"' with an equivalent definition: replacing [" + oldBeanDefinition +"] with [" + beanDefinition + "]");}}// 允许覆盖,直接覆盖原有的 BeanDefinitionthis.beanDefinitionMap.put(beanName, beanDefinition);}/*** 不存在*/else {// 检测创建 Bean 阶段是否已经开启,如果开启了则需要对 beanDefinitionMap 进行并发控制if (hasBeanCreationStarted()) {// beanDefinitionMap 为全局变量,避免并发情况synchronized (this.beanDefinitionMap) {//this.beanDefinitionMap.put(beanName, beanDefinition);List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);updatedDefinitions.addAll(this.beanDefinitionNames);updatedDefinitions.add(beanName);this.beanDefinitionNames = updatedDefinitions;if (this.manualSingletonNames.contains(beanName)) {Set<String> updatedSingletons = new LinkedHashSet<>(this.manualSingletonNames);updatedSingletons.remove(beanName);this.manualSingletonNames = updatedSingletons;}}}else {// 不会存在并发情况,直接设置this.beanDefinitionMap.put(beanName, beanDefinition);this.beanDefinitionNames.add(beanName);this.manualSingletonNames.remove(beanName);}this.frozenBeanDefinitionNames = null;}if (oldBeanDefinition != null || containsSingleton(beanName)) {// 重新设置 beanName 对应的缓存resetBeanDefinition(beanName);}
}- 首先 对BeanDefinition 进行校验,该校验也是注册过程中的最后一次校验了,主要是对 AbstractBeanDefinition 的 methodOverrides 属性进行校验。
- 其次根据 beanName 从缓存中获取 BeanDefinition,如果缓存中存在,则根据 allowBeanDefinitionOverriding 标志来判断是否允许覆盖,如果允许则直接覆盖,否则抛出 BeanDefinitionStoreException 异常。
- 若缓存中没有指定 beanName 的 BeanDefinition,则判断当前阶段是否已经开始了 Bean 的创建阶段(),如果是,则需要对 beanDefinitionMap 进行加锁控制并发问题,否则直接设置即可。对于 hasBeanCreationStarted() 方法后续做详细介绍,这里不过多阐述。
- 若缓存中存在该 beanName 或者 单例 bean 集合中存在该 beanName,则调用 resetBeanDefinition() 重置 BeanDefinition 缓存。
3.1.4.2 通过别名注册BeanDefinition

# SimpleAliasRegistry
public void registerAlias(String name, String alias) {Assert.hasText(name, "'name' must not be empty");Assert.hasText(alias, "'alias' must not be empty");synchronized (this.aliasMap) {if (alias.equals(name)) {this.aliasMap.remove(alias);}else {String registeredName = this.aliasMap.get(alias);if (registeredName != null) {if (registeredName.equals(name)) {// An existing alias - no need to re-registerreturn;}if (!allowAliasOverriding()) {throw new IllegalStateException("Cannot register alias '" + alias + "' for name '" +name + "': It is already registered for name '" + registeredName + "'.");}}//当A->B存在时,若再次出现A->C->B时候则会抛出异常。checkForAliasCircle(name, alias);this.aliasMap.put(alias, name);}}
}3.1.5 通知监听器解析及注册完成_可扩展

3.2 alisa标签的解析

<bean id="demo" class="com.wangjiafu.spring.MyTestBean" name="demo1,demo2"><property name="beanName" value="bean demo1"/>
</bean><bean id="myTestBean" class="com.wangjiafu.spring.MyTestBean"/>
<alias name="myTestBean" alias="testBean1,testBean2"/># DefaultBeanDefinitionDocumentReader
protected void processAliasRegistration(Element ele) {//获取beanNameString name = ele.getAttribute(NAME_ATTRIBUTE);//获取aliasString alias = ele.getAttribute(ALIAS_ATTRIBUTE);boolean valid = true;if (!StringUtils.hasText(name)) {getReaderContext().error("Name must not be empty", ele);valid = false;}if (!StringUtils.hasText(alias)) {getReaderContext().error("Alias must not be empty", ele);valid = false;}if (valid) {try {//注册aliasgetReaderContext().getRegistry().registerAlias(name, alias);}catch (Exception ex) {getReaderContext().error("Failed to register alias '" + alias +"' for bean with name '" + name + "'", ele, ex);}getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));}
}3.3 import标签的解析

<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsd"><bean id="demo" class="com.wangjiafu.spring.MyTestBean" name="demo1,demo2"><property name="beanName" value="bean demo1"/></bean><import resource="lookup-method.xml"/><import resource="replaced-method.xml"/>
</beans># DefaultBeanDefinitionDocumentReader.class
protected void importBeanDefinitionResource(Element ele) {// 获取 resource 的属性值 String location = ele.getAttribute(RESOURCE_ATTRIBUTE);// 为空,直接退出if (!StringUtils.hasText(location)) {getReaderContext().error("Resource location must not be empty", ele);return;}// 解析系统属性,格式如 :"${user.dir}"location = getReaderContext().getEnvironment().resolveRequiredPlaceholders(location);Set<Resource> actualResources = new LinkedHashSet<>(4);// 判断 location 是相对路径还是绝对路径boolean absoluteLocation = false;try {absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();}catch (URISyntaxException ex) {// cannot convert to an URI, considering the location relative// unless it is the well-known Spring prefix "classpath*:"}// 绝对路径if (absoluteLocation) {try {// 直接根据地址加载相应的配置文件int importCount = getReaderContext().getReader().loadBeanDefinitions(location, actualResources);if (logger.isDebugEnabled()) {logger.debug("Imported " + importCount + " bean definitions from URL location [" + location + "]");}}catch (BeanDefinitionStoreException ex) {getReaderContext().error("Failed to import bean definitions from URL location [" + location + "]", ele, ex);}}else {// 相对路径则根据相应的地址计算出绝对路径地址try {int importCount;Resource relativeResource = getReaderContext().getResource().createRelative(location);if (relativeResource.exists()) {importCount = getReaderContext().getReader().loadBeanDefinitions(relativeResource);actualResources.add(relativeResource);}else {String baseLocation = getReaderContext().getResource().getURL().toString();importCount = getReaderContext().getReader().loadBeanDefinitions(StringUtils.applyRelativePath(baseLocation, location), actualResources);}if (logger.isDebugEnabled()) {logger.debug("Imported " + importCount + " bean definitions from relative location [" + location + "]");}}catch (IOException ex) {getReaderContext().error("Failed to resolve current resource location", ele, ex);}catch (BeanDefinitionStoreException ex) {getReaderContext().error("Failed to import bean definitions from relative location [" + location + "]",ele, ex);}}// 解析成功后,进行监听器激活处理Resource[] actResArray = actualResources.toArray(new Resource[0]);getReaderContext().fireImportProcessed(location, actResArray, extractSource(ele));
}- 获取 source 属性的值,该值表示资源的路径
- 解析路径中的系统属性,如”${user.dir}”
- 判断资源路径 location 是绝对路径还是相对路径
- 如果是绝对路径,则调递归调用 Bean 的解析过程,进行另一次的解析
- 如果是相对路径,则先计算出绝对路径得到 Resource,然后进行解析
- 通知监听器,完成解析

- 以 classpath*: 或者 classpath: 开头为绝对路径
- 能够通过该 location 构建出 java.net.URL为绝对路径
- 根据 location 构造 java.net.URI 判断调用 isAbsolute() 判断是否为绝对路径
# AbstractBeanDefinitionReader
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {ResourceLoader resourceLoader = getResourceLoader();if (resourceLoader == null) {throw new BeanDefinitionStoreException("Cannot import bean definitions from location [" + location + "]: no ResourceLoader available");}if (resourceLoader instanceof ResourcePatternResolver) {// Resource pattern matching available.try {Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);int loadCount = loadBeanDefinitions(resources);if (actualResources != null) {for (Resource resource : resources) {actualResources.add(resource);}}if (logger.isDebugEnabled()) {logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]");}return loadCount;}catch (IOException ex) {throw new BeanDefinitionStoreException("Could not resolve bean definition resource pattern [" + location + "]", ex);}}else {// Can only load single resources by absolute URL.Resource resource = resourceLoader.getResource(location);int loadCount = loadBeanDefinitions(resource);if (actualResources != null) {actualResources.add(resource);}if (logger.isDebugEnabled()) {logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]");}return loadCount;}
}- 获取 source 属性值
- 得到正确的资源路径
- 调用 loadBeanDefinitions() 方法进行递归的 BeanDefinition 加载。
3.4 嵌入式beans标签的解析

<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsd"><bean id="demo" class="com.wangjiafu.spring.MyTestBean" name="demo1,demo2"><property name="beanName" value="bean demo1"/></bean><beans></beans>
</beans>与单独的配置文件并没有太大差别,无非是递归调用beans的解析过程。
相关文章:
【Spring详解三】默认标签的解析
三、默认标签的解析 Spring的标签中有 默认标签和 自定义标签,两者的解析有着很大的不同,这次重点说默认标签的解析过程。 DefaultBeanDefinitionDocumentReader.class 默认标签的解析是在 DefaultBeanDefinitionDocumentReader.parseDefaultElement()函…...

Windows 图形显示驱动开发-IoMmu 模型
输入输出内存管理单元 (IOMMU) 是一个硬件组件,它将支持具有 DMA 功能的 I/O 总线连接到系统内存。 它将设备可见的虚拟地址映射到物理地址,使其在虚拟化中很有用。 在 WDDM 2.0 IoMmu 模型中,每个进程都有一个虚拟地址空间,即&a…...

简单易懂,解析Go语言中的Channel管道
Channel 管道 1 初始化 可用var声明nil管道;用make初始化管道; len(): 缓冲区中元素个数, cap(): 缓冲区大小 //变量声明 var a chan int //使用make初始化 b : make(chan int) //不带缓冲区 c : make(chan stri…...

STM32 USB 设备的描述信息作用
在使用 STM32 USB 功能时 usbd_desc.c 文件中定义了一段宏,以下解每段宏的用途。 #define USBD_VID 1155 #define USBD_LANGID_STRING 1033 #define USBD_MANUFACTURER_STRING "STMicroelectronics" #define US…...
)
Redis字符串常见命令(String)
字符串常见命令(String) Redis 中的字符串类型是一种非常基础且常用的数据类型,它不仅可以存储任何形式的字符串(包括文本数据),还可以对数字字符串进行自增、自减等操作。以下是对 Redis 字符串类型常见命…...
Educational Codeforces Round 174 (Rated for Div. 2)(ABCD)
A. Was there an Array? 翻译: 对于整数数组 ,我们将其相等特征定义为数组 ,其中,如果数组 a 的第 i 个元素等于其两个相邻元素,则 ;如果数组 a 的第 i 个元素不等于其至少一个相邻元素,则 …...

基于知识图谱的问答系统:后端Python+Flask,数据库Neo4j,前端Vue3(提供源码)
基于知识图谱的问答系统:后端PythonFlask,数据库Neo4j,前端Vue3 引言 随着人工智能技术的不断发展,知识图谱作为一种结构化的知识表示方式,逐渐成为问答系统的重要组成部分。本文将介绍如何构建一个基于知识图谱的问答…...

面试知识点2
文章目录 1. Linux 与 DockerLinux 基本指令VMware 安装 CentOSDocker 拉取镜像创建容器、部署 Spring Boot 项目 2. 关系型数据库 MySQL数据库语法多表关联查询数据库索引 3. 事务与死锁事务的隔离级别死锁的原因和避免方法 4. 排序算法与数据结构二分查找快速排序常见数据结构…...

Django项目之订单管理part1
一.前言 我们前面把django的常用知识点给讲完了,现在我们开始项目部分,项目是一个订单管理系统,我们同时也会在项目之中也会讲一些前面没有用到的知识点。 项目大概流程如下: 核心的功能模块: 认证模块,用…...
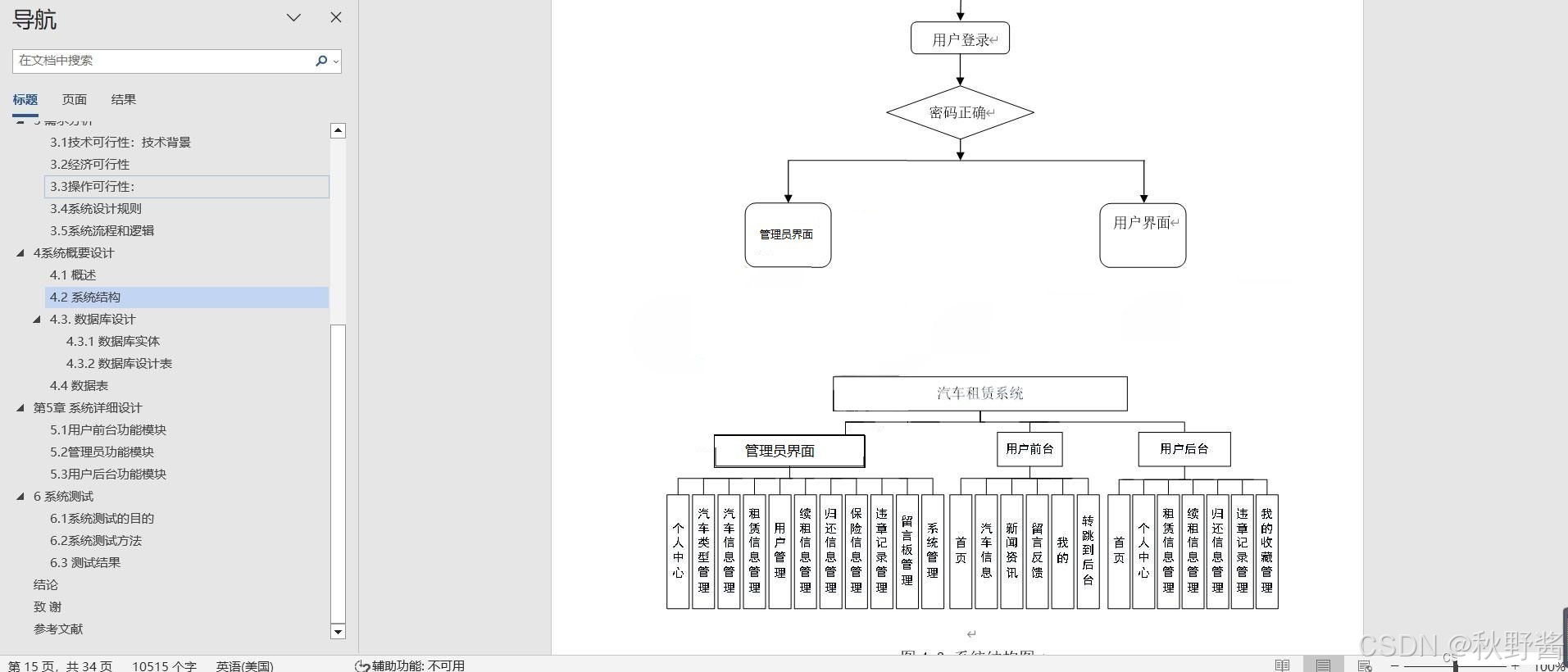
基于SSM+Vue的智能汽车租赁平台设计和实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论…...

deepseek本地调用
目录 1.介绍 2.开始调用 2.1模型检验 2.2 通过url调用 3.总结 1.介绍 这篇博客用来教你如何从本地调用ollama中deepseek的模型接口,直接和deepseek进行对话。 2.开始调用 2.1模型检验 首先要保证ollama已经安装到本地,并且已经下载了deepseek模型…...
文件同步工具哪家强?FreeFileSync 免费无限制
FreeFileSync 是一款备受推崇的开源文件同步与备份软件,凭借其卓越的功能和简洁直观的界面,赢得了全球用户的青睐。该软件不仅支持跨平台操作,兼容 Windows、macOS 和 Linux 系统,还能帮助用户在不同设备之间无缝同步文件…...

捷米特 JM - RTU - TCP 网关应用 F - net 协议转 Modbus TCP 实现电脑控制流量计
一、项目背景 在某工业生产园区的供水系统中,为了精确监测和控制各个生产环节的用水流量,需要对分布在不同区域的多个流量计进行集中管理。这些流量计原本采用 F - net 协议进行数据传输,但园区的监控系统基于 Modbus TCP 协议进行数据交互&…...

Coze扣子怎么使用更强大doubao1.5模型
最近,豆包刚刚发布了最新的doubao1.5系列模型,并且加量不加价。 在性能极大进步的情况下,价格还与之前一致。真是业界良心了。 在同样的价格下,肯定要使用性能更强大的模型嘛 于是我准备把所有的智能体和工作流切换到doubao1.5…...
)
layui 远程搜索下拉选择组件(多选)
模板使用(lay-module/searchSelect),依赖于 jquery、layui.dist 中的 dropdown 模块实现(所以data 格式请参照 layui文档) <link rel"stylesheet" href"layui-v2.5.6/dist/css/layui.css" /&g…...

嵌入式学习(18)---Linux文件编程中的进程
一、进程的概念 进程:(用来描述 程序动态执行的过程,方便操作系统管理的) 进行中的程序 程序的一次执行过程 (内存 CPU) 程序的实例 程序 ----加载到内存----> 进程 应用场景: 实现并发 同一时刻 同时发生 并行 …...

一.AI大模型开发-初识机器学习
机器学习基本概念 前言 本文主要介绍了深度学习基础,包括机器学习、深度学习的概念,机器学习的两种典型任务分类任务和回归任务,机器学习中的基础名词解释以及模型训练的基本流程等。 一.认识机器学习 1.人工智能和机器学习 人工智能&am…...

RoCE和 TCP的区别
RoCE(RDMA over Converged Ethernet)和 TCP(Transmission Control Protocol)都是用于数据传输的协议,但它们在多个方面存在显著区别,以下为你详细介绍: 设计目标 RoCE:主要设计目标…...

勒索病毒攻击:如何应对和恢复
近年来,勒索病毒(Ransomware)已经成为全球信息安全领域最具破坏力的威胁之一。无论是个人用户,还是大中型企业,甚至政府机构,勒索病毒的攻击频率和破坏性日益增加。2020年及2021年,勒索病毒攻击不仅数量激增,且其攻击手法、目标和传播方式也变得更加复杂、精密和具有针…...

解决MySQL错误:You can‘t specify target table ‘xxx‘ for update in FROM clause
目录 错误复现场景原因分析解决方案方法1:使用派生表(推荐)方法2:改用JOIN操作方法3:使用临时表 总结 在编写MySQL的UPDATE或DELETE语句时,如果子查询中直接引用了要操作的目标表,可能会遇到一个…...

百灵快传:三分钟搭建你的局域网文件共享神器,让跨设备传输变得如此简单
百灵快传:三分钟搭建你的局域网文件共享神器,让跨设备传输变得如此简单 【免费下载链接】b0pass 百灵快传(B0Pass):基于Go语言的高性能 "手机电脑超大文件传输神器"、"局域网共享文件服务器"。LAN large file transfer t…...
)
告别串口调试烦恼:STM32 HAL库下三种printf重定向方案保姆级教程(含MicroLIB与标准库对比)
STM32 HAL库下printf重定向的三种高效方案与实战避坑指南 在嵌入式开发中,串口调试是工程师最常用的调试手段之一。然而,许多开发者在使用STM32 HAL库时,常常会遇到printf输出乱码、系统卡死、多任务冲突等问题。本文将深入探讨三种主流的pri…...

MYSQL优化器的主要的优化策略及其示例
MySQL 优化器除了 自动将 WHERE 条件前置(谓词下推,Predicate Pushdown) 之外,还会进行许多其他关键优化,以提高查询性能。以下是主要的优化策略及其示例:1. 查询重写(Query Rewritingÿ…...

独立开发者如何借助 Taotoken 模型广场快速选型与对比测试
独立开发者如何借助 Taotoken 模型广场快速选型与对比测试 1. 模型选型的核心挑战 独立开发者在项目初期常面临模型选型难题。不同功能模块对语言模型的需求各异,例如对话系统需要强上下文理解,而数据清洗可能更看重结构化输出能力。传统方式需要逐一注…...

别再到处找现成的了!手把手教你用CentOS 7.9定制一个带专属软件的LiveCD启动盘
从零构建企业级CentOS 7.9定制化LiveCD实战指南 每次新员工入职都要重复配置相同的开发环境?客户演示时总被环境差异搞得手忙脚乱?教学实验室的机器配置参差不齐?这些场景正是定制化LiveCD大显身手的地方。本文将带你深入掌握基于CentOS 7.9打…...

一个标准 Java SpringBoot 项目 Git ignore 文件
一个标准 Java SpringBoot 项目 Git ignore 文件 target/ !.mvn/wrapper/maven-wrapper.jar !**/src/main/**/target/ !**/src/test/**/target/ .kotlin### IntelliJ IDEA ### .idea/modules.xml .idea/jarRepositories.xml .idea/compiler.xml .idea/libraries/ *.iws *.iml *…...

从CRN到DPCRN:语音增强模型演进中的‘分而治之’哲学与实战调优心得
从CRN到DPCRN:语音增强模型演进中的‘分而治之’哲学与实战调优心得 语音增强技术正经历从传统信号处理到深度学习的范式迁移。当我在2020年首次接触Conv-TasNet时,就被时域端到端方案对相位信息的隐式处理所震撼,但随之而来的长序列建模难题…...
)
保姆级教程:在RT-Thread Studio里给STM32F407VET6接上W5500模块(SPI版)
STM32F407与W5500模块的RT-Thread全流程开发指南 1. 开发环境搭建与工程创建 在嵌入式网络通信领域,W5500硬件TCP/IP协议栈芯片因其稳定的性能和简单的SPI接口而广受欢迎。我们将使用RT-Thread Studio这个专为RT-Thread优化的集成开发环境,基于STM32F407…...

如何快速掌握Windows Cleaner:解决C盘空间危机的完整指南
如何快速掌握Windows Cleaner:解决C盘空间危机的完整指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你的Windows电脑是不是经常弹出"磁盘空…...

bp的使用
BP 在 CTF 中的使用BP(Binary Patch)在 CTF(Capture The Flag)竞赛中常用于修改二进制文件的行为,绕过保护机制或直接获取 flag。以下是常见的使用场景和方法:修改关键跳转或条件通过工具如 IDA Pro、Ghidr…...